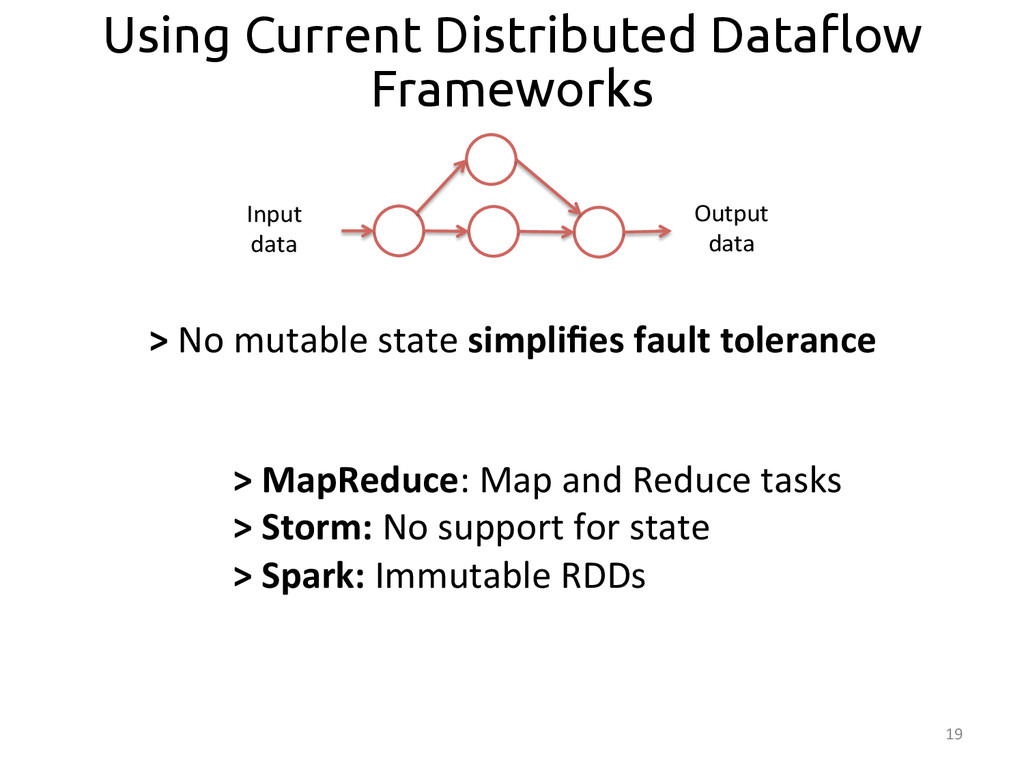
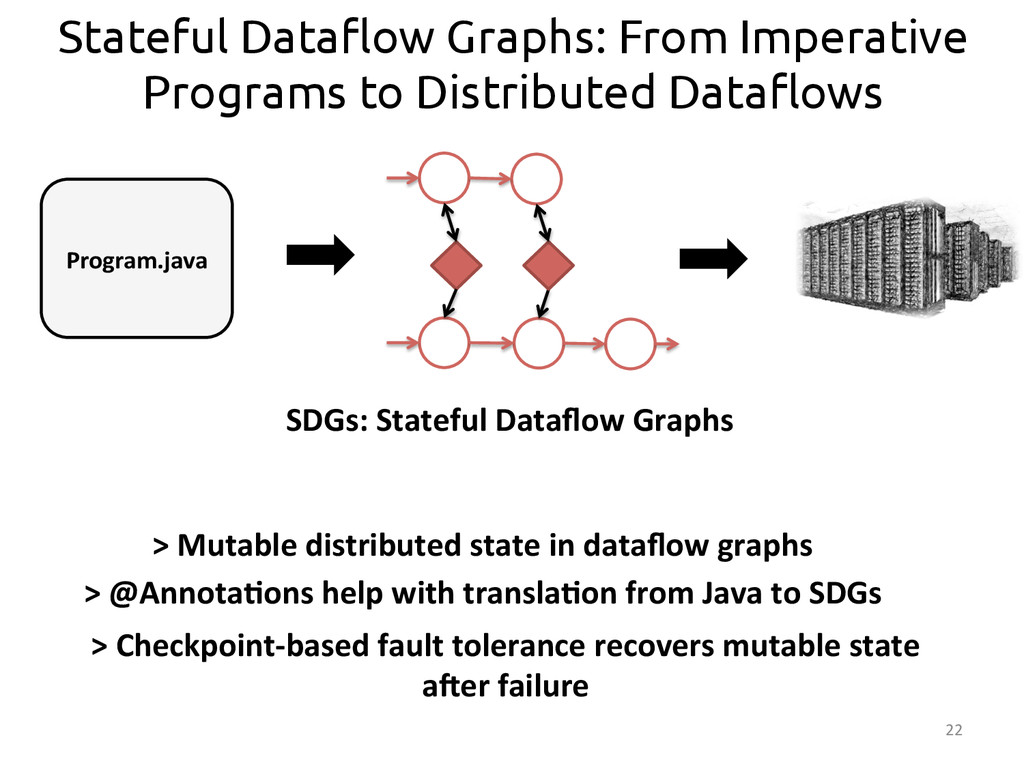
Dataflows are an omnipresent abstraction across many big data technologies due to its suitability for representing programs in a way that is easy to parallelize. All