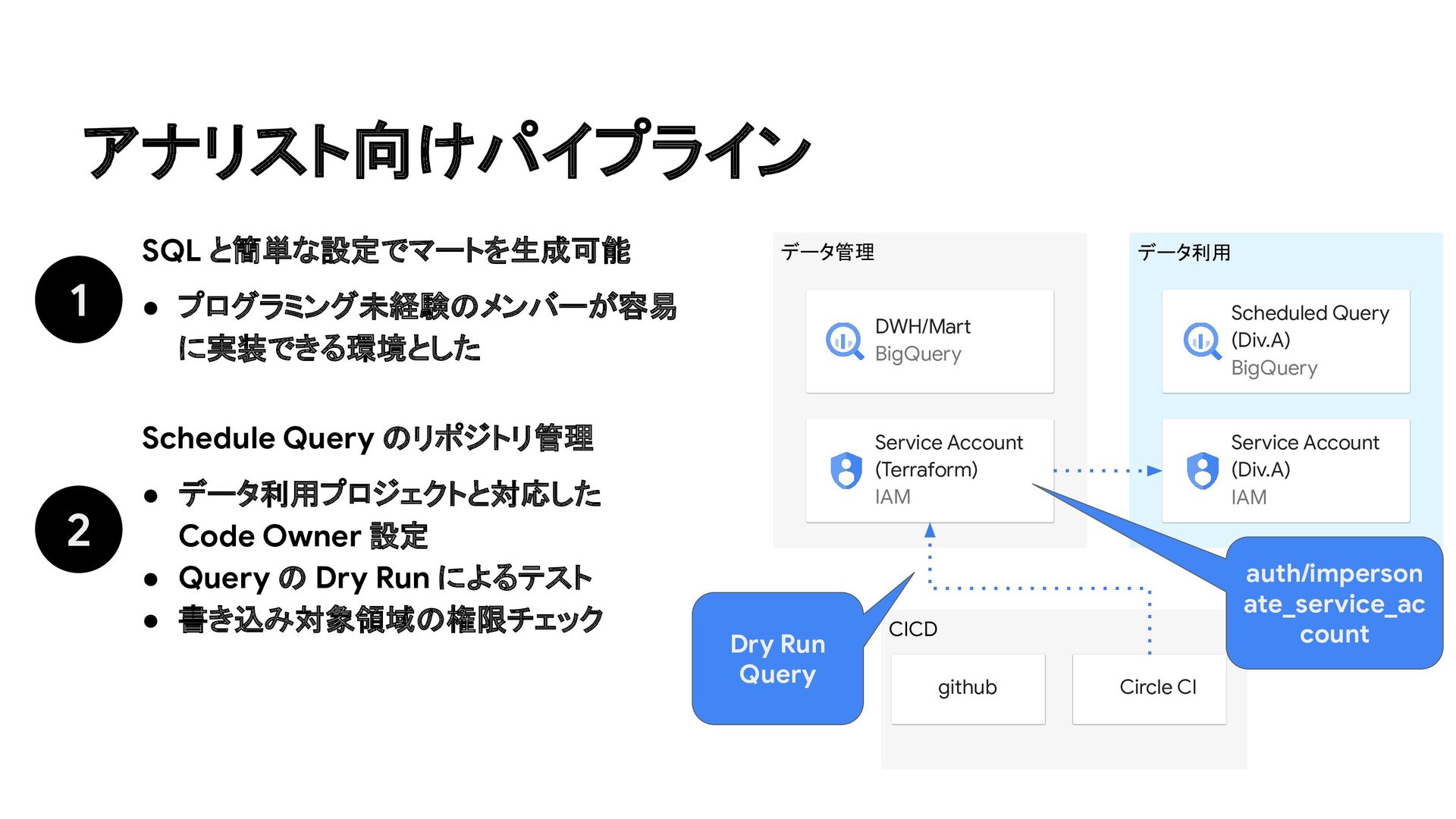
設定 • Query の Dry Run によるテスト • 書き込み対象領域の権限チェック DWH/Mart BigQuery データ利用 CICD github Circle CI Service Account (Terraform) IAM auth/imperson ate_service_ac count Dry Run Query 1 SQL と簡単な設定でマートを生成可能 • プログラミング未経験のメンバーが容易 に実装できる環境とした Scheduled Query (Div.A) BigQuery Service Account (Div.A) IAM
するテストを組み込み • CI に使う Service Account を増やしたくなかったため、各データ利用プロジェクトのScheduled Query 実行 Service Account に impersonate • 変更対象クエリのパスから Service Account を判定できるように、プロジェクトに紐づく IAMの命名整 備と IaC による管理を徹底 Point レビューとテスト
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}