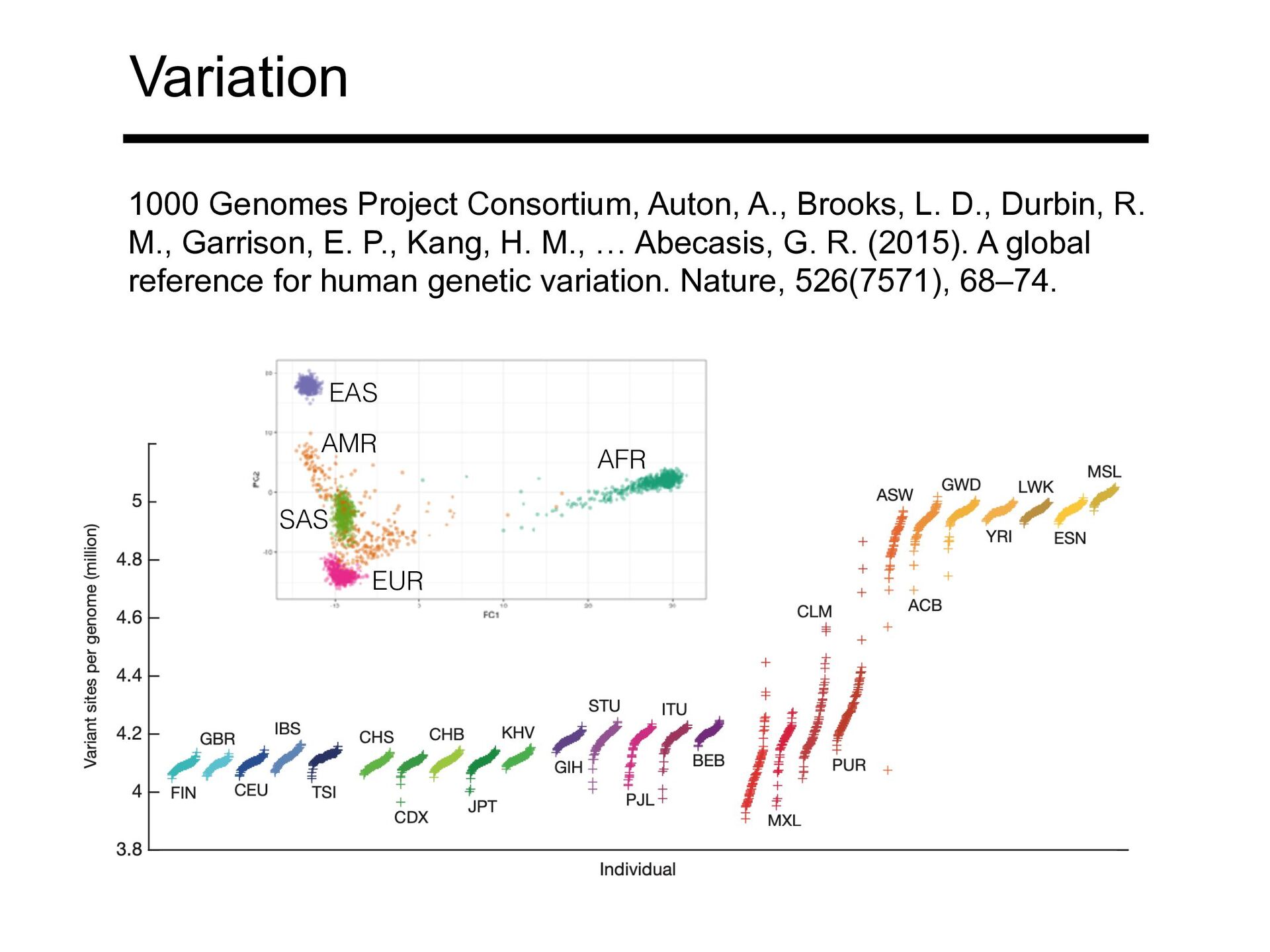
Durbin, R. M., Garrison, E. P., Kang, H. M., … Abecasis, G. R. (2015). A global reference for human genetic variation. Nature, 526(7571), 68–74. AFR EAS AMR EUR SAS
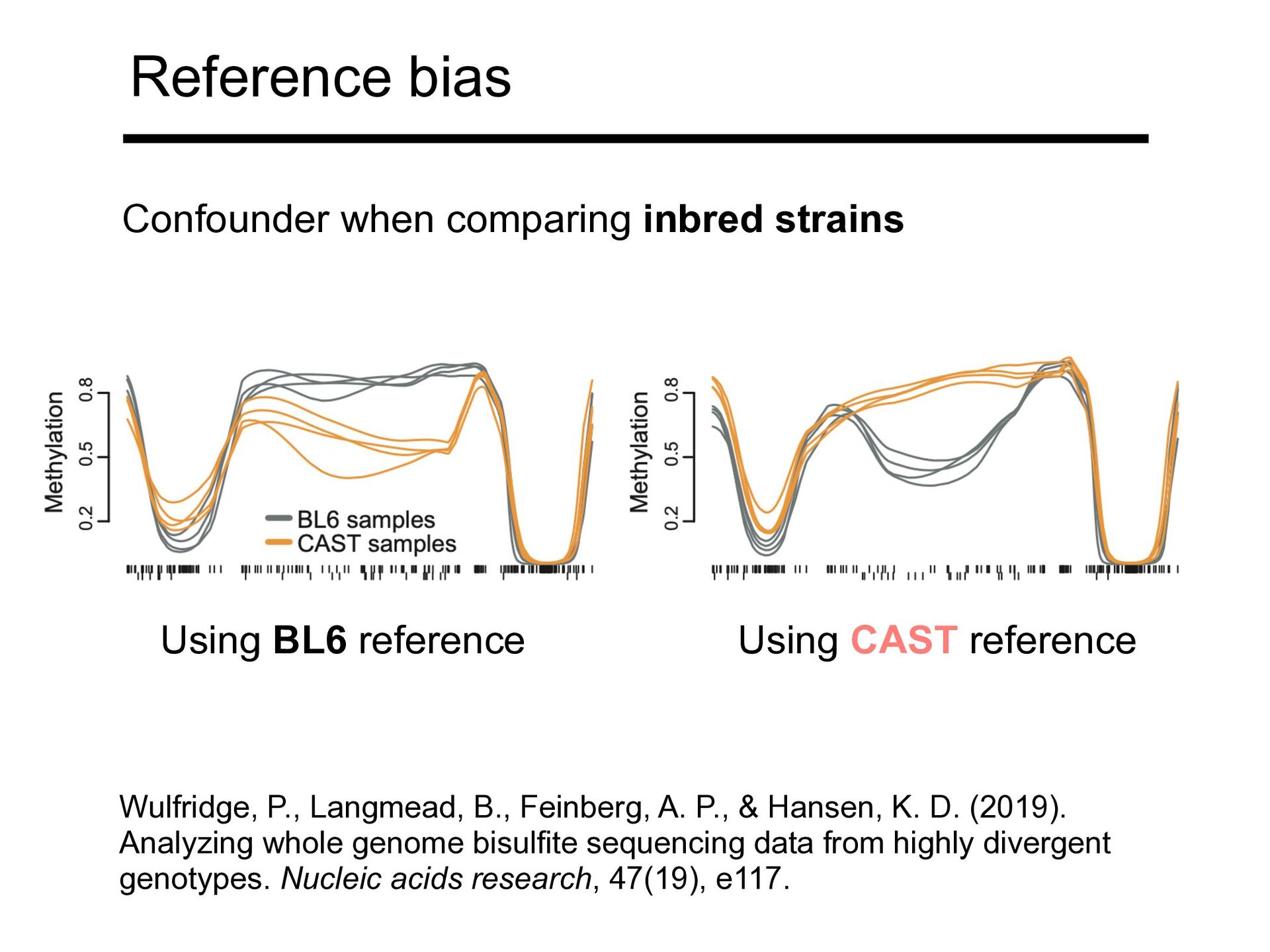
Hansen, K. D. (2019). Analyzing whole genome bisulfite sequencing data from highly divergent genotypes. Nucleic acids research, 47(19), e117. Confounder when comparing inbred strains Using BL6 reference Using CAST reference
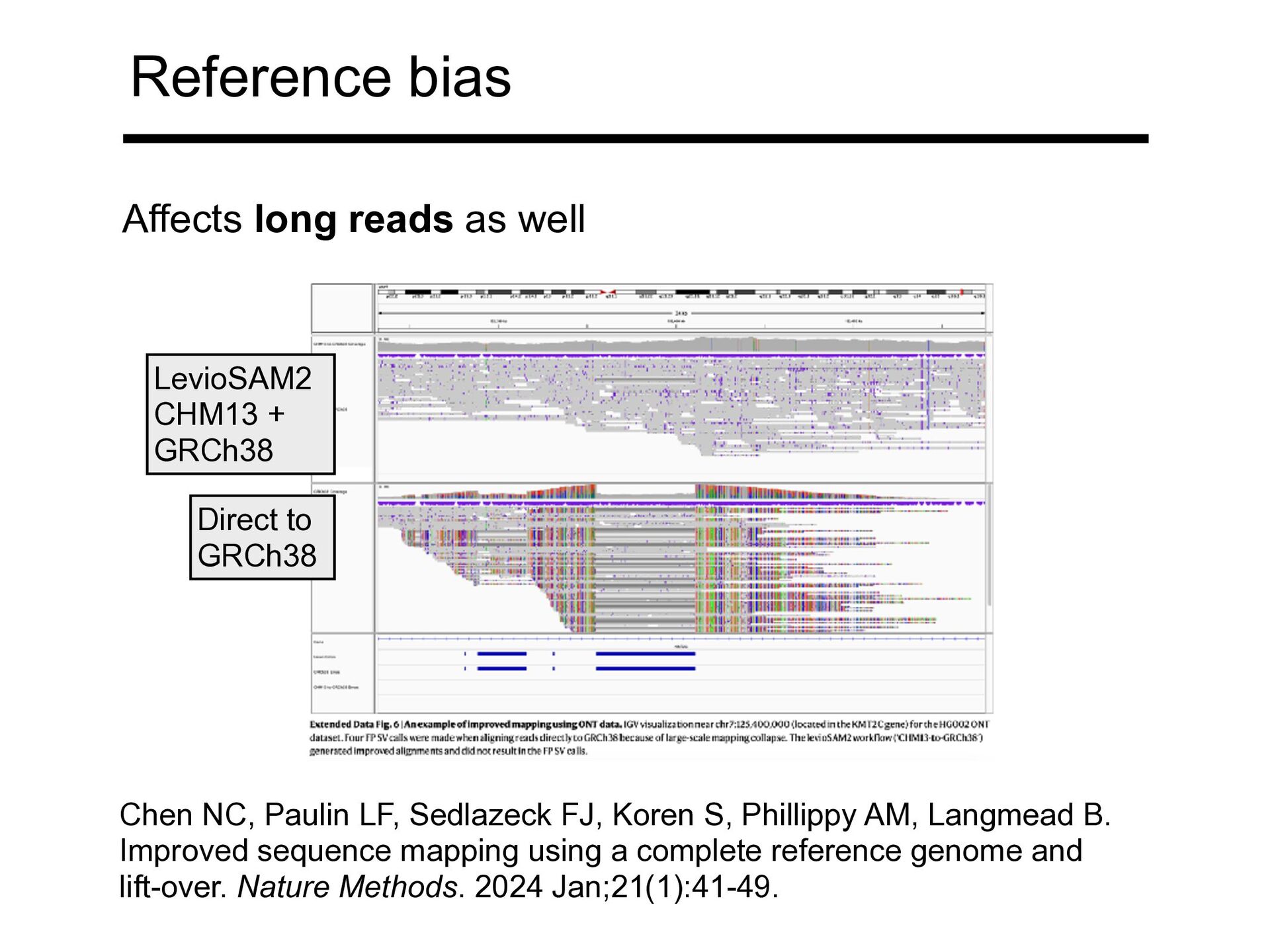
Phillippy AM, Langmead B. Improved sequence mapping using a complete reference genome and lift-over. Nature Methods. 2024 Jan;21(1):41-49. LevioSAM2 CHM13 + GRCh38 Direct to GRCh38 Affects long reads as well
diagnostics & therapeutics are differentially effective by population "...without a more representative reference genome, genetic medicine will never reach some ethnic groups, warns genome scientist Alicia Martin of Mass. General."
