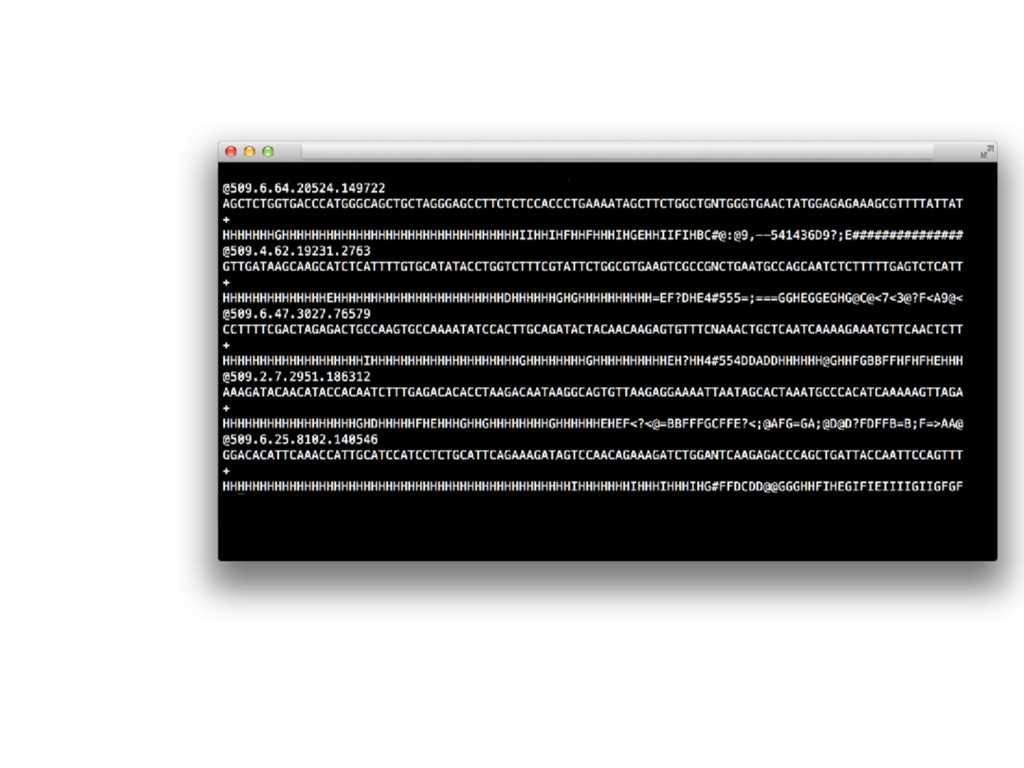
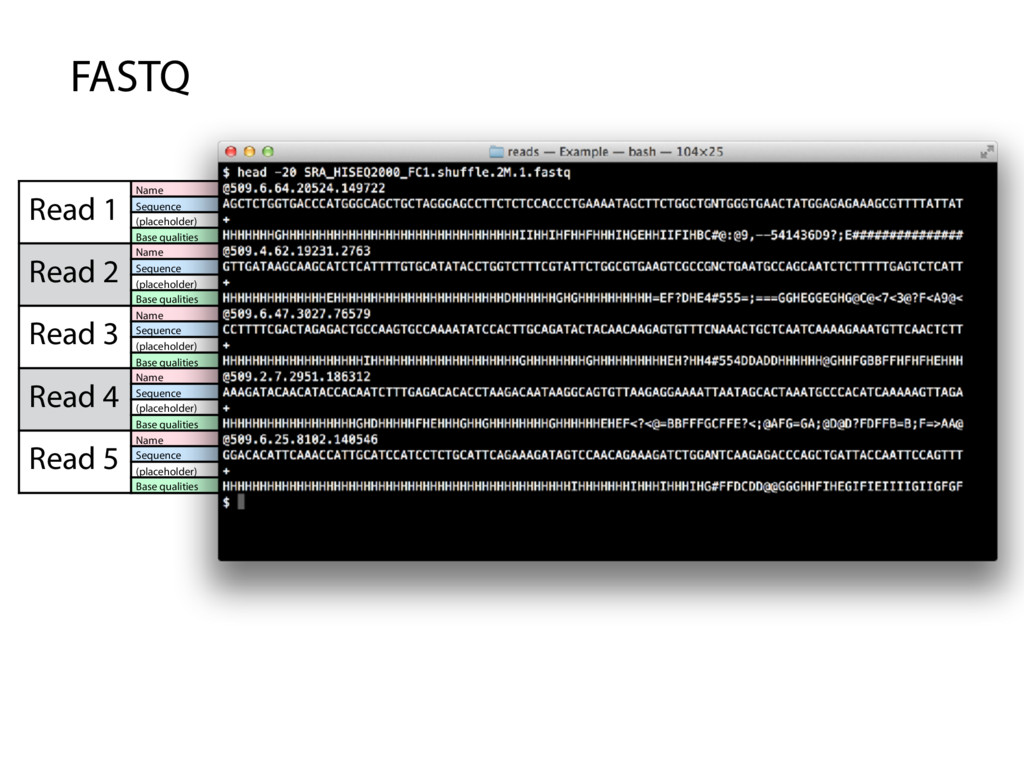
FASTQ Name Sequence (placeholder) Base qualities Name Sequence (placeholder) Base qualities Name Sequence (placeholder) Base qualities Name Sequence (placeholder) Base qualities Name Sequence (placeholder) Base qualities
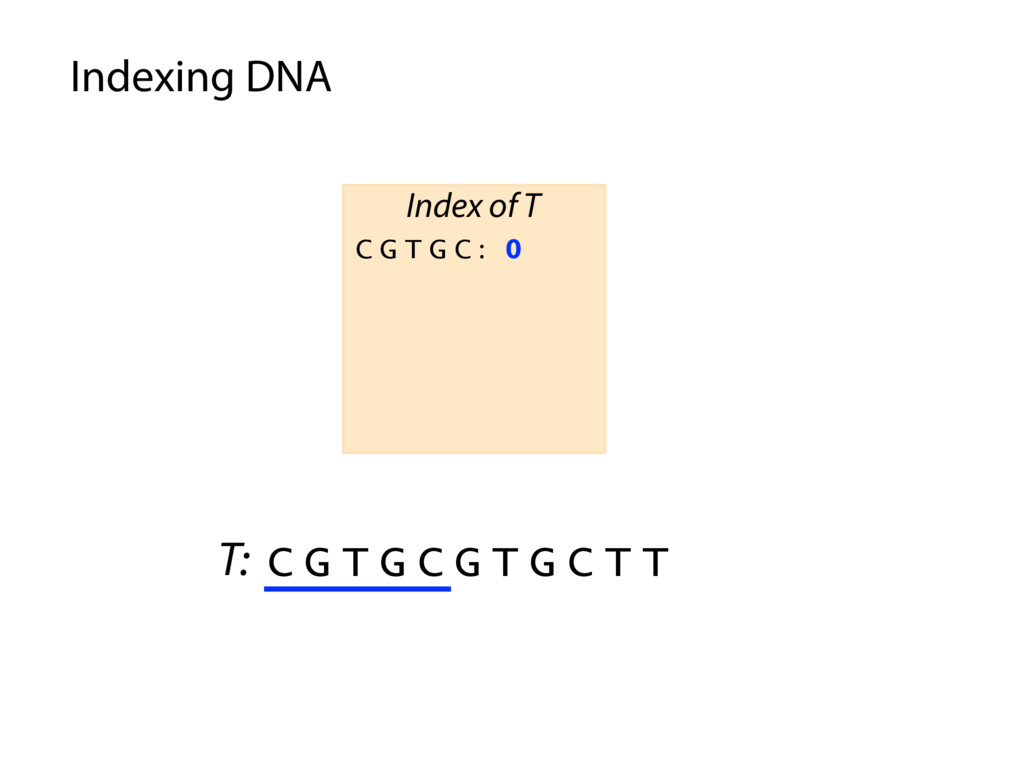
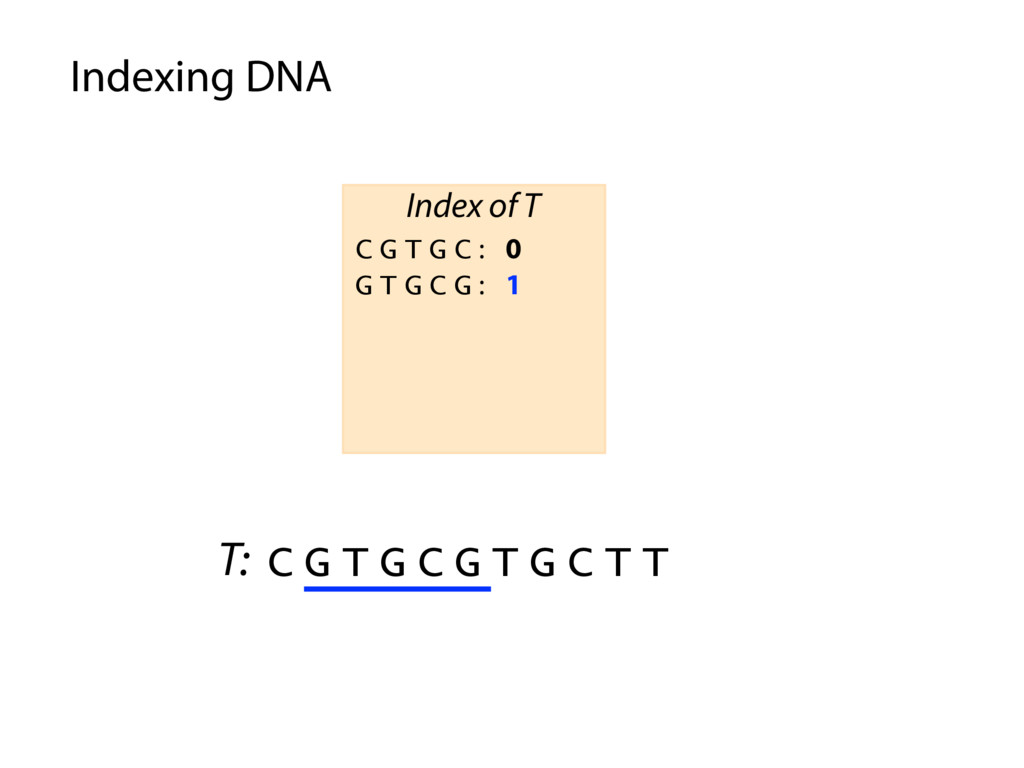
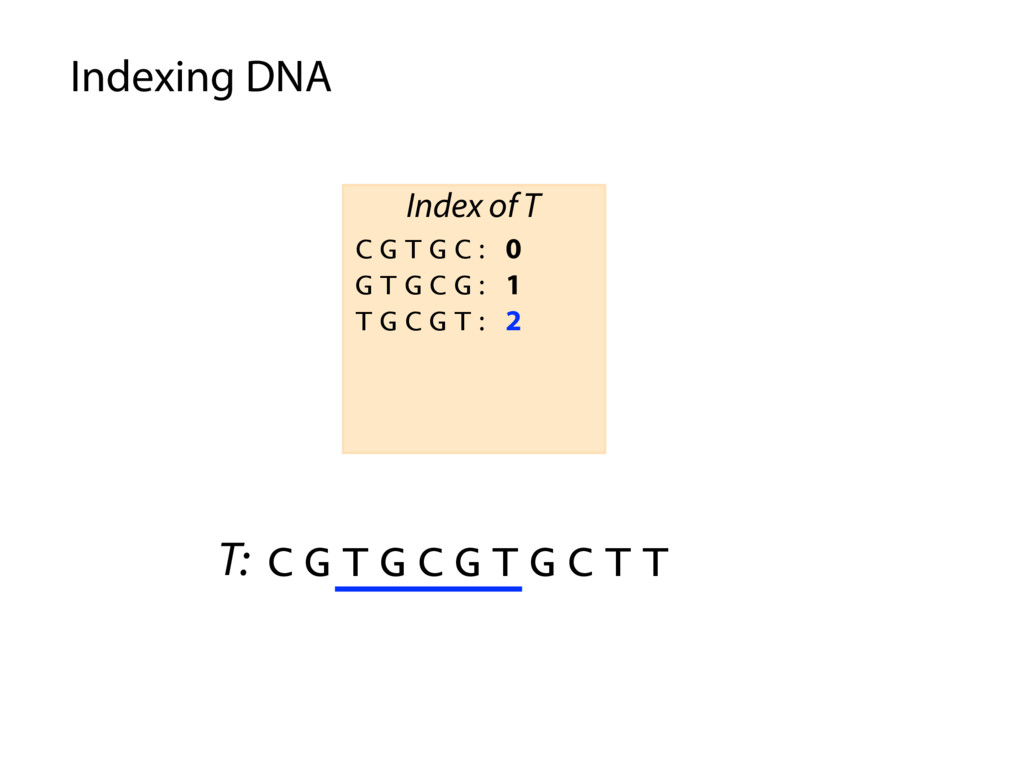
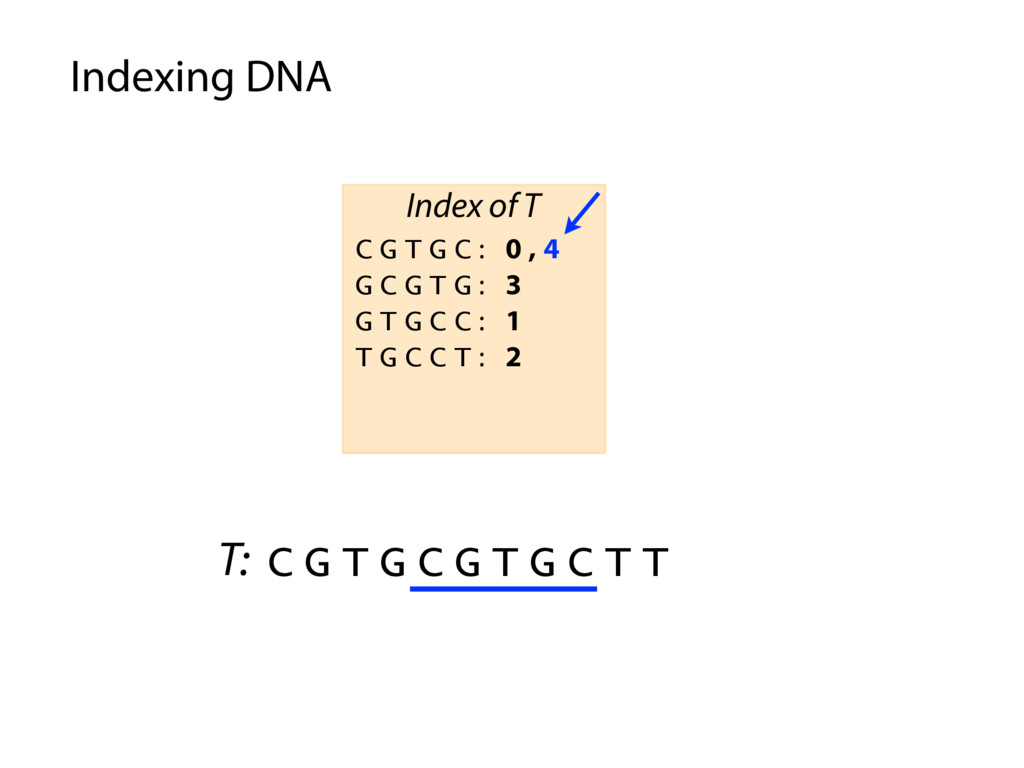
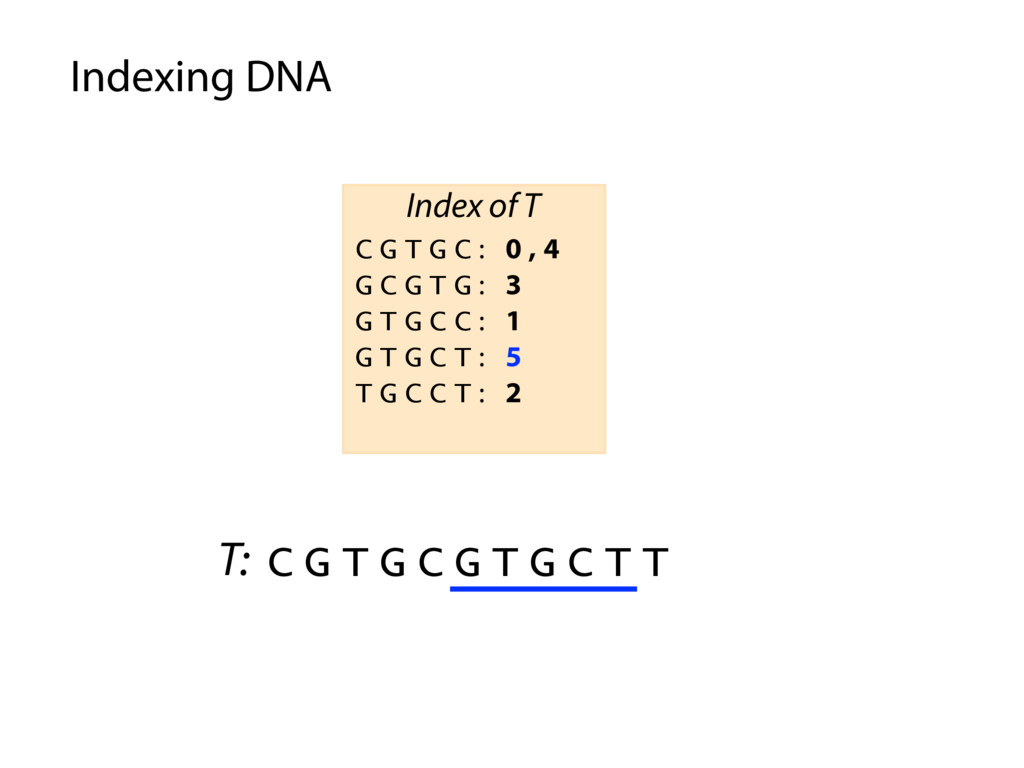
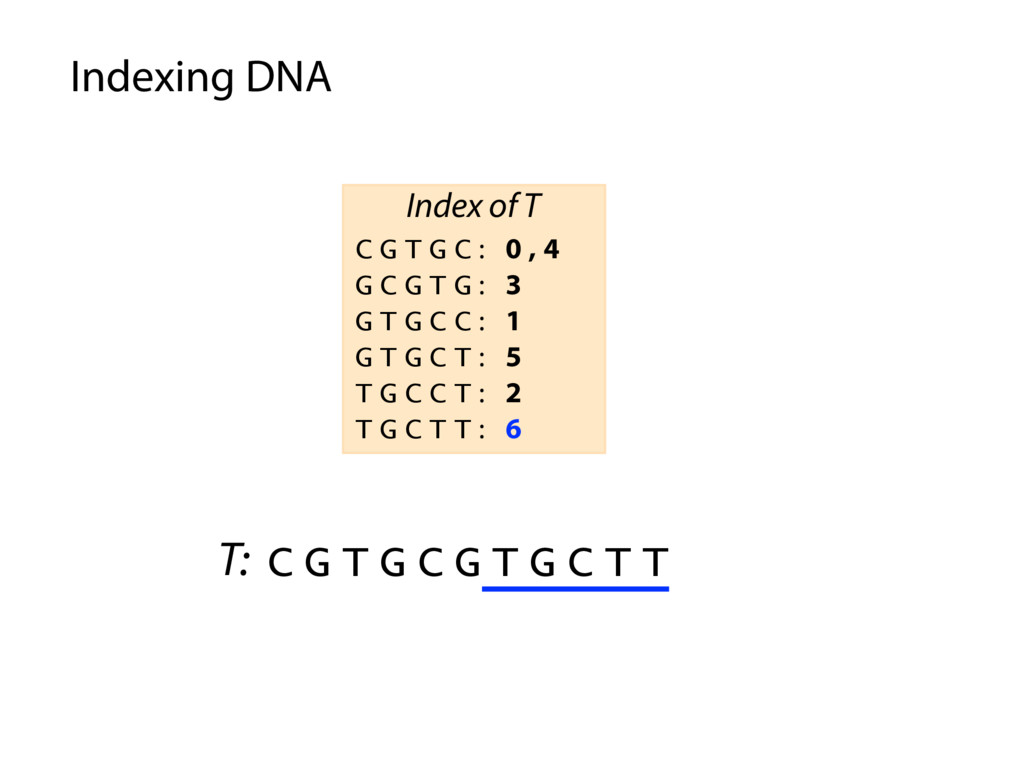
