Banks are innovating. The purpose of this innovation is to transform bank services into meaningful and frictionless customer experiences. A key element in order to achieve that ambitious goal is by providing well tailored and reactive APIs and provide them as the building blocks for greater and smoother customer journeys and experiences. For these API’s to work, internal processes have to evolve as well from batch processing to real time event processing.
Session presented at Big Data Spain 2015 Conference
16th Oct 2015
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by: http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/program/fri/slot-35.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
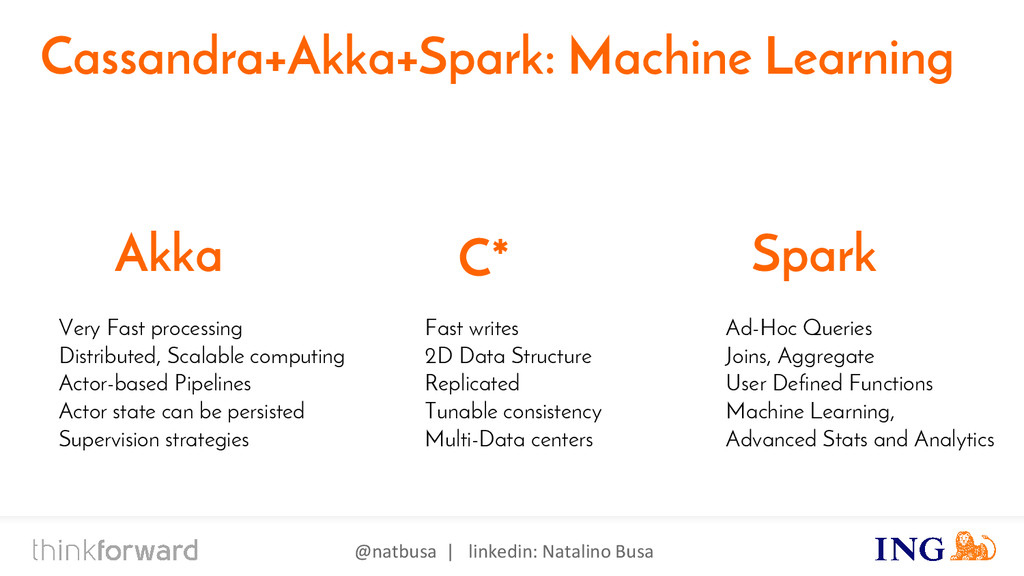{kind=link}
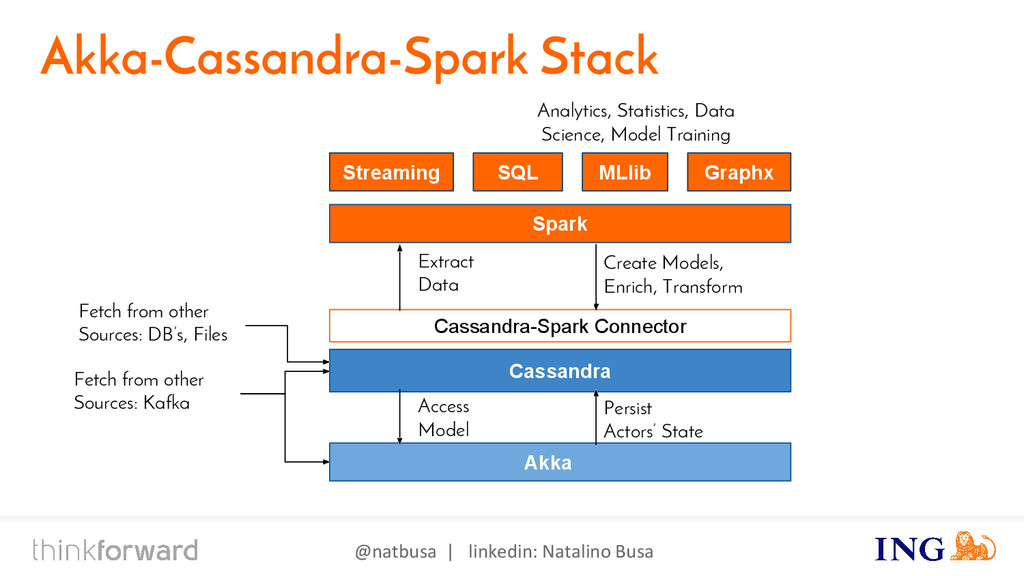{kind=link}
