Available Key-Value Store • Data Model: • Global key-value mapping • Big scalable HashMap • Highly fault tolerant (typically) • Examples: • Redis, Riak, Voldemort
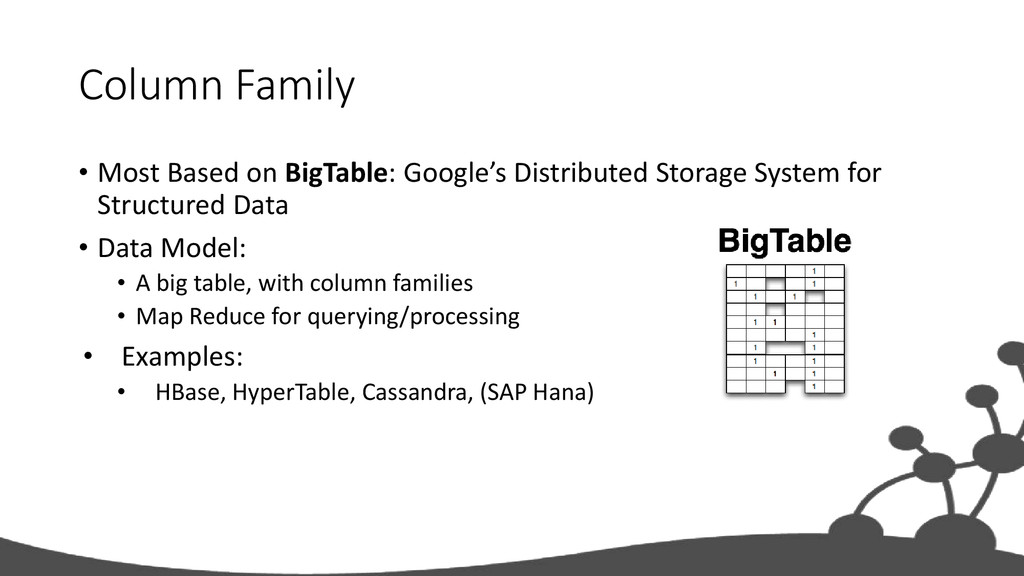
System for Structured Data • Data Model: • A big table, with column families • Map Reduce for querying/processing • Examples: • HBase, HyperTable, Cassandra, (SAP Hana)
model, as general as RDBMS • Connected data locally indexed • Easy to query • Cons • Sharding ( lots of people working on this) • Scales UP reasonably well • Requires rewiring your brain
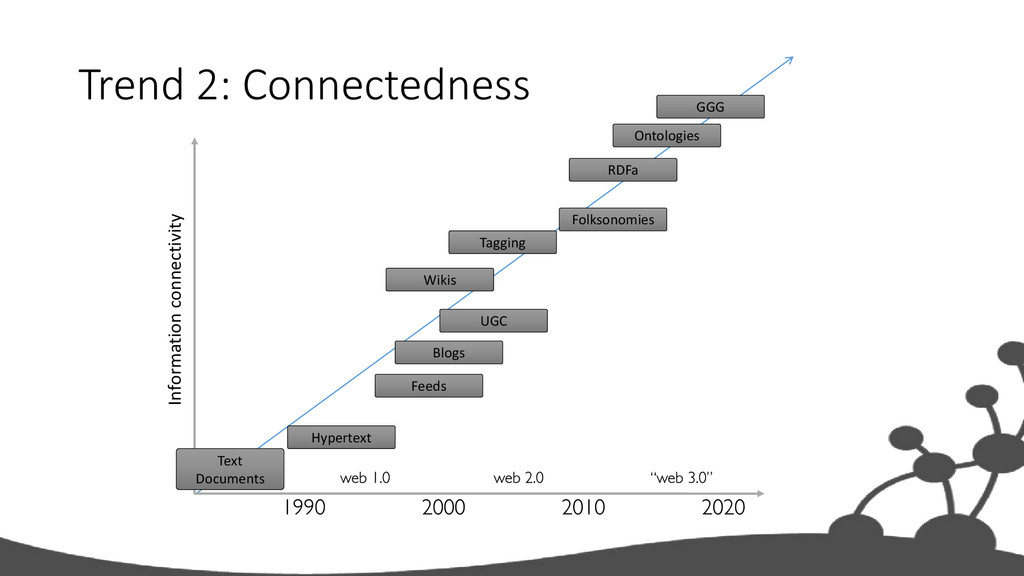
