Apresentação de Claudio Takamya e Alan Silva no Big Data Week São Paulo 2017 [http://sao-paulo.bigdataweek.com].
Um dos grandes desafios quando desenvolvemos um sistema de Workload Analítico em Tempo Real é trabalhar com dados que mudam de forma rápida em um intervalo de tempo muito baixo.
A proposta dessa apresentação é justamente demonstrar como o Apache Kudu pode facilitar a utilização desse tipo de caso de uso e ao final realizar uma demonstração na prática de uma solução que contempla essa questão.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
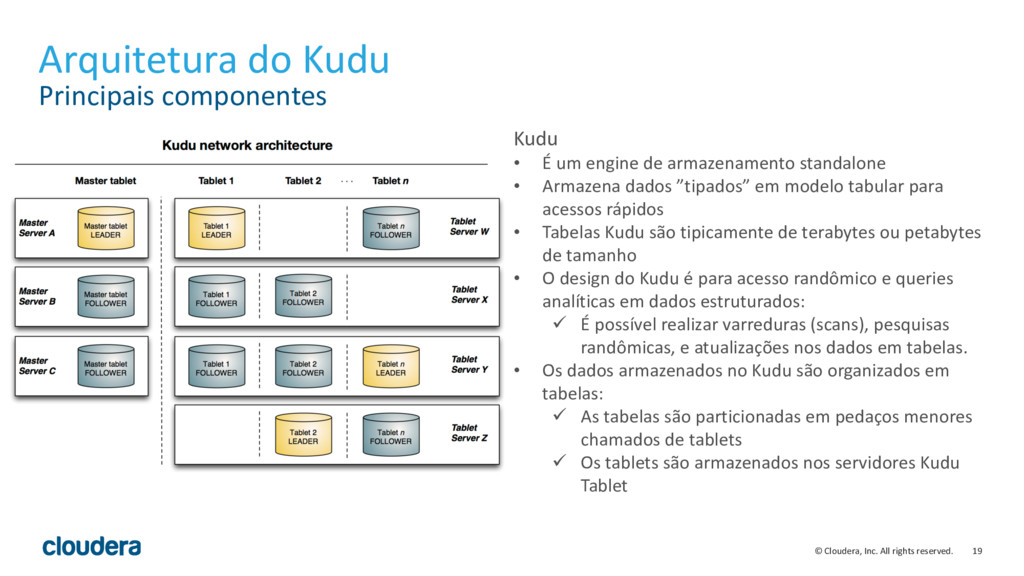{kind=link}
{kind=link}
