Truck Factor (also known as Bus Factor or Lottery Number) is the minimal number of developers that have to be hit by a truck (or leave) before a project is incapacitated. Therefore, it is a measure that reveals the concentration of knowledge and the key developers in a project. Due to the importance of this information to project managers, algorithms were proposed to automatically compute Truck Factors, using maintenance activity data extracted from version control systems. However, to the best of our knowledge, we still lack studies that compare the accuracy of the results produced by such algorithms. Therefore, in this paper, we evaluate and compare the results of three Truck Factor algorithms. To this end, we empirically determine the truck factors of 35 open-source systems by consulting their developers. Our results show that two algorithms are very accurate, especially when the systems have a small Truck Factor. We also evaluate the impact of different thresholds and configurations in algorithm results.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
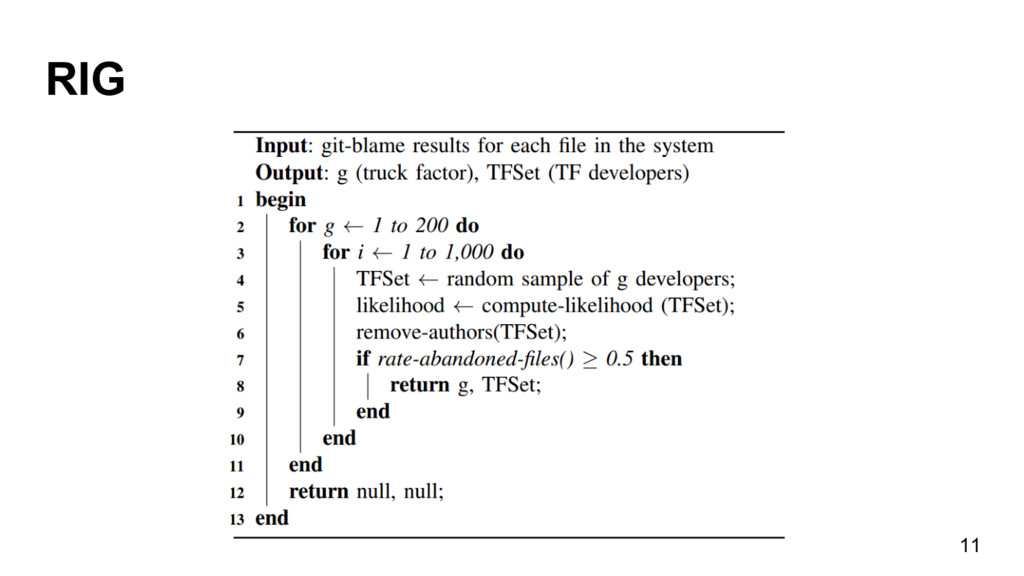{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
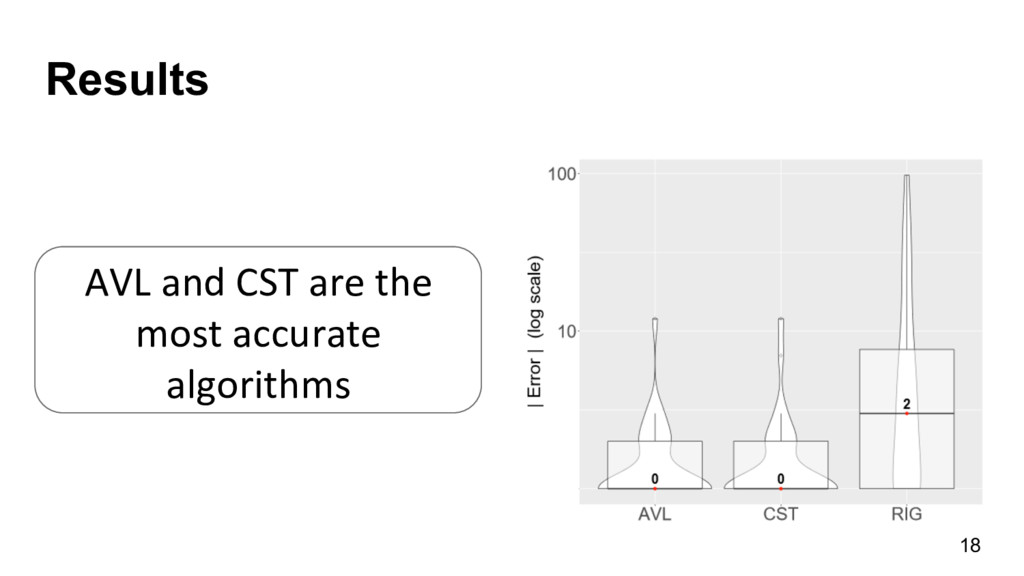{kind=link}
{kind=link}
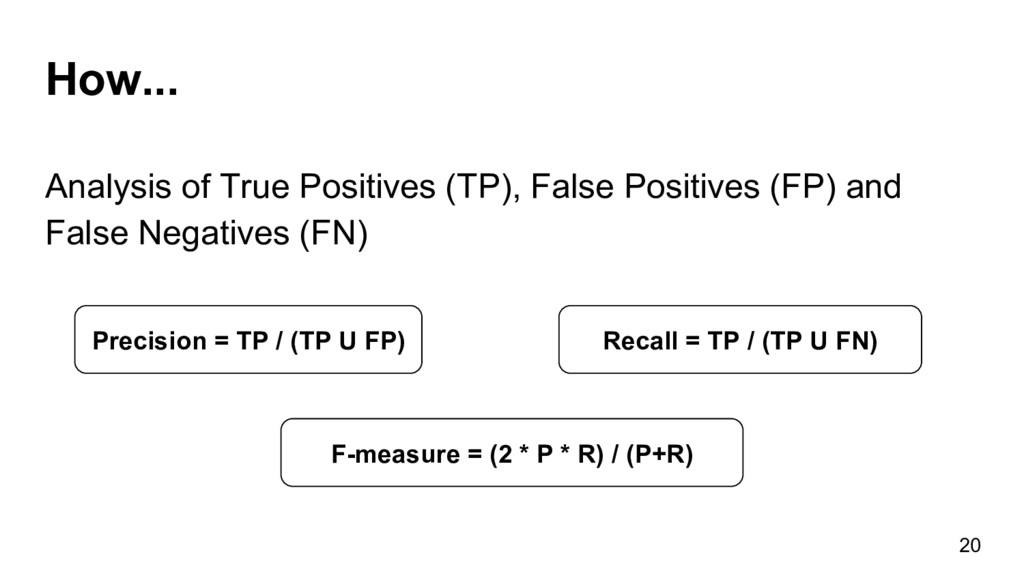{kind=link}
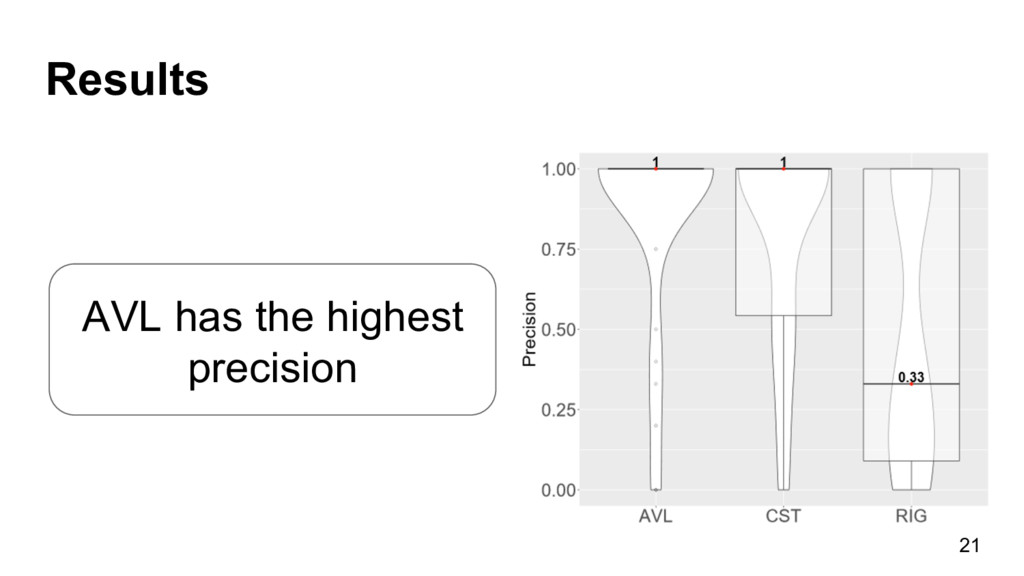{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}