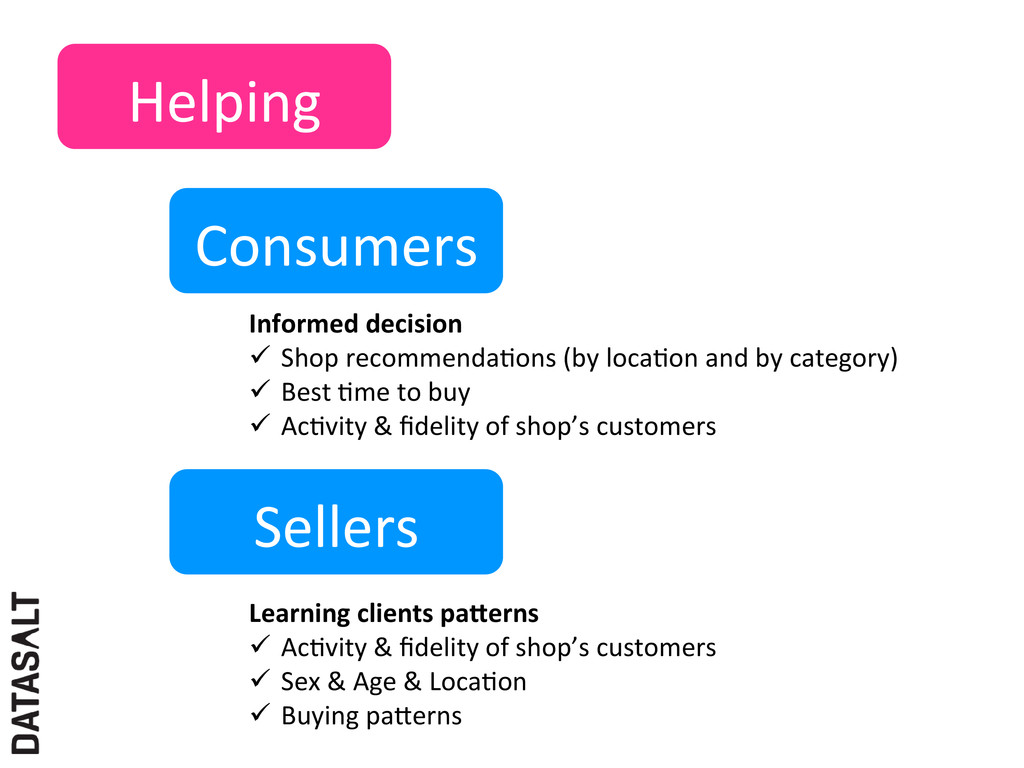
Shop recommendaNons (by locaNon and by category) ü Best Nme to buy ü AcNvity & fidelity of shop’s customers Learning clients paCerns ü AcNvity & fidelity of shop’s customers ü Sex & Age & LocaNon ü Buying paXerns
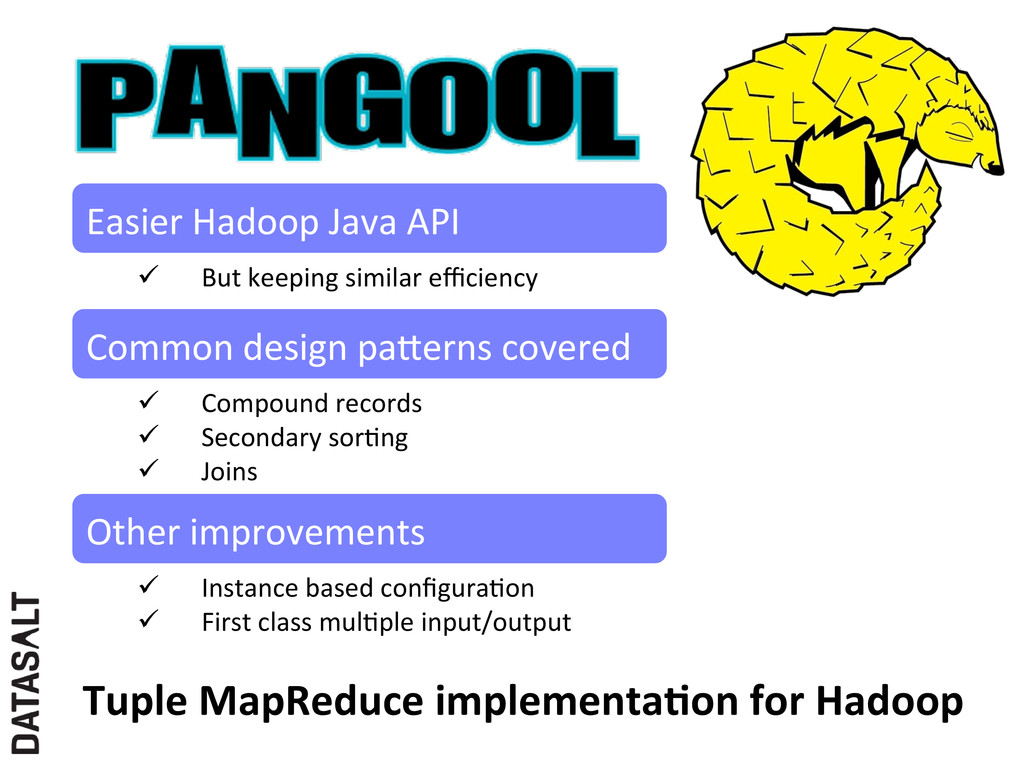
Common design paXerns covered ü Compound records ü Secondary sorNng ü Joins Other improvements ü Instance based configuraNon ü First class mulNple input/output Tuple MapReduce implementaJon for Hadoop
Jose Luis Fernandez-‐ Marquez, Giovanna Di Marzo Serugendo: Tuple MapReduce: Beyond classic MapReduce. In ICDM 2012: Proceedings of the IEEE Interna2onal Conference on Data Mining Brussels, Belgium | December 10 – 13, 2012 Our evoluJon to Google’s MapReduce
