2012 • An example from a talk byJimmy Lin at Hadoop Summit 2012 on calculations Twitter is doing via UDFs (user defined functions) in Pig. This equation uses stochastic gradient descent to do machine learning across with their data: w(t+1) =w(t) −γ(t)∇ (f(x;w(t)),y)
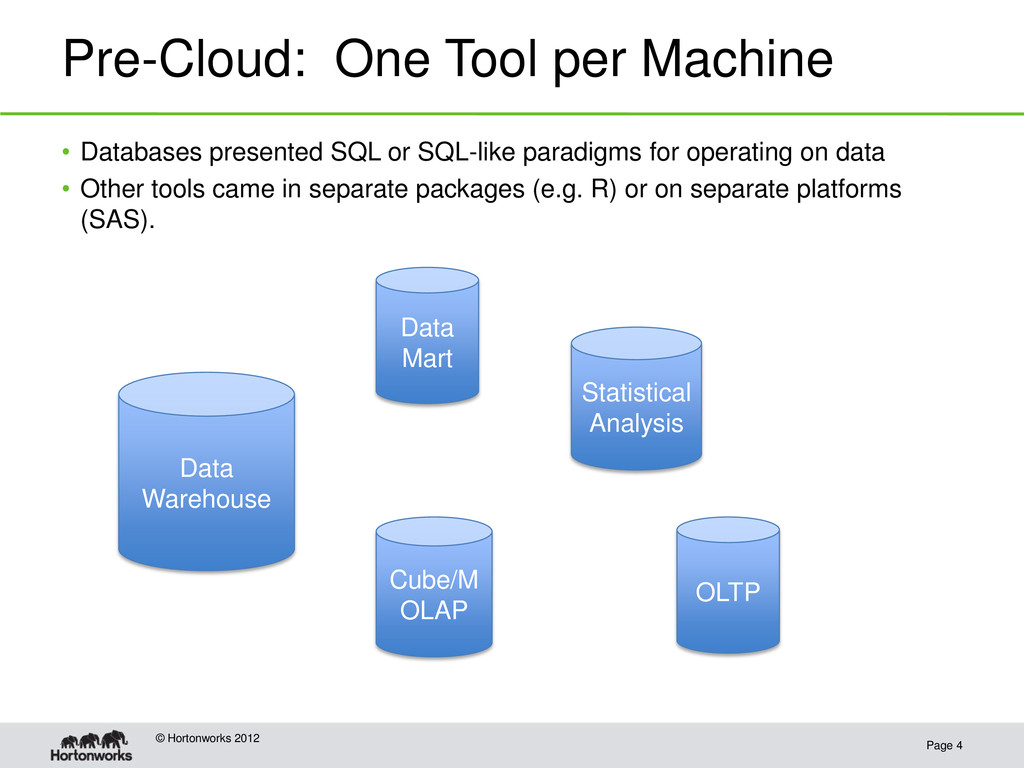
• Databases presented SQL or SQL-like paradigms for operating on data • Other tools came in separate packages (e.g. R) or on separate platforms (SAS). Data Warehouse Statistical Analysis Cube/M OLAP OLTP Data Mart
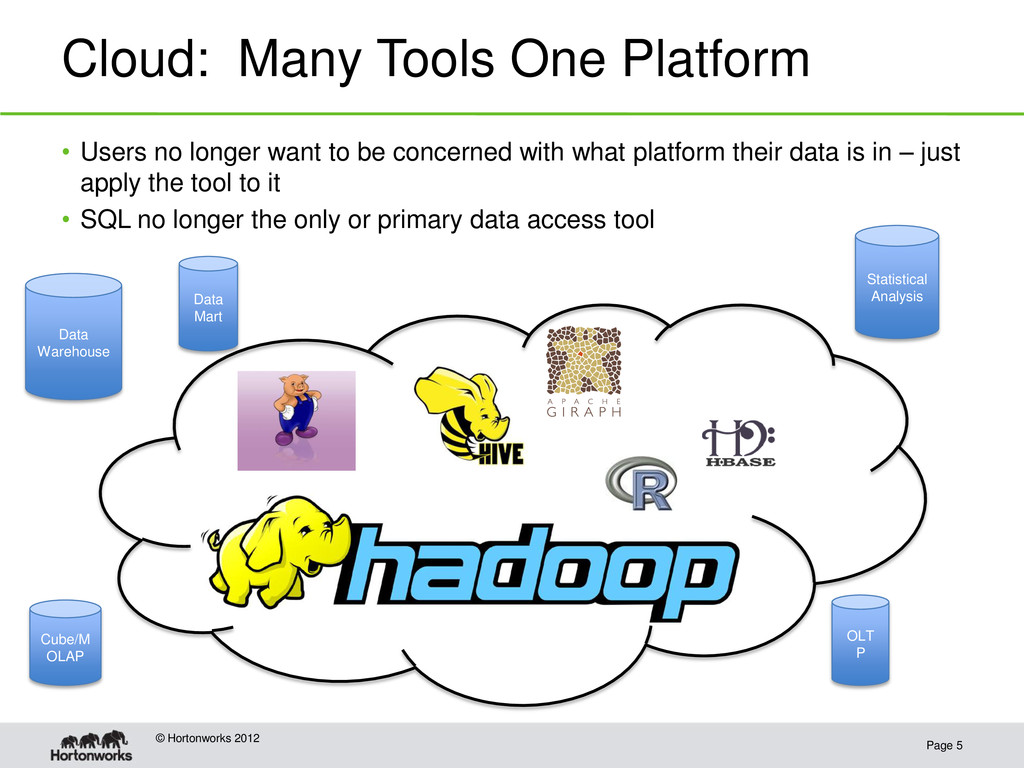
• Users no longer want to be concerned with what platform their data is in – just apply the tool to it • SQL no longer the only or primary data access tool Data Warehouse Statistical Analysis Data Mart Cube/M OLAP OLT P