dataflow models---such as those of Spark or MapReduce---are stateless, which facilitates achieving fault tolerance, a crucial property when running at large-scale. However, this stateless dataflow models have a negative impact on the programming models they expose, which need to adapt to match the stateless nature of the underlying platforms. With the “democratization of data”, different types of users with different skills want answers from their big datasets, but sometimes they lack the skills required to write programs adapted to these specific frameworks: A familiar programming model becomes crucial to open big data value to a broader set of users.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
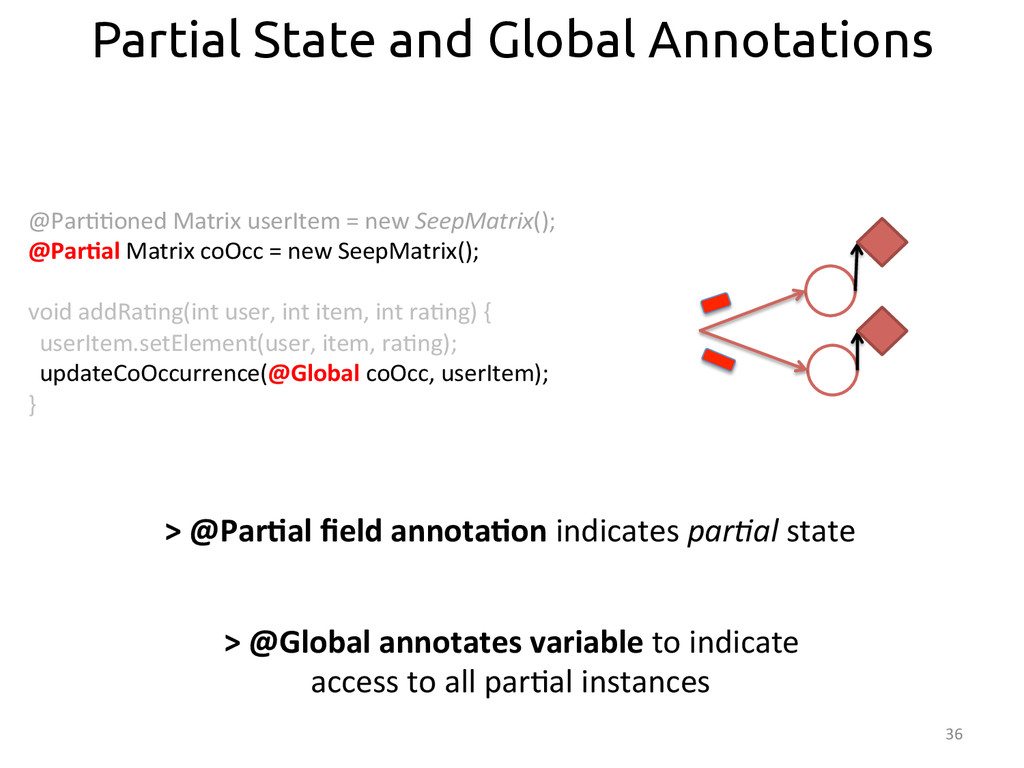{kind=link}
