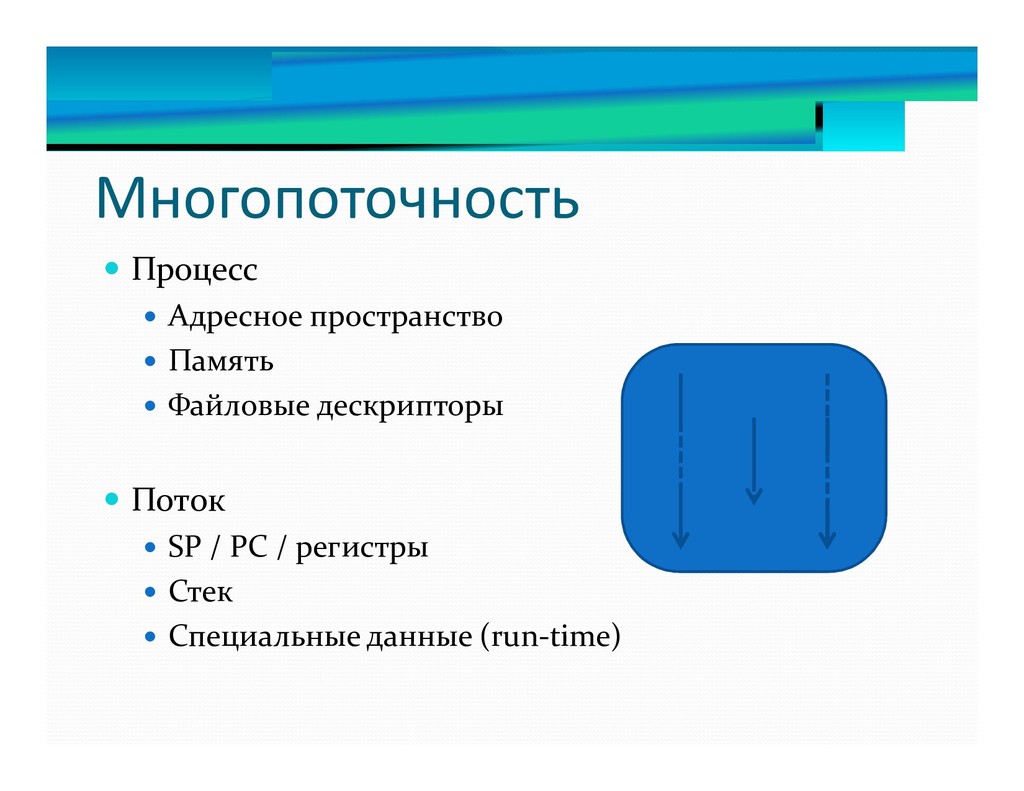
1. Что такое многопоточность?
2. Средства синхронизации.
3. std::thread.
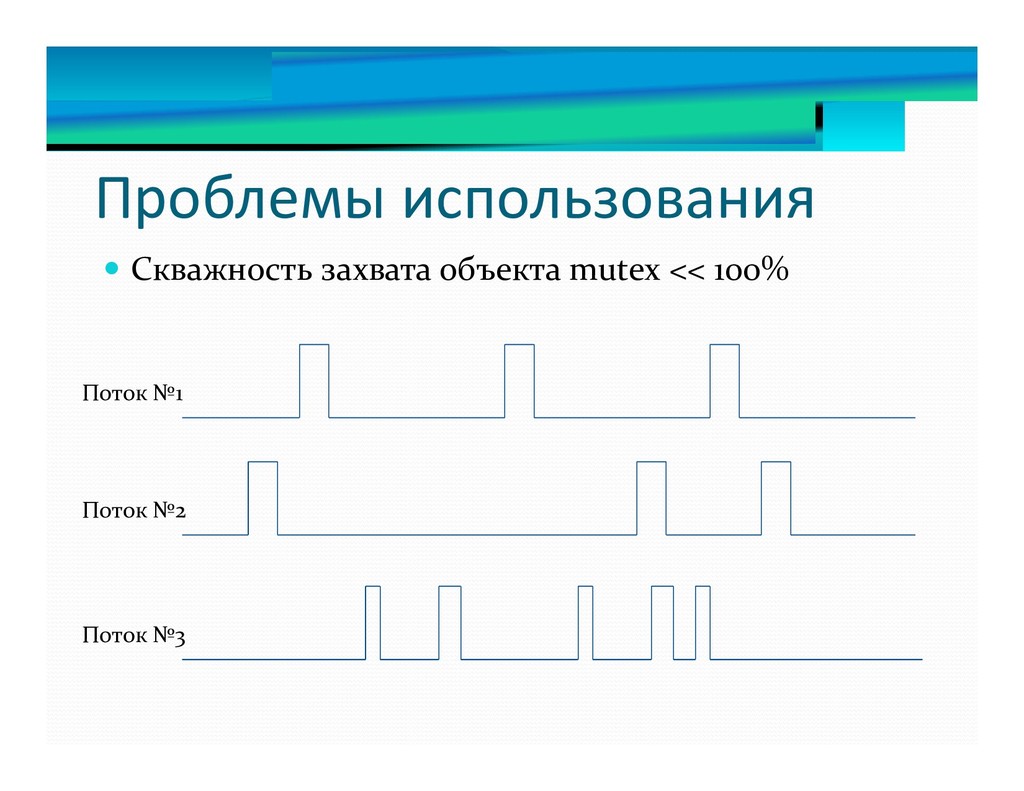
4. std::mutex. Проблемы и удобства использования.
