Apresentação realizada por Silas Tailer no Big Data Week São Paulo 2018 [http://sao-paulo.bigdataweek.com].
O Hadoop e seu Ecossistema estão em constante evolução desde 2007, e agora ele encontra-se disponível para o público em geral ou através de vendors em sua terceira versão. Venha entender quais são as principais modificações nessa plataforma que vem revolucionando o mundo de TI nos últimos anos.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
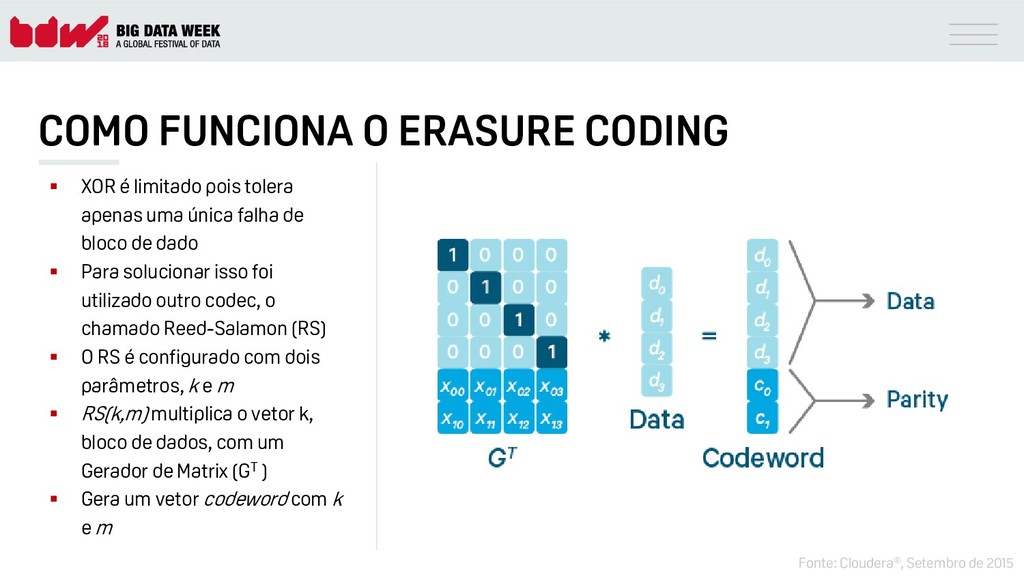{kind=link}
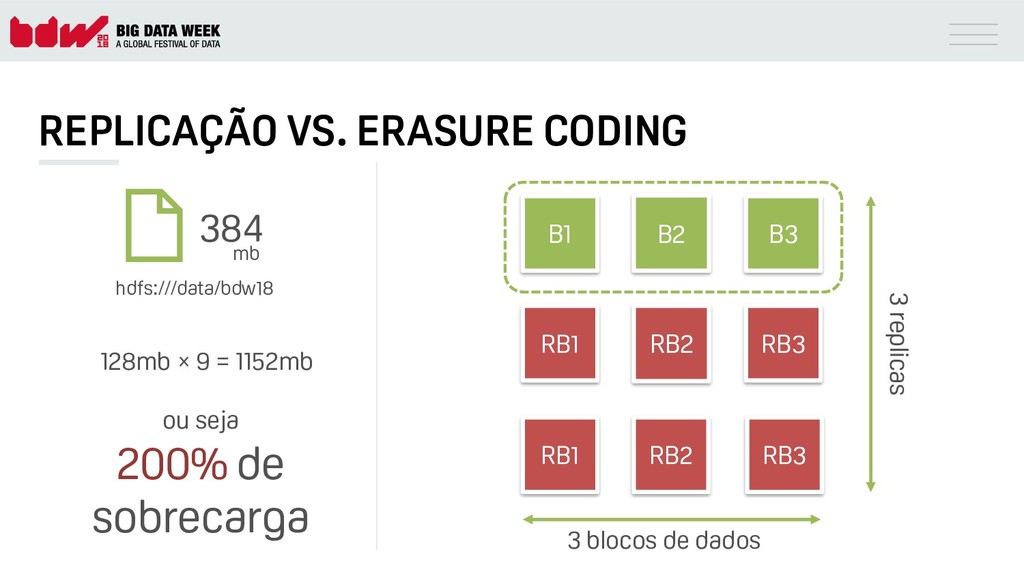{kind=link}
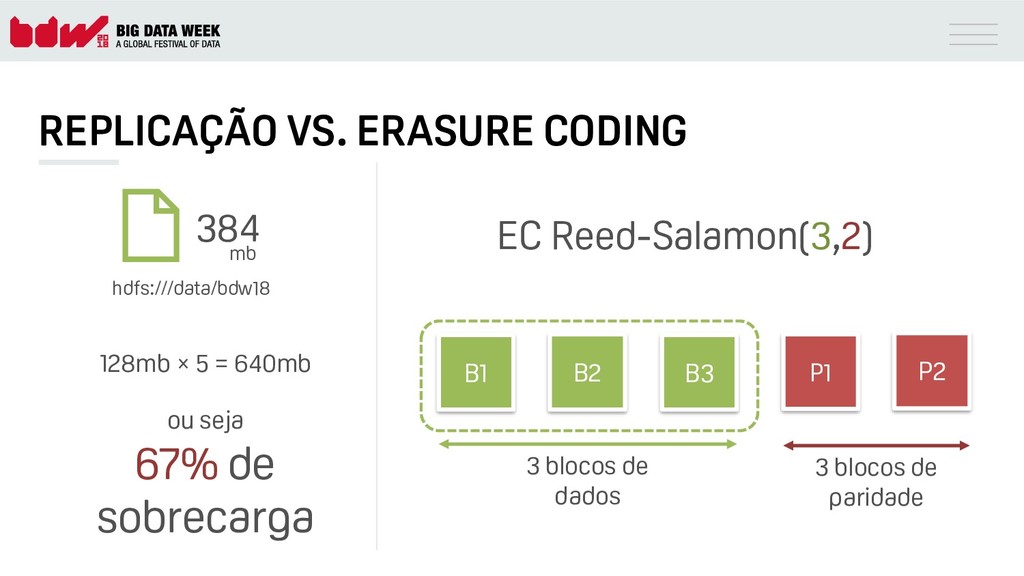{kind=link}