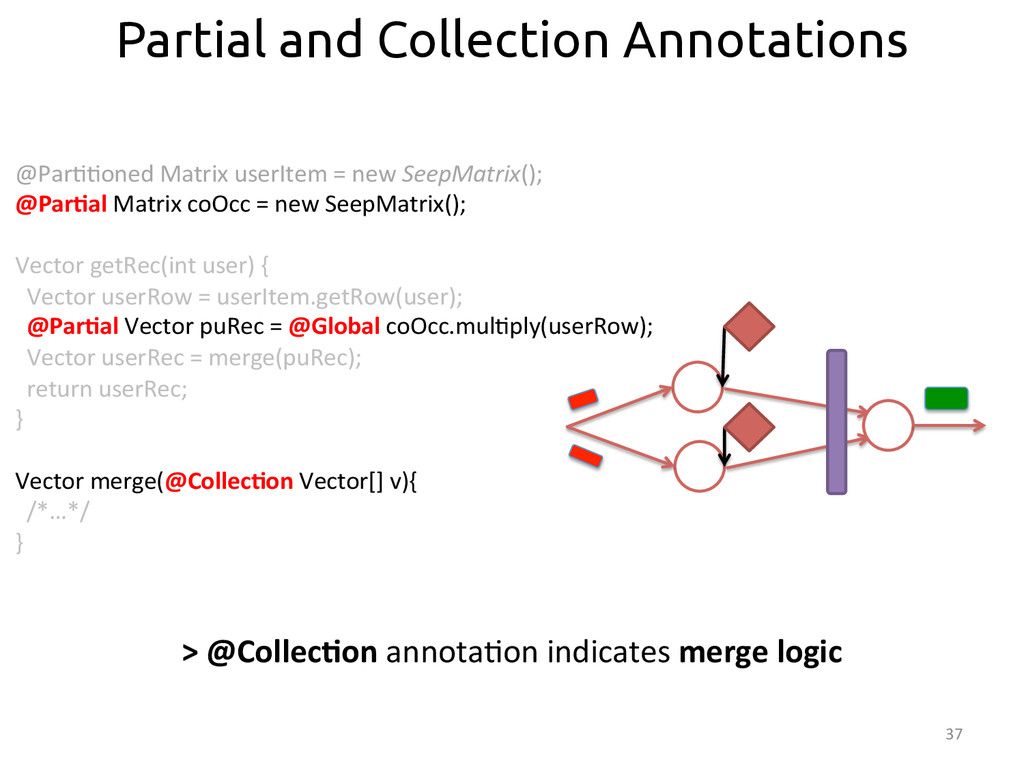{kind=link}
{kind=link}
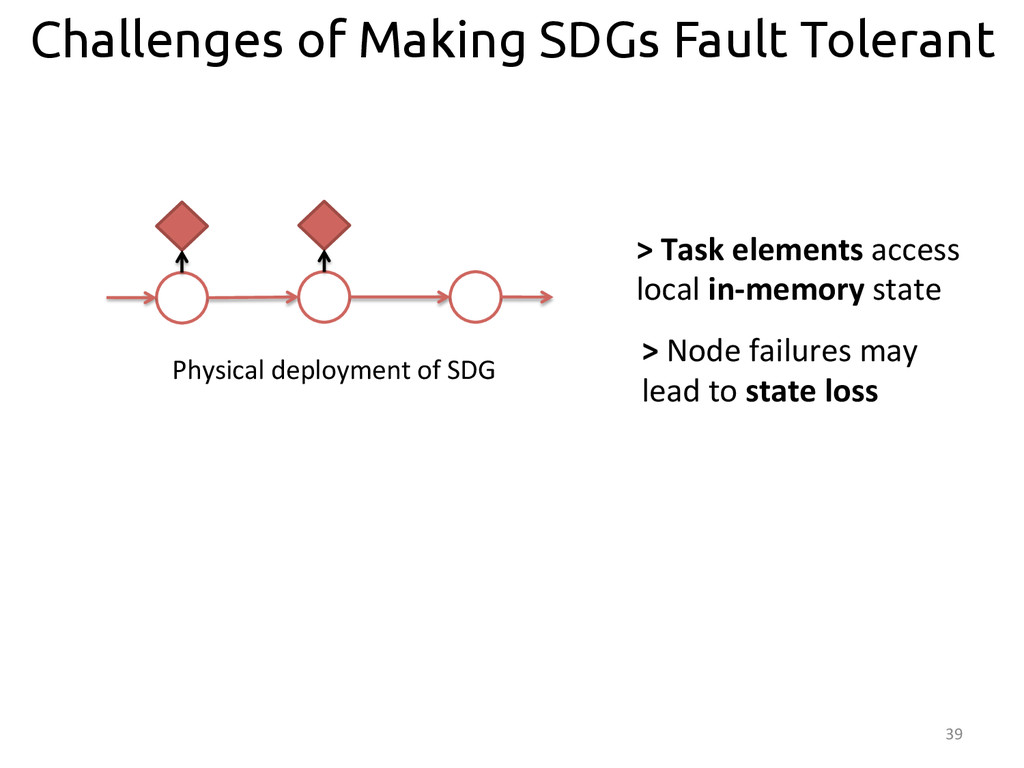{kind=link}
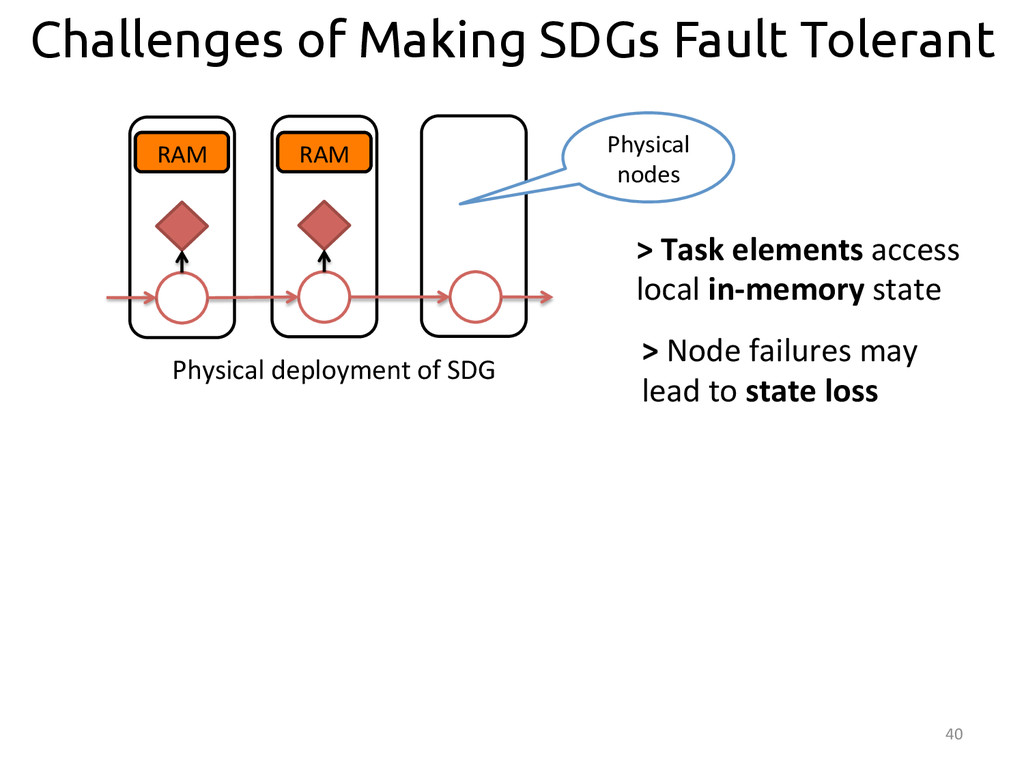{kind=link}
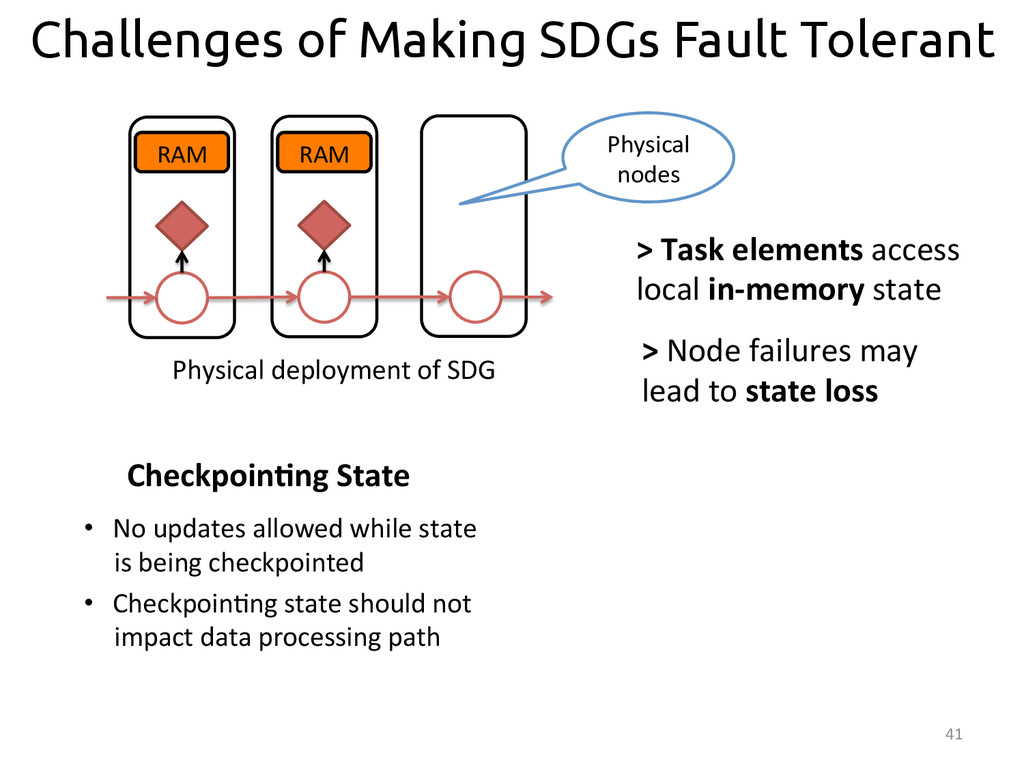{kind=link}