must be a subset of sort by clause Indeed, Tuple MapReduce can be implemented on top of any MapReduce implementaJon • Pangool -‐> Tuple MapReduce over Hadoop
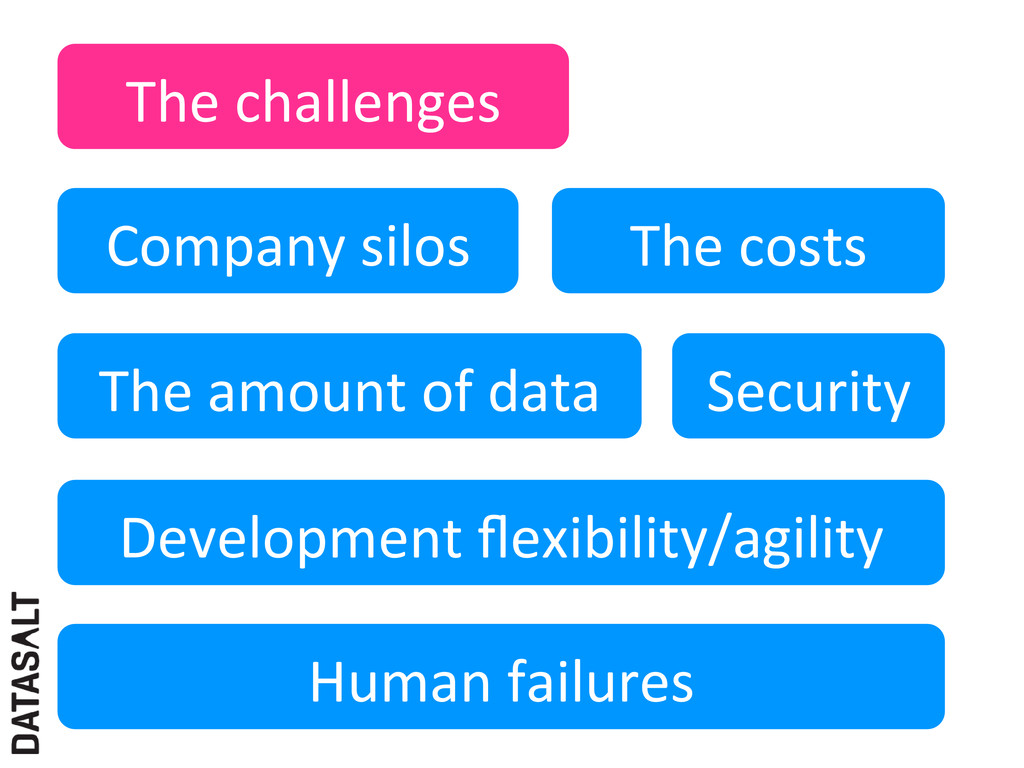
ü UpdaNng the database does not affect serving queries ü All data is replaced at each execuNon • Providing agility/flexibility § Big development changes are not a pain • Easier survival to human errors § Fix code and run again • Easy to set up new clusters with different topologies
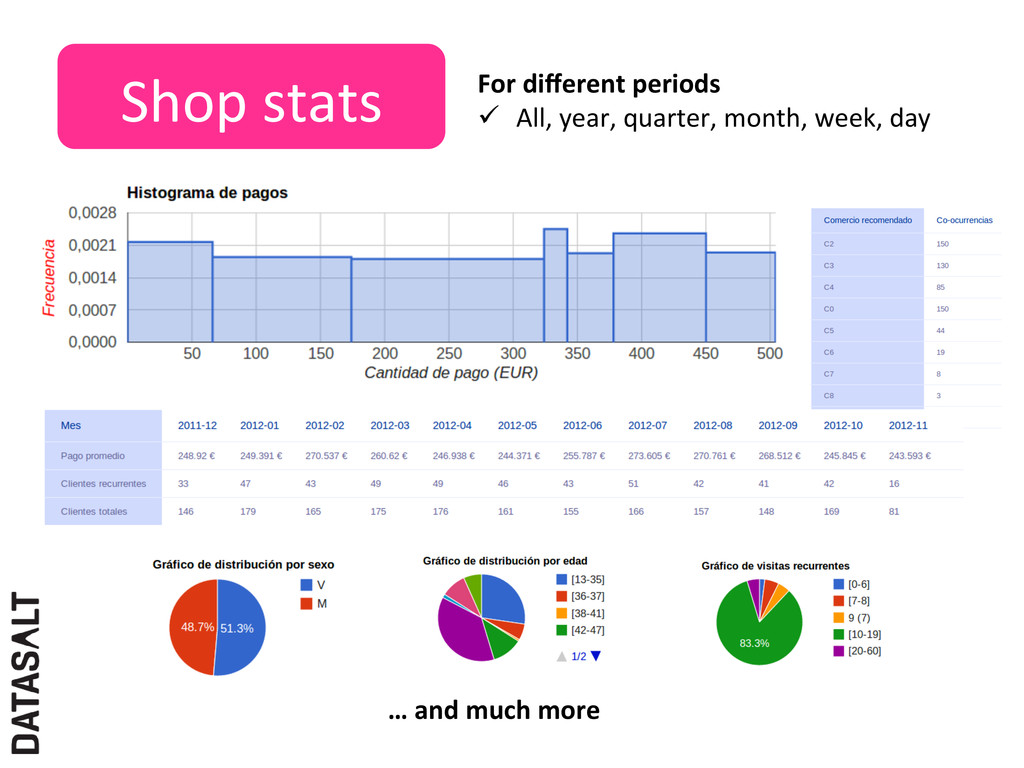
Stdev Easy to implement with Pangool/Hadoop ü One job, grouping by the dimension over which you want to calculate the staNsNcs. CompuJng several Jme periods in the same job ü Use the mapper for replicaNng each datum for each period ü Add a period idenNfier field in the tuple and include it in the group by clause
