sistema não fica no ar, ele se torna menos confiável - Se o sistema apresenta muitos erros, ele se torna menos confiável - Se o sistema não é confiável, seus usuário não vão contar com ele - Se os usuário não contarem com o sistema, eles tendem a não usar
500 funcionários - Por um problema técnico, o G Suite fica fora do ar por 3 horas - Ninguém consegue ler e-mail, utilizar o calendário nem gerenciar documentos no Google Drive
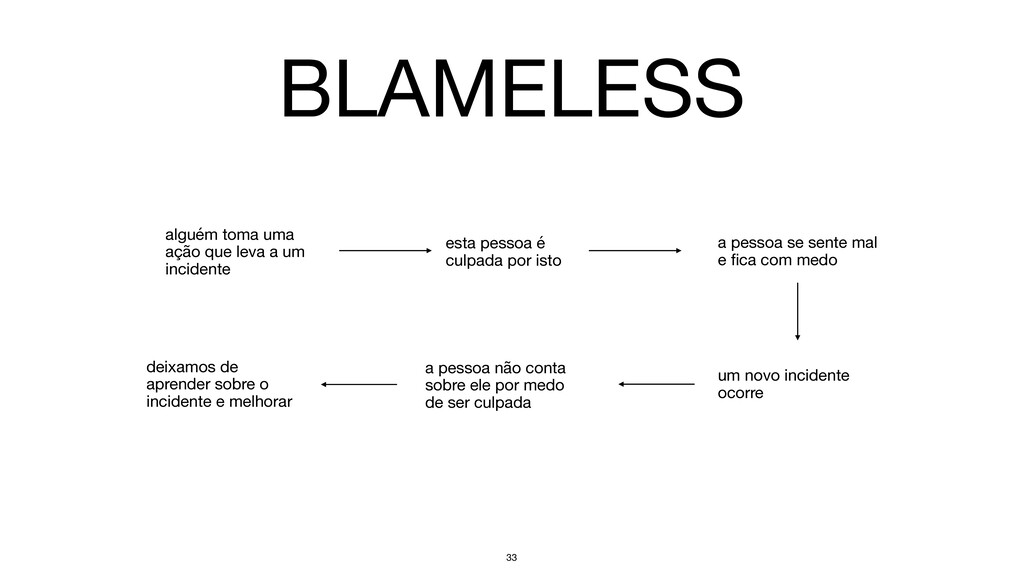
incidente esta pessoa é culpada por isto a pessoa se sente mal e fica com medo um novo incidente ocorre a pessoa não conta sobre ele por medo de ser culpada deixamos de aprender sobre o incidente e melhorar
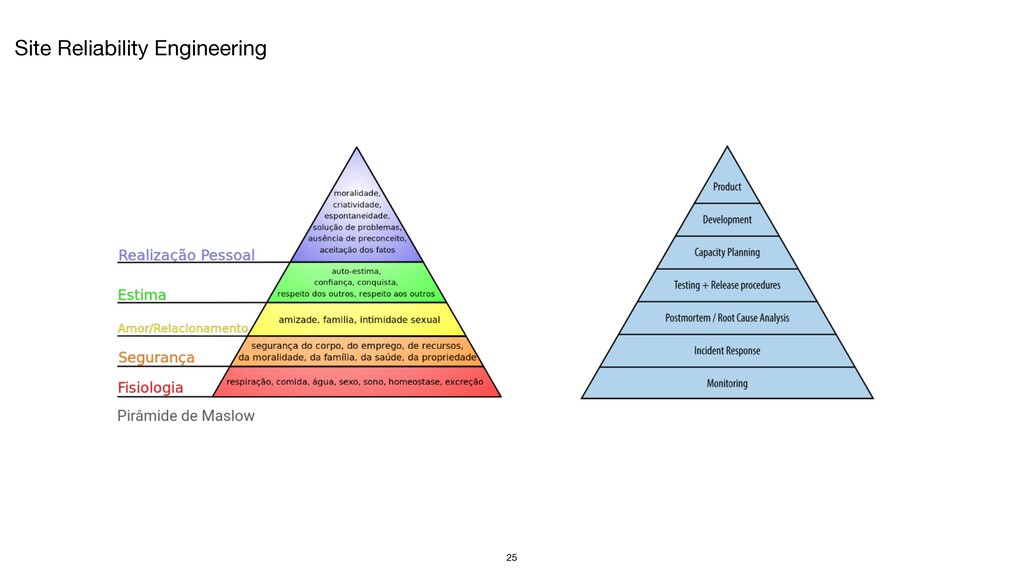
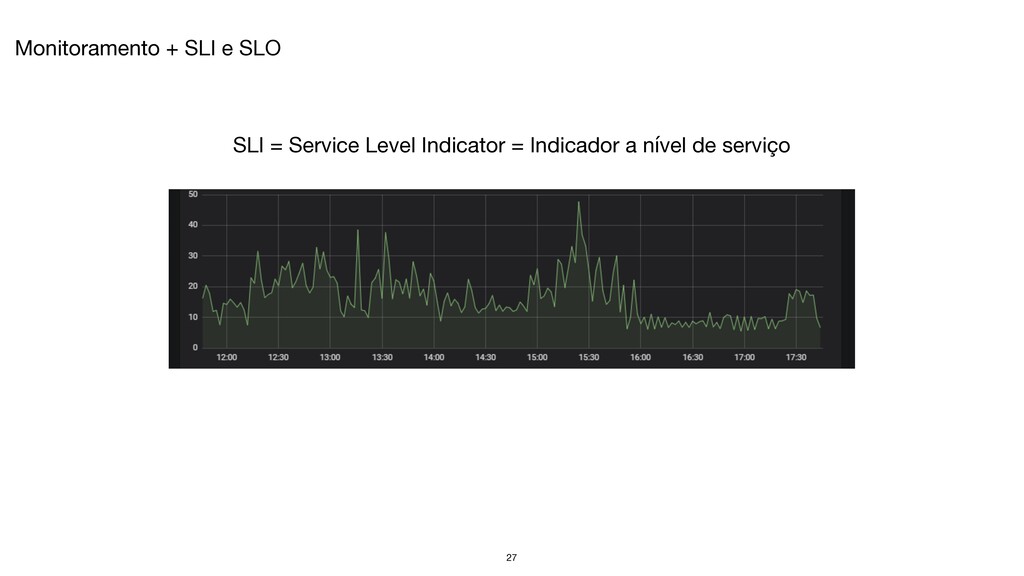
