Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Scaling your data infrastructure
Search
barrachri
April 20, 2018
Technology
240
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Scaling your data infrastructure
Scaling your data infrastructure @ PyConNove
barrachri
April 20, 2018
More Decks by barrachri
See All by barrachri
Will Tech Save Us?
barrachri
0
120
How software can feed the World
barrachri
1
190
How to fight with yourself and win.
barrachri
0
350
Introduction to Statistics with Python
barrachri
0
460
EuroPython 2015 and the future
barrachri
2
130
Start with Flask
barrachri
3
200
Django & Docker
barrachri
6
1.1k
Other Decks in Technology
See All in Technology
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
1k
Kotlin 開発のツラミを爆破した話! / Explode the difficulty of Kotlin dev!
eller86
0
150
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
2k
ゼロをイチにする仕事が終わったあと
smasato
0
310
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
560
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
12
1.7k
NDIAS CTF 2026 問題解説会資料
bata_24
0
180
プライバシー保護の理論と実践
lycorptech_jp
PRO
1
250
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
2.4k
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
170
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
1
1.8k
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
0
1.3k
Featured
See All Featured
BBQ
matthewcrist
89
10k
Google's AI Overviews - The New Search
badams
0
1.1k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
How GitHub (no longer) Works
holman
316
150k
Odyssey Design
rkendrick25
PRO
2
730
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
300
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
240
Transcript
Scaling your data infrastructure C H R I S T
I A N B A R R A @ P Y C O N N O V E
THE AGENDA 2 3 START THE DATA SCIENCE WORKFLOW SCALING
IS NOT JUST A MATTER OF MACHINE WHEN THE SIZE OF YOUR DATA MATTERS 1
THE AGENDA 4 5 CONTAINERIZED DATA SCIENCE CASSINY: PUT ALL
THE THINGS TOGETHER END
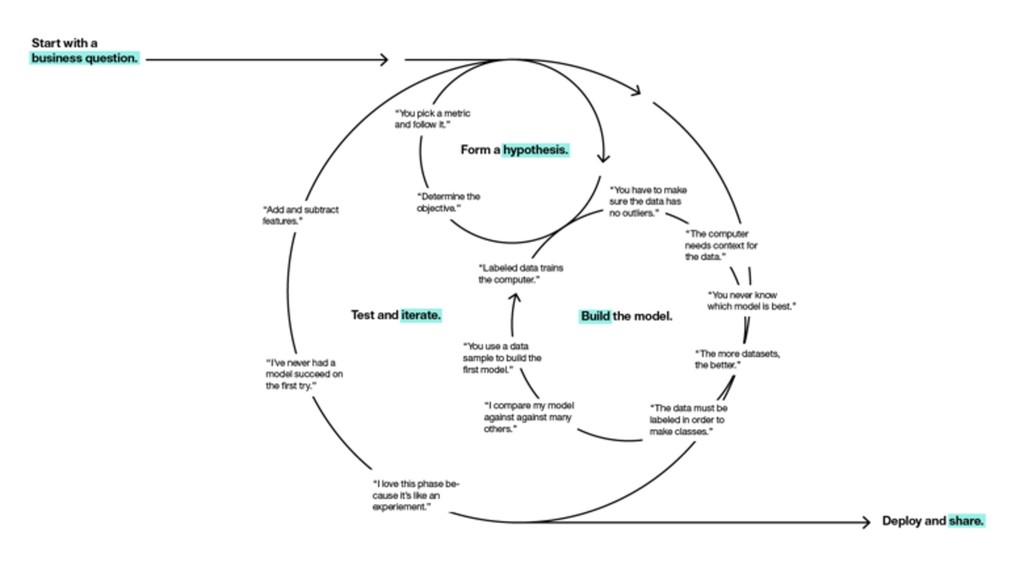
THE DATA SCIENCE WORKFLOW
HEXAGON PRESENTATION TEMPLATE
HOW YOU BUILD, ITERATE AND SHARE DEPENDS ON MANY THINGS
Your Users Your Product Your Team Your Company Your Tech Stack Your Domain
SCIKIT-LEARN DOCKER DATA SCIENCE TOOLBELT PANDAS JUPYTER RAY
SCALING IS NOT JUST A MATTER OF MACHINES
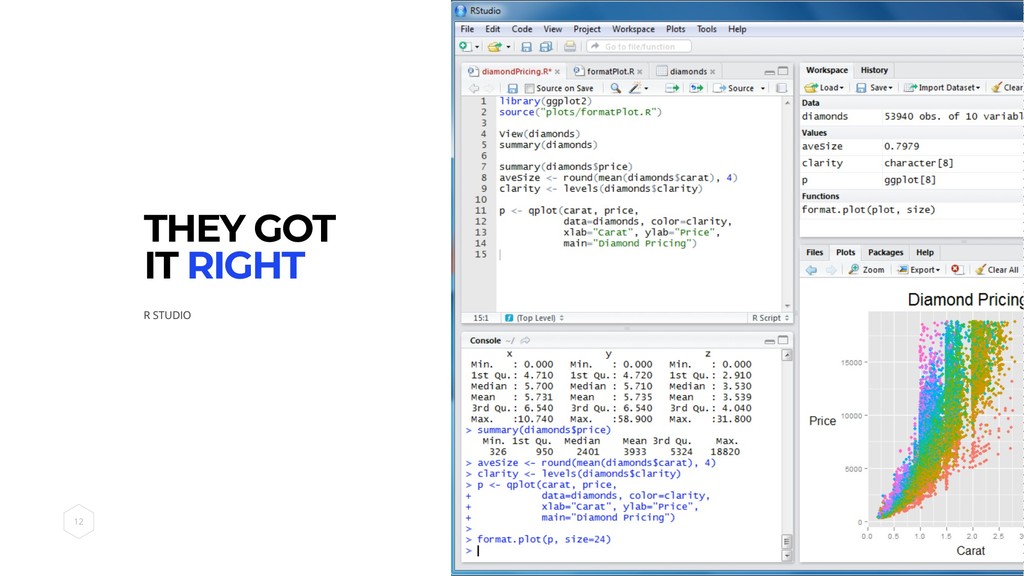
We all use it.
We really care about versioning. We have Untitled_1.ipynb, Untitled_2.ipynb and
Untitled_3.ipynb. HOMER SIMPSON C H I E F D A T A S C I E N T I S T D A T A B E E R I N C
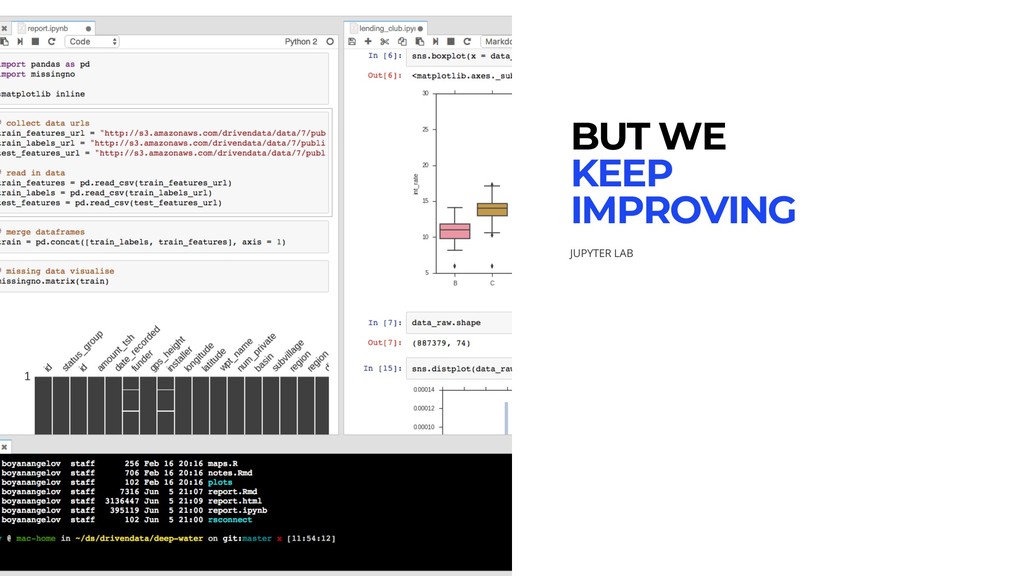
Since JSON is a plain text format, they can be
version-controlled and shared with colleagues. E X I P Y T H O N N O T E B O O K D O C U M E N T A T I O N
THEY GOT IT RIGHT
BUT WE KEEP IMPROVING
90% OF JUPITER IS MADE BY HYDROGEN
THE HARD THING ABOUT STORAGE
PARQUET P A R Q U E T + O
B J E C T S T O R A G E = YO U C A N Q U E R Y I T U S I N G S Q L PA N DA S H A S N AT I V E S U P P O R T F O R G E T A B O U T C S V
