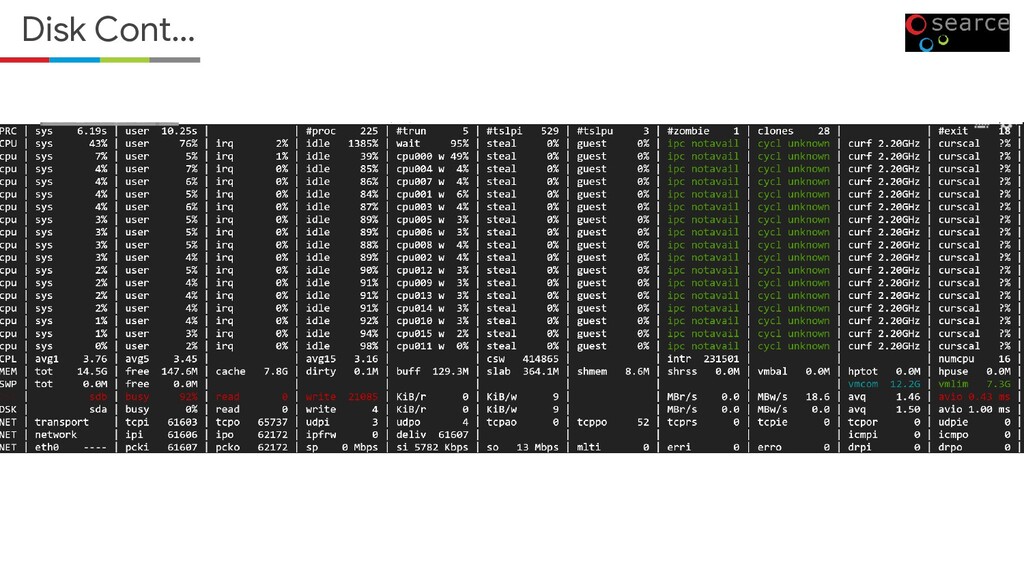
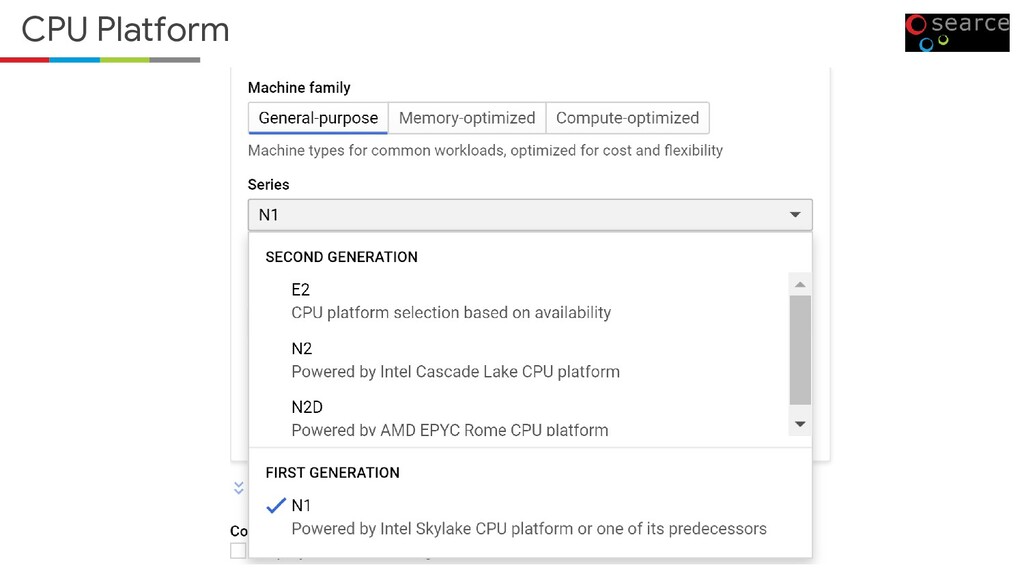
If you are running the elastic search clusters on the GCE, then we need to take a look at the Capacity planning, OS level, and Elasticsearch level optimization. I have presented this at GDG Delhi on Feb 22,2020.
