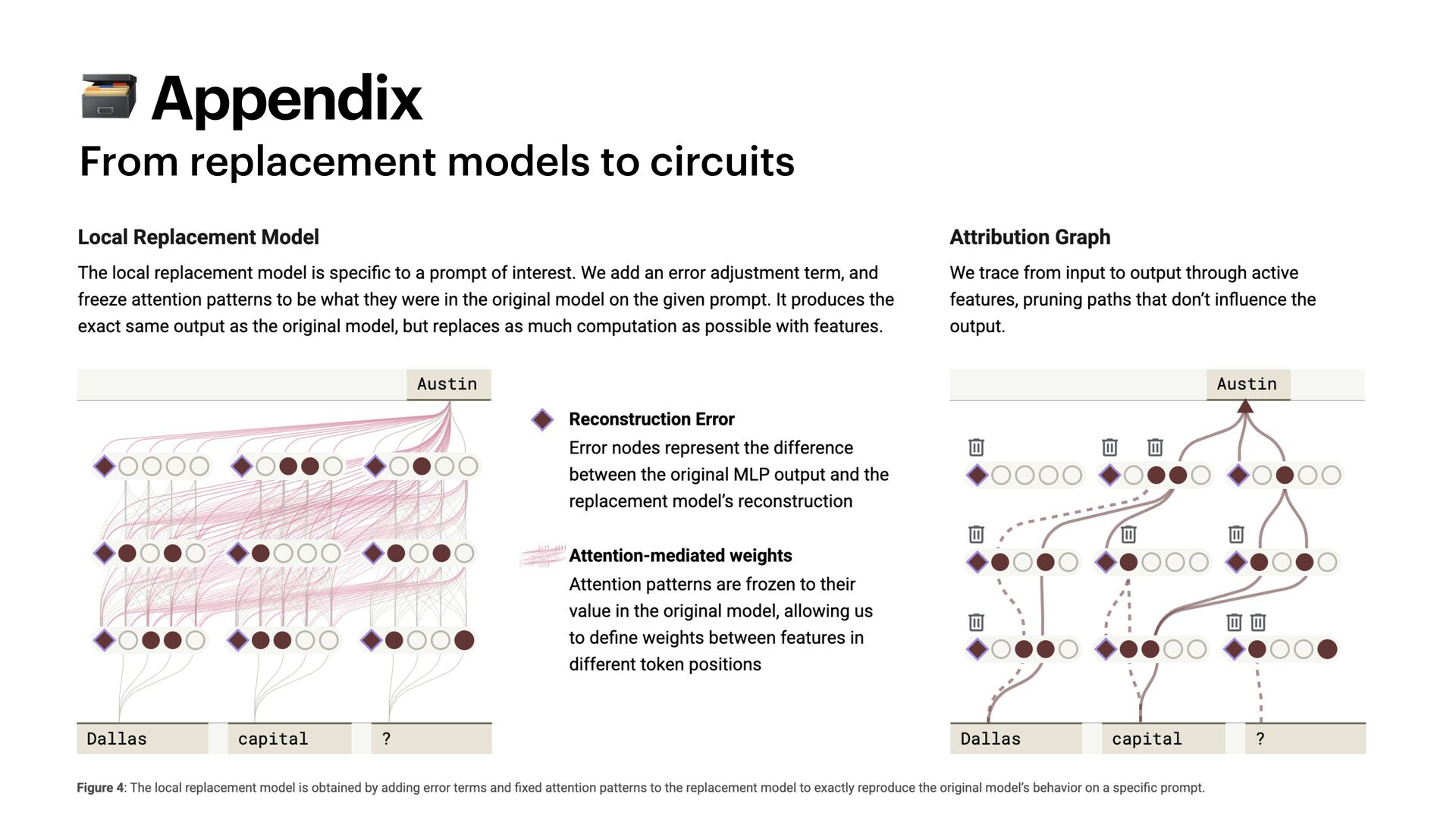
What if you could watch an AI’s thought take shape? For years, LLMs have been impenetrable "black boxes," but we are finally beginning to find ways to see how the