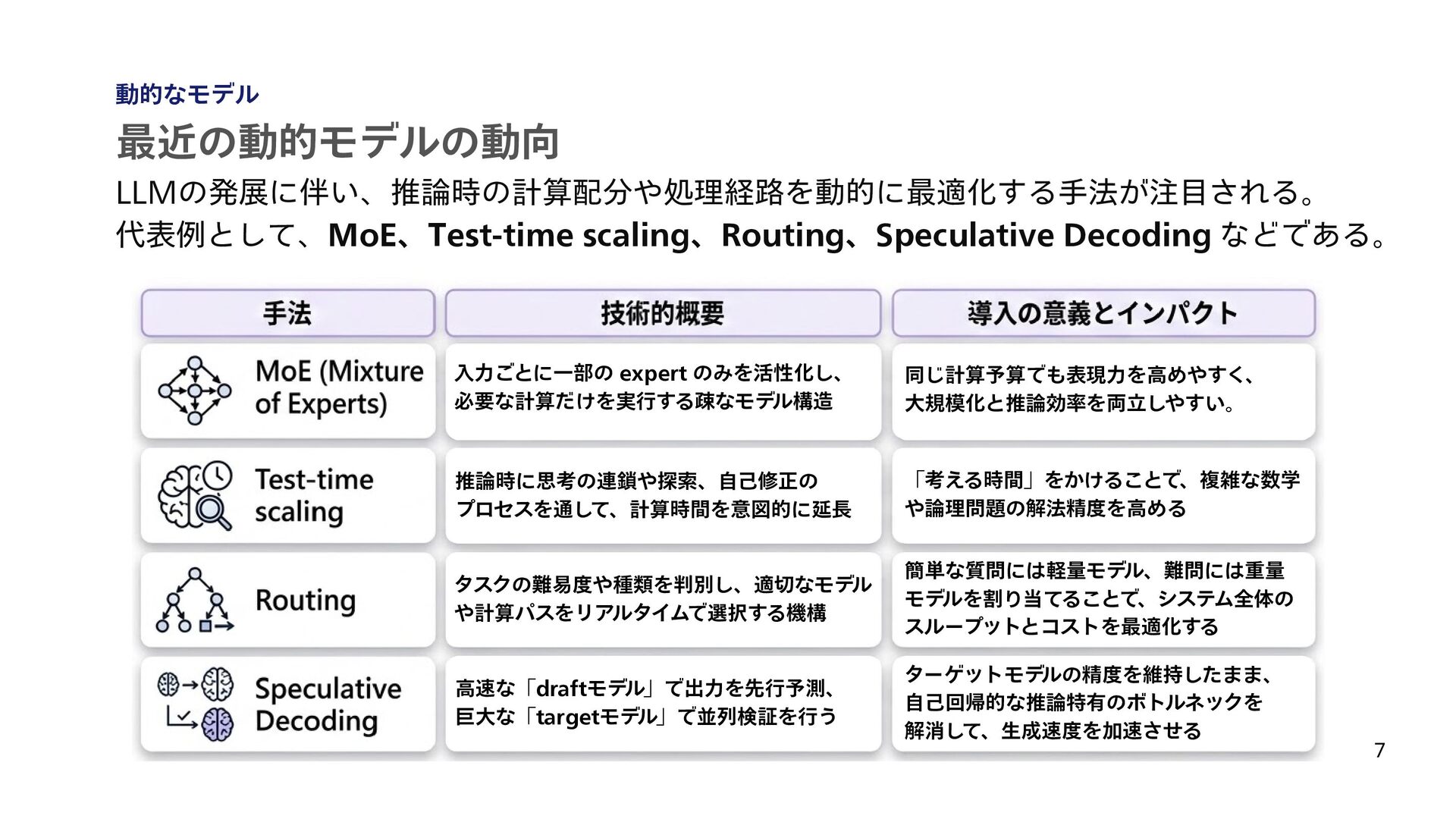
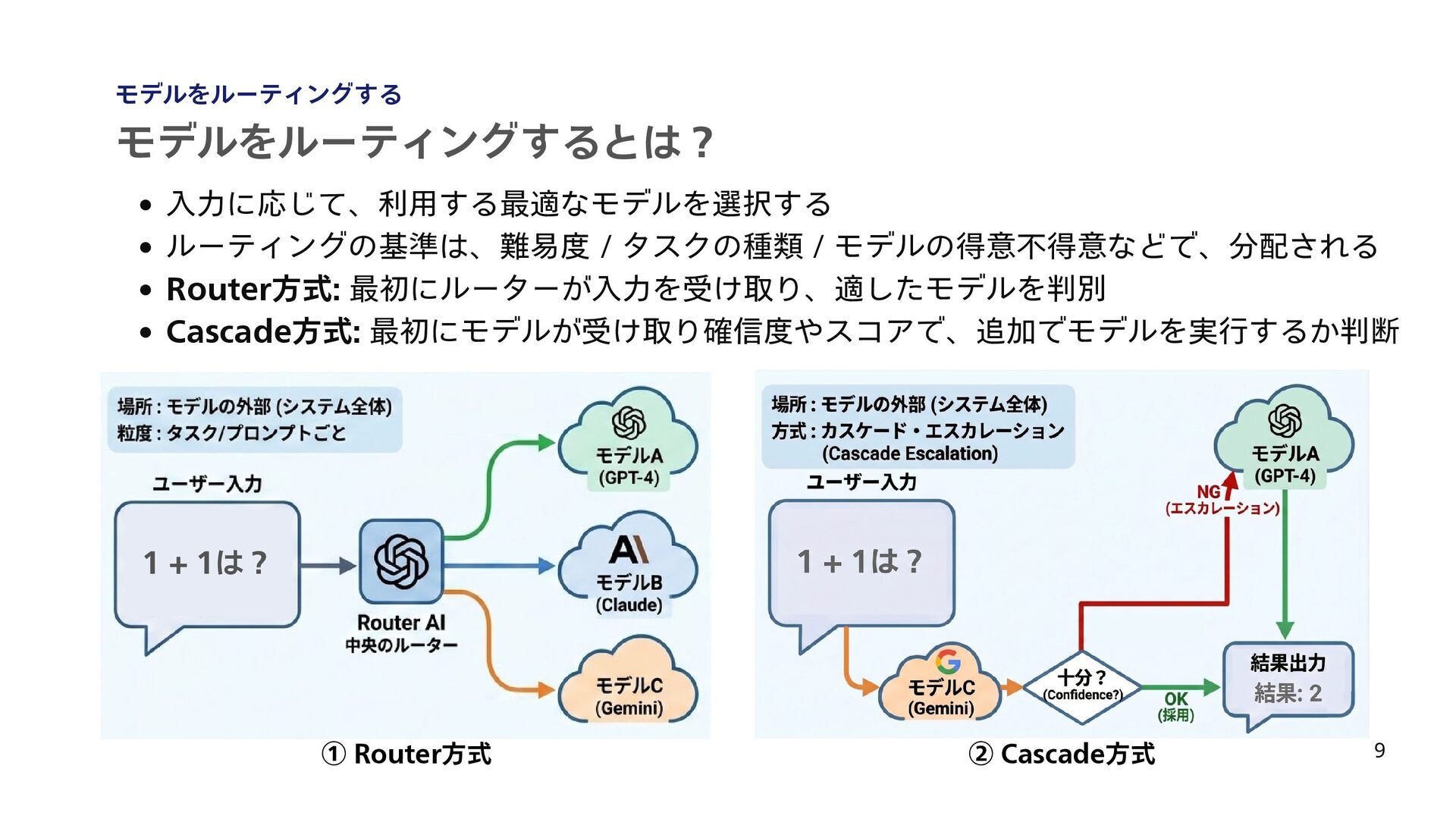
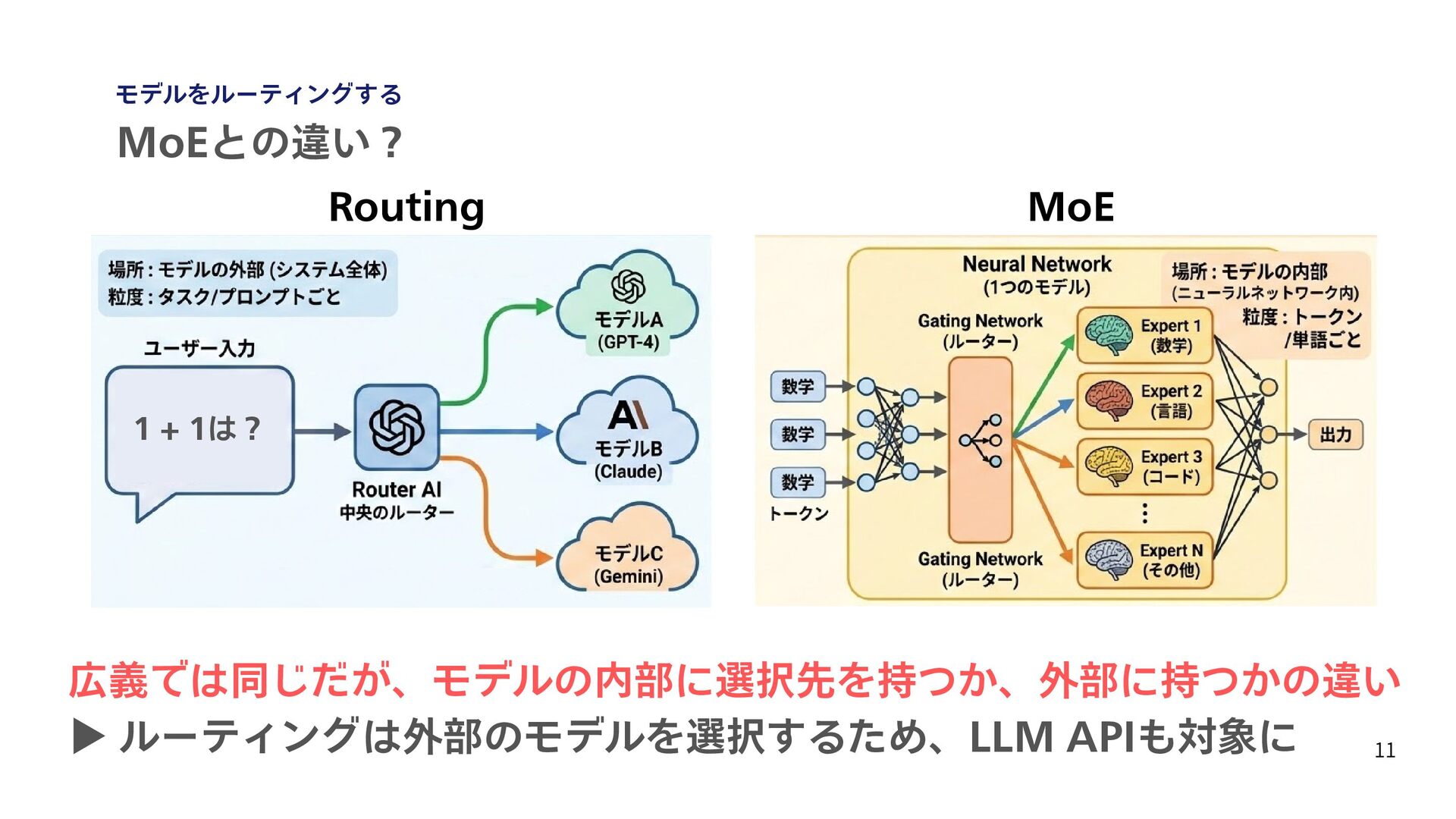
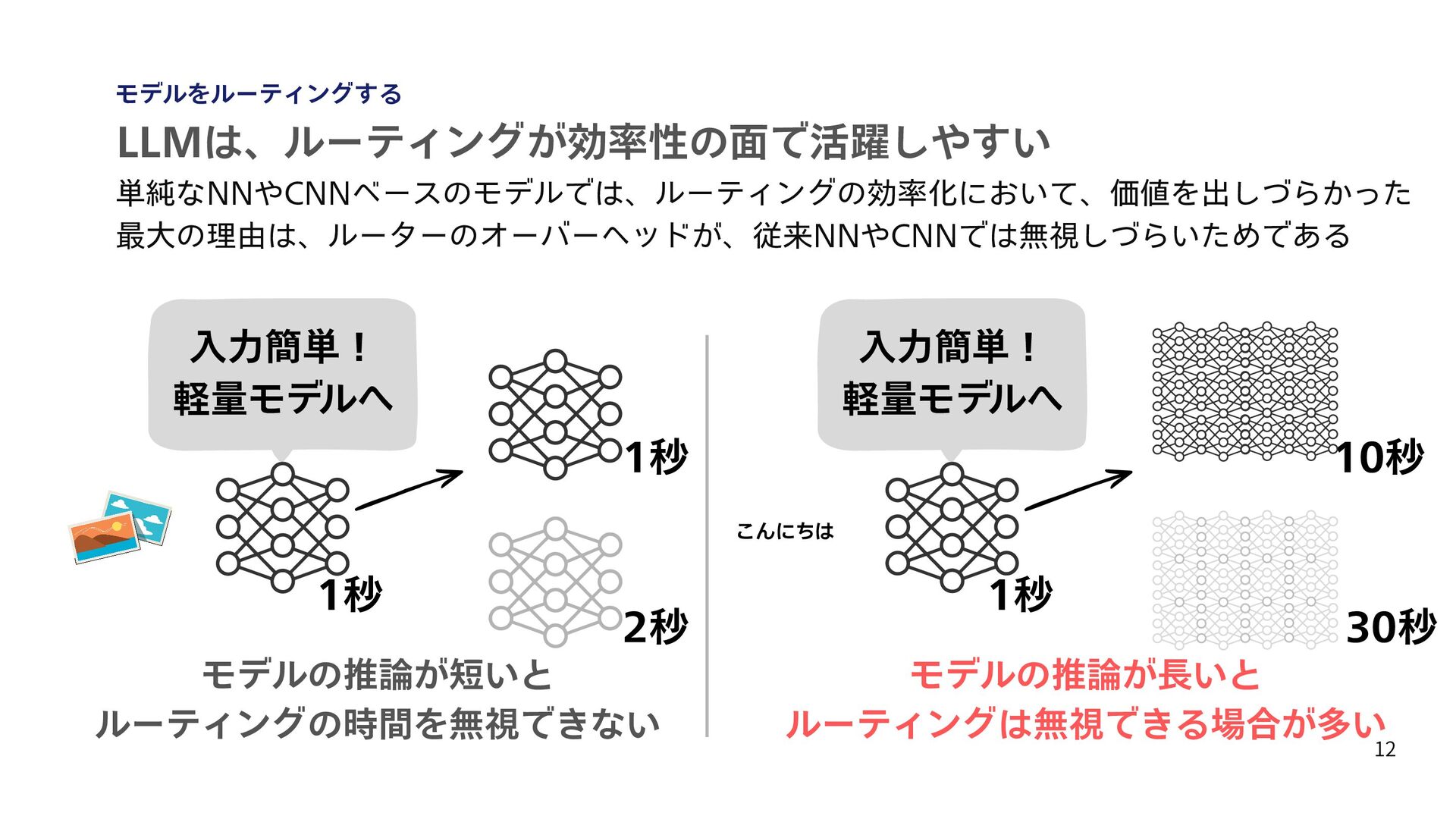
予算制約つきの API 利用最適化を定式化し、コスト削減を目指している [5] Chen, Lingjiao, Matei Zaharia, and James Zou. “FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance.” Transactions on Machine Learning Research (TMLR), 2024. [6] Sanh, Victor, et al. "DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter." arXiv preprint arXiv:1910.01108 (2019). 17 最近のLLMをルーティングする技術の動向
(Program-of-Thought) を実行して一致しているかどうかで、後続の高性能モデルを実行するか判断する 2つのLLMのコストの差が十分大きいという前提がある [8] Yue, Murong, Jie Zhao, Min Zhang, Liang Du, and Ziyu Yao. “Large Language Model Cascades with Mixture of Thoughts Representations for Cost-Efficient Reasoning.” International Conference on Learning Representations (ICLR 2024), 2024. [9] Wei, Jason, et al. "Chain-of-thought prompting elicits reasoning in large language models." Advances in neural information processing systems 35 (2022): 24824-24837. [10] Chen, Wenhu, et al. "Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks." arXiv preprint arXiv:2211.12588 (2022). 19 最近のLLMをルーティングする技術の動向