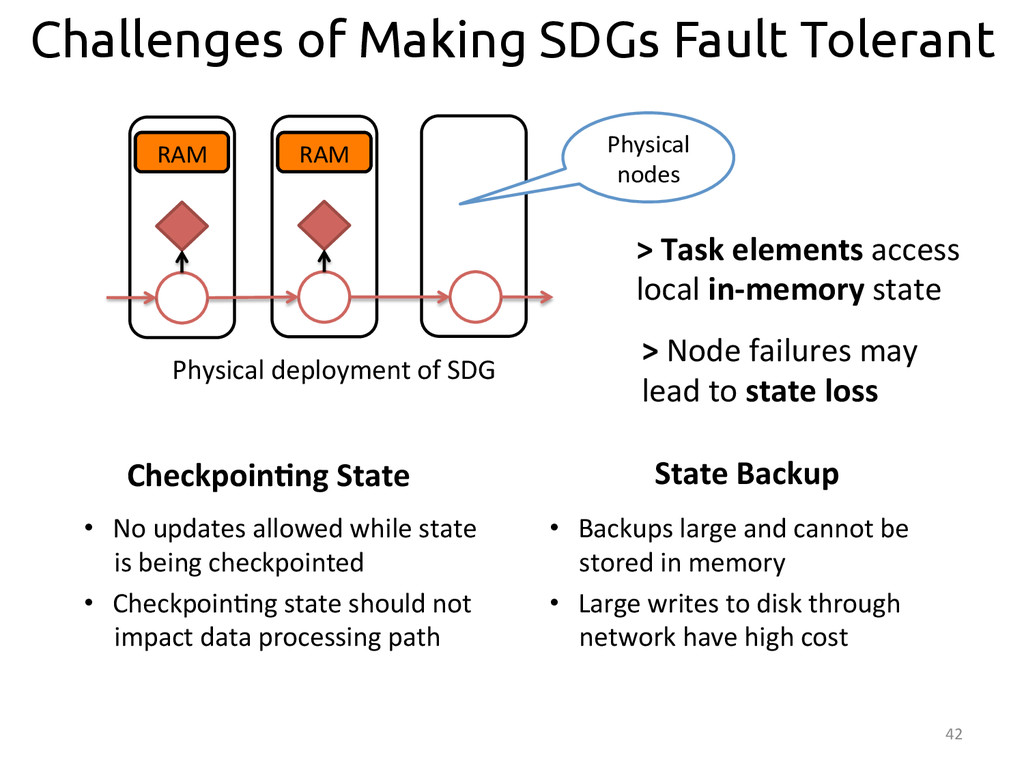{kind=link}
{kind=link}
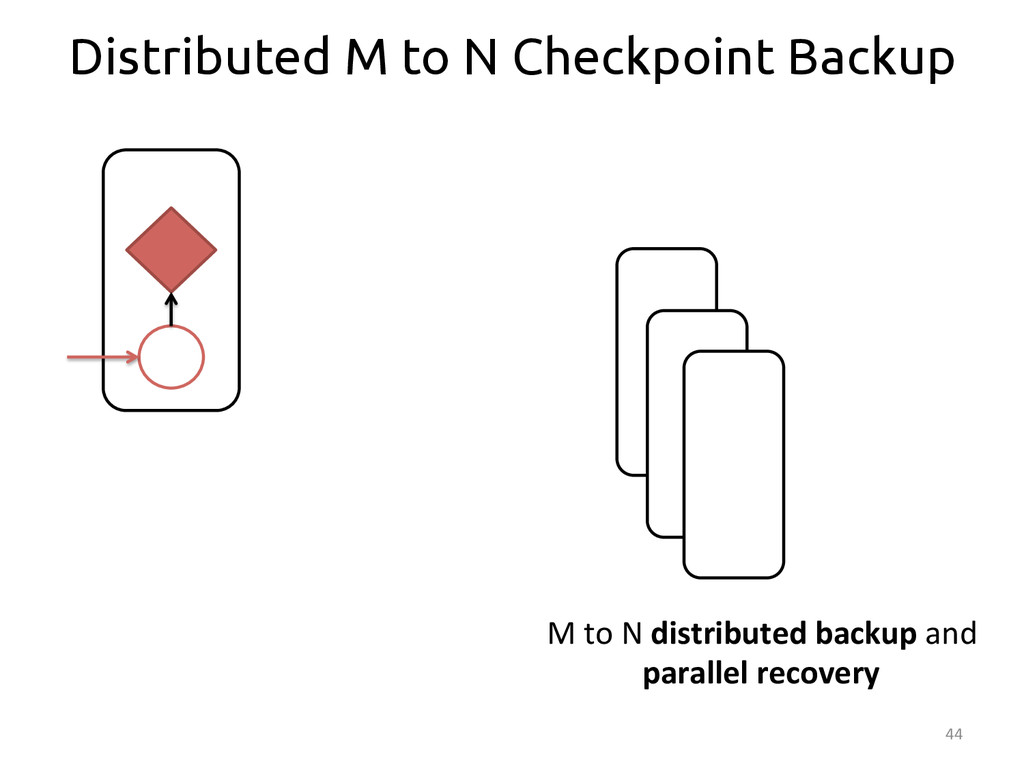{kind=link}
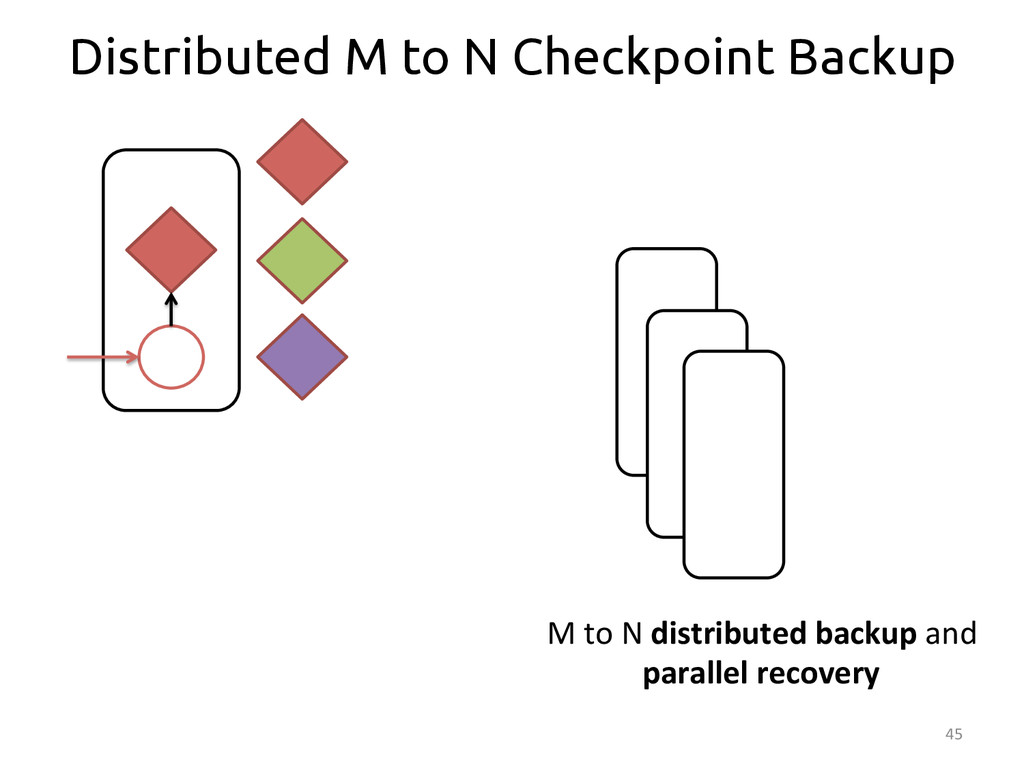{kind=link}
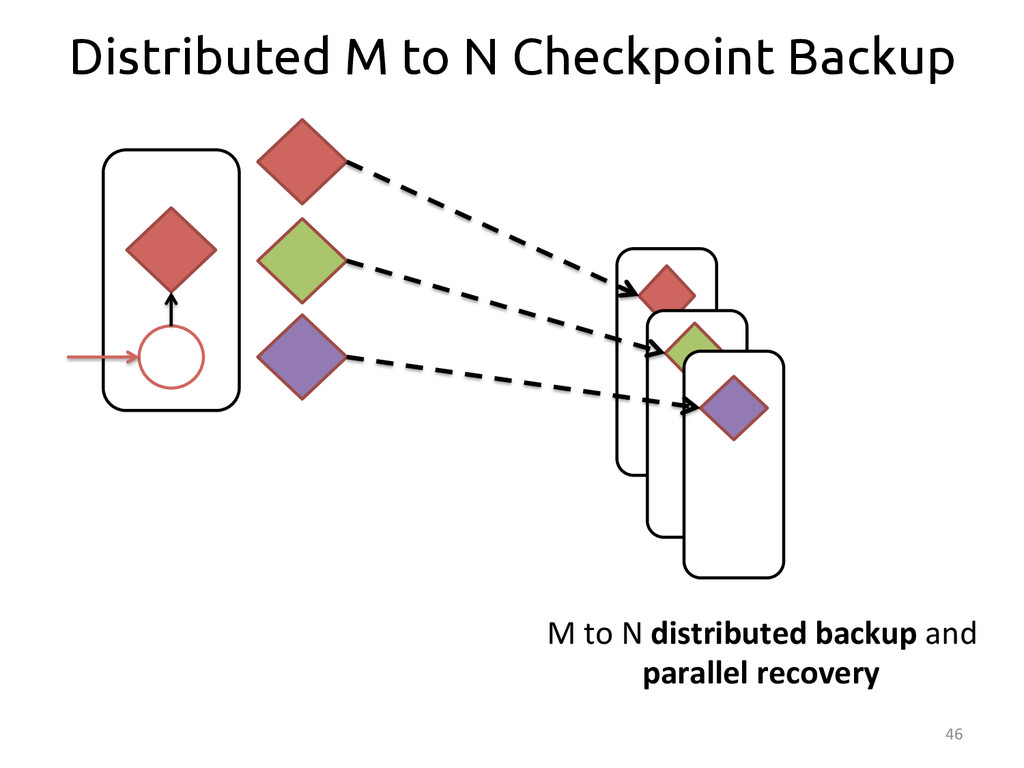{kind=link}
{kind=link}
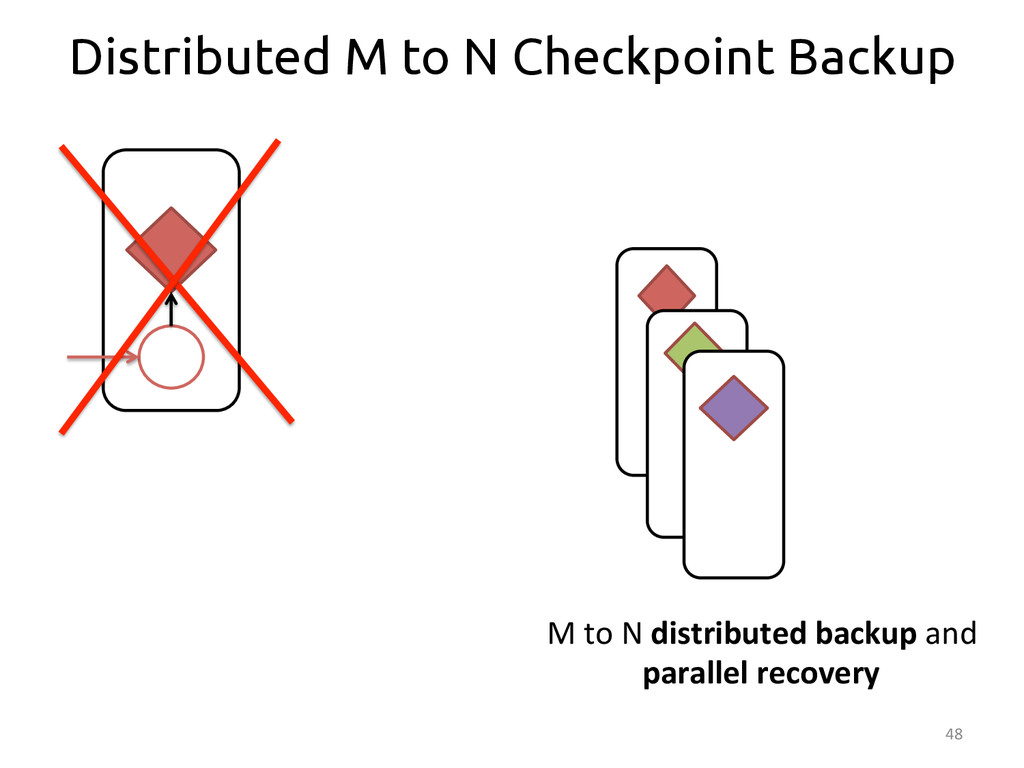{kind=link}