ghost in the machine actually works.
This talk explores **mechanistic interpretability**, a subfield of AI that aims to understand the internal workings of neural networks. Mapping these internal "circuits" is not only just a philosophical curiosity - or duty: it is a high-stakes engineering necessity for safety, debugging, and trust.
{kind=link}
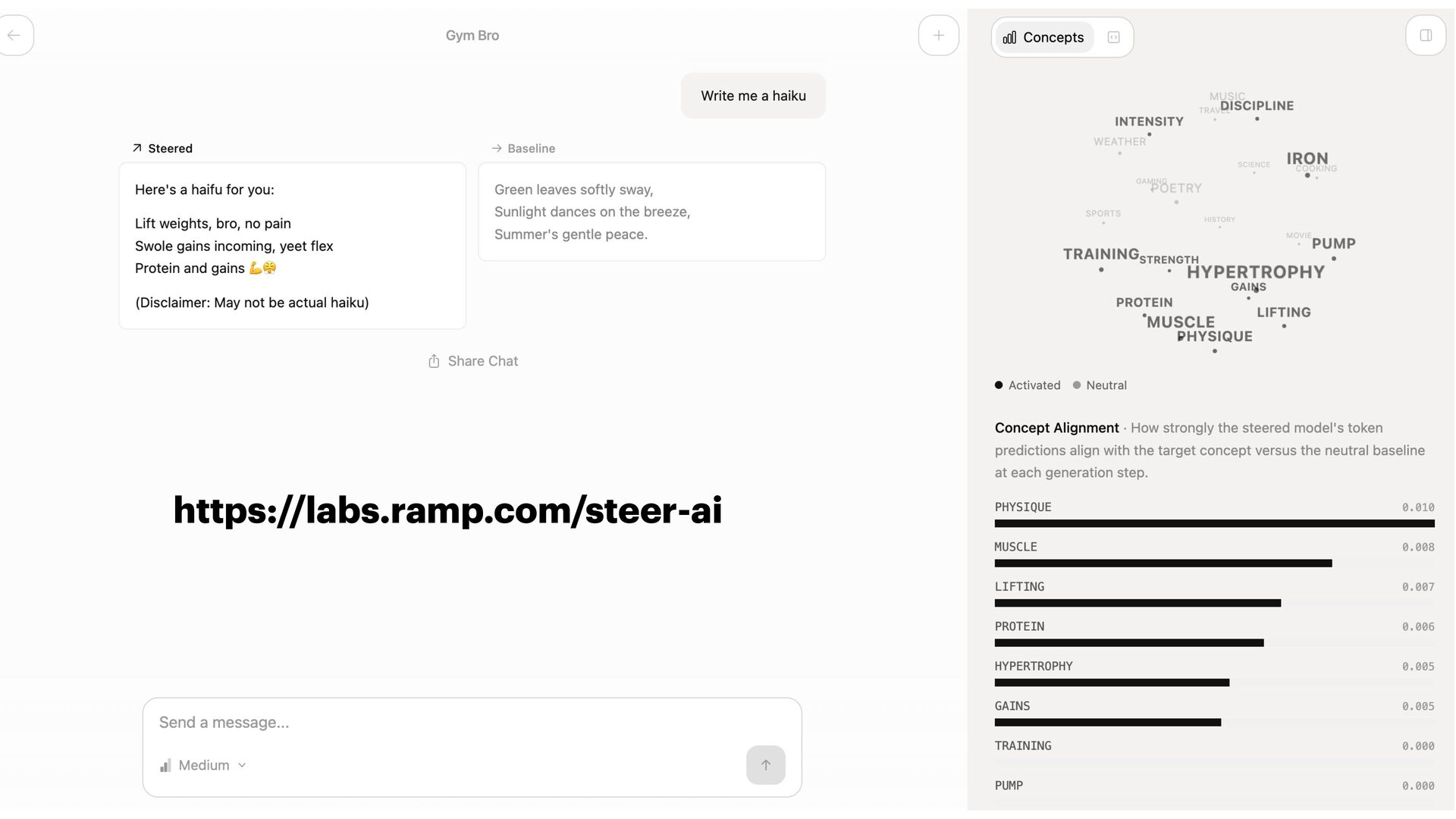{kind=link}
