My presentation at AWS Community Day Turkey 2024
Github repo with colab notebooks: https://github.com/bilgeyucel/presentations/tree/main/aws-community-day-2024
Recording: https://youtu.be/yfn1Wbe5Uuk?si=Tr8kZXBo9tsBehFE
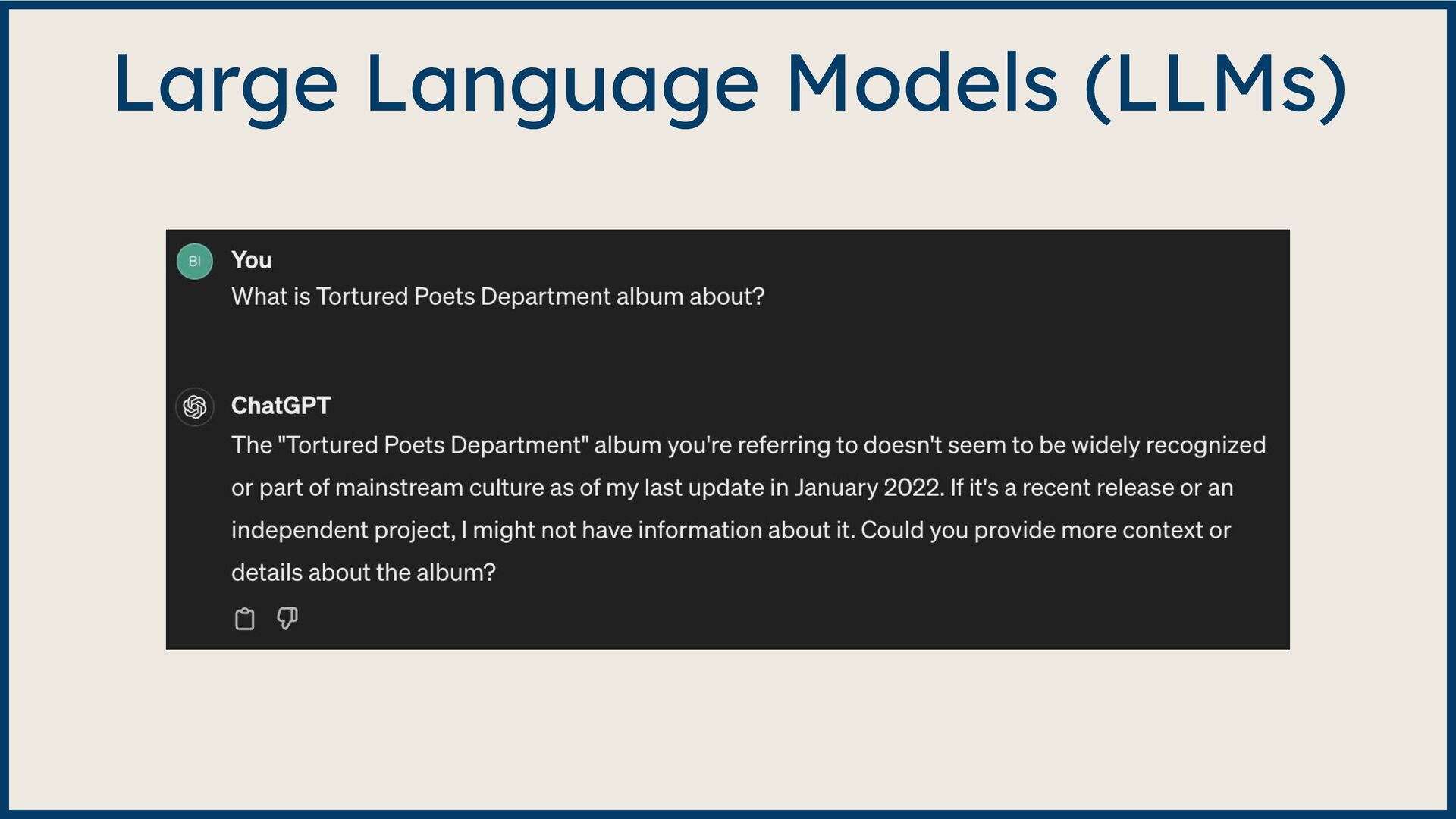
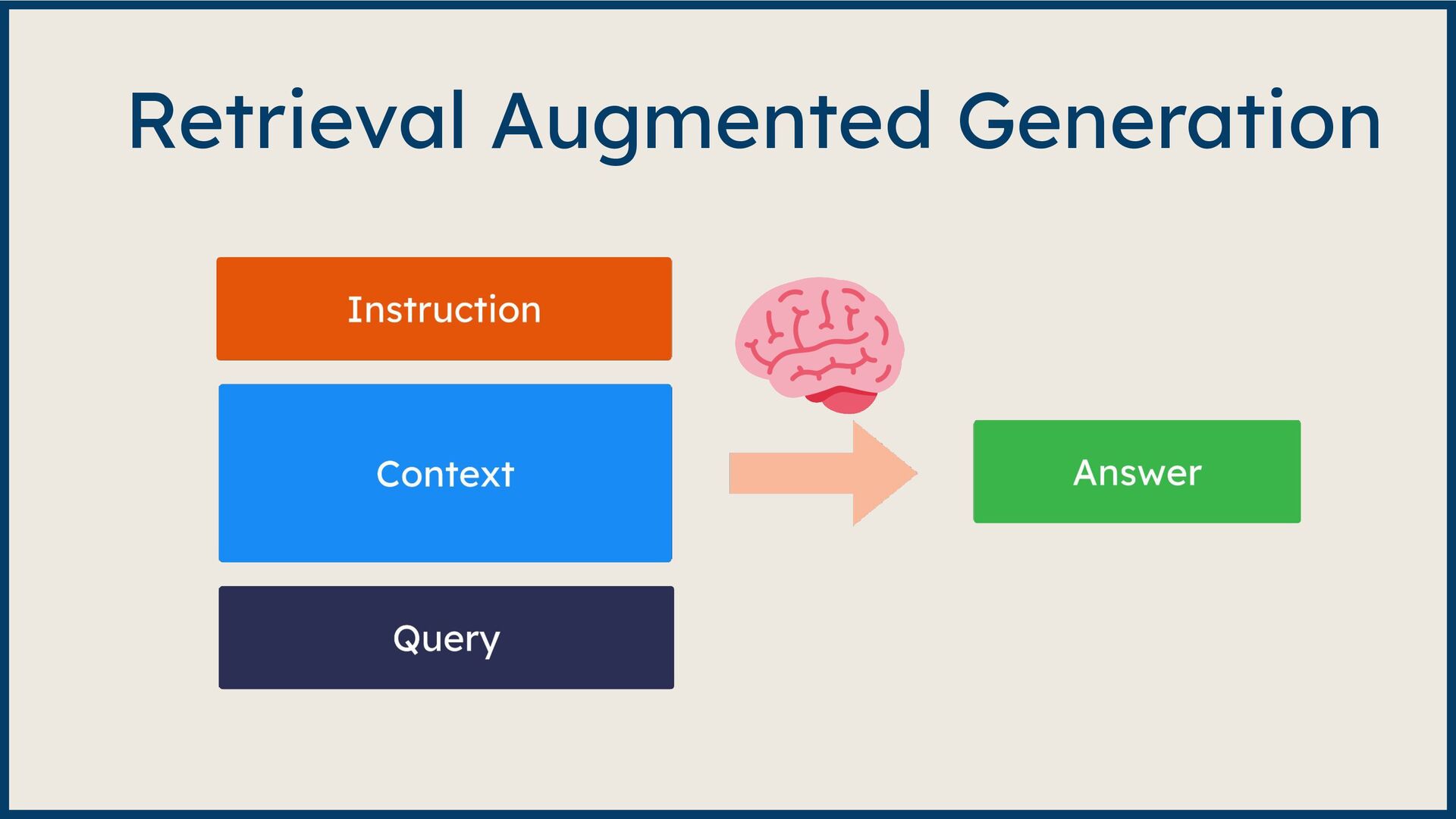
