Ben has been doing data sciencey work since 1999 for organisations in the banking, retailing, health and education industries. He is currently on contracts with Pharmac and Aspire2025 (a Tobacco Control research collaboration) where, happily, he gets to use his data-wrangling powers for good.
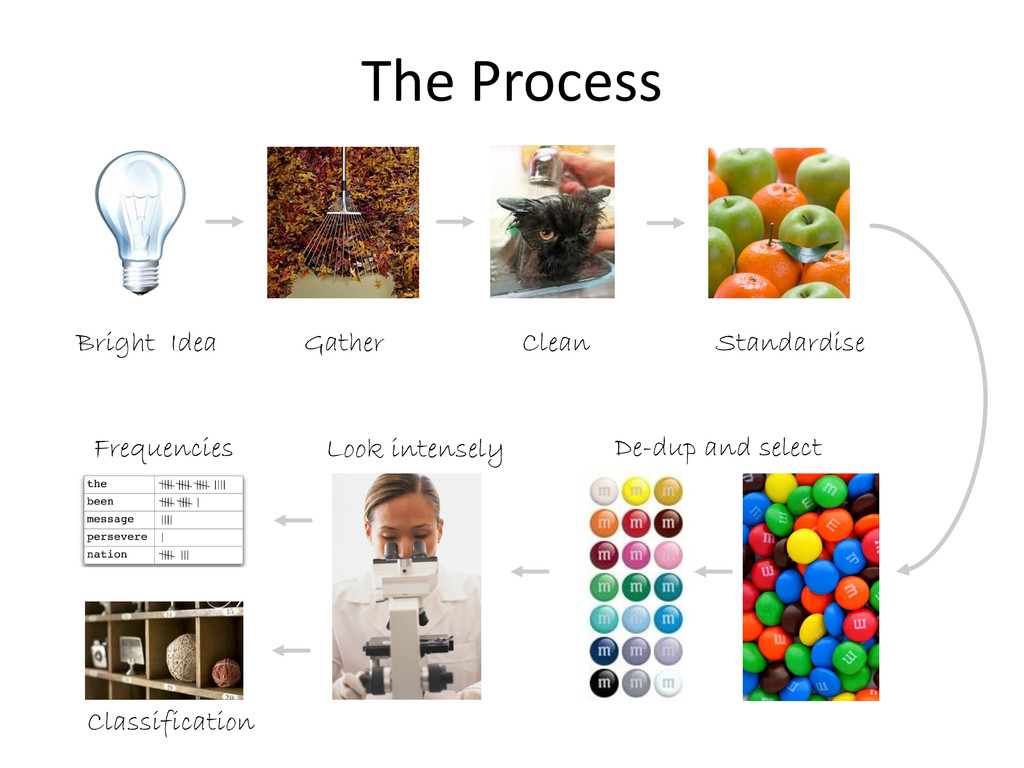