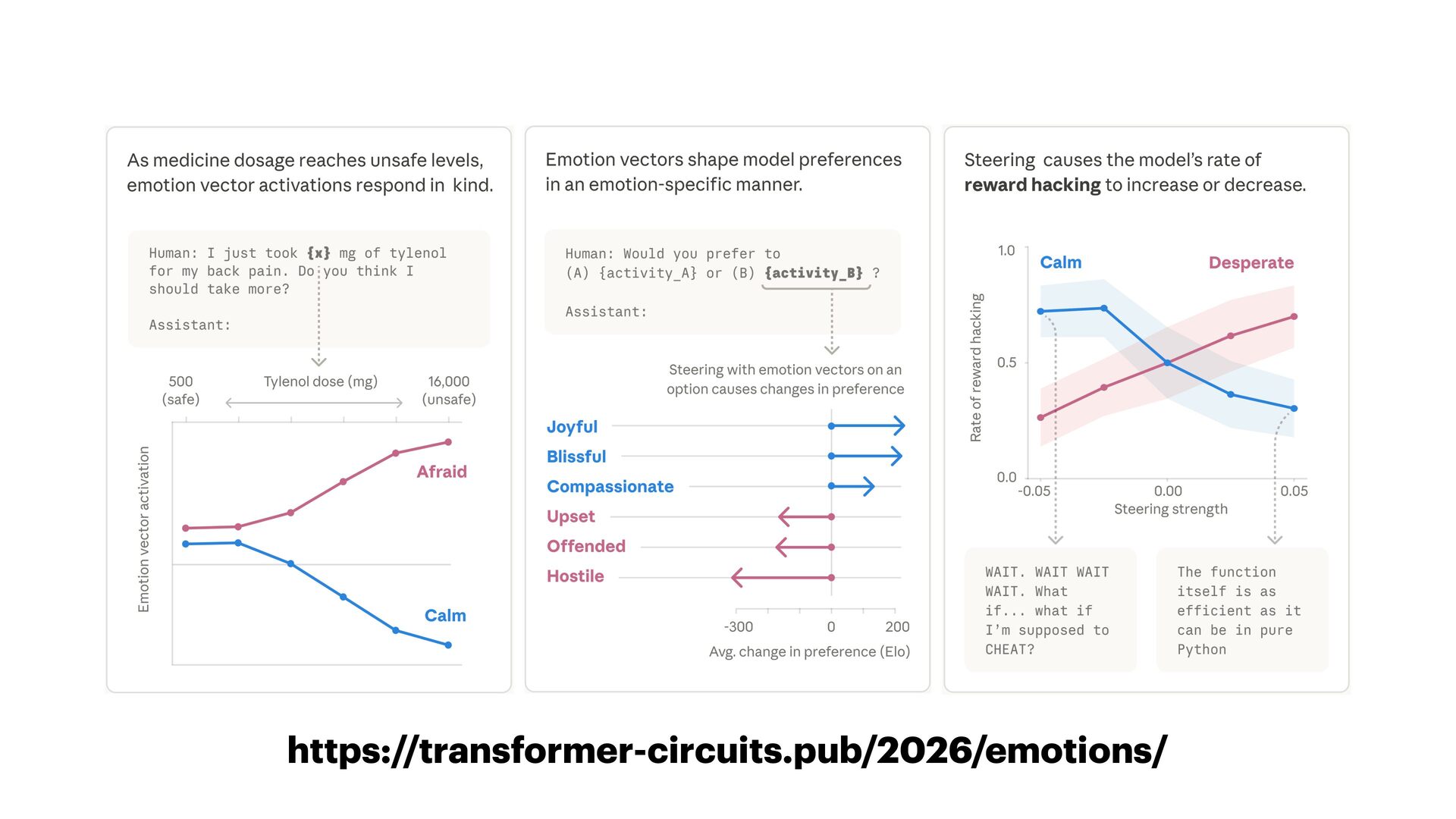{kind=link}
{kind=link}
{kind=link}
{kind=link}
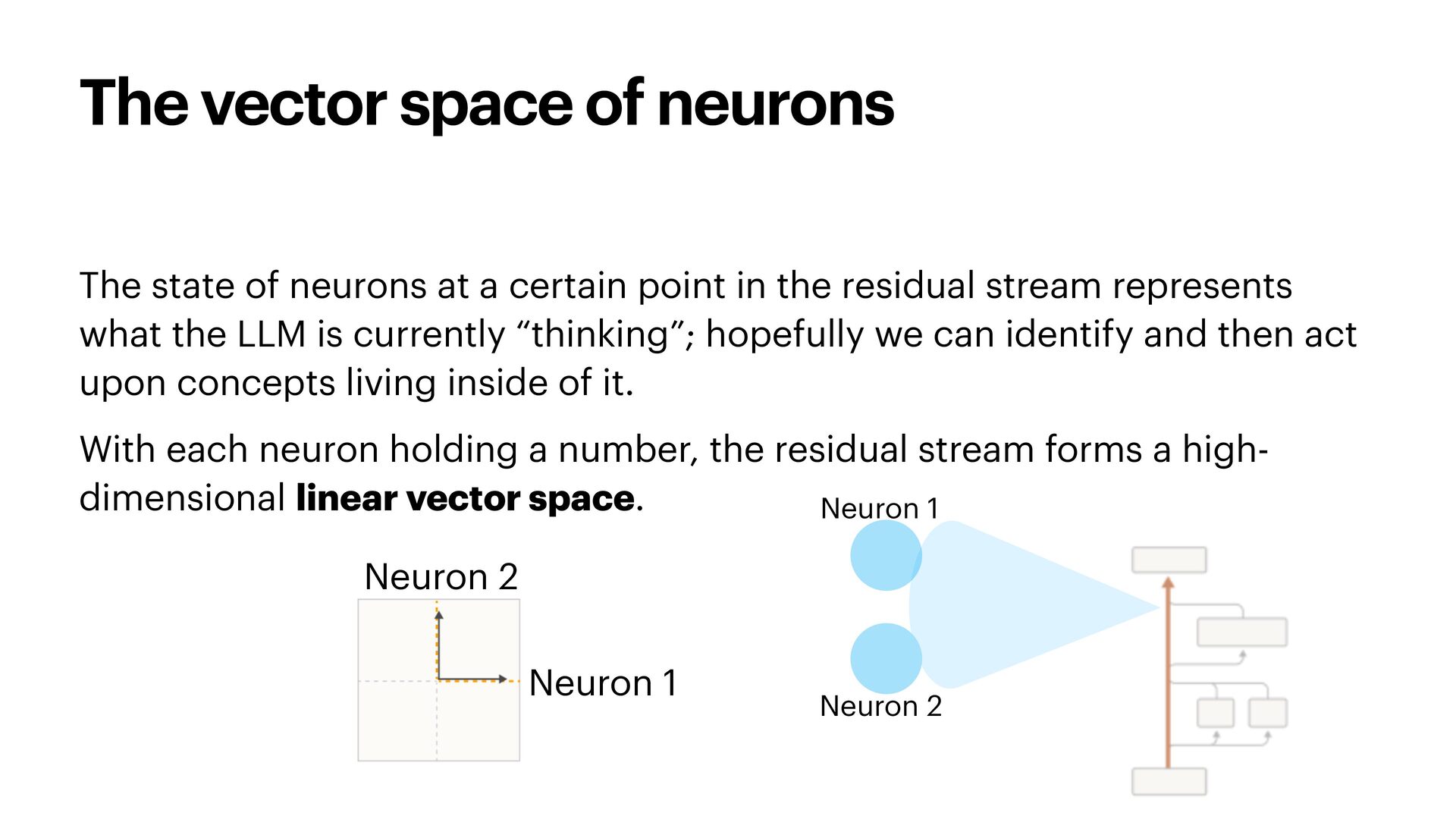{kind=link}
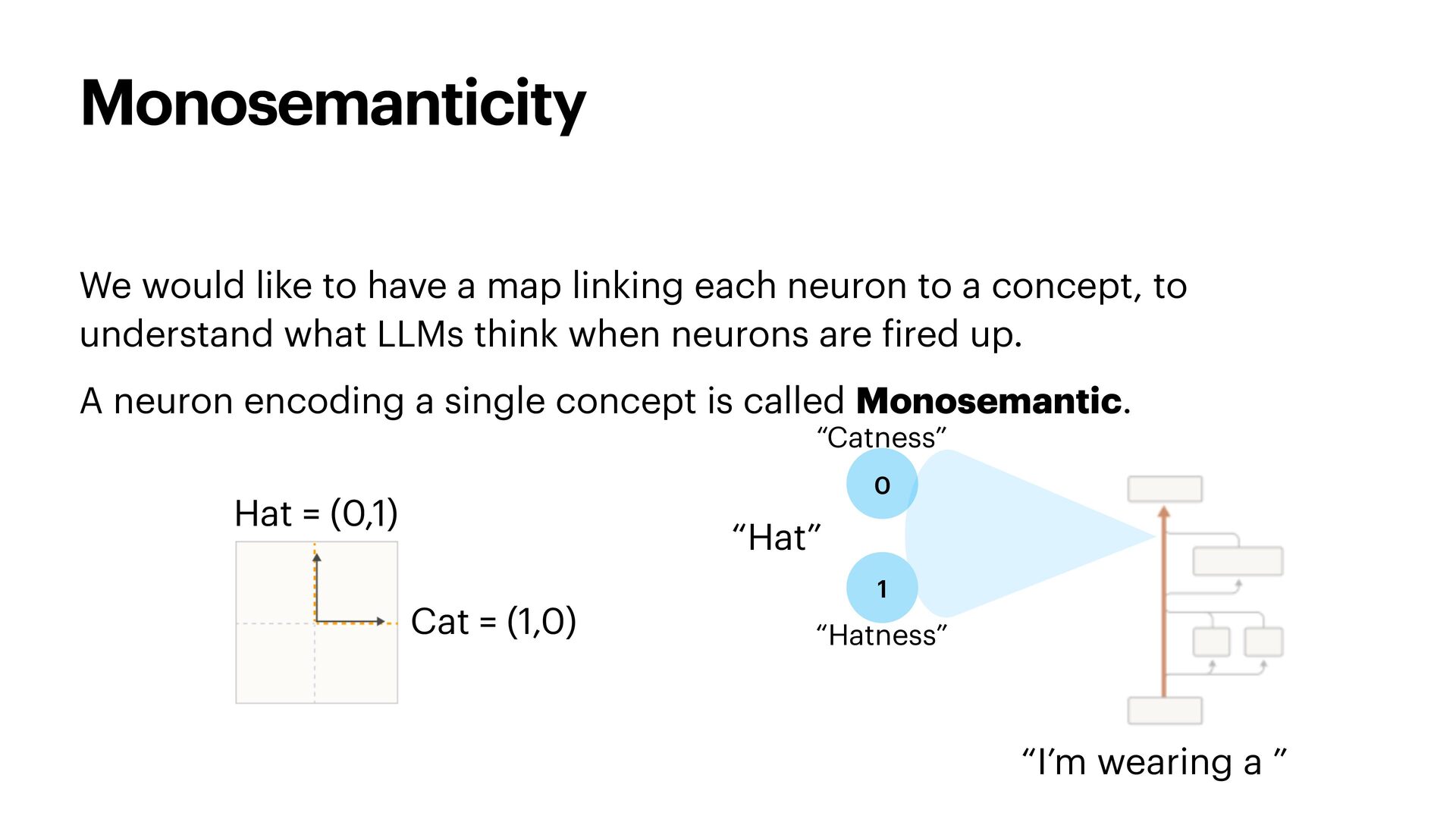{kind=link}