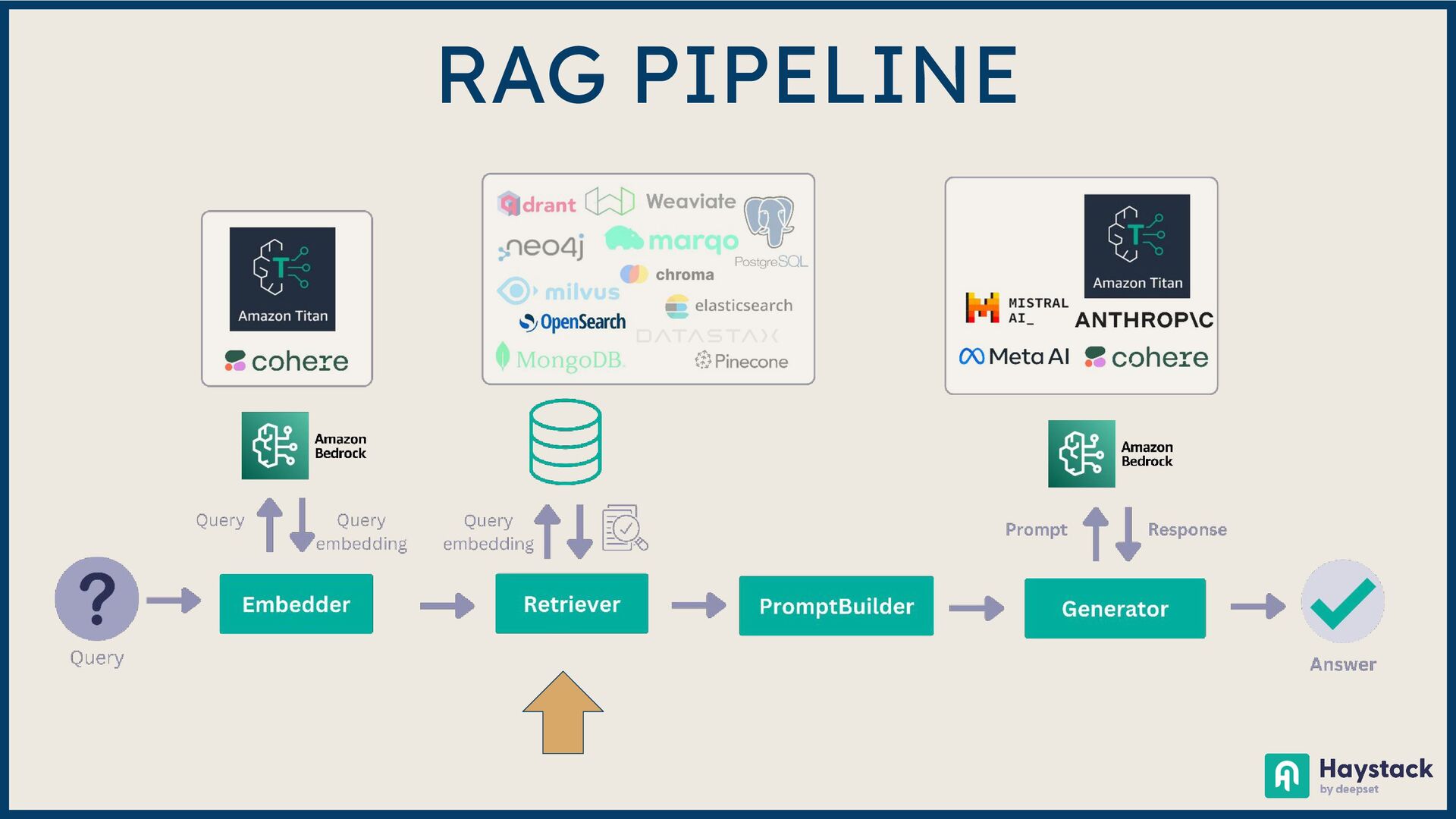
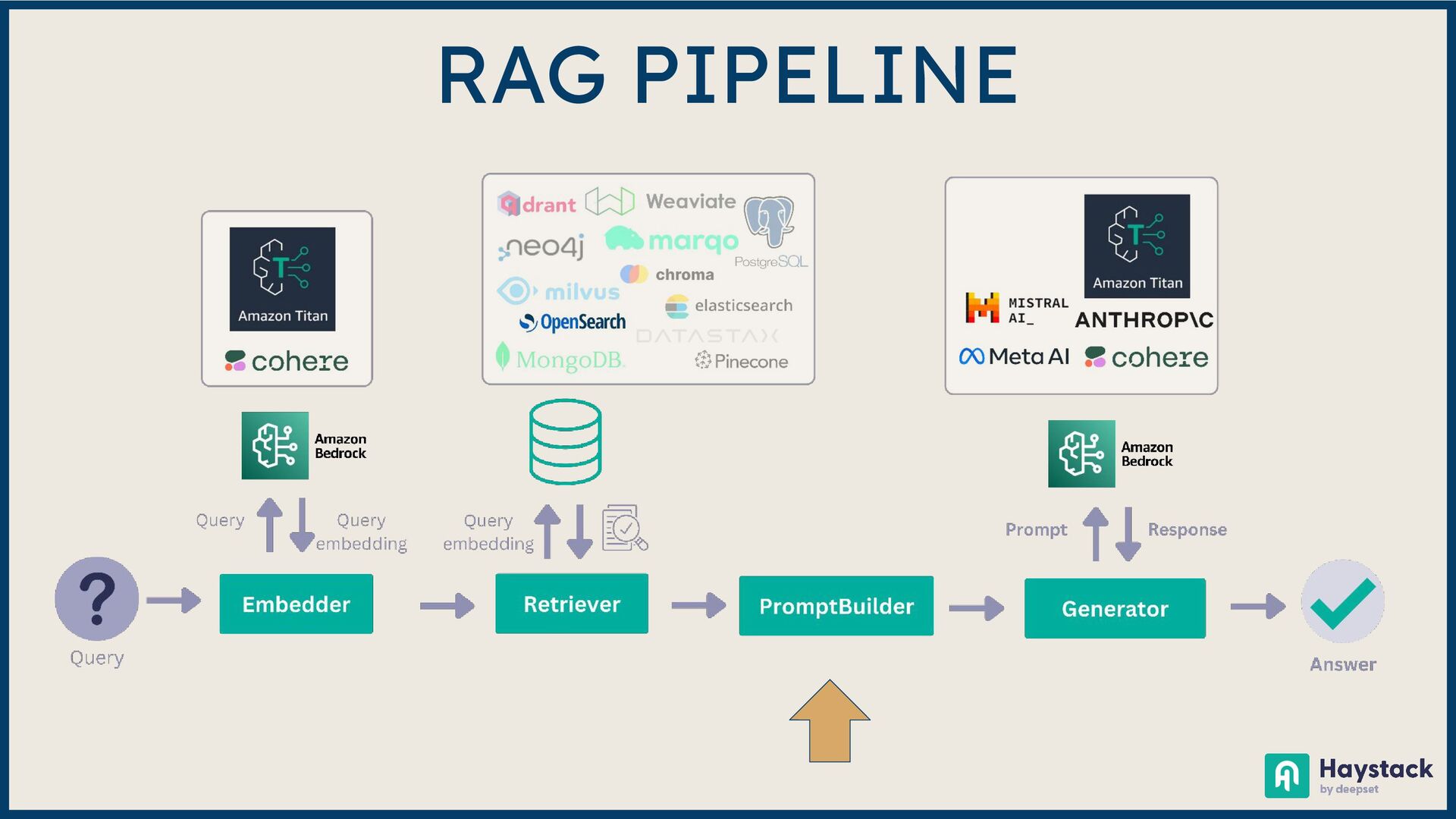