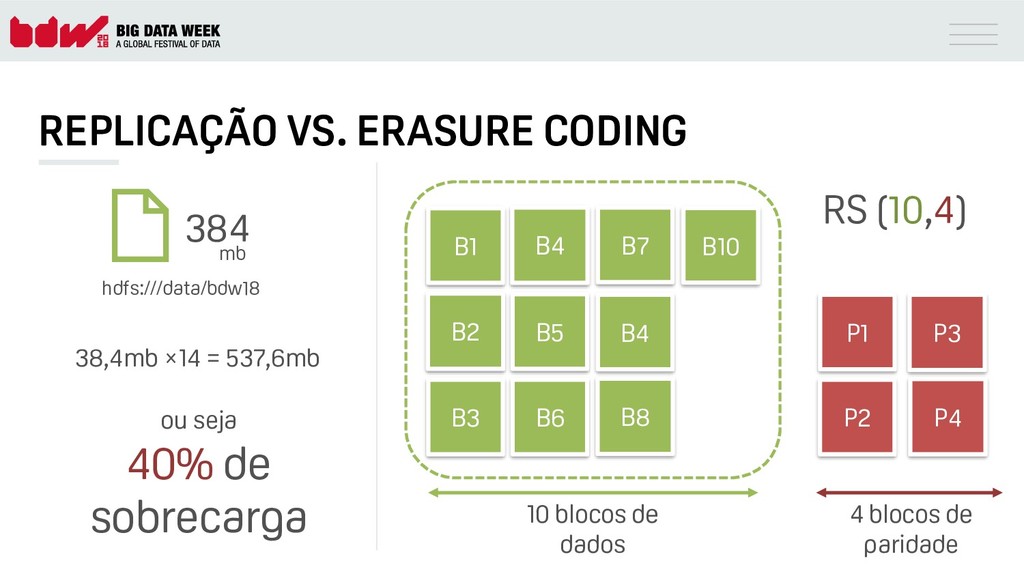{kind=link}
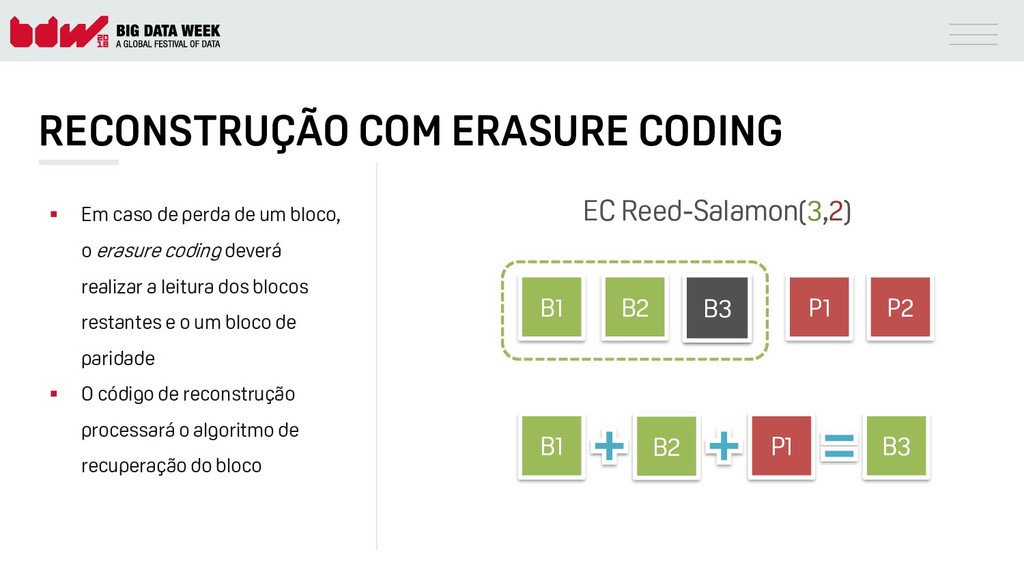{kind=link}
{kind=link}
{kind=link}
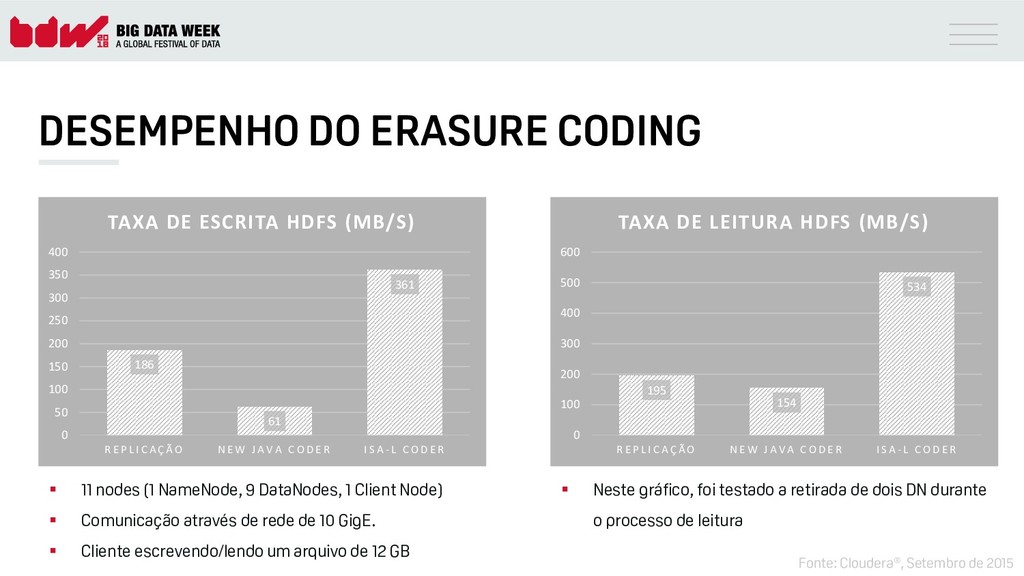{kind=link}
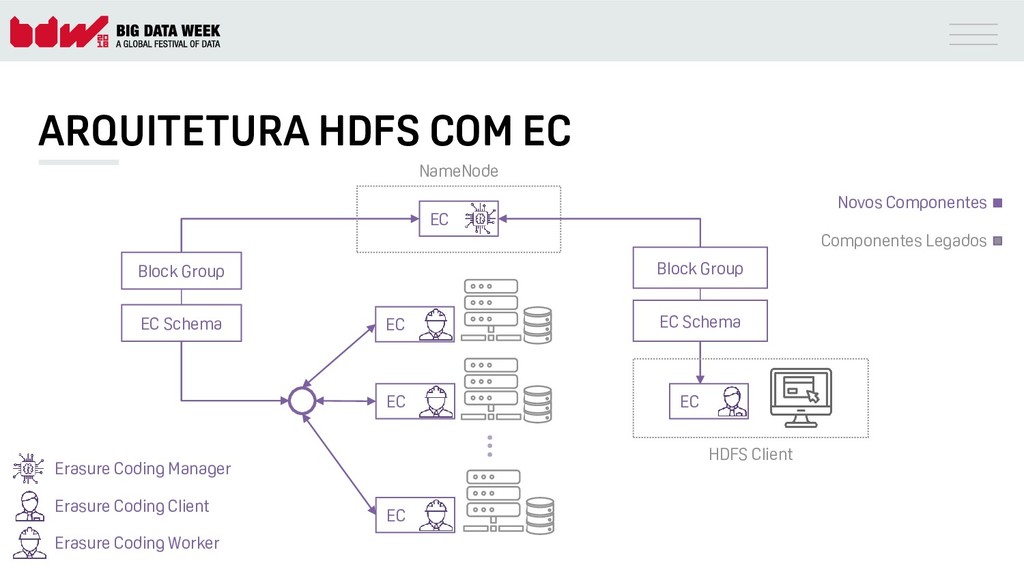