[11]Lu, Keming, et al. "Routing to the expert: Efficient reward-guided ensemble of large language models." Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. [12]Jiang, Dongfu, Xiang Ren, and Bill Yuchen Lin. "Llm-blender: Ensembling large language models with pairwise ranking and generative fusion." Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. 20 最近のLLMをルーティングする技術の動向
タや含まれないタスクのデータに対しても、最良の単体LLMやZooterよりも優れる [13] Chen, Shuhao, Weisen Jiang, Baijiong Lin, James T. Kwok, and Yu Zhang. "RouterDC: Query-Based Router by Dual Contrastive Learning for Assembling Large Language Models." Advances in Neural Information Processing Systems 37, 2024. 21 最近のLLMをルーティングする技術の動向
BERT classifier 2値分類を解くfull fine-tuning Causal LLM classifier(Llama 3[16] 8Bベース) 2値分類を解くinstruct形式でfull fine-tuning 報告上は、BERTやCausal LLMのような高性能なモデルでなくても、 軽量手法でも十分性能が高い [14] Ong, Isaac, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M. Kadous, and Ion Stoica. “RouteLLM: Learning to Route LLMs from Preference Data.” International Conference on Learning Representations (ICLR 2025), 2025. [15] Yehuda Koren, Robert Bell, and Chris Volinsky. Matrix factorization techniques for recommender systems. Computer, 42(8):30–37, 2009. [16] Dubey, Abhimanyu, et al. "The Llama 3 Herd of Models." arXiv preprint arXiv:2407.21783, 2024. 22 最近のLLMをルーティングする技術の動向
44M) で、多モデル/nサンプル数を一括で 推論し、オーバーヘッドを小さく保つ 推論時間において、ルーターの追加処理は非常に小さいオーバーヘッドであり、 品質低下は 1%未満、最大 60%のコスト(API料金)削減に成功 [17] Ding, Dujian, Ankur Mallick, Shaokun Zhang, Chi Wang, Daniel Madrigal, Mirian Del Carmen Hipolito Garcia, Menglin Xia, Laks V. S. Lakshmanan, Qingyun Wu, and Victor Rühle. “BEST-Route: Adaptive LLM Routing with Test-Time Optimal Compute.” Proceedings of the 42nd International Conference on Machine Learning, vol. 267, pp. 13870–13884, 2025. 23 最近のLLMをルーティングする技術の動向
手法よりも、ほとんどのタスクで優れる(数学やプログラミングの推論を要する手法含め) [18]Huang, Canbin, Tianyuan Shi, Yuhua Zhu, Ruijun Chen, and Xiaojun Quan. “Lookahead Routing for Large Language Models.” Advances in Neural Information Processing Systems (NeurIPS 2025), 2025. 24 最近のLLMをルーティングする技術の動向