5. std::condition_variable.
6. Атомарные операции, std::atomic.
7. Volatile.
8. std::future.
9. std::packed_task.
10. std::async.
11. std::promise.
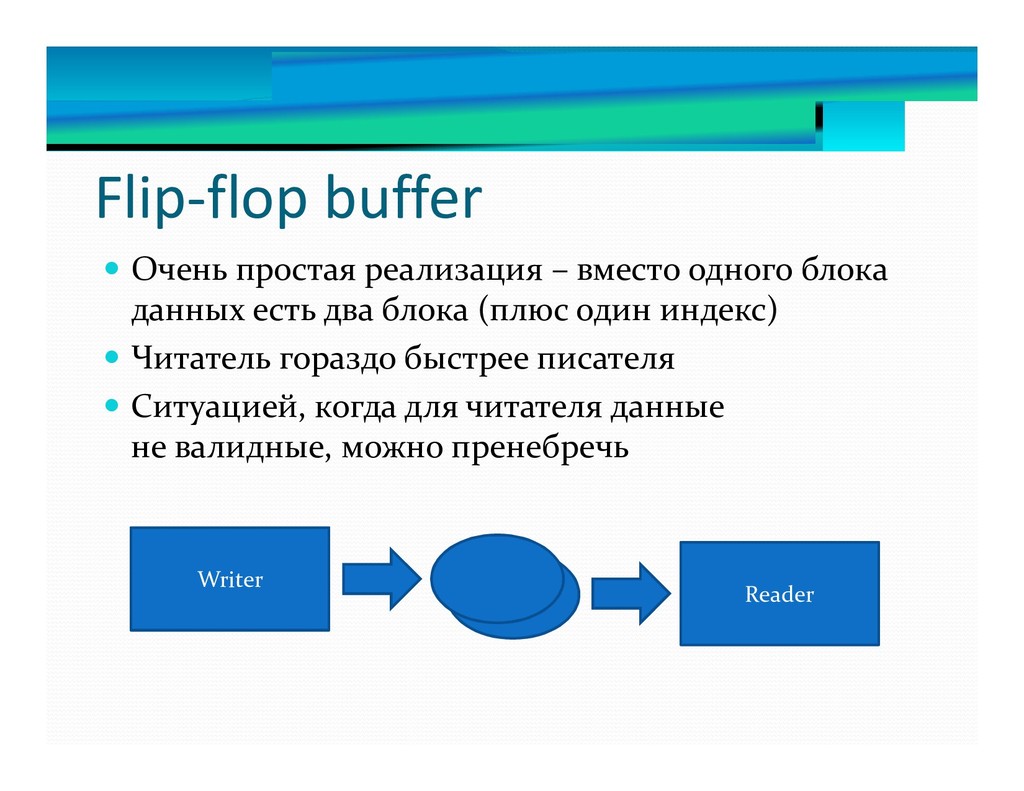
12. Flip-flop буфер.
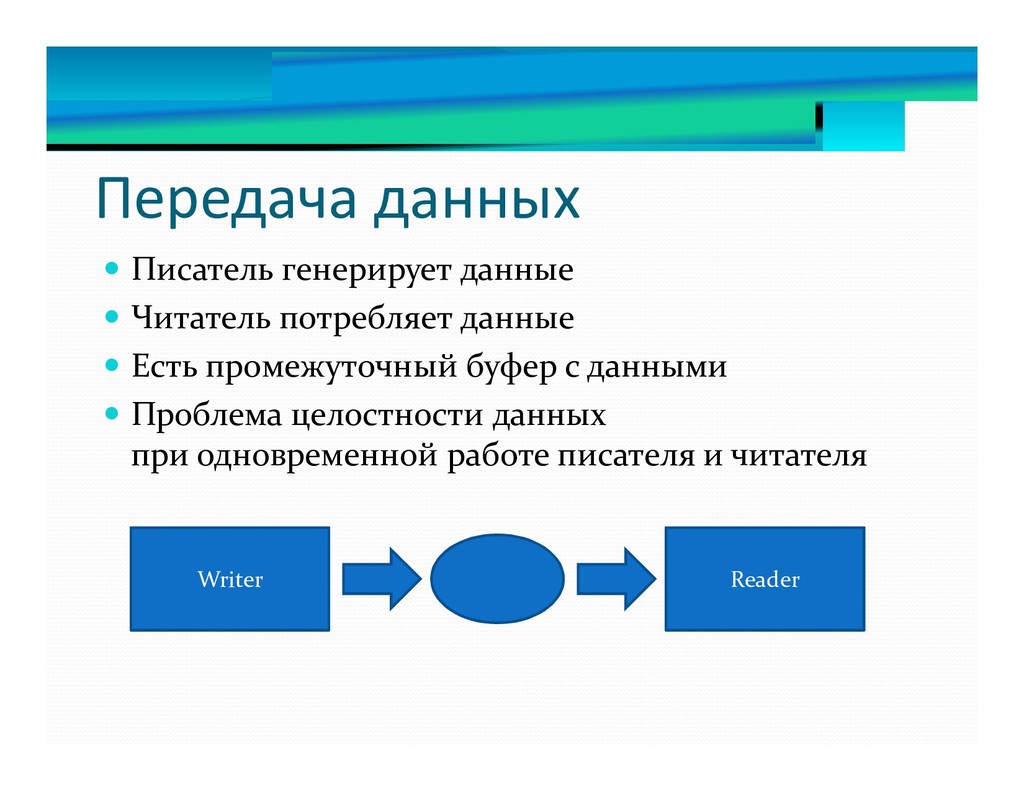
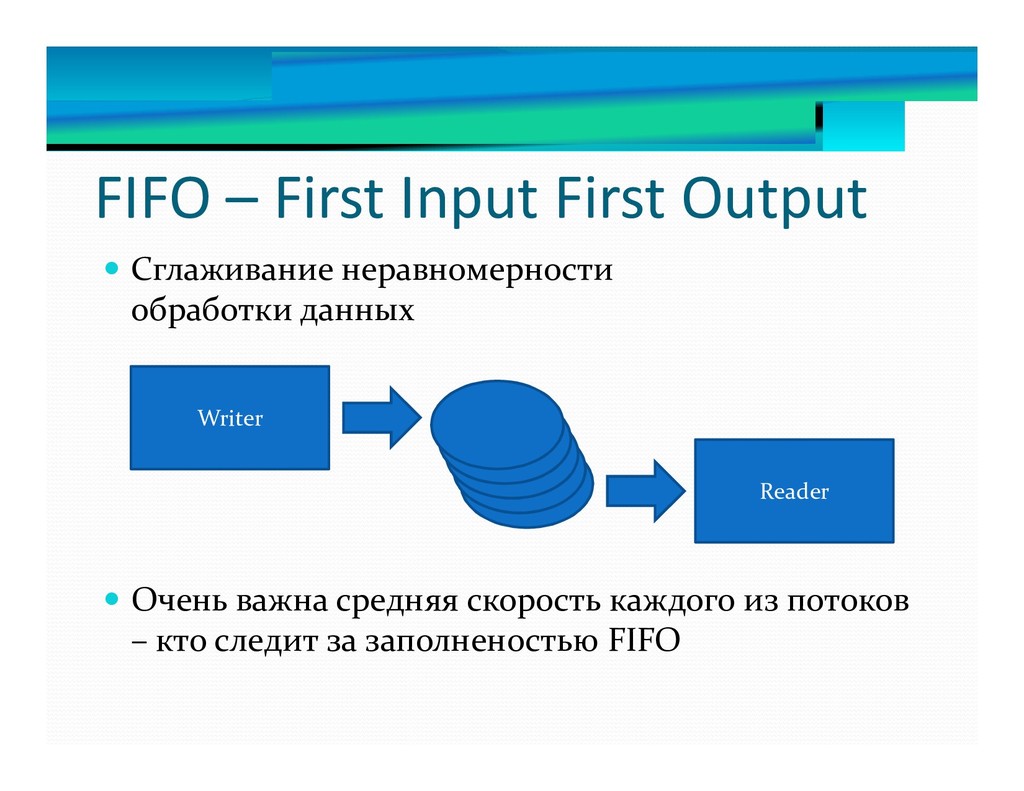
13. FIFO на списке блоков.
14. FIFO на кольцевом буфере.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
](https://files.speakerdeck.com/presentations/4cc6e6e1b3894cc0a09817cb4aabbe71/slide_16.jpg){kind=link}
](https://files.speakerdeck.com/presentations/4cc6e6e1b3894cc0a09817cb4aabbe71/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{](https://files.speakerdeck.com/presentations/4cc6e6e1b3894cc0a09817cb4aabbe71/slide_29.jpg){kind=link}
![std::async std::future<int> f = std::async( std::launch::async, [](){ return 8; }](https://files.speakerdeck.com/presentations/4cc6e6e1b3894cc0a09817cb4aabbe71/slide_30.jpg){kind=link}
![std::packed_task std::packaged_task<int()> task([](){ return 7; }); std::future<int> f = task.get_future();](https://files.speakerdeck.com/presentations/4cc6e6e1b3894cc0a09817cb4aabbe71/slide_31.jpg){kind=link}
{kind=link}
![Exception from std::future auto f = std::async( []() { throw](https://files.speakerdeck.com/presentations/4cc6e6e1b3894cc0a09817cb4aabbe71/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
![Flip-flop buffer MyData data[2]; volatile int nReadyIndex = 0; //](https://files.speakerdeck.com/presentations/4cc6e6e1b3894cc0a09817cb4aabbe71/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}