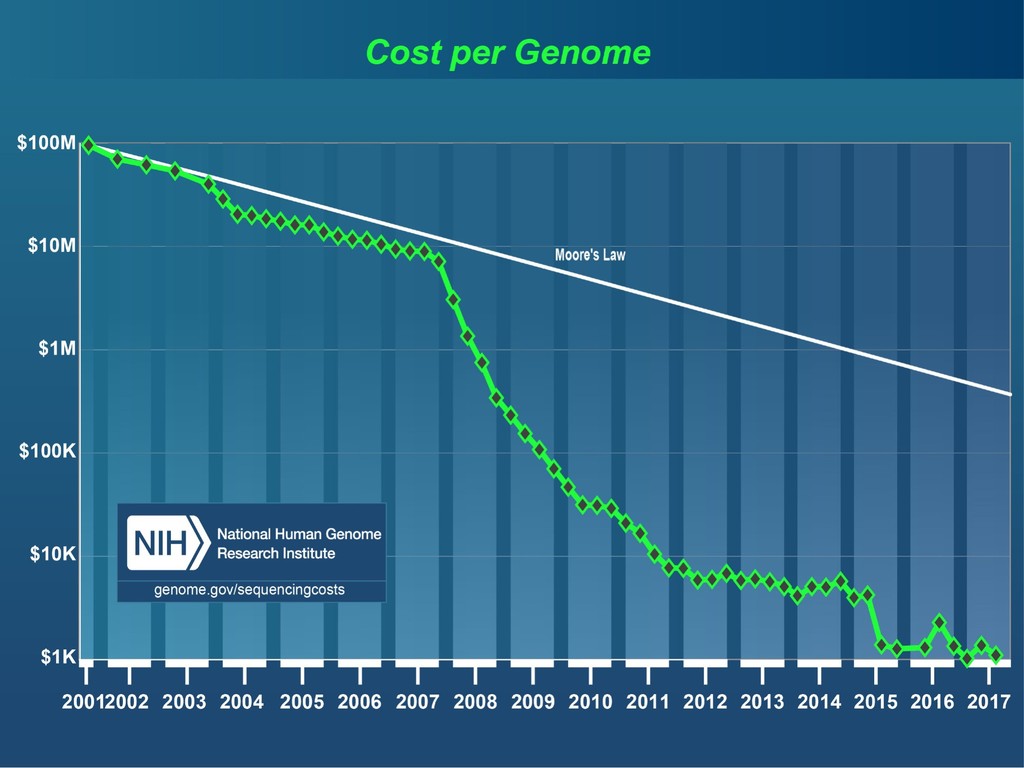
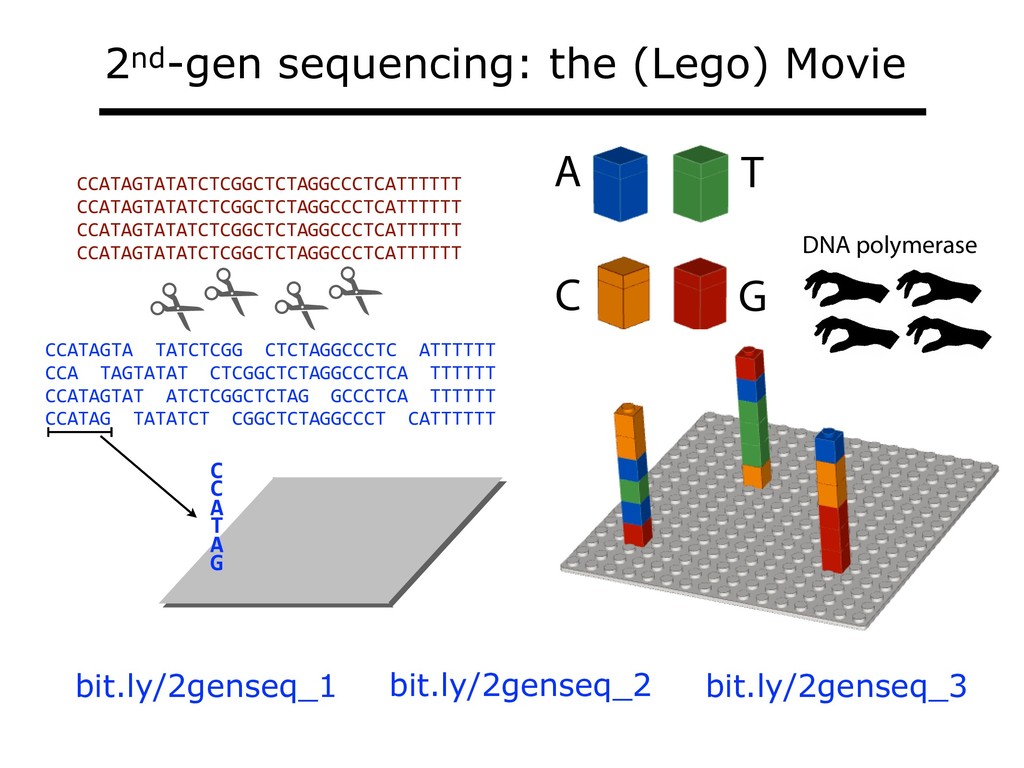
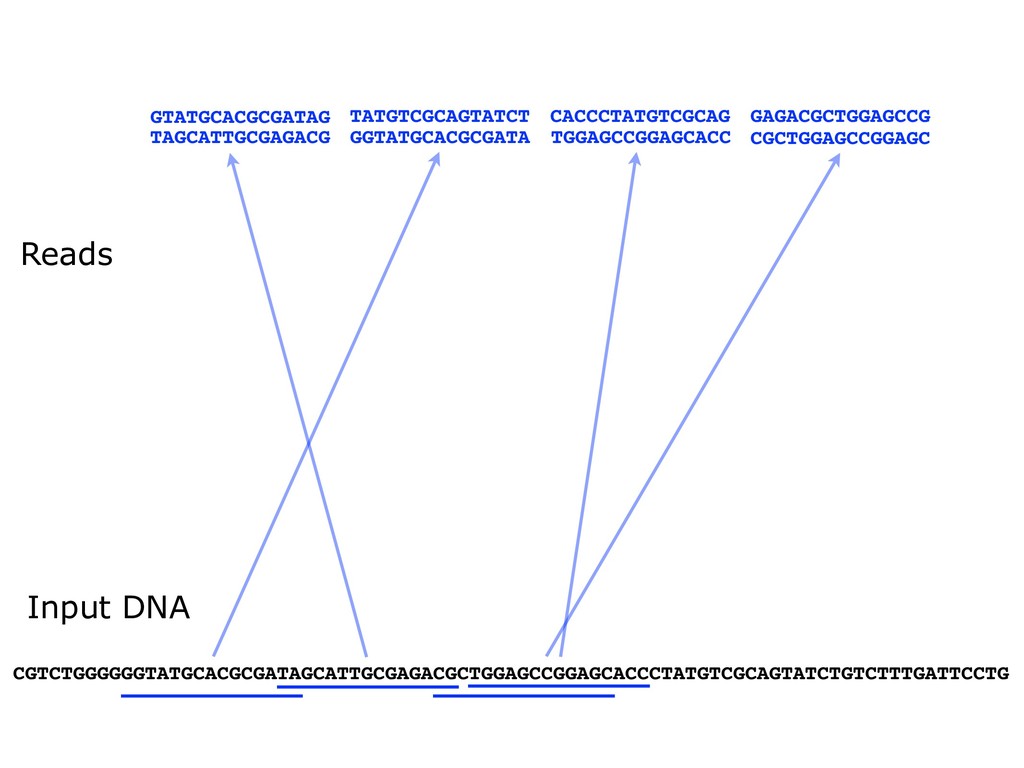
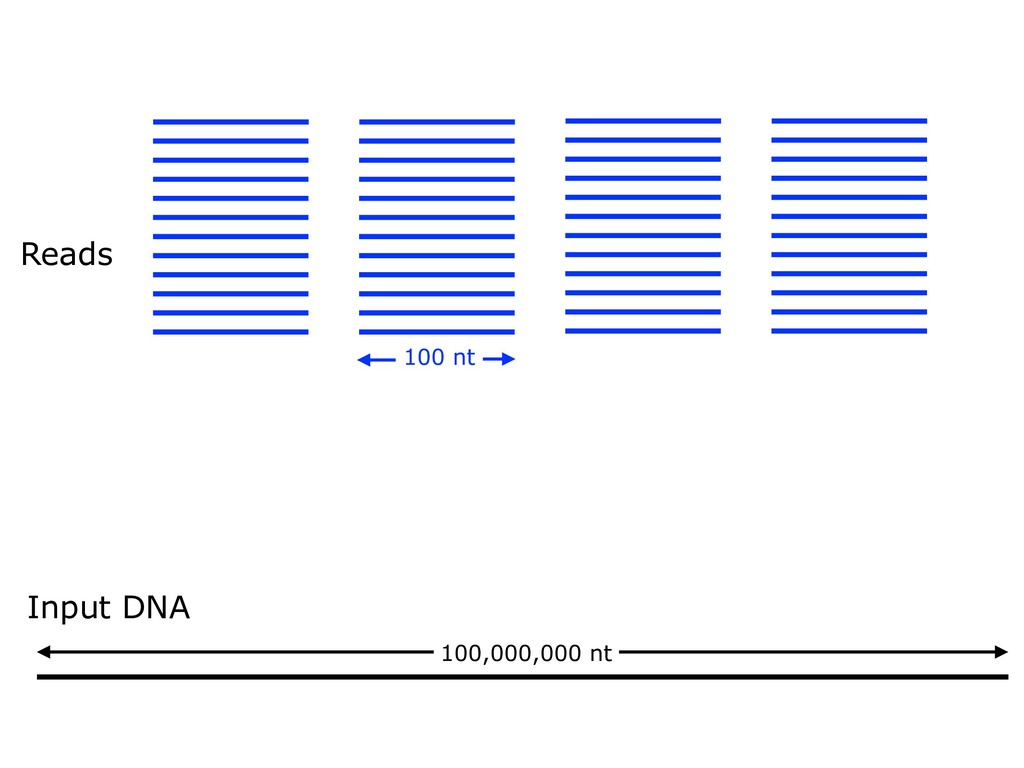
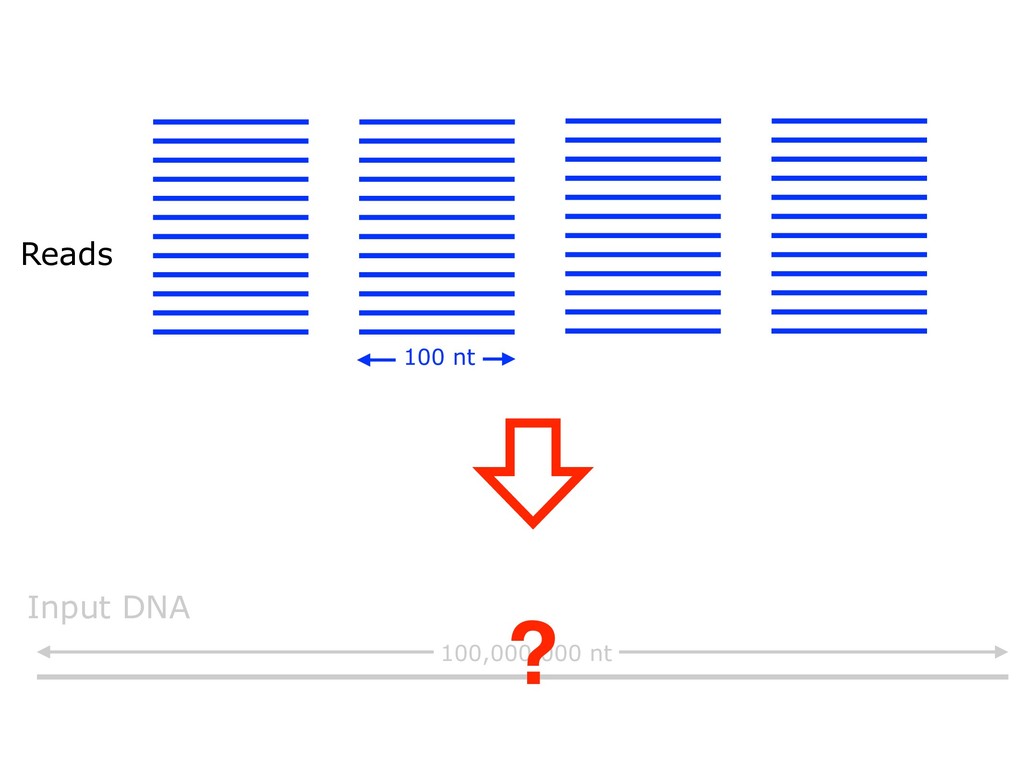
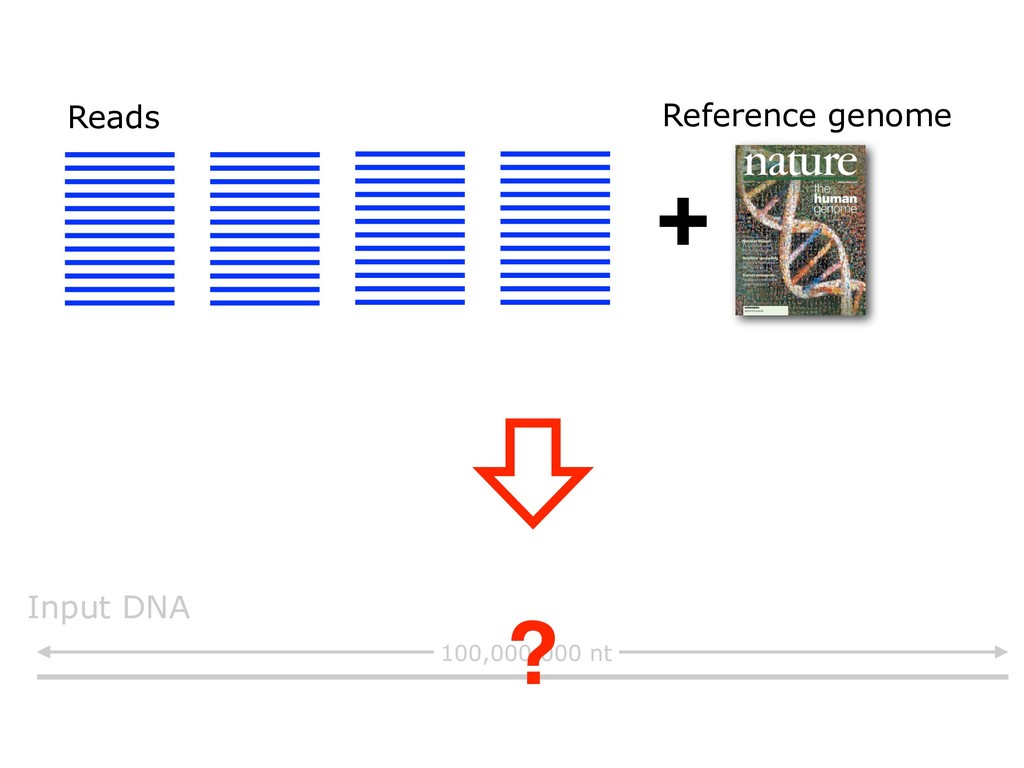
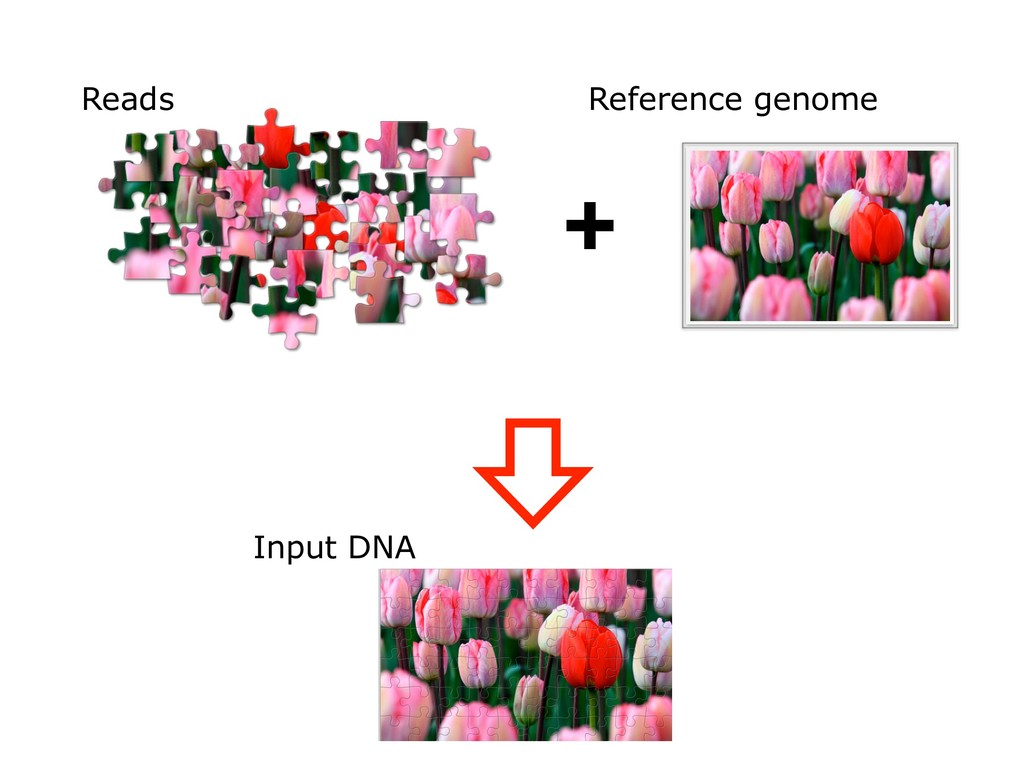
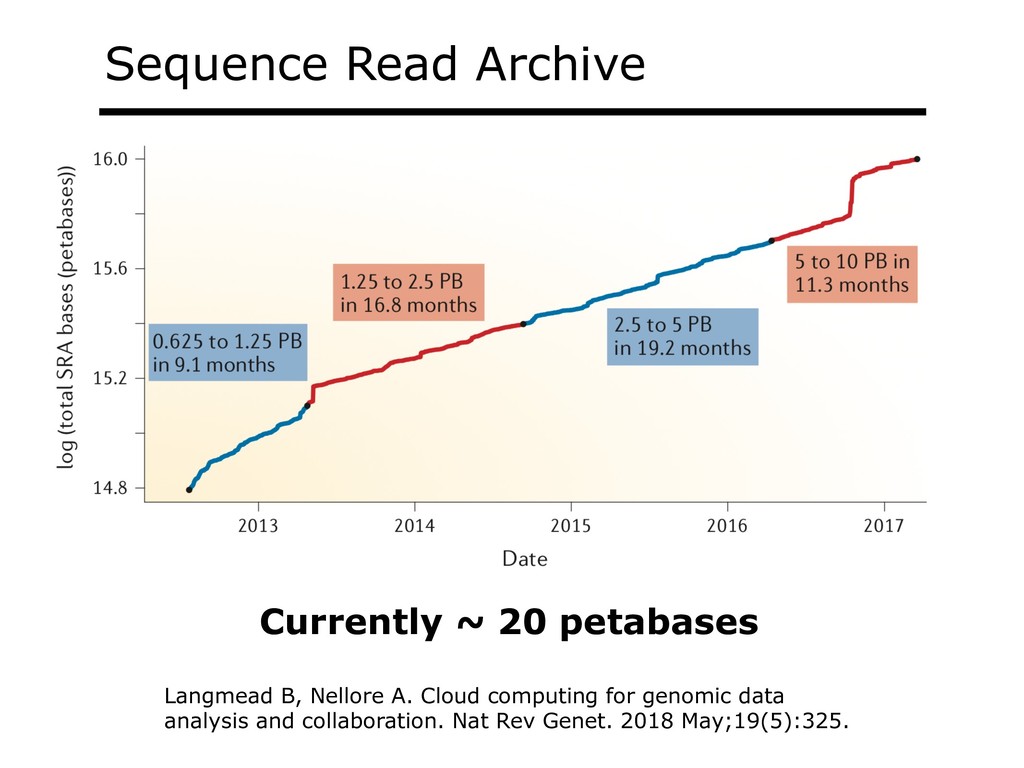