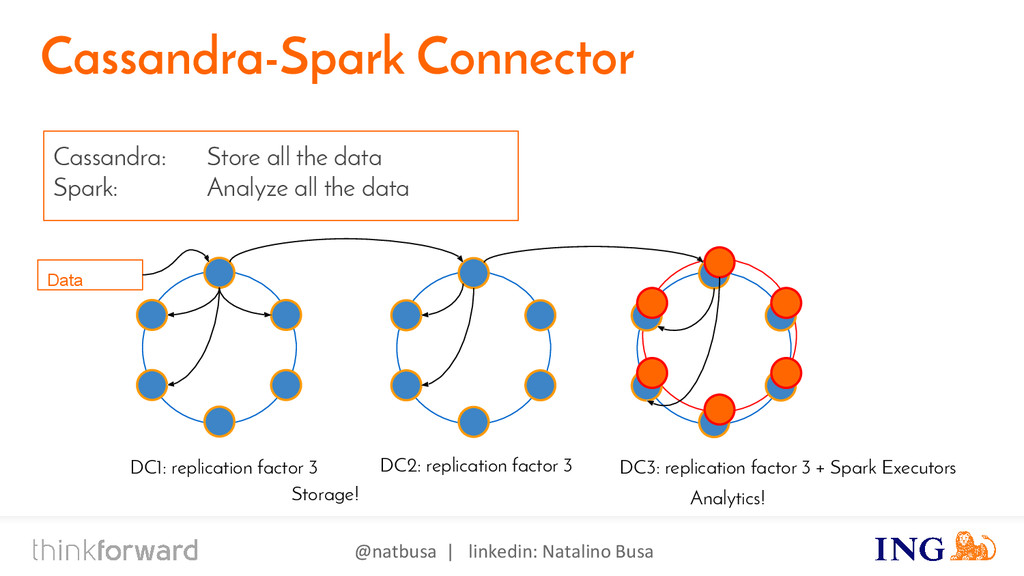{kind=link}
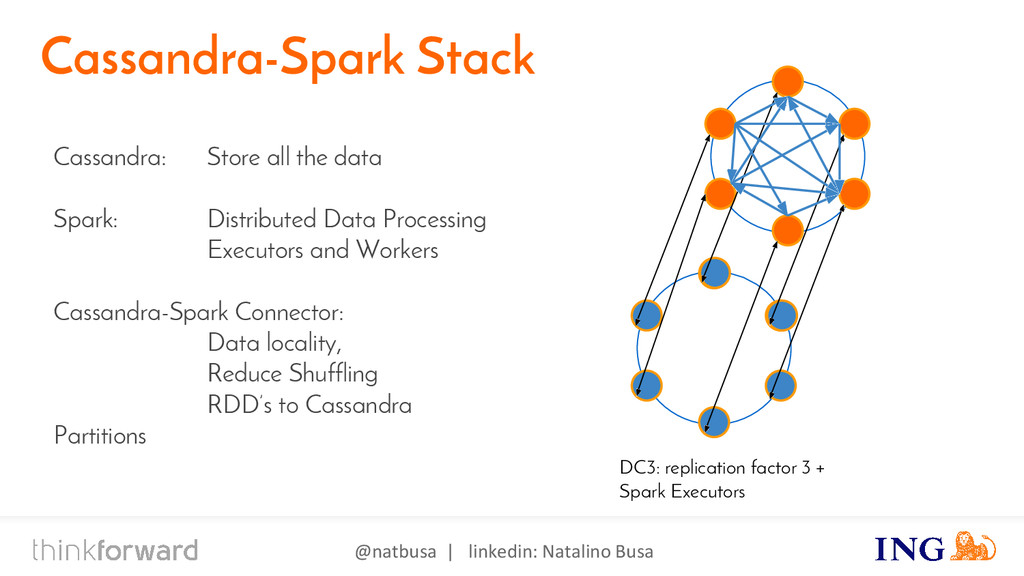{kind=link}
{kind=link}
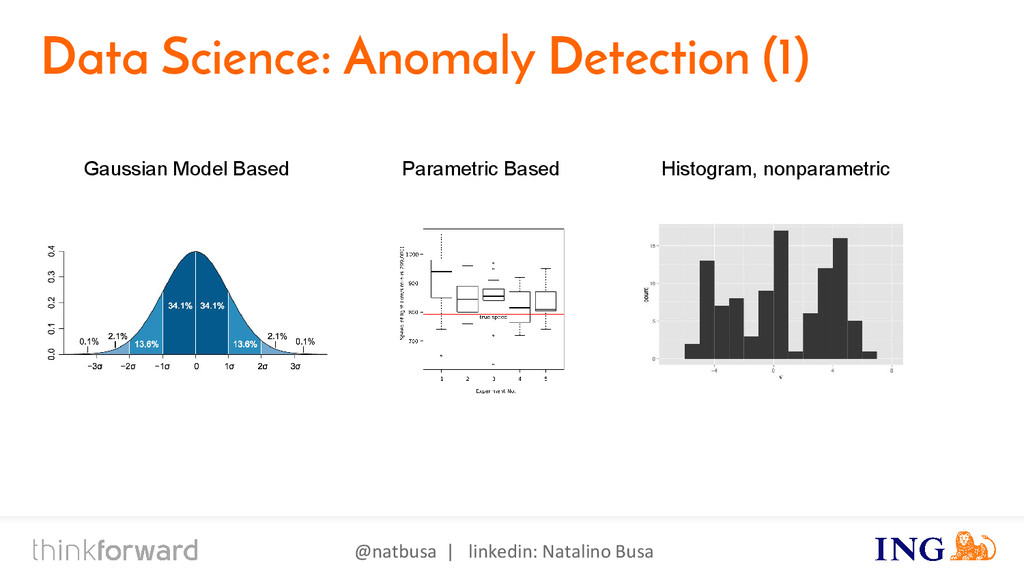{kind=link}
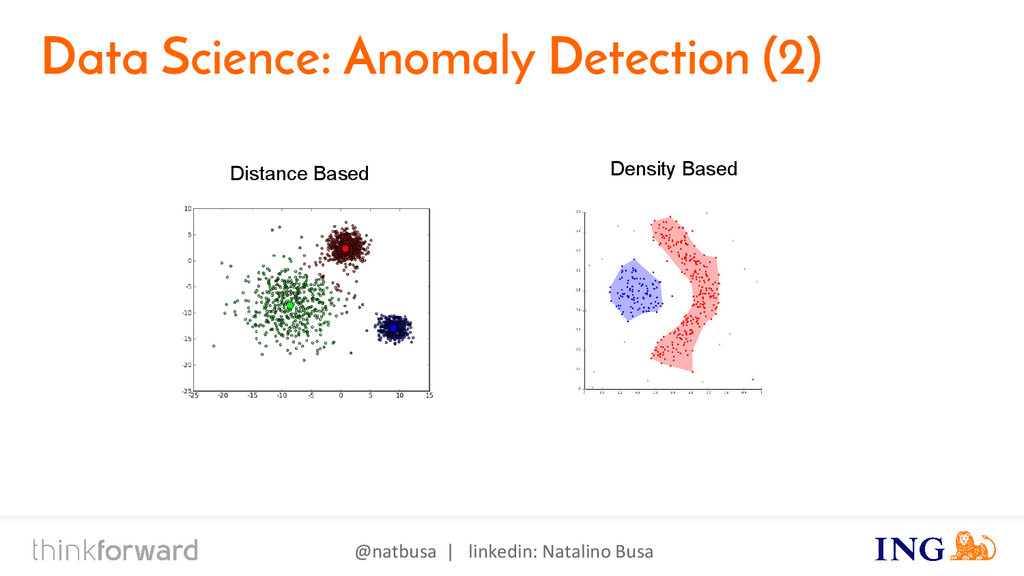{kind=link}
{kind=link}
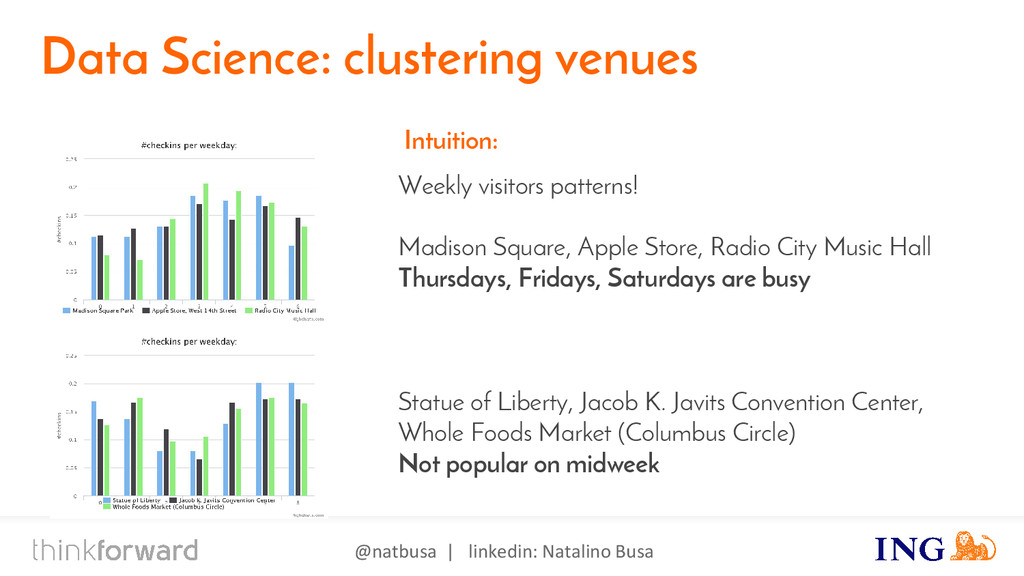{kind=link}
