practices have evolved • Infrastructure and deployment practices have gotten better Over the last few years... Monitoring solutions and the culture around it? Software systems have become more complex
to understand and pinpoint where errors originate • Logs and metrics are humongous in volume and making sense is tough • Increased MTTD (Mean Time To Detect) and MTTR (Mean Time to Resolve)
transactions * number of microservices * days of retention period * cost of (network + storage) Metrics Cost Number of metrics * days of retention period * cost of (network + storage) ( number of metrics to monitor increases with number of microservices too)
determine the behavior of the system based on its outputs. “Observability is about being able to ask arbitrary questions about your environment without---and this is the key part---having to know ahead of time what you wanted to ask” - Charity Majors, CoFounder @ HoneyComb What is Observability
incident, so I should make an alarm for that.' And you had another incident, and you should make a tool for that. At each step you’re making a rational choice, but you don’t realize that the cumulative effect is something that’s hard to maintain, and kind of unbearable.” - Greg Poirier (in his famous talk “Monitoring is dead”)
(APM) • Infra metrics and dashboards • Custom data pipelines and analytics dashboards Limitations • Inability to do high cardinality queries across services • Missing distributed tracing • Root cause analysis starts with assumptions • No first pane of analysis to go to • No scope for unknown-unknowns Our march towards better Observability
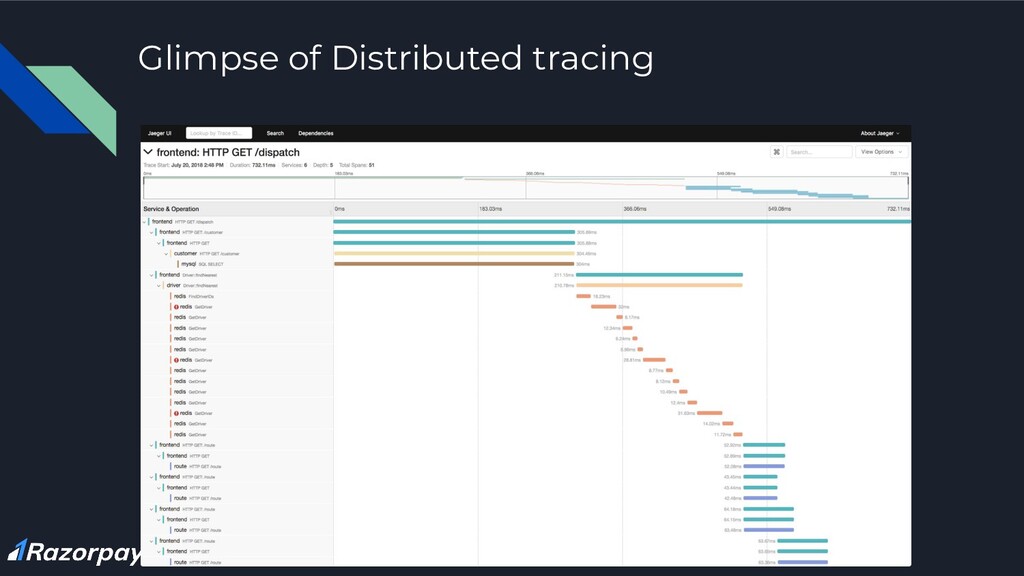
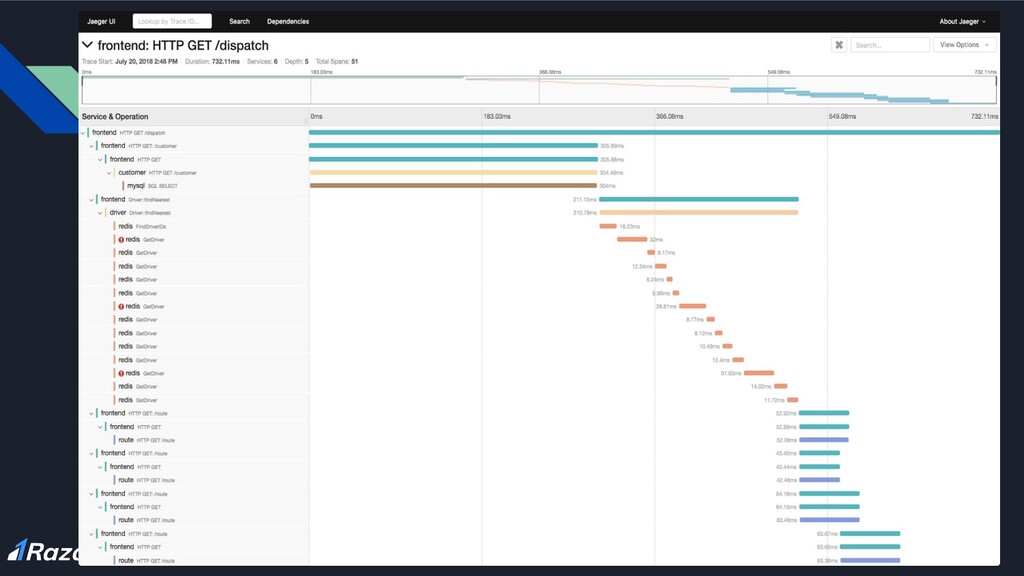
or more services • Span: work done by a single-service with time intervals • Tags: metadata to help contextualize a span While traces and spans do the stitching of the requests, tags enable context
through all others • Make the traces rich with context in tags ◦ add business values ◦ add technical details • Enrich traces with tags and do sampling for sanity of costs • Wrap every network call • Wrap every data fetch call Best practices: Instrumenting traces Embrace a culture where instrumentation is part of building software
the customers. Health of each individual request is of supreme consequence. RED Method • Request Rate (the number of requests per second) • Error Rate (the number of those requests that are failing) • Duration (the amount of time those requests take)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}