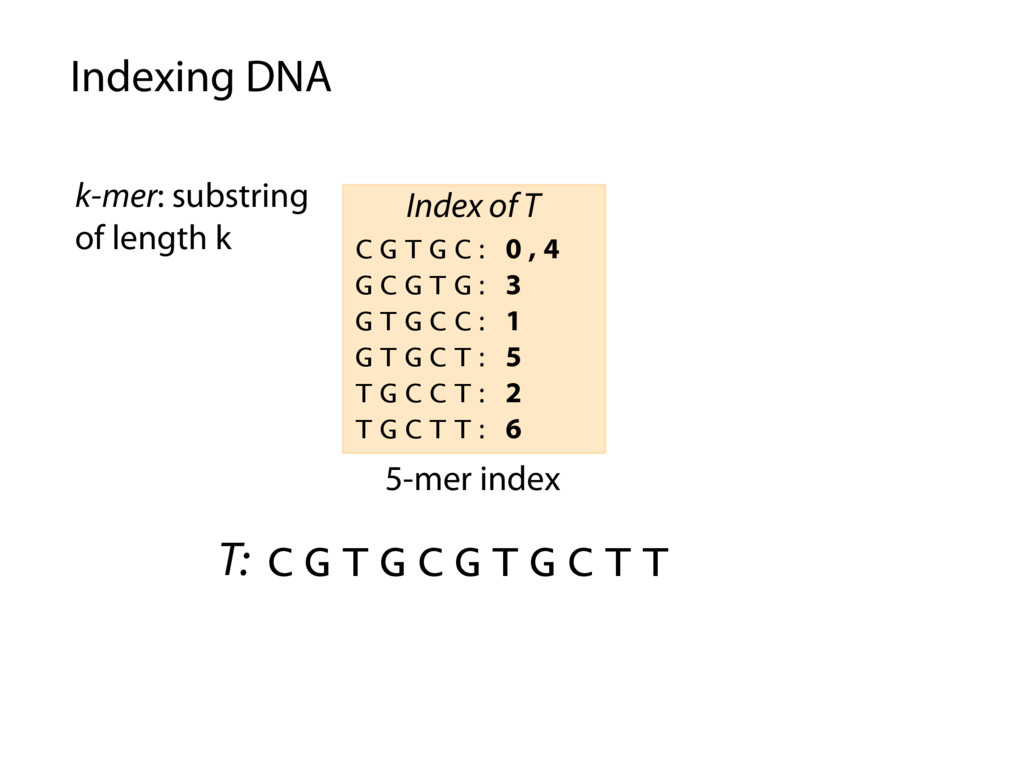
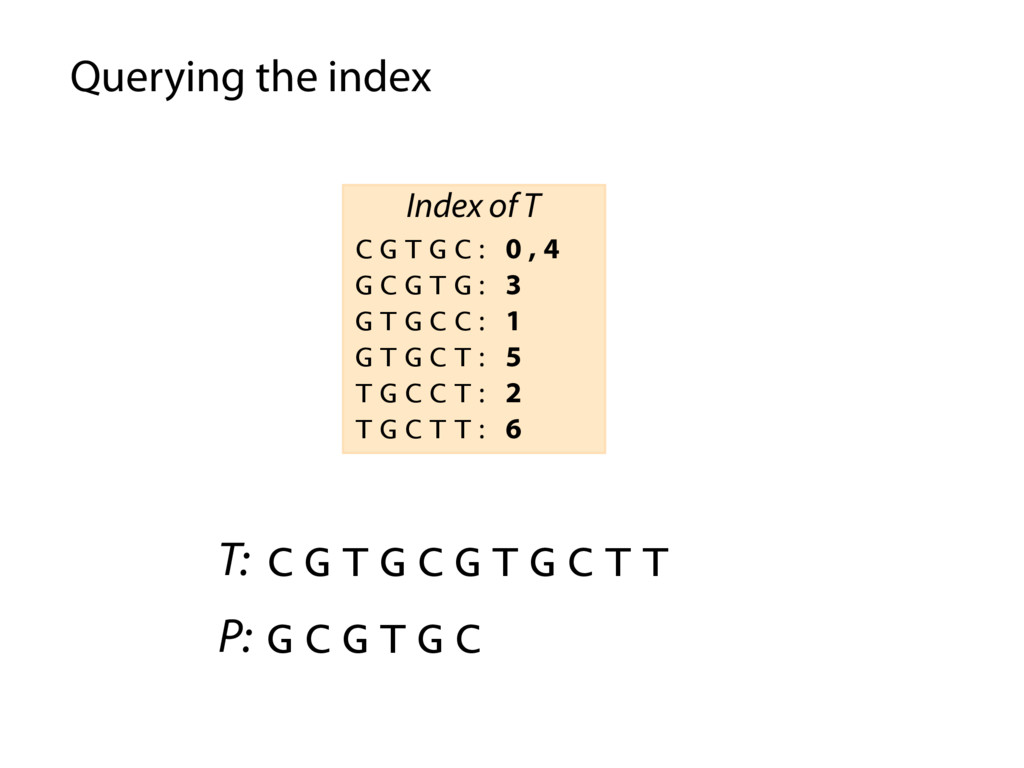
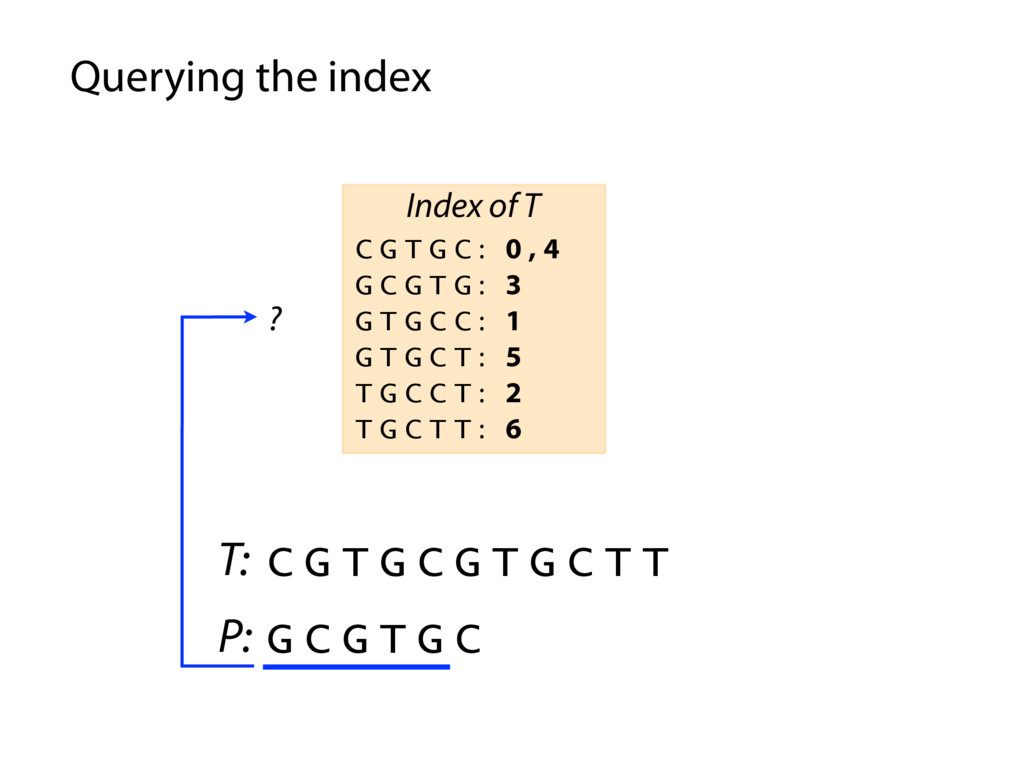
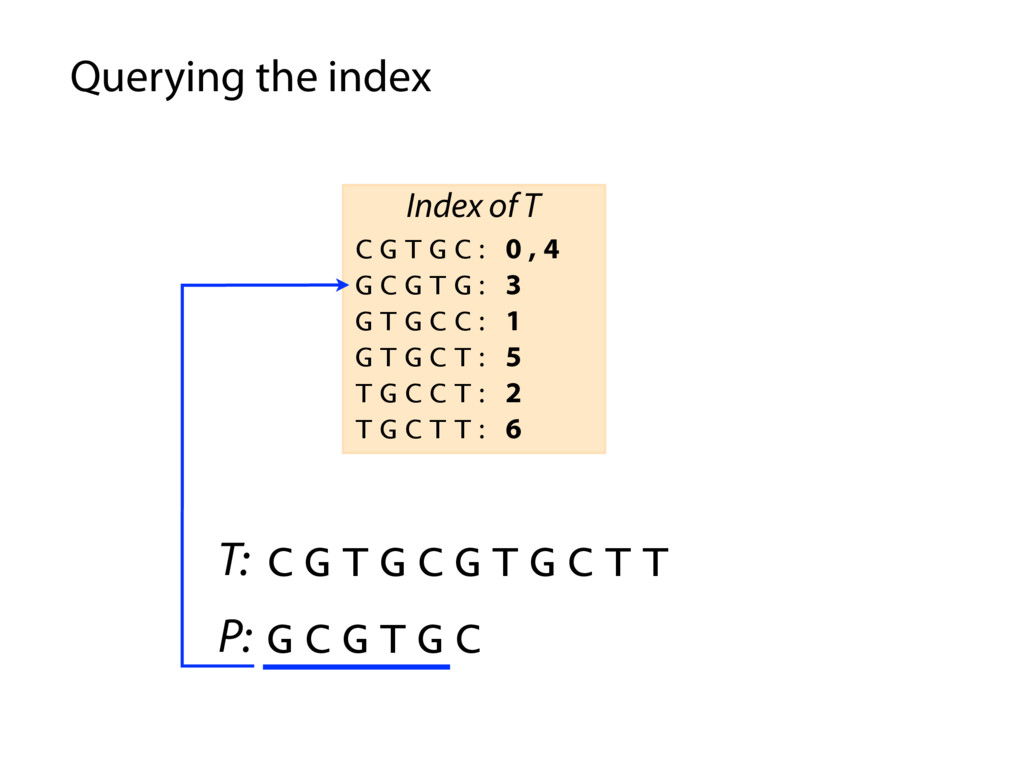
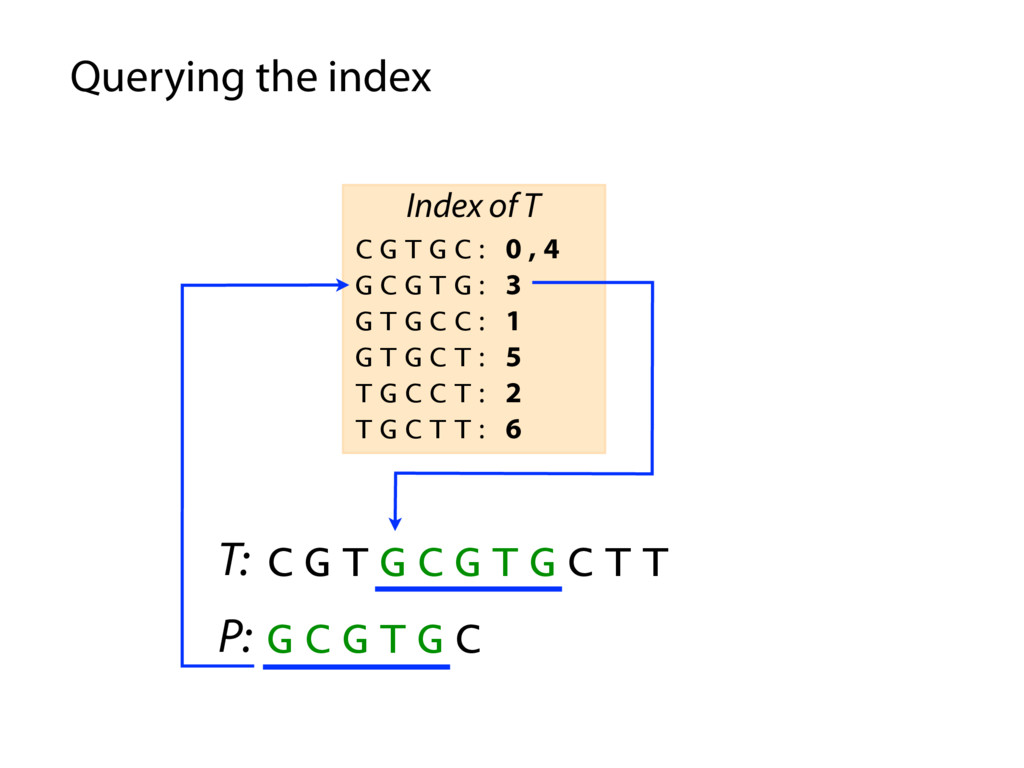
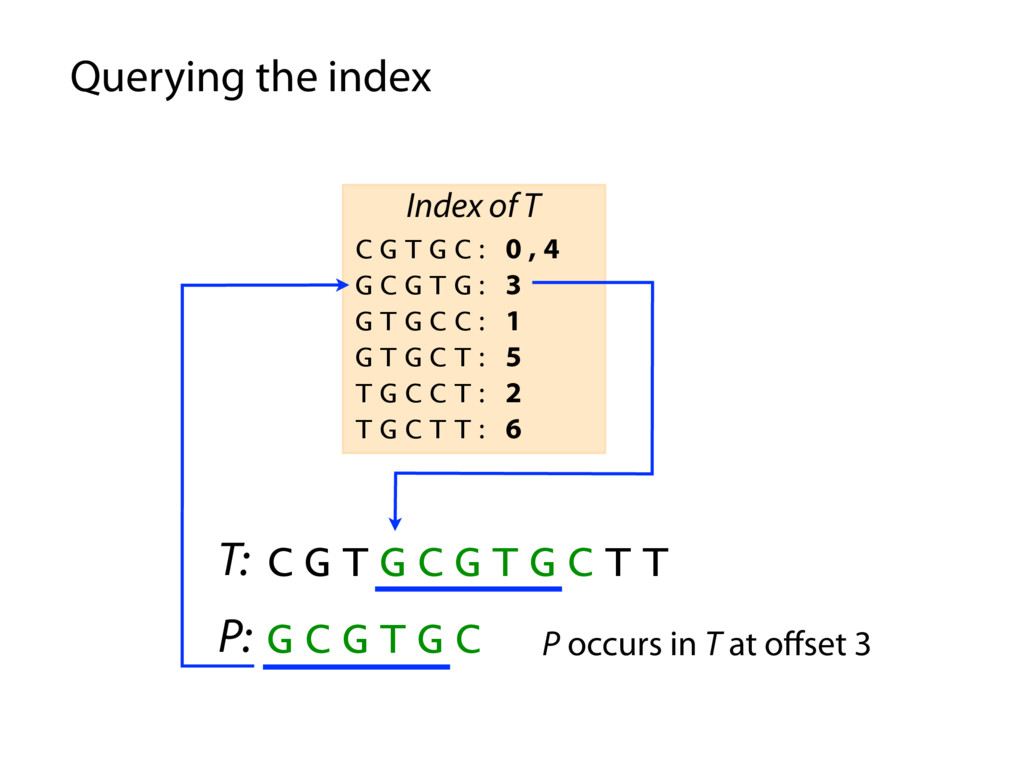
T T C G T G C : 0 , 4 G C G T G : 3 G T G C C : 1 G T G C T : 5 T G C C T : 2 T G C T T : 6 Index of T P: G C G T G C P occurs in T at offset 3 Querying the index
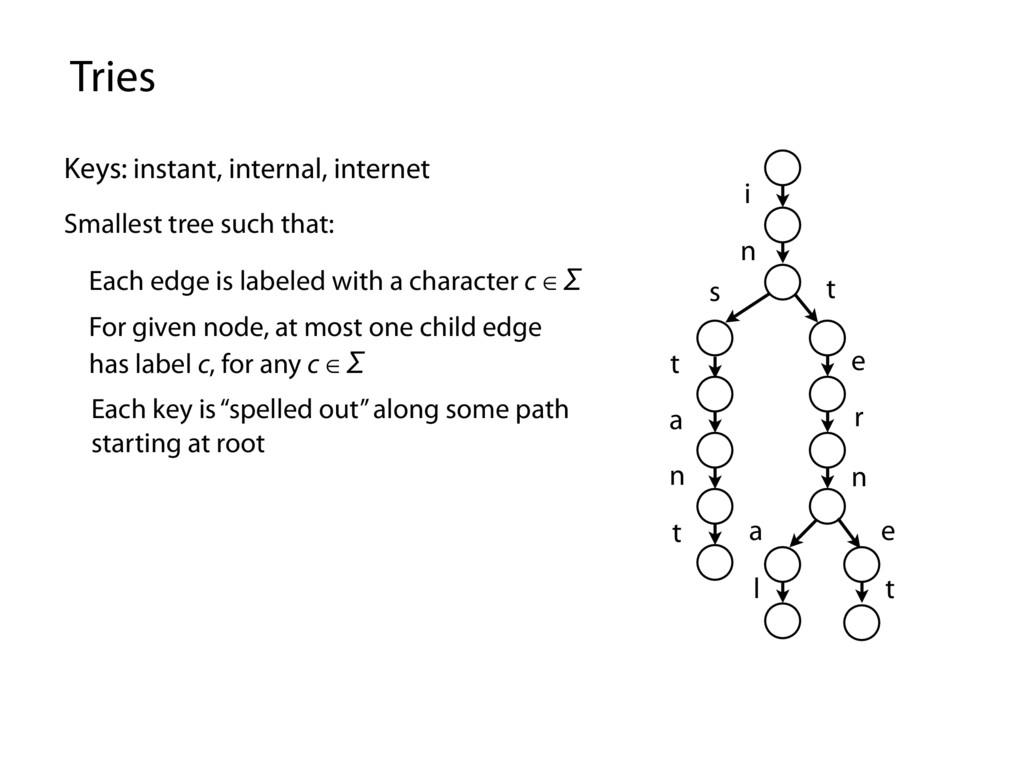
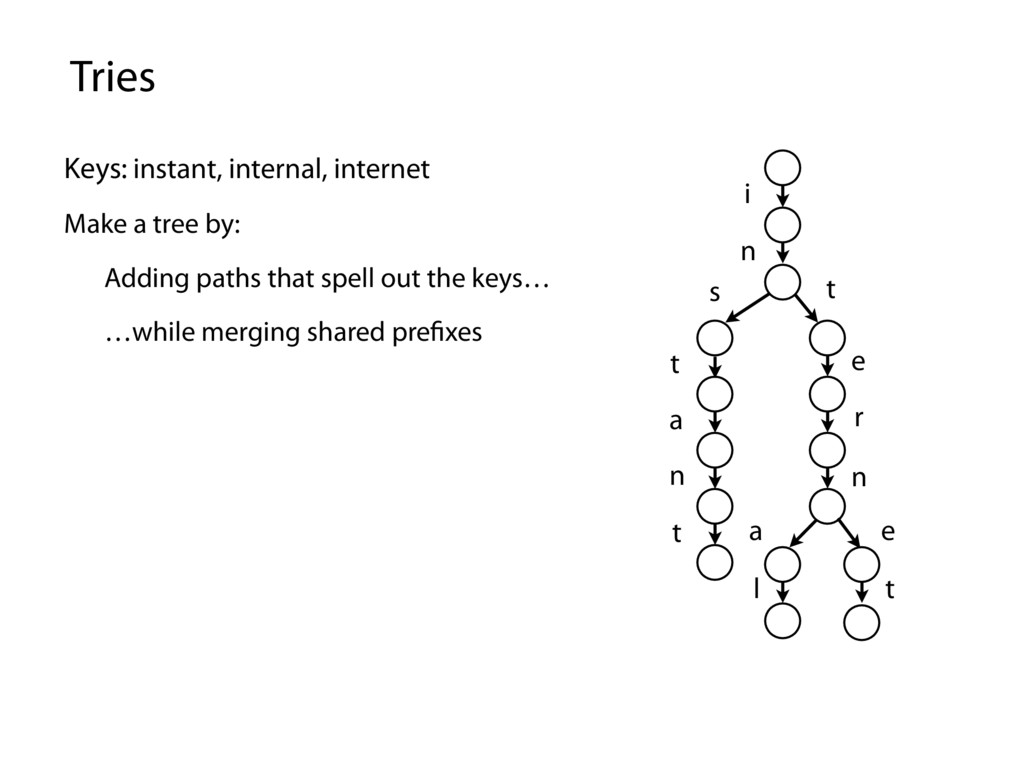