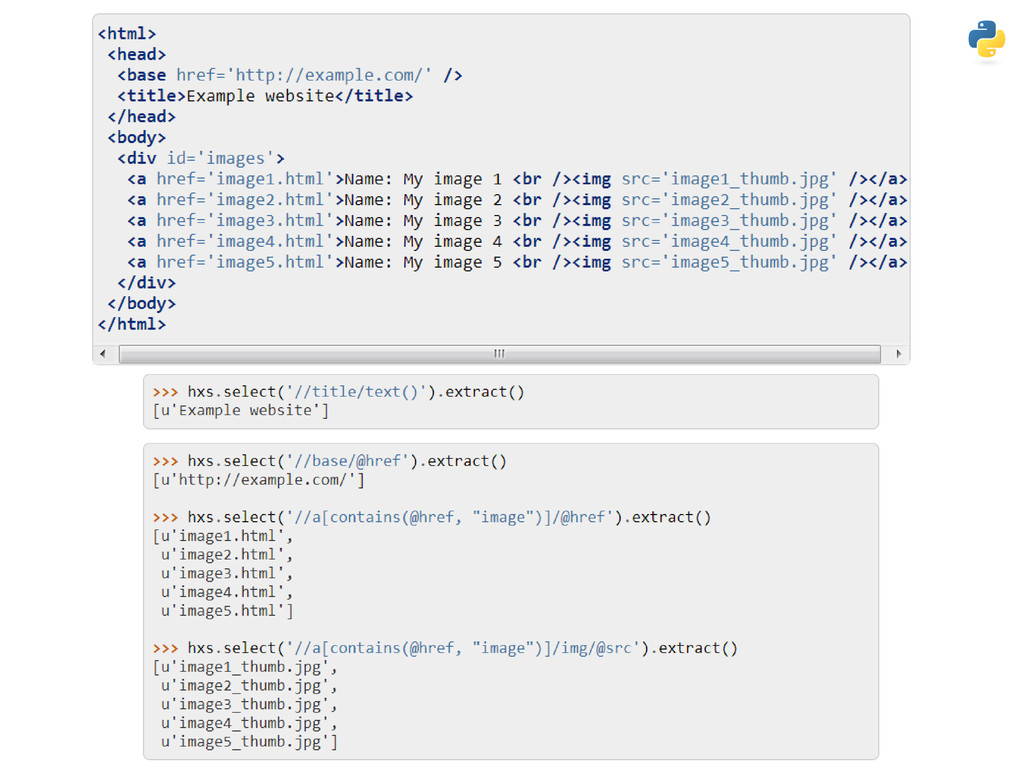
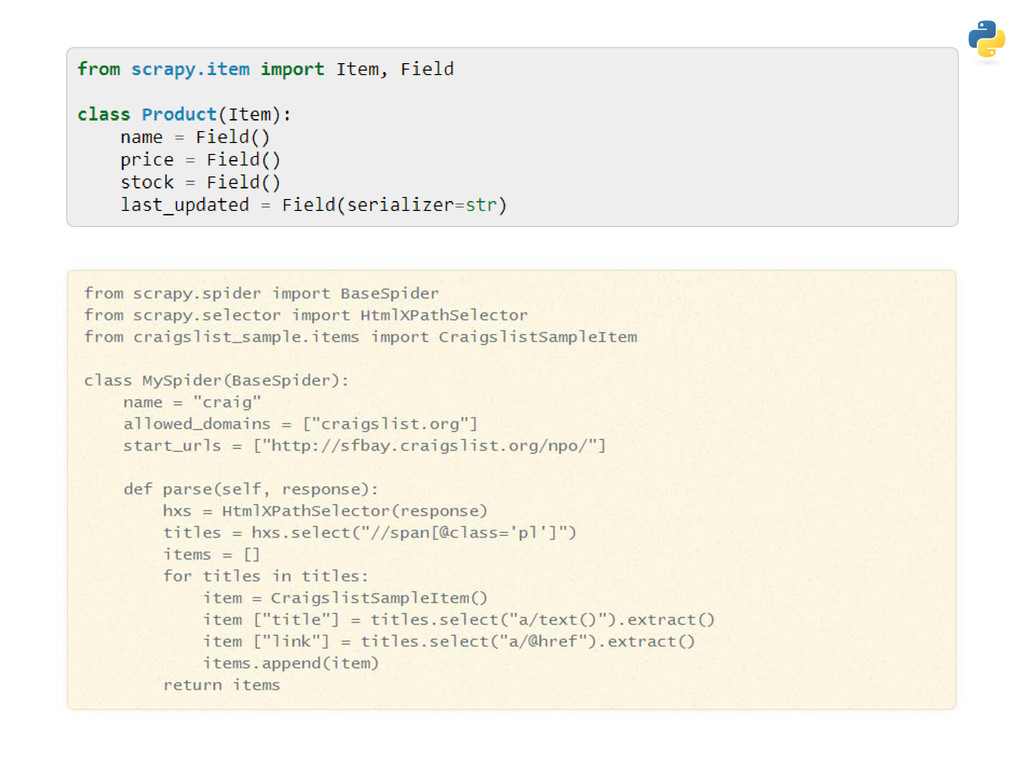
This presentation focuses on analysing text, with Tobacco Control as the context. Examples include monitoring mentions of NZ's smokefree goal by politicians and examining media uptake of BATNZ's Agree/Disagree PR campaign. It covers common obstacles