Working in operations in 2014 is hard.*
More applications are running in the cloud, the infrastructures we manage are getting bigger and bigger, and responsibility for that is being divided up across multiple teams.
Then something breaks. All hell breaks loose. Your on-call engineer receives 900 SMS in 30 seconds. Her phone melts. You can’t distinguish the signal from the noise. It takes an hour to fix the problem.
Weren’t computers meant to solve these problems?
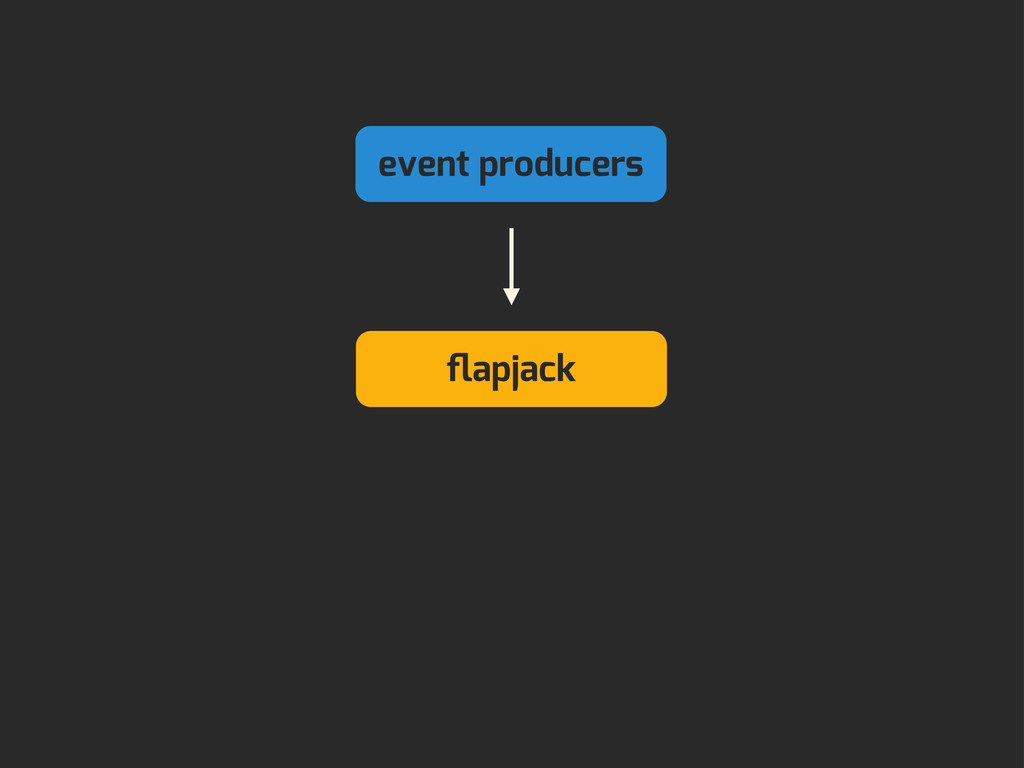
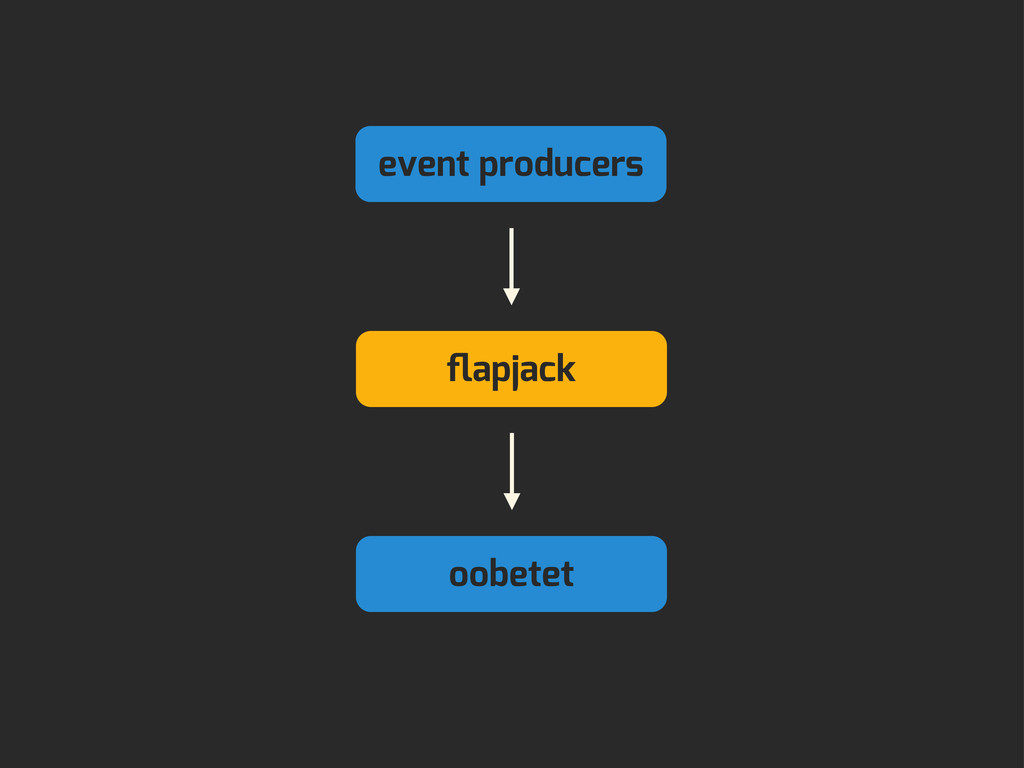
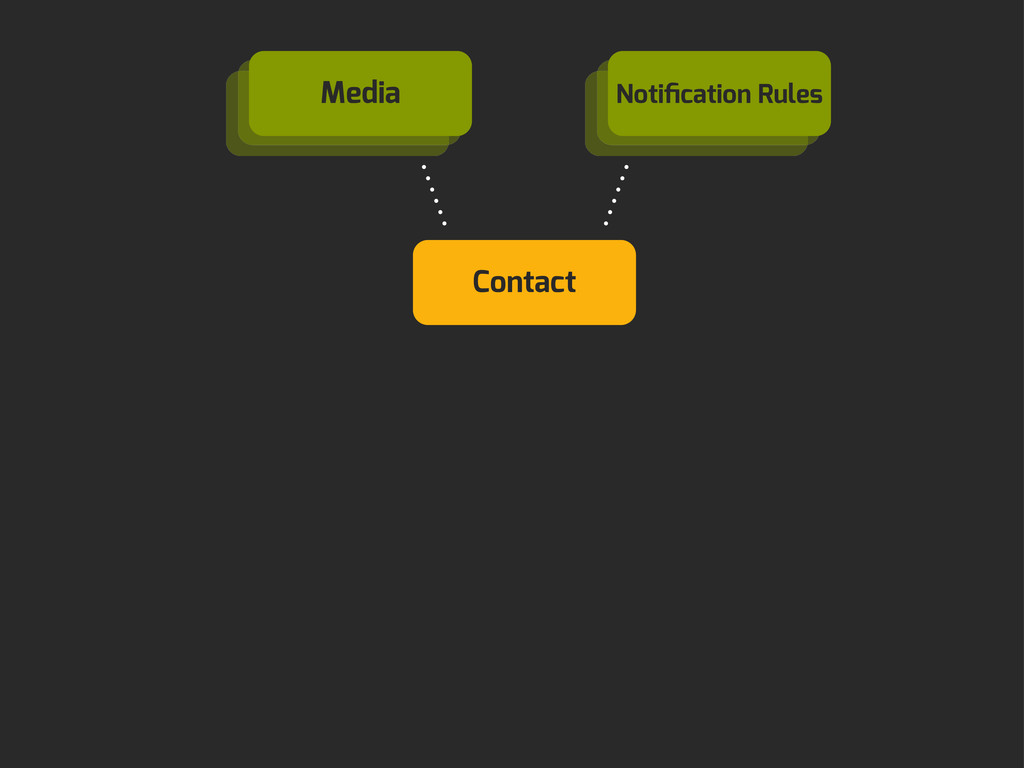
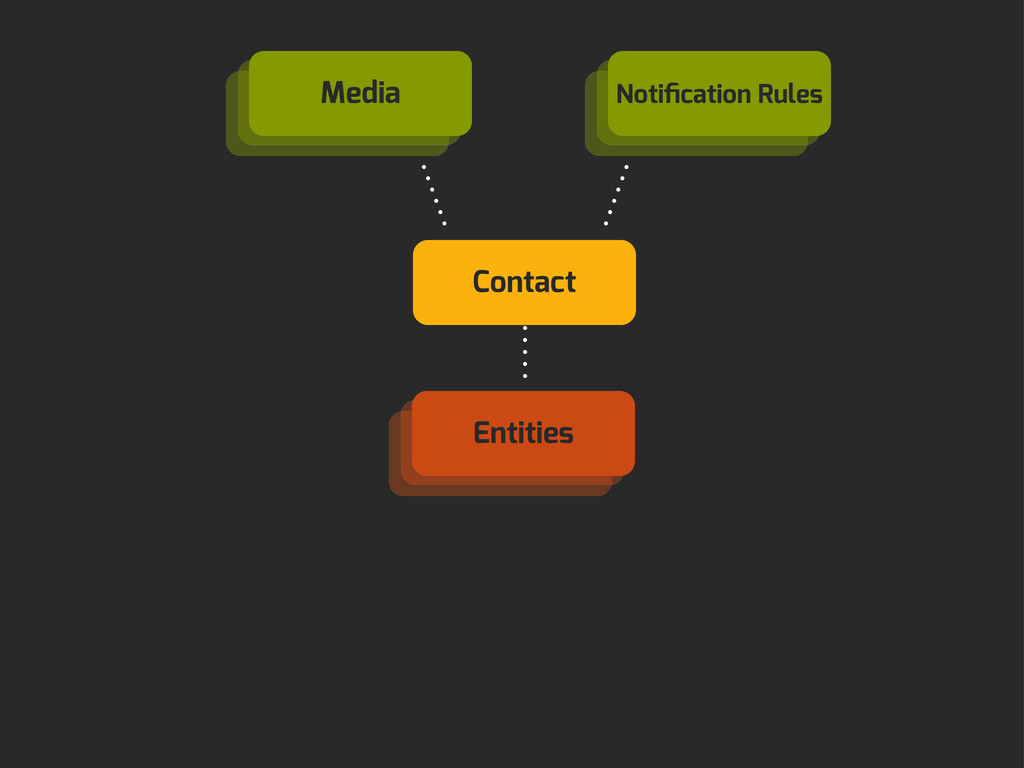
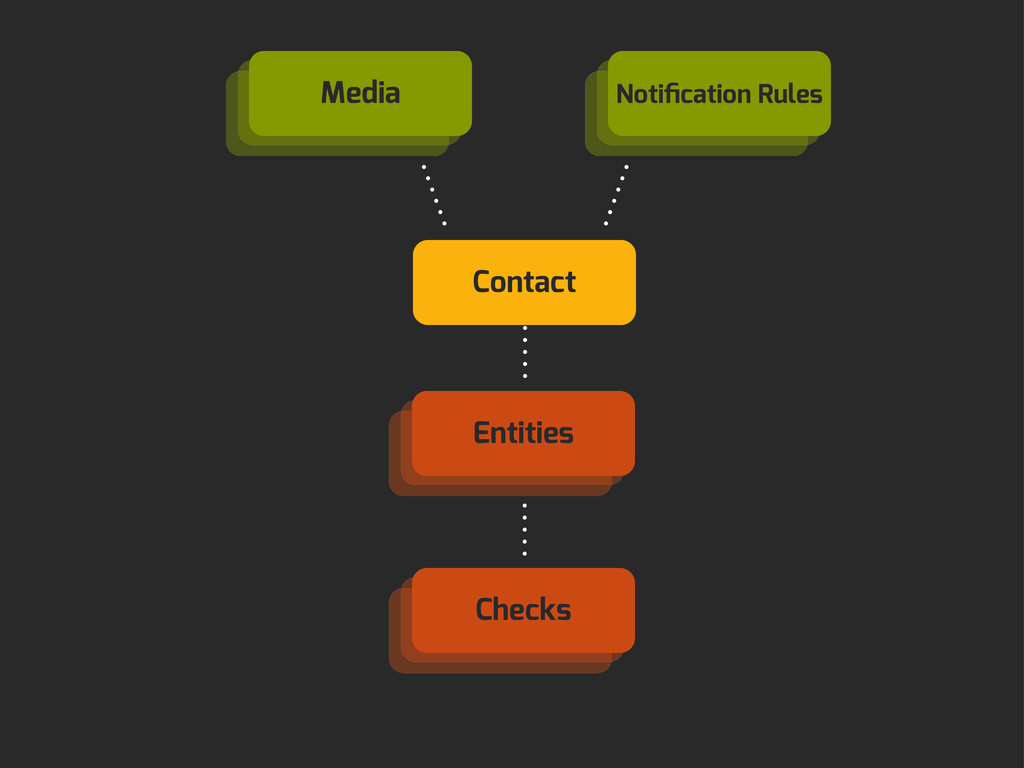
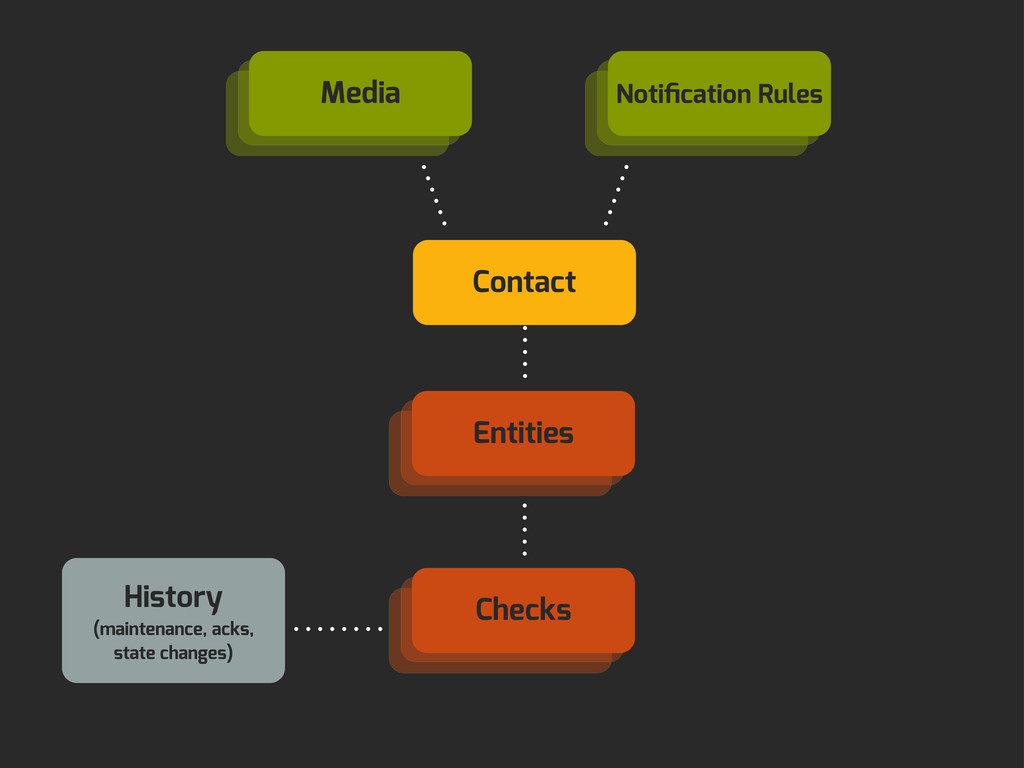