al. "vLLM Semantic Router: Signal Driven Decision Routing for Mixture-of-Modality Models." arXiv preprint arXiv:2603.04444 (2026). [21] "vLLM Semantic Router." Accessed March 9, 2026. [22] Warner, Benjamin, et al. "Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference." Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. vLLM Semantic Router は、リクエストの内容や状況に応じて、どのモデルに投げる か / どの安全処理を挟むか / キャッシュを使うかを判断する、LLM 推論の前段に置く 賢いルーティング層 Hybrid-LLMやRouterDCなどのモデル選択手法も、実装ロードマップに含まれている 26 最近のLLMをルーティングする技術の動向
重大な課題に対しても、従来の性能を維持したまま改善を期待できる ルーティングがLLM/MLOpsの可能性を広げる LLM/MLOpsへの活用展望 [23] Khattab, Omar, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan A, Saiful Haq, Ashutosh Sharma, Thomas Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. “DSPy: Compiling Declarative Language Model Calls into State-of-the-Art Pipelines.” International Conference on Learning Representations (ICLR 2024), 2024. 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![高性能/高価なLLM、エッジでも利用できる低性能/安価なLLMを組み合わせ、 入力毎にどちらを利用するかルーター(DeBERTa-v3-large[4] 300M)で判定、 条件がデータセットでは、性能を維持して最大40%の高性能モデルの呼び出しを削減 