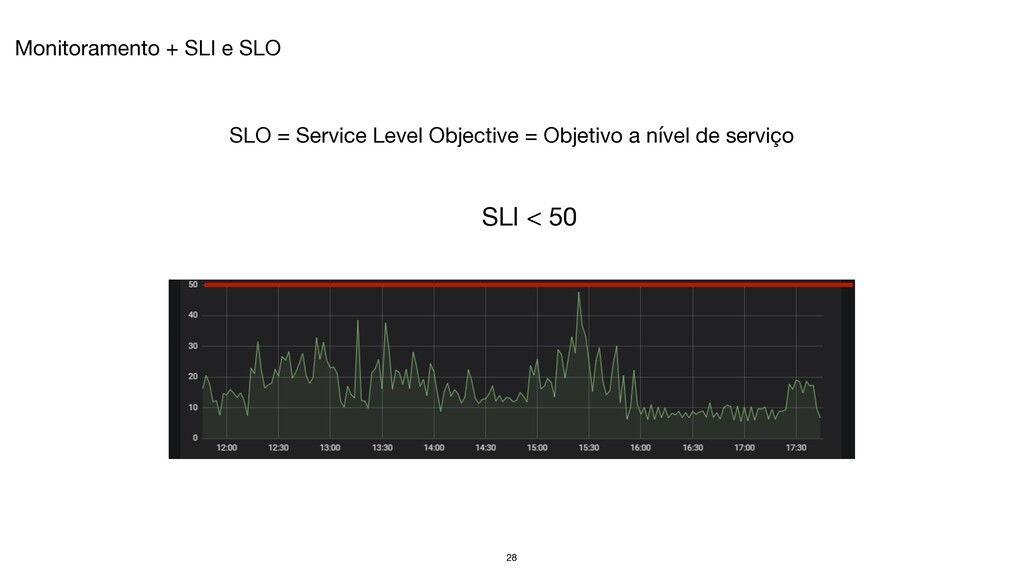
operação - Criação e desenvolvimento de software - Práticas de qualidade de código - Automatização de trabalho repetitivo - Sistemas operacionais - Redes de computadores - Monitoramento
{kind=link}
![2 Victor Silveira Bogo SRE @ @B0go @victorbogo [email protected]](https://files.speakerdeck.com/presentations/a93783348458410a