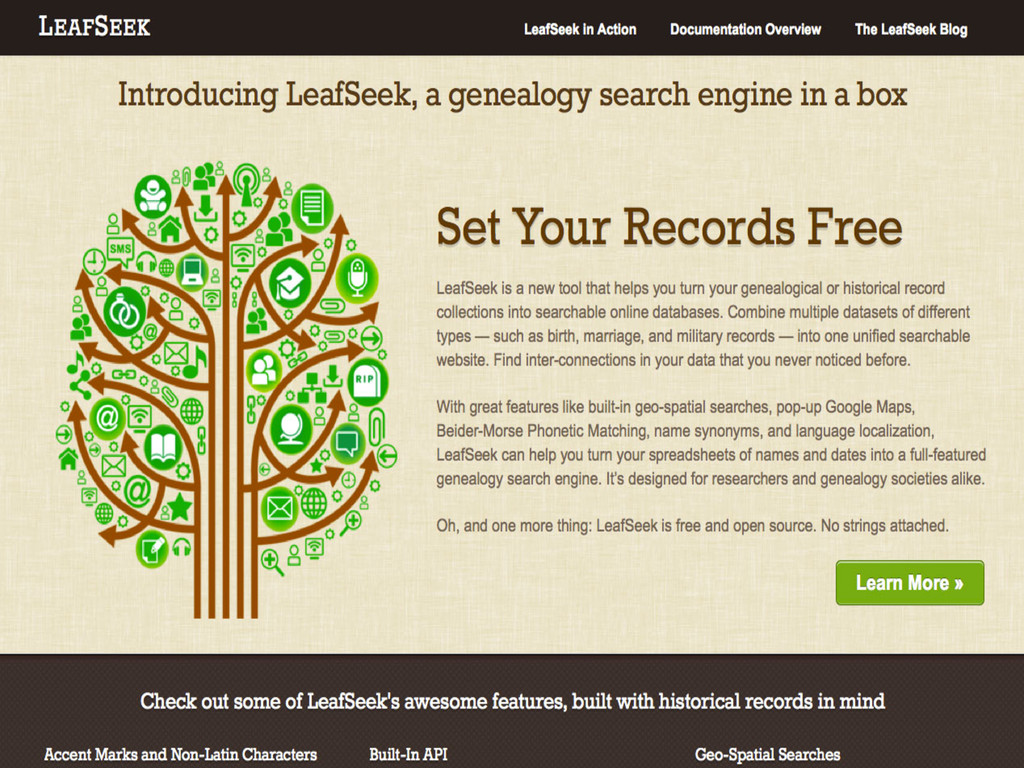
Set Your Records Free!
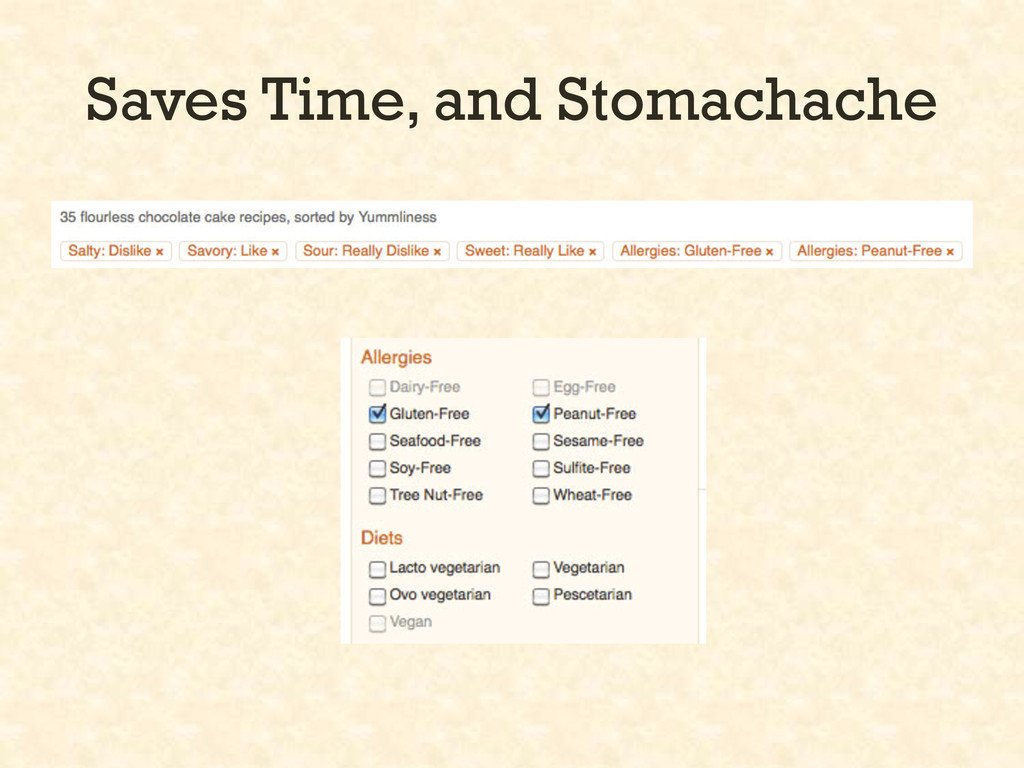
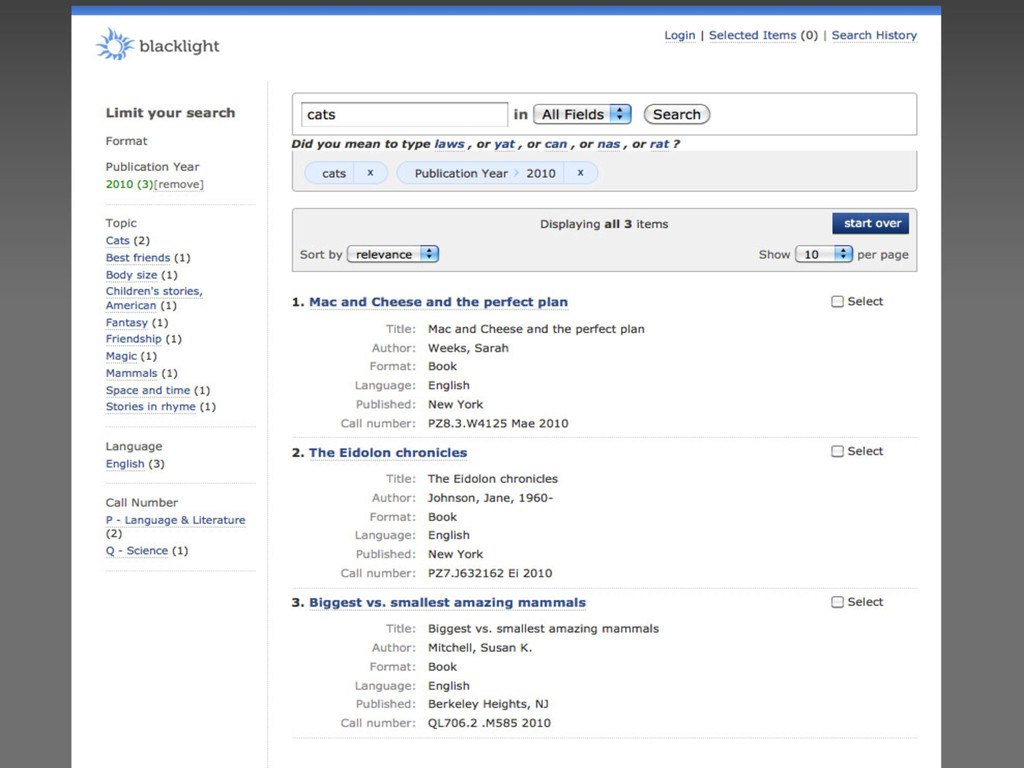
LeafSeek is a new tool that helps you turn your genealogical or historical record collections into searchable online databases. Combine multiple datasets of different types — such as birth, marriage, and military records — into one unified searchable website. Find inter-connections in your data that you never noticed before.
With great features like built-in geo-spatial searches, pop-up Google Maps, Beider-Morse Phonetic Matching, name synonyms, and language localization, LeafSeek can help you turn your spreadsheets of names and dates into a full-featured genealogy search engine. It’s designed for researchers and genealogy societies alike.
Oh, and one more thing: LeafSeek is free and open source. No strings attached.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}