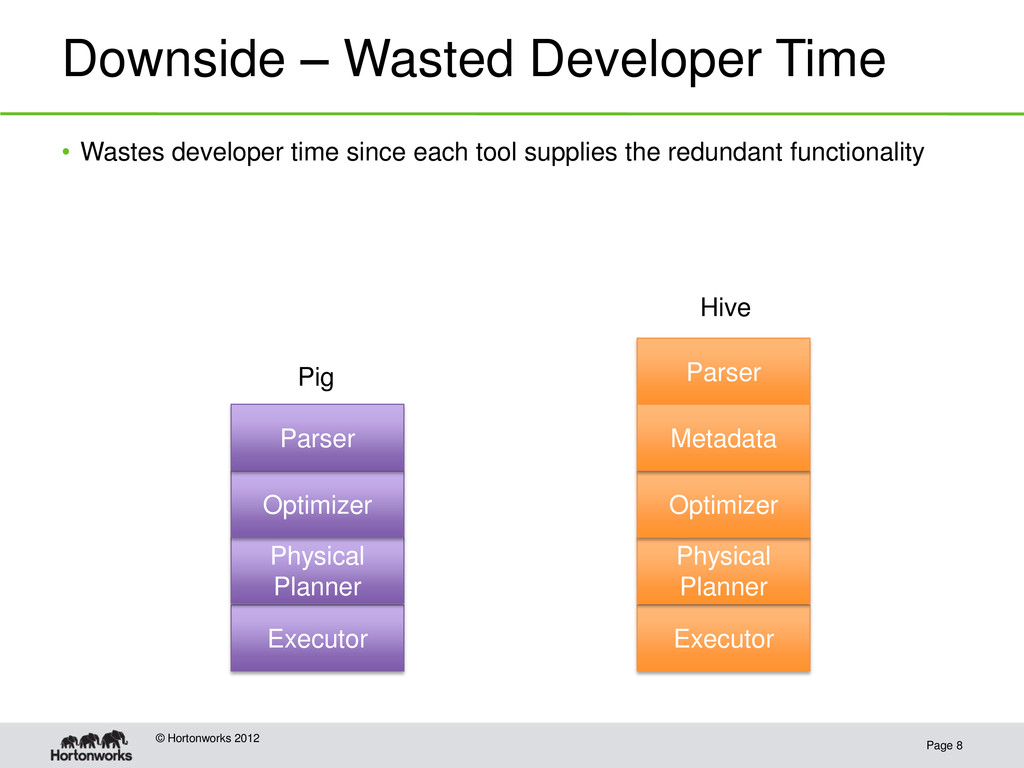
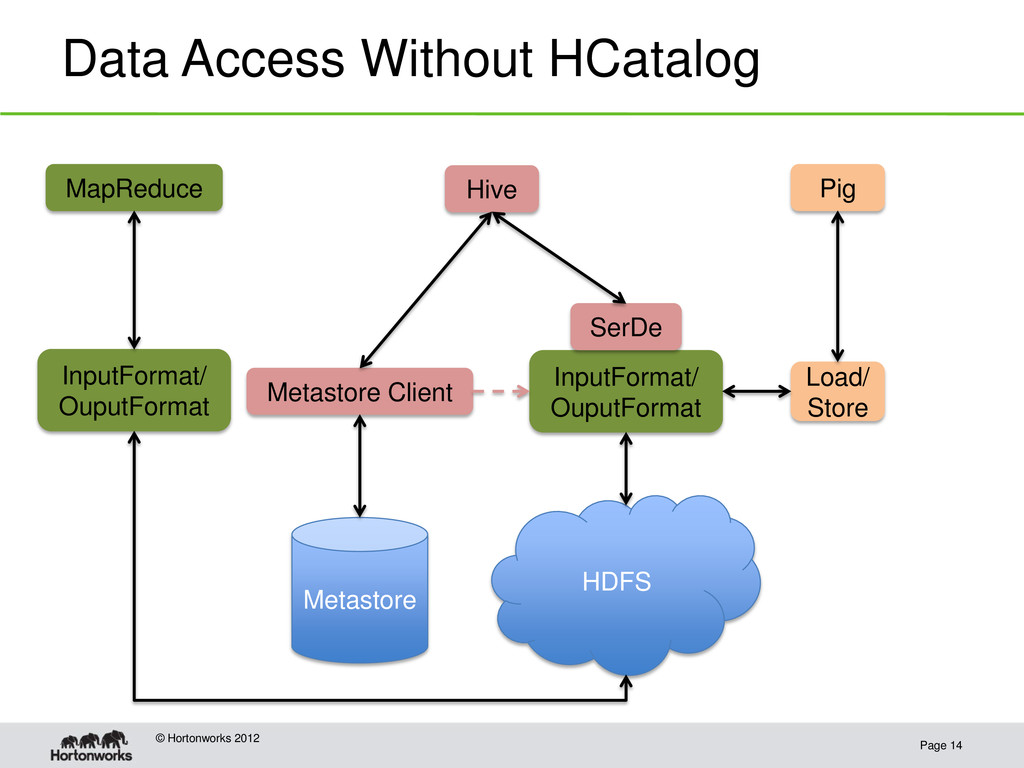
Hortonworks 2012 • Hard for users to share data between tools – Different storage formats – Different data models – Different user defined function interfaces
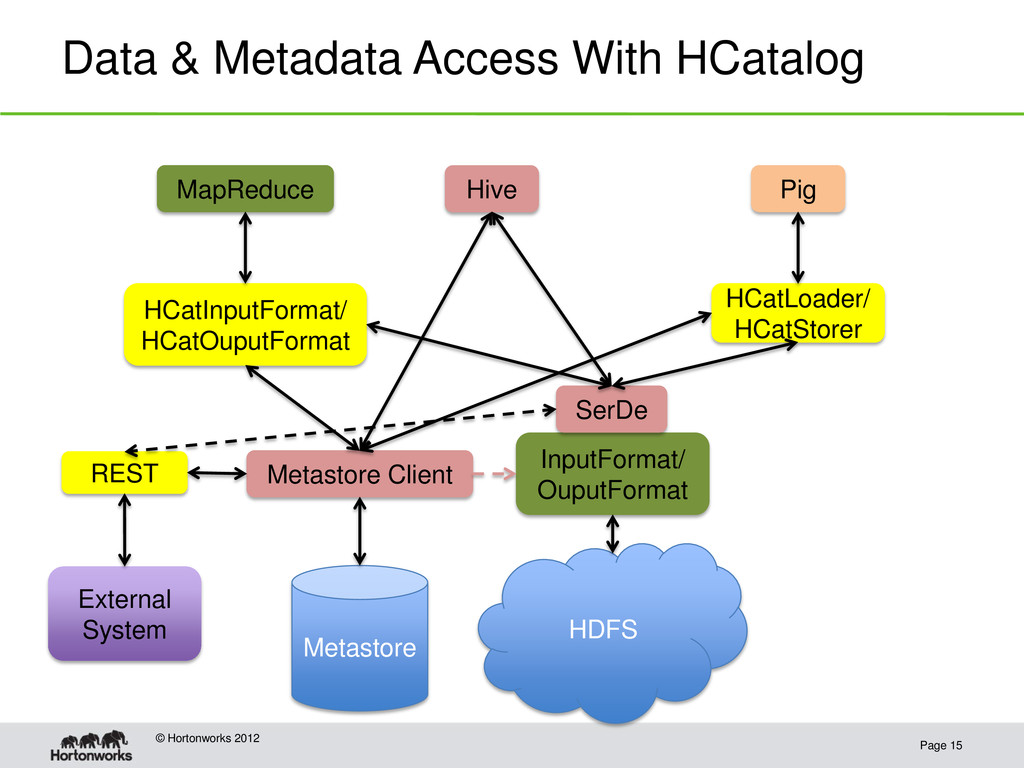
We need to find a way to share services where we can. • Gives users the same experience across tools • Allows developers to share effort when it makes sense
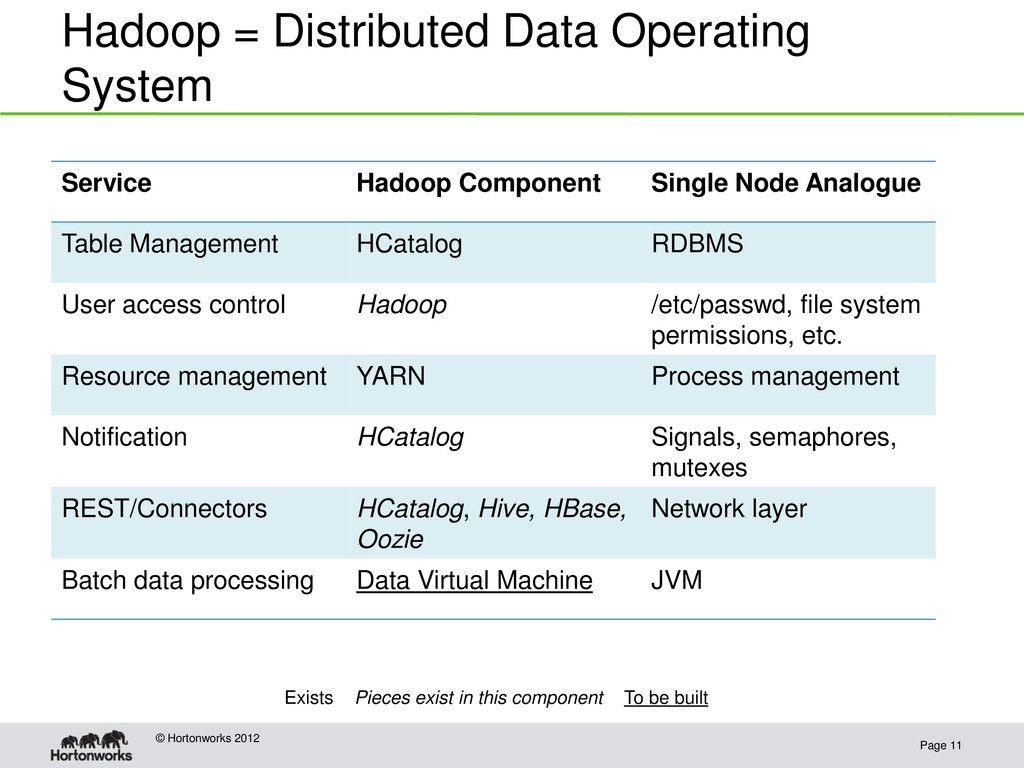
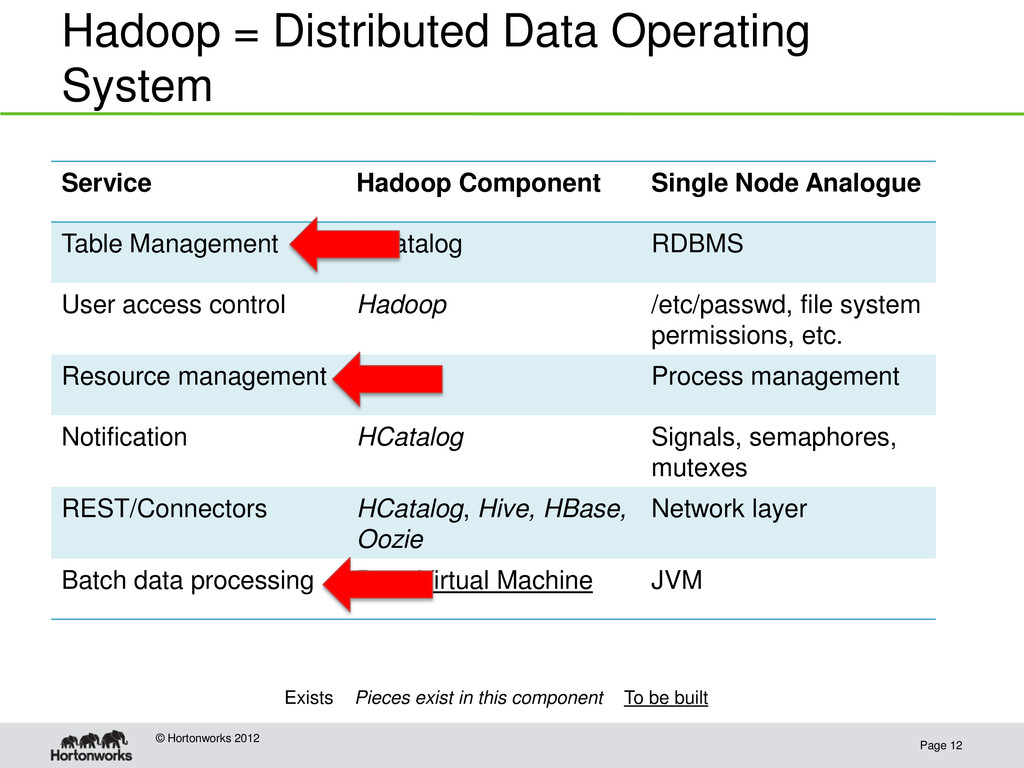
2012 Service Hadoop Component Single Node Analogue Table Management HCatalog RDBMS User access control Hadoop /etc/passwd, file system permissions, etc. Resource management