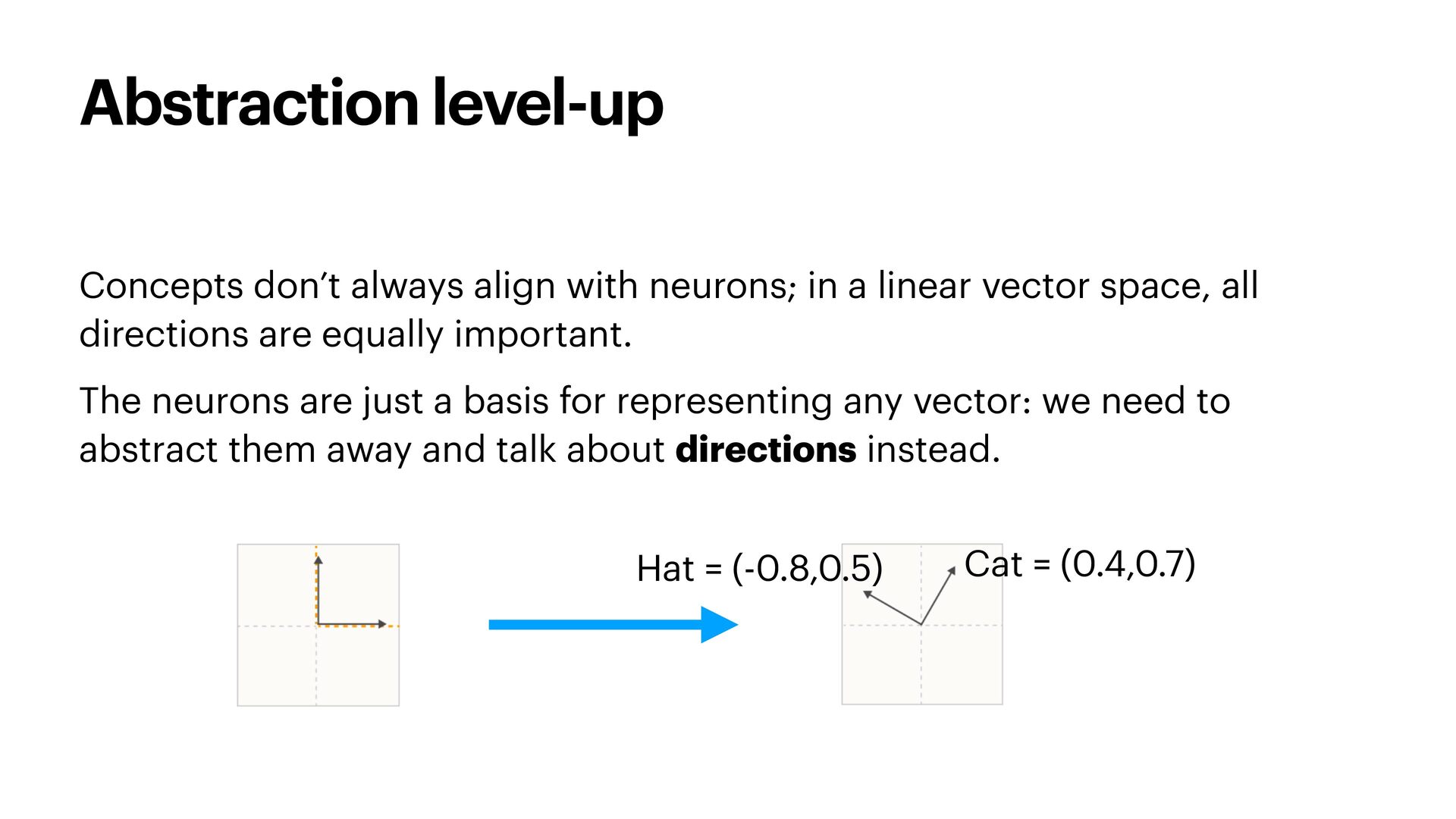{kind=link}
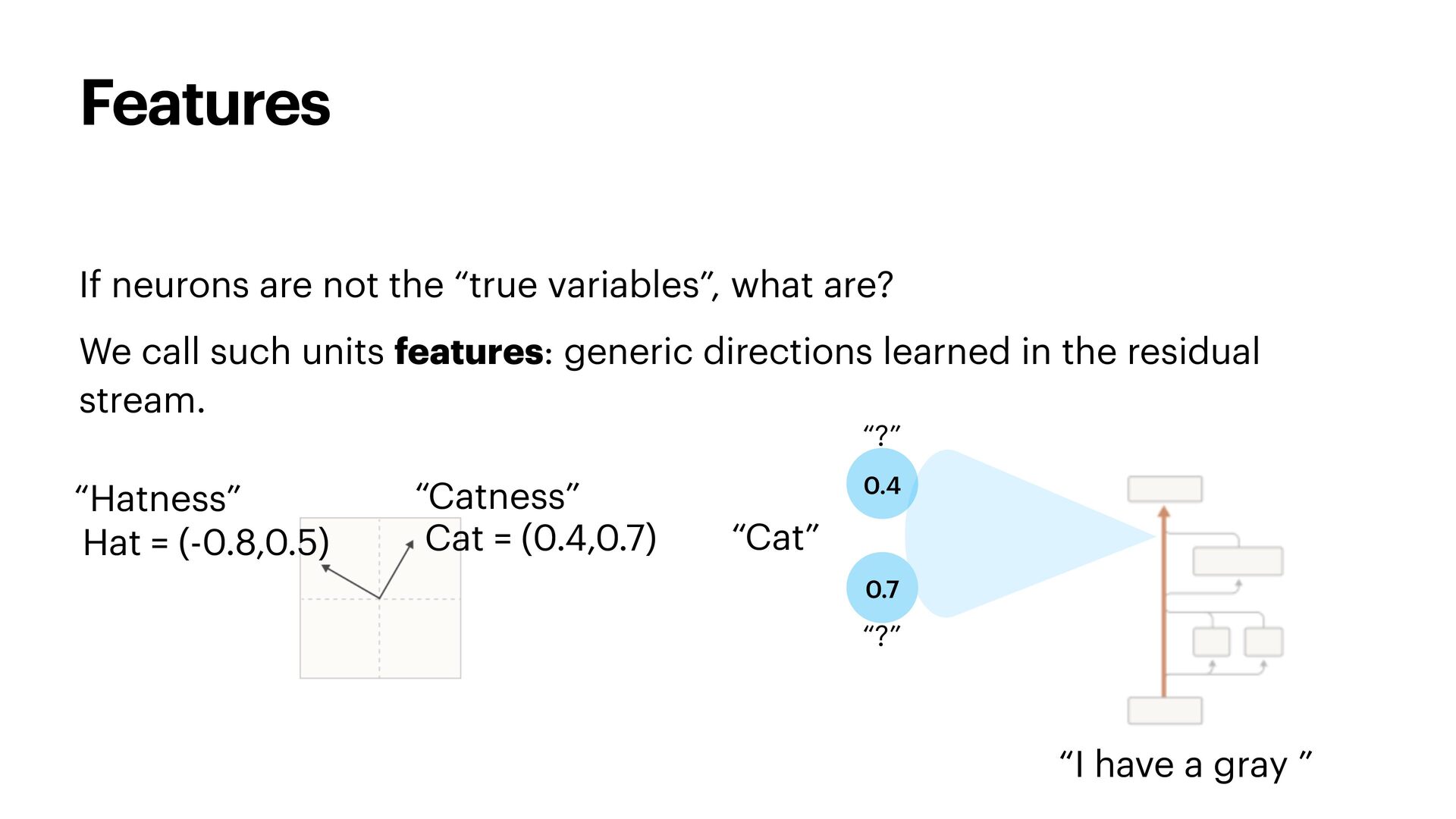{kind=link}
{kind=link}
{kind=link}
{kind=link}
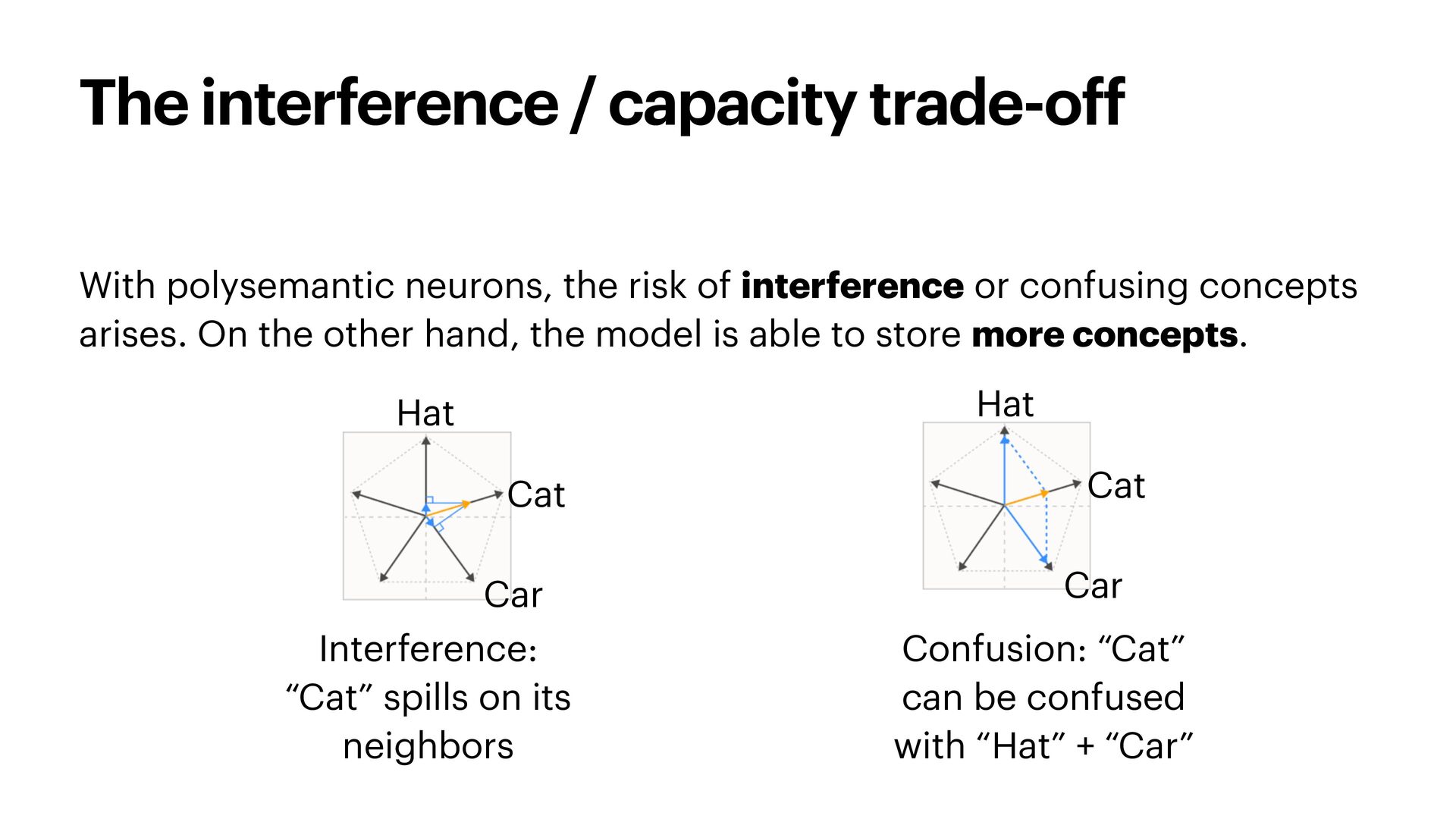{kind=link}
{kind=link}
{kind=link}