ルータは小モデルと大モデルの品質差を学習して判断する 2024: Hybrid-LLM[3] 最近のLLMをルーティングする技術の動向](https://files.speakerdeck.com/presentations/a8c19e6571e54359aadeee0f928e65fb/slide_15.jpg){kind=link}
![2024: FrugalGPT[5] 「複数LLM」を用意し、安いモデルから順番に試し、答えに自信が持てるときは止め、 自信が低いときは次の高性能モデルへ送るカスケード推論 ルーティングの基準となるスコアは、DistilBERT[6](約66M)で回帰的に推論 商用LLM APIのコスト削減を目的にした LLM cascade の代表的な初期論文の一つ](https://files.speakerdeck.com/presentations/a8c19e6571e54359aadeee0f928e65fb/slide_16.jpg){kind=link}
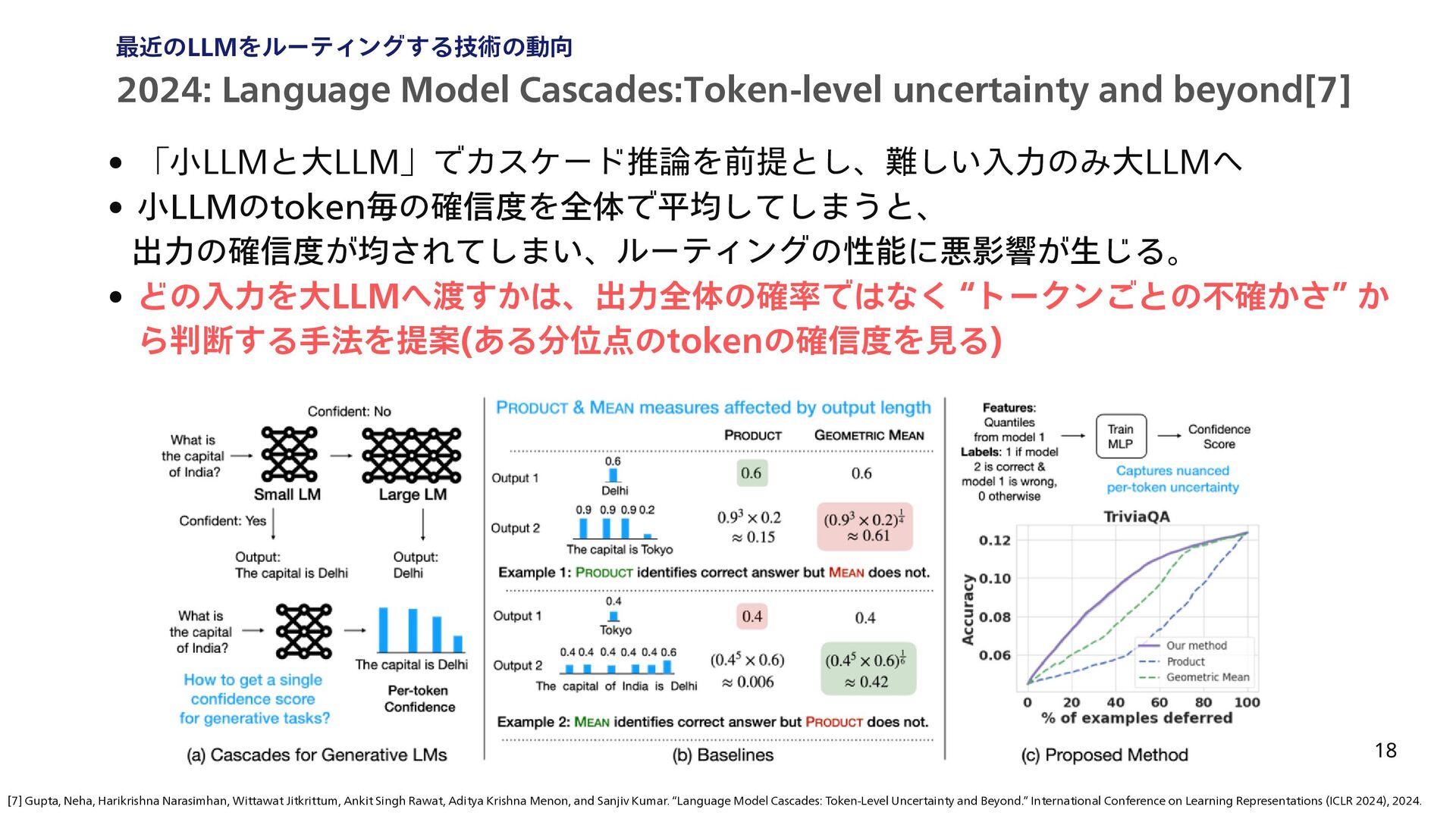{kind=link}
![2024: LLM Cascades with MoT[8] 数理推論のようなLMにとって難しい推論タスクを対象にして、高性能と低性能LLMのカス ケード方式でコストを下げながら推論を行う 数理推論において入力だけでは、難易度や切り替えの判断ができないと示唆 低性能LLMで、複数回CoT [9](Chain-of-Thought)、PoT[10]](https://files.speakerdeck.com/presentations/a8c19e6571e54359aadeee0f928e65fb/slide_18.jpg){kind=link}
![2024: Zooter[11] 報酬モデルで得た候補モデルのスコア分布を教師データにしてルーター(86M)を学習 報酬モデルのスコアはノイズが多いため、学習対象の入力をグループに分けて、その 平均との加重平均を取ることでノイズを低減 得意不得意を含む、6個の候補モデルに対してルーティングを実施 候補モデルすべてに回答を生成させた後で報酬モデルが順位付けして回答するReward Model Ranking (RMR)[12]よりも、効率よく同等の性能で推論が行えた](https://files.speakerdeck.com/presentations/a8c19e6571e54359aadeee0f928e65fb/slide_19.jpg){kind=link}