YARN Process management Notification HCatalog Signals, semaphores, mutexes REST/Connectors HCatalog, Hive, HBase, Oozie Network layer Batch data processing Data Virtual Machine JVM Exists Pieces exist in this component To be built
2012 Service Hadoop Component Single Node Analogue Table Management HCatalog RDBMS User access control Hadoop /etc/passwd, file system permissions, etc. Resource management YARN Process management Notification HCatalog Signals, semaphores, mutexes REST/Connectors HCatalog, Hive, HBase, Oozie Network layer Batch data processing Data Virtual Machine JVM Exists Pieces exist in this component To be built
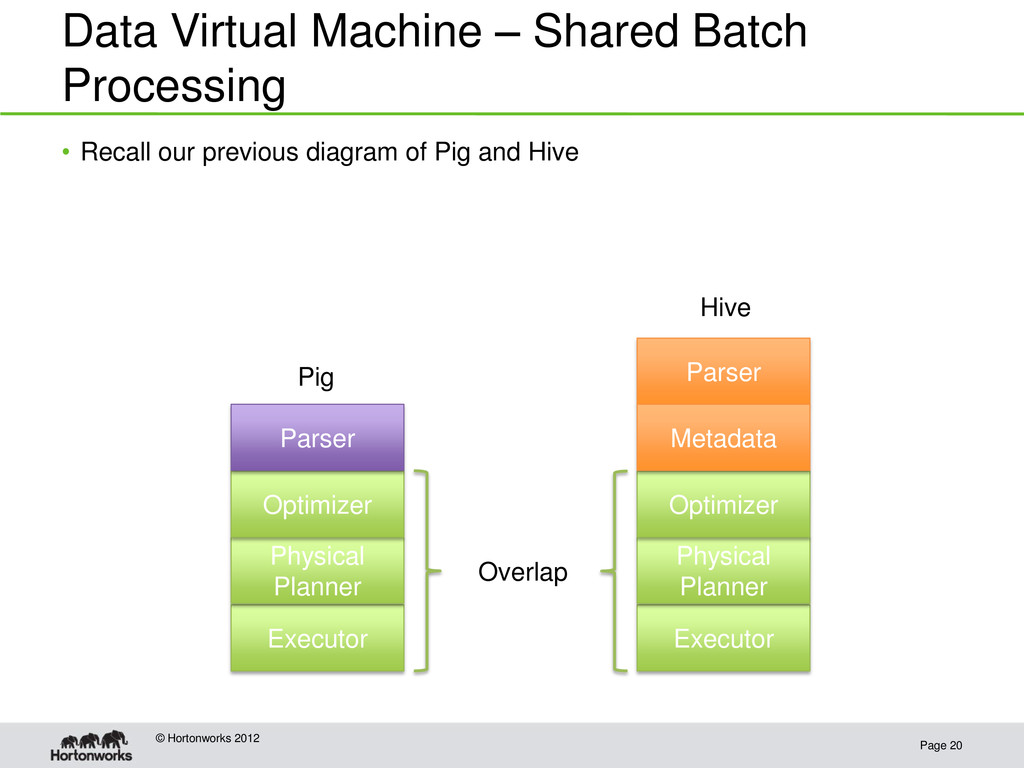