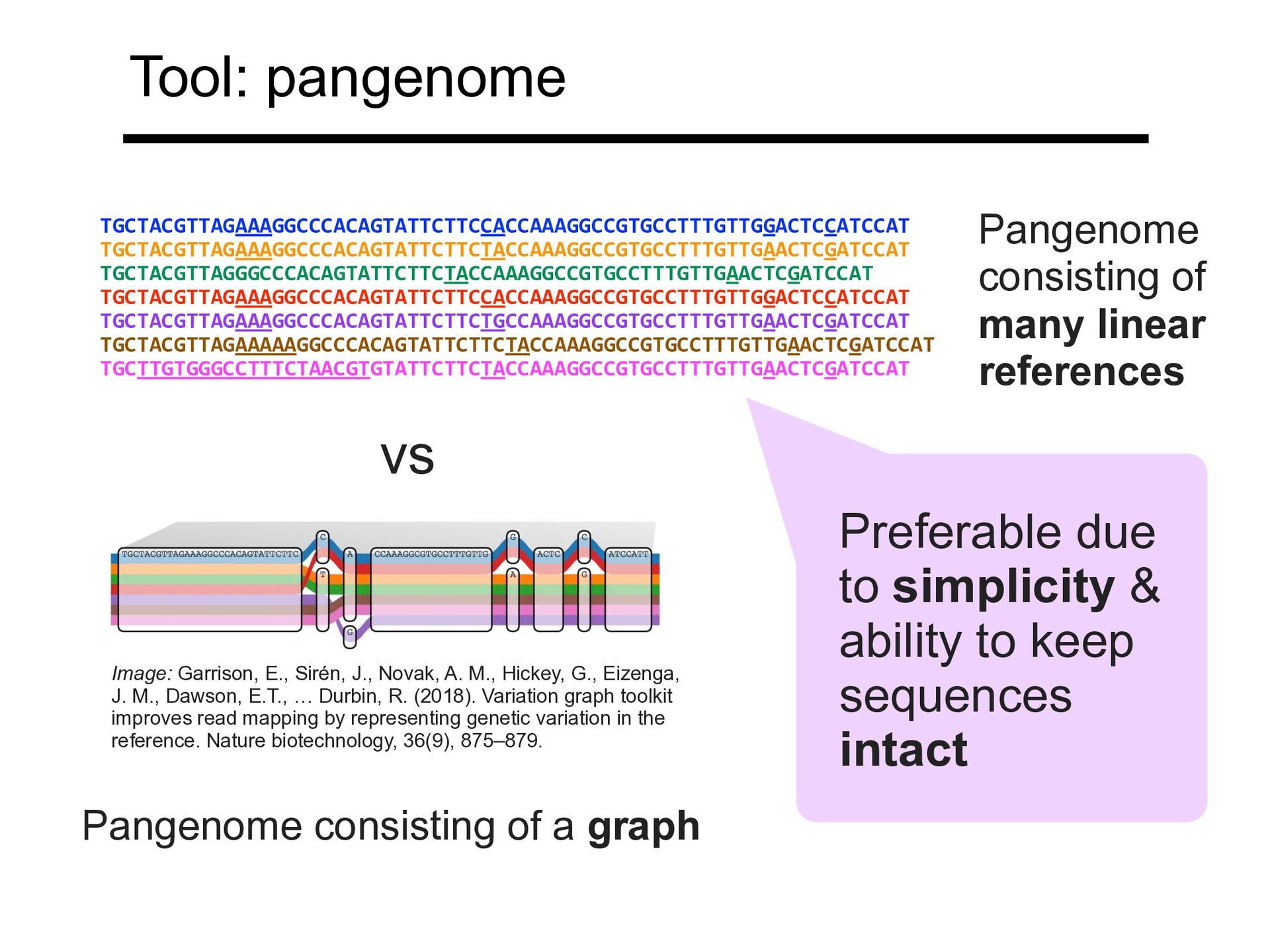
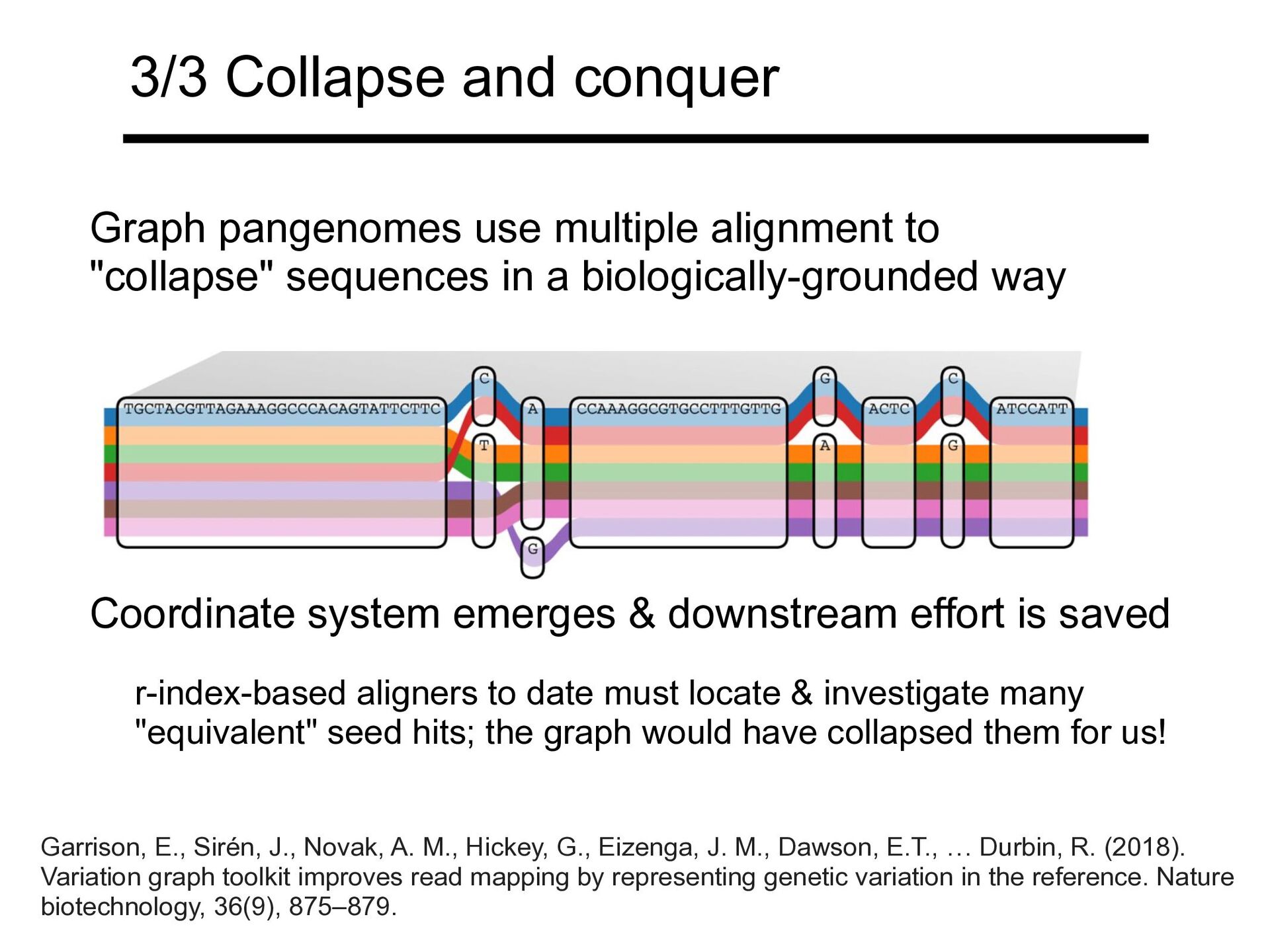
TGCTACGTTAGGGCCCACAGTATTCTTCTACCAAAGGCCGTGCCTTTGTTGAACTCGATCCAT TGCTACGTTAGAAAGGCCCACAGTATTCTTCCACCAAAGGCCGTGCCTTTGTTGGACTCCATCCAT TGCTACGTTAGAAAGGCCCACAGTATTCTTCTGCCAAAGGCCGTGCCTTTGTTGAACTCGATCCAT TGCTACGTTAGAAAAAGGCCCACAGTATTCTTCTACCAAAGGCCGTGCCTTTGTTGAACTCGATCCAT TGCTTGTGGGCCTTTCTAACGTGTATTCTTCTACCAAAGGCCGTGCCTTTGTTGAACTCGATCCAT Image: Garrison, E., Sirén, J., Novak, A. M., Hickey, G., Eizenga, J. M., Dawson, E.T., … Durbin, R. (2018). Variation graph toolkit improves read mapping by representing genetic variation in the reference. Nature biotechnology, 36(9), 875–879. Pangenome consisting of a graph Preferable due to simplicity & ability to keep sequences intact vs
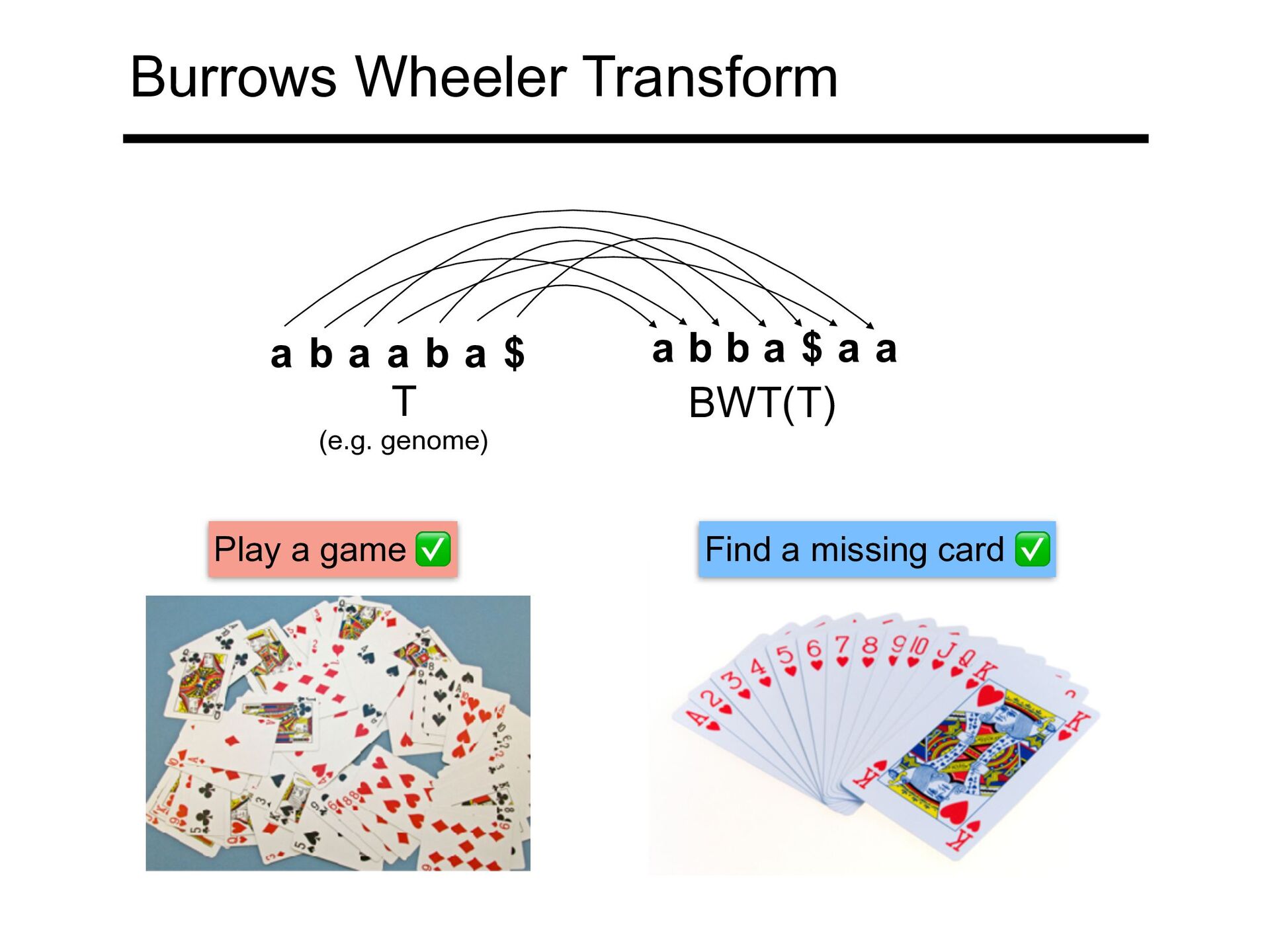
a $ a b b a $ a a BWT reorders T's letters according to the alphabetical order of their right contexts in T (e.g. genome) Ferragina P, and Manzini M. Opportunistic data structures with applications. Proceedings of 41st FOCS. IEEE, 2000.