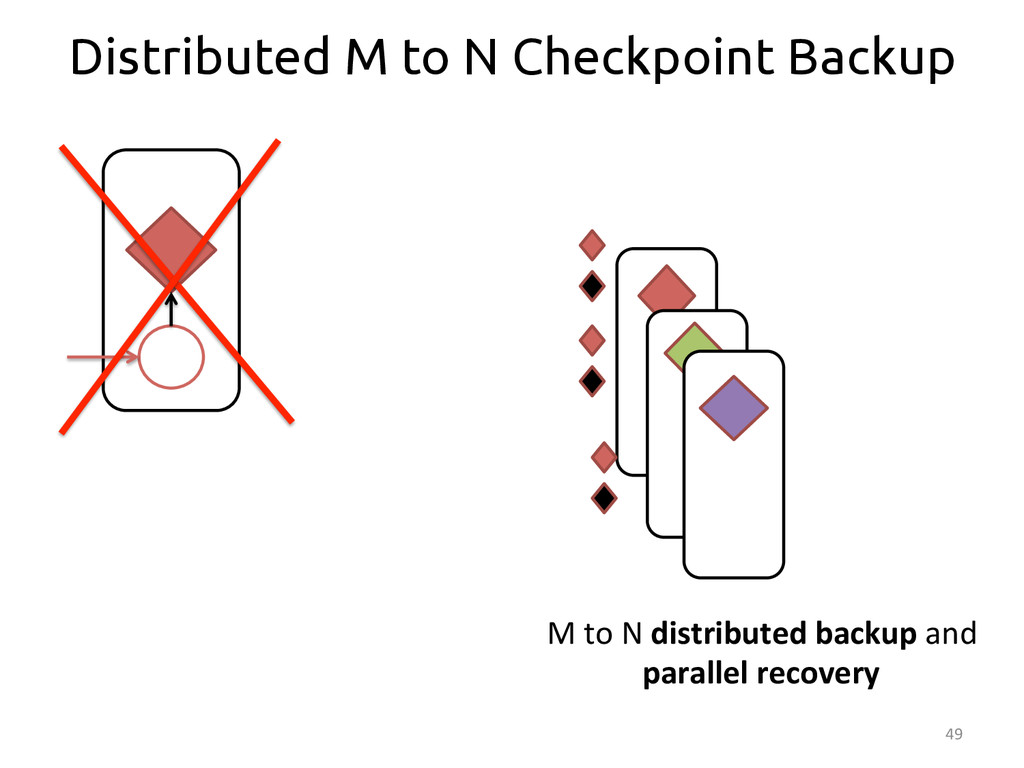{kind=link}
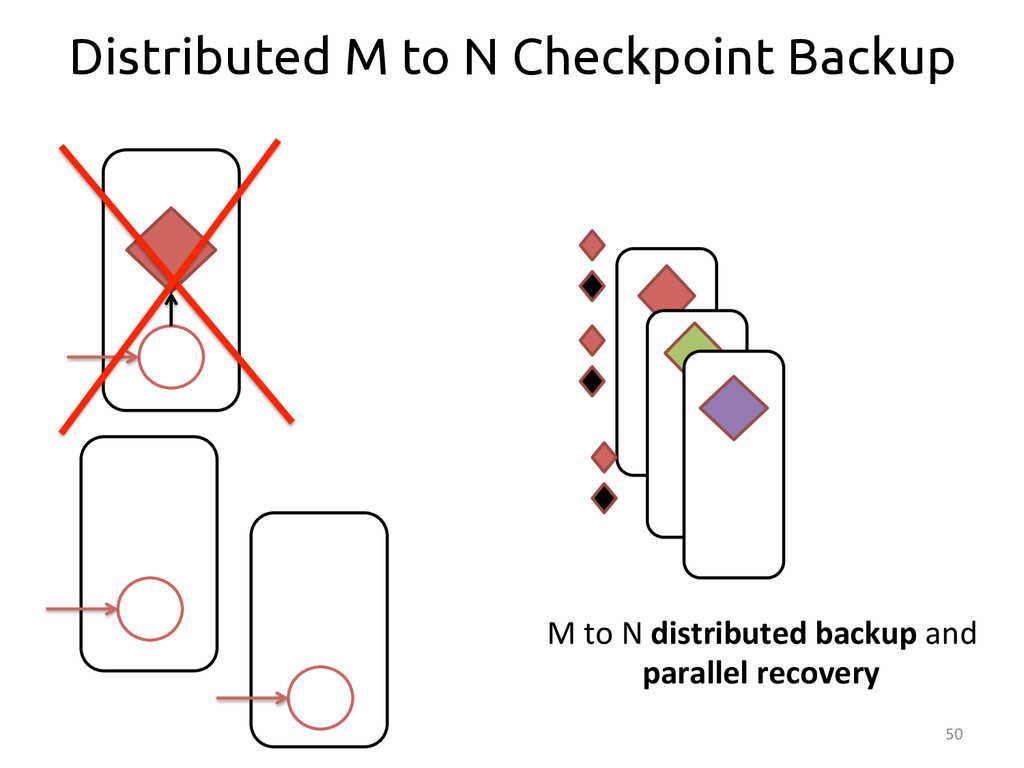{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
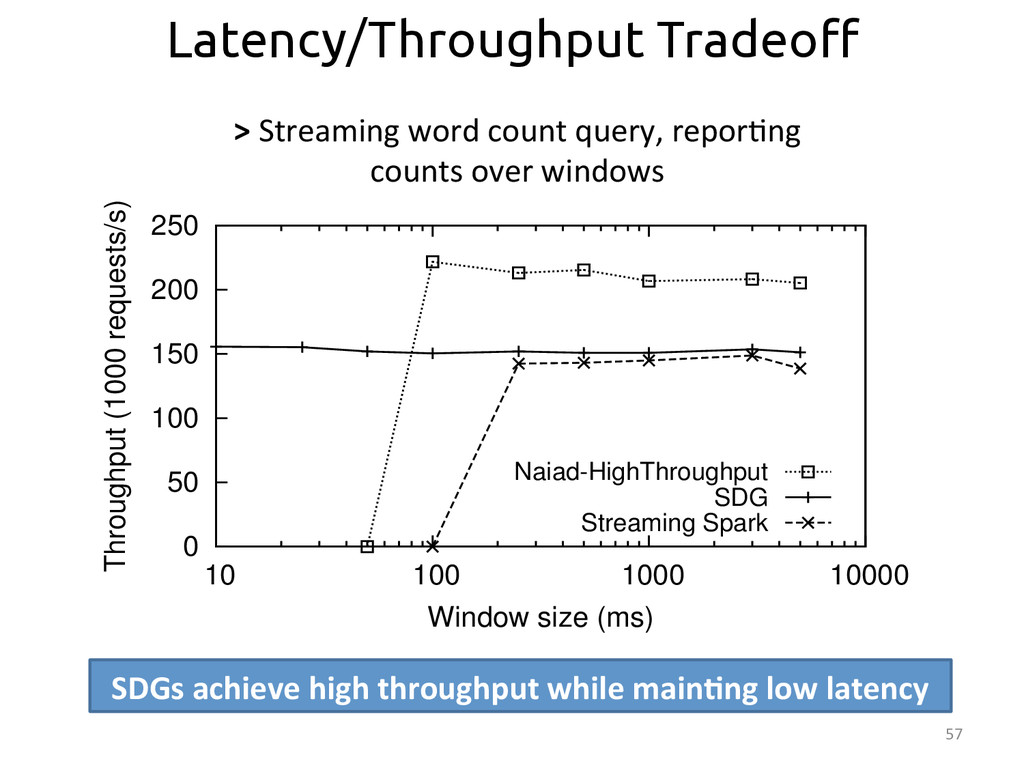{kind=link}
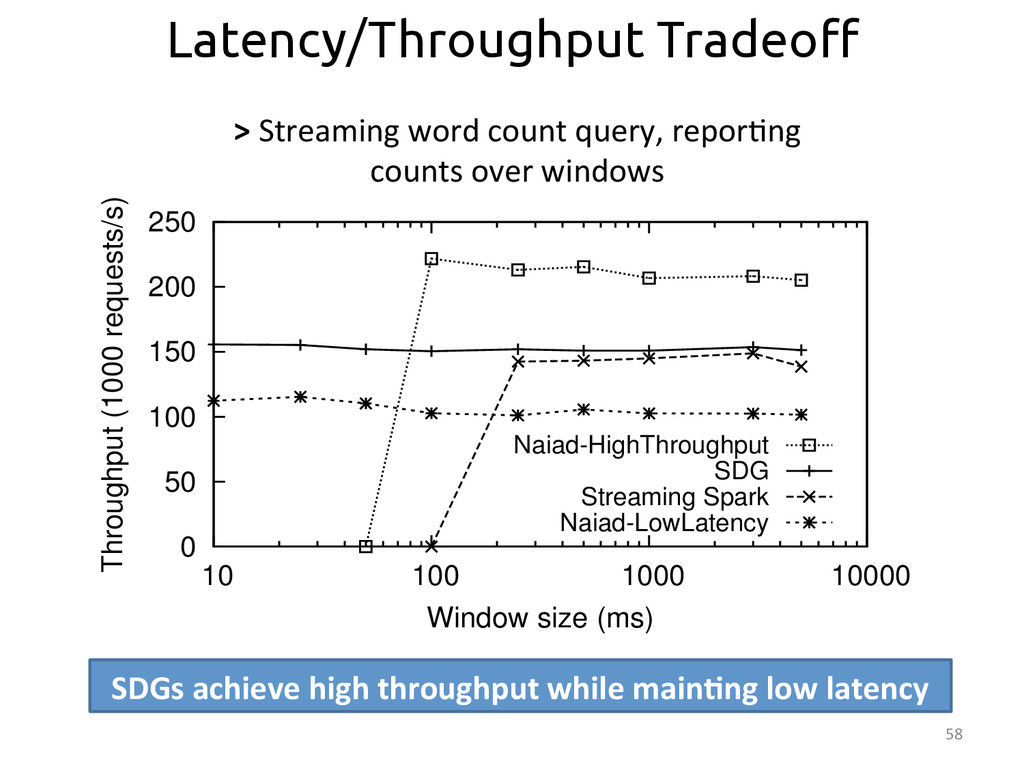{kind=link}