during data extraction, cleaning and analysis, along with the key Python and R packages you can use to help clear them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Deduplication • Python sets – shingles1 = set(get_shingles(record1['standardised_content'])) • Shingling](https://files.speakerdeck.com/presentations/5aeb3890033e0131f0b27e4850bc76c4/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
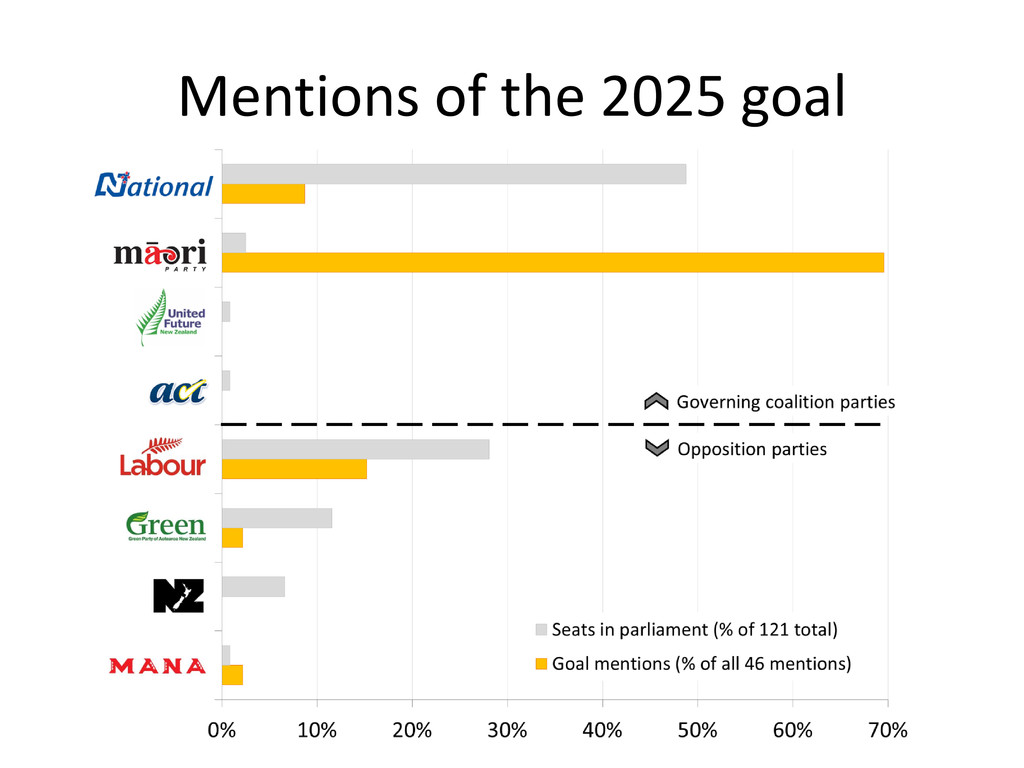{kind=link}
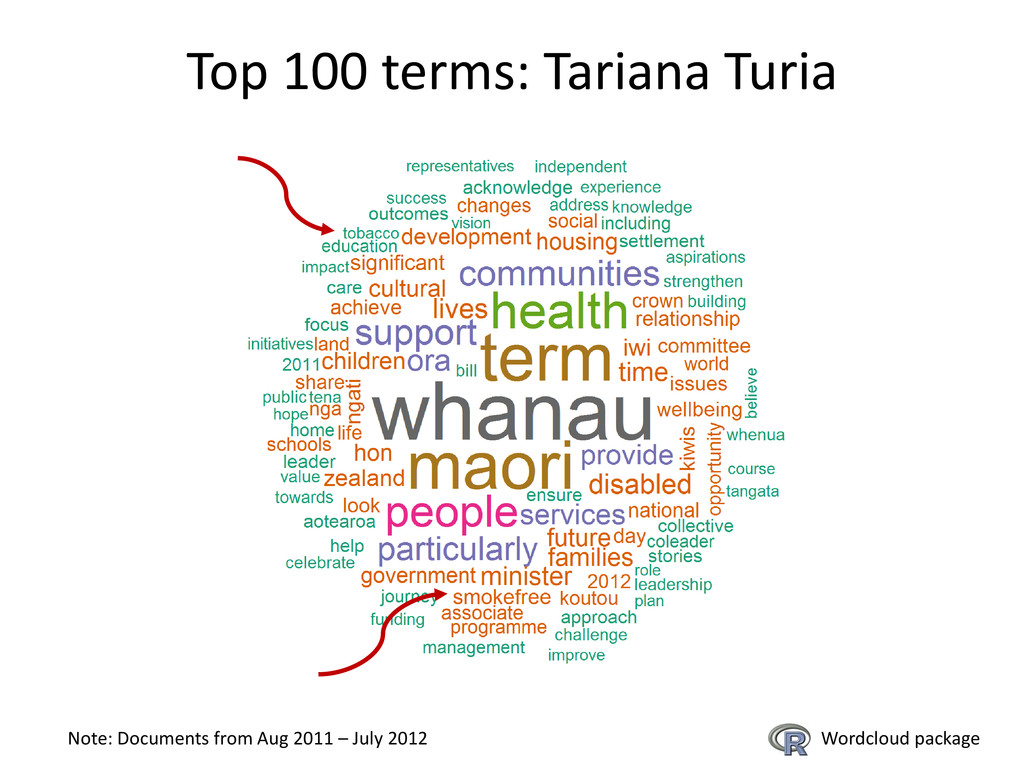{kind=link}
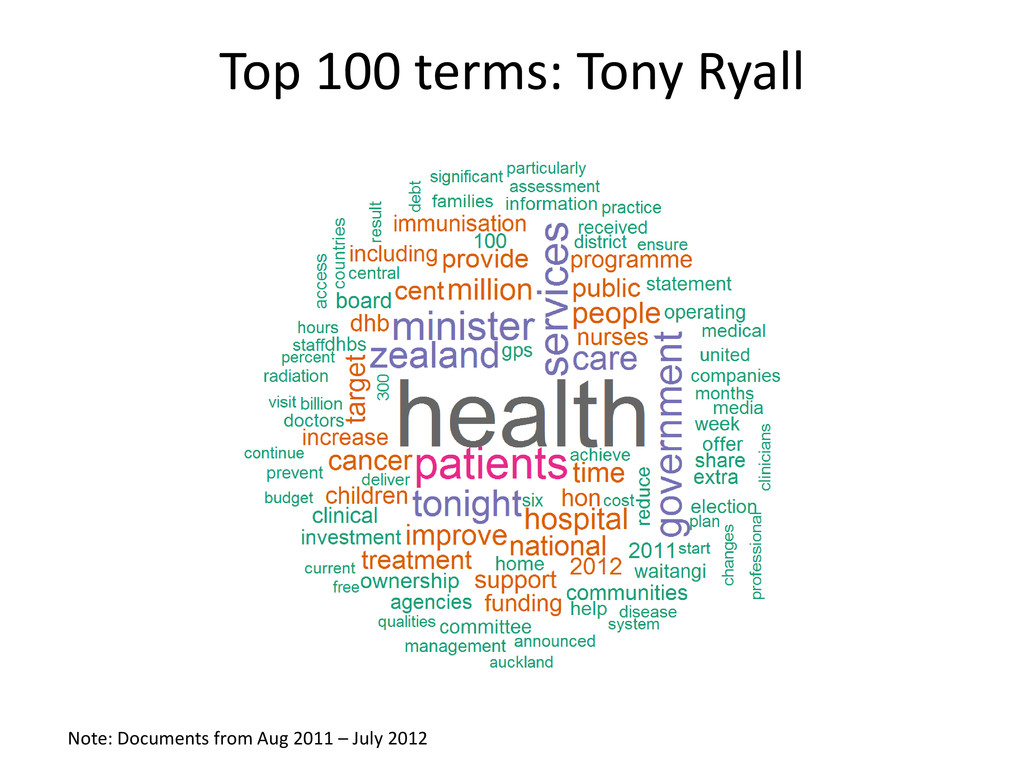{kind=link}
{kind=link}
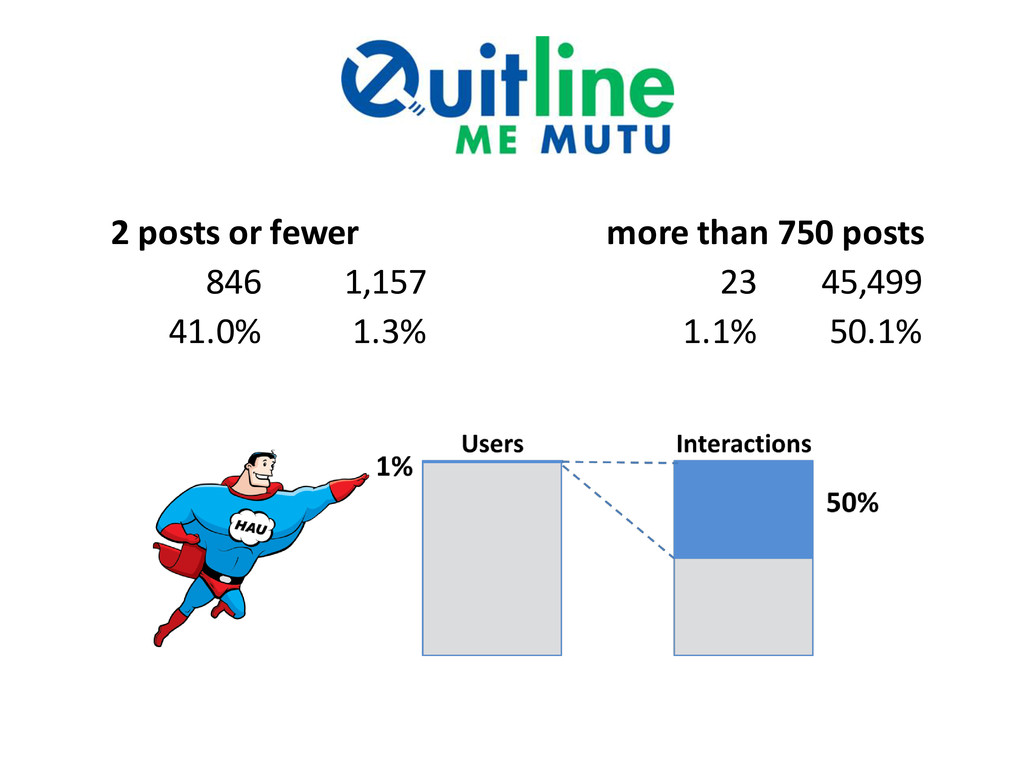{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}