ü Using secondary sorNng by the field you want to disNnct count on ü DetecNng changes on that field Example Shop Card Shop 1 1234 Shop 1 1234 Shop 1 1234 Shop 1 5678 Shop 1 5678 Change +1 Change +1 2 disNnct buyers for shop 1 ü Group by shop, sort by shop and card
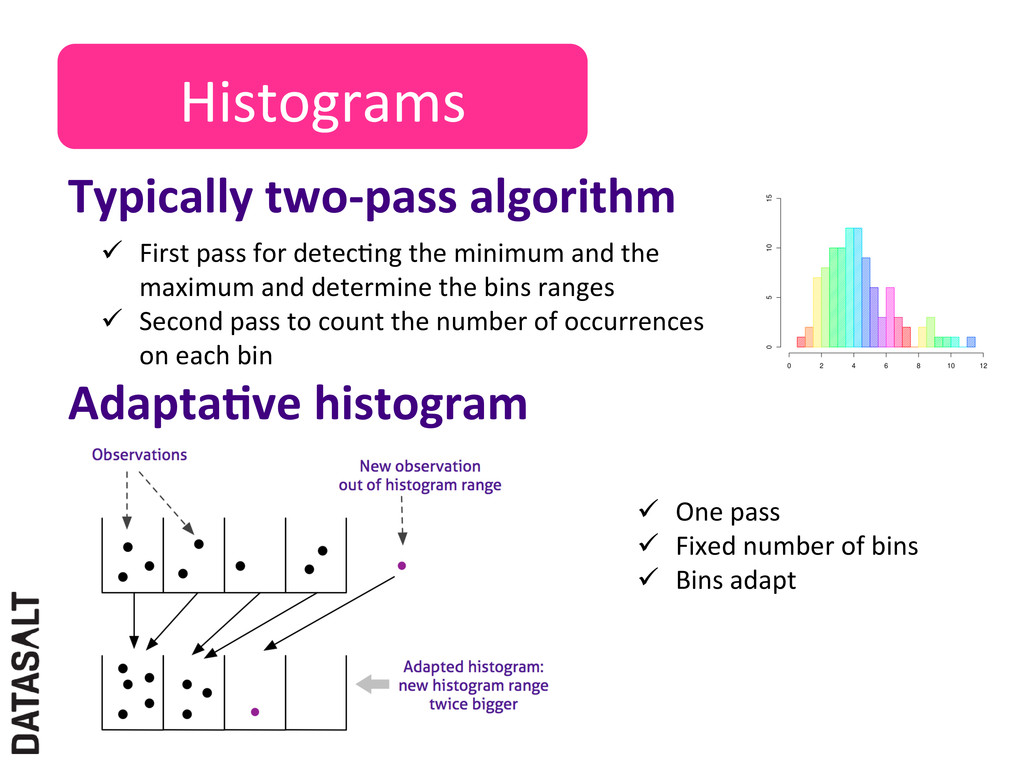
detecNng the minimum and the maximum and determine the bins ranges ü Second pass to count the number of occurrences on each bin AdaptaJve histogram ü One pass ü Fixed number of bins ü Bins adapt
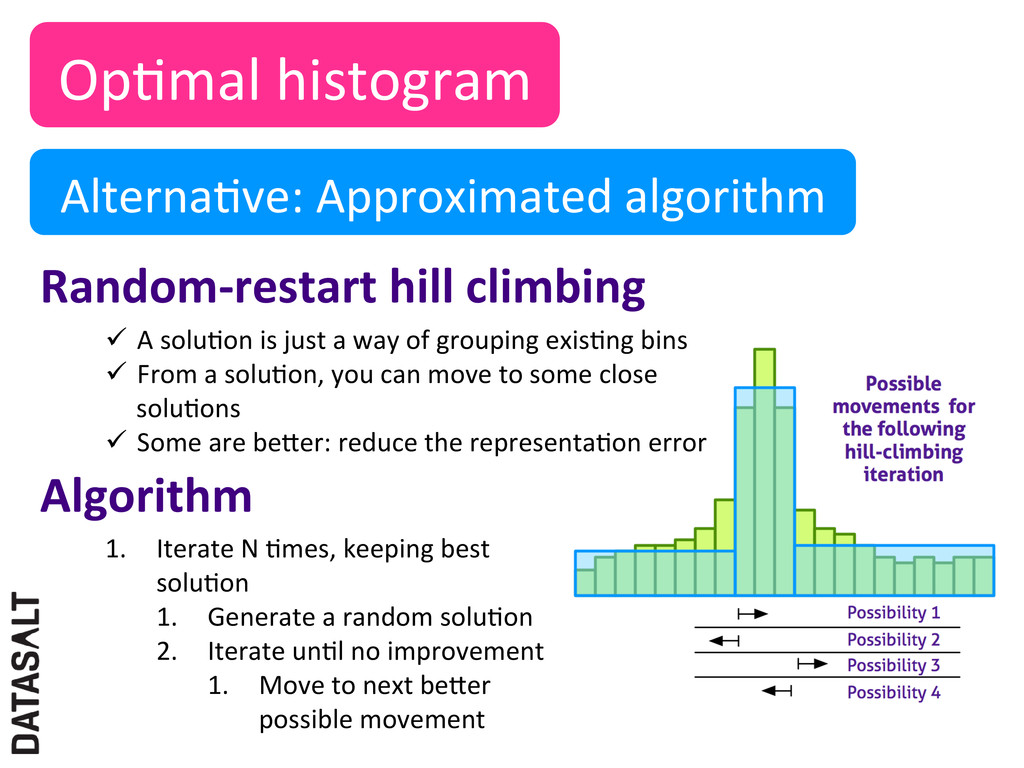
1. Iterate N Nmes, keeping best soluNon 1. Generate a random soluNon 2. Iterate unNl no improvement 1. Move to next beXer possible movement ü A soluNon is just a way of grouping exisNng bins ü From a soluNon, you can move to some close soluNons ü Some are beXer: reduce the representaNon error Algorithm