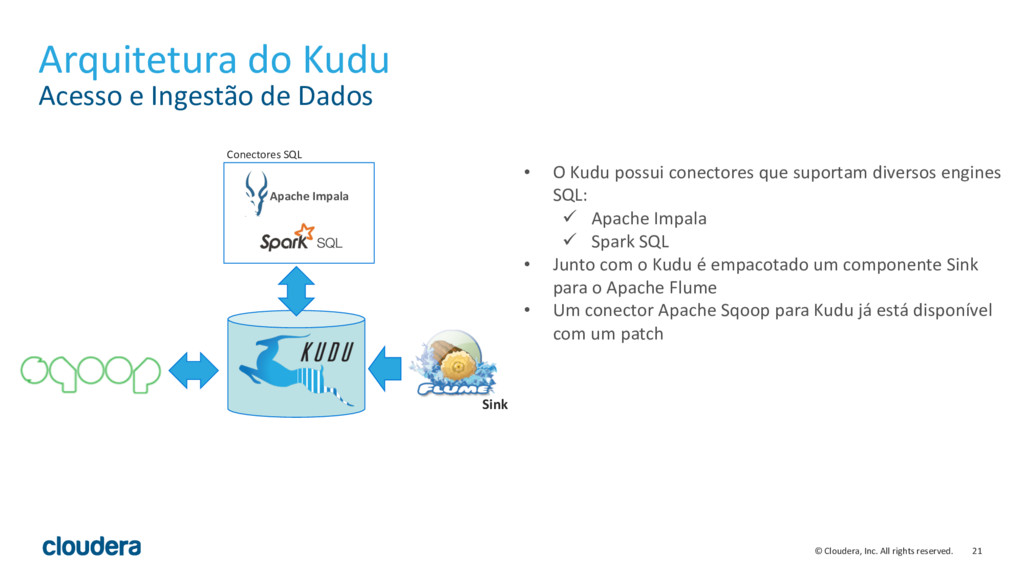{kind=link}
{kind=link}
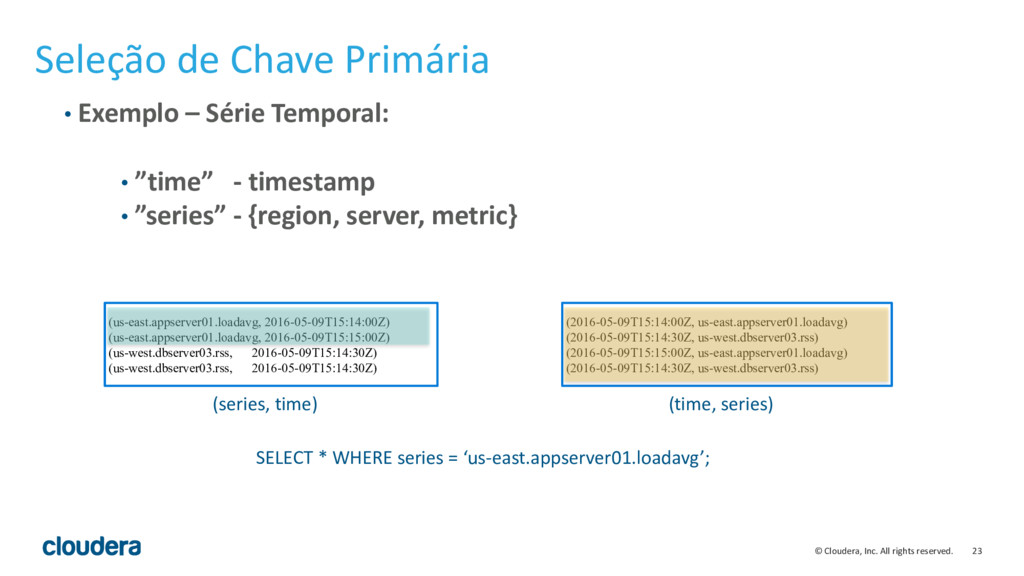{kind=link}
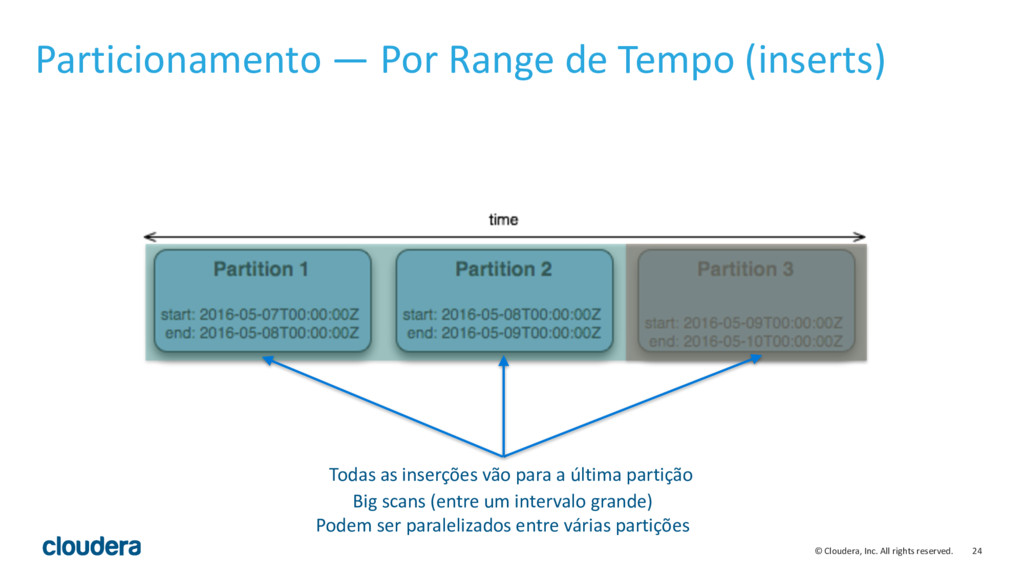{kind=link}
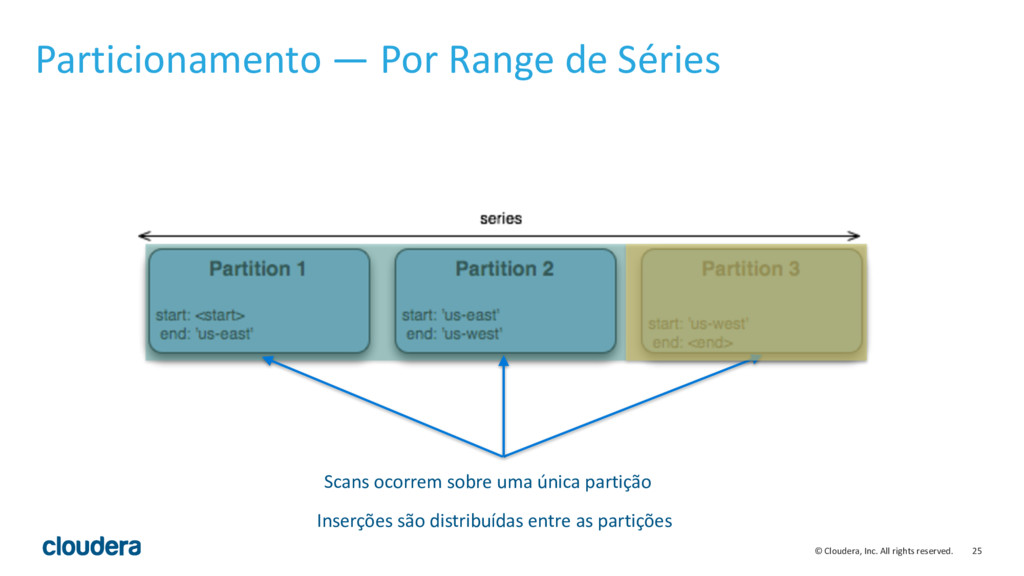{kind=link}