![2024: RouterDC[13] Zooterのように候補LLMの性能差が小さく、モデルの量が多い中から選択を行うと、 softmaxによりルーターのスコア分布が平坦になってしまい学習が困難になる 「LLMの座標を意味する学習可能な埋め込みベクトル{k}」と「入力から埋め込みベク トルに変換するEncoder 」に対して、「スコアの高いLLMのグループに近づけ、スコ アの低いLLMのグループから遠ざける」対照学習を行うことで上記の課題を改善 「7個の候補モデル」とルーター(DeBERTaV3-base 100M)で、学習に含まれるデー](https://files.speakerdeck.com/presentations/a8c19e6571e54359aadeee0f928e65fb/slide_20.jpg){kind=link}
![2025: RouteLLM[14] 2モデルに対する、ルーターベースの難易度の高い質問を高性能モデルを利用する手法 4つのルーターを用いて網羅的に評価している Similarity-weighted ranking 入力に類似する、学習データのルーティングを参照 Matrix factorization[15] 入力とモデルのマッチングを2層程度の処理で実施](https://files.speakerdeck.com/presentations/a8c19e6571e54359aadeee0f928e65fb/slide_21.jpg){kind=link}
![2025 : BEST-Route[17] 今までのどのモデルを使うか?だけでなく、モデルから何本サンプルを生成するか? を入力毎に適応的に決める手法を提案 (モデル候補数は8個) 小さいモデルでも複数回出力して、品質良いものを選べば品質は上がる(Best-of-N) Multi-head Router (DeBERTa-v3-small](https://files.speakerdeck.com/presentations/a8c19e6571e54359aadeee0f928e65fb/slide_22.jpg){kind=link}
