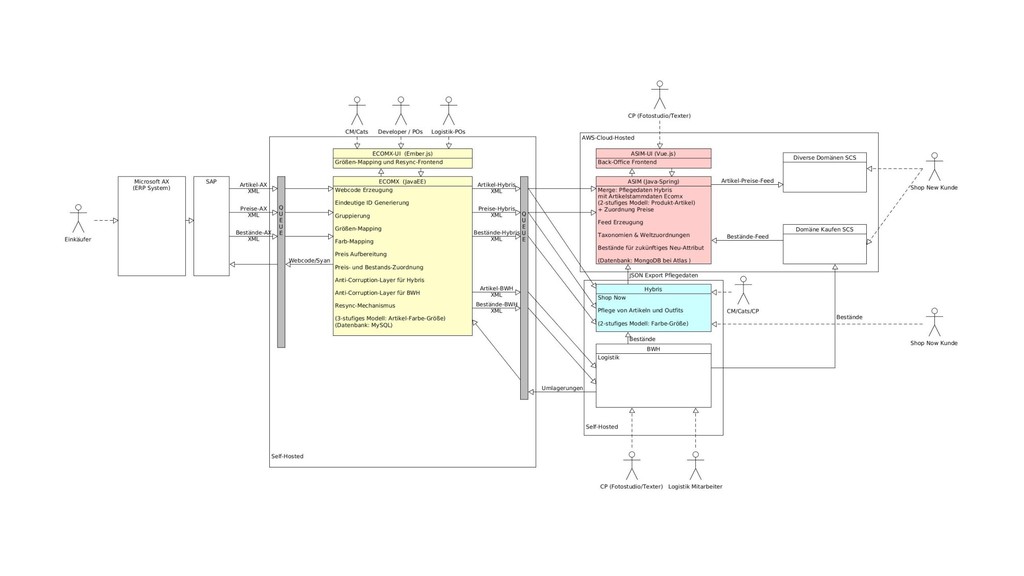
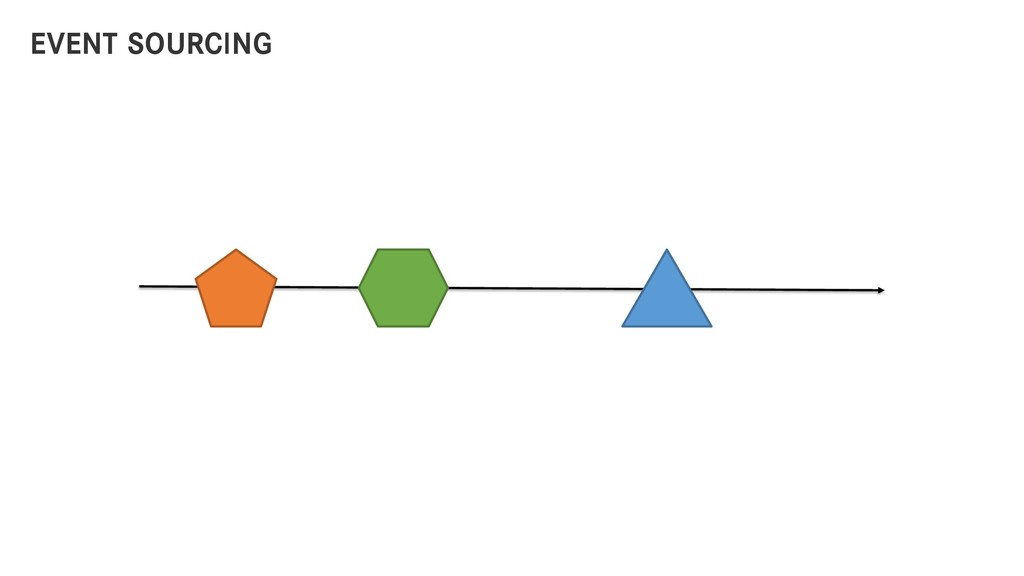
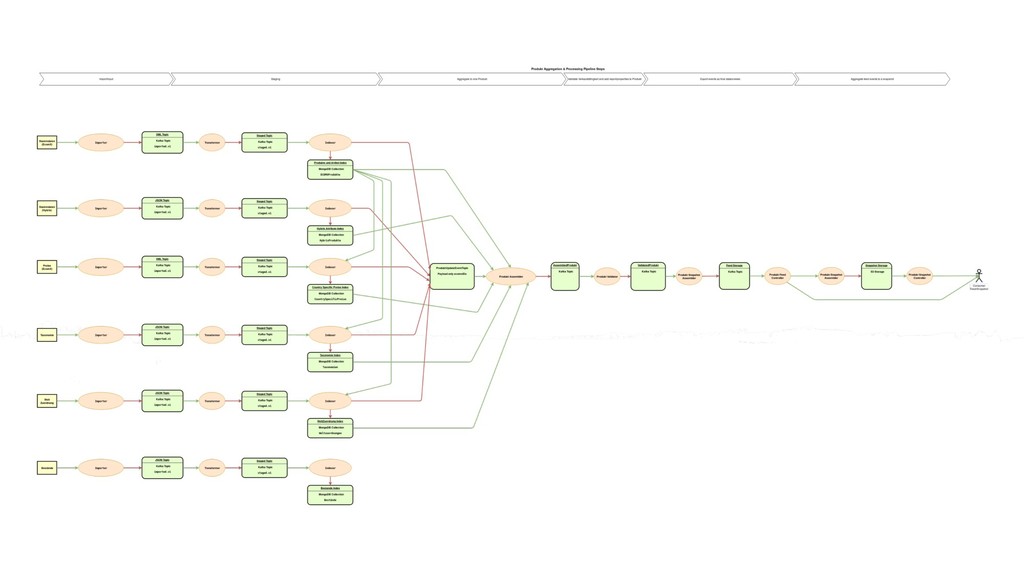
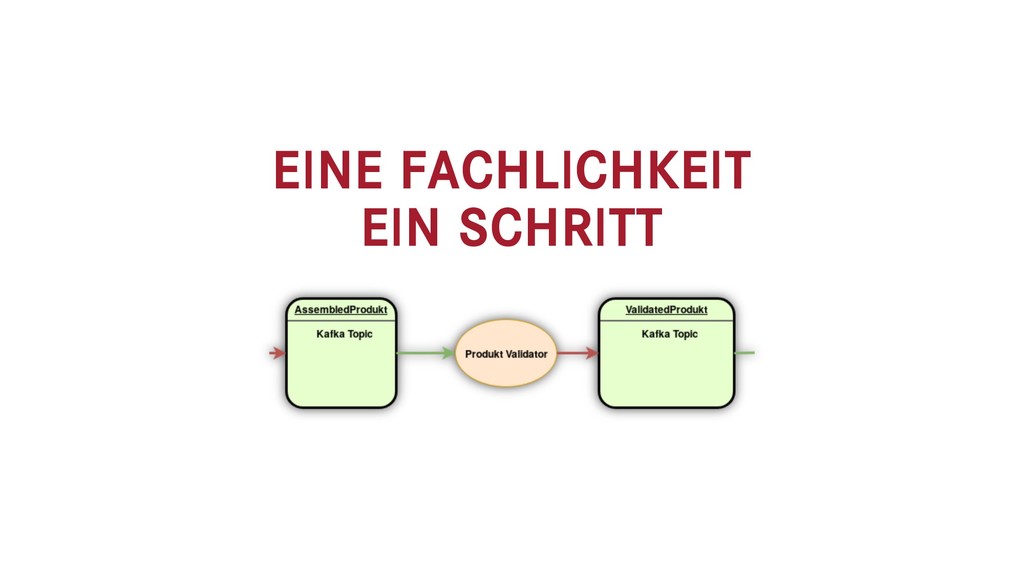
Seit vielen Jahren verarbeitet Breuninger seine Produktdaten mit klassischen Batch Jobs. Durch die immer höher werdenden fachlichen Anforderungen ist diese Art der Verarbeitung nicht mehr möglich. Wir haben daher unsere Verarbeitungs-Pipeline auf einen event-getriebenen Ansatz umgebaut. Diese neue Pipeline, ihre Vor- und Nachteile wollen wir euch in diesem Talk vorstellen. Verwendete Technologien sind Java11, Kafka, MongoDB und Atom-Feeds über HTTP & JSON.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TILL LORENTZEN BENEDIKT STEMMILDT JOIN US! TEAM.BREUNINGER.COM [email protected] [email protected]](https://files.speakerdeck.com/presentations/e6835670956a413889eb1ea27b9a2656/slide_23.jpg){kind=link}