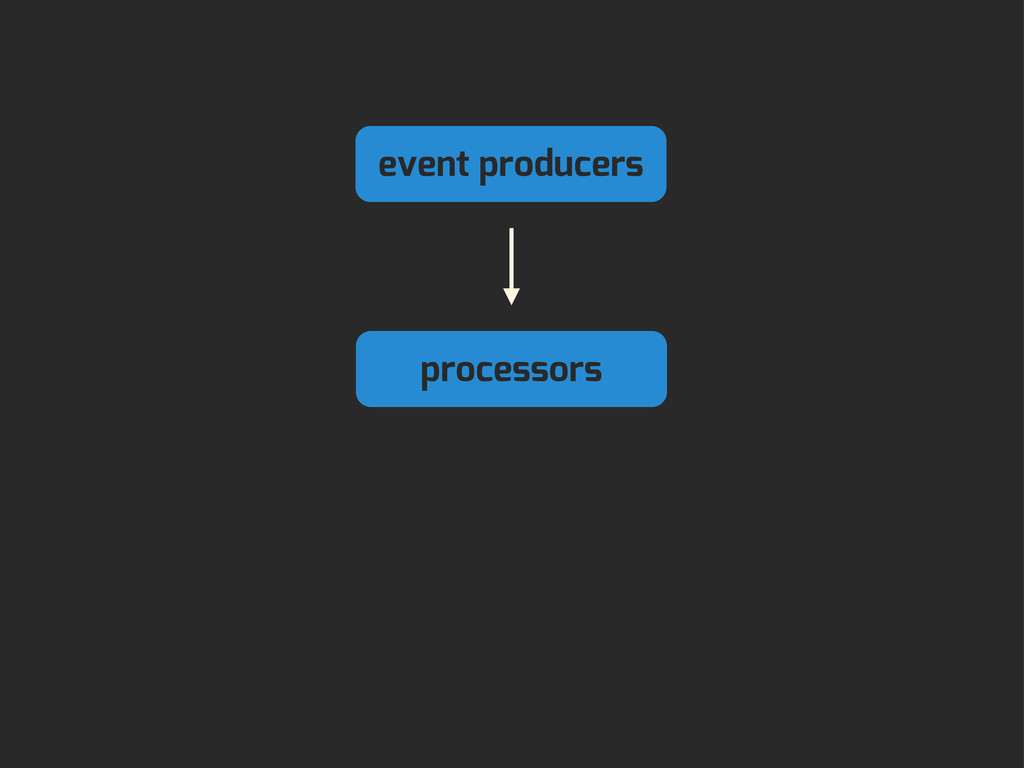
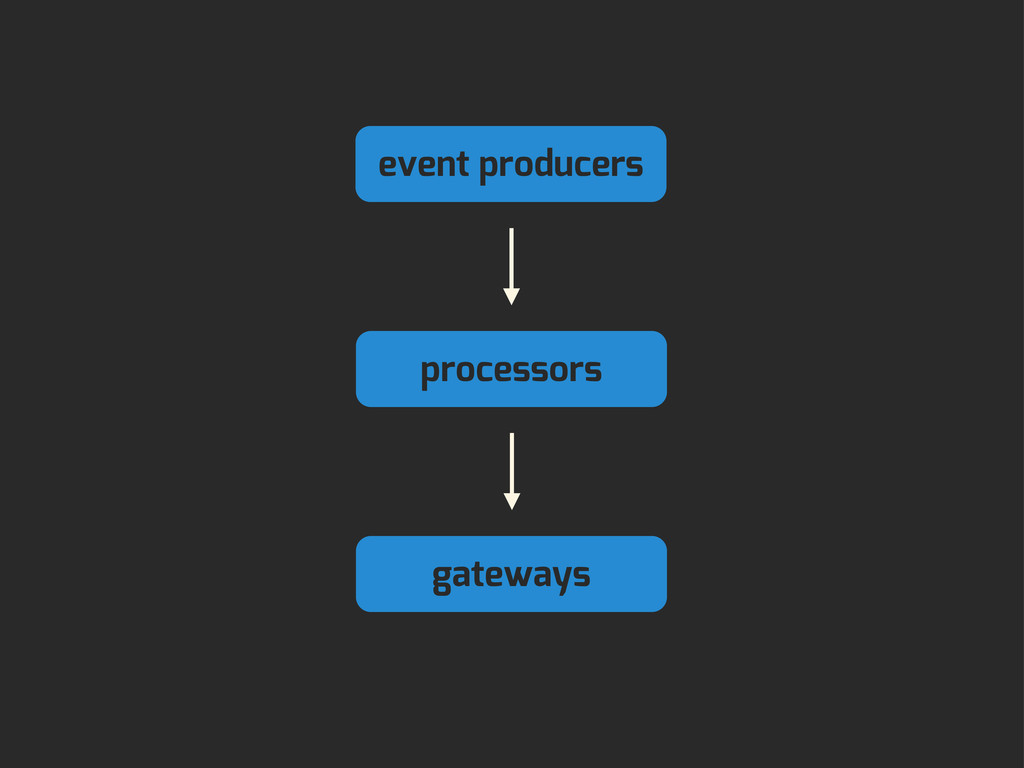
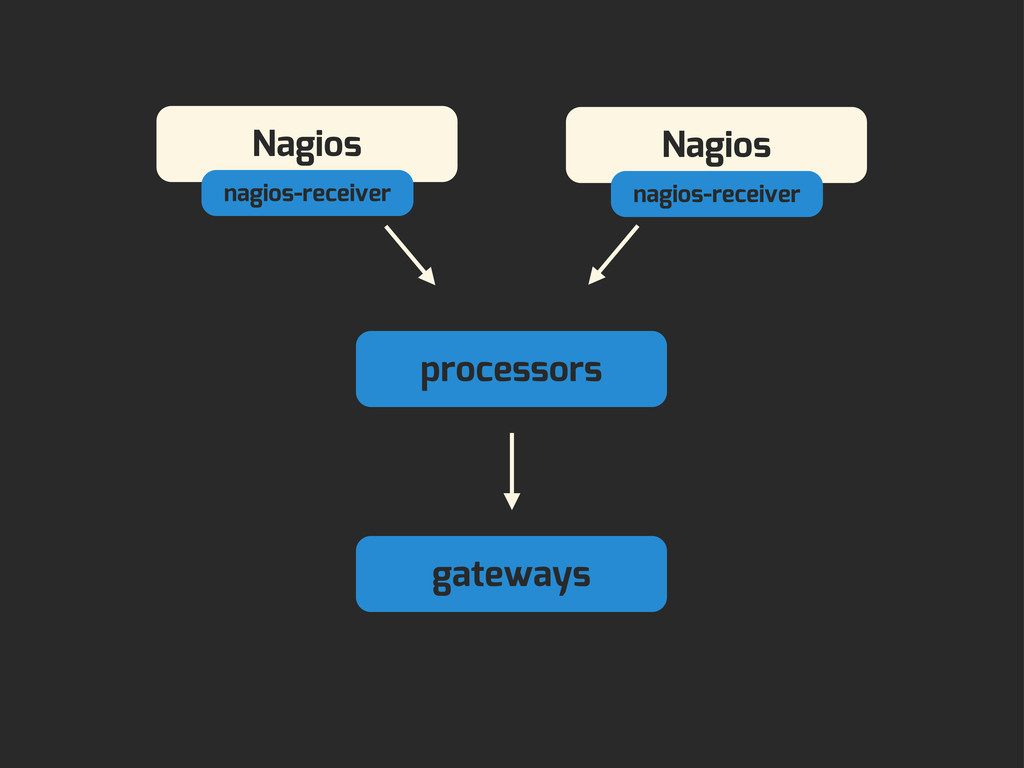
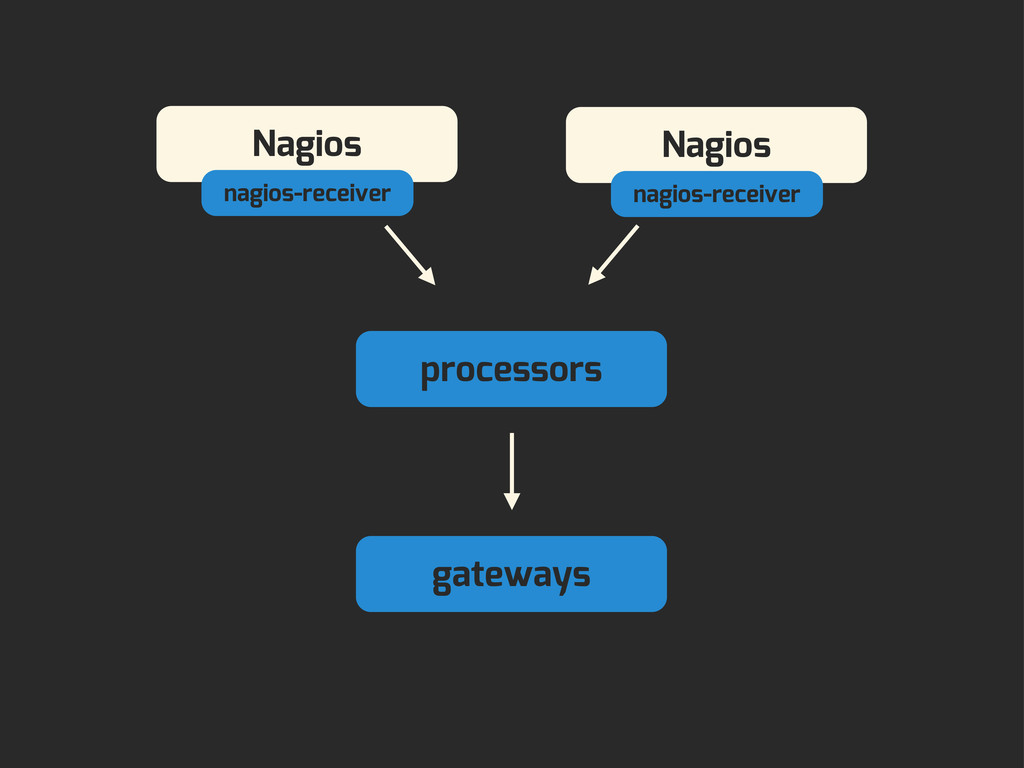
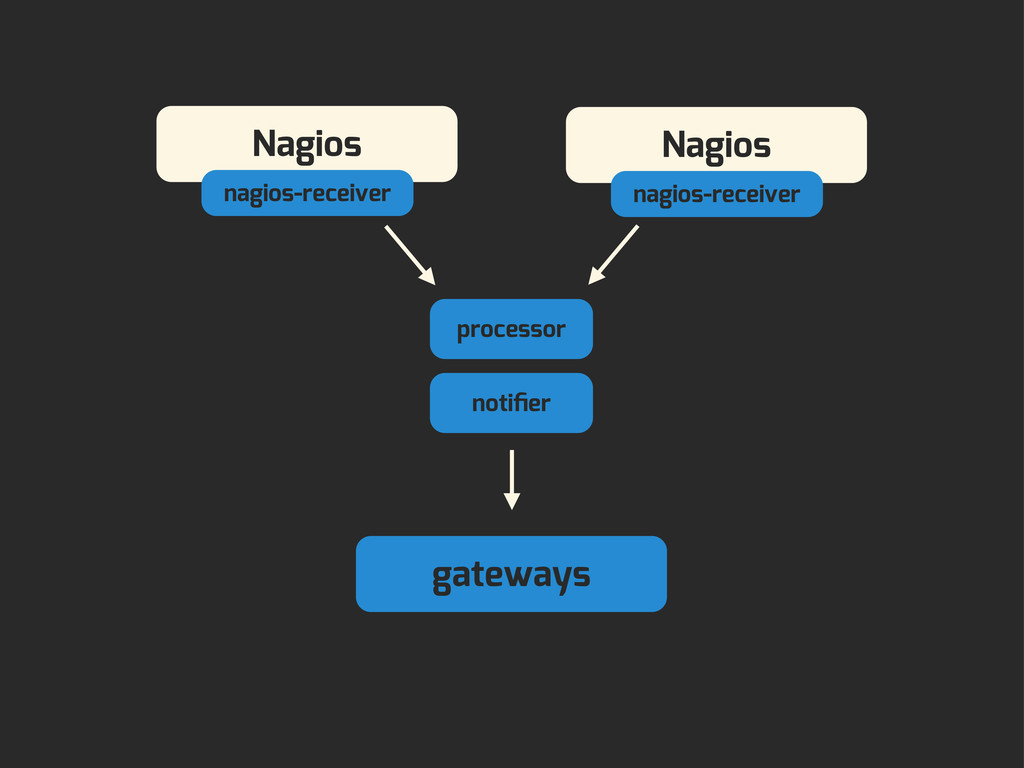
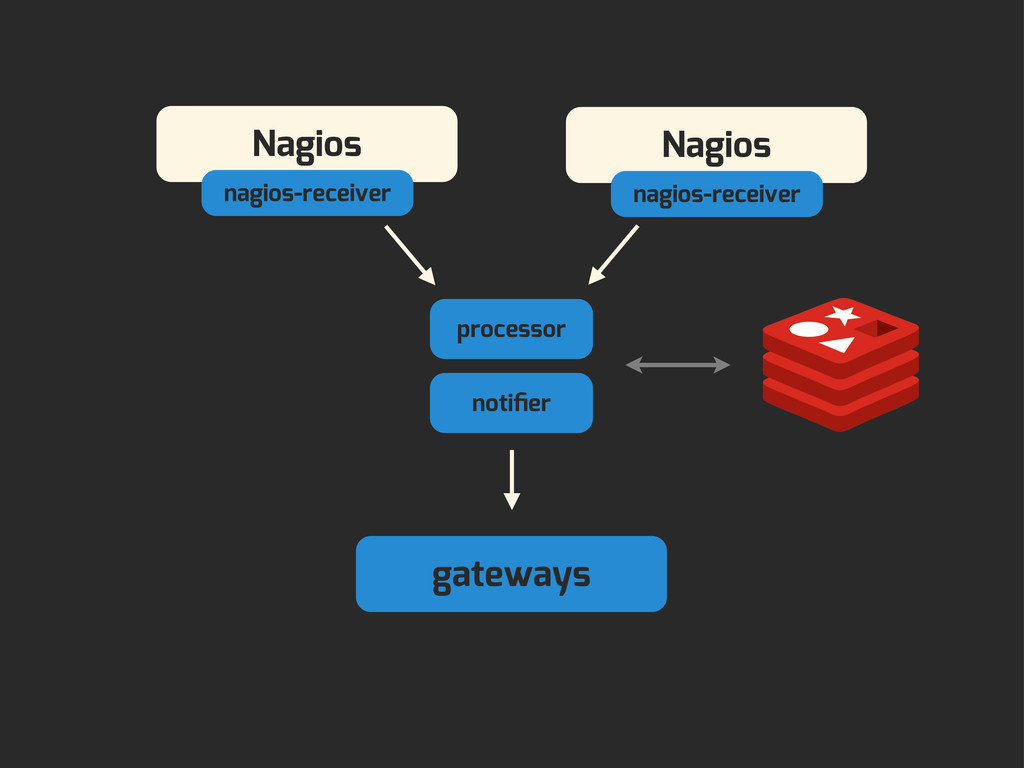
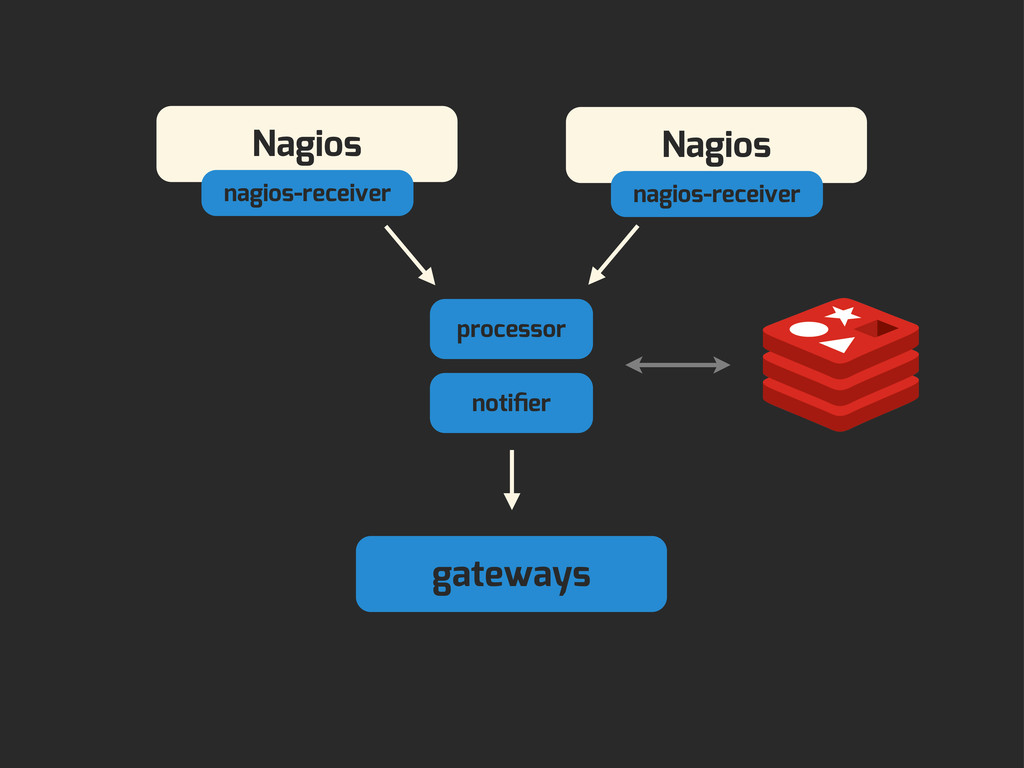
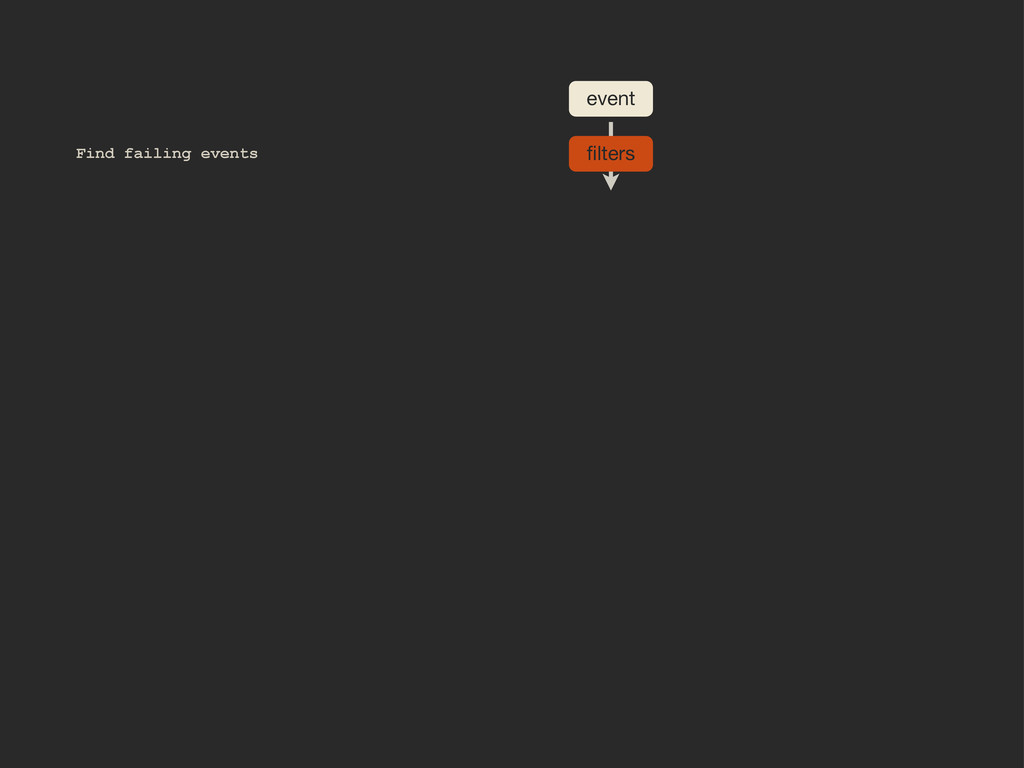
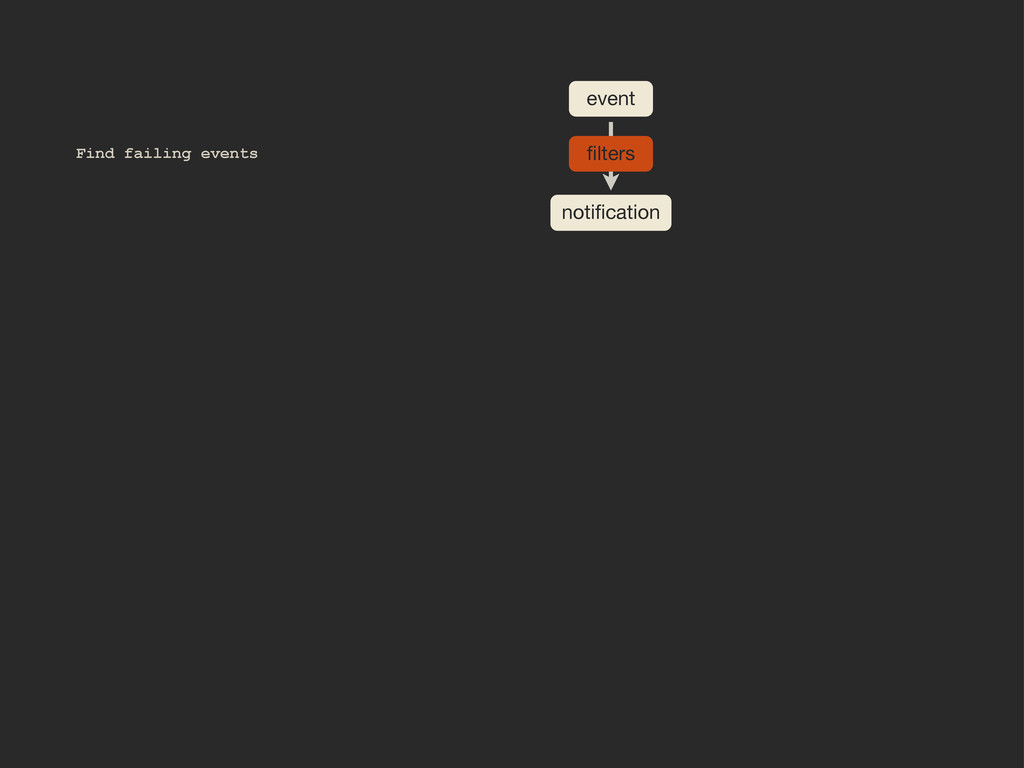