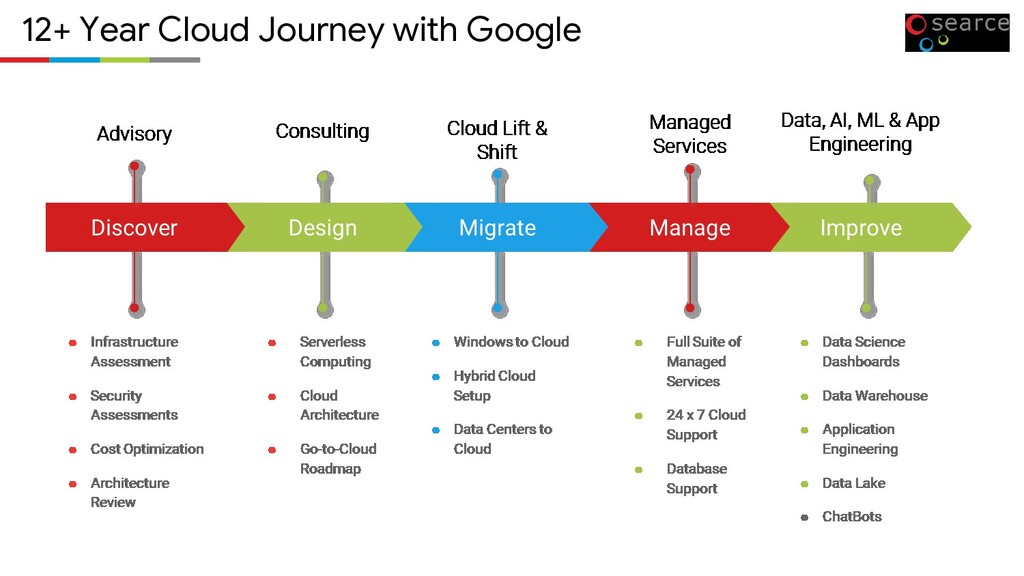
Google’s data centers with access to high-performance networking infrastructure and block storage. Live migration for VMs Compute Engine virtual machines can live-migrate between host systems without rebooting, which keeps your applications running even when host systems require maintenance. Preemptible VMs Run batch jobs and fault-tolerant workloads on preemptible VMs to reduce your vCPU and memory costs by up to 80% while still getting the same performance and capabilities as regular VMs. Sole-tenant nodes Sole-tenant nodes are physical Compute Engine servers dedicated exclusively for your use. Sole-tenant nodes simplify deployment for bring your own license (BYOL) applications. Sole-tenant nodes give you access to the same machine types and VM configuration options as regular compute instances.