DisJnct count staJsJcs -‐> 1 job One pass histograms -‐> 1 job Several periods & shops -‐> 1 job We can put all together so that compuNng all staNsNcs for all shops fits into exactly one job
bought in shop A and in shop B, then a co-‐occurrence between A and B exists ü Only one co-‐occurrence is considered although a buyer bought several Nmes in A and B ü Top co-‐occurrences per each shop are the recommendaNons Improvements ü Most popular shops are filtered out because almost everybody buys in them. ü RecommendaNons by category, by locaJon and by both ü Different calculaNon periods
counNng and joining capabiliNes ü Several jobs Challenges ü If somebody bought in many shops, the list of co-‐occurrences can explode: • Co-‐occurrences = N * (N – 1), where N = # of disNnct shops where the person bought ü Alleviated by limiNng the total number of disNnct shops to consider ü Only uses the top M shops where the client bought the most Future ü Time aware co-‐occurrences. The client bought in A and B and he did it in a close period of Nme.
data 270 GB of stats to serve 24 large instances ~ 11 hours of execuNon $3500 month ü OpNmizaNons sNll possible ü Cost without the use of reserved instances ü Probably cheaper with an in-‐house Hadoop cluster
soluJon for a Bank ü With low use of resources ü Quickly ü Thanks to the use of technologies like Hadoop, Amazon Web Services and NoSQL databases The soluJon is ü Scalable ü Flexible/agile. Improvements easy to implement ü Prepared to stand human failures ü At a reasonable cost Main advantage: doing always everything
