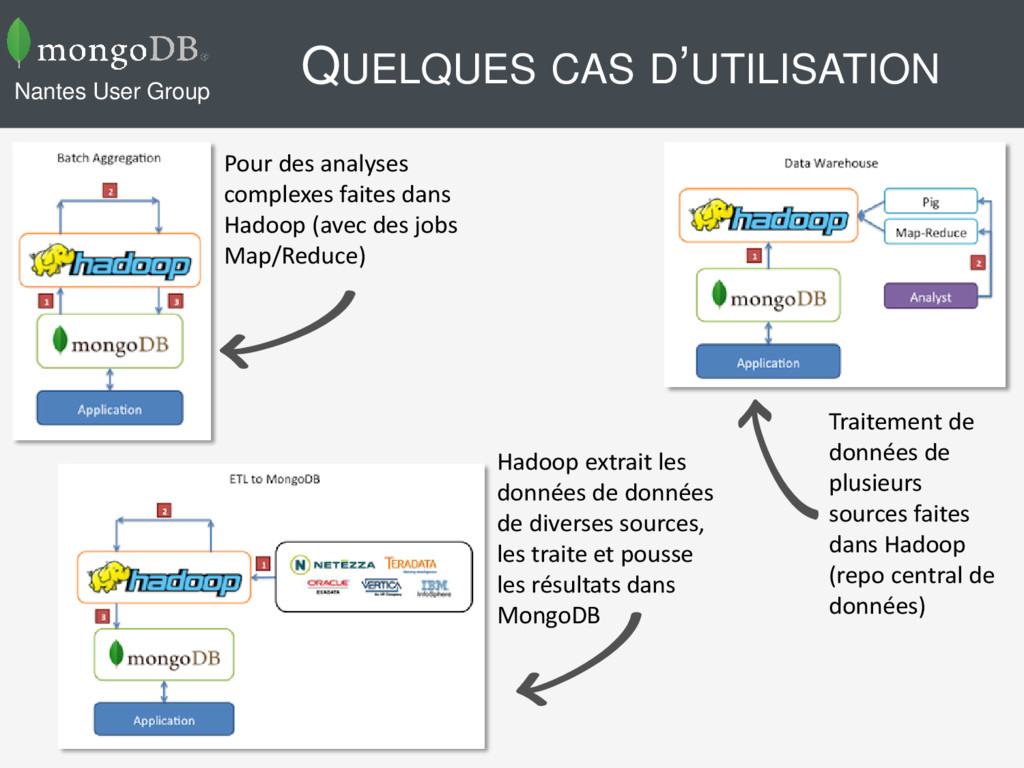
Les entreprises ont des données stockées dans MongoDB, … et dans Hadoop • Besoin d’intégration • Traiter les données à partir de plusieurs sources (en éliminant des étapes d’import/export) • … Nantes User Group
faites dans Hadoop (avec des jobs Map/Reduce) Traitement de données de plusieurs sources faites dans Hadoop (repo central de données) Hadoop extrait les données de données de diverses sources, les traite et pousse les résultats dans MongoDB
