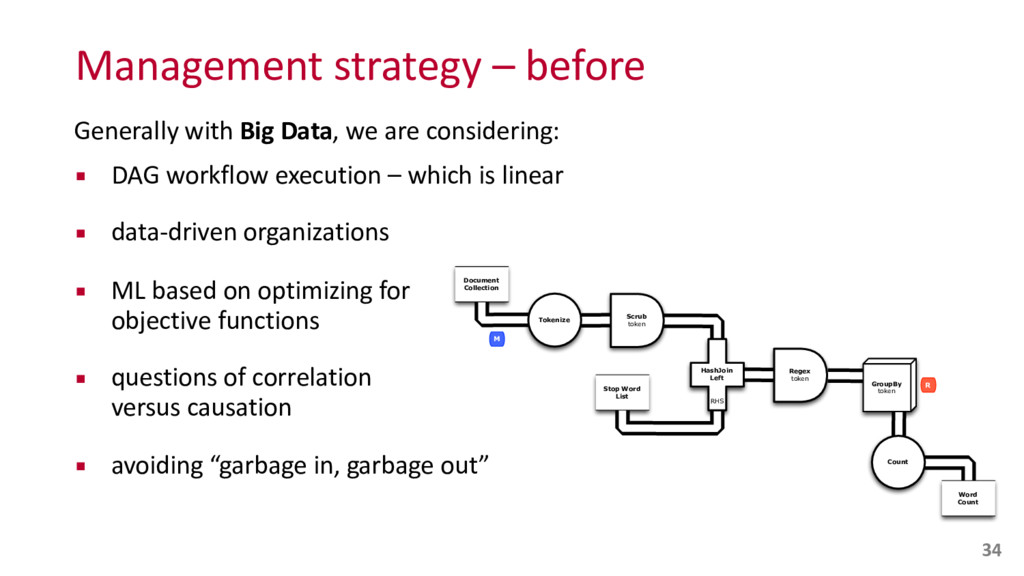
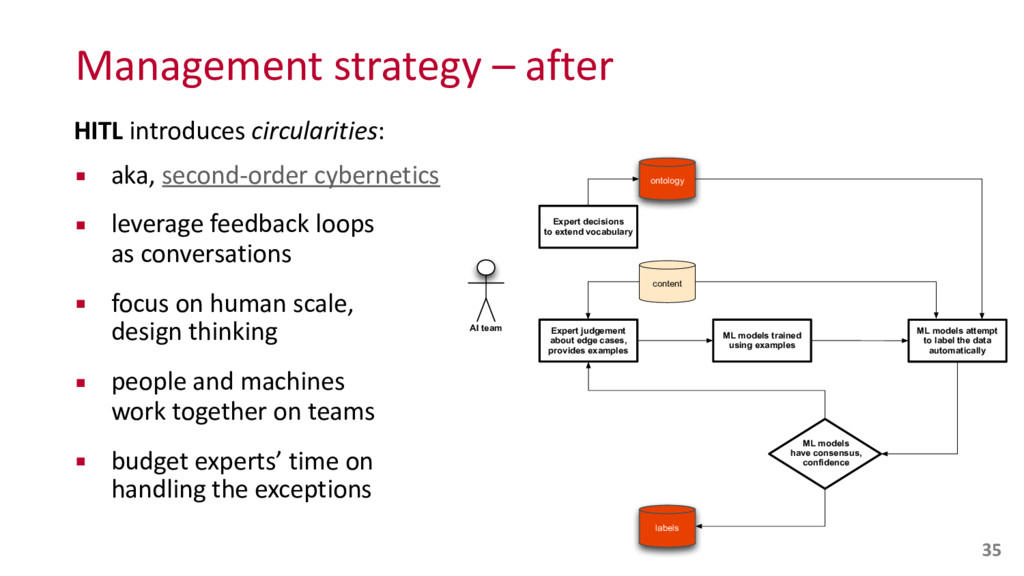
"PRP", 0, 49], "take", "take", "VB", 1, 50], [0, "a", "a", "DT", 0, 51], [23, "look", "l "NN", 1, 52], [0, "at", "at", "IN", 0, 53], [0, "a", "a", "DT", 0, 54], [ "few", "few", "JJ", 1, 55], [25, "examples", "example", "NNS", 1, 56], [0 "often", "often", "RB", 0, 57], [0, "when", "when", "WRB", 0, 58], [11, "people", "people", "NNS", 1, 59], [2, "are", "be", "VBP", 1, 60], [26, " "first", "JJ", 1, 61], [27, "learning", "learn", "VBG", 1, 62], [0, "abou "about", "IN", 0, 63], [28, "Docker", "docker", "NNP", 1, 64], [0, "they" "they", "PRP", 0, 65], [29, "try", "try", "VBP", 1, 66], [0, "and", "and" 0, 67], [30, "put", "put", "VBP", 1, 68], [0, "it", "it", "PRP", 0, 69], "in", "in", "IN", 0, 70], [0, "one", "one", "CD", 0, 71], [0, "of", "of", 0, 72], [0, "a", "a", "DT", 0, 73], [24, "few", "few", "JJ", 1, 74], [31, "existing", "existing", "JJ", 1, 75], [18, "categories", "category", "NNS 76], [0, "sometimes", "sometimes", "RB", 0, 77], [11, "people", "people", 1, 78], [9, "think", "think", "VBP", 1, 79], [0, "it", "it", "PRP", 0, 80 "'s", "be", "VBZ", 1, 81], [0, "a", "a", "DT", 0, 82], [32, "virtualizati "virtualization", "NN", 1, 83], [19, "tool", "tool", "NN", 1, 84], [0, "l "like", "IN", 0, 