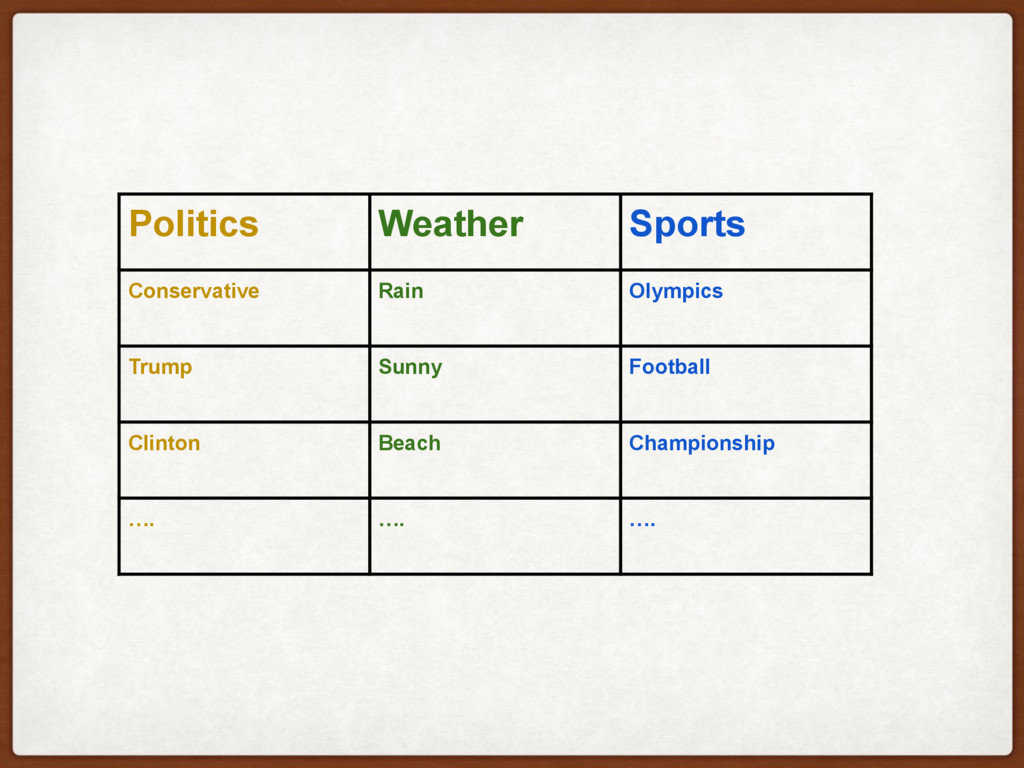
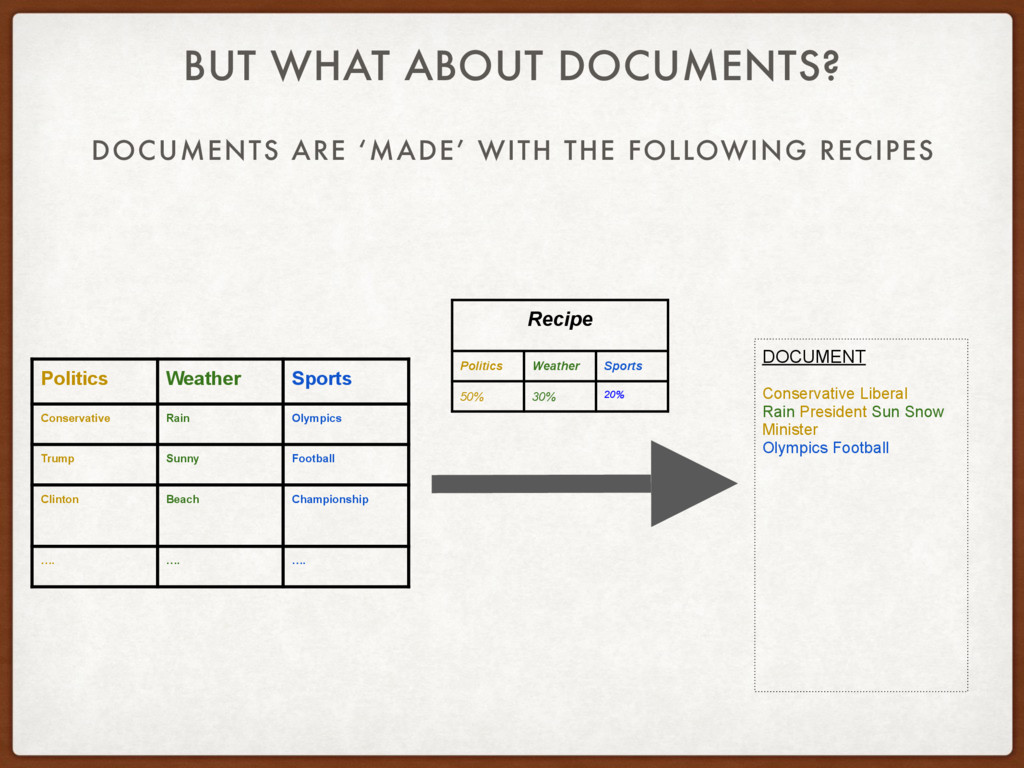
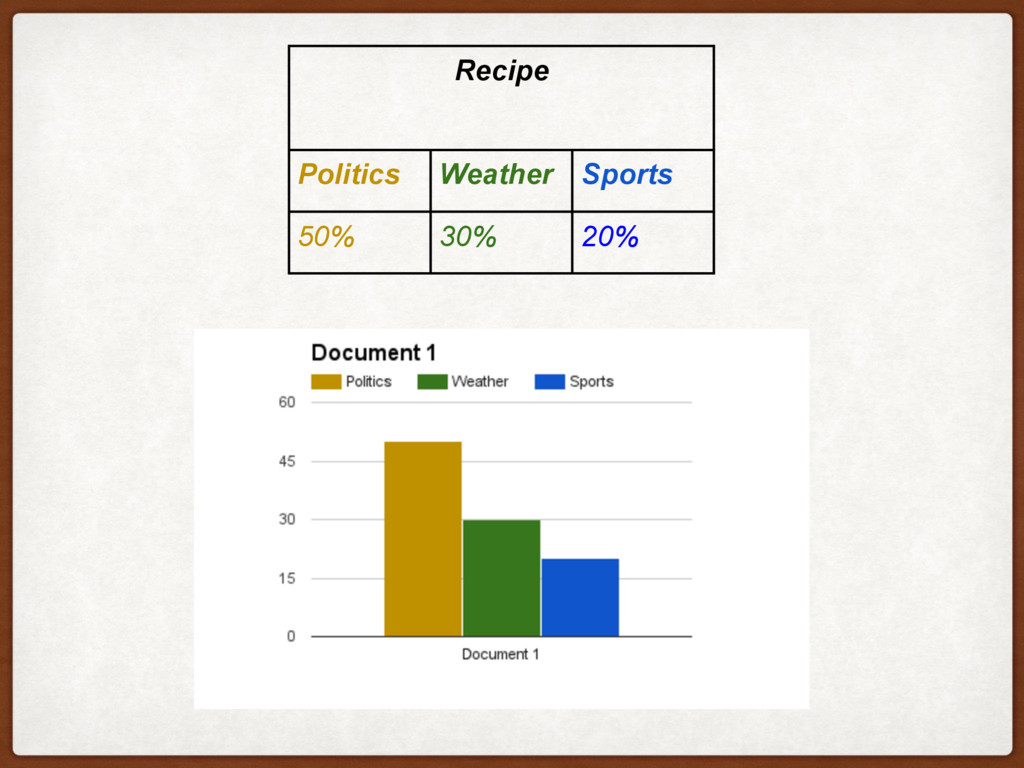
DOCUMENTS? Politics Weather Sports Conservative Rain Olympics Trump Sunny Football Clinton Beach Championship …. …. …. Recipe Politics Weather Sports 50% 30% 20% DOCUMENT Conservative Liberal Rain President Sun Snow Minister Olympics Football
Rain Olympics Trump Sunny Football Clinton Beach Championship …. …. …. DOCUMENT 1 Conservative Liberal Rain President Sun Snow Minister Olympics Football DOCUMENT 2 Trump Clinton Storm Swimming Hockey DOCUMENT 1000 UEFA PSG Lille Football We just go backwards by