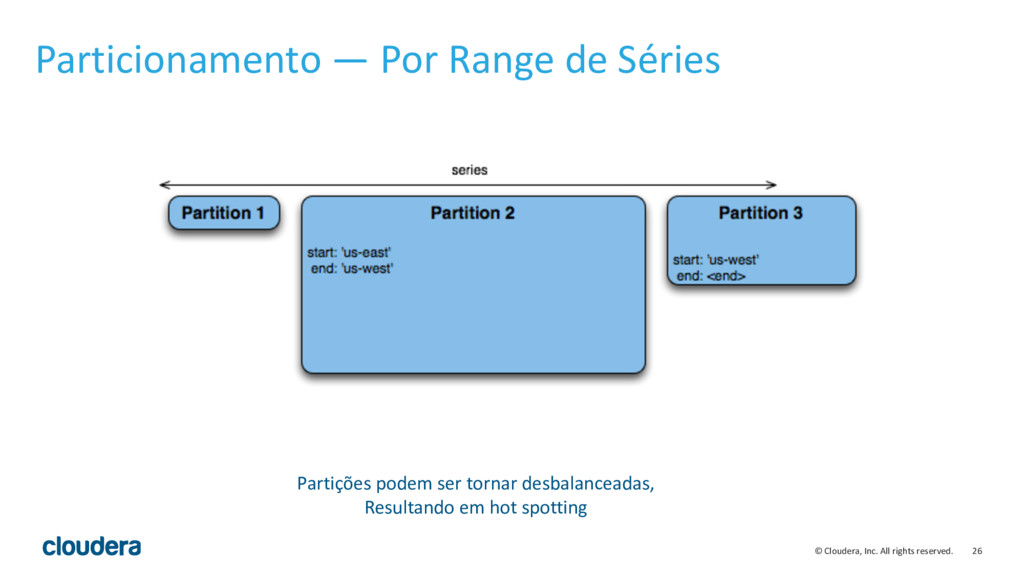{kind=link}
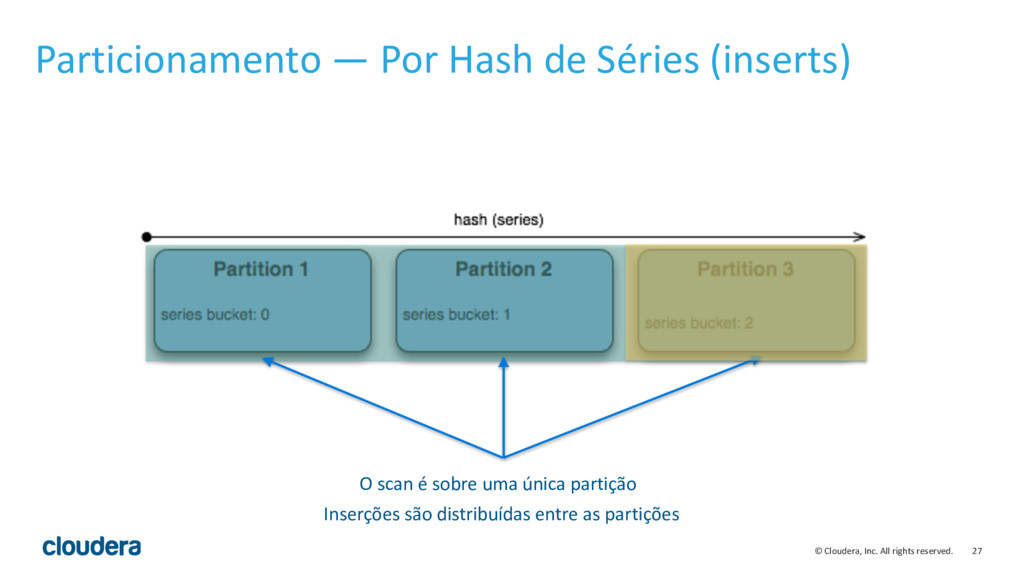{kind=link}
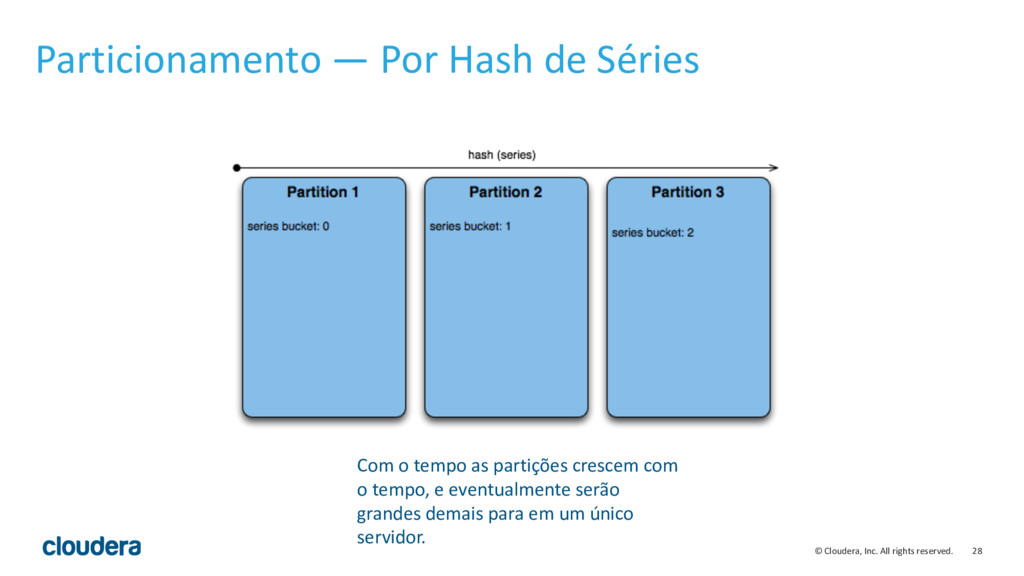{kind=link}
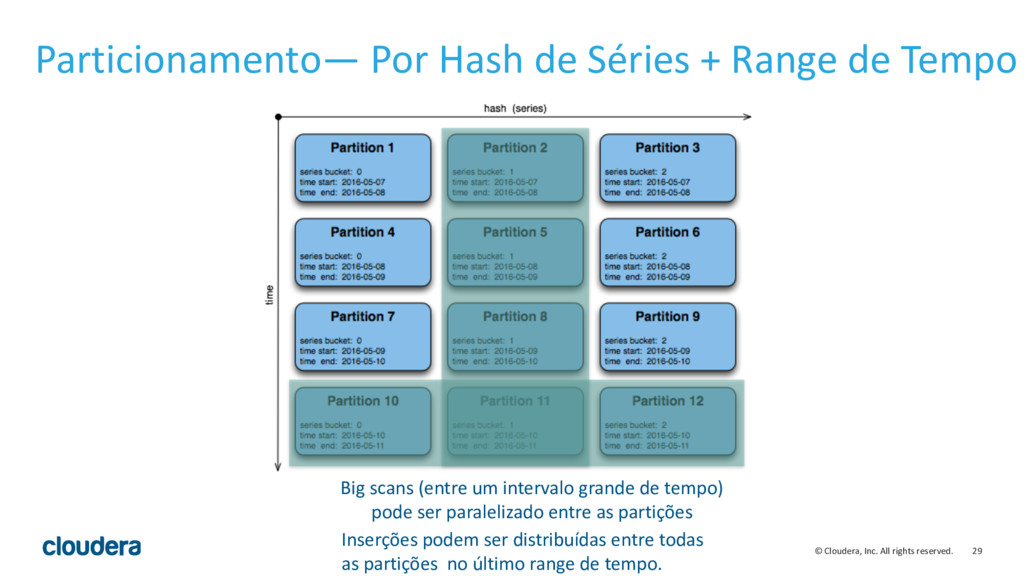{kind=link}