{kind=link}
{kind=link}
{kind=link}
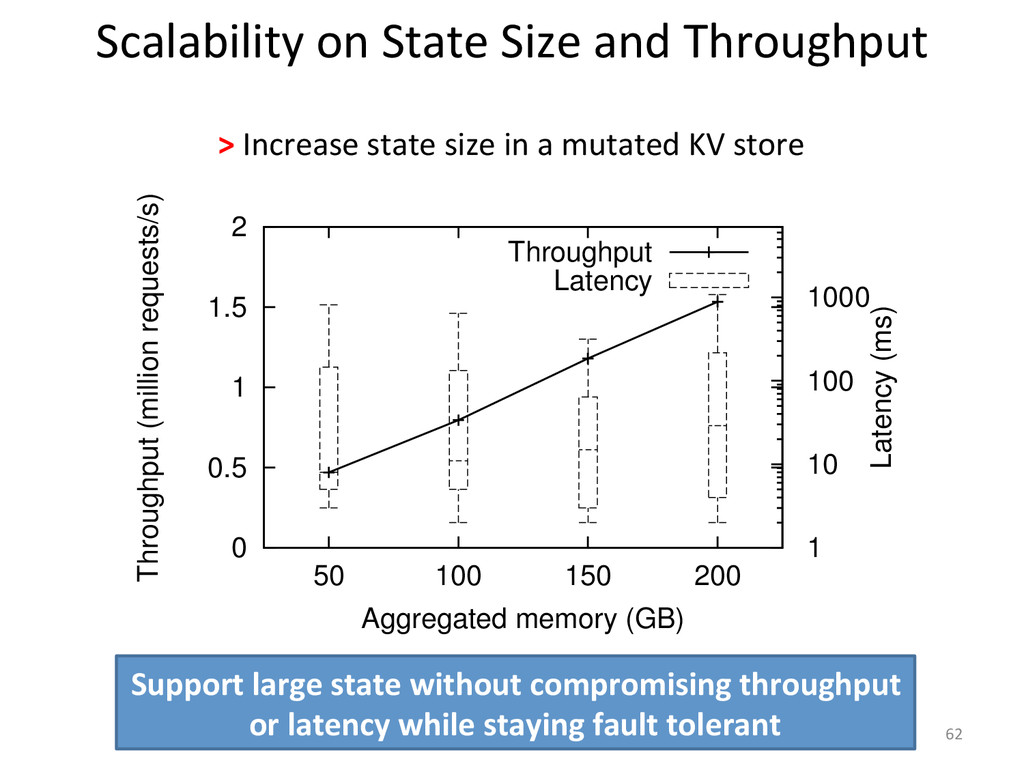{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
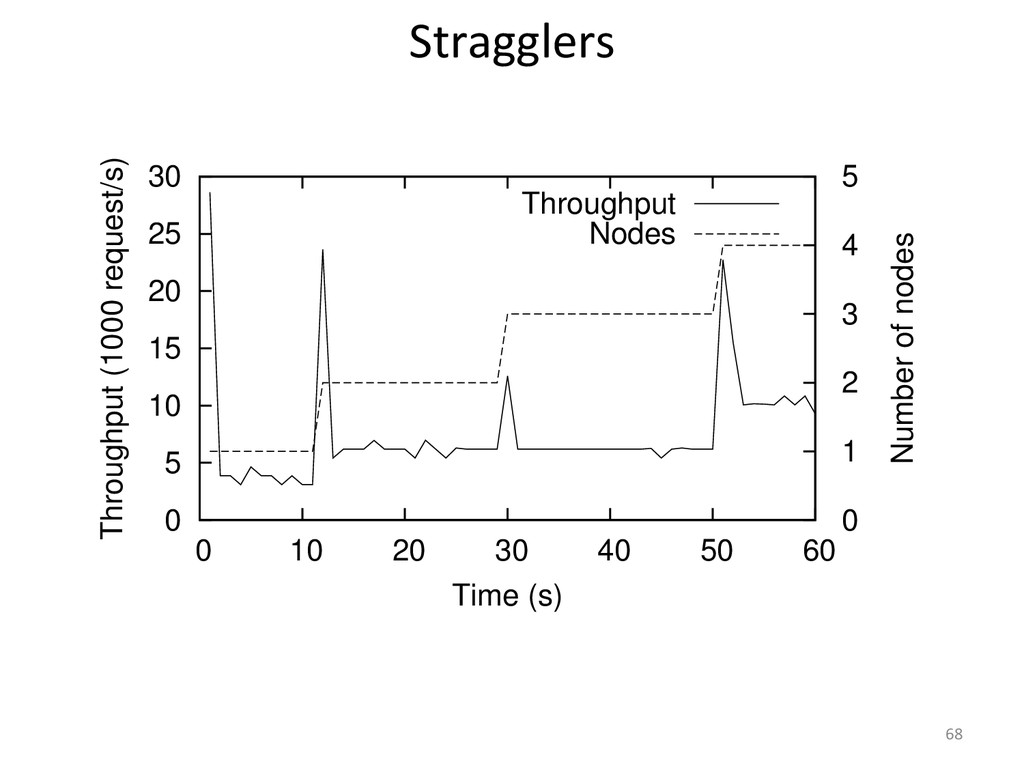{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}