be Distributed too • Failover does not work • Services have multiple end points • Clients prefer local calls, but can tolerate remote calls • Service itself handles coordination
this hard? • Failover does not work • Easy for stateless app servers • Harder for stateful data stores • Multi-Master Datastores • Percona MySQL XtraDB Cluster • Replaced DRBD pair • Cassandra • Zookeeper
this hard? • Multiple end-points and local vs. remote calls • Service is backed by HAProxy locally • Even if the service is failing on the host, HAProxy can re-route • Eventually host is marked as bad • HAProxy prefers local calls
this hard? • Cannot use vendor specific tools • No AWS specific services • All servers have to be treated as bare metal • Network routes need to be distributed • AWS regions share common peering points
Fridays at Pagerduty • Attack our own services • Based on Netflix’s Simian Army • Service shutdown • Network blocks • Network slowness • Single Host Failure • Regional and Datacenter Failure
![PagerDuty Arup Chakrabarti OPERATIONS ENGINEERING @arupchak [email protected] Distributed Systems at](https://files.speakerdeck.com/presentations/dc509cd0bdd3013191822a9c30b9cc56/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
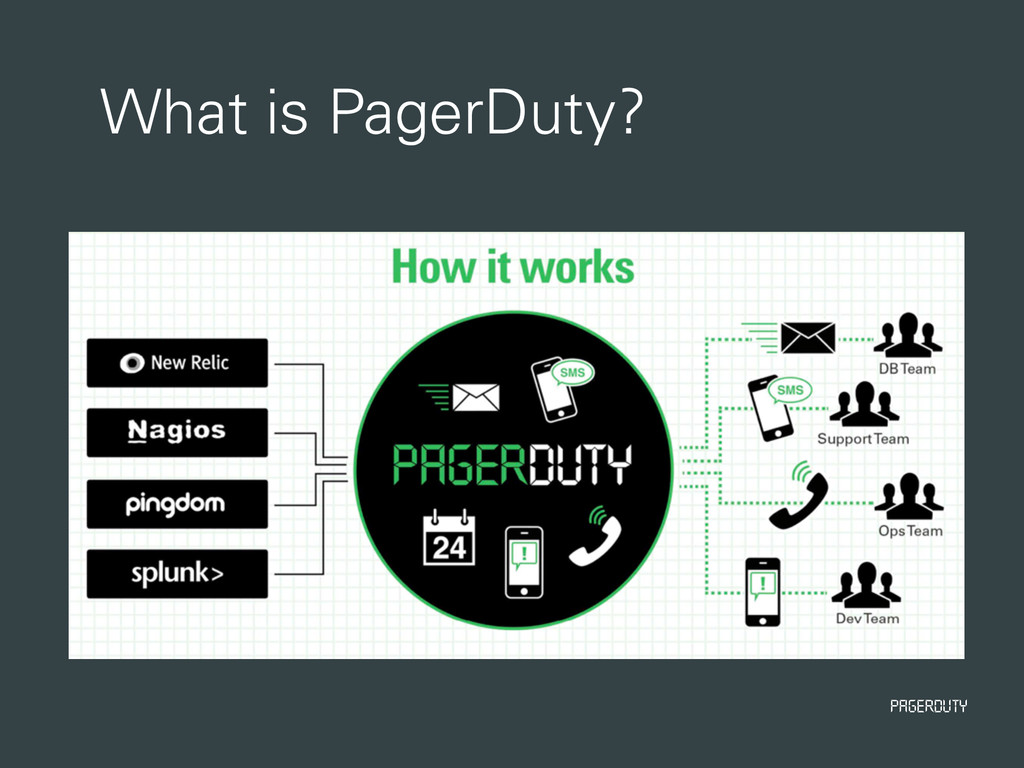{kind=link}
{kind=link}
{kind=link}
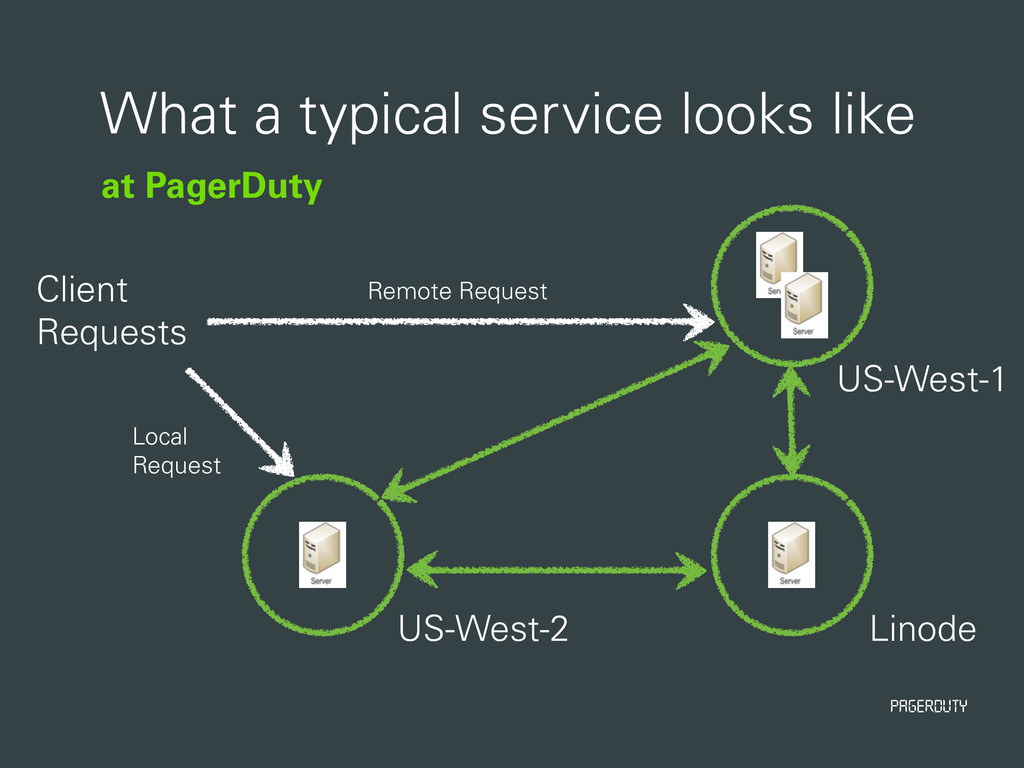{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
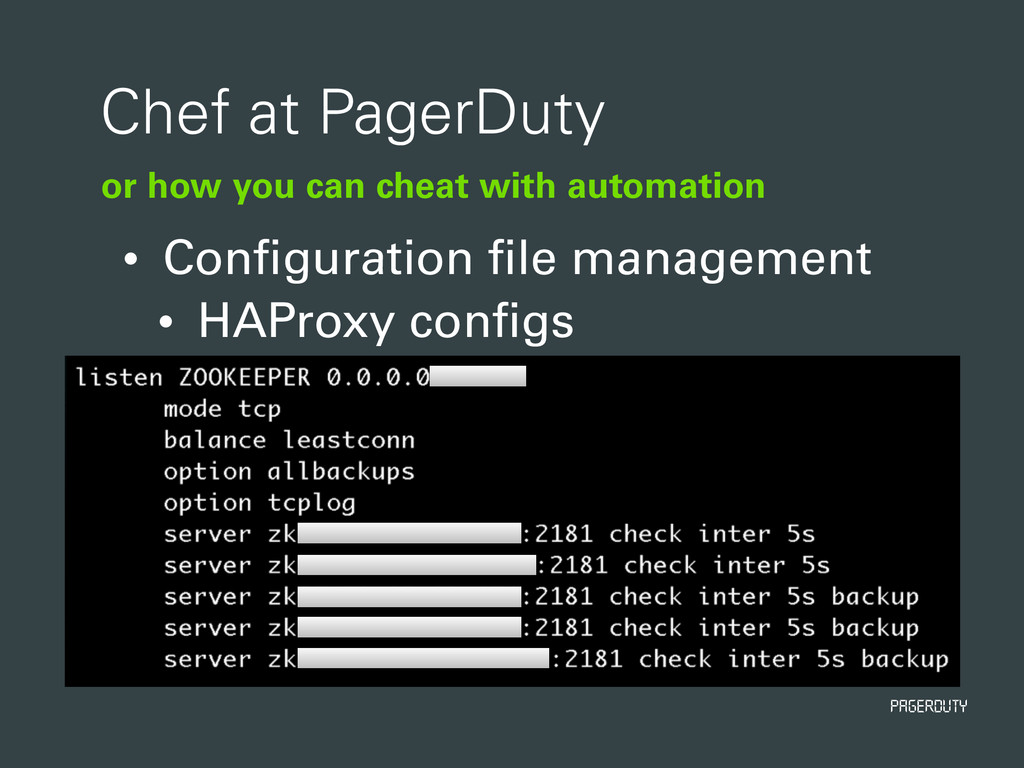{kind=link}
{kind=link}
![PagerDuty [email protected] Thank you. We are hiring! http://pagerduty.com/jobs Arup Chakrabarti](https://files.speakerdeck.com/presentations/dc509cd0bdd3013191822a9c30b9cc56/slide_14.jpg){kind=link}