{kind=link}
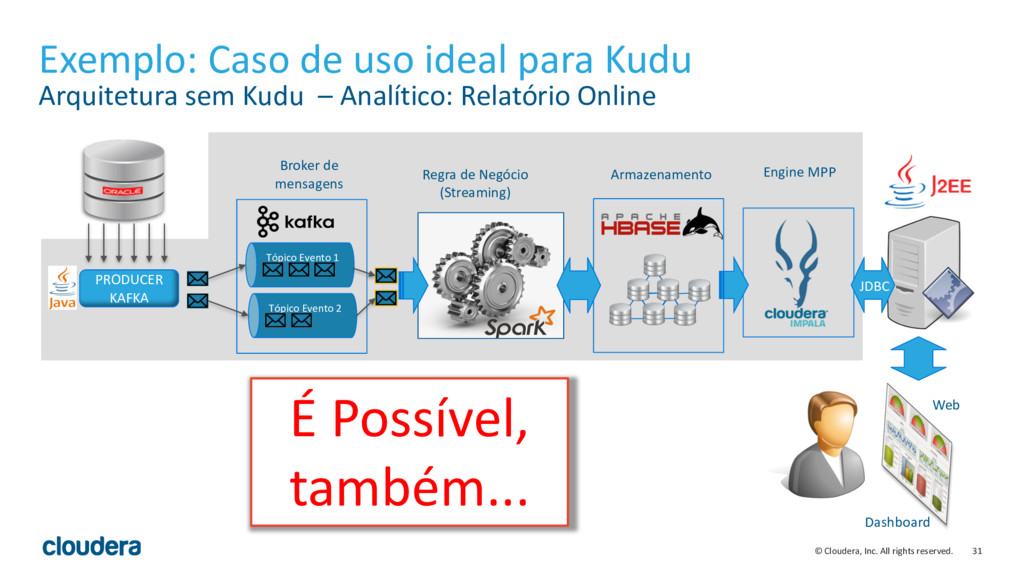{kind=link}
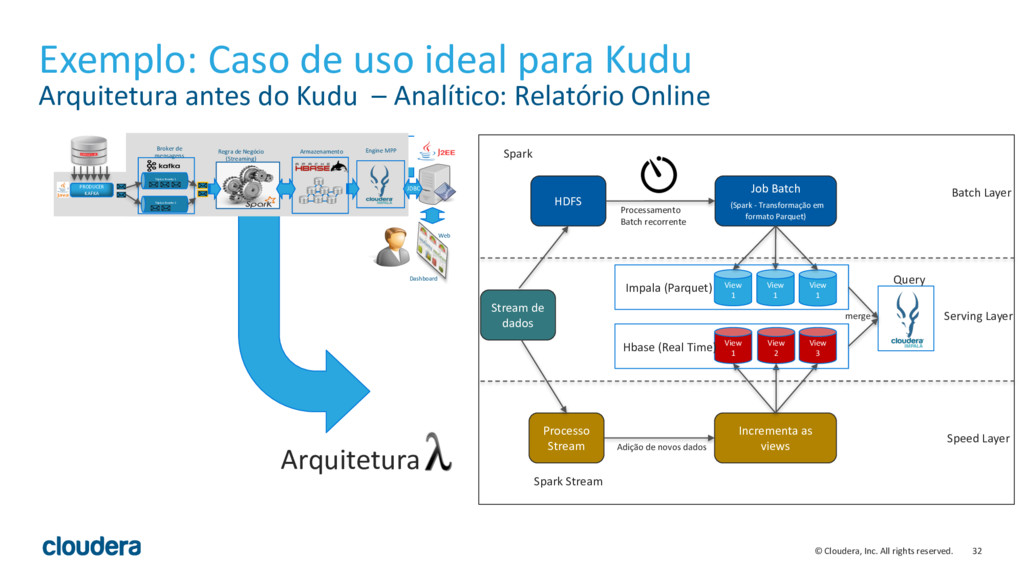{kind=link}
{kind=link}
{kind=link}
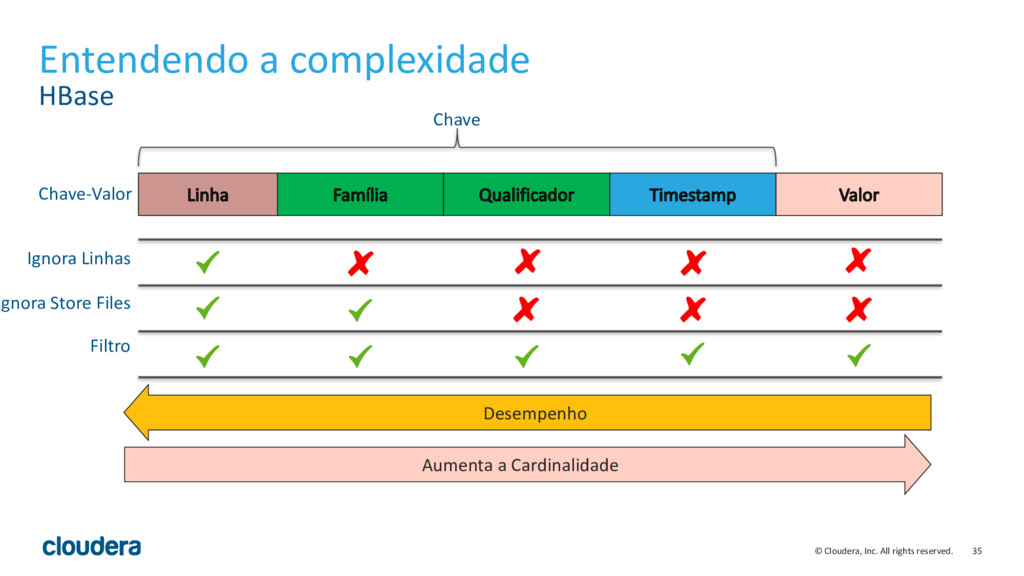{kind=link}