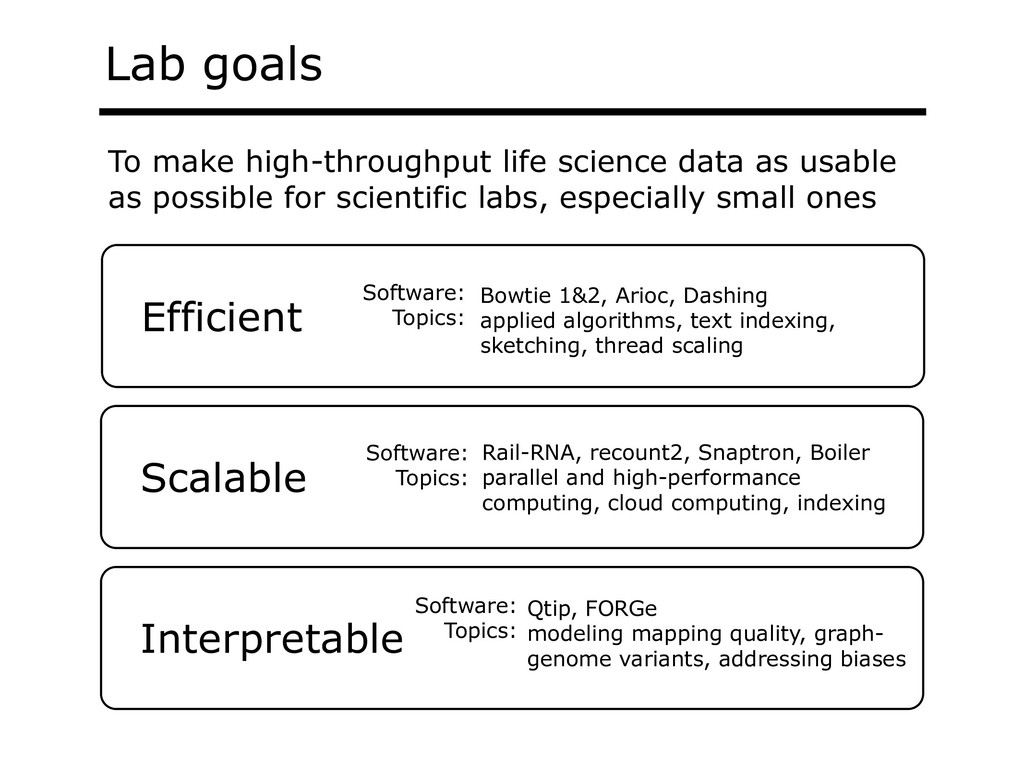
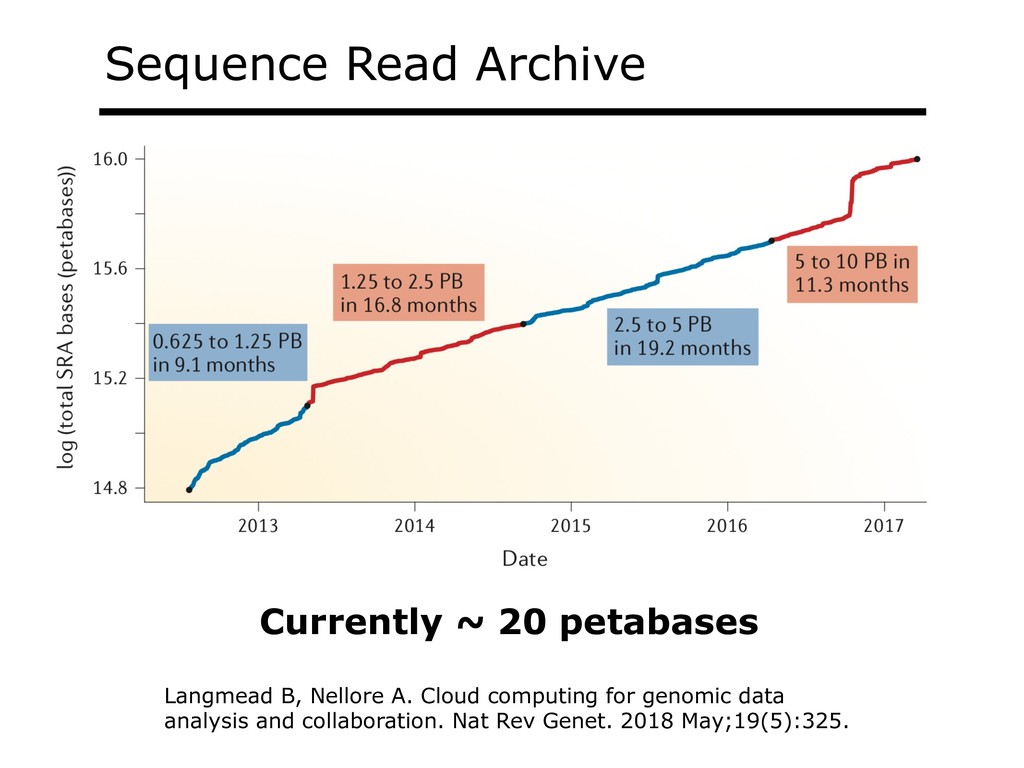
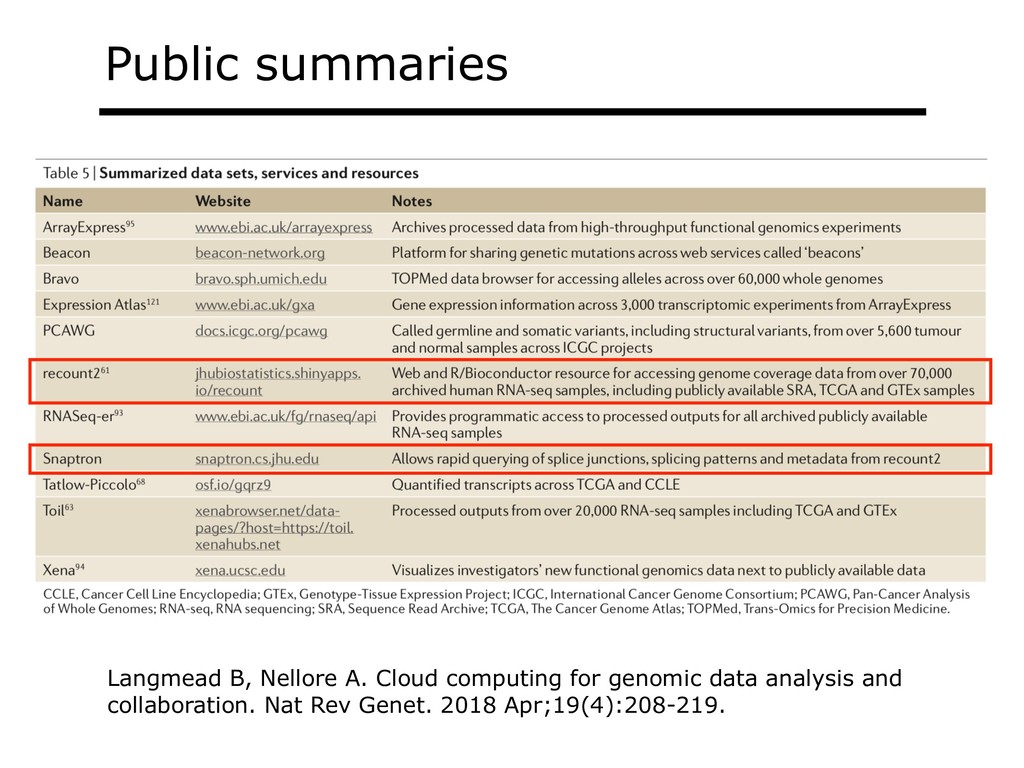
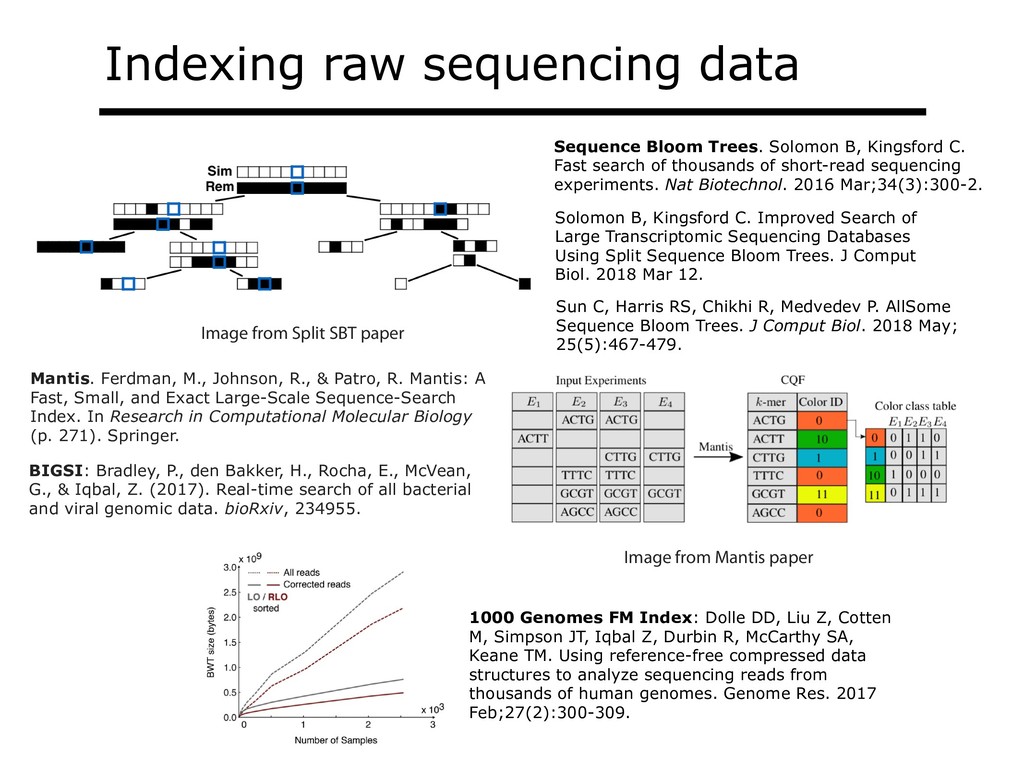
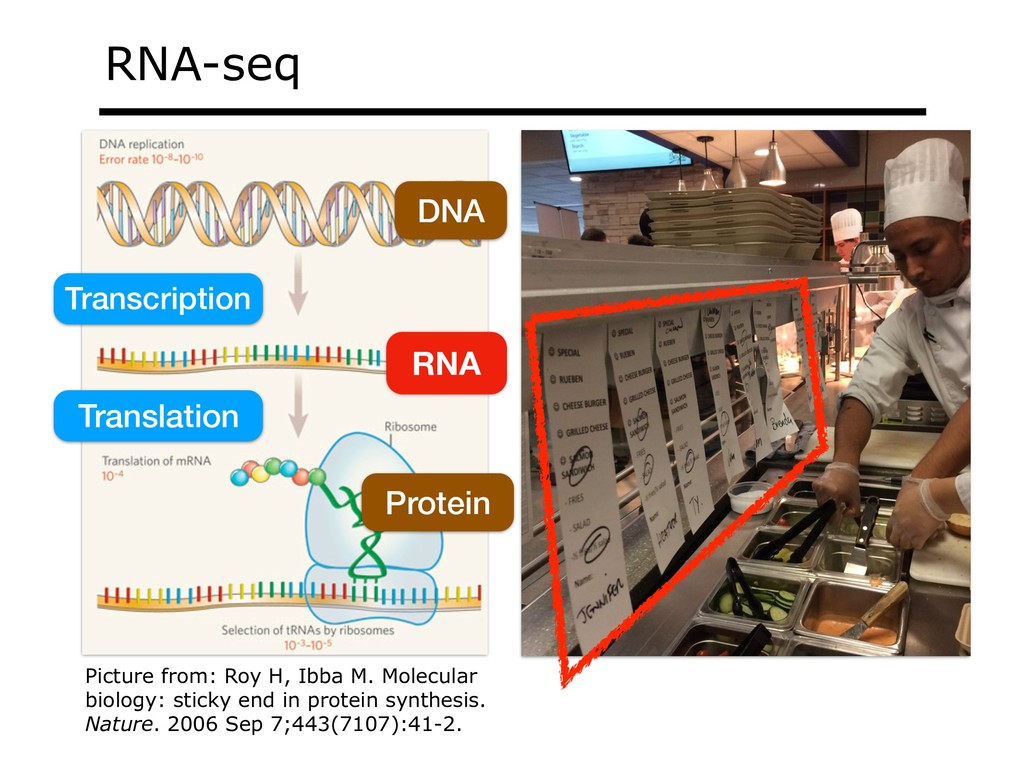
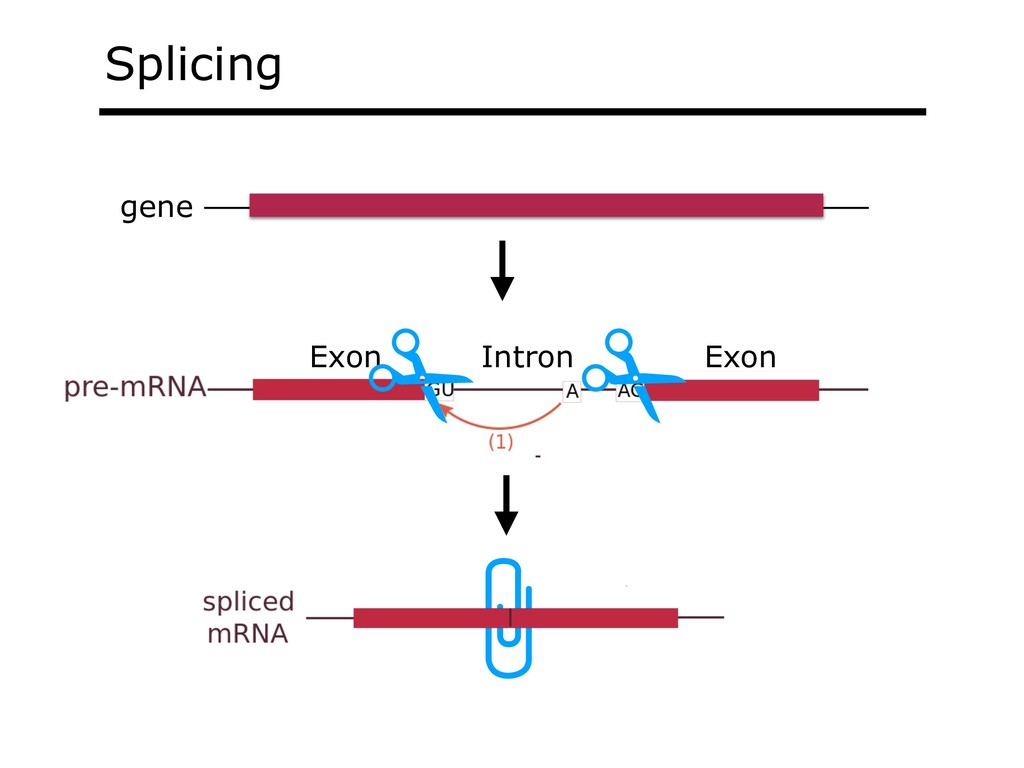
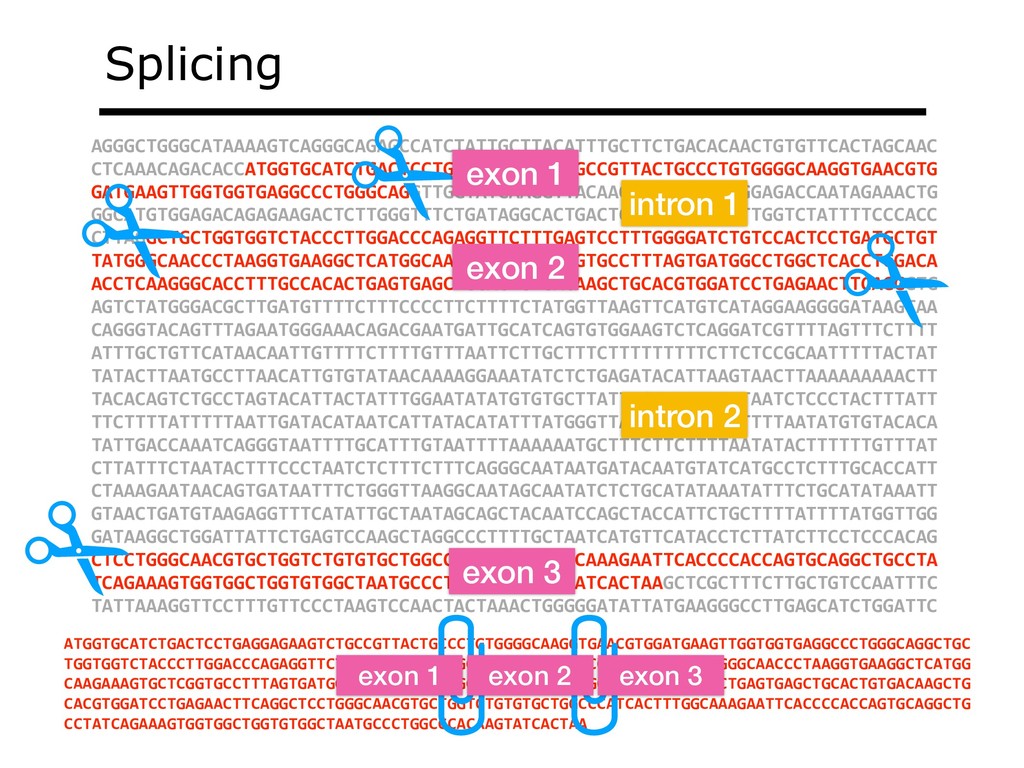
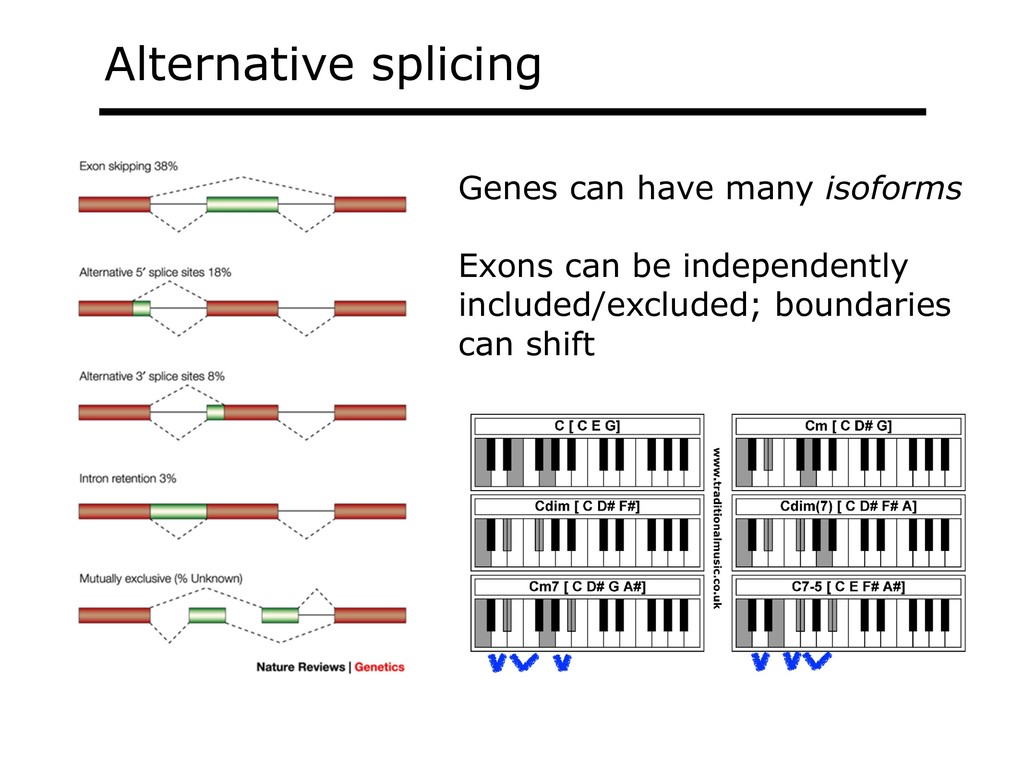