{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
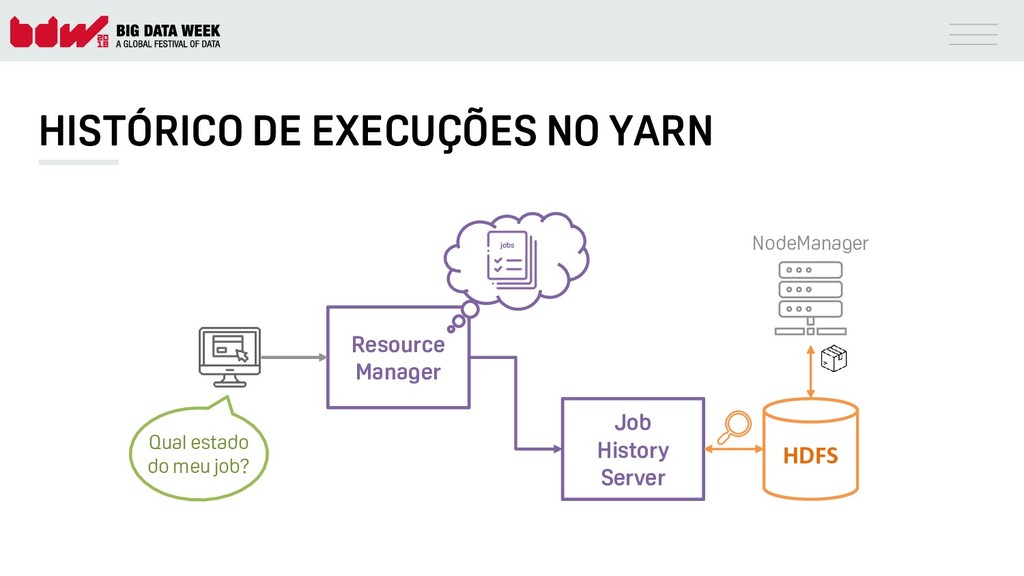{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
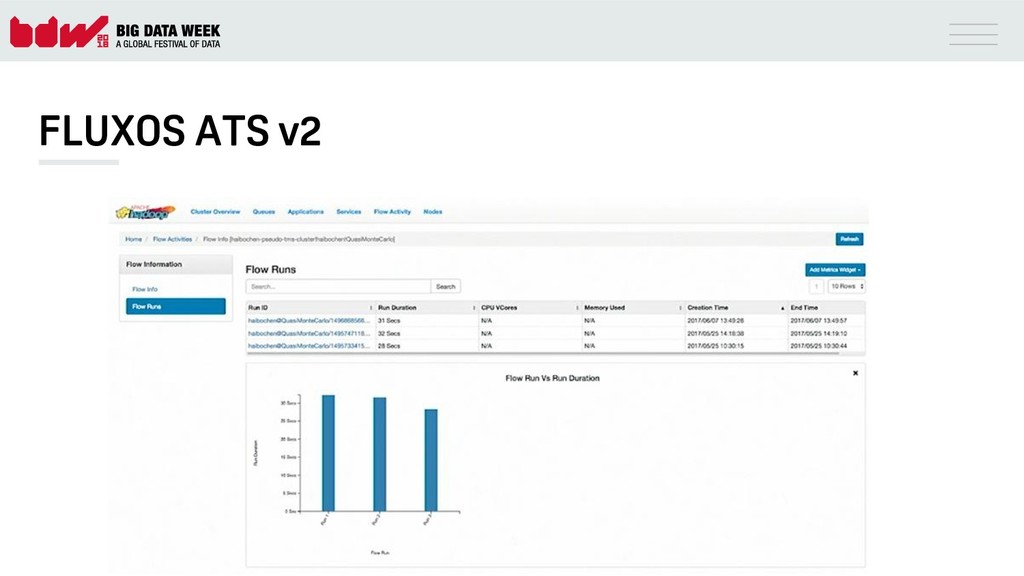{kind=link}