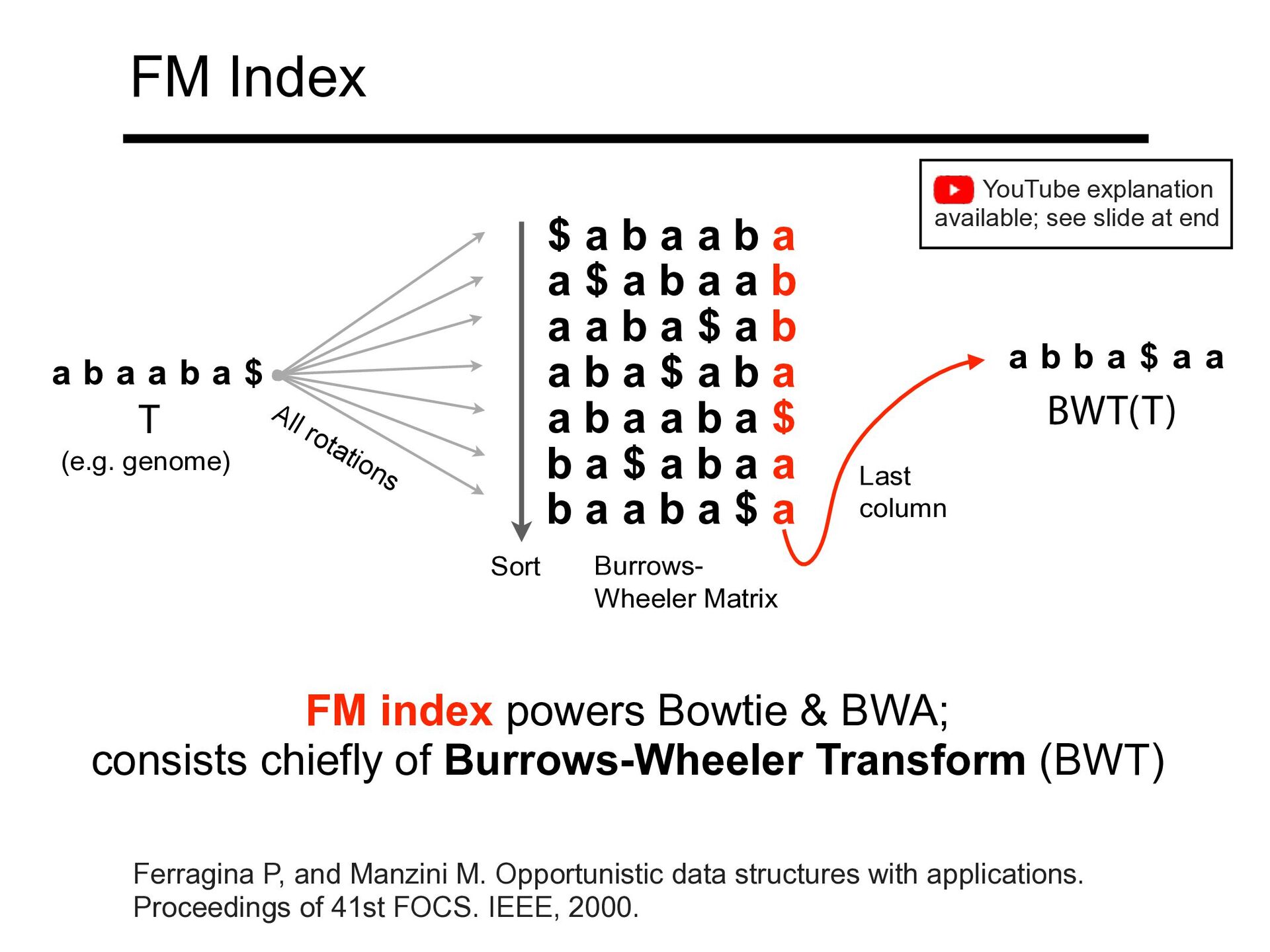
$ a b a a b a a b a $ a b a b a $ a b a a b a a b a $ b a $ a b a a b a a b a $ a T All rotations Sort BWT(T) Last column Burrows- Wheeler Matrix a b a a b a $ a b b a $ a a FM index powers Bowtie & BWA; consists chiefly of Burrows-Wheeler Transform (BWT) (e.g. genome) Ferragina P, and Manzini M. Opportunistic data structures with applications. Proceedings of 41st FOCS. IEEE, 2000. YouTube explanation available; see slide at end
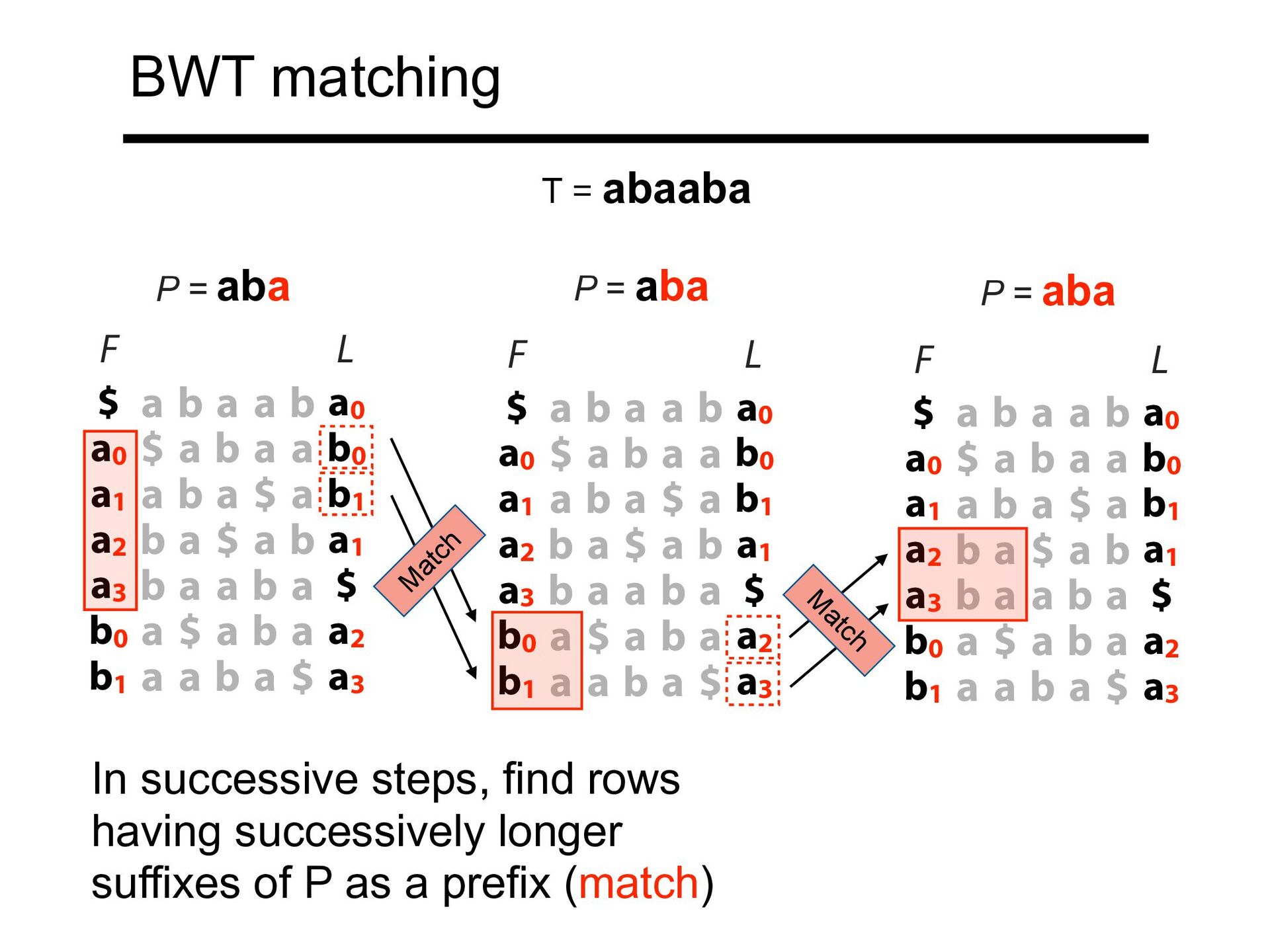
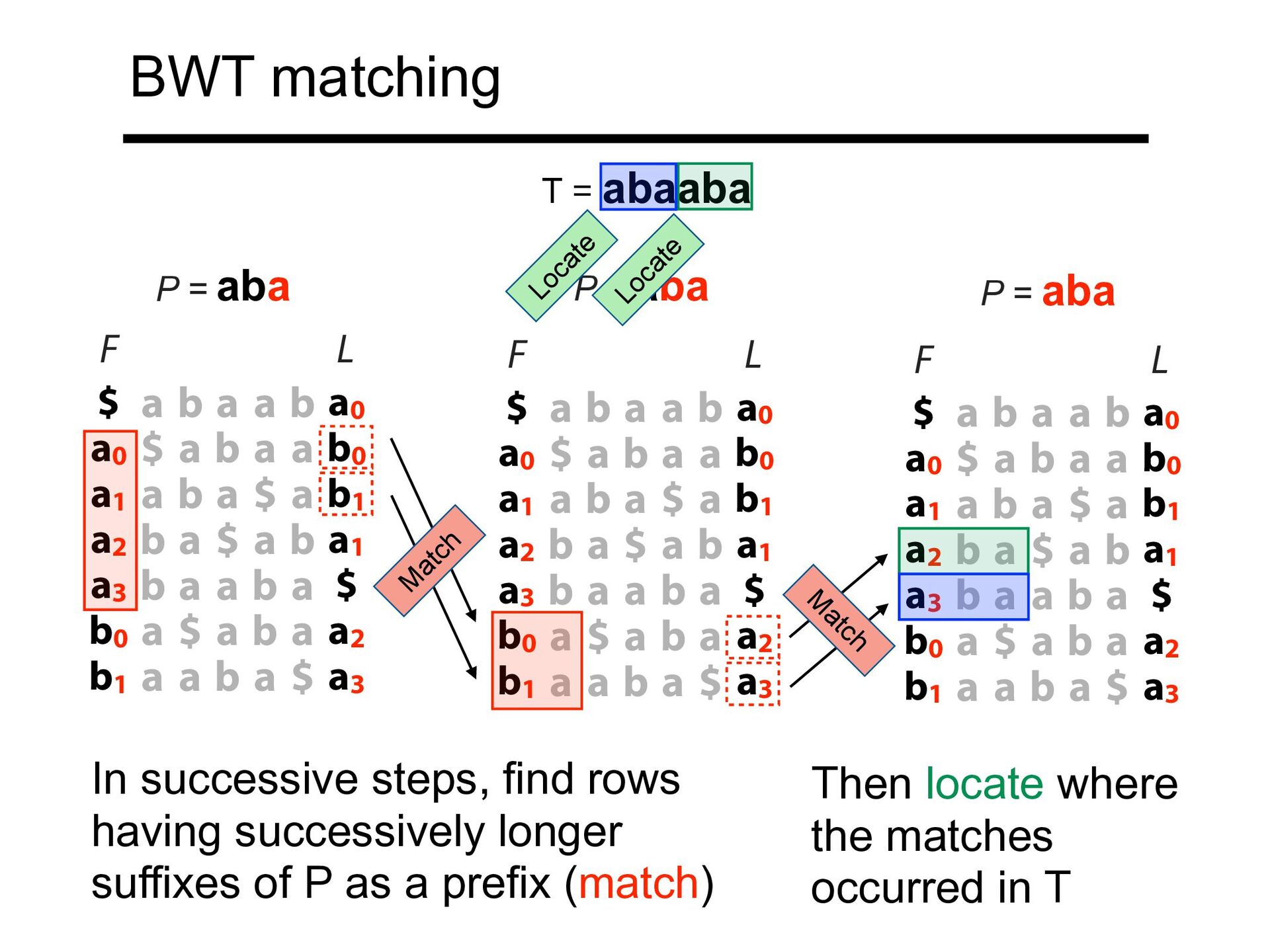
$ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F L P = aba aba L $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F P = aba $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F L P = aba T = abaaba M atch M atch In successive steps, find rows having successively longer suffixes of P as a prefix (match)
BWT matching $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F L L $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F In successive steps, find rows having successively longer suffixes of P as a prefix (match) $ a b a a b a0 a0 $ a b a a b0 a1 a b a $ a b1 a2 b a $ a b a1 a3 b a a b a $ b0 a $ a b a a2 b1 a a b a $ a3 F L T = abaaba M atch M atch Locate Locate Then locate where the matches occurred in T
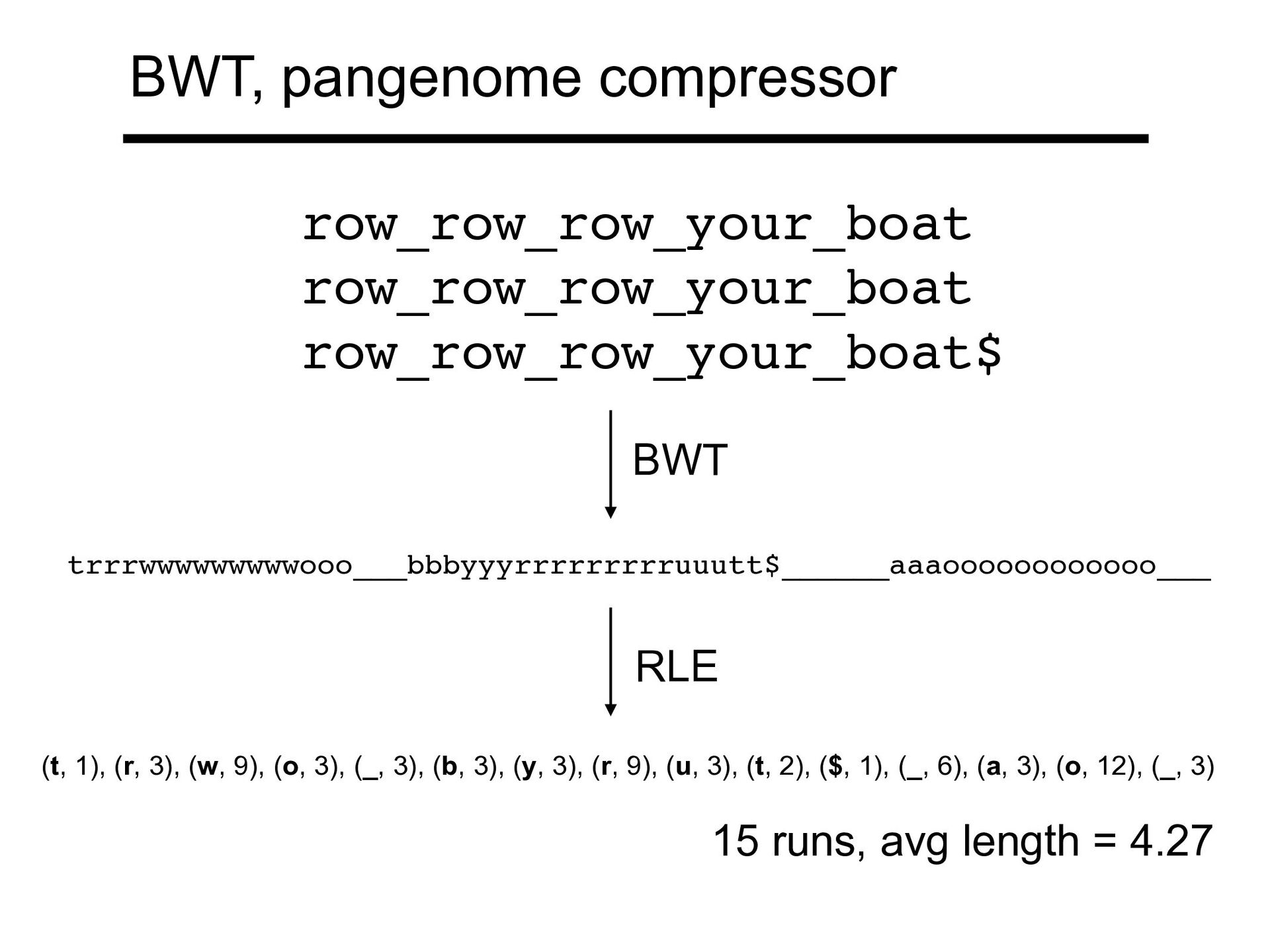
eetlejuice is always preceded by b These b's come together in a BWT run T beetlejuice_beetlejuice_beetlejuice$ BWT(T) eee__$iiicccbbbllleeeuuueeettteeejjj BWT, pangenome compressor
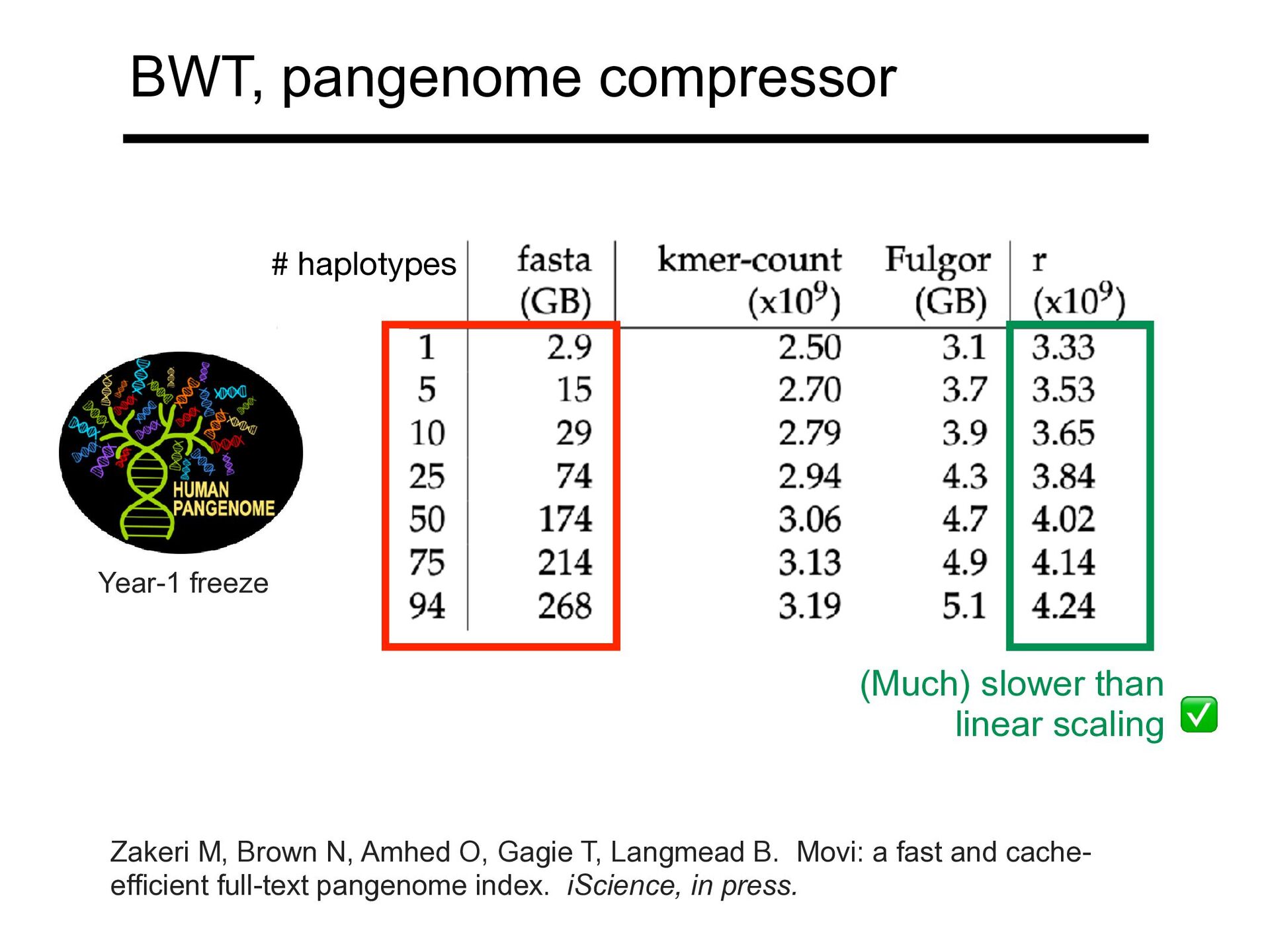
Zakeri M, Brown N, Amhed O, Gagie T, Langmead B. Movi: a fast and cache- efficient full-text pangenome index. iScience, in press. ✅ # haplotypes Year-1 freeze
BWT runs Ind. build Project strains (n, billions) (r, billions) n/r time Human, 1kGenomes* 1 2,504 7,710 2.82 2,730 † Human, HPRC 2 95 573 4.24 135 11h06m Yeast 3 142 3.87 0.059 65.3 11m08s Maize 4 27 119 2.82 42.3 10h31m Arabidopsis 5 69 18.7 0.445 42.0 1h20m Potato 6 88 90.3 2.99 30.2 7h36m 1. 1000 Genomes Project Consortium. A global reference for human genetic variation. Nature. 2015 Oct 1;526(7571):68-74 2. Human Pangenome Reference Consortium. A draft human pangenome reference. Nature. 2023 May ;617(7960):312-324. 3. O'Donnell S, Yue JX, Saada OA et al. T2T assemblies of 142 strains characterize the genome structural landscape in Saccharomyces cerevisiae. Nat Genet. 2023 Aug;55(8):1390-1399. 4. Hufford MB, Seetharam AS, Woodhouse MR et al. De novo assembly, annotation, and comparative analysis of 26 diverse maize genomes. Science. 2021 Aug 6;373(6555):655-662. 5. Lian Q, Huettel B, Walkemeier B et al. A pan-genome of 69 Arabidopsis thaliana accessions reveals a conserved genome structure throughout the global species range. Nat Genet. 2024 May;56(5):982-991. 6: Tang D, Jia Y, Zhang J, et al. Genome evolution and diversity of wild and cultivated potatoes. Nature. 2022 Jun;606(7914):535-541.
applications. Proceedings of 41st FOCS. IEEE, 2000. BWT, pangenome indexer Match Locate FM Index (2000) Where = # characters, is # BWT runs n r O(n) O(n) Needed: indexes that grow with i.e. use space and handle our favorite queries r O(r) (Big-Os omit some minor terms)