along some path starting at root Each edge is labeled with a character c ∈ Σ For given node, at most one child edge has label c, for any c ∈ Σ i n s t a n t t e r n a l e t Smallest tree such that:
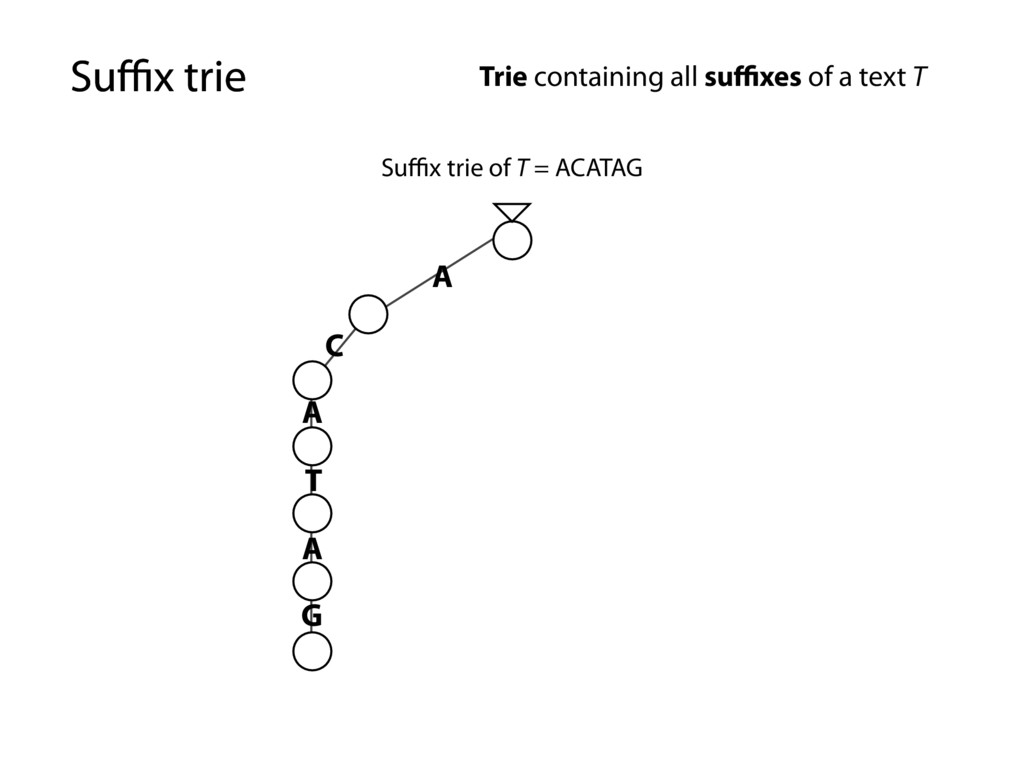
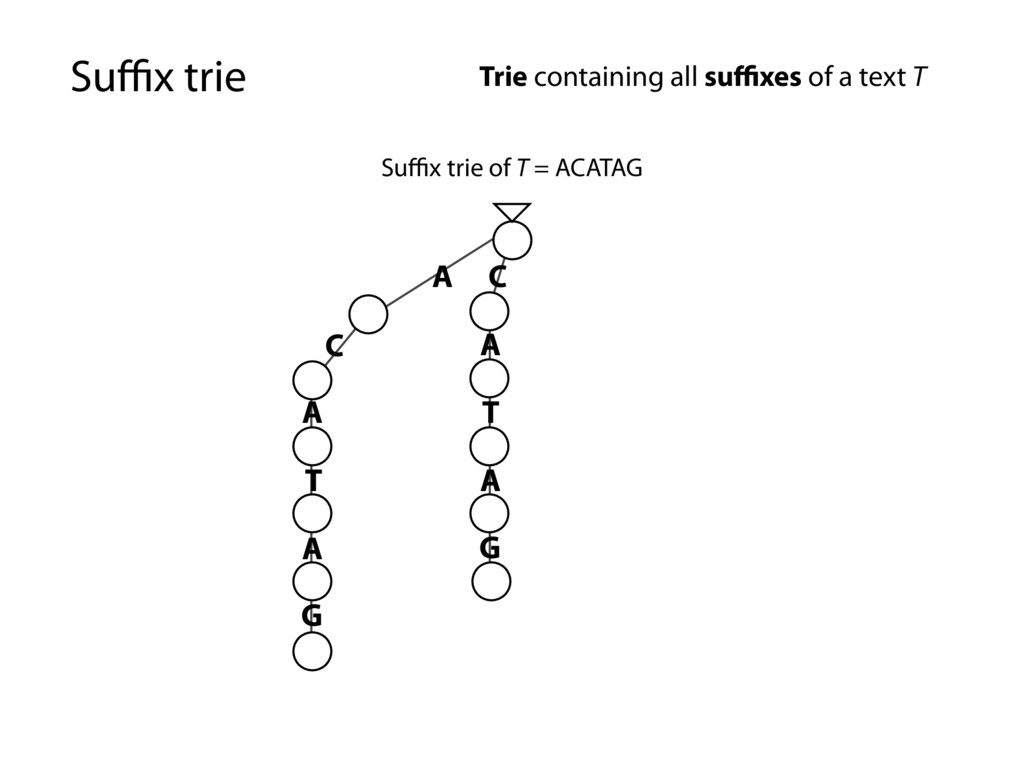
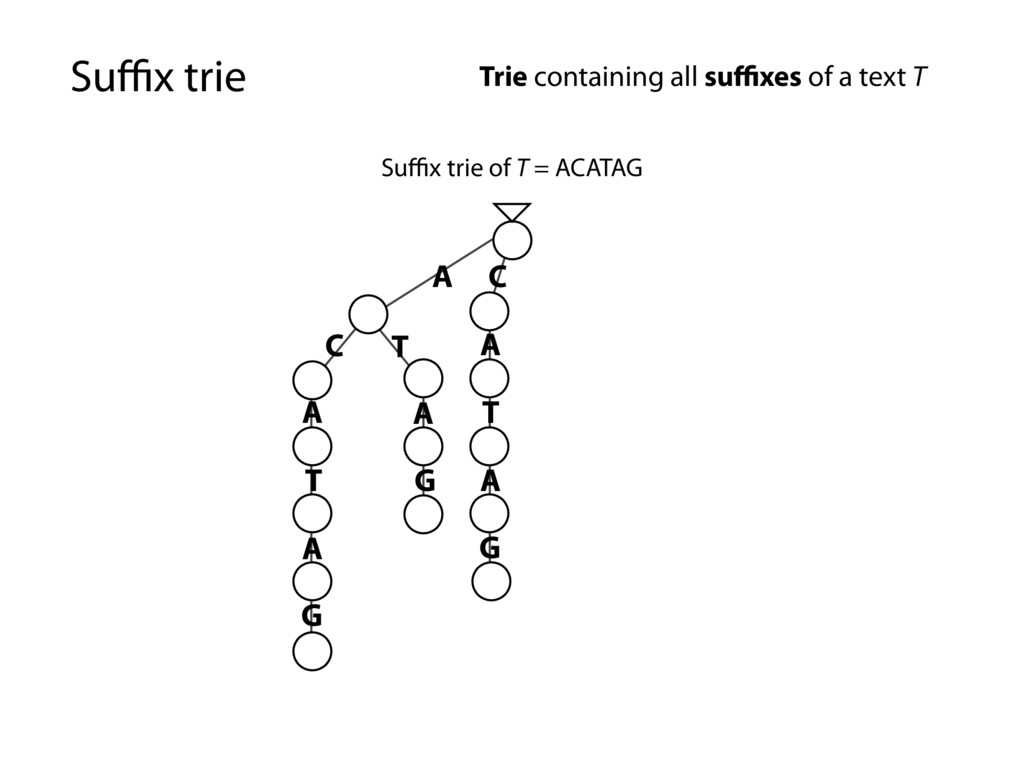
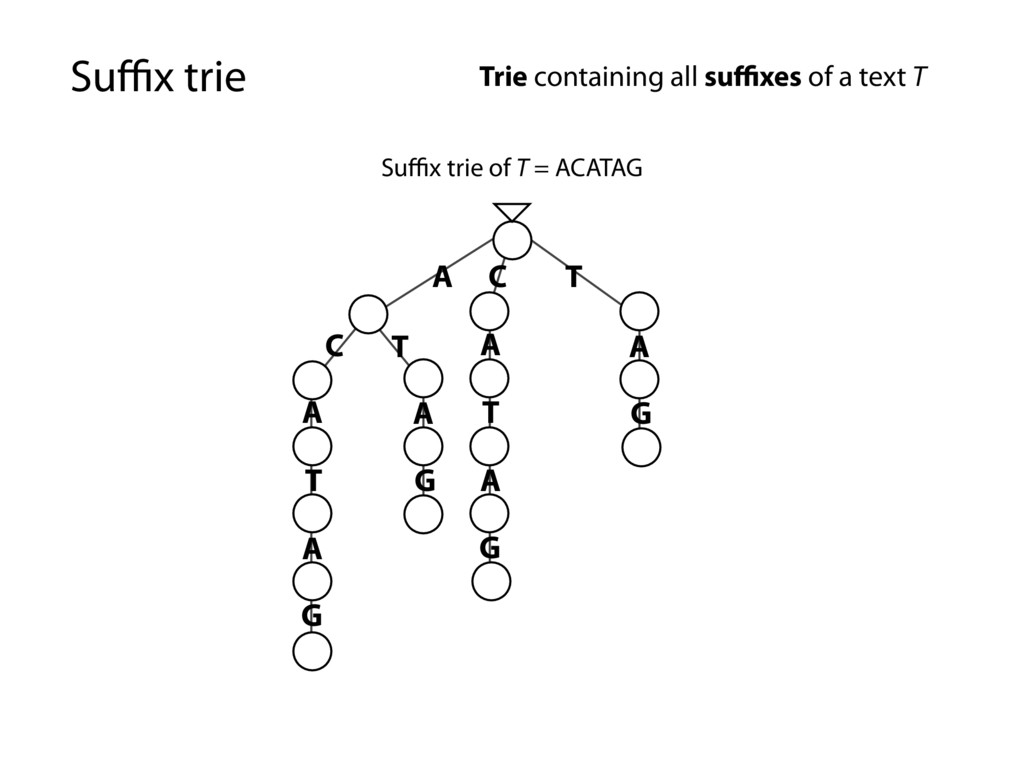
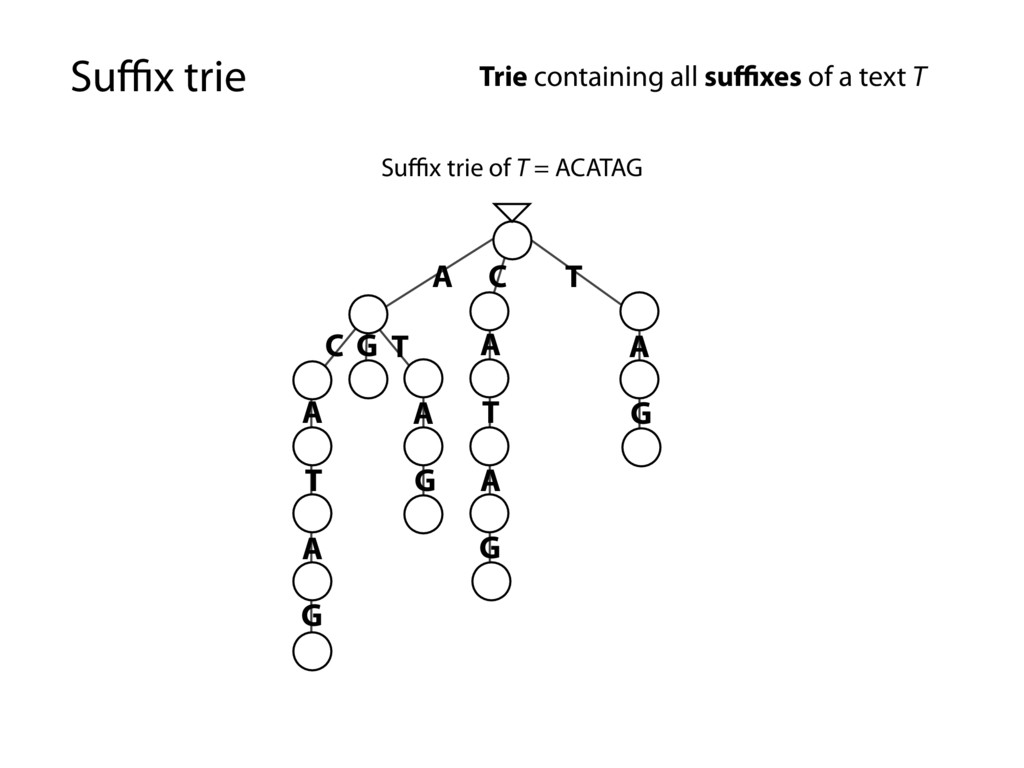
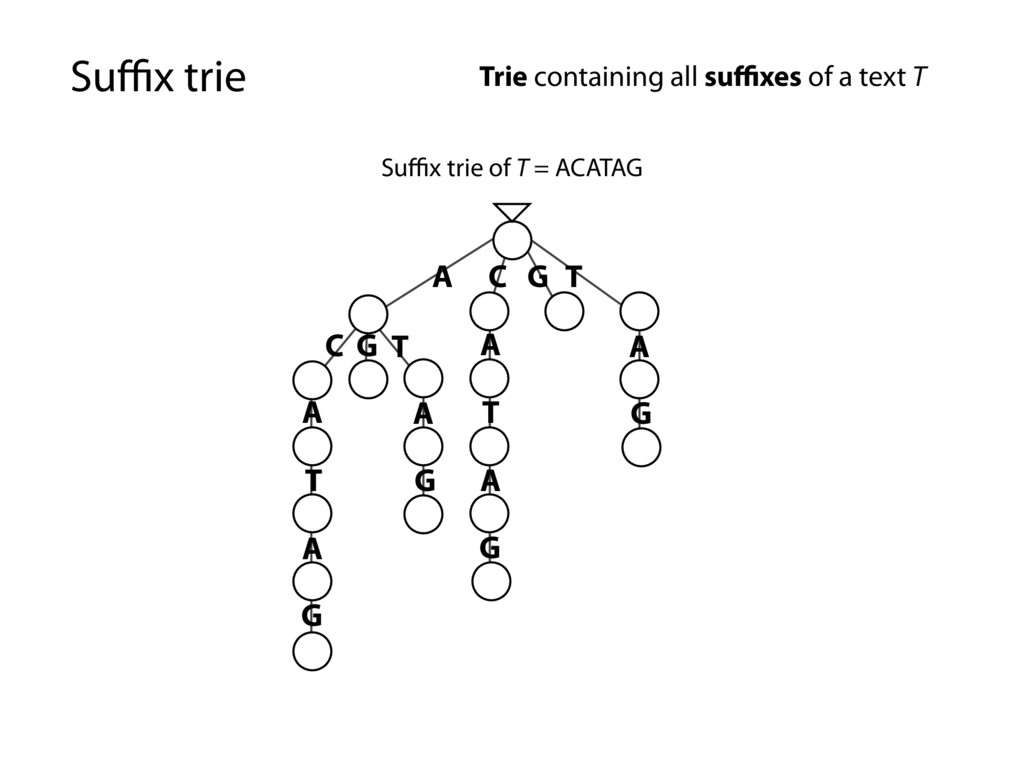
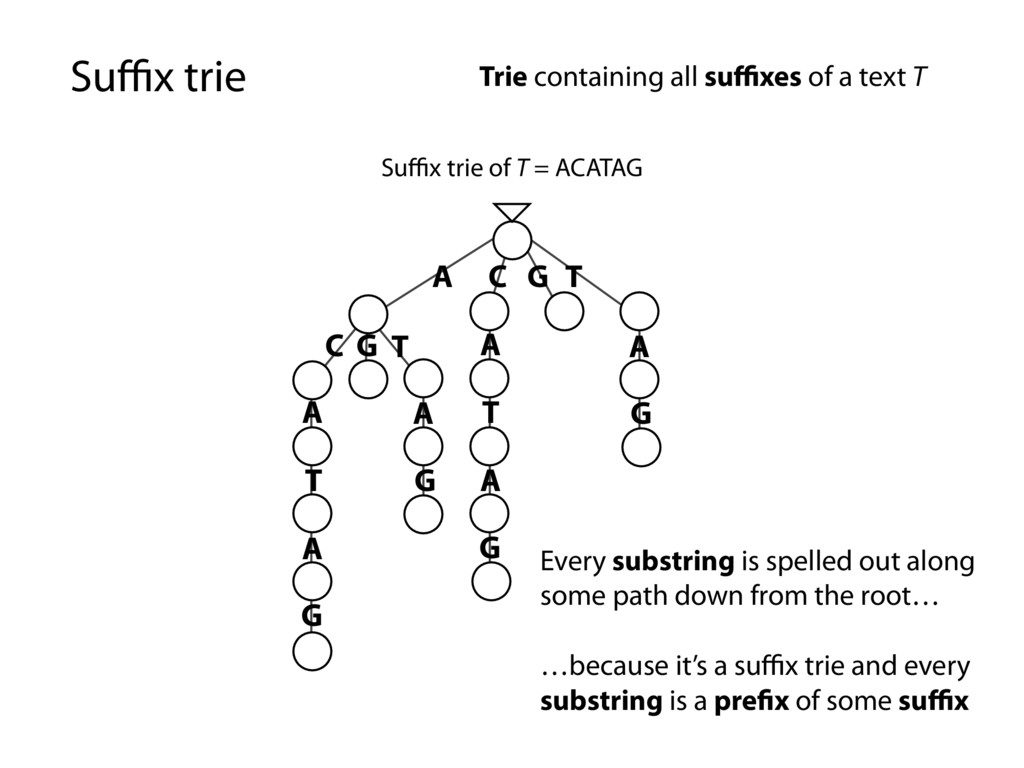
G T A T A G C G T A T A G A G A G Trie containing all suffixes of a text T Every substring is spelled out along some path down from the root… …because it’s a suffix trie and every substring is a prefix of some suffix