Opens up Hive’s tables to other tools inside and outside Hadoop • Presents tools with a table paradigm that abstracts away storage details • Provides a shared data model • Provides a shared code path for data and metadata access
Hive Record format Key value pairs Tuple Record Data model User defined int, float, string, bytes, maps, tuples, bags int, float, string, maps, structs, lists Schema Encoded in app Declared in script or read by loader Read from metadata Data location Encoded in app Declared in script Read from metadata Data format Encoded in app Declared in script Read from metadata
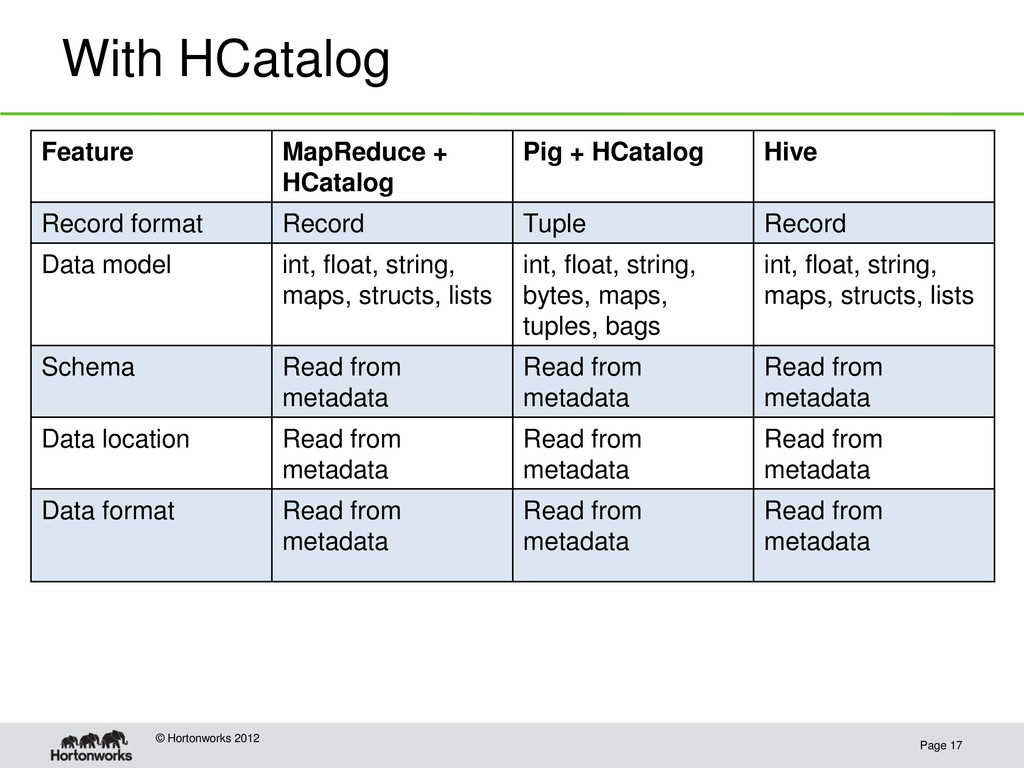
HCatalog Pig + HCatalog Hive Record format Record Tuple Record Data model int, float, string, maps, structs, lists int, float, string, bytes, maps, tuples, bags