(2005) O(n) O(n) RLFM: Mäkinen V, and Navarro G. Succinct suffix arrays based on run-length encoding. Annual Symposium on CPM. Springer, Berlin, Heidelberg. 2005. pp45–56. O(r) O(n) Needed: indexes that grow with i.e. use space and handle our favorite queries r O(r) FM: Ferragina P, and Manzini M. Opportunistic data structures with applications. Proceedings of 41st FOCS. IEEE, 2000. Where = # characters, is # BWT runs n r (Big-Os omit some minor terms)
(2005) O(n) O(n) RLFM: Mäkinen V, and Navarro G. Succinct suffix arrays based on run-length encoding. Annual Symposium on CPM. Springer, Berlin, Heidelberg. 2005. pp45–56. O(r) O(n) Needed: indexes that grow with i.e. use space and handle our favorite queries r O(r) FM: Ferragina P, and Manzini M. Opportunistic data structures with applications. Proceedings of 41st FOCS. IEEE, 2000. Where = # characters, is # BWT runs n r (Big-Os omit some minor terms)
indexing in BWT-runs bounded space. Proceedings of 29th SODA, ACM-SIAM. 2018. pp1459—1477. RLFM: Mäkinen V, and Navarro G. Succinct suffix arrays based on run-length encoding. Annual Symposium on CPM. Springer, Berlin, Heidelberg. 2005. pp45–56. FM: Ferragina P, and Manzini M. Opportunistic data structures with applications. Proceedings of 41st FOCS. IEEE, 2000. BWT, pangenome indexer Match Locate FM Index (2000) RLFM Index (2005) r-index (2018) O(n) O(r) O(r) O(n) O(n) O(r) Needed: indexes that grow with i.e. use space and handle our favorite queries r O(r) Where = # characters, is # BWT runs n r (Big-Os omit some minor terms)
in BWT-runs bounded space. Proceedings of 29th SODA, ACM-SIAM. 2018. pp1459—1477. BWT, pangenome indexer Via "toehold lemma" Image from: Cobas D, Gagie T, and Navarro G. "A Fast and Small Subsampled R-Index." 32nd Annual Symposium on Combinatorial Pattern Matching. 2021. Policriti A, and Prezza N. "From LZ77 to the Run-Length Encoded Burrows-Wheeler Transform, and Back." 28th Annual Symposium on Combinatorial Pattern Matching. 2017. YouTube explanation available; see slide at end
indexing in BWT-runs bounded space. Proceedings of 29th SODA, ACM-SIAM. 2018. pp1459—1477. RLFM: Mäkinen V, and Navarro G. Succinct suffix arrays based on run-length encoding. Annual Symposium on CPM. Springer, Berlin, Heidelberg. 2005. pp45–56. FM: Ferragina P, and Manzini M. Opportunistic data structures with applications. Proceedings of 41st FOCS. IEEE, 2000. BWT, pangenome indexer Match Locate FM Index (2000) RLFM Index (2005) r-index (2018) O(n) O(r) O(r) O(n) O(n) O(r) ✅ Needed: indexes that grow with i.e. use space and handle our favorite queries r O(r) Where = # characters, is # BWT runs n r (Big-Os omit some minor terms)
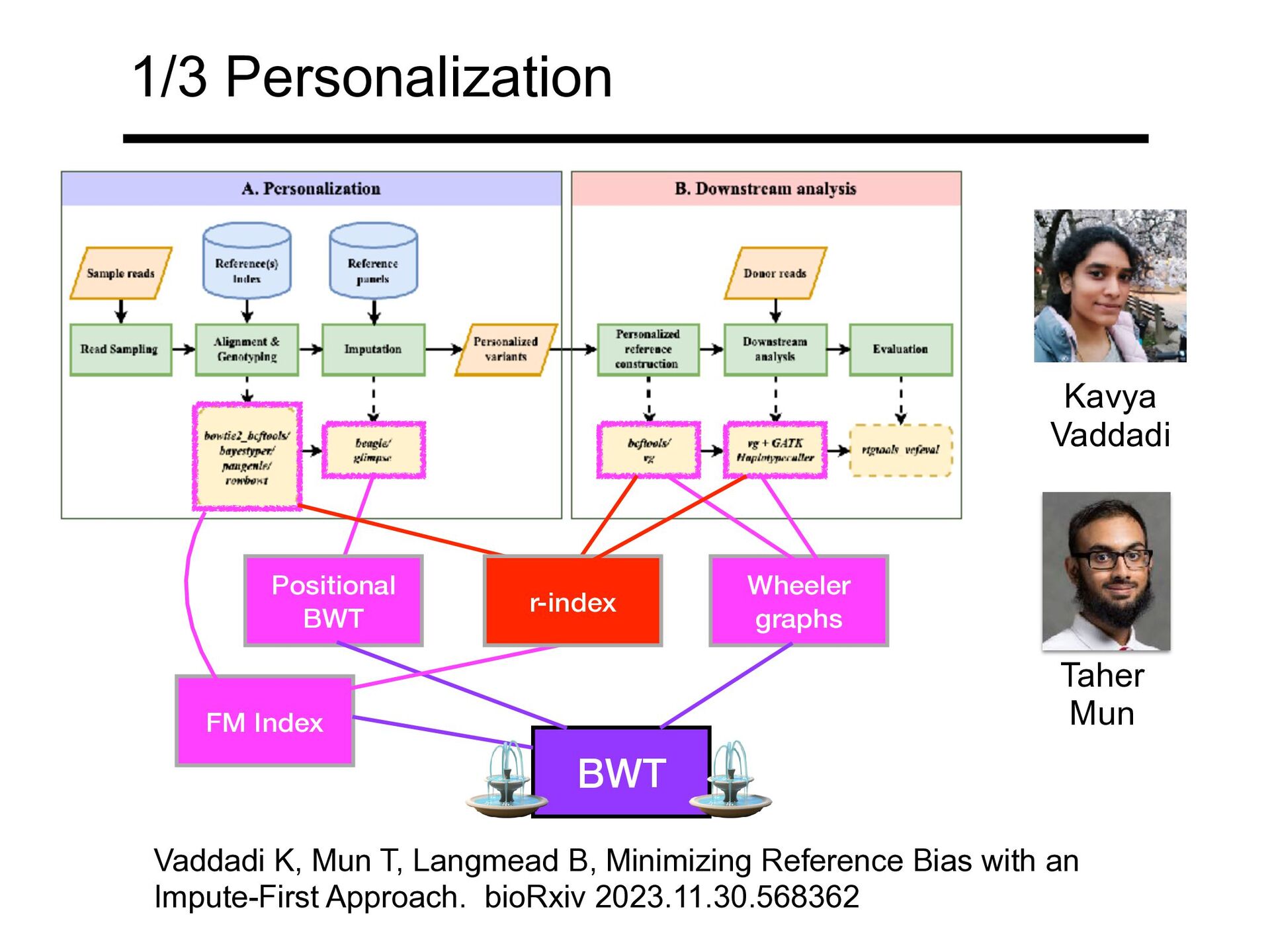
allows for indexing a human pangenome Christina Boucher Travis Gagie Alan Kuhnle Giovanni Manzini Kuhnle A, Mun T, Boucher C, Gagie T, Langmead B, Manzini G. Efficient Construction of a Complete Index for Pan-Genomics Read Alignment. Journal of Computational Biology. 2020 Apr;27(4):500-513. Taher Mun Boucher C, Gagie T, Kuhnle A, Langmead B, Manzini G, Mun T. Prefix-free parsing for building big BWTs. Algorithms for Molecular Biology. 2019 May 24;14:13.