salary lists, all elements exactly one job • 2000’s salary lists, we need many job columns! • Store more data about each entity • Trend accelerated by the decentralization of content generation • Age of participation (“web 2.0”)
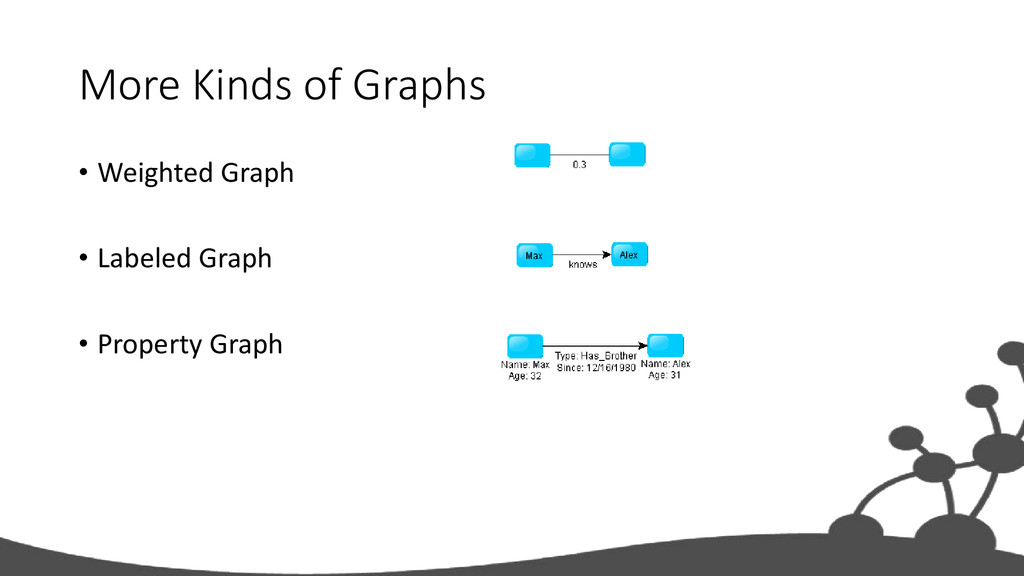
explicit graph structure • Each node knows its adjacent nodes • As the number of nodes increases, the cost of a local step (or hop) remains the same • Plus an Index for lookups
online database management system with CRUD methods that expose a graph data model”1 • T wo important properties: • Native graph storage engine: written from the ground up to manage graph data • Native graph processing, including index-free adjacency to facilitate traversals 1] Robinson,Webber , Eifrem. Graph Databases. O’Reilly, 2013. p. 5. ISBN-10: 1449356265
