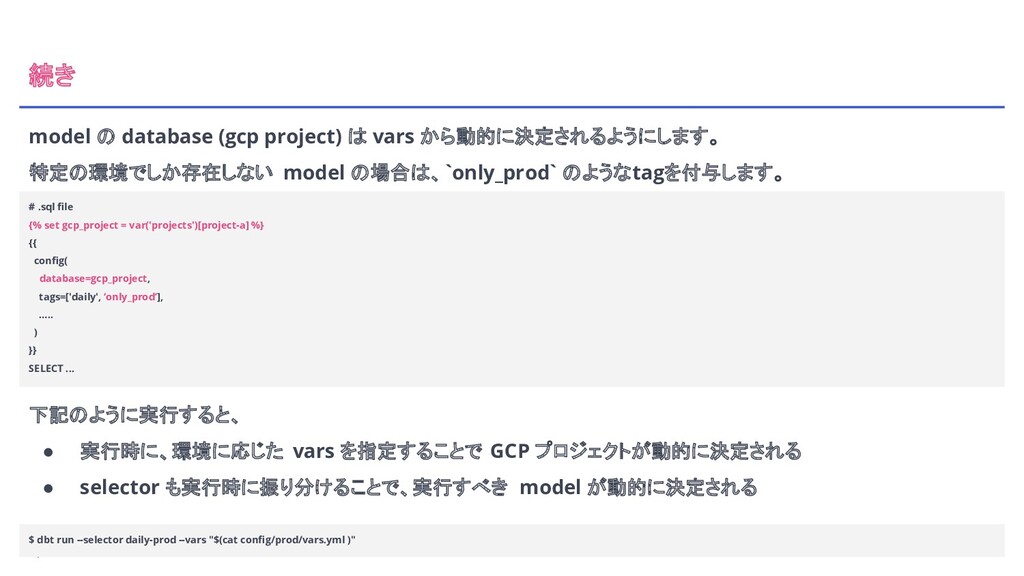
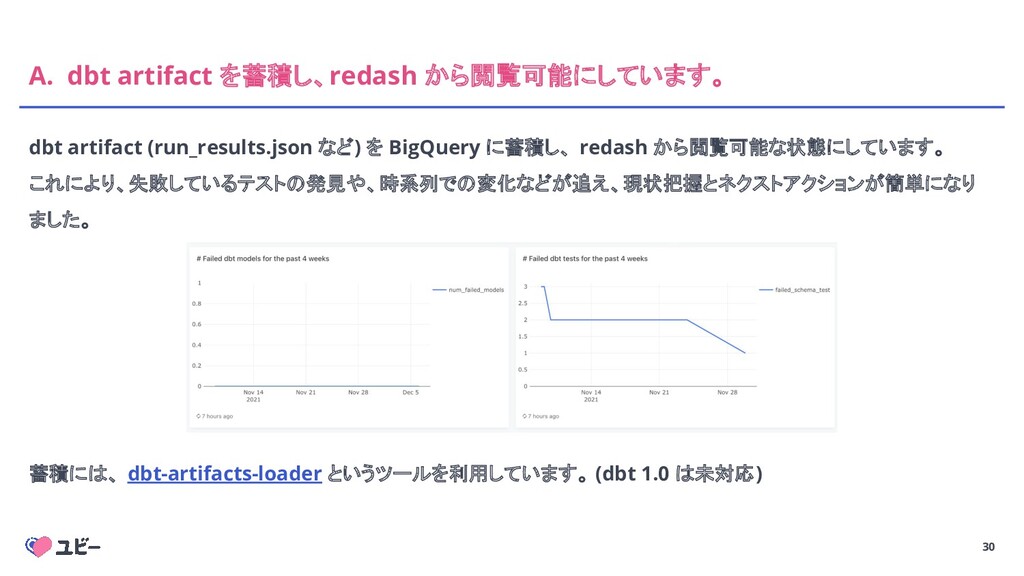
selector も実行時に振り分けることで、実行すべき model が動的に決定される $ dbt run --selector daily-prod --vars "$(cat config/prod/vars.yml )" model の database (gcp project) は vars から動的に決定されるようにします。 特定の環境でしか存在しない model の場合は、`only_prod` のようなtagを付与します。 # .sql file {% set gcp_project = var('projects')[project-a] %} {{ config( database=gcp_project, tags=['daily', ‘only_prod’], ….. ) }} SELECT ...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}