Opening The Floodgates: Unicode Identifiers in Python
Python 3 introduced unicode identifiers into the language. This talk discusses what this means, what restrictions are included and shows what can happen when you drop those restrictions
in computers • Other standards (ascii, latin-1, euc-jp) are culturally specific ◦ Inappropriate for a global internet • Over one million characters allowing all known characters to be represented • There is even room for Emoji!
points from 0 to 1,114,112 • These codepoints correspond to characters ◦ U+0045 -> E ◦ U+1F60A -> • To represent these in the machine an encoding is used.
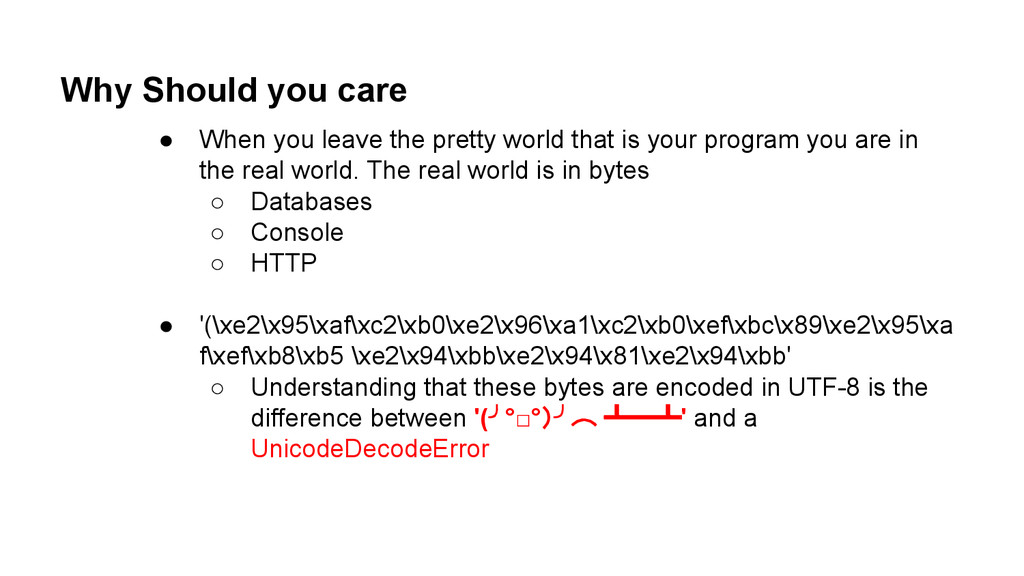
world that is your program you are in the real world. The real world is in bytes ◦ Databases ◦ Console ◦ HTTP • '(\xe2\x95\xaf\xc2\xb0\xe2\x96\xa1\xc2\xb0\xef\xbc\x89\xe2\x95\xa f\xef\xb8\xb5 \xe2\x94\xbb\xe2\x94\x81\xe2\x94\xbb' ◦ Understanding that these bytes are encoded in UTF-8 is the difference between '(╯°□°)╯︵ ┻━┻' and a UnicodeDecodeError
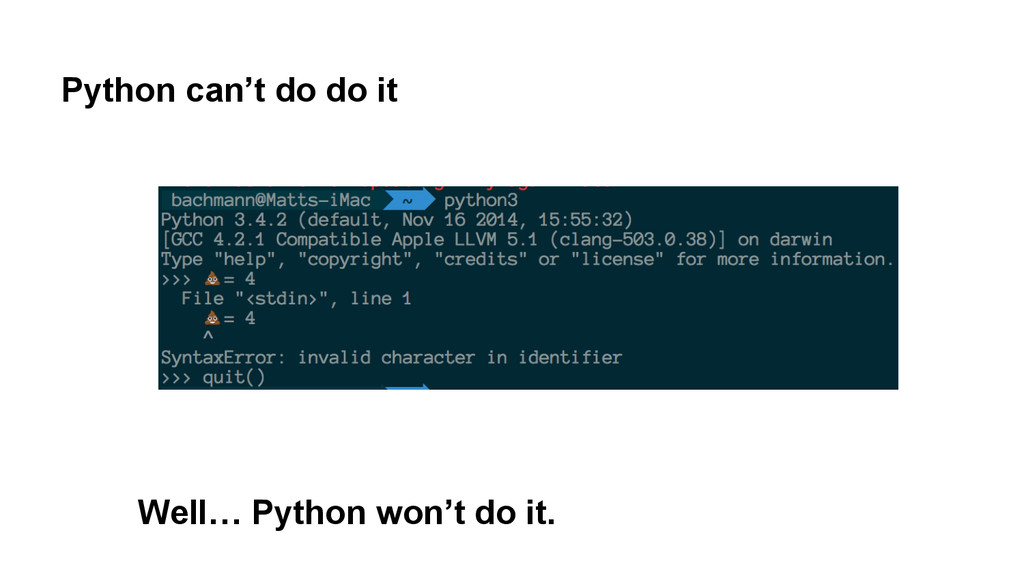
2 string • u”¥” is a unicode object • encode must be called on unicode objects ◦ Encode into bytes ◦ Decode into unicode • Call encode on a string Python tries to “help” by decoding it into unicode first • And it explodes.