using Bayesian Inference :) We find the model that describes the documents best. “Put words that appear together into the same topic”
If the sentence contains the following words: sentence = “BANK WATER RIVER TREE” And we do want to find if it is good or bad model — color_words(bad_lda, sentence) BANK WATER WATER TREE color_words(good_lda, sentence) BANK WATER WATER TREE
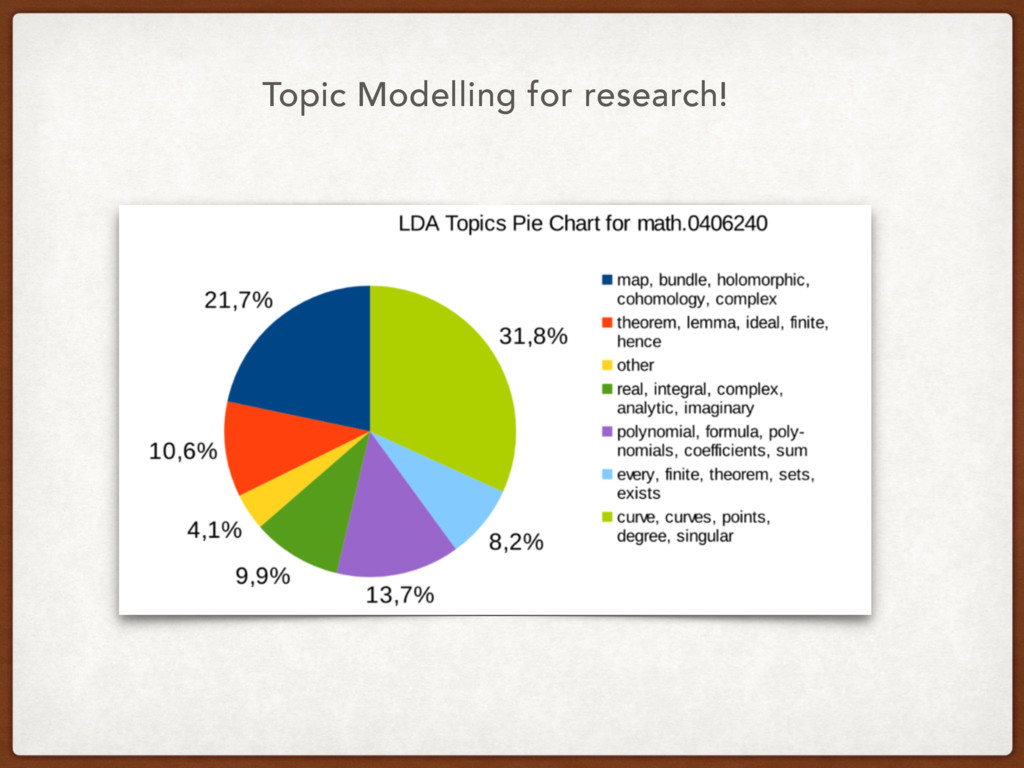
unstructured textual data • How to do it very easily with Python and Gensim • How to color words in a document • How to find the best model! • What else can we do?
Doc2Vec and Word2Vec! • LSI, HDP for more topic modelling! • And why is this useful or important? • Document Similarity over time-periods • Easy text analysis with a variety of algorithms
regularly hold Sprints and Tutorials • Variety of tutorials, practical implementations on the GitHub page • Would be very happy to see Gensim being used to solve business problems in Slovakia • Even happier to see everyone contributing to Gensim :)
• Currently research assistant at INRIA Lille, France. https://github.com/ bhargavvader • My French is pretty bad • Still - Dobrý deň! • My Slovak is worse https://twitter.com/ bhargavvader
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}