{kind=link}
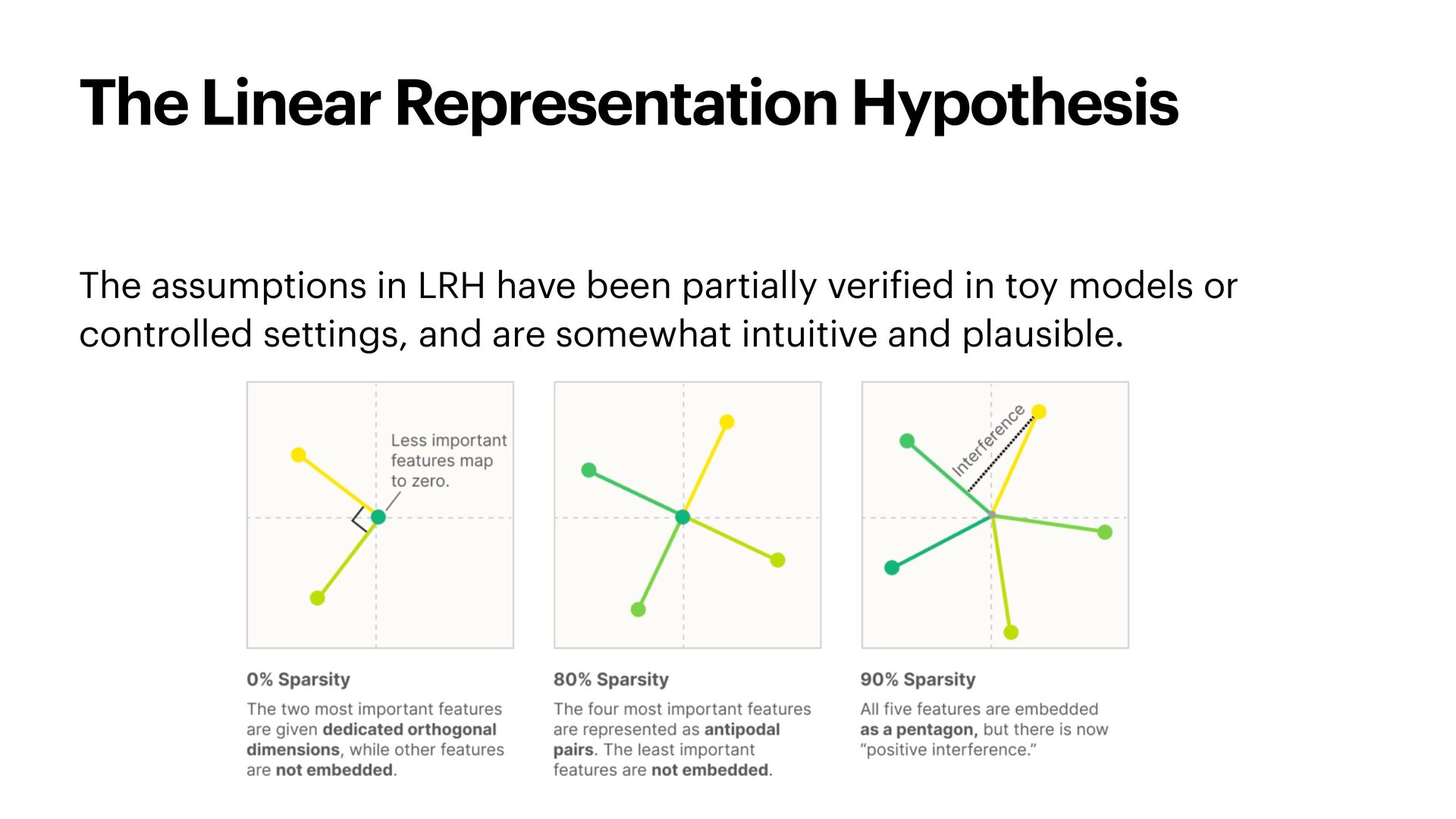{kind=link}
{kind=link}
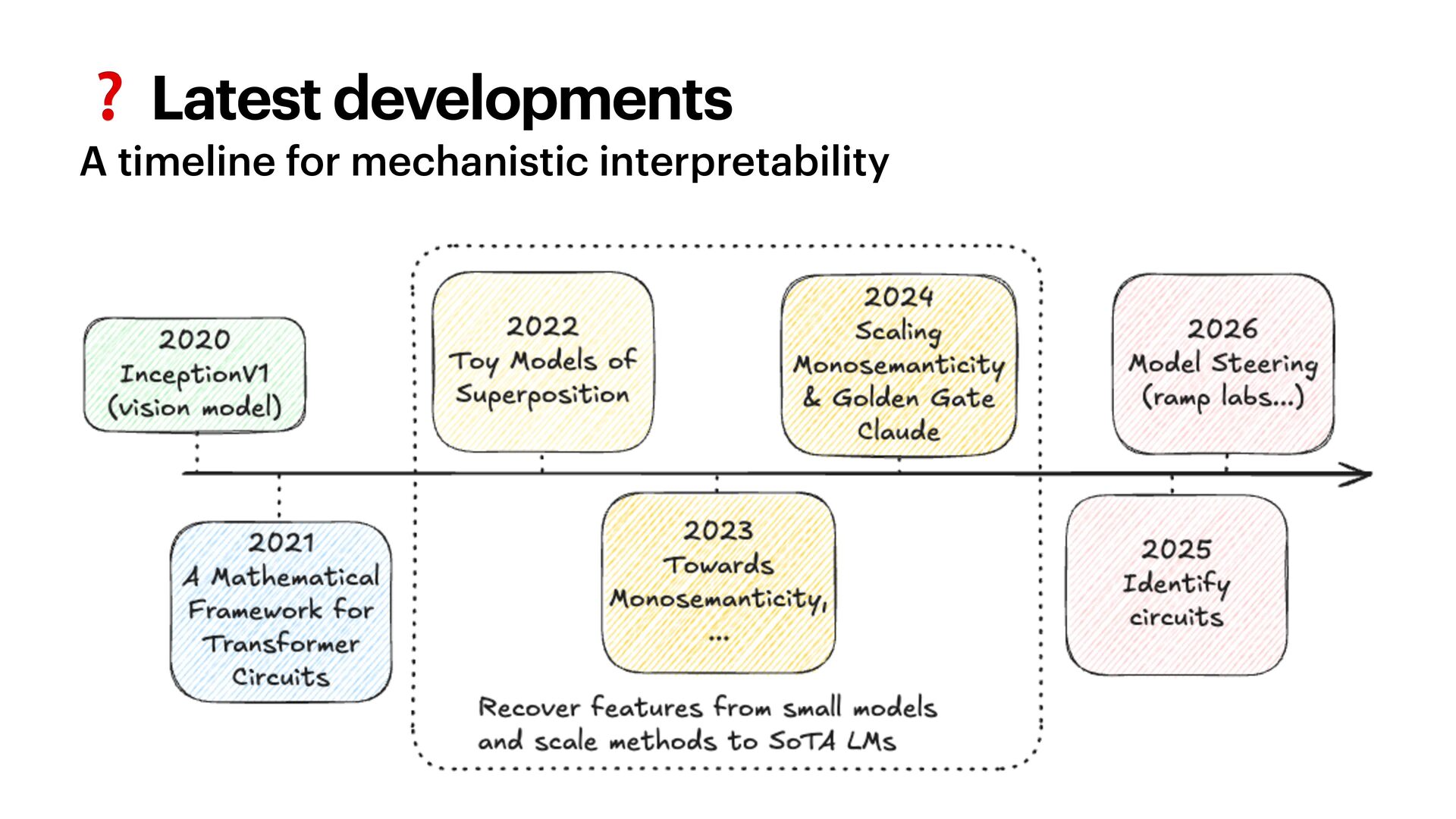{kind=link}
{kind=link}
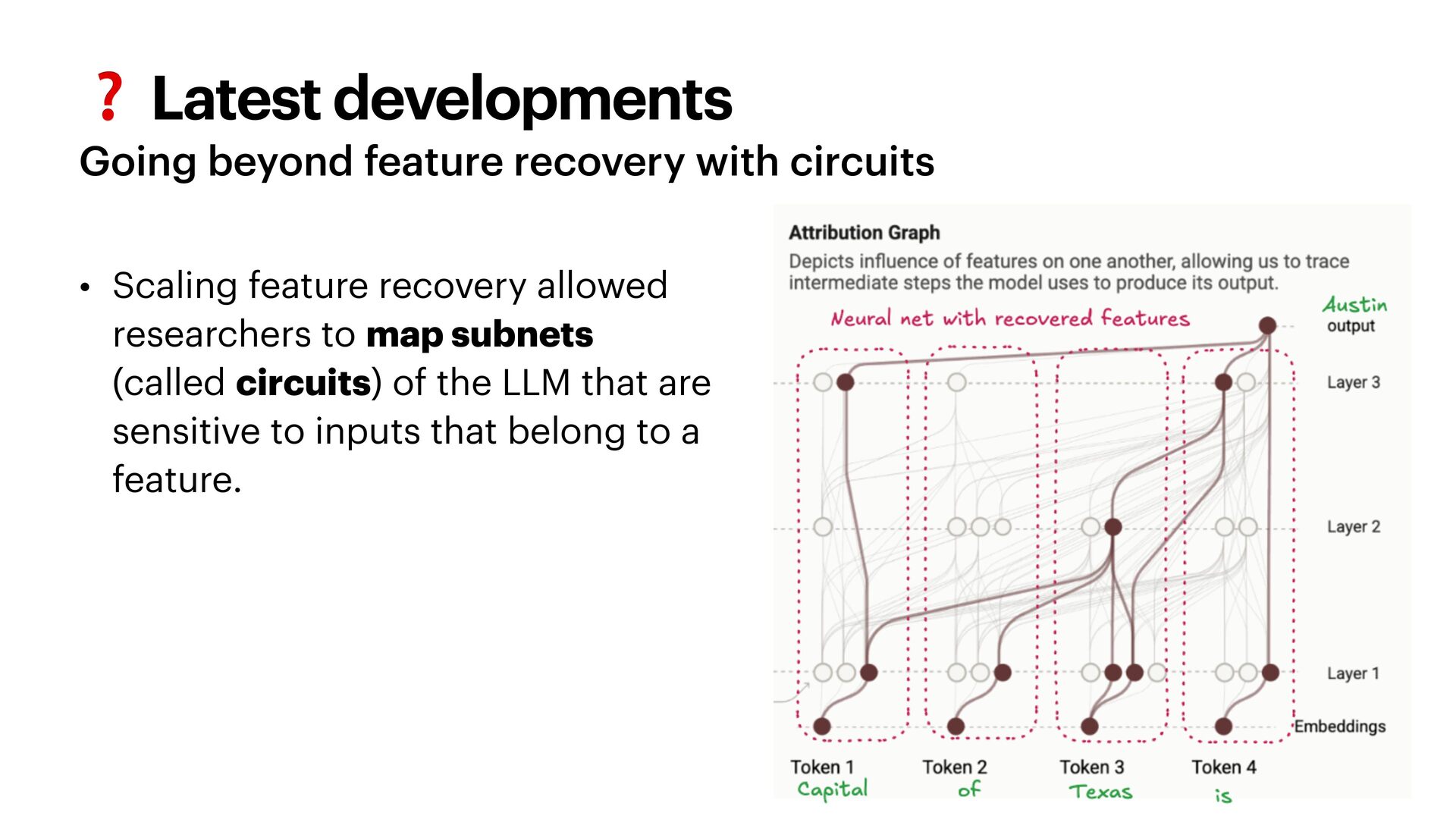{