Make it easy to make sense of that data 3. Enable extreme-performance operations for: • Discovery of connected data patterns • Relatedness queries > depth 1 • Relatedness queries of arbitrary length 4. Make it easy to evolve the database
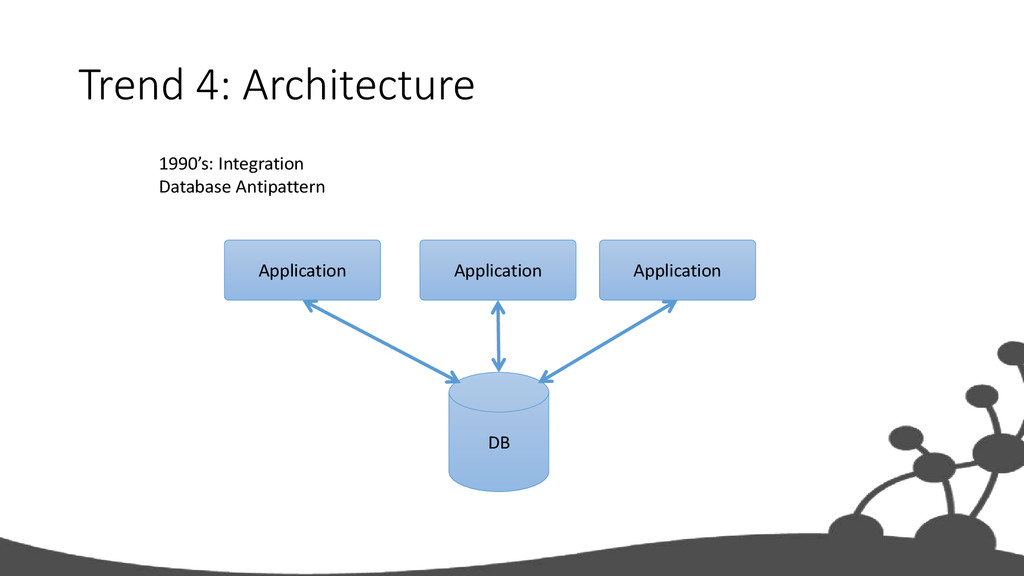
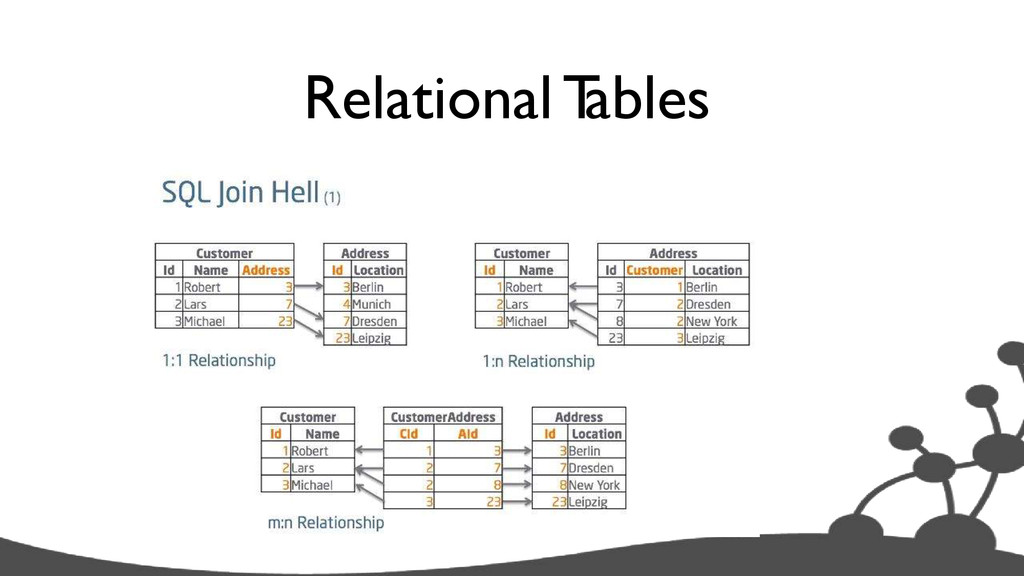
the relationship • executing a JOIN means to search for a key in another table • with Indices executing a JOIN means to lookup a key • B-T ree Index: O(log(n)) • more entries => more lookups => slower JOINs The Problem
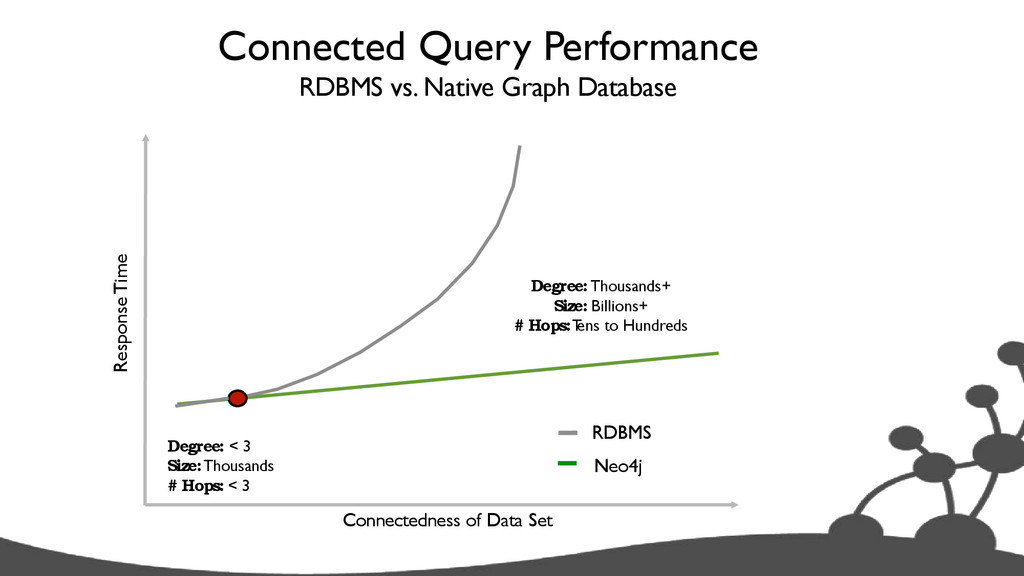
size, query degree) • Graph Density (avg # rel’s / node) • Graph Size (total # nodes in the graph) • Query