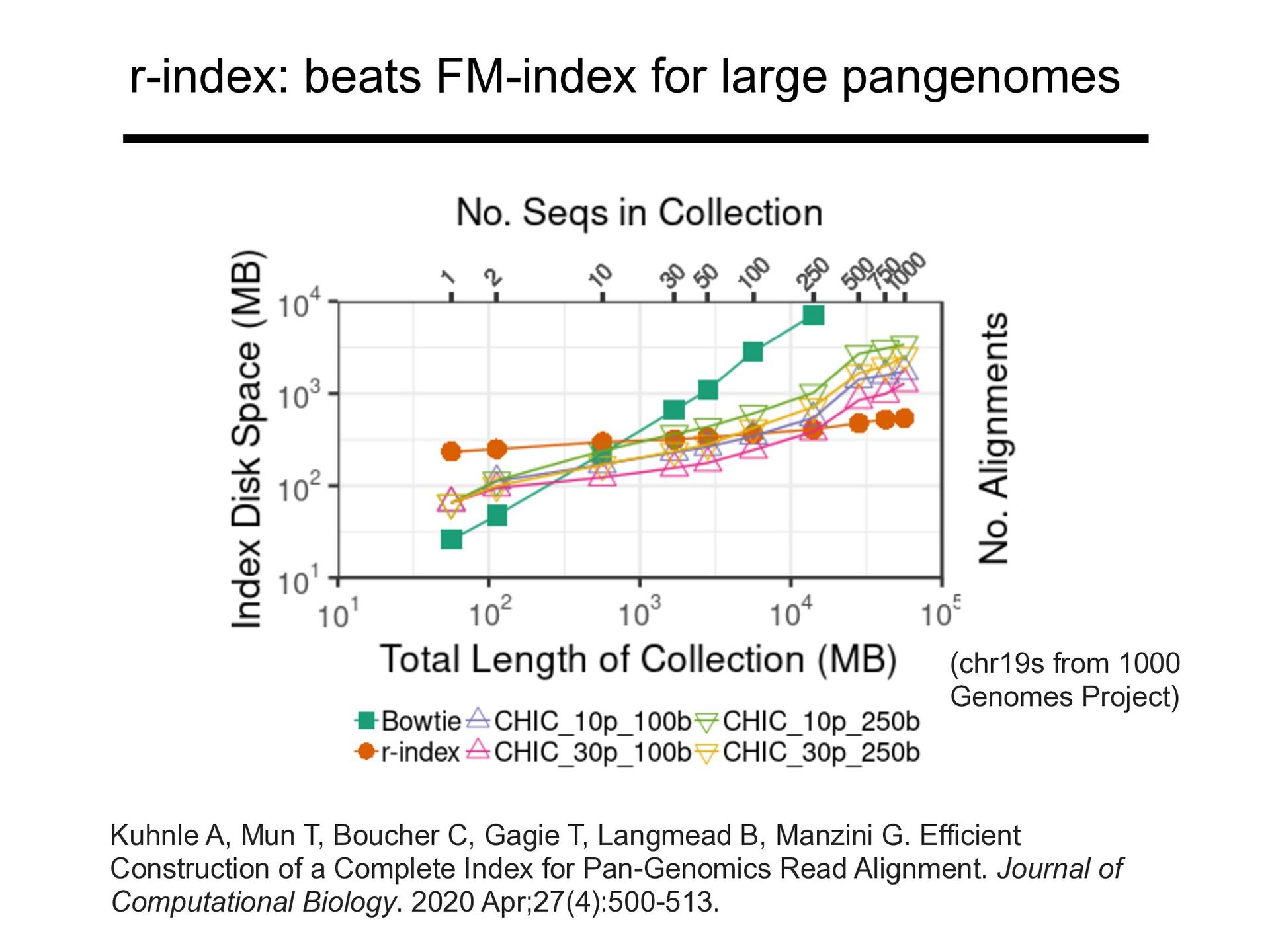
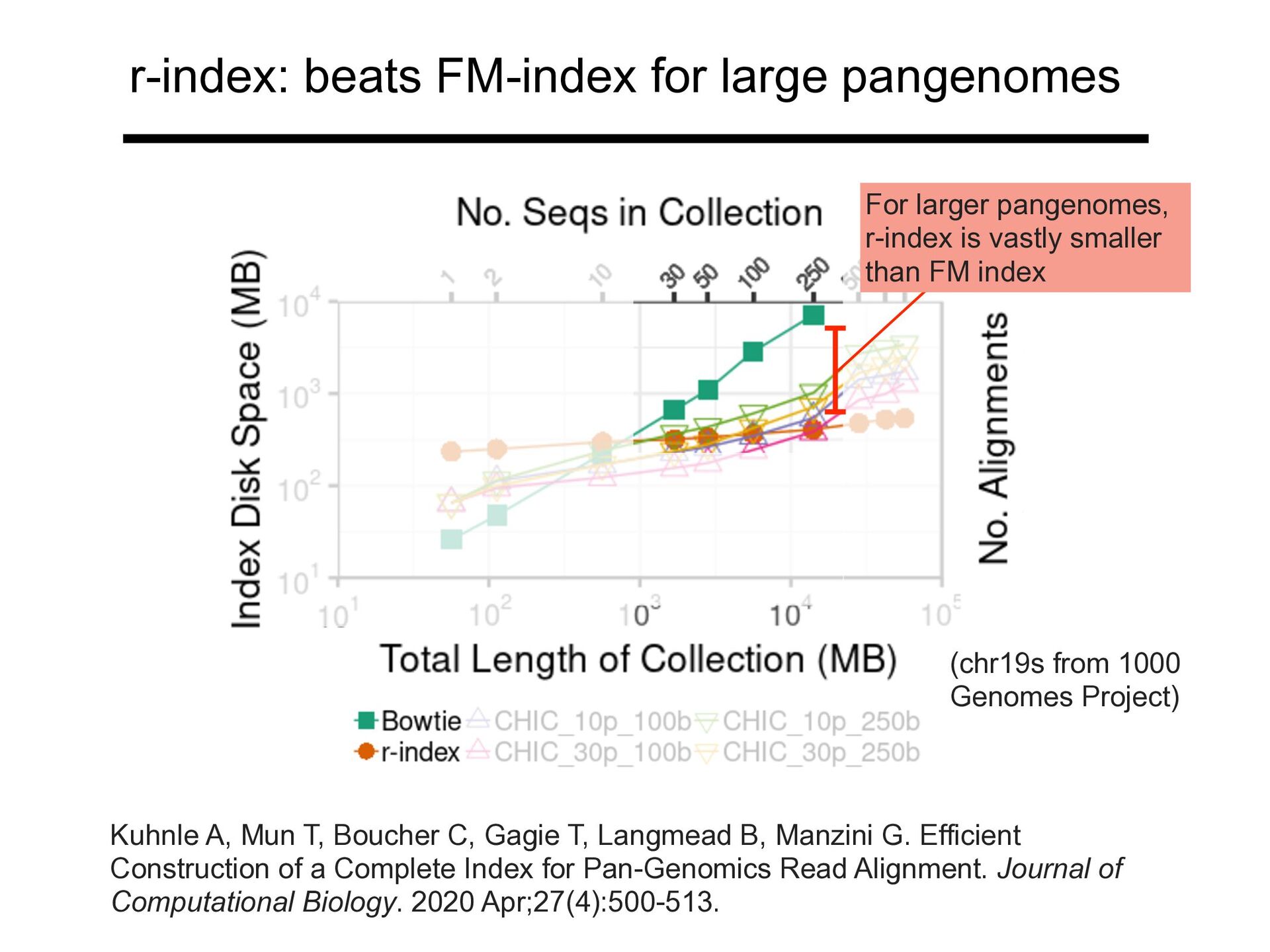
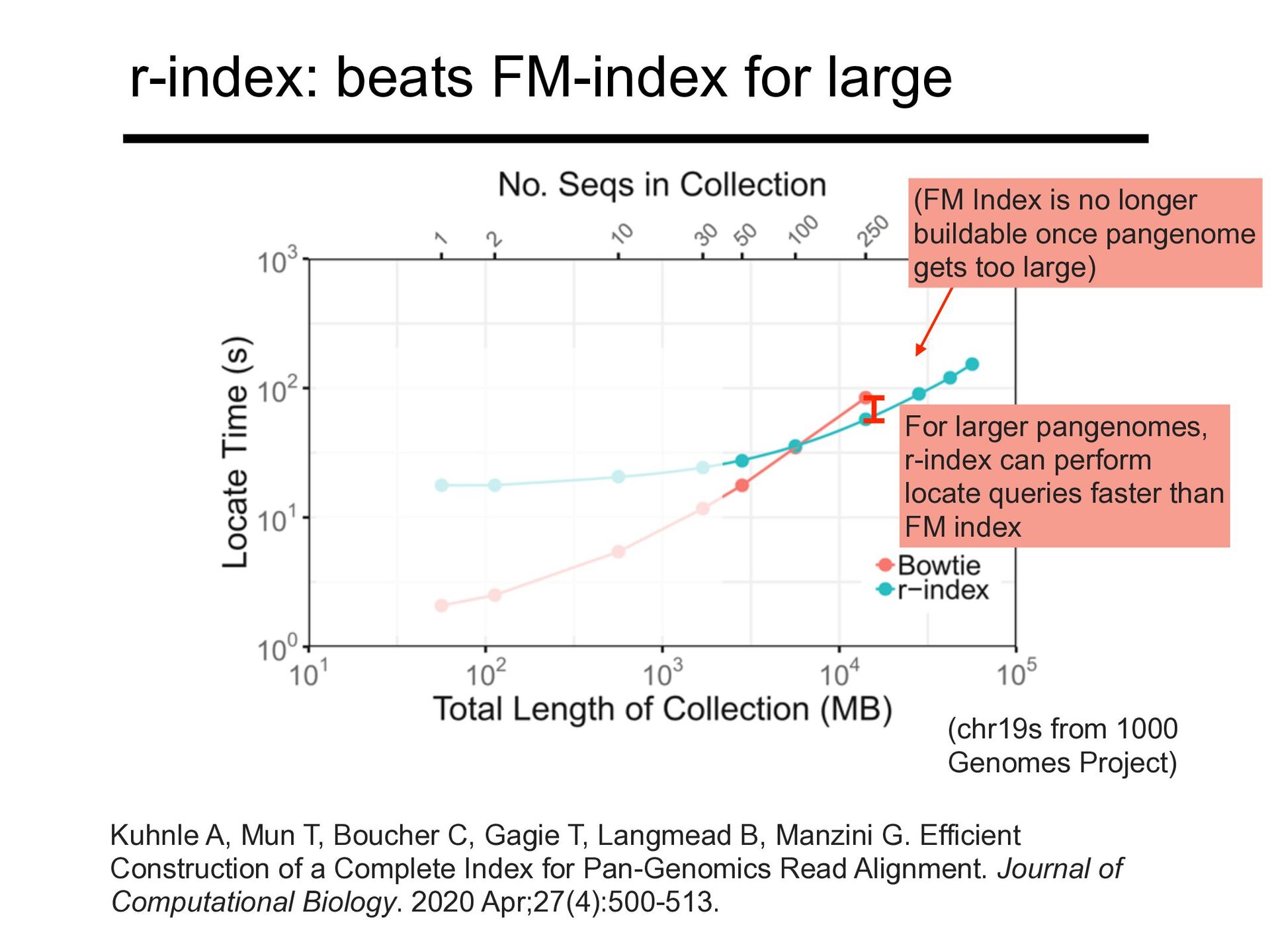
Project) Kuhnle A, Mun T, Boucher C, Gagie T, Langmead B, Manzini G. Efficient Construction of a Complete Index for Pan-Genomics Read Alignment. Journal of Computational Biology. 2020 Apr;27(4):500-513.