{kind=link}
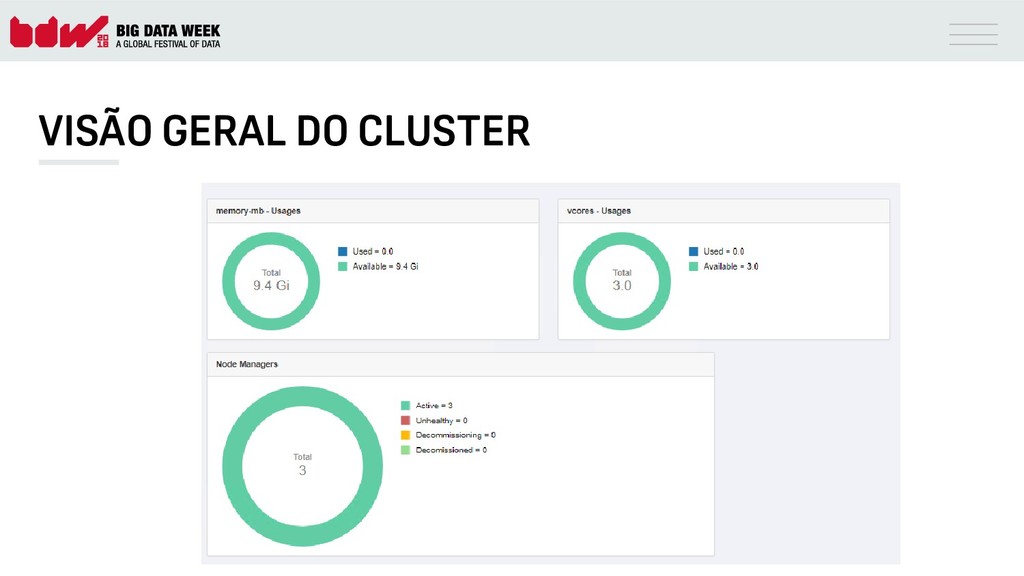{kind=link}
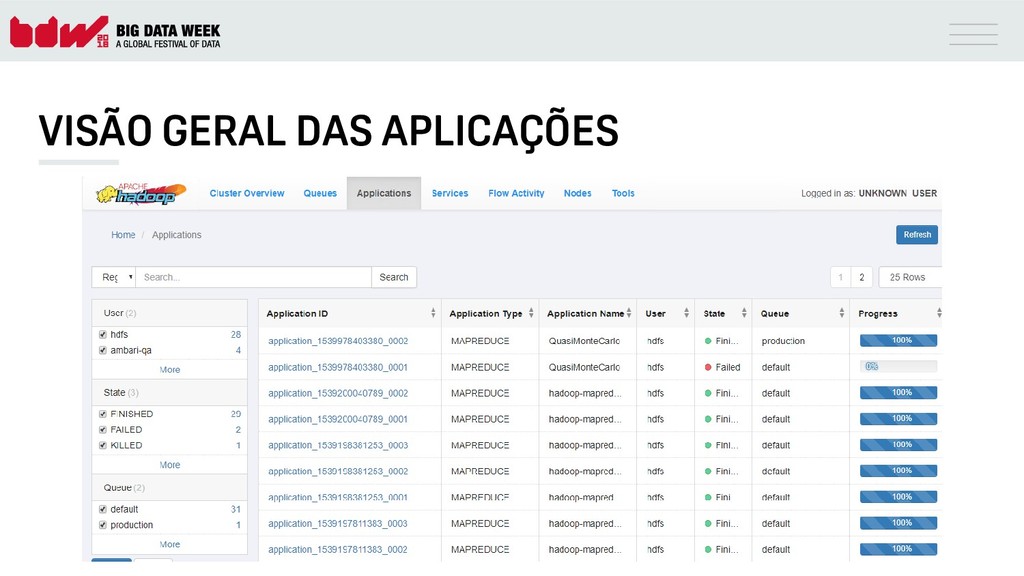{kind=link}
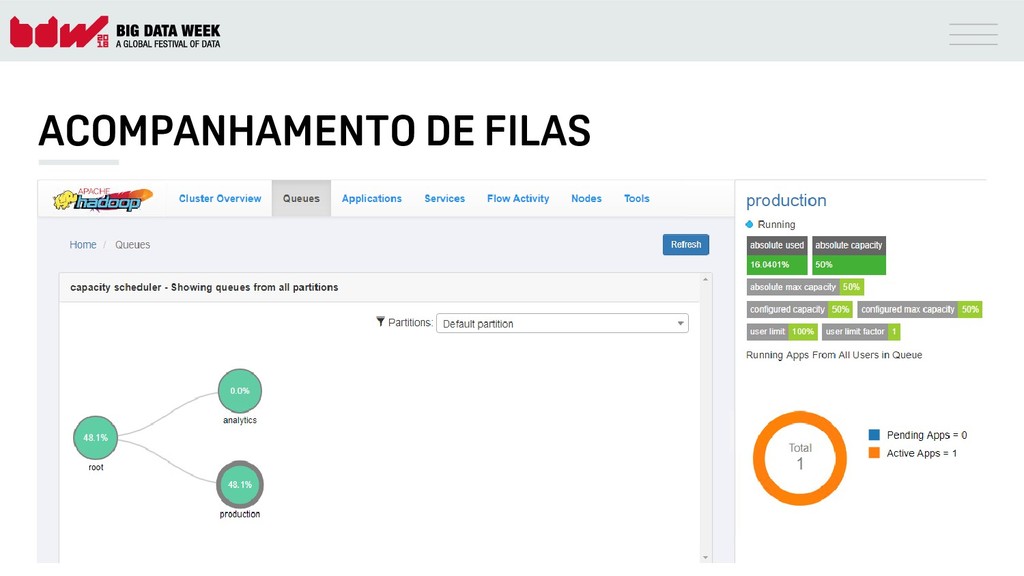{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}