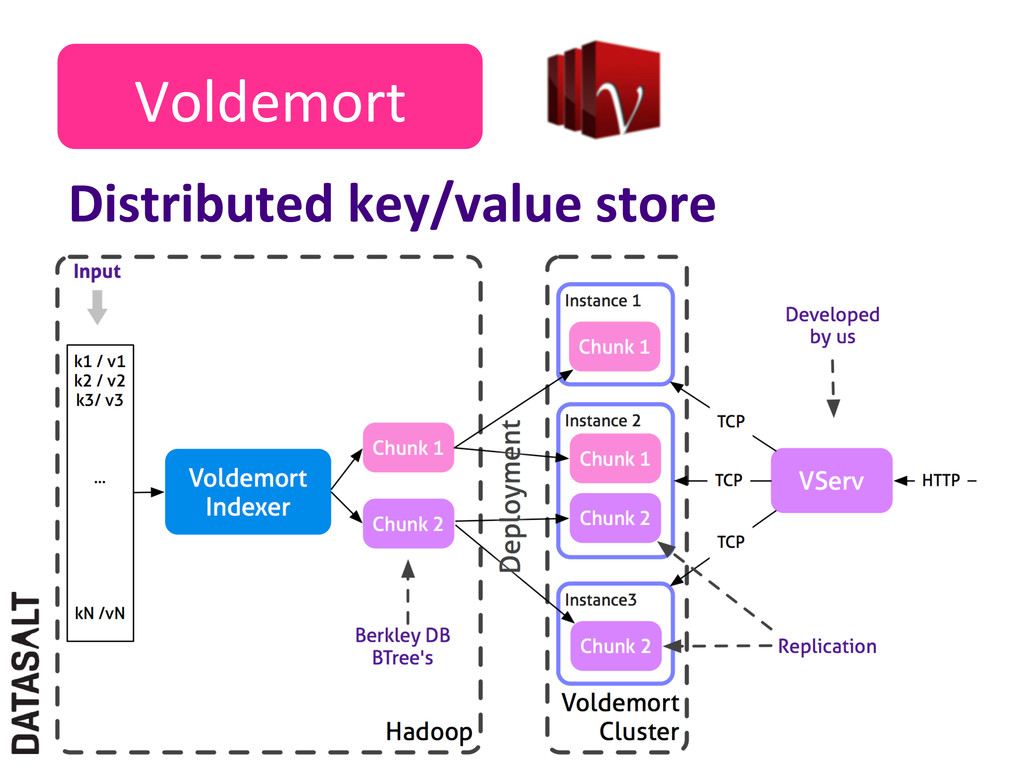
accept querying by the key ü AggregaNons no possible ü In other words, we are forced to pre-‐compute everything ü Not always possible -‐> data explode ü For this parNcular case, Nme ranges are fixed Splout: like Voldemort but SQL! ü The idea: to replace Voldemort by Splout SQL ü Much richer queries: real-‐Nme aggregaNons, flexible Nme ranges ü It would allow to create some kind of Google AnalyNcs for the staNsNcs discussed in this presentaNon ü Open Sourced!!! hXps://github.com/datasalt/splout-‐db
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
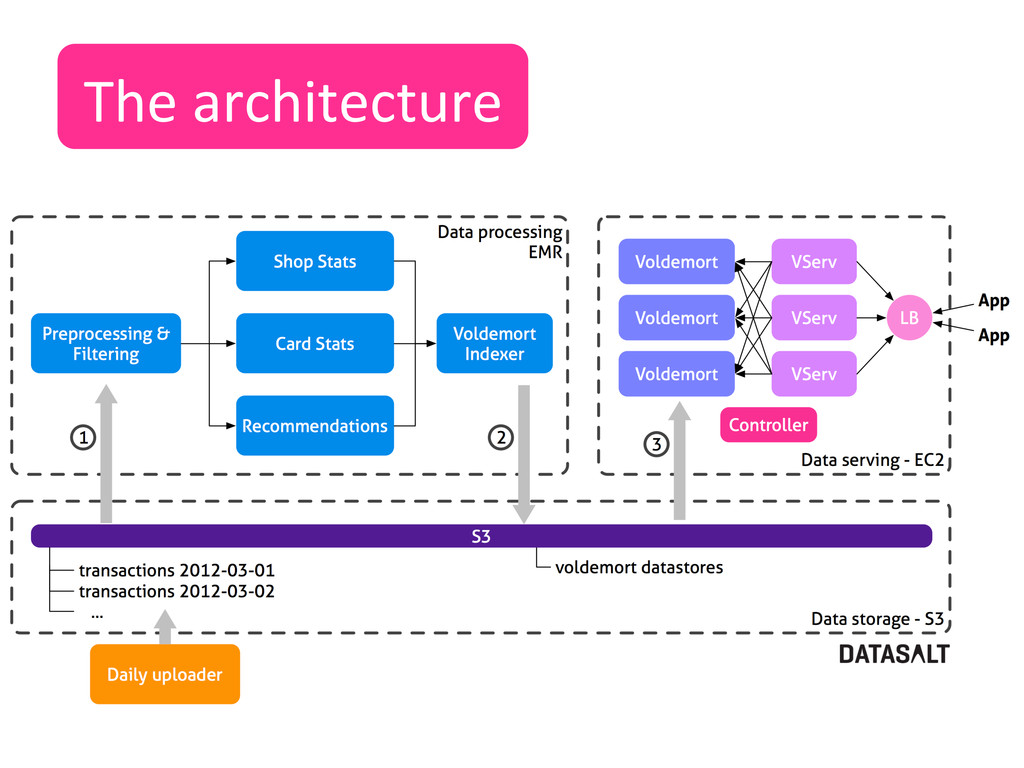
![The pla]orm S3 Data storage ElasNc Map](https://files.speakerdeck.com/presentations/a0b351901b68013014db1231380fad16/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}