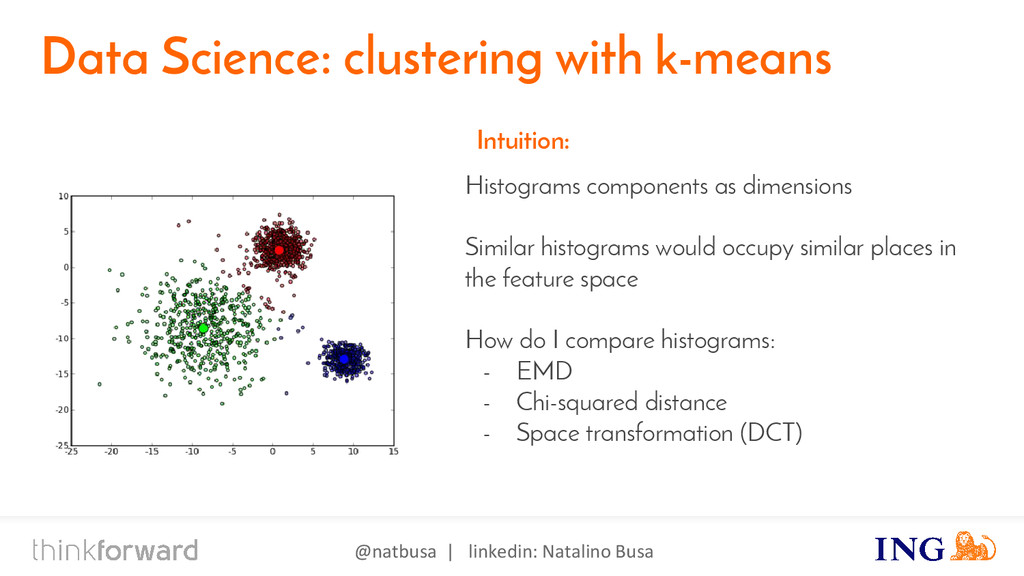{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
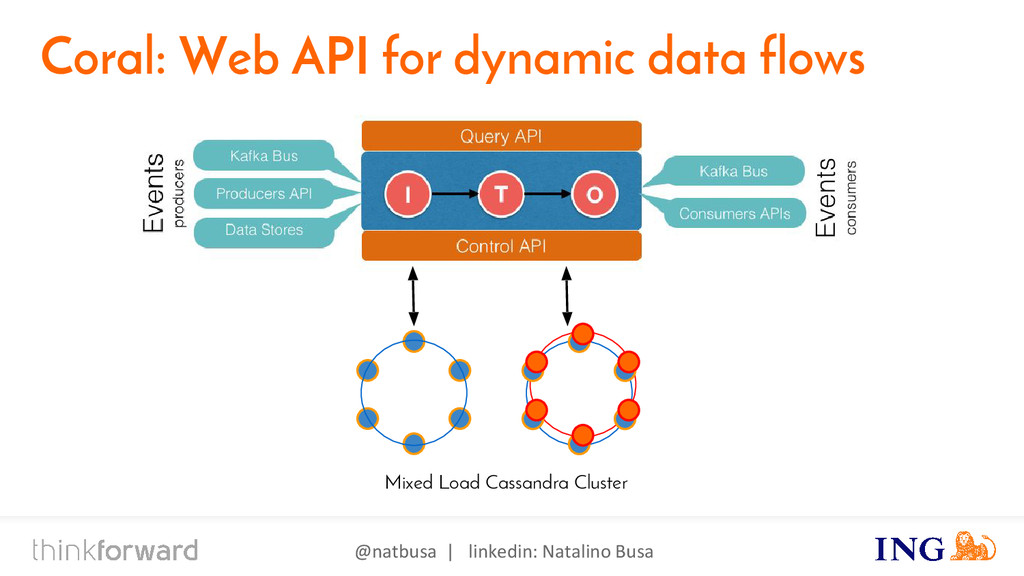{kind=link}
{kind=link}
{kind=link}
{kind=link}
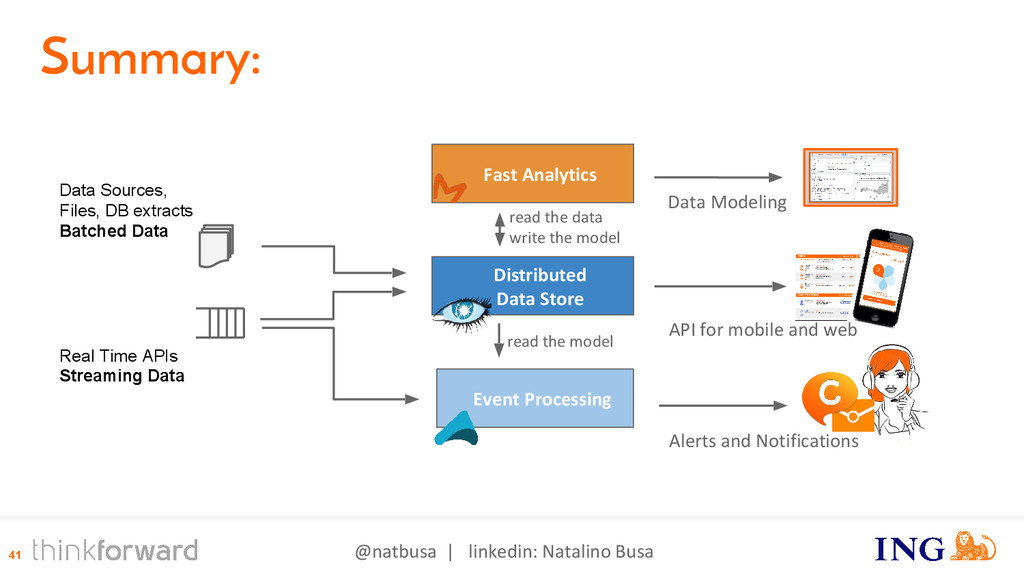{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}