Degree (# of hops in one’s query) RDBMS: >> exponential slowdown as each factor increases Neo4j: >> Performance remains constant as graph size increases >> Performance slowdown is linear or better as density & degree increase
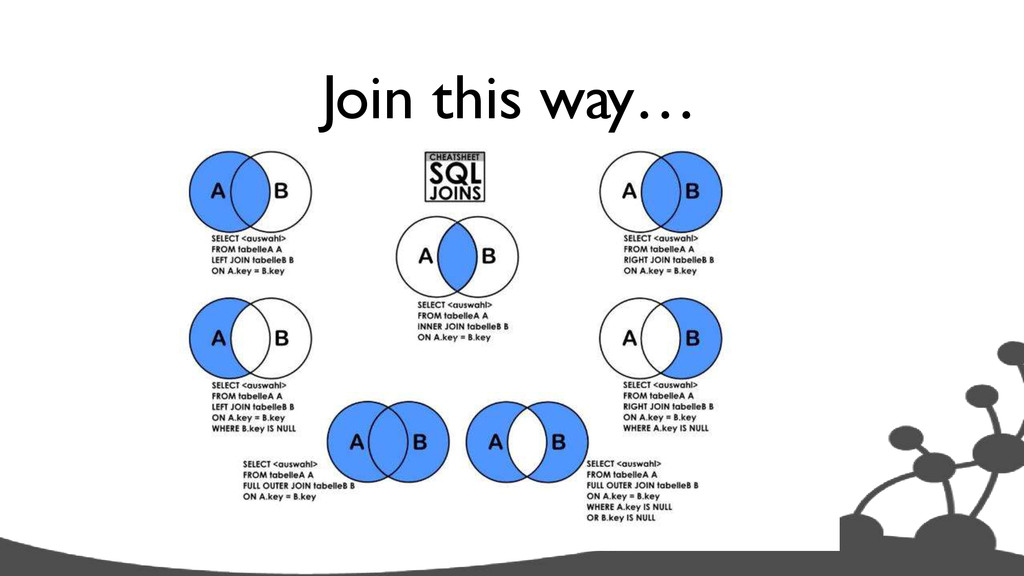
traverse from node 1 start a=(1) match (a)-->(b) return b // return friends of friends start a=(1) match (a)--()--(c) return c Pattern Matching Query Language (like SQL for graphs)
fours • How to pick • Why Aggregates suck with connected data • Slicing through data limited (needs lots of map&reduce) • Connected Query Performance • IP needs “hopping” through data anyway (k > 3)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}