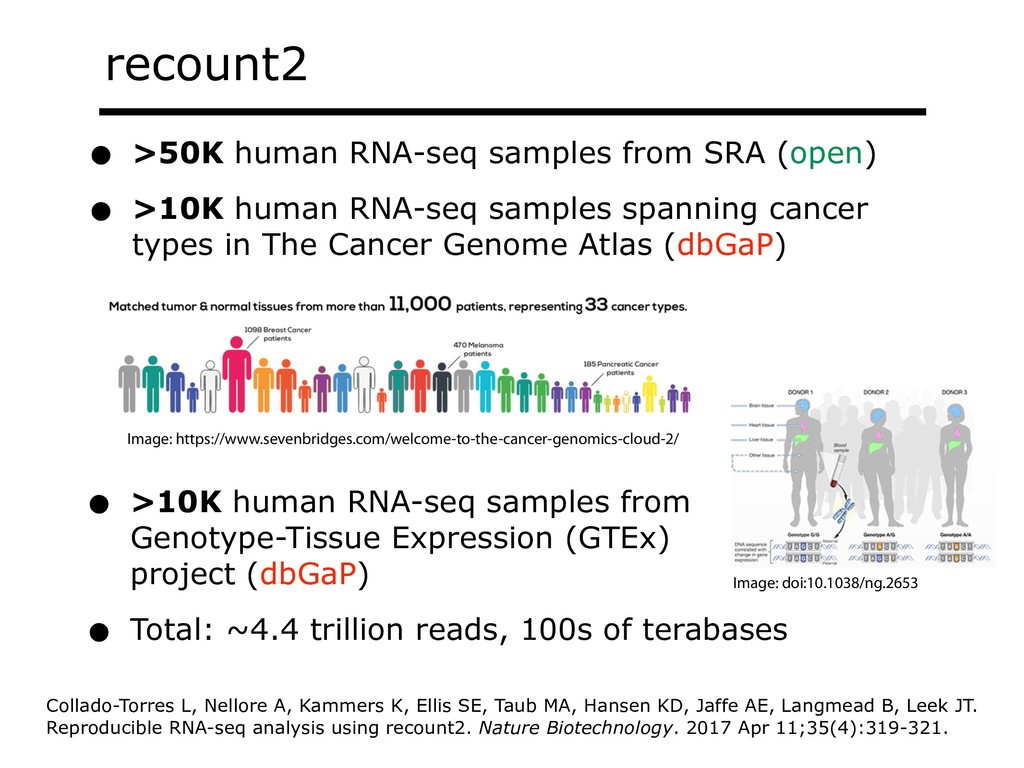
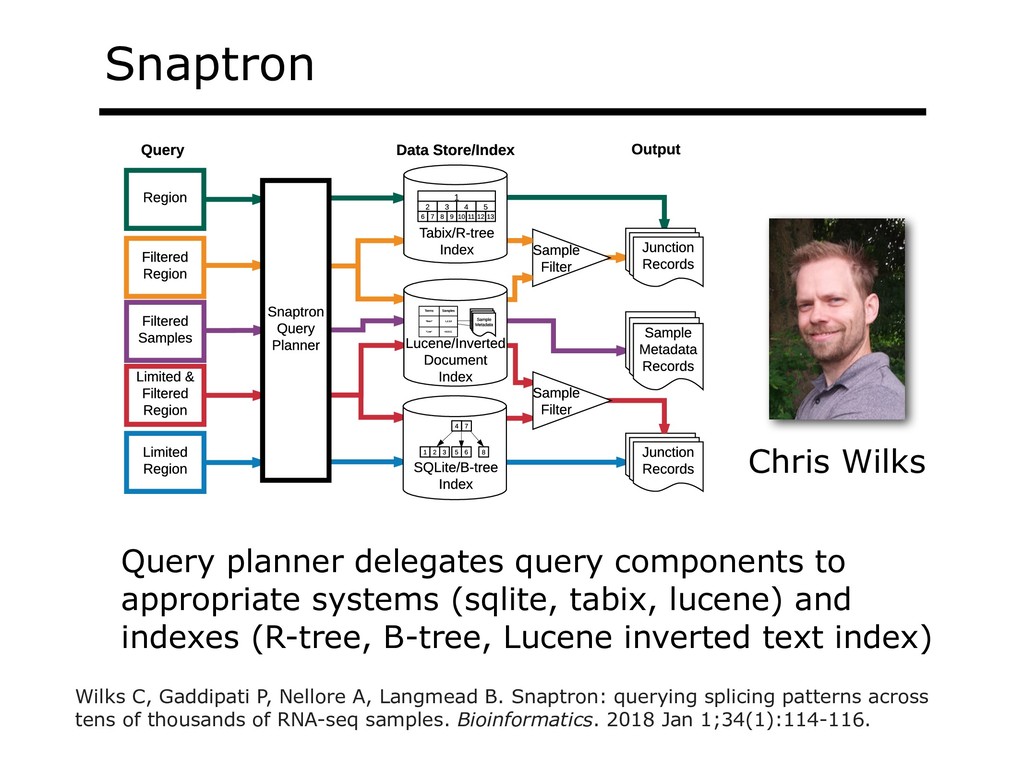
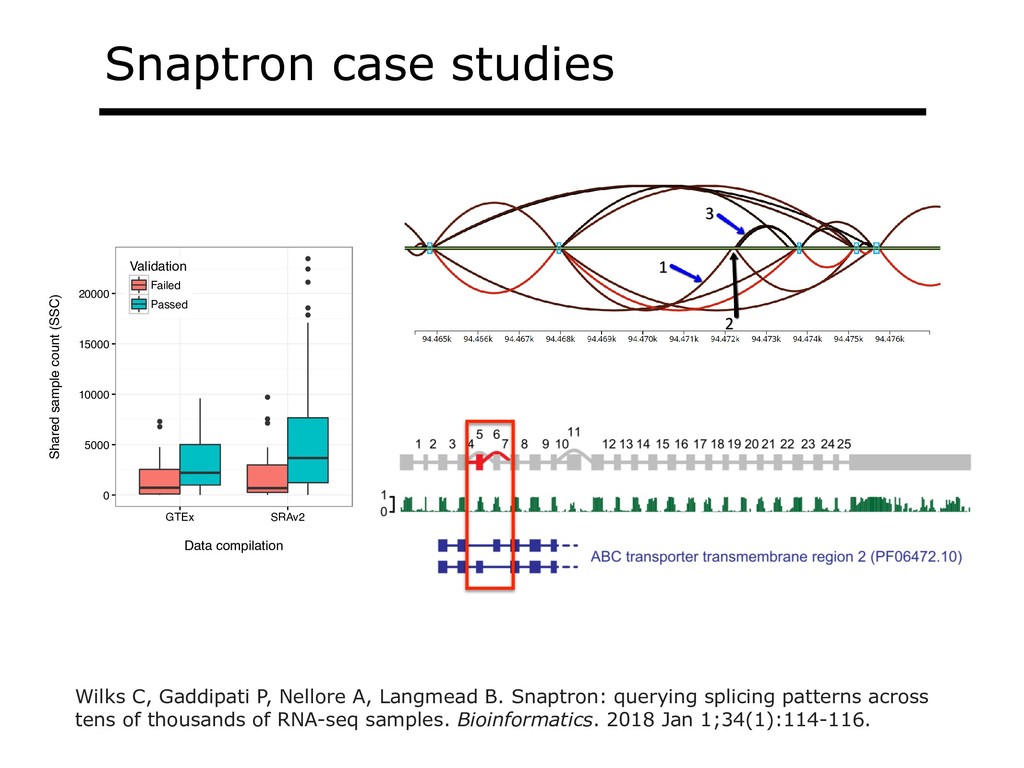
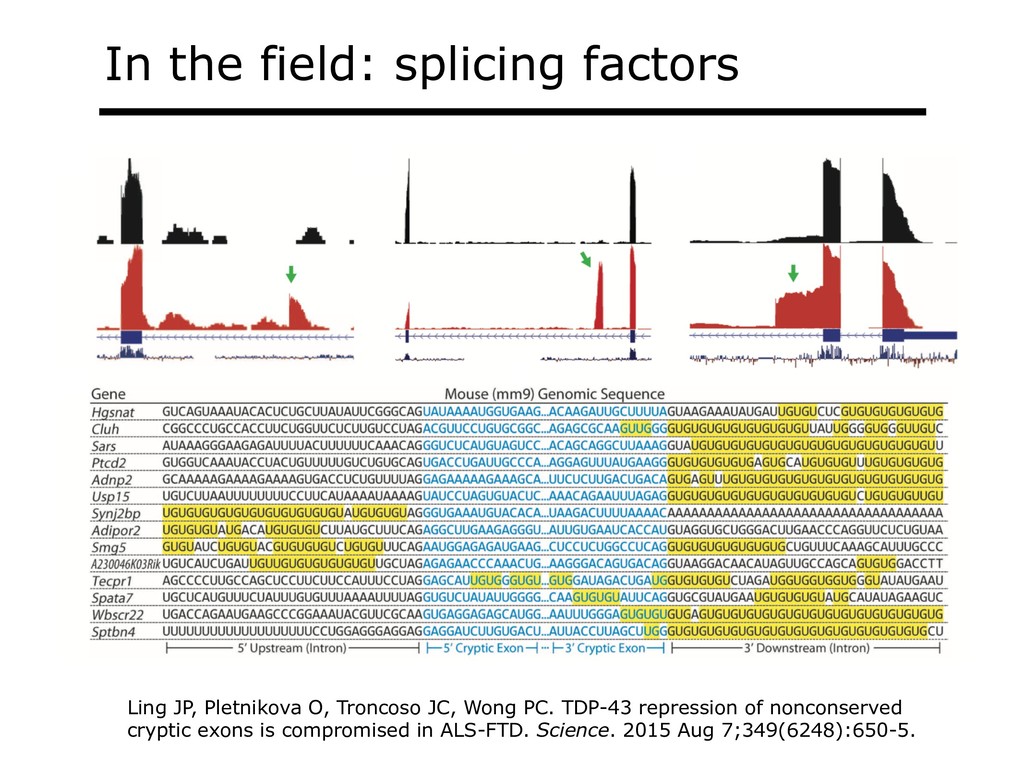
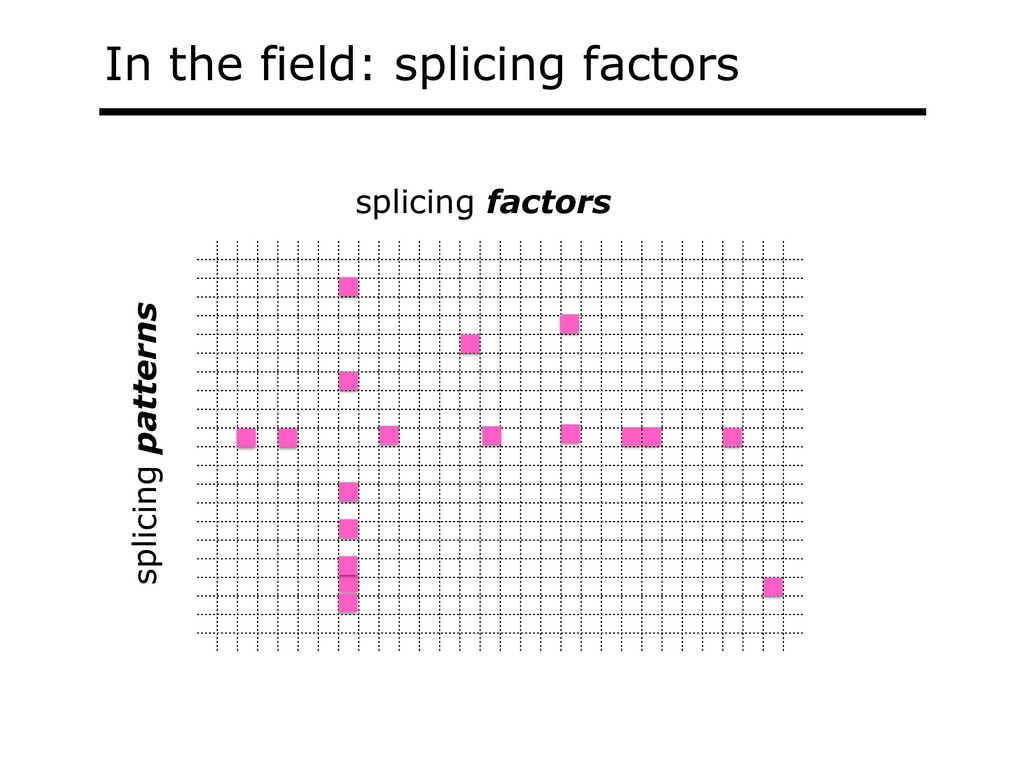
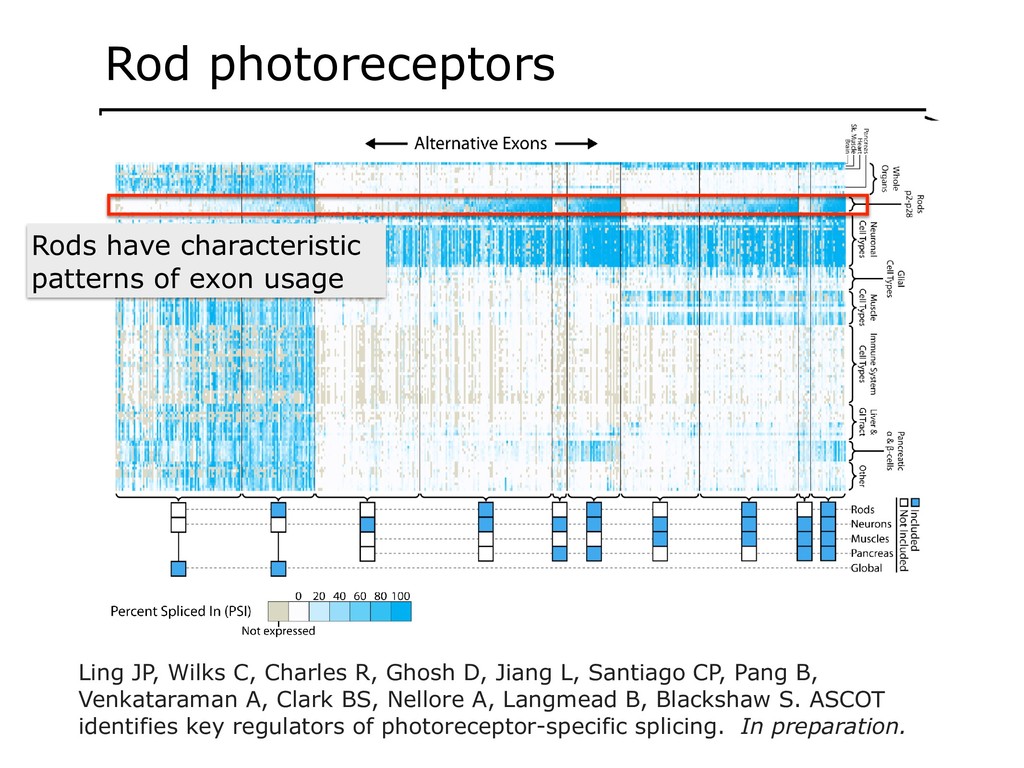
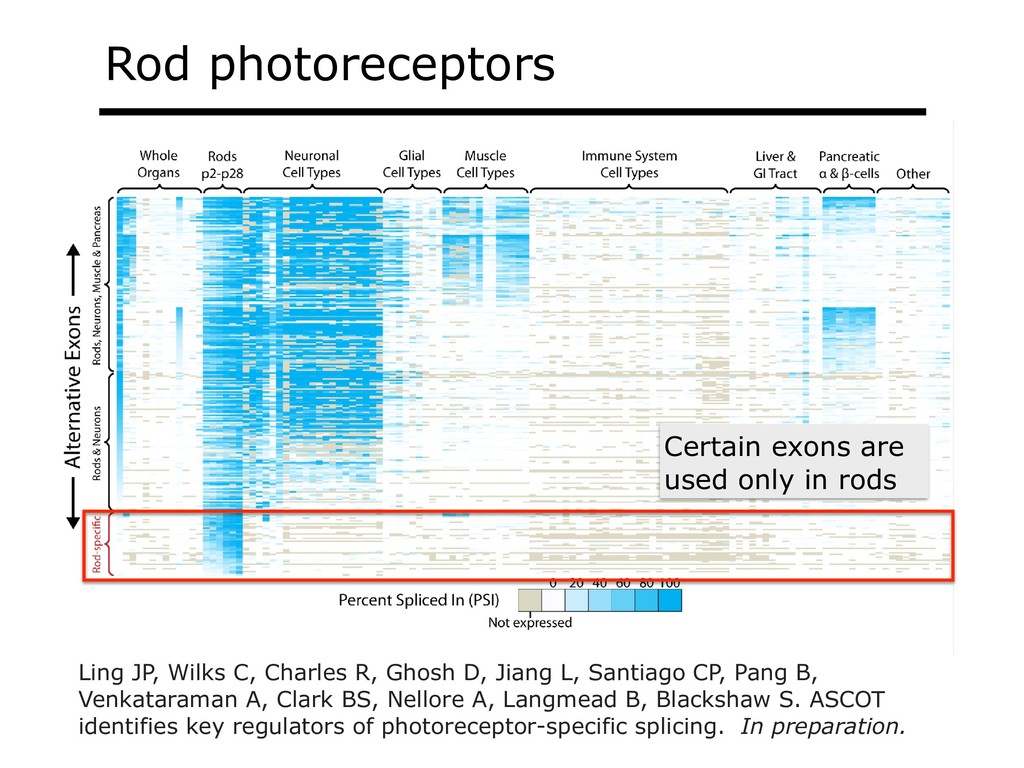
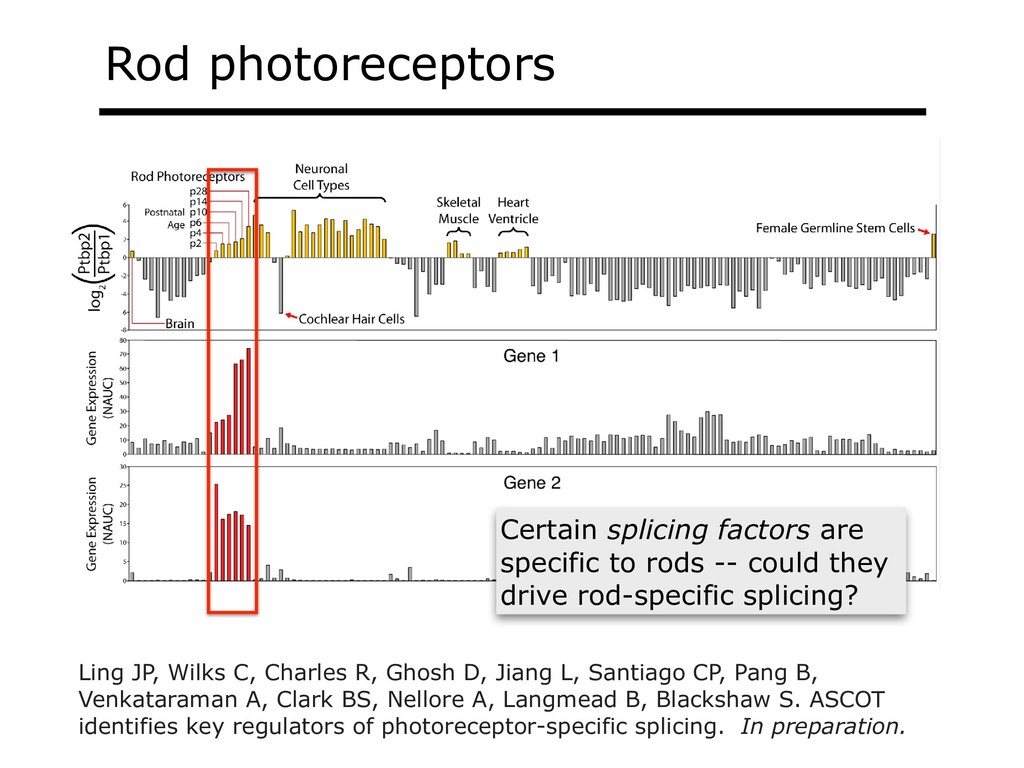