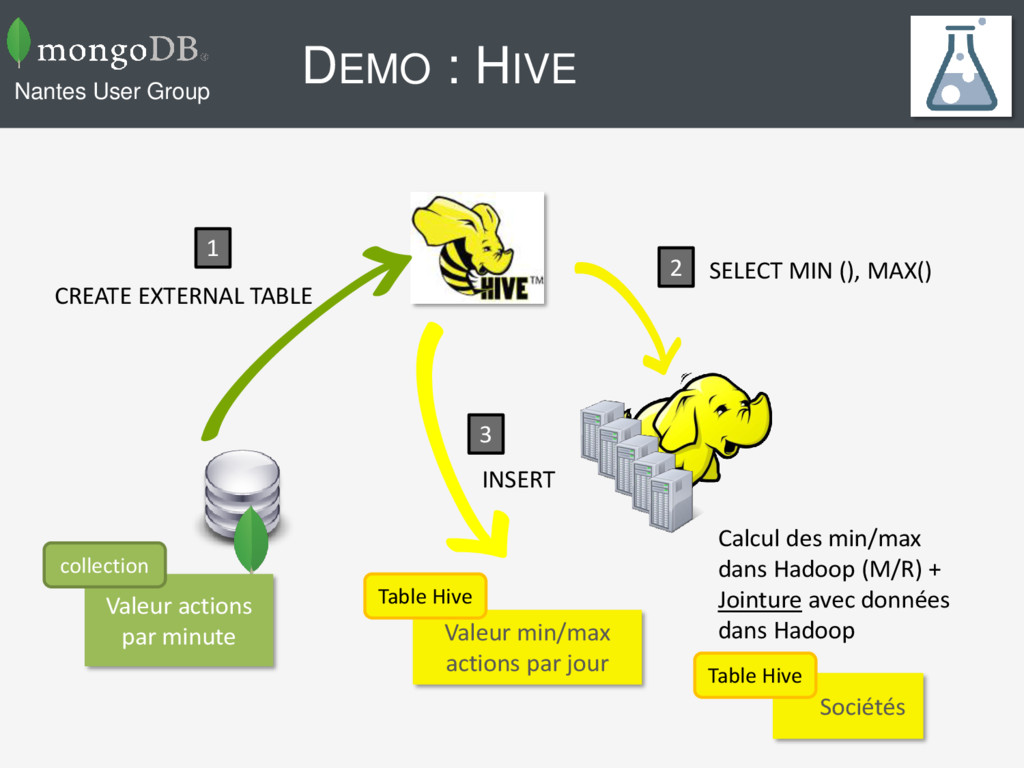
Calcul des min/max dans Hadoop (M/R) + Jointure avec données dans Hadoop 1 3 2 Sociétés Valeur min/max actions par jour CREATE EXTERNAL TABLE SELECT MIN (), MAX() INSERT collection Table Hive Table Hive
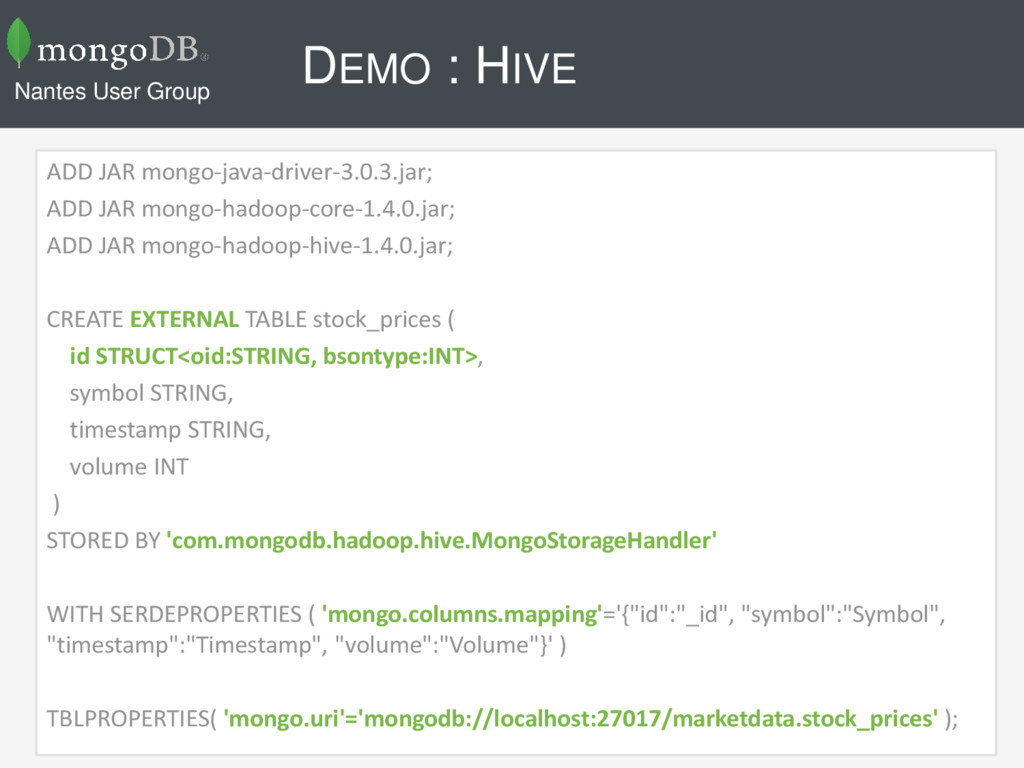
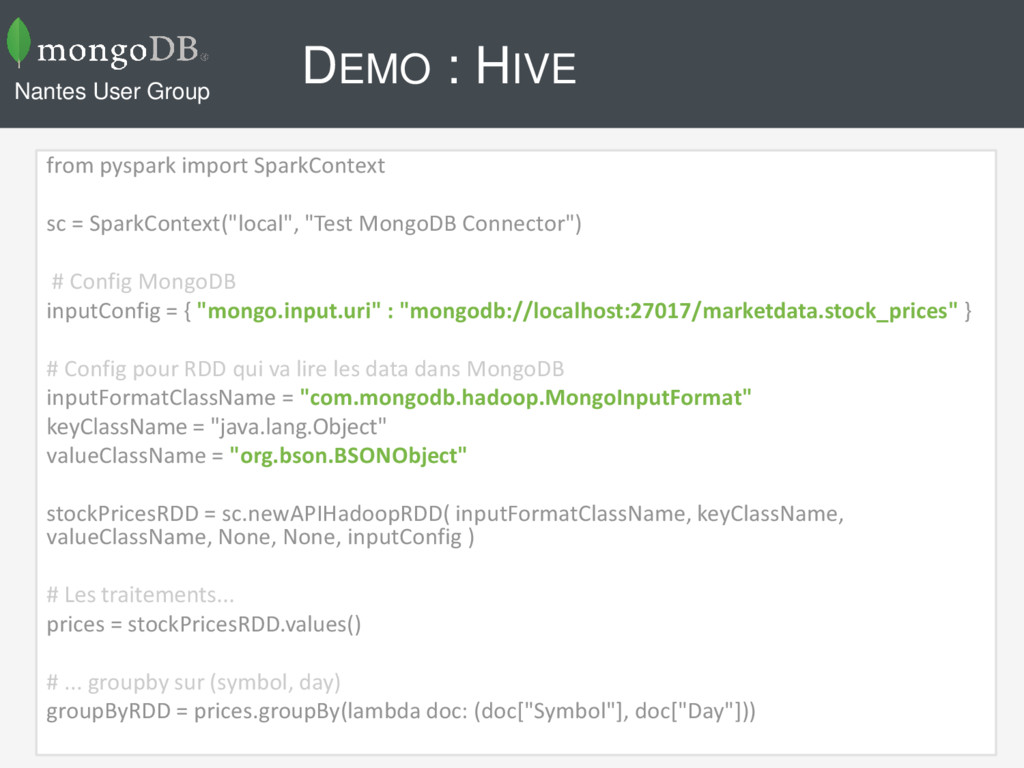
JAR mongo-hadoop-hive-1.4.0.jar; CREATE EXTERNAL TABLE stock_prices ( id STRUCT<oid:STRING, bsontype:INT>, symbol STRING, timestamp STRING, volume INT ) STORED BY 'com.mongodb.hadoop.hive.MongoStorageHandler' WITH SERDEPROPERTIES ( 'mongo.columns.mapping'='{"id":"_id", "symbol":"Symbol", "timestamp":"Timestamp", "volume":"Volume"}' ) TBLPROPERTIES( 'mongo.uri'='mongodb://localhost:27017/marketdata.stock_prices' ); Nantes User Group
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}