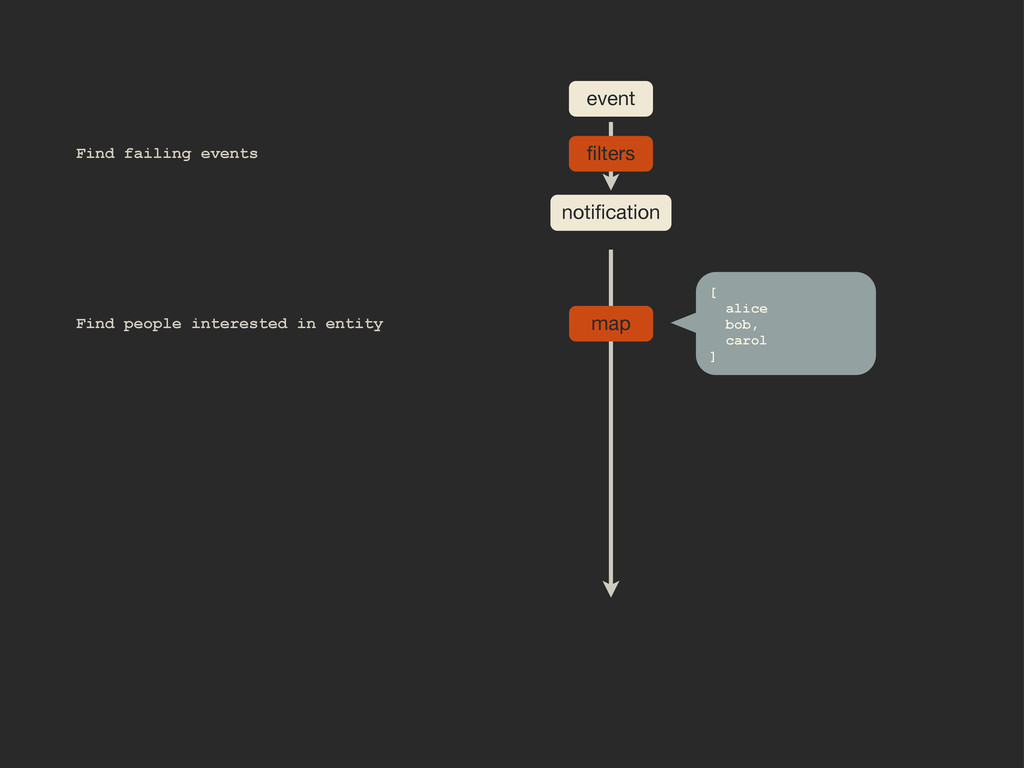
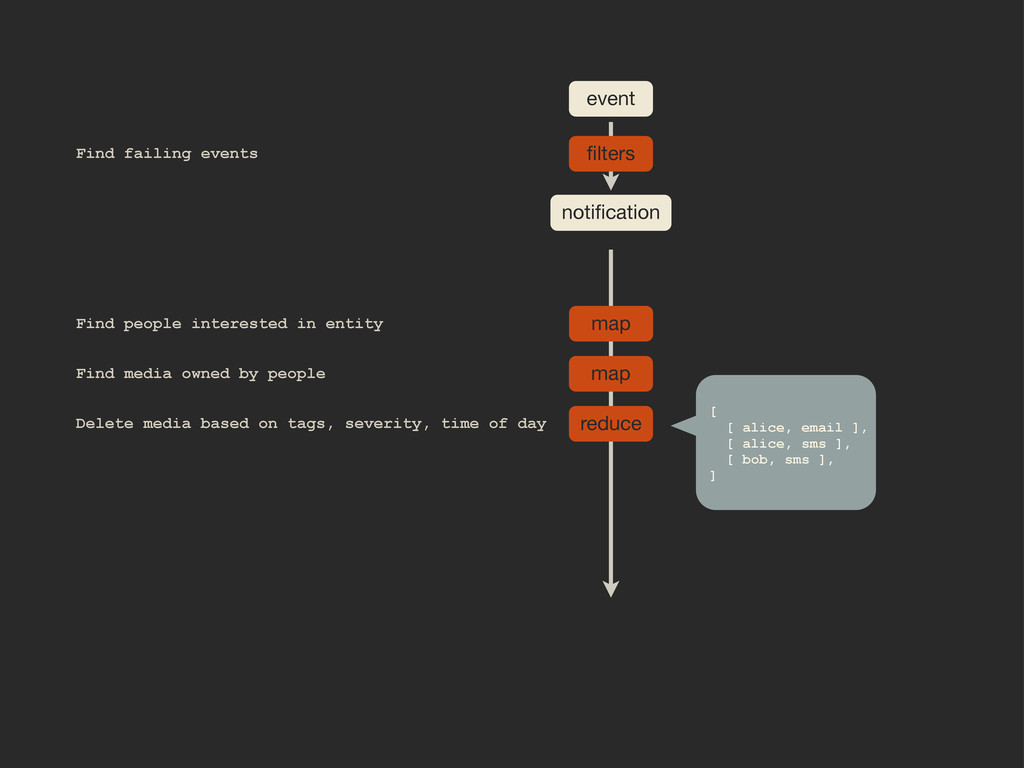
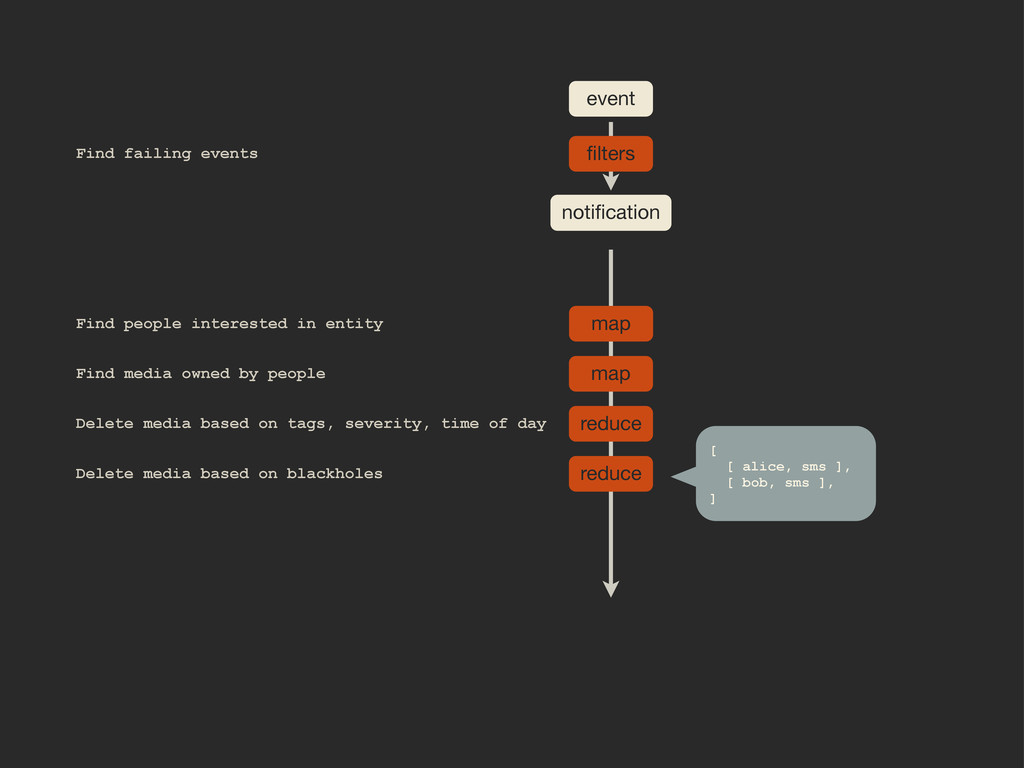
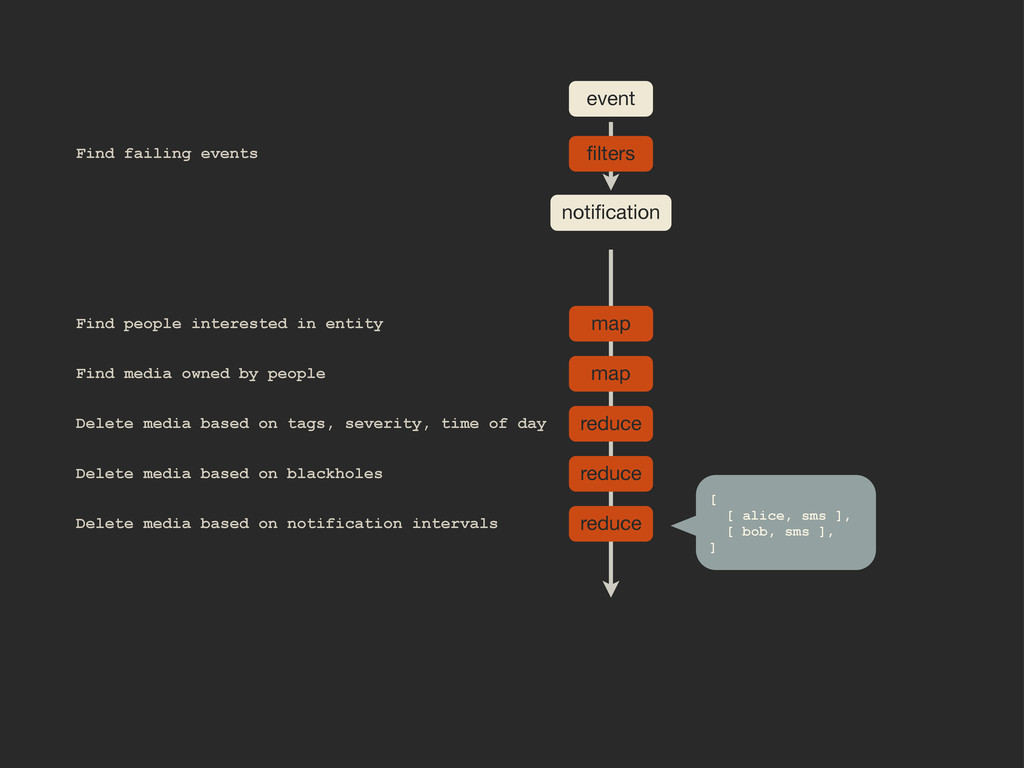
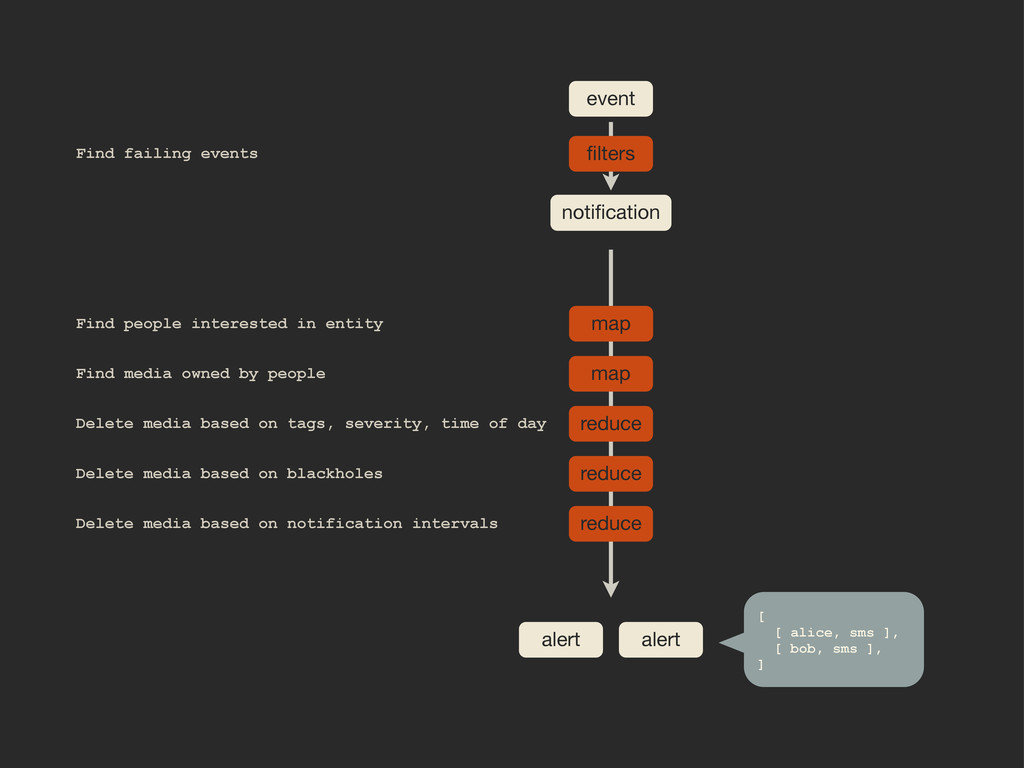
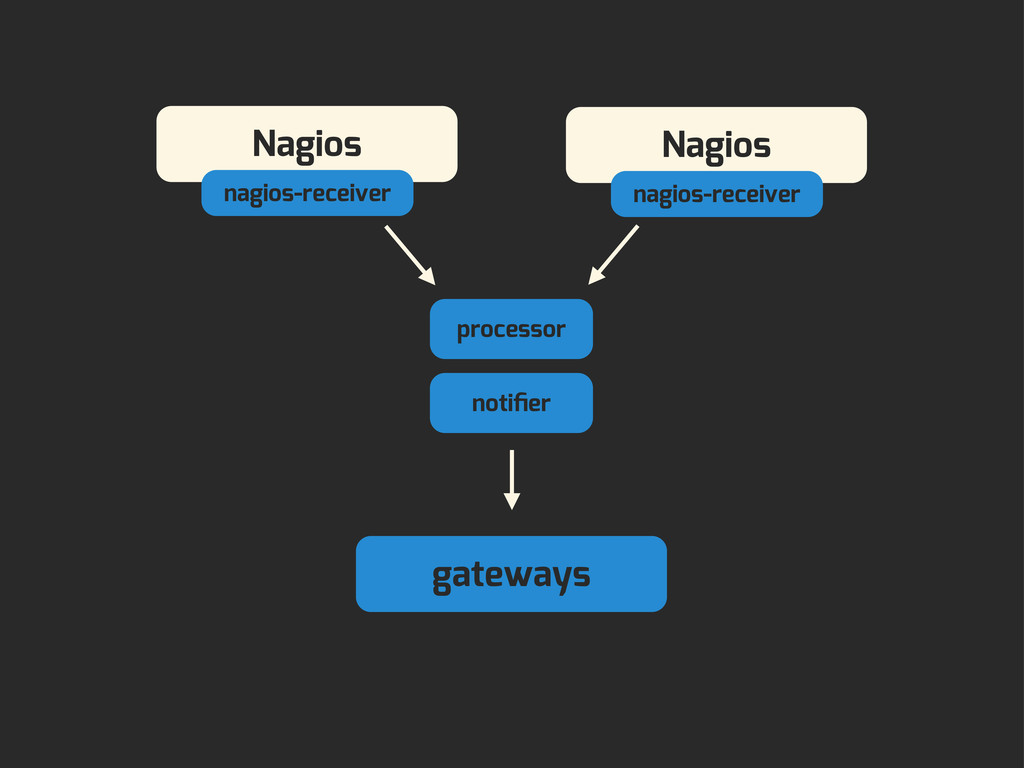
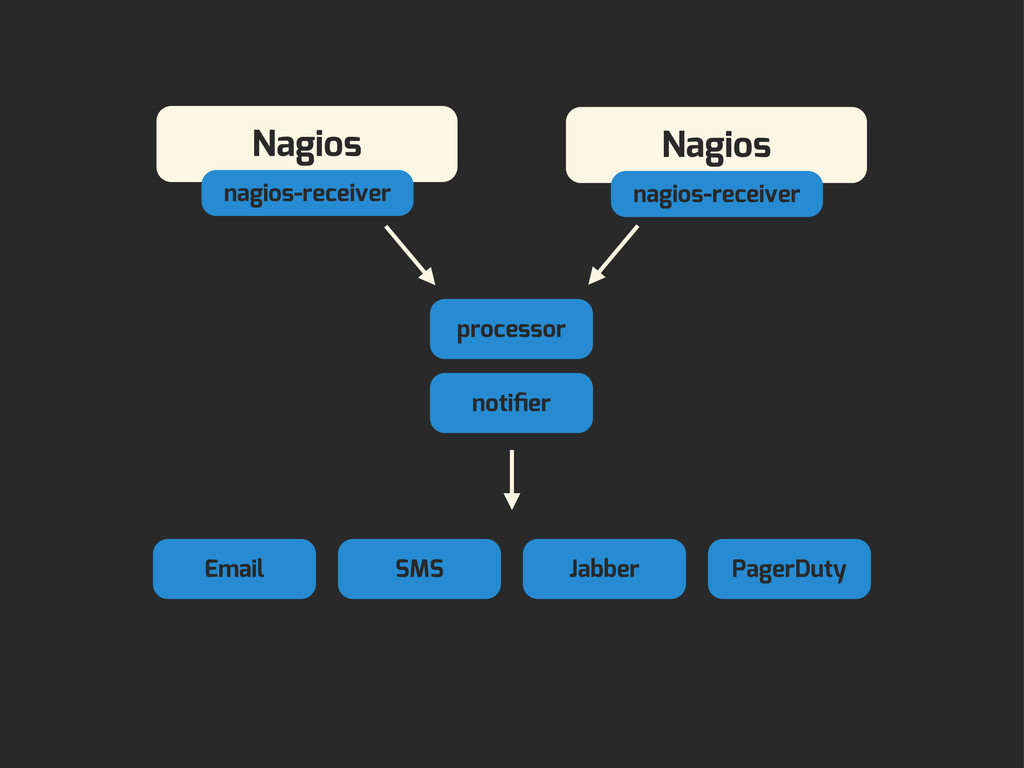
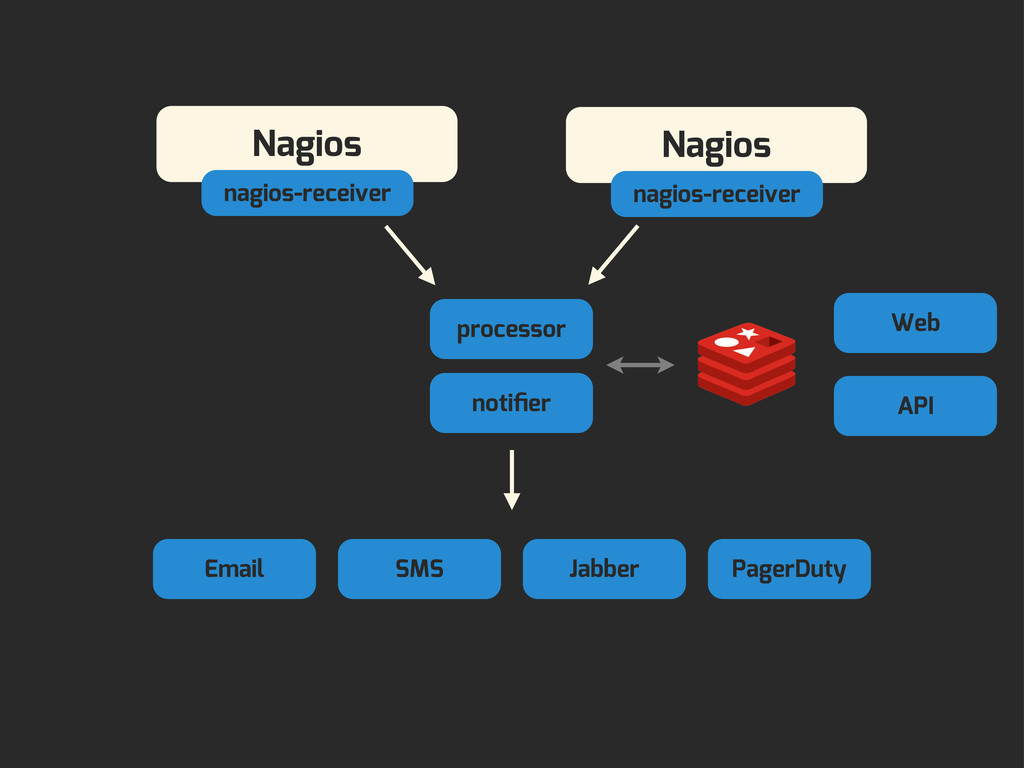
