not great • Redshift ◦ Concurrency limits • Aurora (MySQL) ◦ Aggregations are not optimized • Memsql ◦ Insufficient performance ◦ Too pricy • Cassandra ◦ Not flexible
redundancy or HA, thus not recommended • Via Indexing Service and Tranquility API ◦ Core API ◦ Integrations with Streaming Frameworks ◦ HTTP Server ◦ Kafka Consumer
• Top N ◦ like grouping by a single dimension • Timeseries ◦ w/o grouping over dimensions • Search ◦ Dimensions lookup • Time boundary ◦ Find available data timeframe • Metadata queries
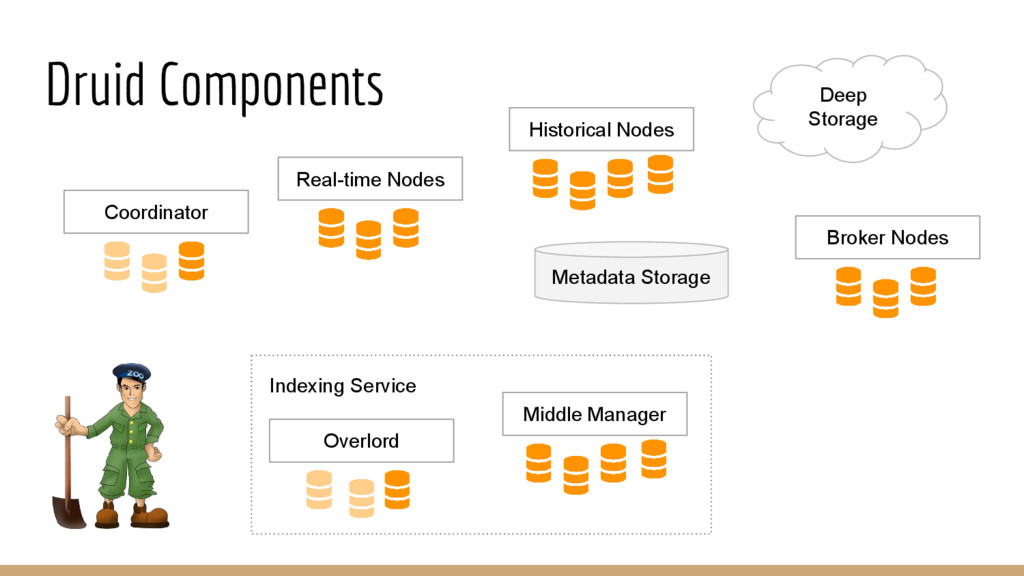
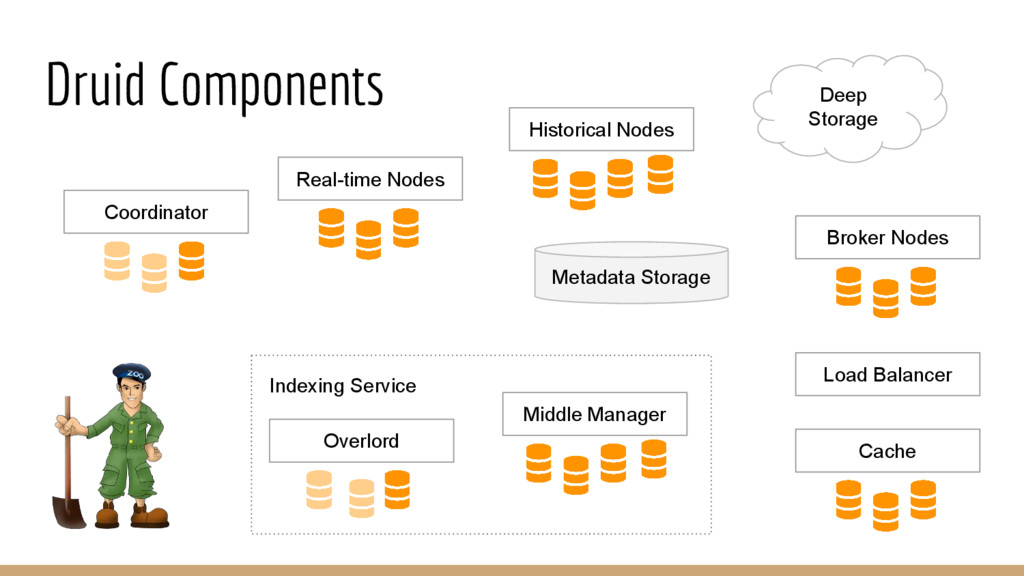
◦ Tasks are replicated ◦ Pool of nodes • Historical nodes ◦ Data is replicated ◦ Pool of nodes ◦ All segments are backed up in the deep storage • Brokers ◦ Pool of nodes ◦ Load balancer at the front
configuration is OK) • Redundancy for coordinator and overlord (node per AZ) • Historical and real-time nodes are spread between AZ • LB - Consul from Hashicorp • Service discovery - Consul again • Memcached • Monitoring via Graphite Emitter extension ◦ https://github.com/druid-io/druid/pull/1978 • Alerting via Sensu
for ZK machines • Use latest version (0.8.3) ◦ Restartable tasks ◦ Indexing time improvement! (https://github.com/druid-io/druid/pull/1960) ◦ Data sketches library • All exceptions are useful
Rebuild everything to order by your timestamp • Or, use single-dimension partitioning ◦ Segments partitioned by timestamp first, then by dimension range ◦ Find optimal target segment size Still, please don’t use Druid for non-time series!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Sample Query ~# curl -X POST [email protected] -H "Content-Type: application/json"](https://files.speakerdeck.com/presentations/db013133d8e9453da04a560fb542efdd/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}