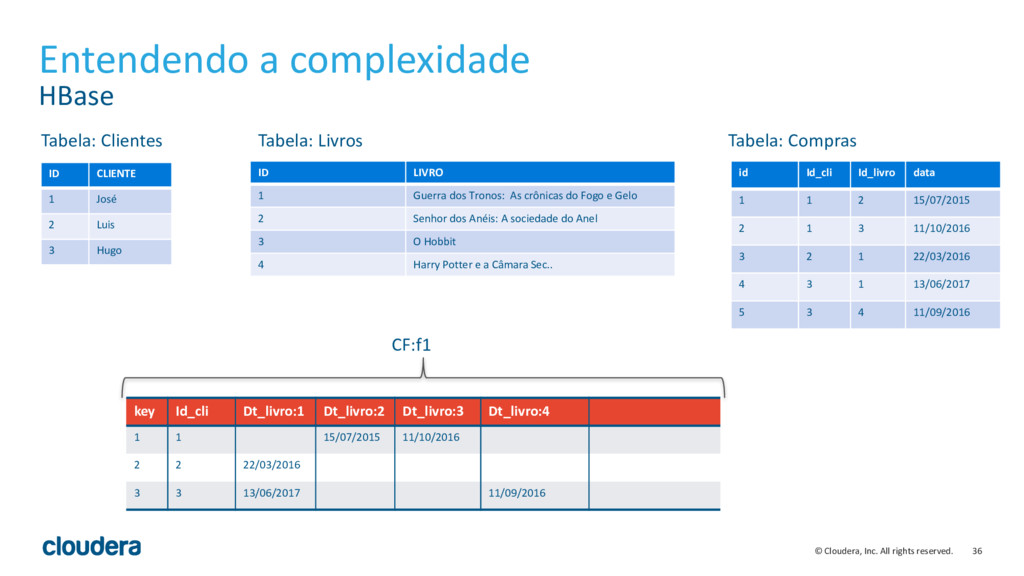{kind=link}
{kind=link}
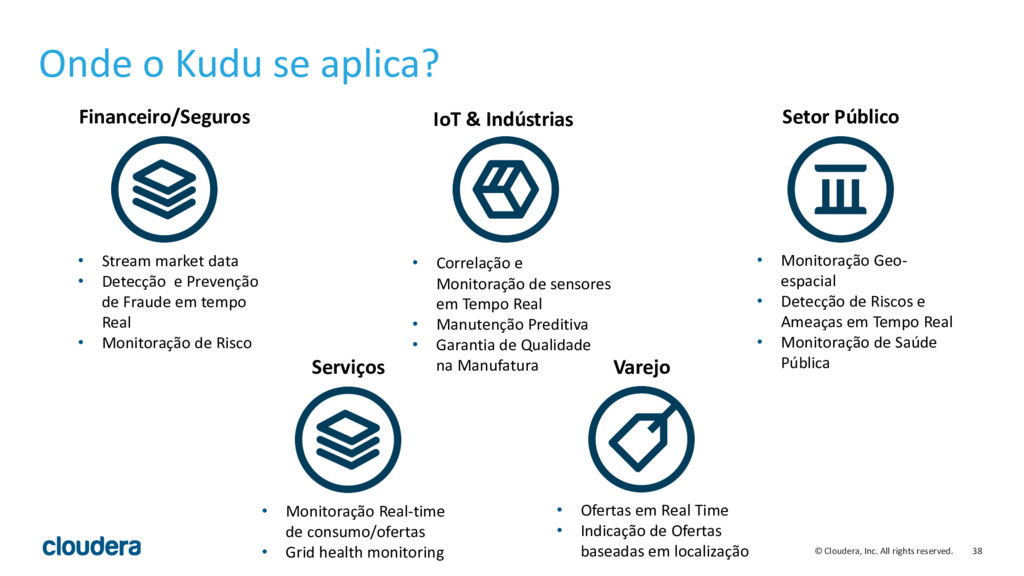{kind=link}
{kind=link}
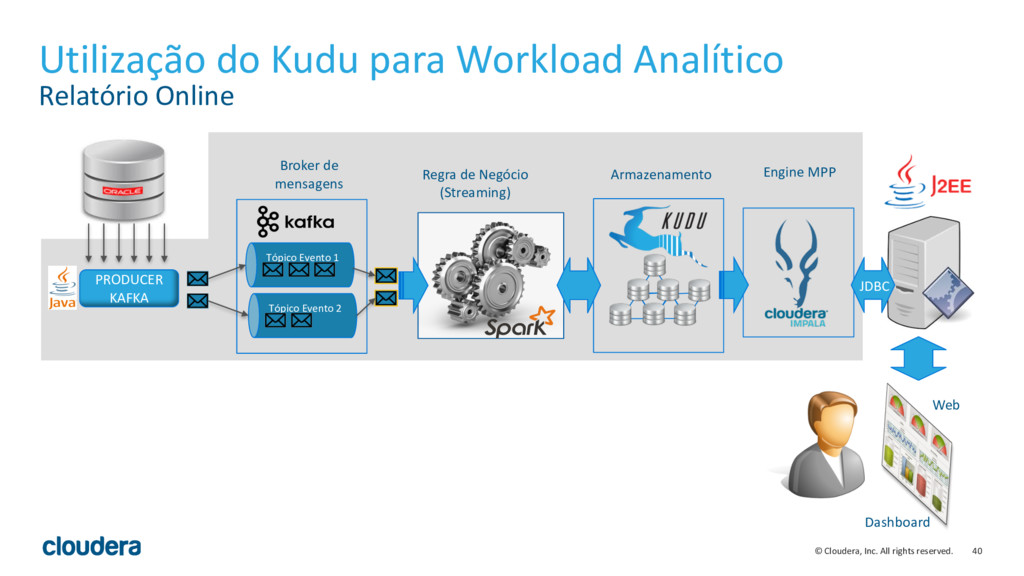{kind=link}
{kind=link}
{kind=link}