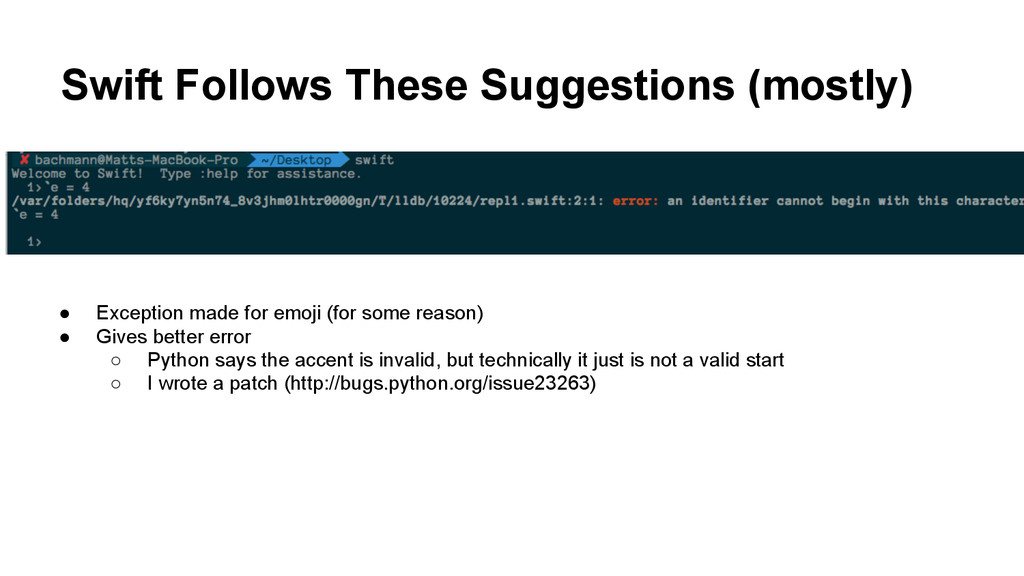
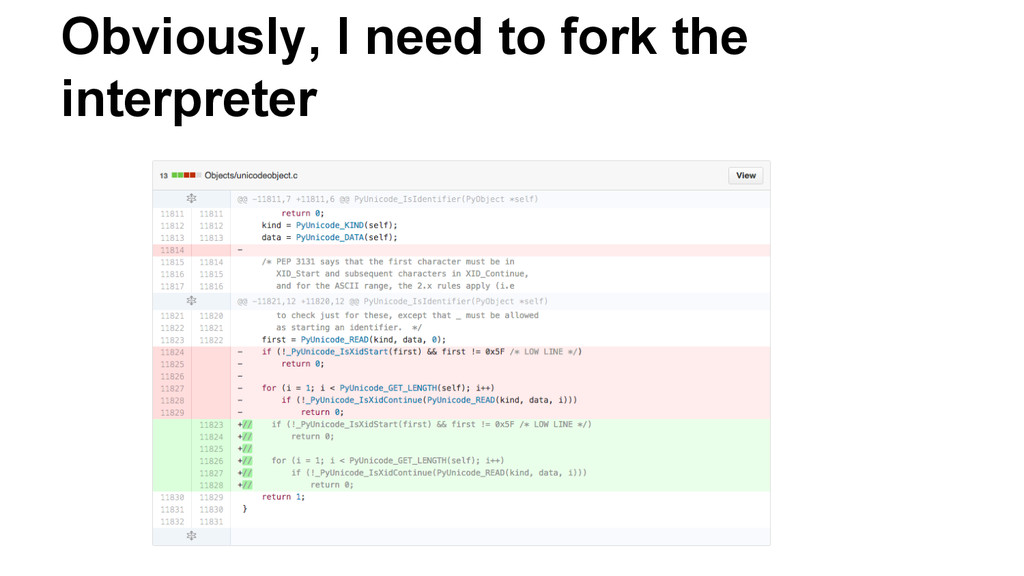
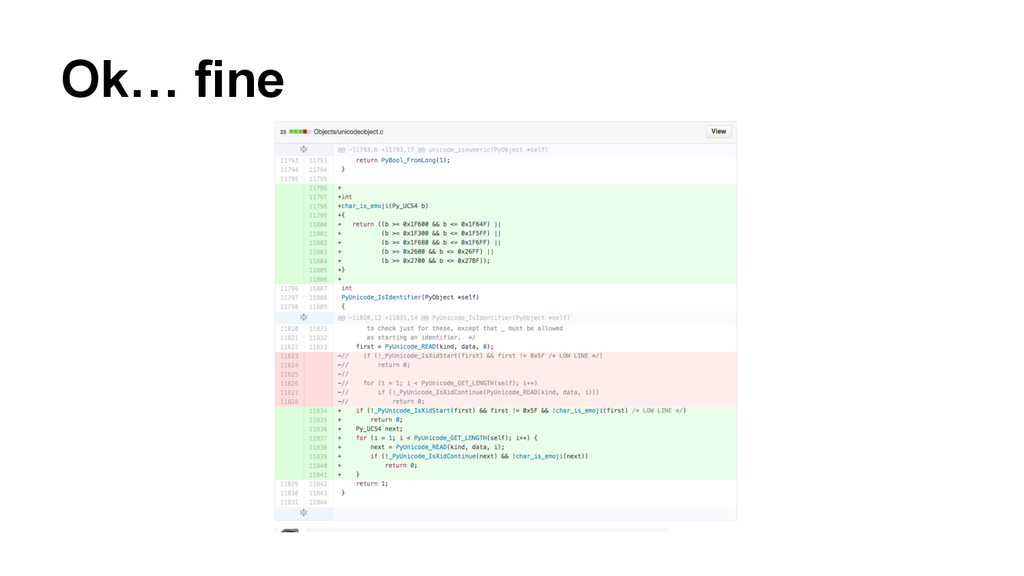
identifiers only allow a subset of Unicode • Specifically the follow the suggestions of The Unicode Consortium ◦ Identifier: XID_START XID_CONTINUE* • XID_START ◦ Basically “This is a letter” • XID_CONTINUE ◦ Everything in XID_START and modifier characters
(for some reason) • Gives better error ◦ Python says the accent is invalid, but technically it just is not a valid start ◦ I wrote a patch (http://bugs.python.org/issue23263)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}