WHEN THE SIZE OF YOUR DATA MATTERS
IT’S TOO SLOW DOESN’T FIT IN YOUR RAM
CODE OPTIMIZATION APPROACH SCALING FROM DIFFERENT SIDES A BIGGER MACHINE
USE MULTIPLE CORES MORE MACHINES FRAMEWORKS: DASK RAY SPARK PANDAS: READ BY CHUNKS SCIKIT-LEARN: PARTIAL FIT
chunks & partial_fit 1 M A C H I N
E
Multiple machines. n M A C H I N E
S
I don’t want to use Spark/JVM, what do you have
for me? H A P P Y P Y T H O N U S E R
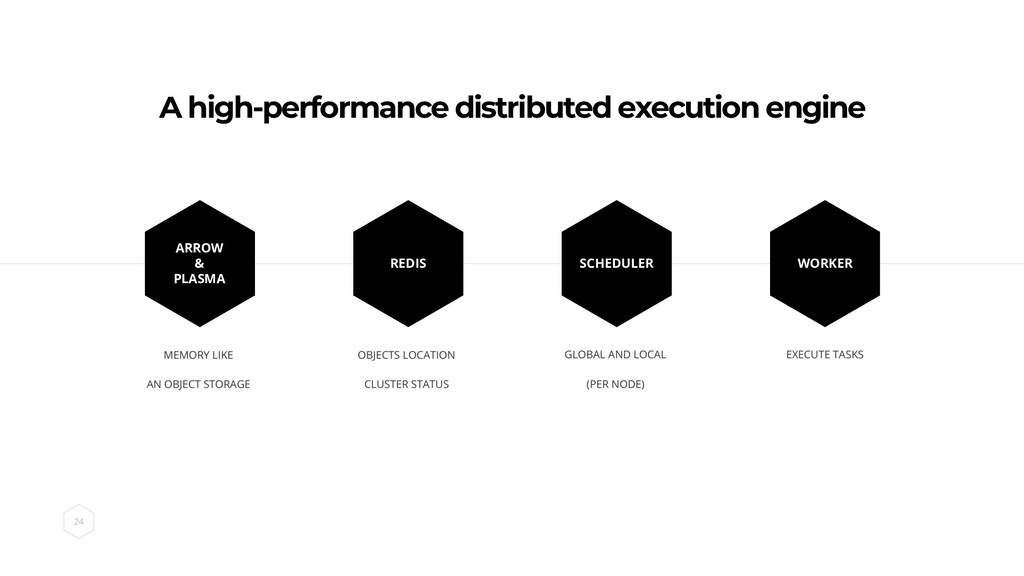
WHAT IS RAY?
A high-performance distributed execution engine REDIS SCHEDULER WORKER ARROW &
PLASMA
Use pandas through ray to query parquet files in an
object storage. W O R K I N P R O G R E S S
CONTAINERIZED DATA SCIENCE
If you trained a model with scikit-learn 0.18.1, will the
same model work with 0.19.1? P R O B L E M # 1
How do you share your models? P R O B
L E M # 2
How do you put your models in production? P R
O B L E M # 3
Containerize everything. T H E A N S W E
R
1. It’s damn easy to move things around 2. You
get versioning for free 3. Stack agnostic 4. Move Docker images around T O R E C A P
CASSINY: PUT ALL THE THINGS TOGETHER
CLEAR REQUIREMENTS CONTAINERIZED EASY OBJECT STORAGE JUPYTER + IPYTHON PLATFORM
AGNOSTIC
OPEN SOURCE
DEMO
TAKEAWAYS UNIFIED DATA WAREHOUSE KEEP YOUR CODE RUNNING ON ONE
MACHINE USE DOCKER TRY RAY BRING CI/CD TO YOUR DATASCIENCE WORKFLOW OBJECT STORAGE IS COOL DISTRIBUTED COMPUTING IS HARD I DIDN’T HAVE ANOTHER POINT
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}