Project) For larger pangenomes, r-index is vastly smaller than FM index Kuhnle A, Mun T, Boucher C, Gagie T, Langmead B, Manzini G. Efficient Construction of a Complete Index for Pan-Genomics Read Alignment. Journal of Computational Biology. 2020 Apr;27(4):500-513.
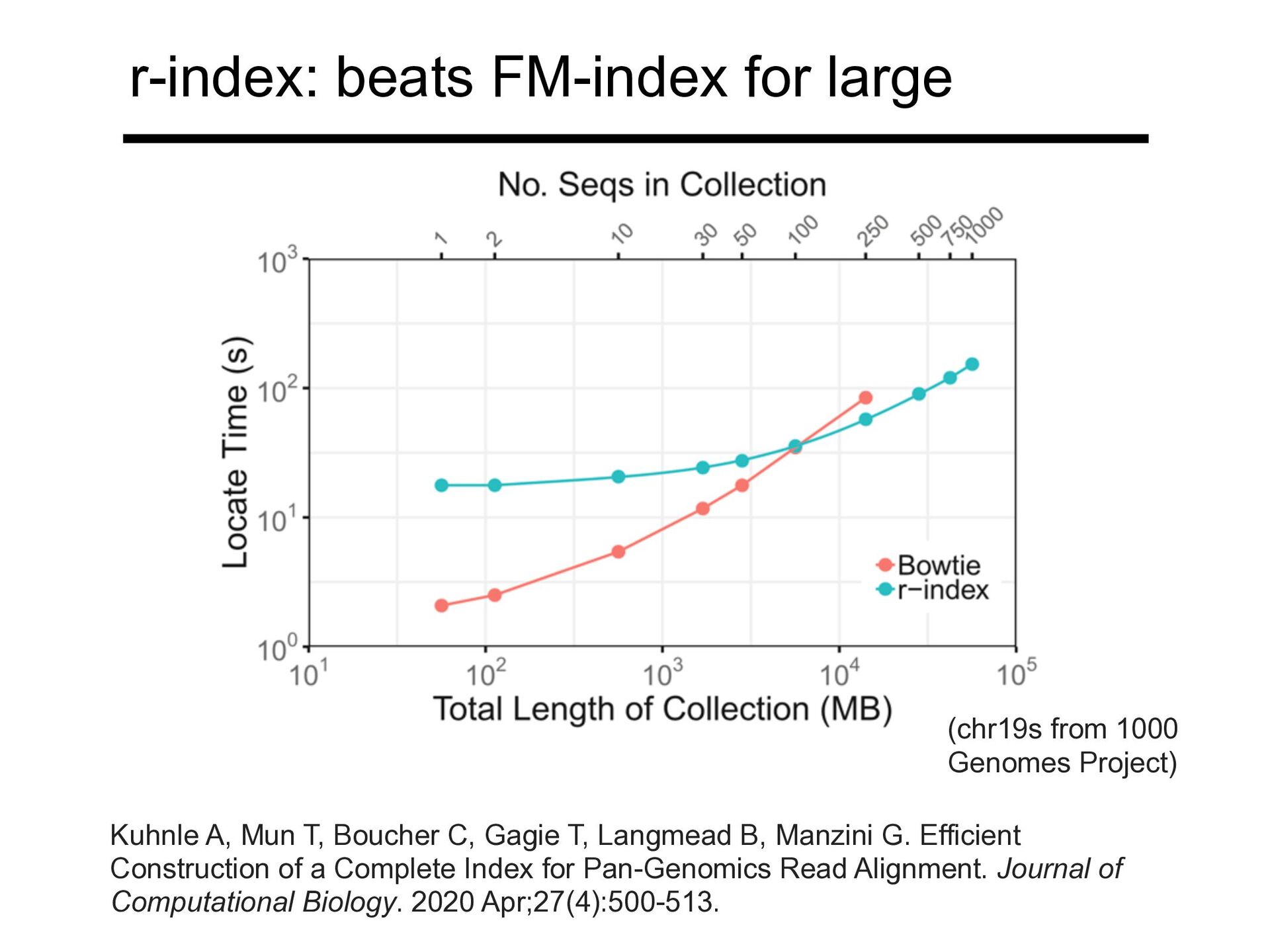
Kuhnle A, Mun T, Boucher C, Gagie T, Langmead B, Manzini G. Efficient Construction of a Complete Index for Pan-Genomics Read Alignment. Journal of Computational Biology. 2020 Apr;27(4):500-513.
For larger pangenomes, r-index can perform locate queries faster than FM index Kuhnle A, Mun T, Boucher C, Gagie T, Langmead B, Manzini G. Efficient Construction of a Complete Index for Pan-Genomics Read Alignment. Journal of Computational Biology. 2020 Apr;27(4):500-513. (FM Index is no longer buildable once pangenome gets too large)
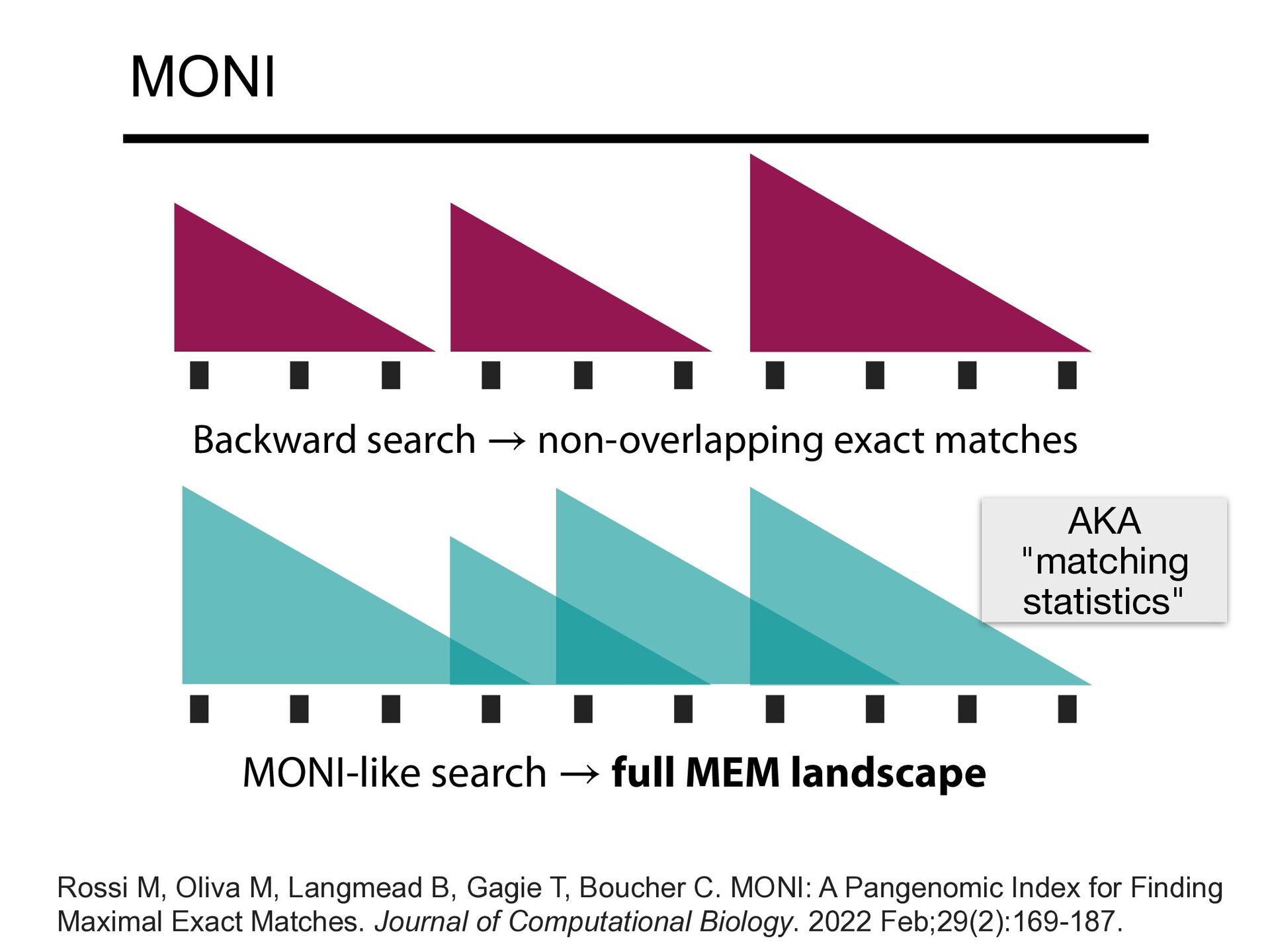
NVIDIA) Rossi M, Oliva M, Langmead B, Gagie T, Boucher C. MONI: A Pangenomic Index for Finding Maximal Exact Matches. Journal of Computational Biology. 2022 Feb;29(2):169-187.