![2025: Lookahead Routing for LLM[18] 従来は、「入力とスコア」からモデルを選択しており、モデルがどういう推論をしてい るかについてルーターは考えることがなかった。 ルーターが各モデルの推論の再現を目指すように学習し、過程で得られる潜在表現を用 いて、ルーティングすることで各モデルの推論内容まで想定した手法を提案 5つの7B~34BのLLMに対して選択を行い、ZooterやRouterDCなどの他のルーティング](https://files.speakerdeck.com/presentations/a8c19e6571e54359aadeee0f928e65fb/slide_23.jpg){kind=link}
![2026: UniRoute[19] LLM ルーティングを「固定されたモデル集合」ではなく、あとから新しいモデルが追 加されても再学習なしで使える形に拡張した研究 従来の手法は、新しいモデルを追加するとルーターなどの再学習が必要な場合が多い 各LLMを代表プロンプト群上での予測誤差ベクトルで表現し、入力 prompt に対する 推定誤差](https://files.speakerdeck.com/presentations/a8c19e6571e54359aadeee0f928e65fb/slide_24.jpg){kind=link}
![2026 : vLLM Semantic Router[20] 2026/01にメジャーverリリース[21] [20] Liu, Xunzhuo, et](https://files.speakerdeck.com/presentations/a8c19e6571e54359aadeee0f928e65fb/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LLMでは、API型でもローカル型でも、基盤モデル本体を継続的に更新するコストは高い 「プロンプトの修正」や「モデルを変える」ことで対処する場合が多い DSPy[23]のような自動でプロンプトを最適化する試みは有効 ルーティングを行うルーターのみなら追加学習は現実的 追加データを用いた、ルーティングの性能改善を通じて、出力全体の改善も期待 出力の精度だけでなく、ユーザの分布から「コスト」や「推論速度」の改善も継続的 に行える可能性がある 課題に対して特化モデルを追加して、ルーターのみ追加で学習することで、](https://files.speakerdeck.com/presentations/a8c19e6571e54359aadeee0f928e65fb/slide_31.jpg){kind=link}