90f3467697cbf656/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
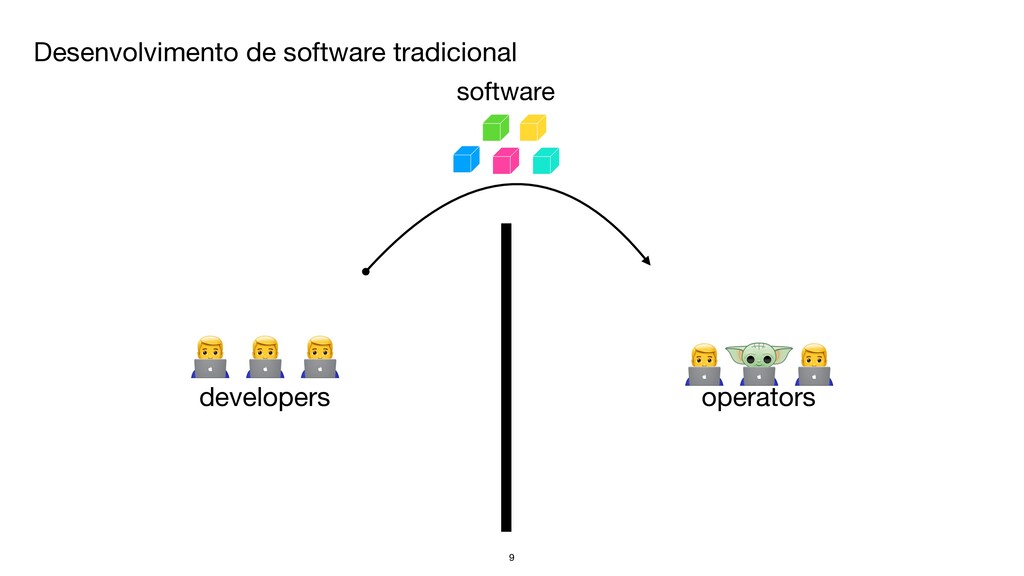{kind=link}
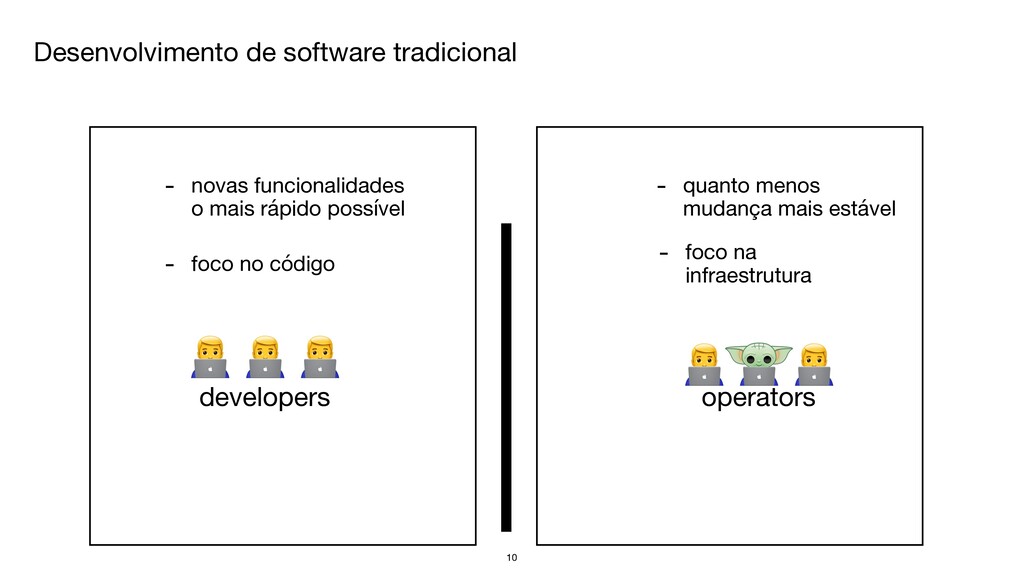{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
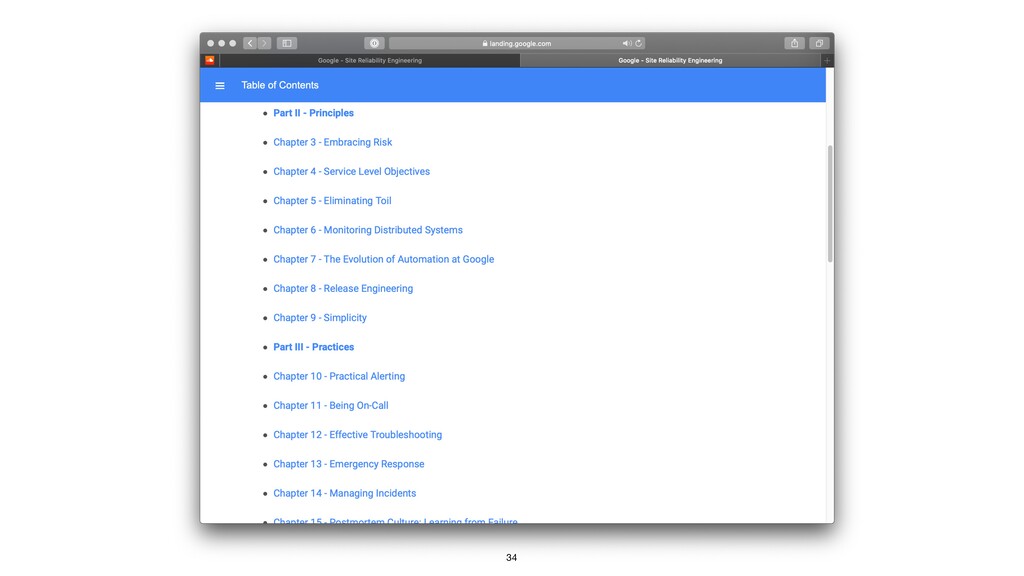{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
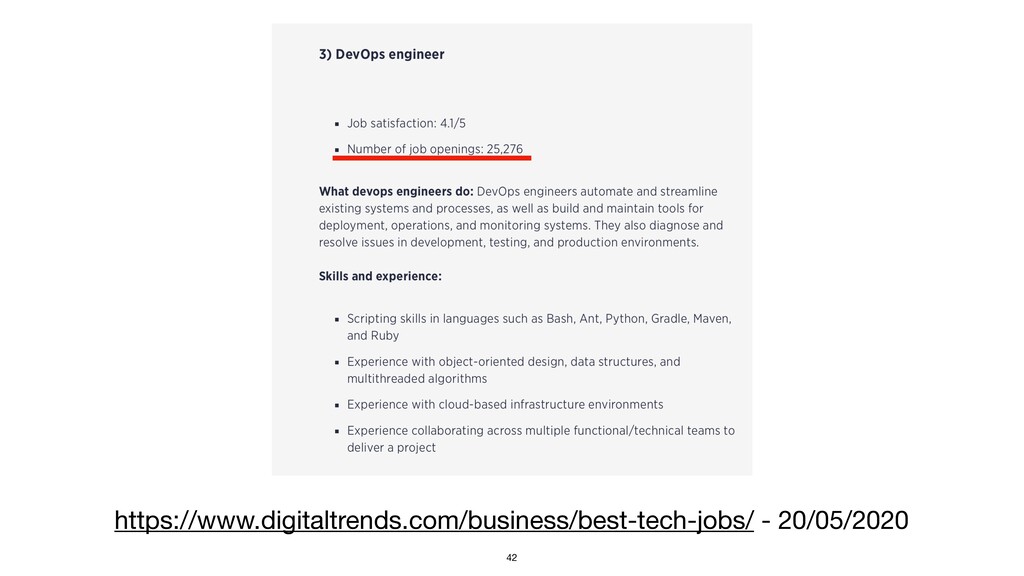{kind=link}
{kind=link}