Integrating C* and Spark gives us a system that combines the best of both worlds. The goal of this integration is to obtain a better result than using Spark over HDFS because Cassandra´s philosophy is much closer to RDD's philosophy than what HDFS is.
Session presented at Big Data Spain 2013 Conference
7th Nov 2013
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by: http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/2013/conference/an-efficient-data-mining-solution-by-integrating-spark-and-cassandra
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
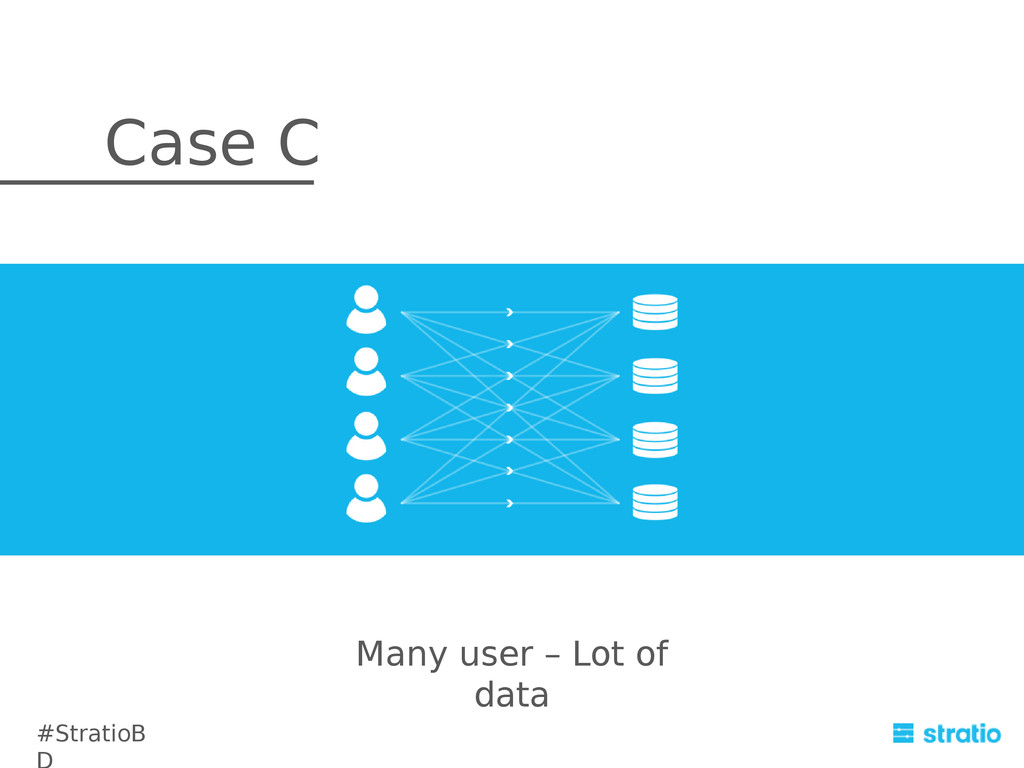{kind=link}
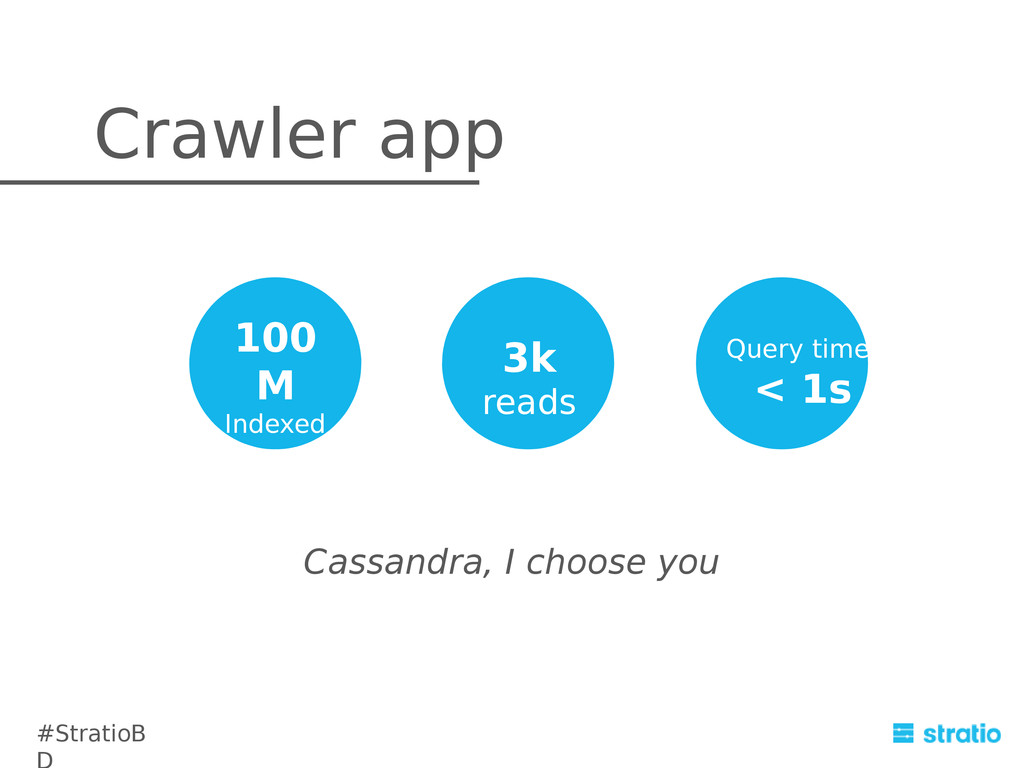{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
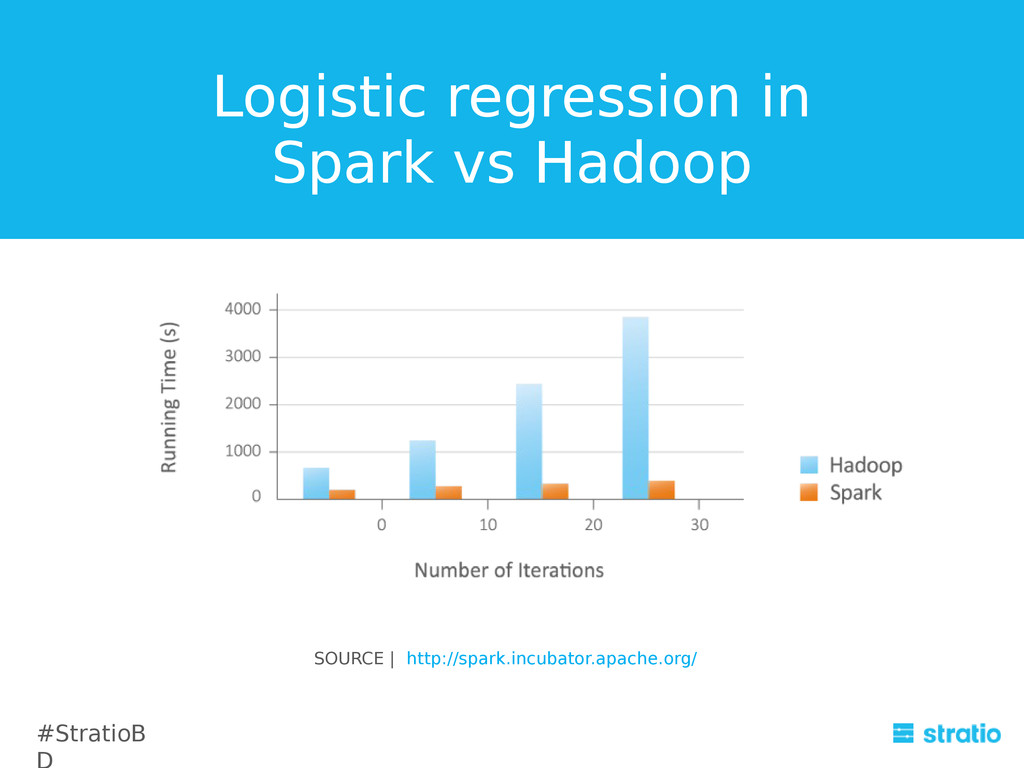{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
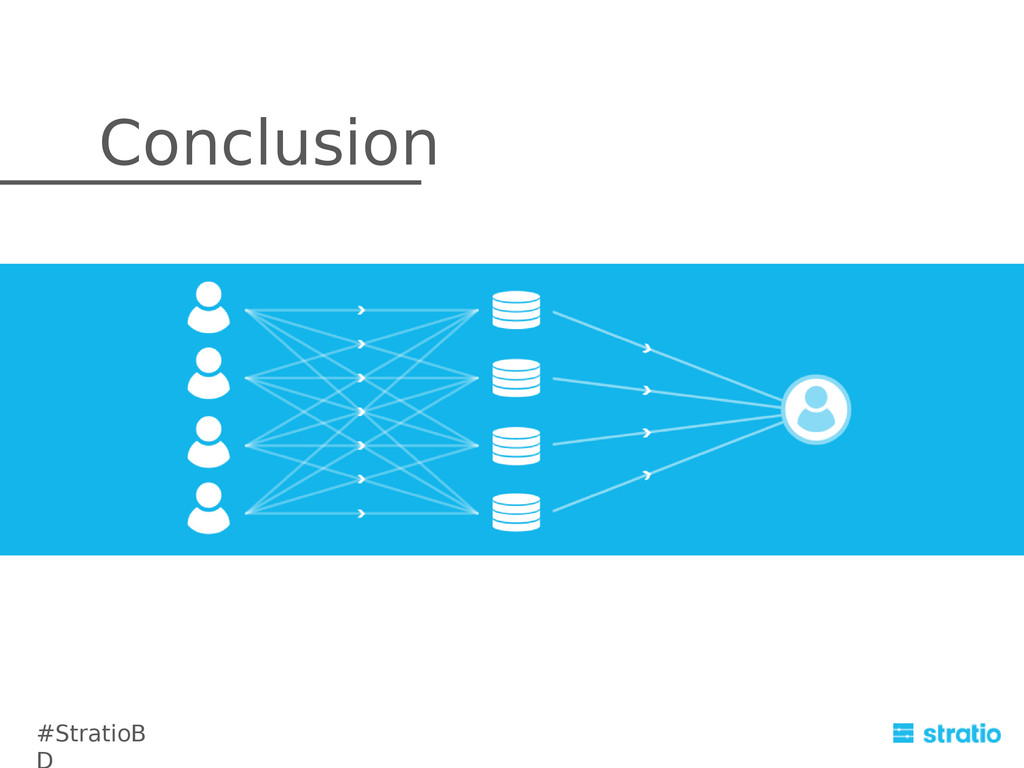{kind=link}
{kind=link}
{kind=link}