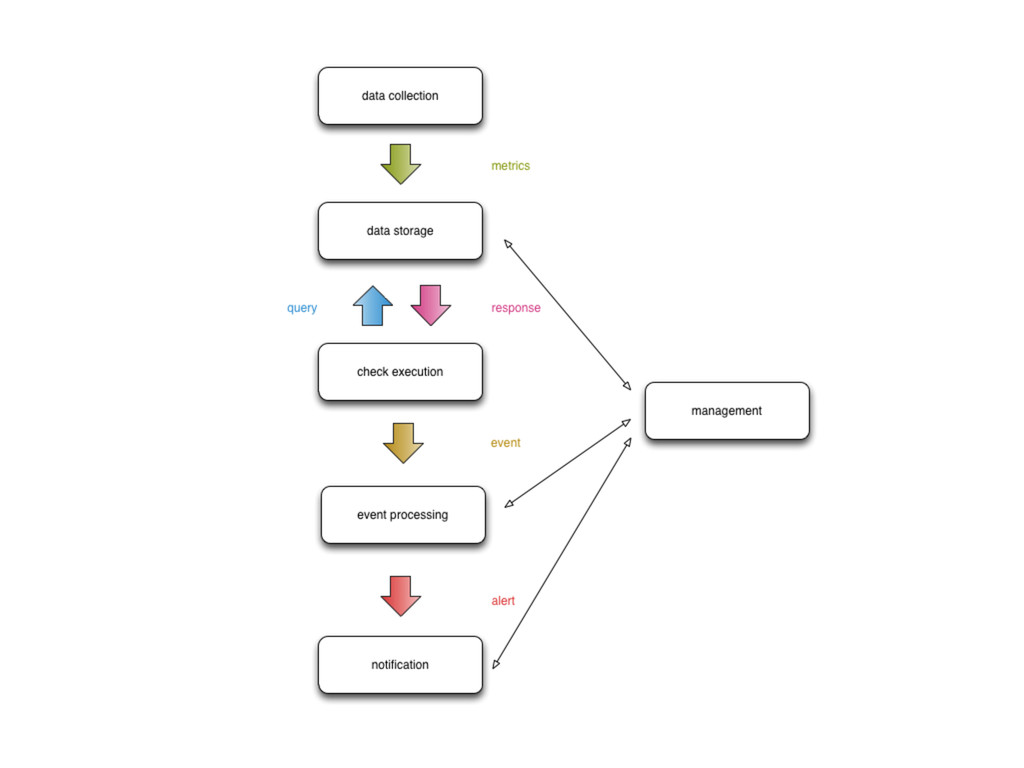
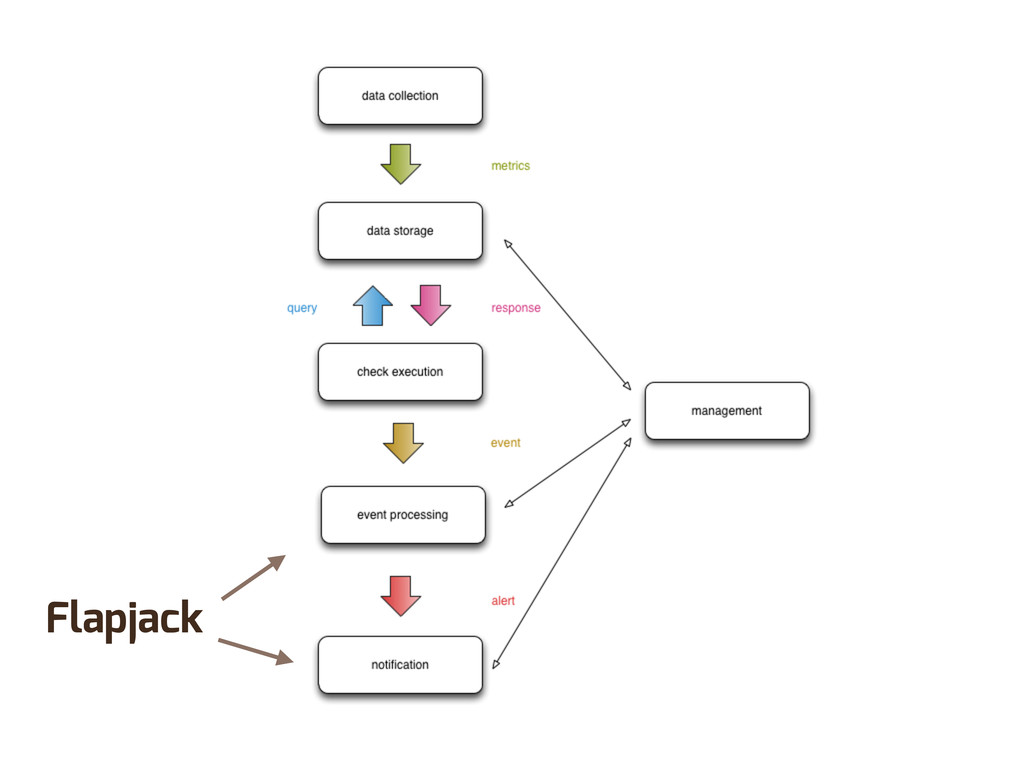
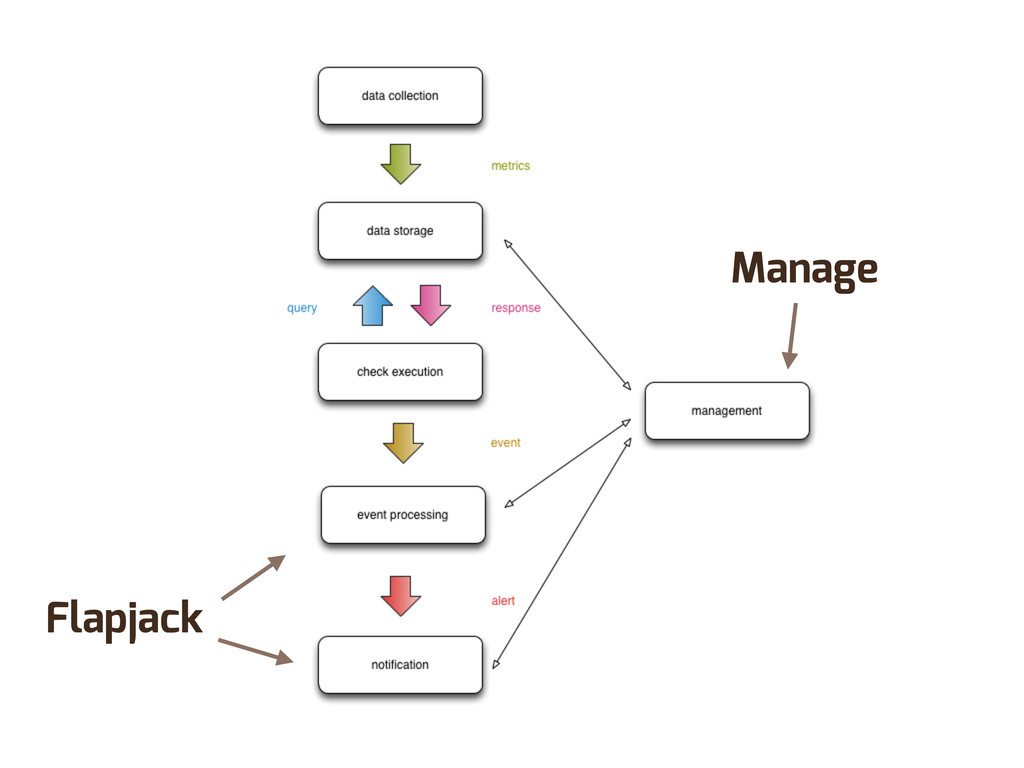
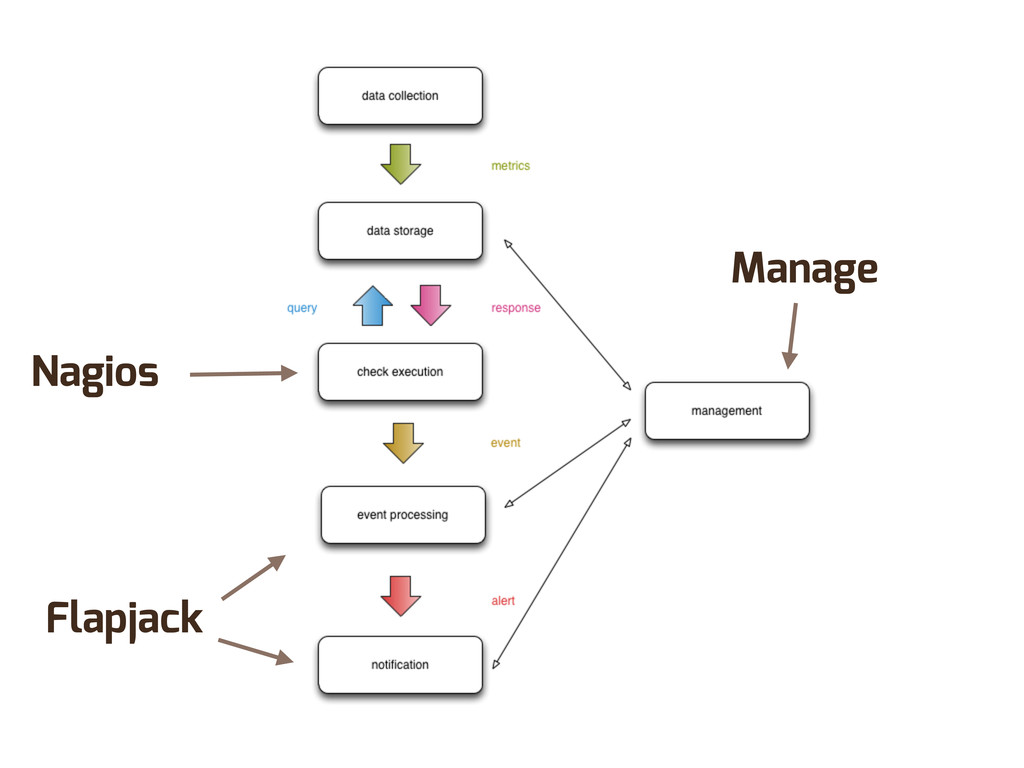
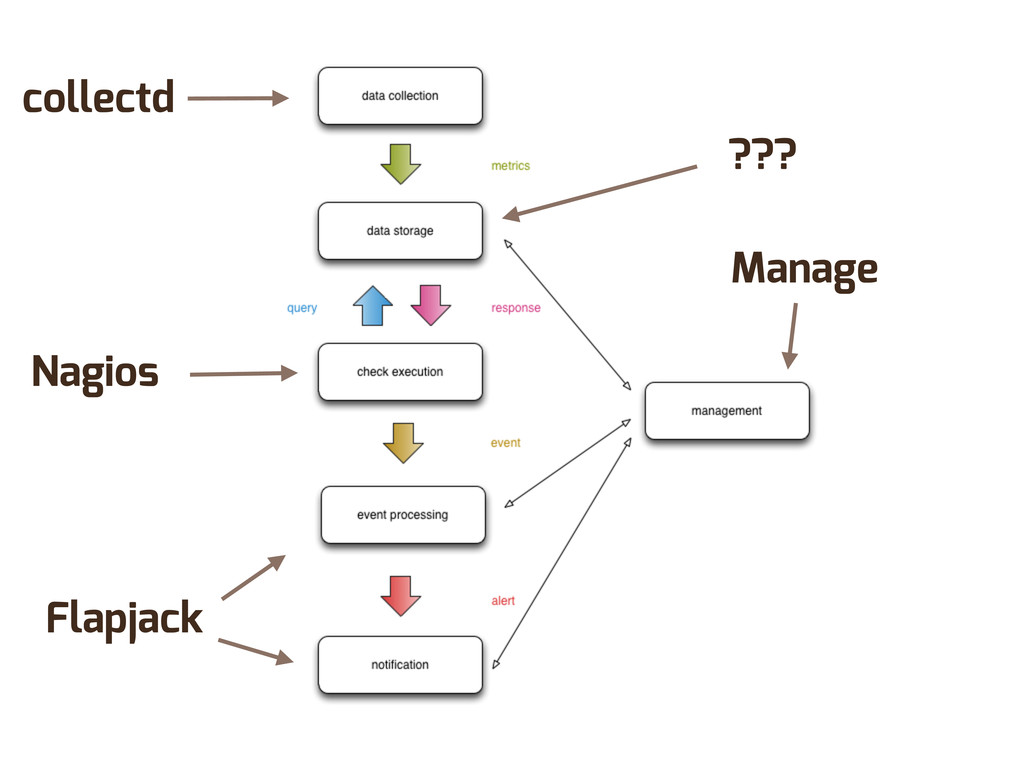
Enter Flapjack: a distributed event processing + monitoring alert routing system. Flapjack sits at the end of your monitoring pipeline and works out who it should send alerts to. Sounds pretty simple? Flapjack tries to make it so.
There are still really hard problems to solve when working out who to notify about a detected failure, and what to do when lots of things fail simultaneously.
You should be interested in Flapjack if:
- You want to track down failures faster by rolling up your alerts across multiple monitoring systems.
- You monitor large infrastructures that have multiple teams responsible for keeping them up.
- You want to dip your toe in the water and try alternative check execution engines like Sensu in parallel to Nagios.
In this talk, Jesse Reynolds and Lindsay Holmwood will take you on a whirlwind tour of Flapjack - what it is, how it solves problems, where it’s going - with a hands on lab that you can start applying in your organisation tomorrow.
*Disclaimer: this abstract was written in 2013. Things may have since gotten awesome and we’re all sitting on the beach in the Bahamas drinking piña coladas. But this is highly unlikely.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}