G T T A T A G C T G A T C G C G G C G T A G C G G $ G T T A T A G C T G A T C G C G G C G T A G C G G $ T T A T A G C T G A T C G C G G C G T A G C G G $ T A T A G C T G A T C G C G G C G T A G C G G $ A T A G C T G A T C G C G G C G T A G C G G $ T A G C T G A T C G C G G C G T A G C G G $ A G C T G A T C G C G G C G T A G C G G $ G C T G A T C G C G G C G T A G C G G $ C T G A T C G C G G C G T A G C G G $ T G A T C G C G G C G T A G C G G $ G A T C G C G G C G T A G C G G $ A T C G C G G C G T A G C G G $ T C G C G G C G T A G C G G $ C G C G G C G T A G C G G $ G C G G C G T A G C G G $ C G G C G T A G C G G $ G G C G T A G C G G $ G C G T A G C G G $ C G T A G C G G $ G T A G C G G $ T A G C G G $ A G C G G $ G C G G $ C G G $ G G $ G $ $ T: m(m+1)/2 chars quadratic growth
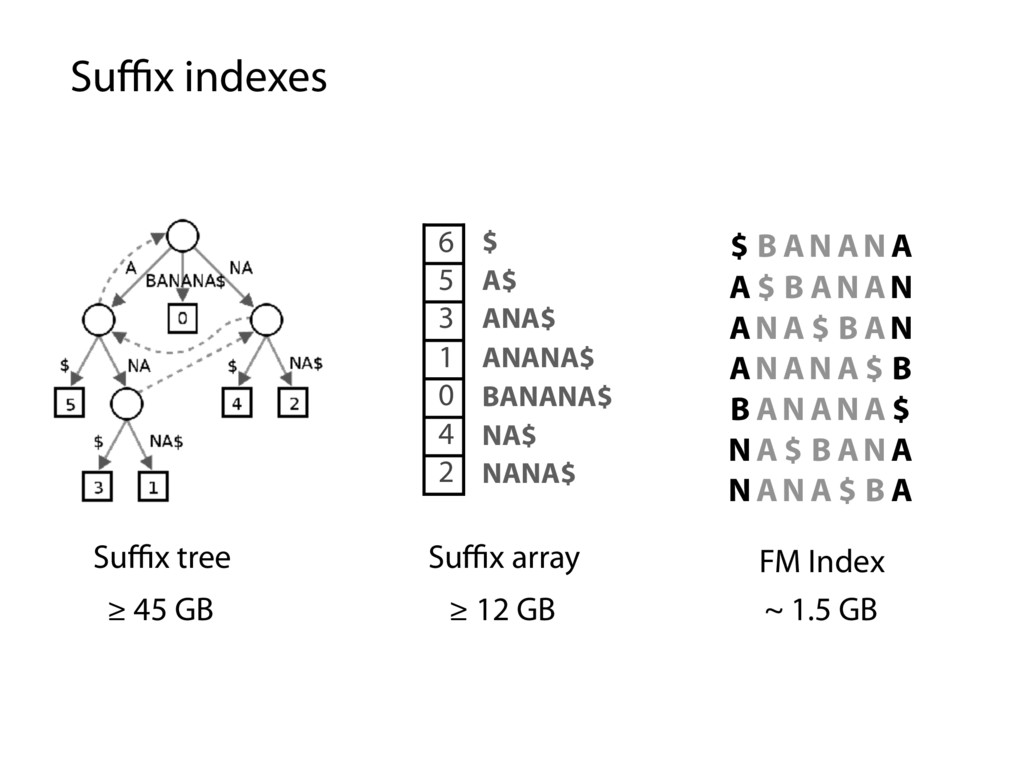
A$ ANA$ ANANA$ BANANA$ NA$ NANA$ Suffix tree Suffix array ≥ 45 GB ≥ 12 GB FM Index $ B AN AN A A $ B AN AN AN A $ B AN AN AN A $ B B AN AN A $ N A $ B AN A N AN A $ B A ~ 1.5 GB
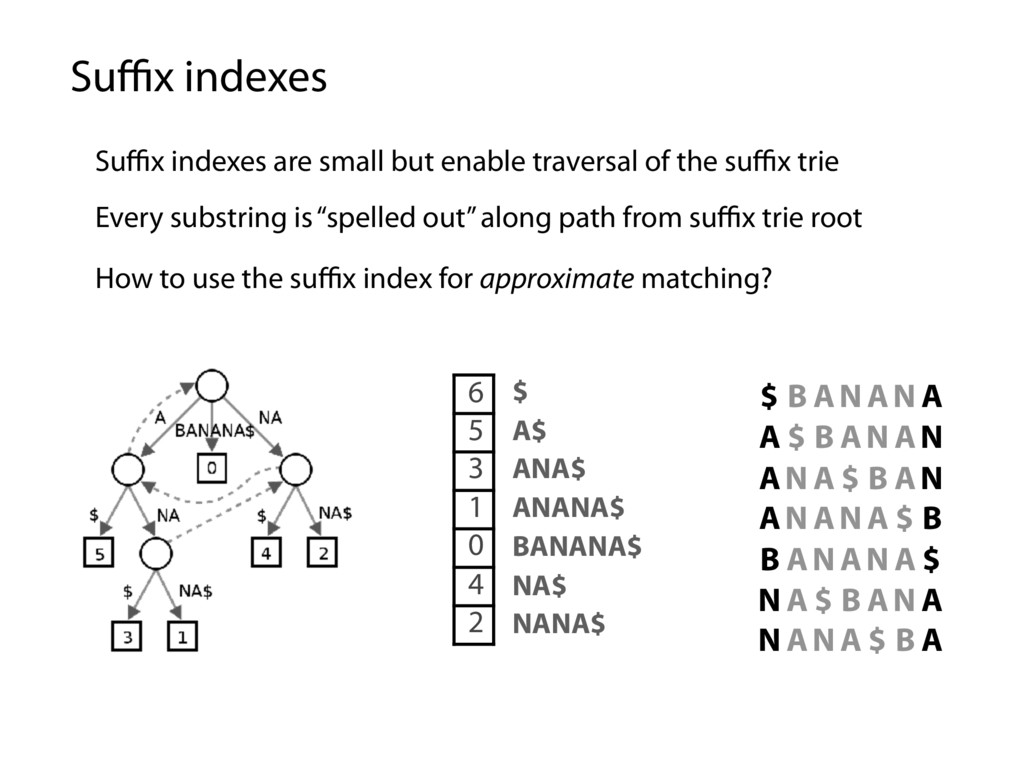