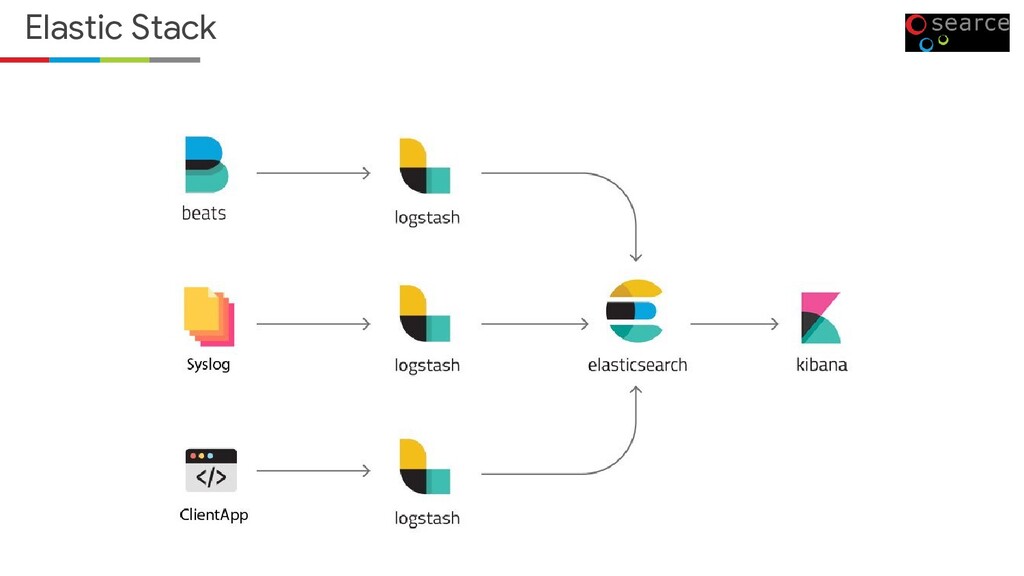
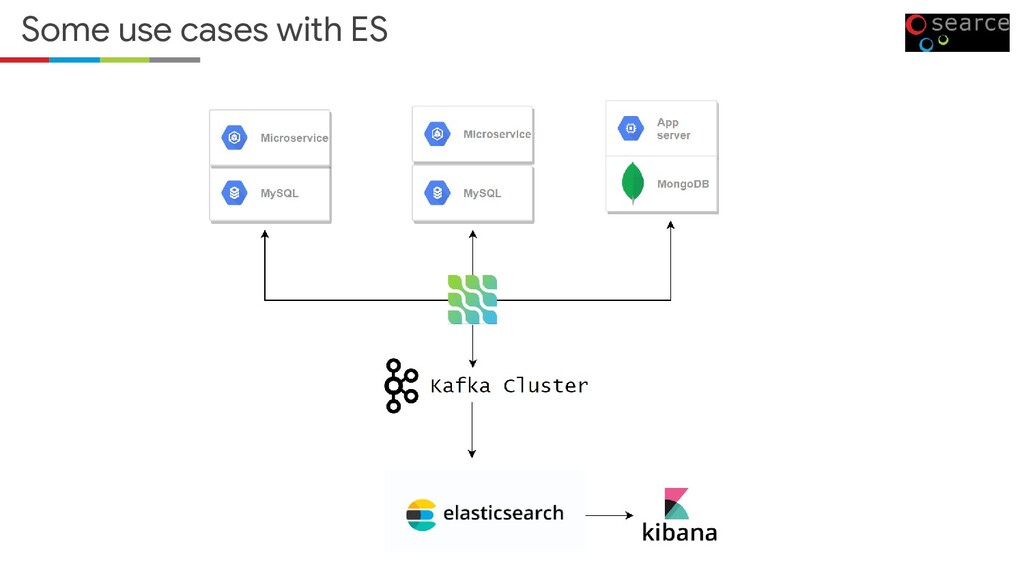
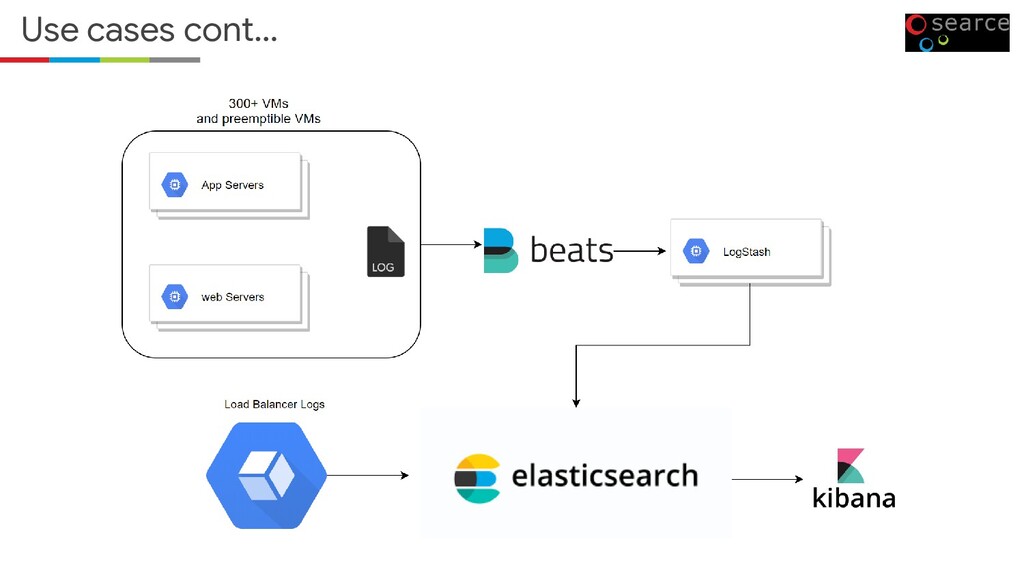
Source search and analytical engine • Elasticsearch is the central component of the Elastic Stack • Distributed processing • Works with all types of data (textual, numerical, geospatial, structured, and unstructured) • Powerful REST API • And everything is indexed
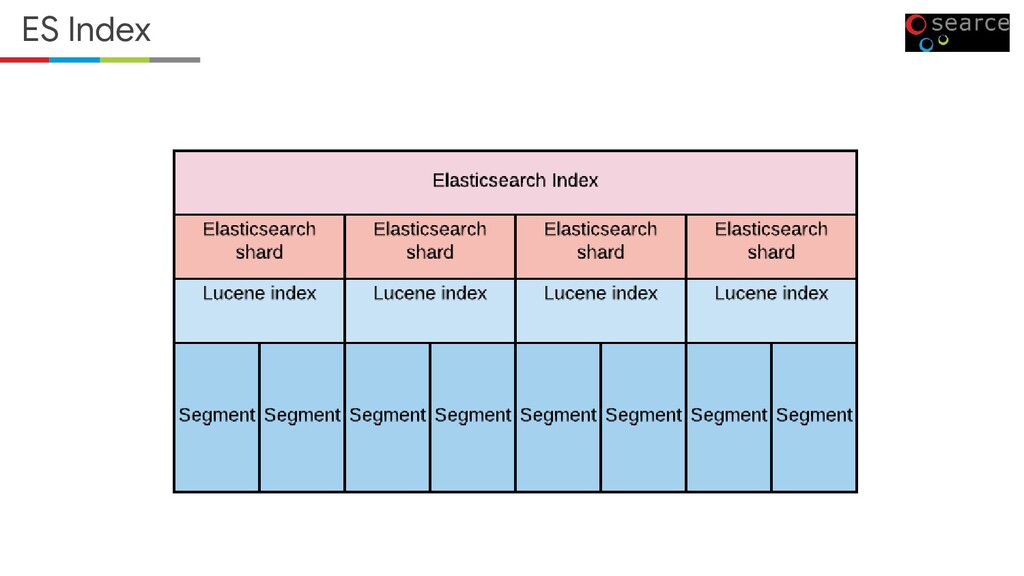
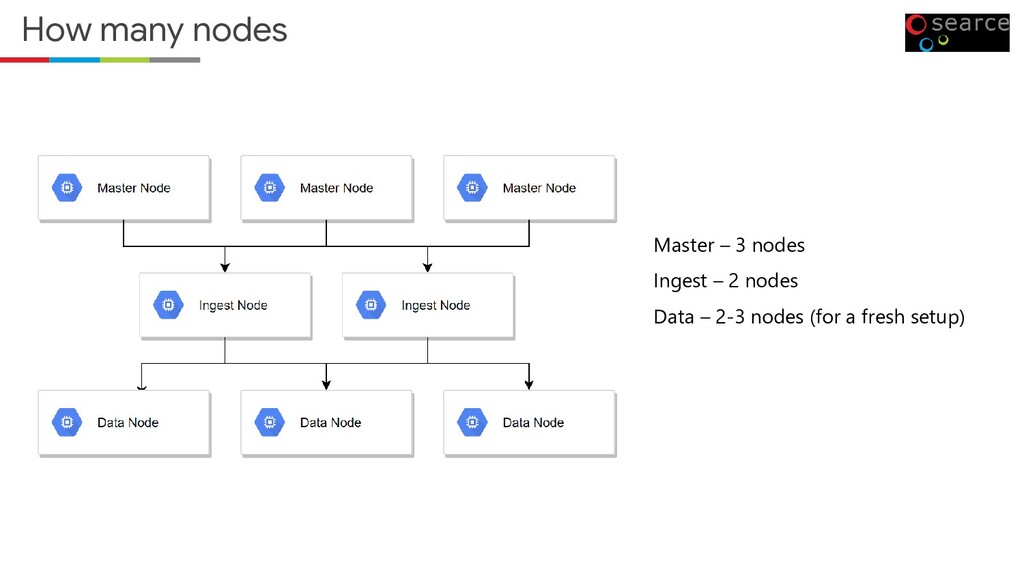
• Responsible for maintaining the metadata about the cluster. • Decide where to move the data and relocating the data. • We can have multiple nodes for Master role. • But Elasticsearch will select any one of the node as an elastic master. • In the event of failure, a new elastic master will be selected from the available nodes.
here. • Responsible for managing the stored data. • Perform the operations when it queried. Ingest Node • Pre-process’s documents before the actual document indexing. • The ingest node intercepts bulk and index requests, applies transformations, and it then passes the documents back to the index or bulk APIs.
VM instance is subject to maximum network egress throughput caps. These caps are dependent on the number of vCPUs that the VM instance has. Each vCPU is subject to a 2 Gbps cap for peak performance. Each additional vCPU increases the network cap, up to a theoretical maximum of 32 Gbps for each instance. The actual performance you experience will vary depending on your workload. All caps are meant as maximum possible performance, and not sustained performance.