int, float, string, maps, structs, lists Schema Read from metadata Read from metadata Read from metadata Data location Read from metadata Read from metadata Read from metadata Data format Read from metadata Read from metadata Read from metadata
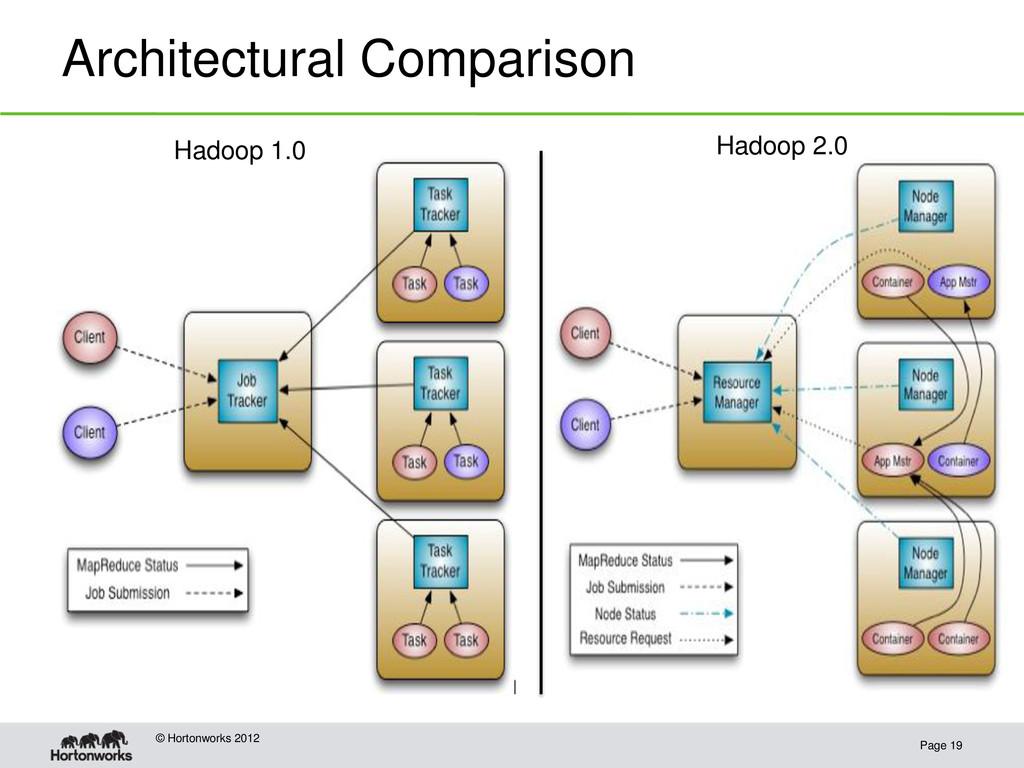
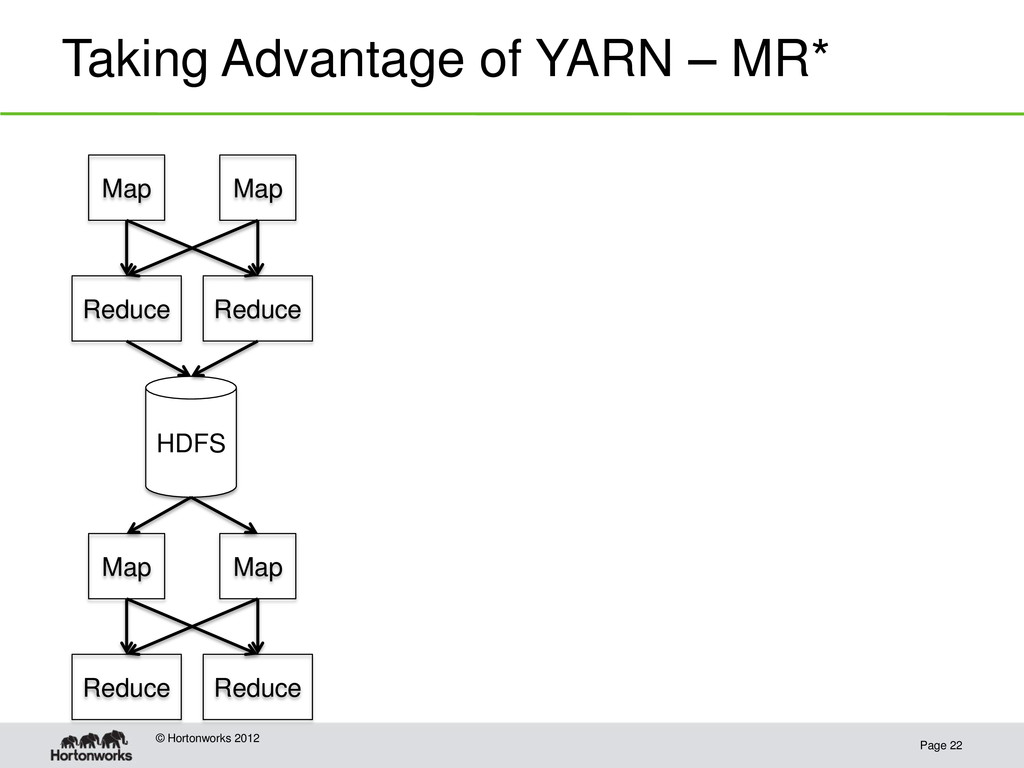
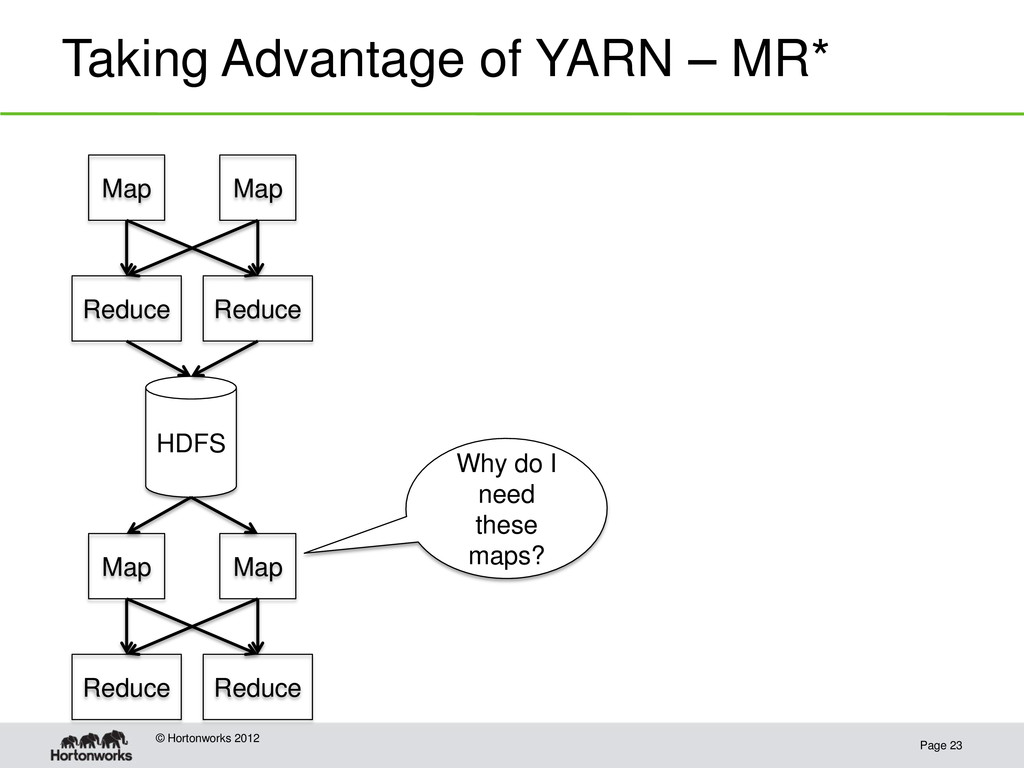
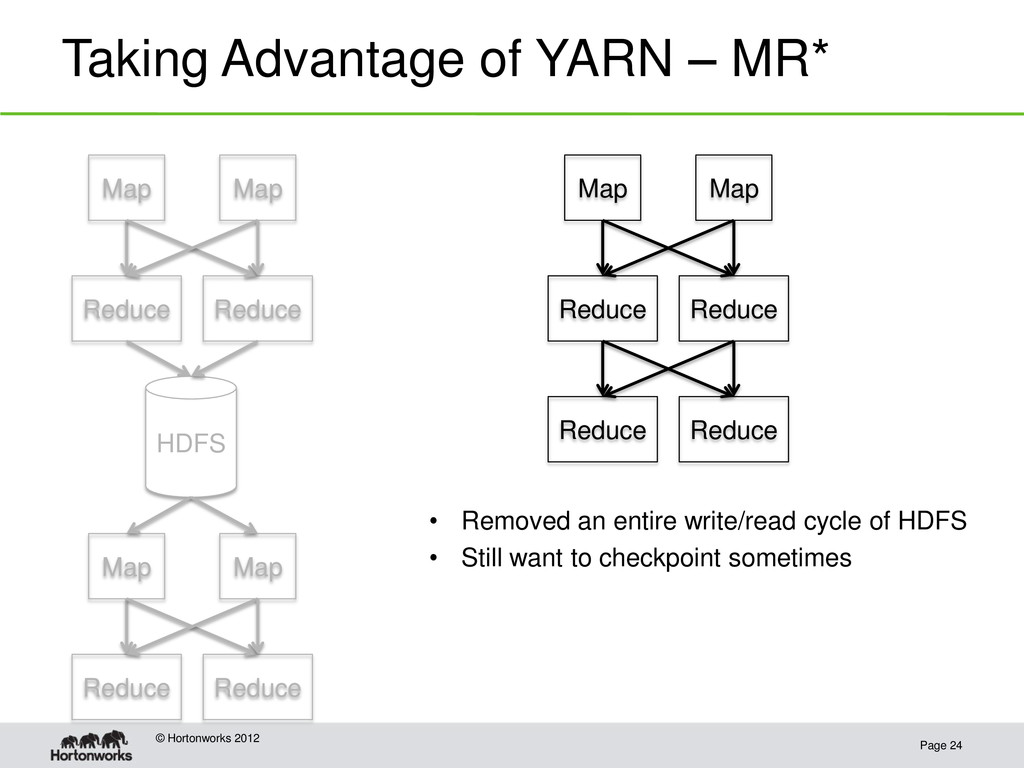
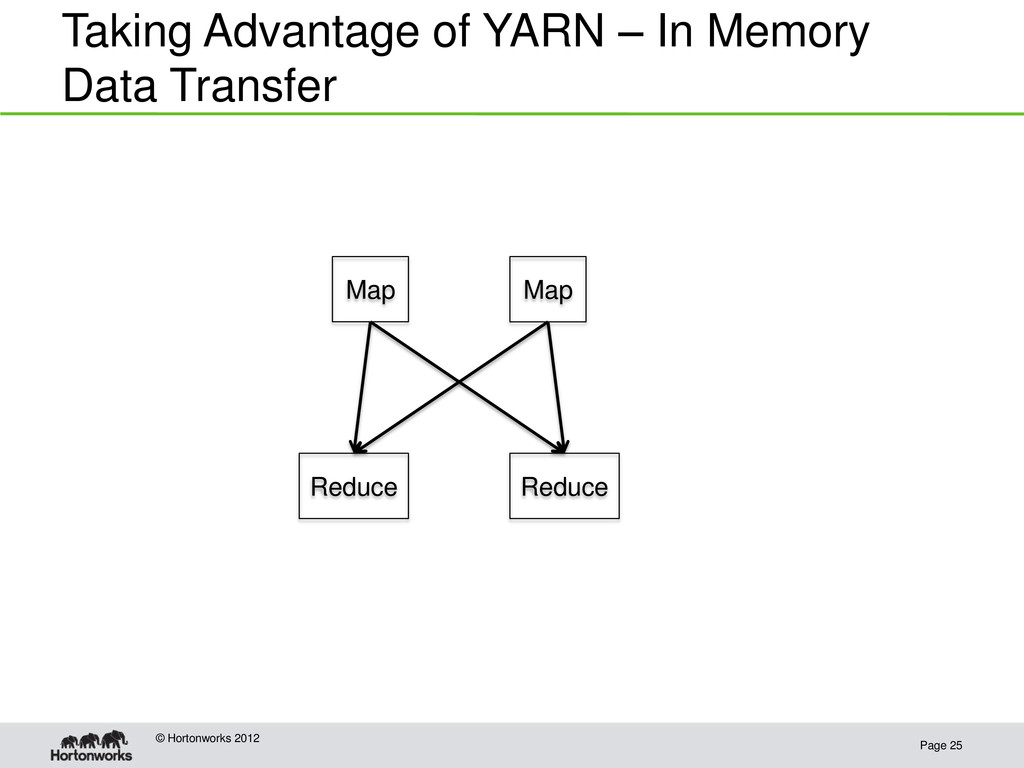
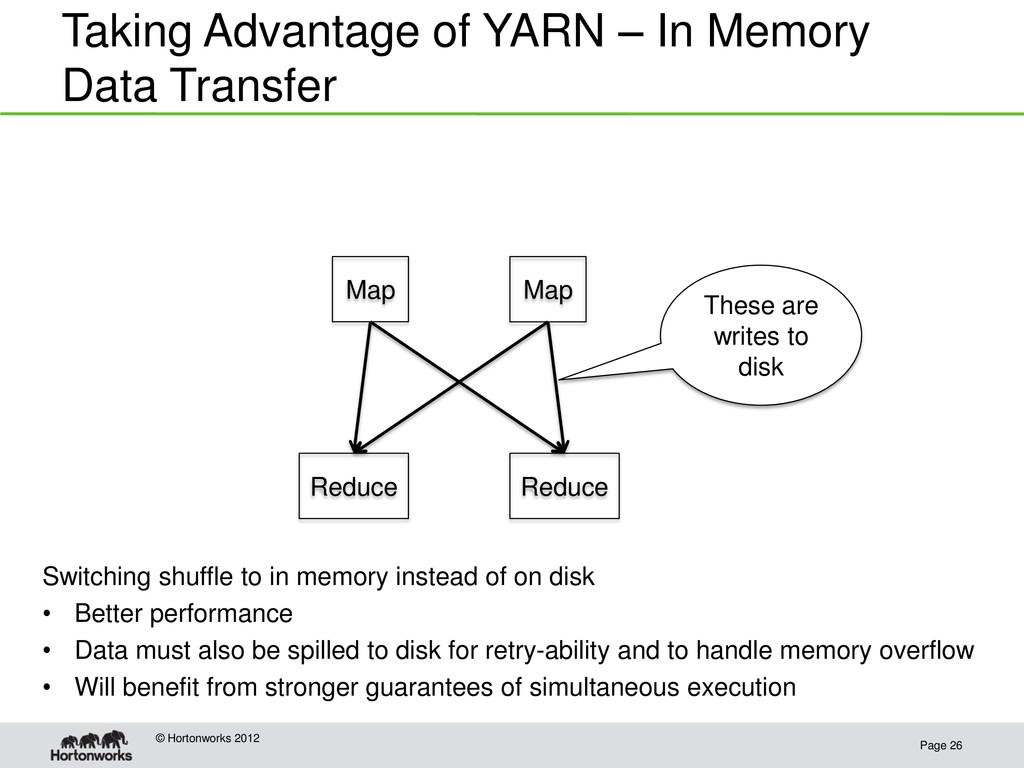
Hadoop 1.0: HDFS plus MapReduce • Hadoop 2.0: HDFS plus YARN Resource Manager, an interface for developers to write parallel applications on top of the Hadoop cluster • The Resource Manager provides: – applications a way to request resources in the cluster – allocation and scheduling of machine resource to the applications • MapReduce is now an application provided inside YARN • Other systems have been ported to YARN such as Spark (cluster computing system that focuses on in memory operations) and Storm (streaming computations)
Standard operators (equivalent of Java byte codes): – Project – Select – Join – Aggregate – Sort – … • An optimizer that could – Choose appropriate implementation of an operator based on physical data characteristics – Dynamically re-optimize the plan based on information gathered executing the plan • Shared execution layer – Can provide its own YARN application master and improve on MapReduce paradigm for batch processing • Shared User Defined Function (UDF) framework – user code works across systems
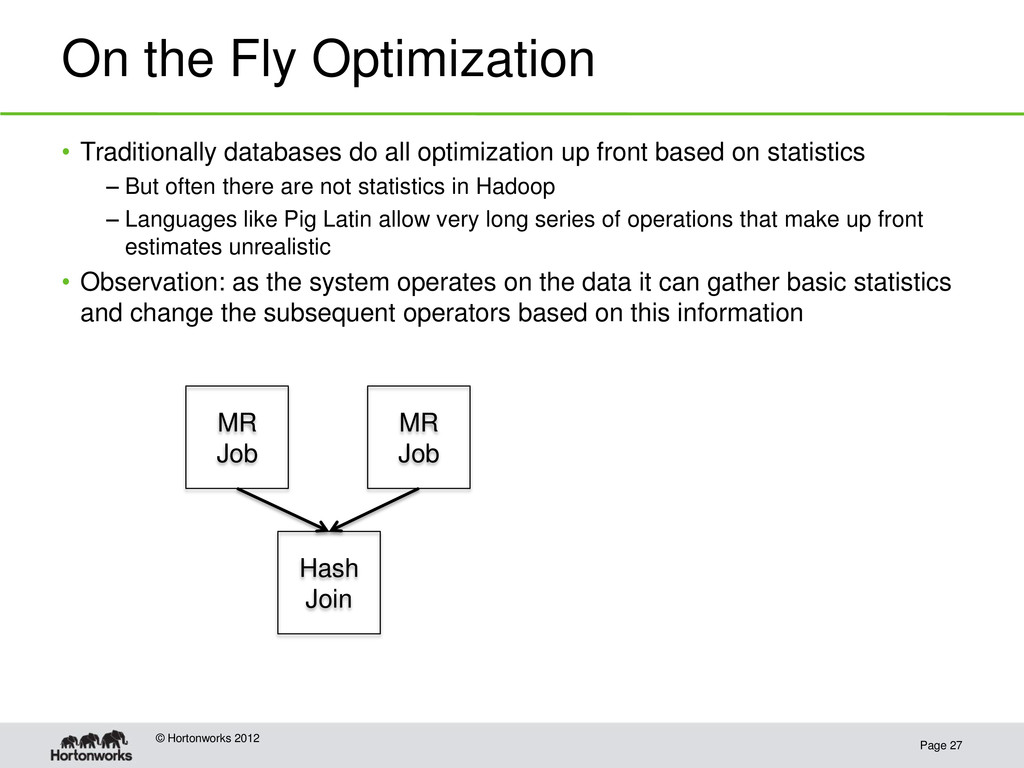
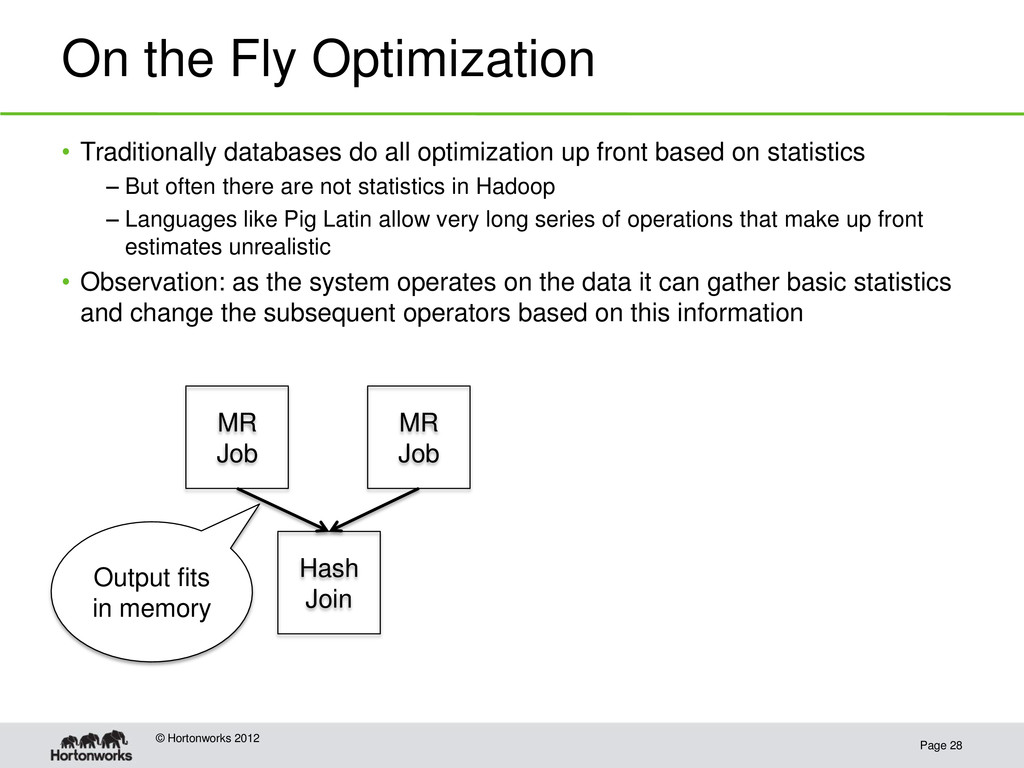
Traditionally databases do all optimization up front based on statistics – But often there are not statistics in Hadoop – Languages like Pig Latin allow very long series of operations that make up front estimates unrealistic • Observation: as the system operates on the data it can gather basic statistics and change the subsequent operators based on this information MR Job MR Job Hash Join
Traditionally databases do all optimization up front based on statistics – But often there are not statistics in Hadoop – Languages like Pig Latin allow very long series of operations that make up front estimates