A$ ANA$ ANANA$ BANANA$ NA$ NANA$ $ B AN AN A A $ B AN AN AN A $ B AN AN AN A $ B B AN AN A $ N A $ B AN A N AN A $ B A Suffix indexes are small but enable traversal of the suffix trie Every substring is “spelled out” along path from suffix trie root How to use the suffix index for approximate matching?
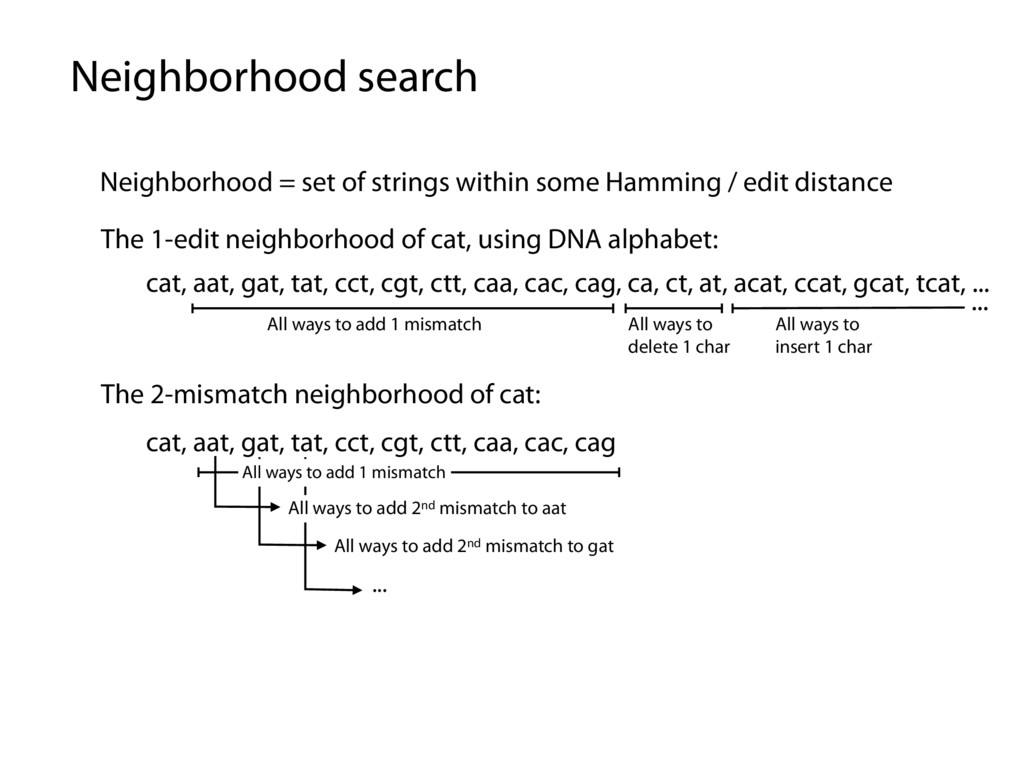
/ edit distance The 1-edit neighborhood of cat, using DNA alphabet: The 2-mismatch neighborhood of cat: cat, aat, gat, tat, cct, cgt, ctt, caa, cac, cag, ca, ct, at, acat, ccat, gcat, tcat, ... All ways to add 1 mismatch All ways to delete 1 char ... All ways to insert 1 char cat, aat, gat, tat, cct, cgt, ctt, caa, cac, cag All ways to add 1 mismatch All ways to add 2nd mismatch to aat All ways to add 2nd mismatch to gat ...
If | P | = n, and | ∑ | = a, how many strings are within Hamming distance 1? 1 + n(a - 1) How many strings are within edit distance 1? 1 + n(a - 1) + n + (n + 1)a P itself a - 1 ways to replace each of P’s n chars Delete each char in P * n + 1 positions where we can insert any of the a characters * In both cases, O(an) strings in the neighborhood * Some insertions are equivalent. E.g. there are two equivalent insertions of ‘a’ into ‘cat’. Likewise deletions (‘caat’).
Within distance k? O(an) strings within Hamming or edit distance 1, each with O(an) neighbors within distance 1, so O(a2n2) O(aknk) How much work to query suffix tree with all strings within distance k? O(n + # occurrences) for each of the O(aknk) strings, so roughly O(aknk+1) Good news: no m. Bad news: exponential in k. Compare to O(aknk+1) to O(mn) for full dynamic programming
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}