Ad Networks act as the middleman between advertisers and publishers on the Internet. The advertiser is the agent that wants to allocate a particular ad in different medias. The publisher is the agent who owns the medias. These medias are usually web pages or mobile applications.
Session presented at Big Data Spain 2013 Conference
8th Nov 2013
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/2013/conference/ad-networks-analytics-using-hadoop-and-splout-sql
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
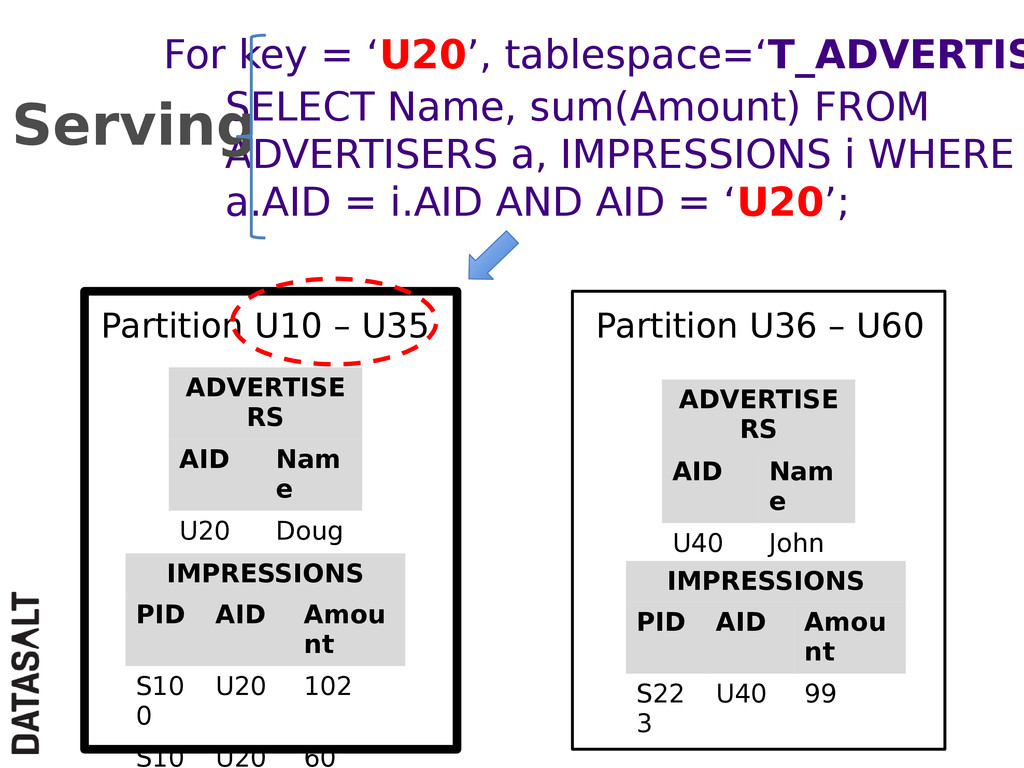{kind=link}
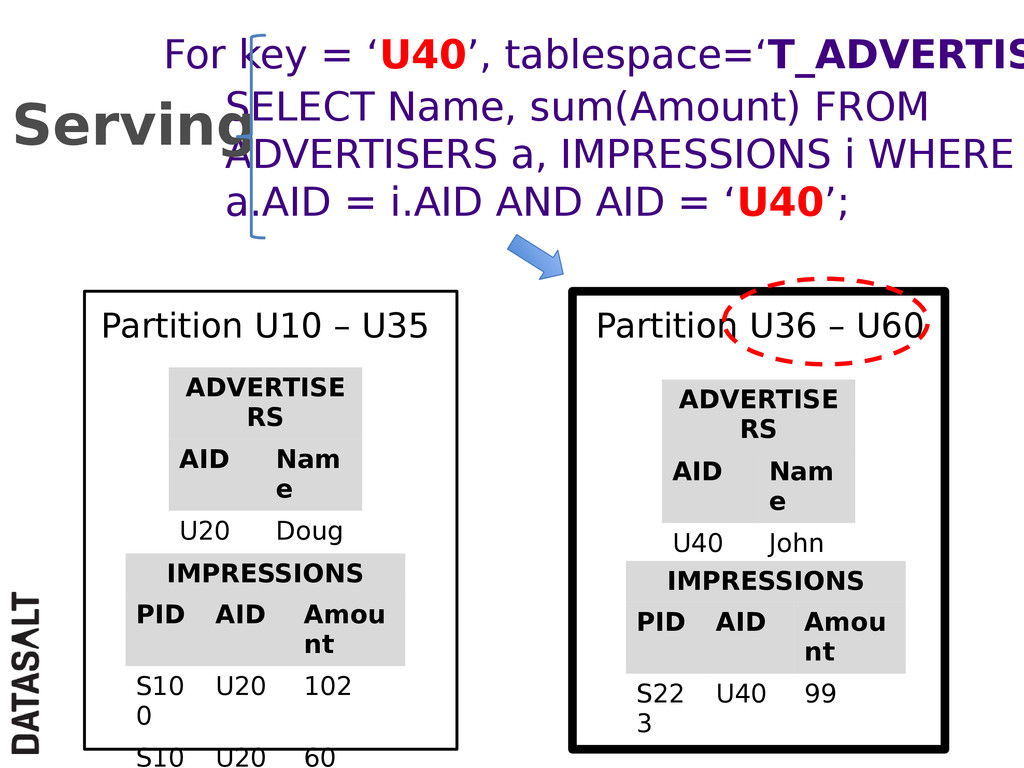{kind=link}
{kind=link}
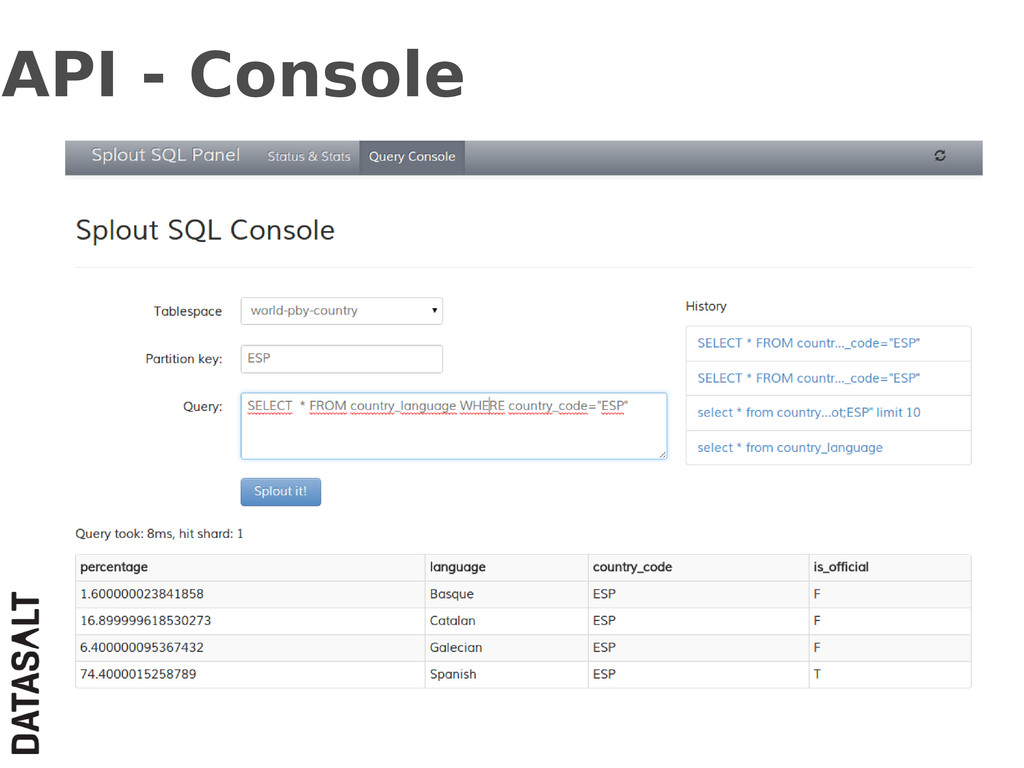{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}