unrealistic • Observation: as the system operates on the data it can gather basic statistics and change the subsequent operators based on this information MR Job MR Job Hash Join Output fits in memory
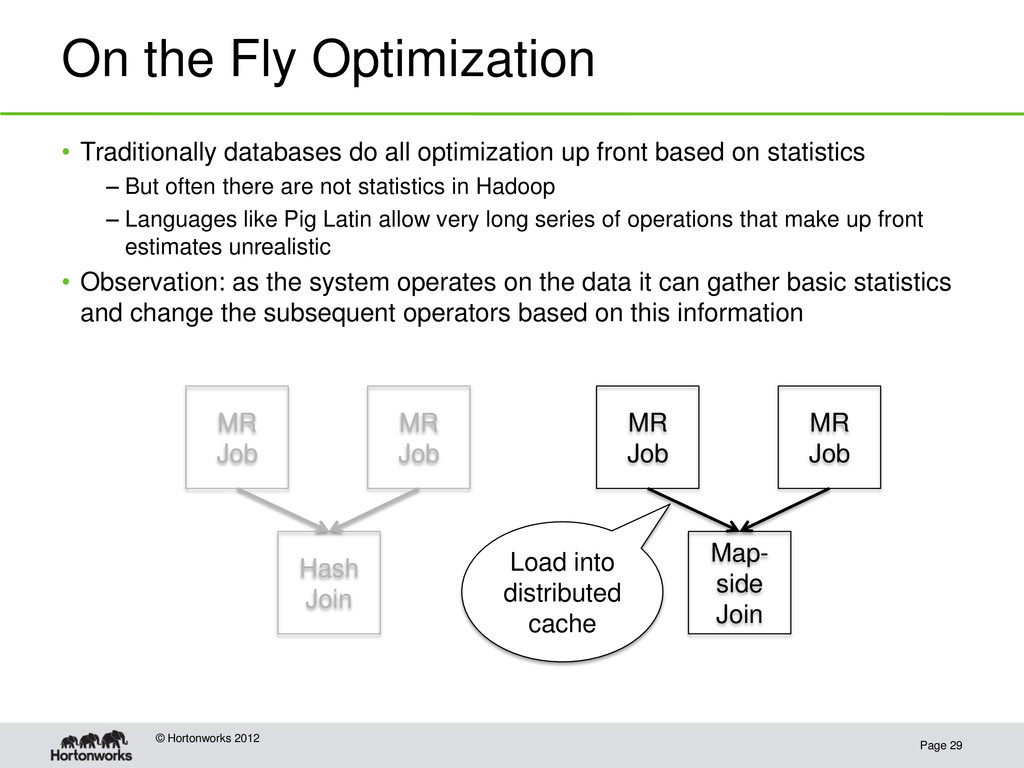
Traditionally databases do all optimization up front based on statistics – But often there are not statistics in Hadoop – Languages like Pig Latin allow very long series of operations that make up front estimates unrealistic • Observation: as the system operates on the data it can gather basic statistics and change the subsequent operators based on this information MR Job MR Job Hash Join MR Job MR Job Map- side Join Load into distributed cache
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}