With the advent of modern DNA sequencing, life science is increasingly becoming a big-data science. The main public archive for sequencing data, the Sequence Read Archive (SRA), now contains over a million datasets and many petabytes of data. While large-scale projects like GTEx, ICGC and TOPmed have been major contributors, even larger projects are on the horizon, e.g. the All of Us and Million Veterans programs. The SRA and similar archives are potential gold mines for researchers but they are not organized for everyday use by scientists. The situation resembles the early days of the World Wide Web, before search engines made the web easy to use. I will describe our progress toward the goal of making it easy for researchers to ask scientific questions about public datasets, focusing on datasets that measure abundance of messenger RNA transcripts (RNA-seq). I will describe how we borrow from trends in big-data wrangling and cloud computing to make public data easier to use and query. I will motivate the work with examples of how we are applying it in research areas concerned with novel (e.g. cryptic) splicing patterns and the splicing factors that regulate them. This is work in progress, and I will highlight ways in which we are learning to make our tools better suited to how scientists work. This is joint work with Abhinav Nellore, Chris Wilks, Jonathan Ling, Luigi Marchionni, Jeff Leek, Kasper Hansen, Andrew Jaffe and others.
![Ben Langmead Assistant Professor, JHU Computer Science [email protected], langmead-lab.org, @BenLangmead](https://files.speakerdeck.com/presentations/4b7a1427e9074f66b917f12748e23050/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}