Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Design for Retry (Nodevember)
Search
Aria Stewart
November 15, 2014
Programming
59
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Design for Retry (Nodevember)
Aria Stewart
November 15, 2014
More Decks by Aria Stewart
See All by Aria Stewart
Nuts and Bolts of Internationalization
aredridel
0
240
Design for Retry (Oneshot Budapest)
aredridel
0
71
Other Decks in Programming
See All in Programming
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
540
ここ半年くらいでAIに作らせたR用ツール
eitsupi
0
170
AI時代、エンジニアはどう育つのか -未経験エンジニアの成長を間近で見て考えたこと-
thasu0123
0
140
Augmenting AI with the Power of Jakarta EE
ivargrimstad
0
180
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
1
220
php-fpmのプロセスが枯渇した日-調査・対処・そして本当にやるべきだったこと-
shibuchaaaan
0
130
The Bowling Game - From Imperative to Functional Programming - Part 1
philipschwarz
PRO
0
340
霧の中の代数的エフェクト
funnyycat
1
420
「正の参照」と 「負の導出」で組む ハーネスエンジニアリング
cottpan
1
150
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
16
3.6k
作るコストが小さくなった時代 幸せに働くために改めて考えたいこと 〜エンジニアとして価値を出し続けるために注視している二分野〜
yuppeeng
0
120
AI駆動開発を妨げる技術的負債の解消アプローチ / ai-refactoring-approach
minodriven
17
9.3k
Featured
See All Featured
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
280
A Soul's Torment
seathinner
6
3.1k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Designing for Timeless Needs
cassininazir
1
400
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
It's Worth the Effort
3n
188
29k
Embracing the Ebb and Flow
colly
88
5.1k
Typedesign – Prime Four
hannesfritz
42
3.1k
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
Ethics towards AI in product and experience design
skipperchong
2
330
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Transcript
None
Hi! I'm Aria Stewart, that's @aredridel on just about every
service out there. Right now I'm an engineer at PayPal, working on the open source Kraken.js framework.
I'm going to talk about errors. It's going to be
okay.
We all know HTTP
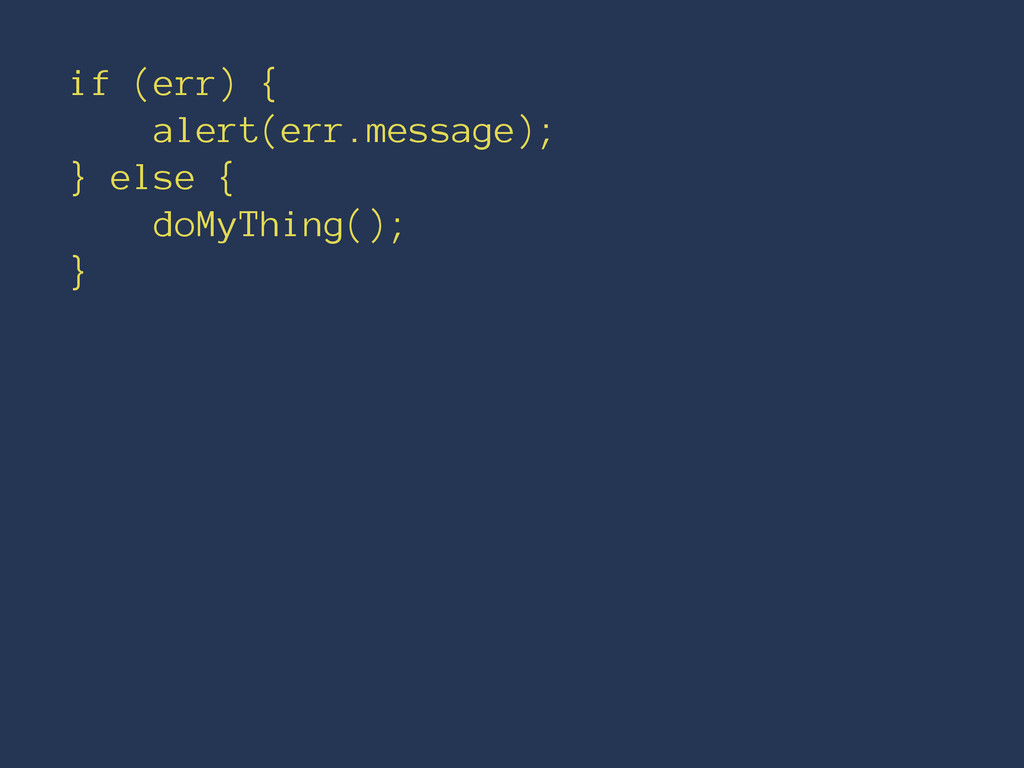
if (err) { alert(err.message); } else { doMyThing(); }
2xx OK 3xx Go elsewhere 4xx Tell user what they
did wrong 5xx Bail out and log an error I'd call this Error avoidance
You can't avoid errors
Here's the secret Handle errors instead
4xx Tell the user what they did wrong 5xx Save
that request and do something with it later.
Retry it 5xx are errors the requestor can handle
But you can't just do things twice? We must make
operations idempotent
Idempotency Repeated actions have no effect, give the same result
This means being smart about IDs. Don't recycle! Check if things are already done. They are? Just give the same answer again.
Causes! • database down • bug in a service •
Deploy in progress • power failure • kicked a cable • Network congestion • Capacity exceeded • Microbursts
• Tree fell on the data center • earthquake •
tornado • birds, snakes and aeroplanes • Black Friday • Slashdot effect • Interns • QA tests • DoS attack
You need a queue
Lots of ways to do it Database on the nodes
Log file Queue server
gearman Queues built in There are many alternatives, but gearmand
is very simple. The memcache of job queues.
Three statuses: • OK (Like 200) • FAIL (Like 400)
• ERROR (Like 500)
design so ERROR can be retried.
gearmand automatically tries a job ERROR again. And again. And
again.
If it isn't sure it worked? Tries it again.
You cannot know if an error is a failure.
Error handling gets simpler • Exception? ERROR. • Database down?
ERROR. • Downstream service timeout? ERROR. Maybe you retry right away.
How many of you have used a job queue?
You have used a job queue
Let me tell you about one TRILLIONS of messages MILLIONS
of nodes 100% availability (at least partial) for years. 32 years. Resilient to MILLIONS of bad actors. It is attached to the most malicious network.
EMAIL. 250 OK 4xx RETRY 5xx Fail
Responsibility for messages 250 - accept responsibility 4xx - reject
responsibility 5xx - return responsibility
reject responsibility. If there's an error? Fail fast. The requester
can retry.
Fail fast. Queue work you can't reject. Reject everything you
can if there is an error.
You need a smart client. Keeps outstanding requests. Resubmit. Try
a different server! Try a second queue service. Maybe have a fallback plan.
Smart Clients on the device Toto, we're not in AWS
anymore.
Ever lose an email because you've been logged out?
Latency + Mutable state = Distributed system CAP Theorem Applies!
C = Consistency If there's state that one part knows
of that another doesn't? That's inconsistency.
Job queues are controlled inconsistency.
Ever try to write email on the web while not
on the Internet? It's cloud easy!
This is really good for offline- first design! Being offline
is the ultimate retriable error.
Some ideas
Queue things in localStorage
Use third-party storage
Integrate third-party services with this approach.
Use different strategies for available resources vs contended
Thank you! I hope you have lots of ideas queued
up. Save your ideas and unspool them onto Twitter when you get home. Let me know if this changed how you think about designing applications!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}