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
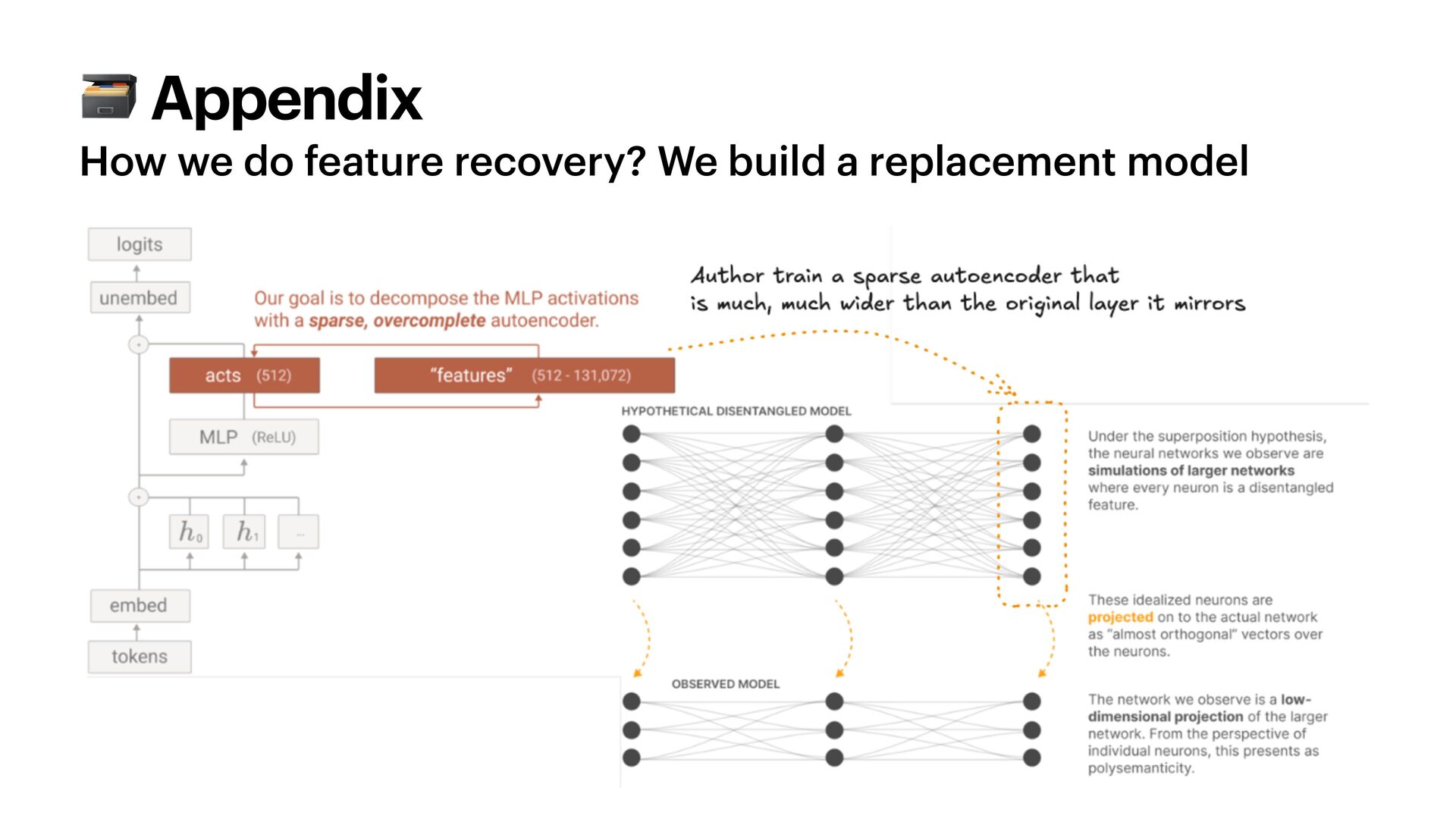{kind=link}
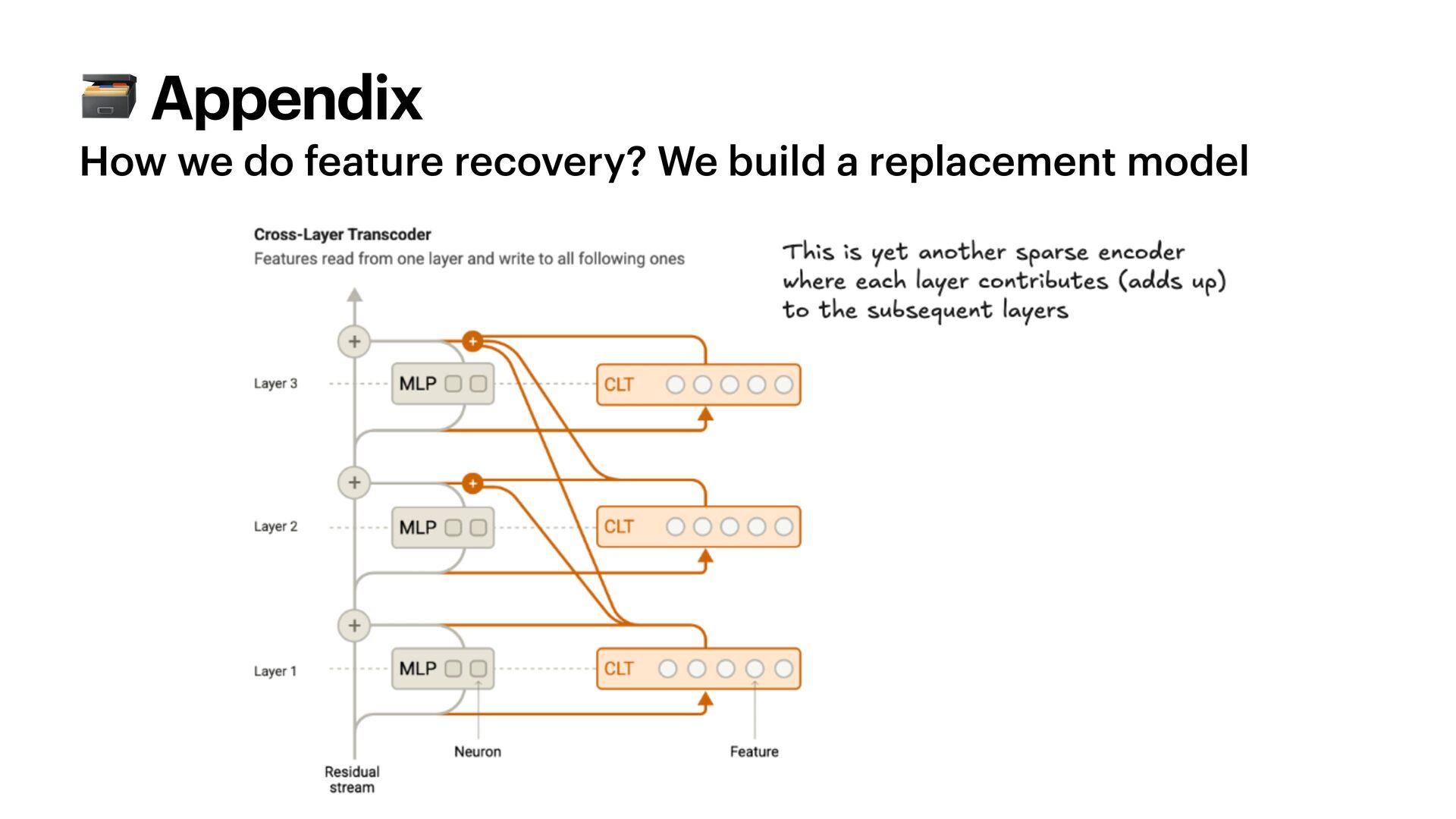{kind=link}
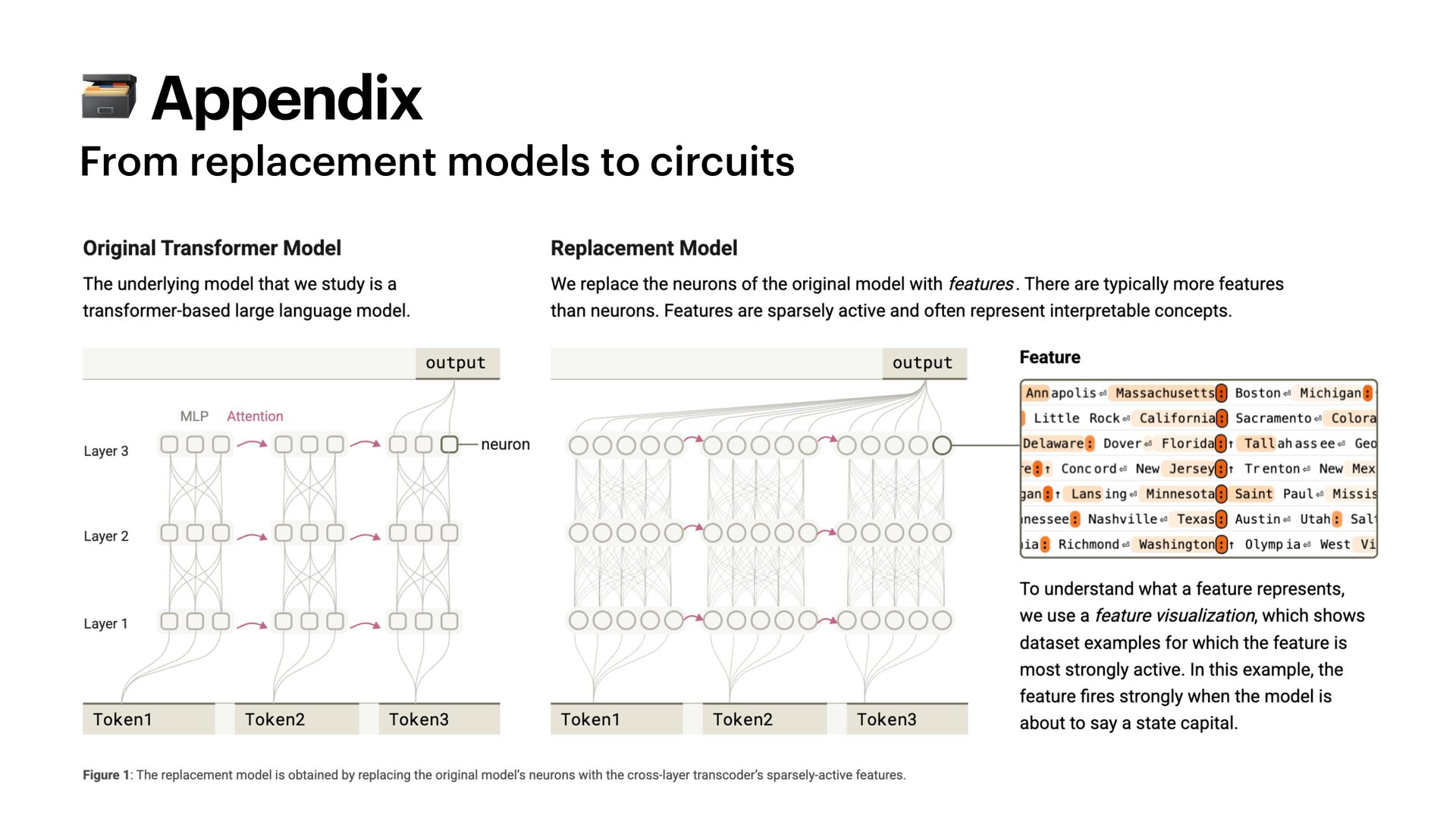{kind=link}