85], [33, "VMware", "vmware", "NNP", 1, 86], [0, "or", " "CC", 0, 87], [34, "virtualbox", "virtualbox", "NNP", 1, 88], [0, "also", "also", "RB", 0, 89], [35, "known", "know", "VBN", 1, 90], [0, "as", "as" 0, 91], [0, "a", "a", "DT", 0, 92], [36, "hypervisor", "hypervisor", "NN" 93], [0, "these", "these", "DT", 0, 94], [2, "are", "be", "VBP", 1, 95], "tools", "tool", "NNS", 1, 96], [0, "which", "which", "WDT", 0, 97], [2, "be", "VBP", 1, 98], [37, "emulating", "emulate", "VBG", 1, 99], [38, "hardware", "hardware", "NN", 1, 100], [0, "for", "for", "IN", 0, 101], [ "virtual", "virtual", "JJ", 1, 102], [40, "software", "software", "NN", 1 103]], "id": "001.video197359", "sha1": "4b69cf60f0497887e3776619b922514f2e5b70a8"} AI in Media 6 {"count": 2, "ids": [32, 19], "pos": "np", "rank": 0.0194, "text": "virtualization tool"} {"count": 2, "ids": [40, 69], "pos": "np", "rank": 0.0117, "text": "software applications"} {"count": 4, "ids": [38], "pos": "np", "rank": 0.0114, "text": "hardware"} {"count": 2, "ids": [33, 36], "pos": "np", "rank": 0.0099, "text": "vmware hypervisor"} {"count": 4, "ids": [28], "pos": "np", "rank": 0.0096, "text": "docker"} {"count": 4, "ids": [34], "pos": "np", "rank": 0.0094, "text": "virtualbox"} {"count": 10, "ids": [11], "pos": "np", "rank": 0.0049, "text": "people"} {"count": 