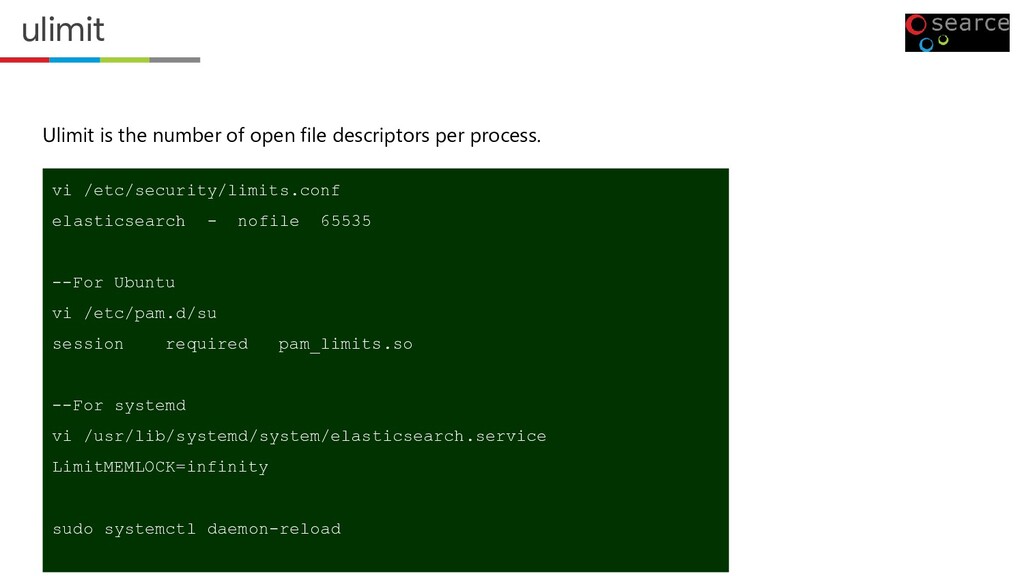
can’t give a tons of memory to the server. • The OS will swap out the unused applications memory. • That’s bad for the performance. Prevent Swapping 1. From OS Level(temporarily) - sudo swapoff –a 2. Configure swappiness from the Kernal - vm.swappiness=1 3. Enable bootstrap-memory_lock - bootstrap.memory_lock: true
use a heap with a minimum and maximum size of 1 GB. • When moving to production, it is important to configure heap size to ensure that Elasticsearch has enough heap available. • Set the Heap size <50% of your total Memory “The more heap available to Elasticsearch, the more memory it can use for its internal caches, larger heaps can cause longer garbage collection pauses” – From Elastic
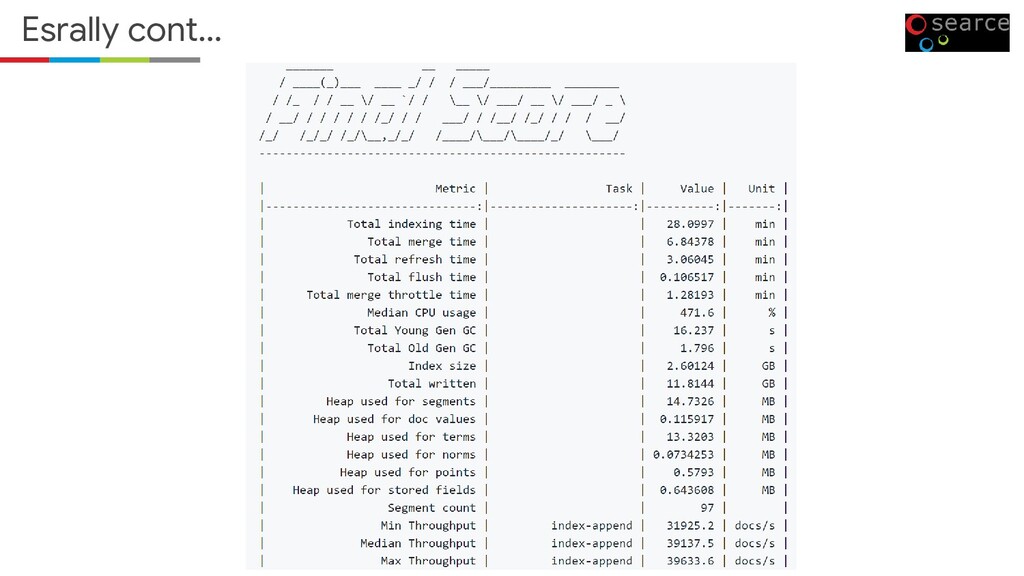
to benchmark Elasticsearch? Then Rally is for you. It can help you with the following tasks: • Setup and teardown of an Elasticsearch cluster for benchmarking • Management of benchmark data and specifications even across Elasticsearch versions • Running benchmarks and recording results • Finding performance problems by attaching so-called telemetry devices • Comparing performance results pip3 install esrally
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}