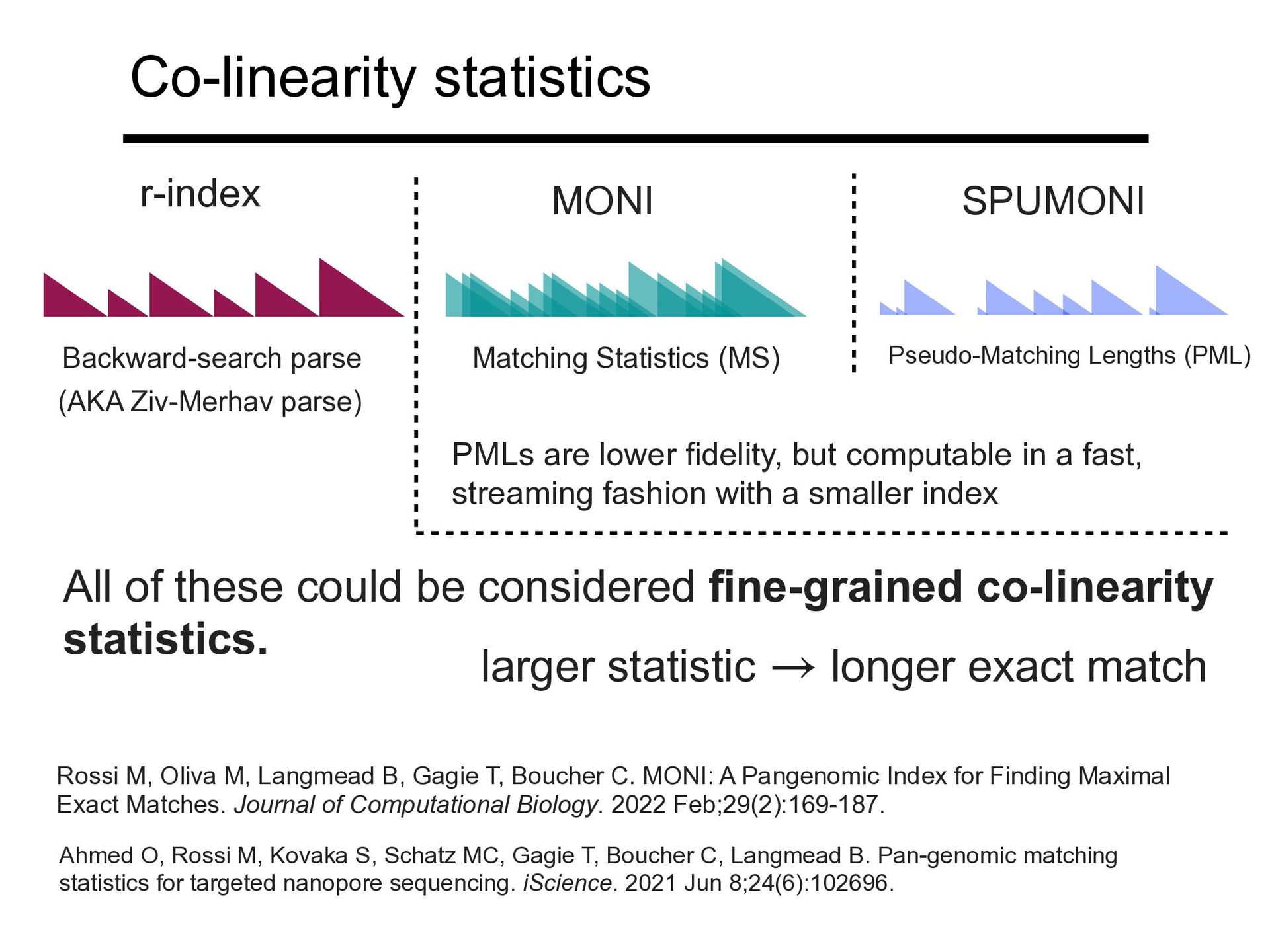
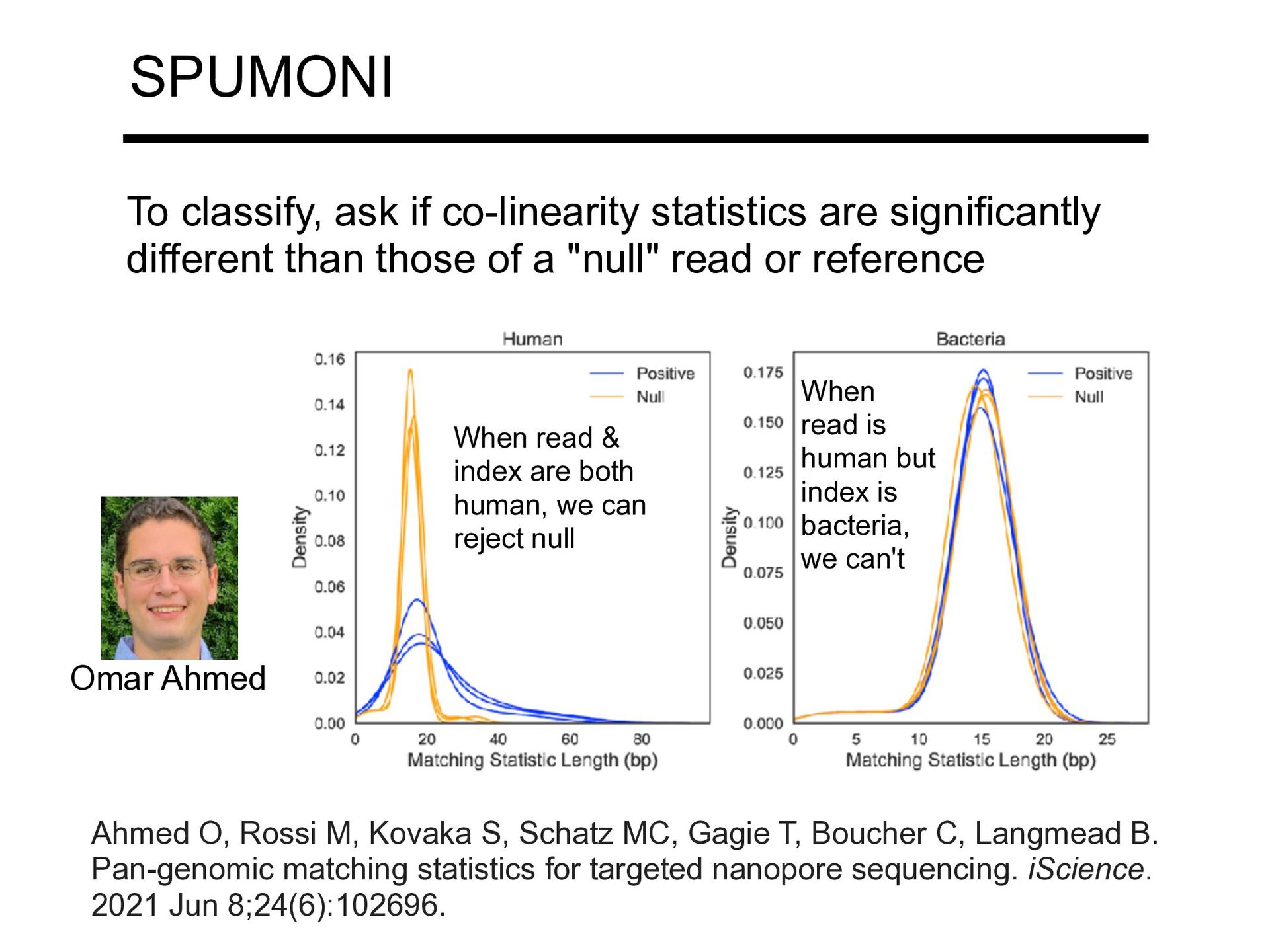
Pseudo-Matching Lengths (PML) r-index MONI SPUMONI PMLs are lower fidelity, but computable in a fast, streaming fashion with a smaller index All of these could be considered fine-grained co-linearity statistics. Rossi M, Oliva M, Langmead B, Gagie T, Boucher C. MONI: A Pangenomic Index for Finding Maximal Exact Matches. Journal of Computational Biology. 2022 Feb;29(2):169-187. Ahmed O, Rossi M, Kovaka S, Schatz MC, Gagie T, Boucher C, Langmead B. Pan-genomic matching statistics for targeted nanopore sequencing. iScience. 2021 Jun 8;24(6):102696. larger statistic longer exact match →
than those of a "null" read or reference When read & index are both human, we can reject null When read is human but index is bacteria, we can't Ahmed O, Rossi M, Kovaka S, Schatz MC, Gagie T, Boucher C, Langmead B. Pan-genomic matching statistics for targeted nanopore sequencing. iScience. 2021 Jun 8;24(6):102696. Omar Ahmed
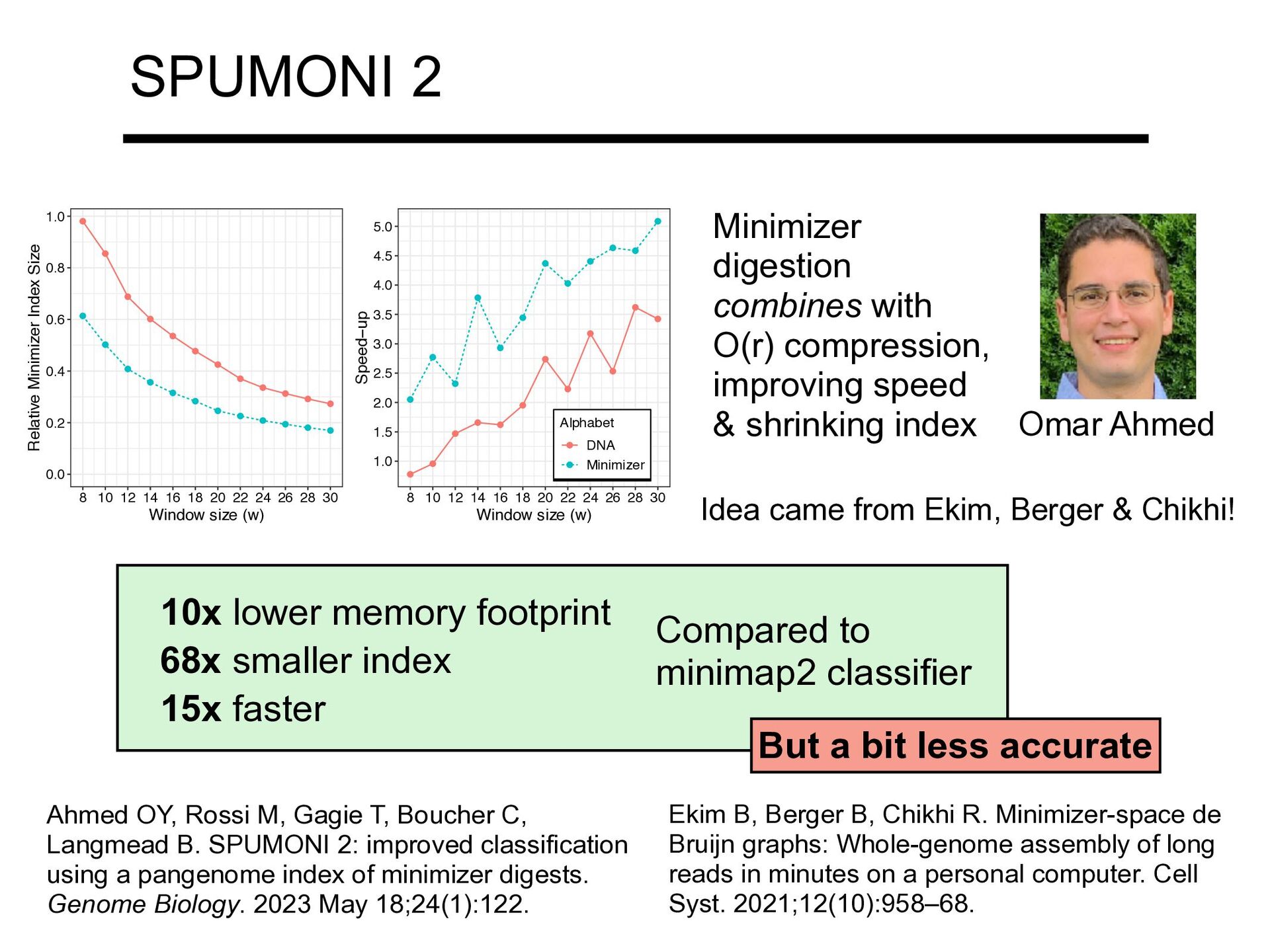
index SPUMONI 2 Omar Ahmed Ahmed OY, Rossi M, Gagie T, Boucher C, Langmead B. SPUMONI 2: improved classification using a pangenome index of minimizer digests. Genome Biology. 2023 May 18;24(1):122. 10x lower memory footprint 68x smaller index 15x faster Compared to minimap2 classifier But a bit less accurate 0.0 0.2 0.4 0.6 0.8 1.0 8 10 12 14 16 18 20 22 24 26 28 30 Window size (w) Relative Minimizer Index Size a 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 8 10 12 14 16 18 20 22 24 26 28 30 Window size (w) Speed−up Alphabet DNA Minimizer b Idea came from Ekim, Berger & Chikhi! Ekim B, Berger B, Chikhi R. Minimizer-space de Bruijn graphs: Whole-genome assembly of long reads in minutes on a personal computer. Cell Syst. 2021;12(10):958–68.