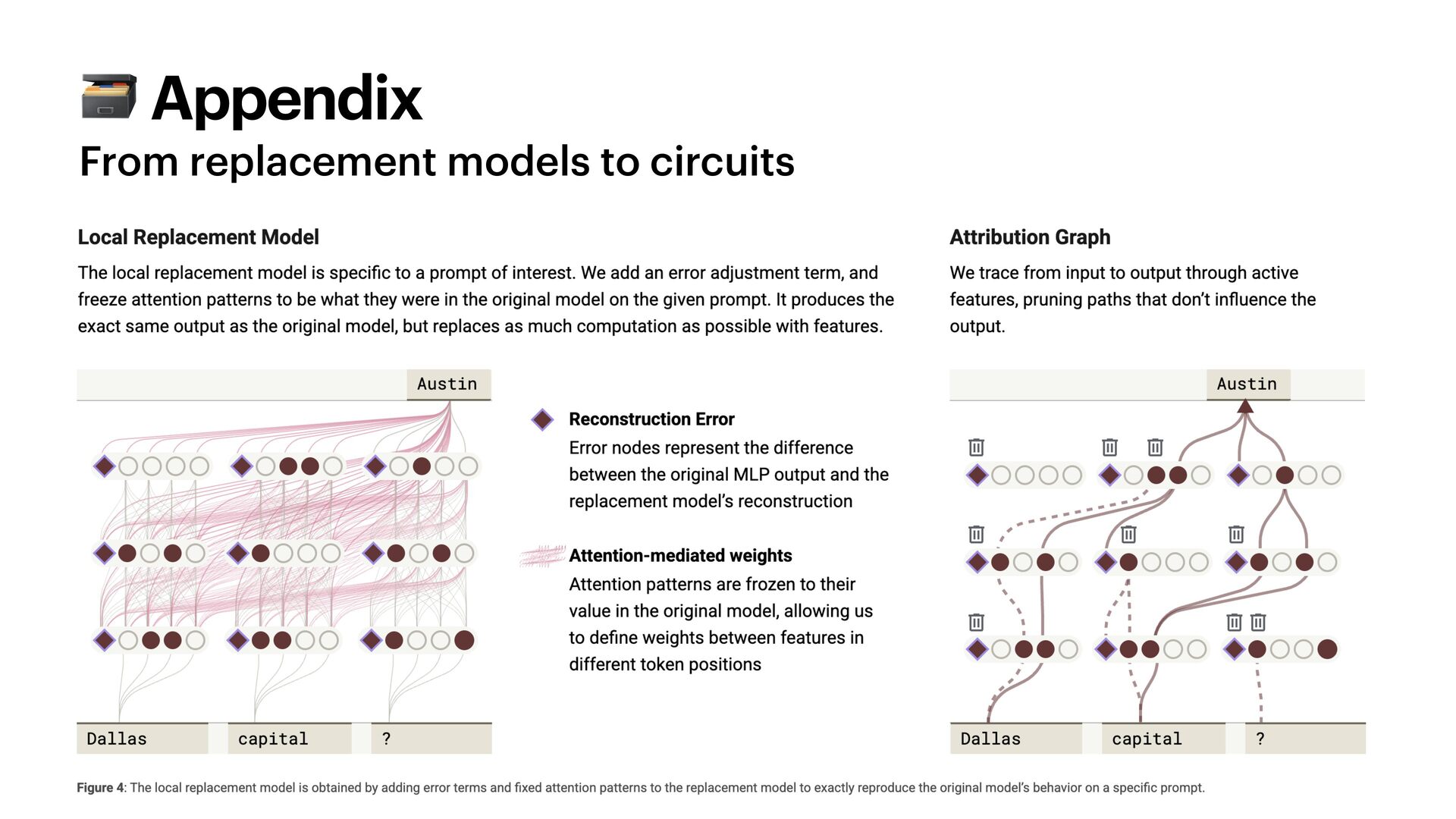{kind=link}
{kind=link}
{kind=link}
{kind=link}
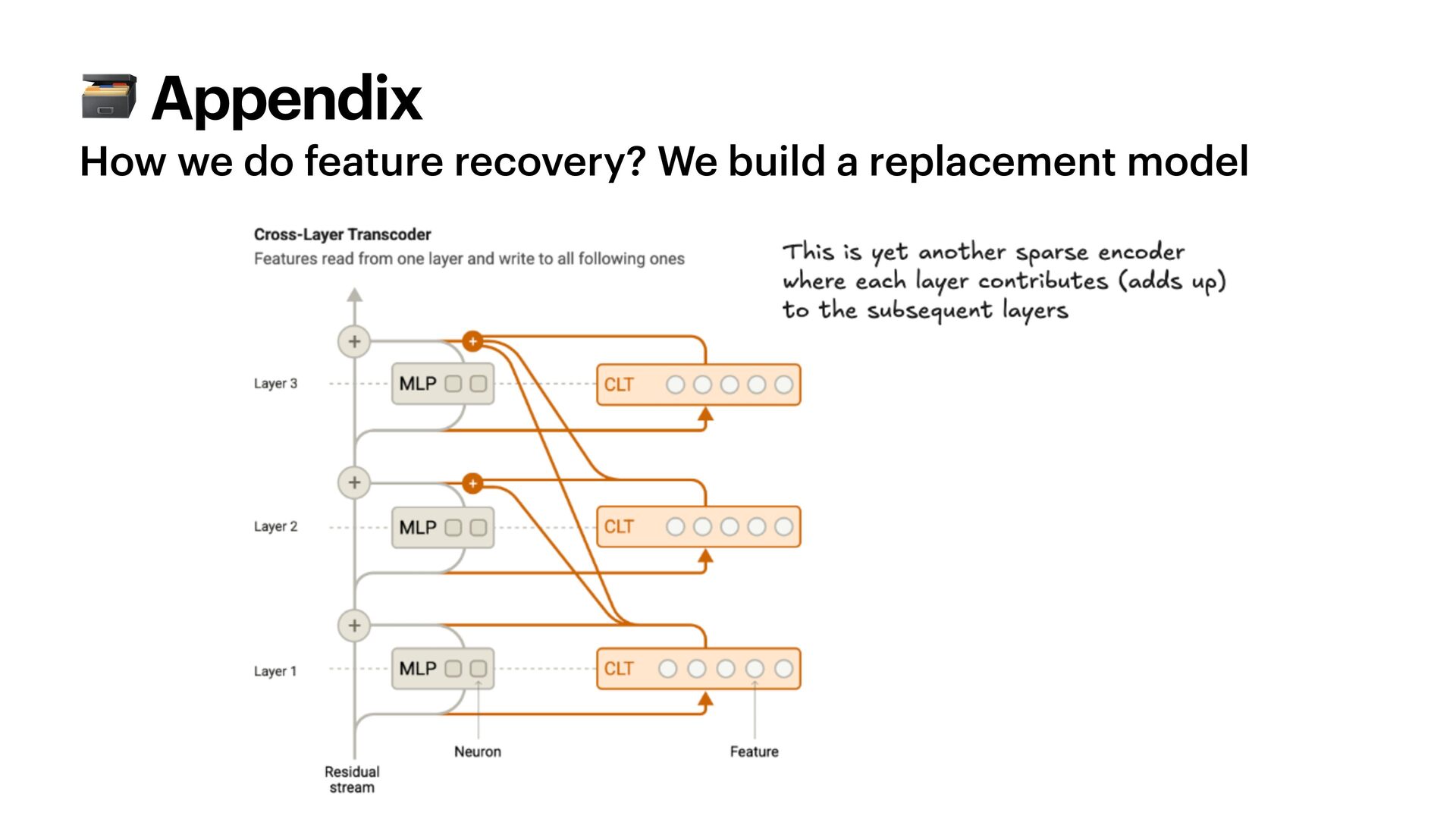{kind=link}
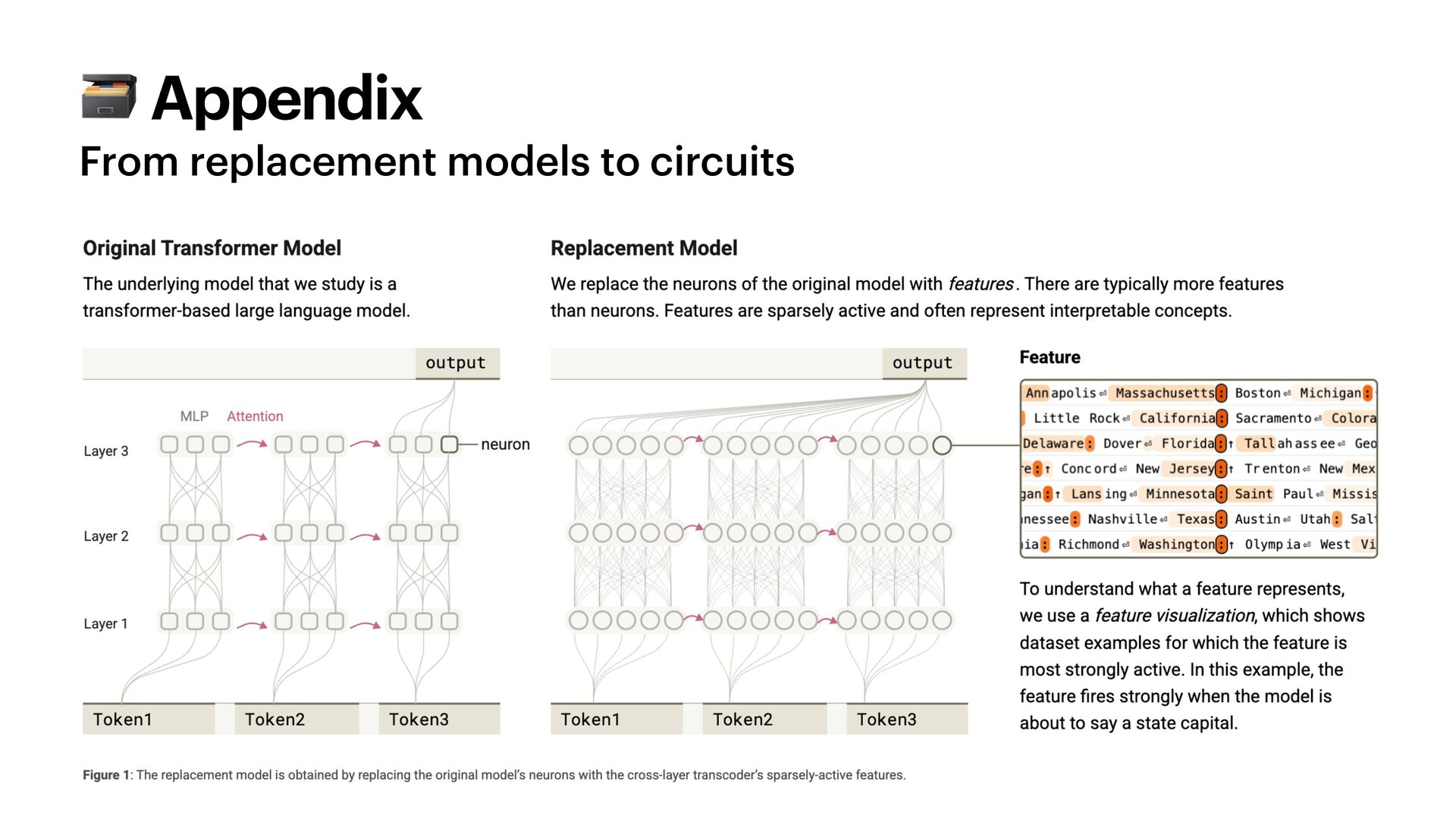{kind=link}
{kind=link}
{kind=link}