4, "ids": [37], "pos": "vbg", "rank": 0.0026, "text": "emulating"} {"count": 2, "ids": [27], "pos": "vbg", "rank": 0.0016, "text": "learning"} Transcript: let's take a look at a few examples often when people are first learning about Docker they try and put it in one of a few existing categories sometimes people think it's a virtualization tool like VMware or virtualbox also known as a hypervisor these are tools which are emulating hardware for virtual software Confidence: 0.973419129848 39 KUBERNETES 0.8747 coreos 0.8624 etcd 0.8478 DOCKER CONTAINERS 0.8458 mesos 0.8406 DOCKER 0.8354 DOCKER CONTAINER 0.8260 KUBERNETES CLUSTER 0.8258 docker image 0.8252 EC2 0.8210 docker hub 0.8138 OPENSTACK orm:Docker a orm:Vendor; a orm:Container; a orm:Open_Source; a orm:Commercial_Software; owl:sameAs dbr:Docker_%28software%29; skos:prefLabel "Docker"@en;
{kind=link}
{kind=link}
{kind=link}
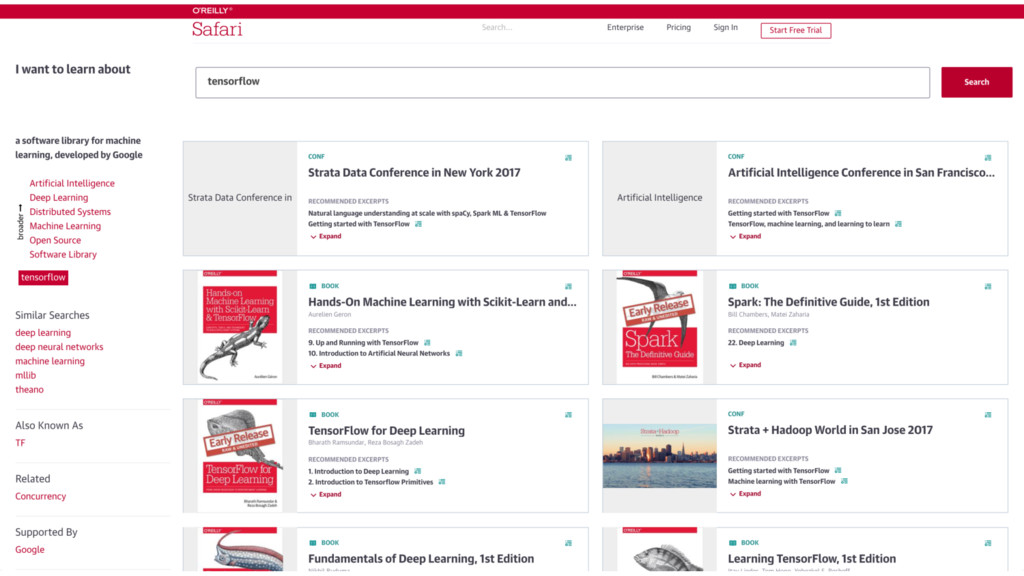{kind=link}
{kind=link}
{kind=link}
![{"graf": [[21, "let", "let", "VB", 1, 48], [0, "'s", "'s",](https://files.speakerdeck.com/presentations/88fea2b1b7f14625a5f32726ee1a7bff/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
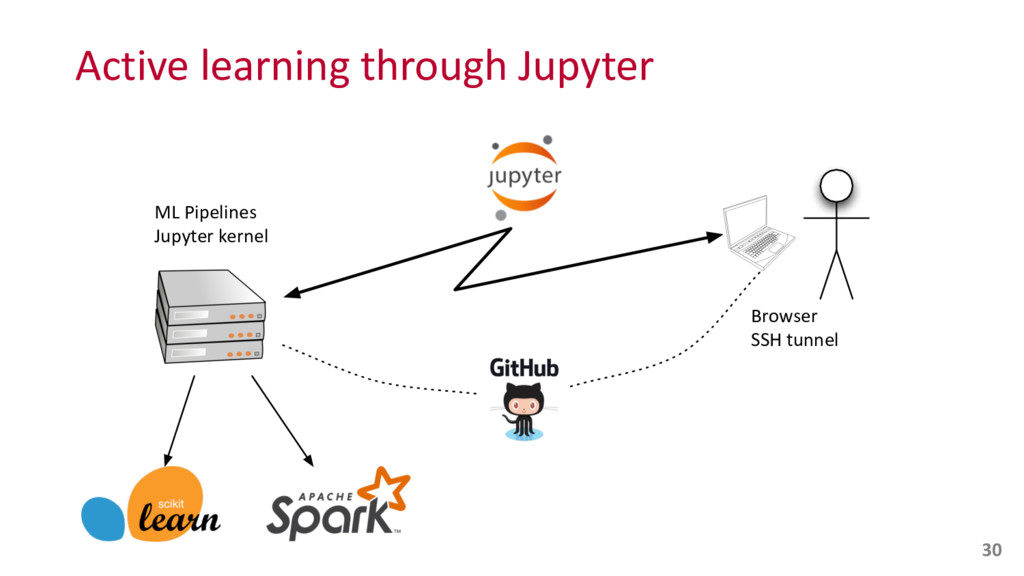{kind=link}
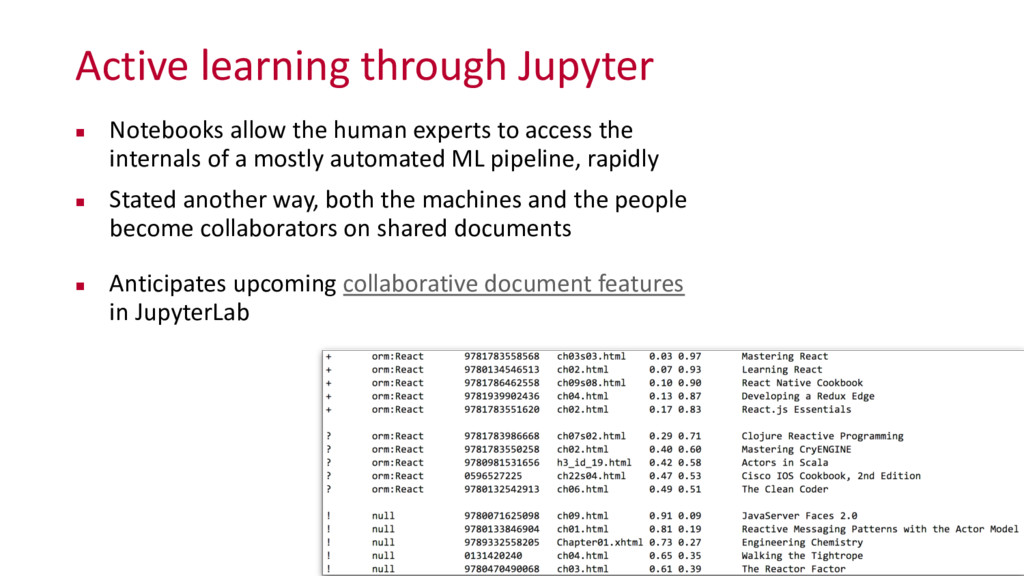{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}