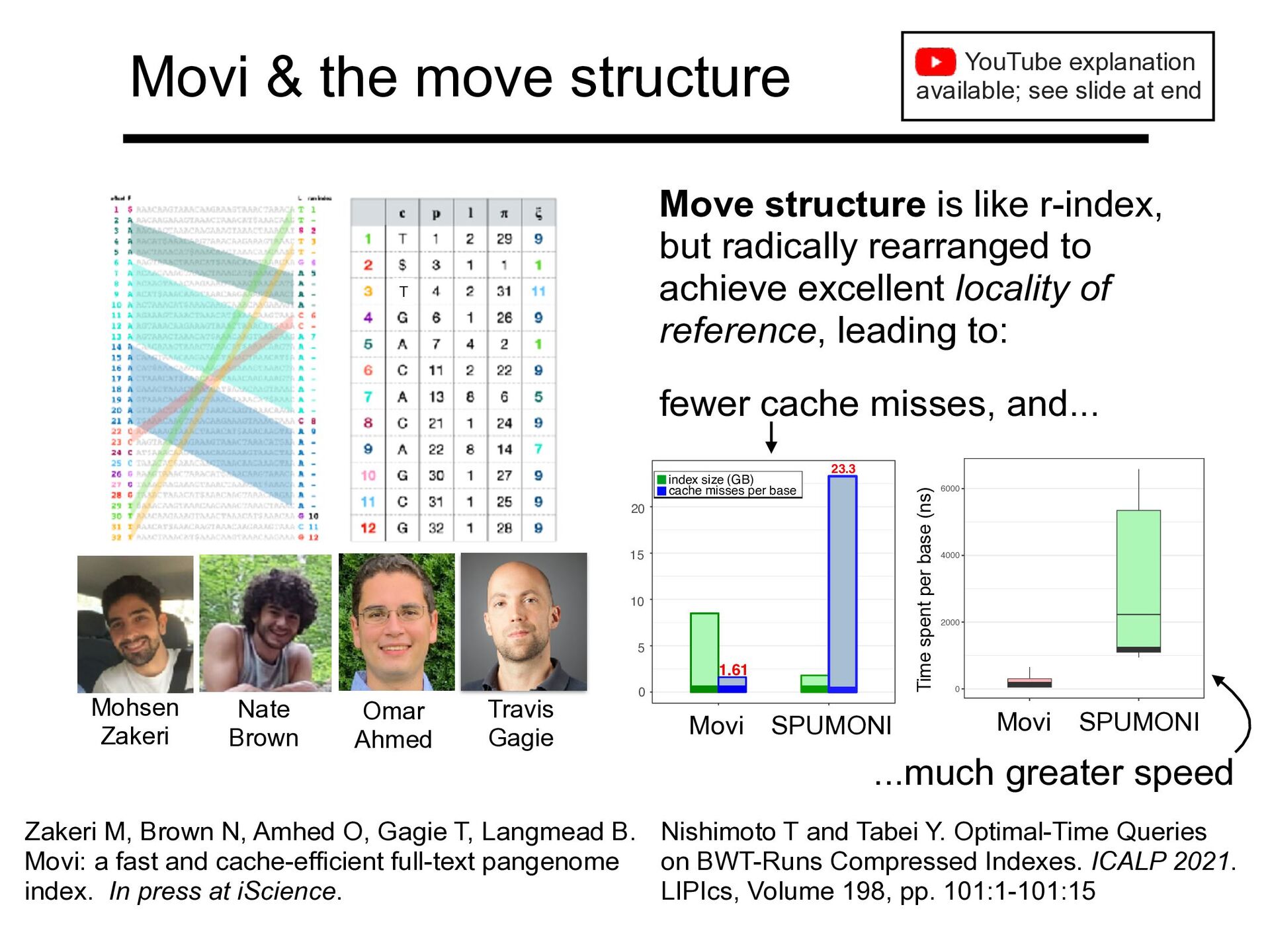
Zakeri Nate Brown Move structure is like r-index, but radically rearranged to achieve excellent locality of reference, leading to: fewer cache misses, and... ...much greater speed Zakeri M, Brown N, Amhed O, Gagie T, Langmead B. Movi: a fast and cache-efficient full-text pangenome index. In press at iScience. YouTube explanation available; see slide at end 1.61 23.3 0 5 10 15 20 Movi SPUMONI index size (GB) cache misses per base 0 2000 4000 6000 Movi SPUMONI PML per base (ns) Movi SPUMONI Movi SPUMONI Time spent per base (ns) Nishimoto T and Tabei Y. Optimal-Time Queries on BWT-Runs Compressed Indexes. ICALP 2021. LIPIcs, Volume 198, pp. 101:1-101:15 T
especially with move structure Vastly smaller than FM Index Classification ✅ Minimizer digestion imparts further benefits No fixed k; matches can be any length 💪 💪 💪 💪 💪
is more accurate 😔 Does not yet scale well for read alignment 😔 Not as small as k-mer indexes 😔 We approach but do not match distinguishing power of minimap2's alignments Due to locate-query redundancies Perhaps an unavoidable trade if we need to support flexible-length matches. But we're not far!
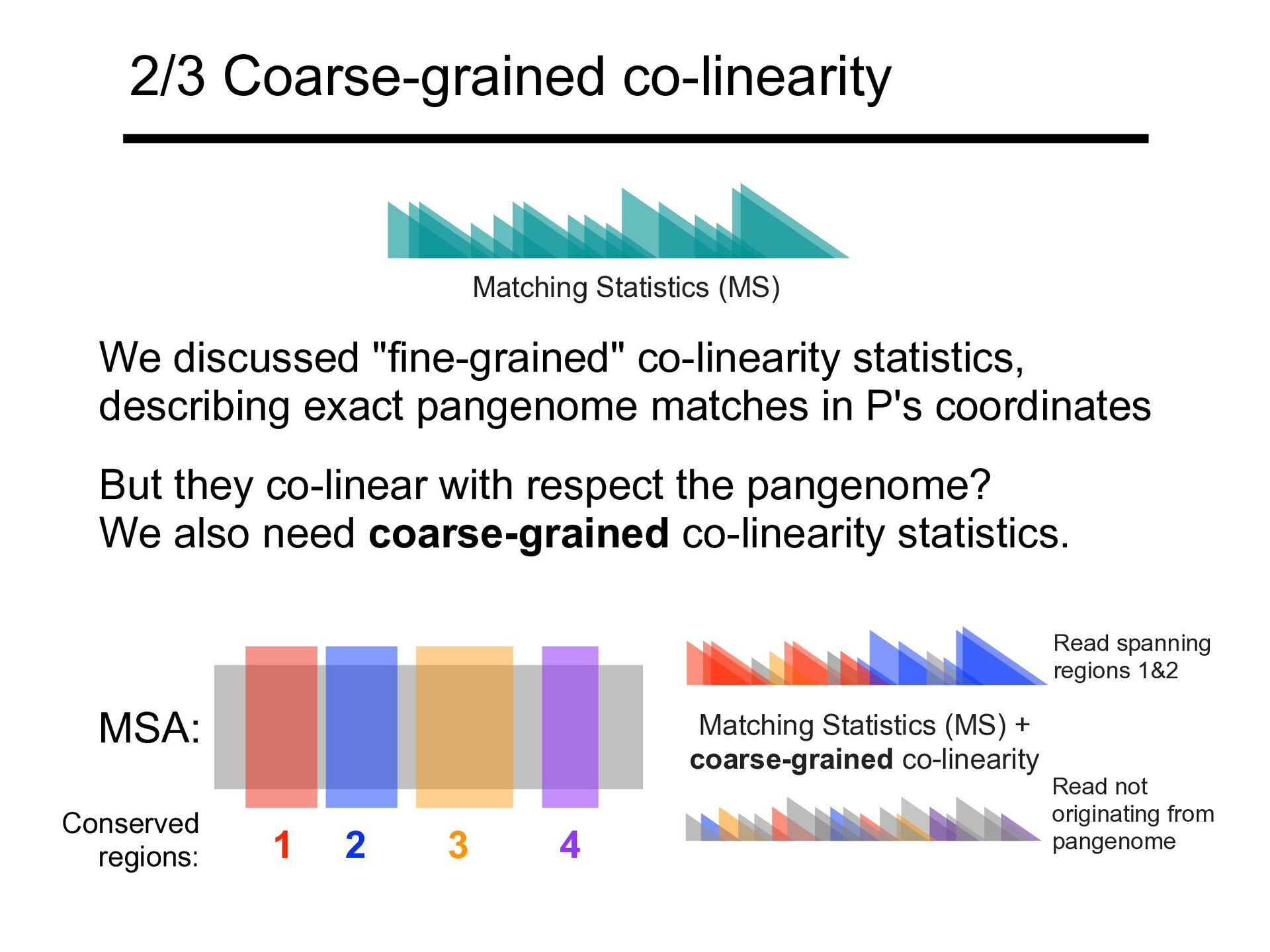
statistics, describing exact pangenome matches in P's coordinates But they co-linear with respect the pangenome? We also need coarse-grained co-linearity statistics. Matching Statistics (MS) + coarse-grained co-linearity Conserved regions: MSA: 1 2 3 4 Read spanning regions 1&2 Read not originating from pangenome
biologically-grounded way Coordinate system emerges & downstream effort is saved Garrison, E., Sirén, J., Novak, A. M., Hickey, G., Eizenga, J. M., Dawson, E.T., … Durbin, R. (2018). Variation graph toolkit improves read mapping by representing genetic variation in the reference. Nature biotechnology, 36(9), 875–879. 3/3 Collapse and conquer r-index-based aligners to date must locate & investigate many "equivalent" seed hits; the graph would have collapsed them for us!
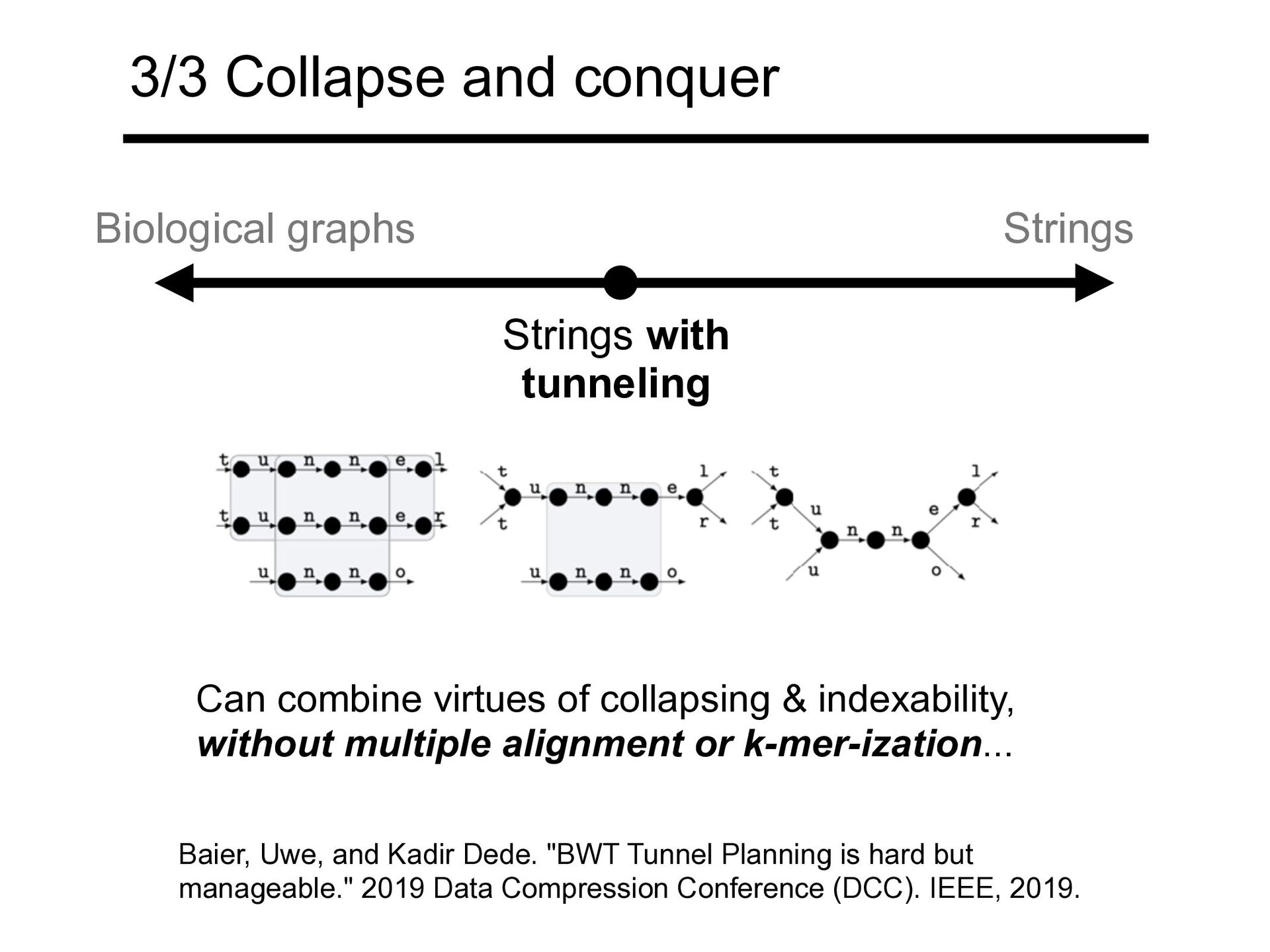
Dede. "BWT Tunnel Planning is hard but manageable." 2019 Data Compression Conference (DCC). IEEE, 2019. Can combine virtues of collapsing & indexability, without multiple alignment or k-mer-ization... 3/3 Collapse and conquer
structure talk: https://bit.ly/move_talk ALPACA virtual seminar Jan 8, 2024 Especially last 3 videos Talk with more on MONI algorithm: https://bit.ly/cbcb_talk UMD CBCB seminar Sept 15, 2022
Gagie Alan Kuhnle Giovanni Manzini Jacob Pritt Nae-Chyun Chen Taher Mun Omar Ahmed Max Rossi Marco Oliva Mohsen Zakeri Nate Brown R01HG011392 R35GM139602 Kavya Vaddadi NIH: NSF: www.youtube.com/BenLangmead bit.ly/yt_index bit.ly/move_talk bit.ly/cbcb_talk Omar Ahmed also supported by: T32GM119998 Mao-Jan Lin
![Ben Langmead Associate Professor, JHU Computer Science [email protected], langmead-lab.org, @BenLangmead](https://files.speakerdeck.com/presentations/8214e5eceb9f4c1d81c7211a6dc73473/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}