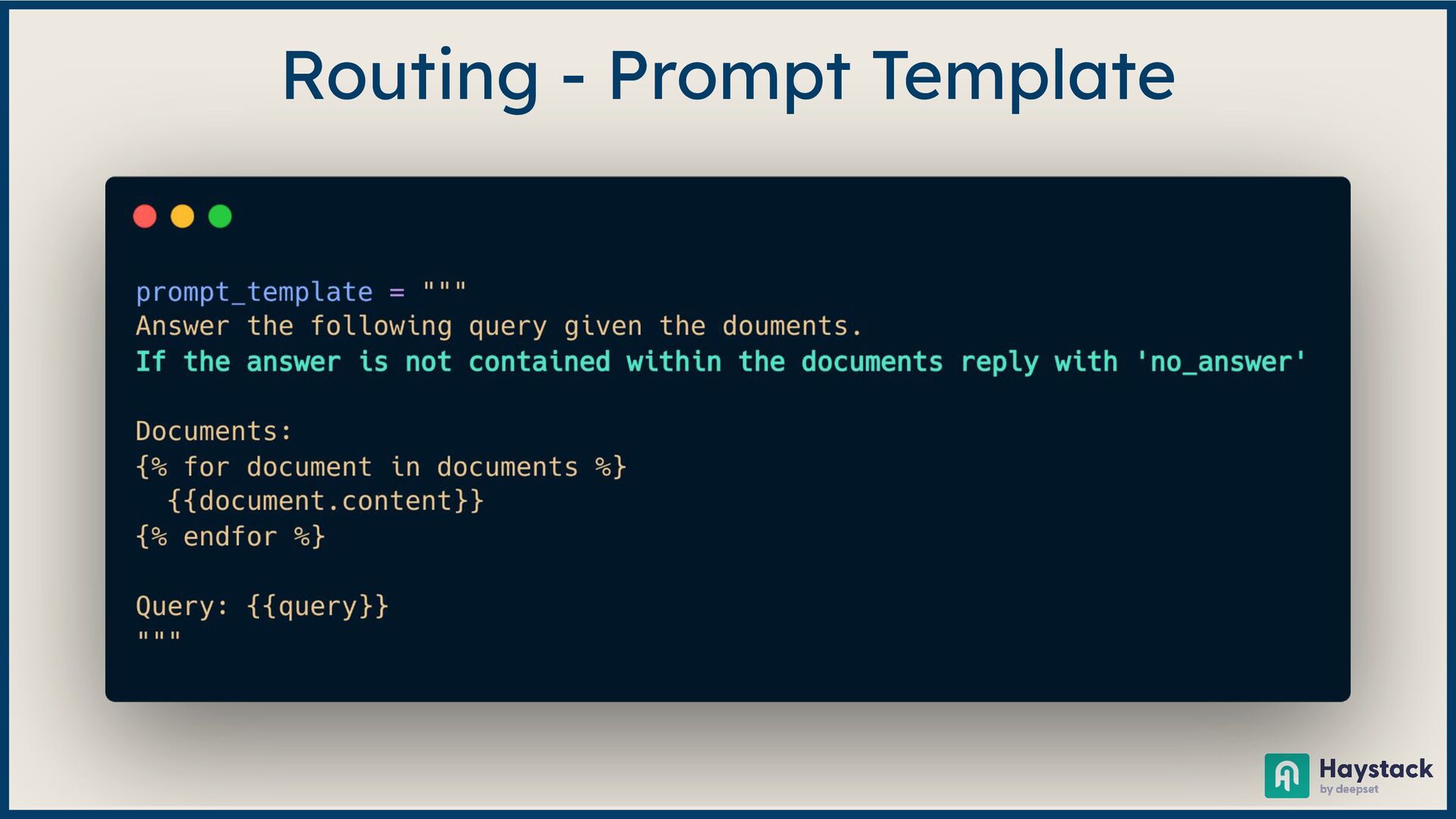
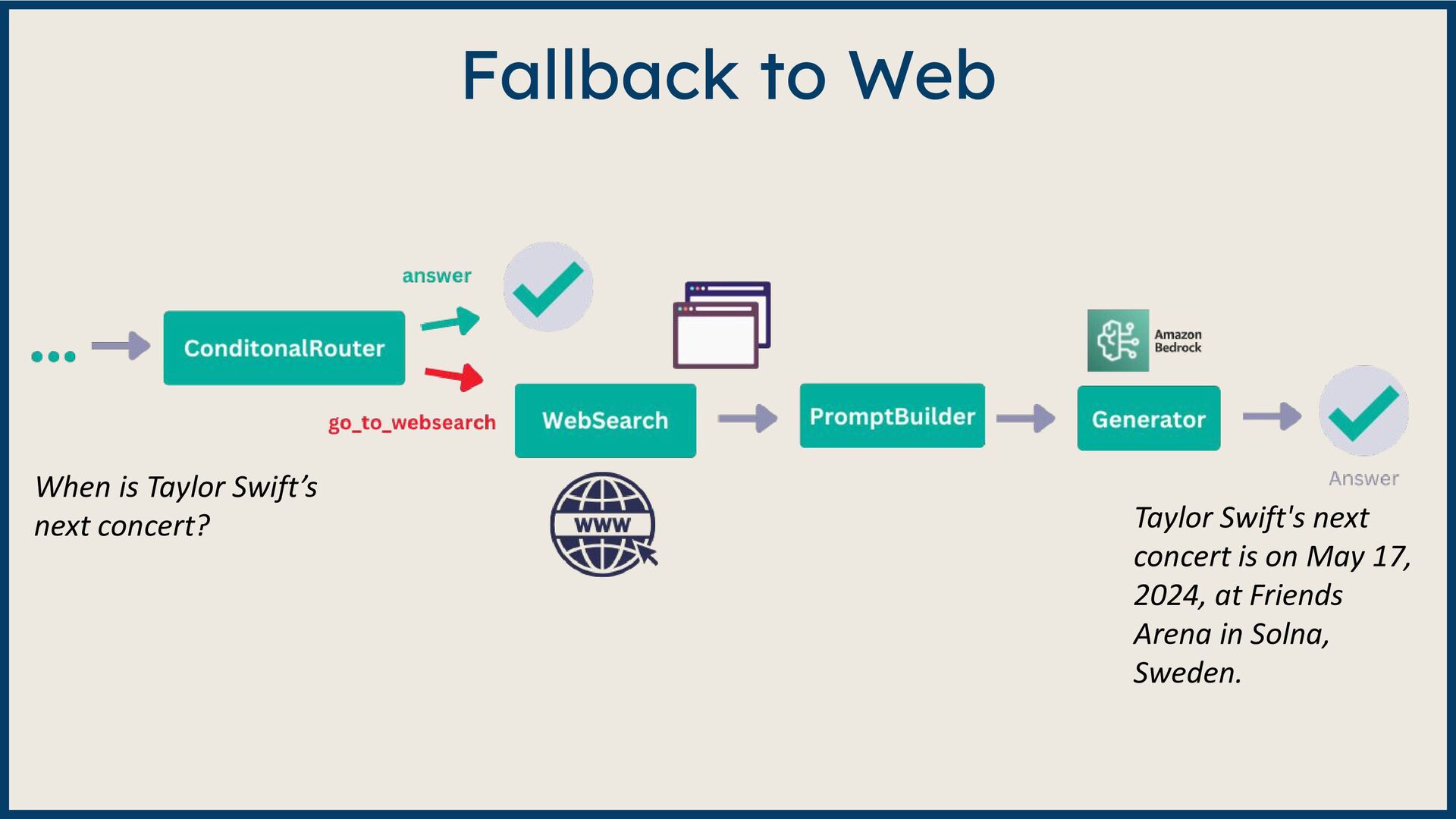
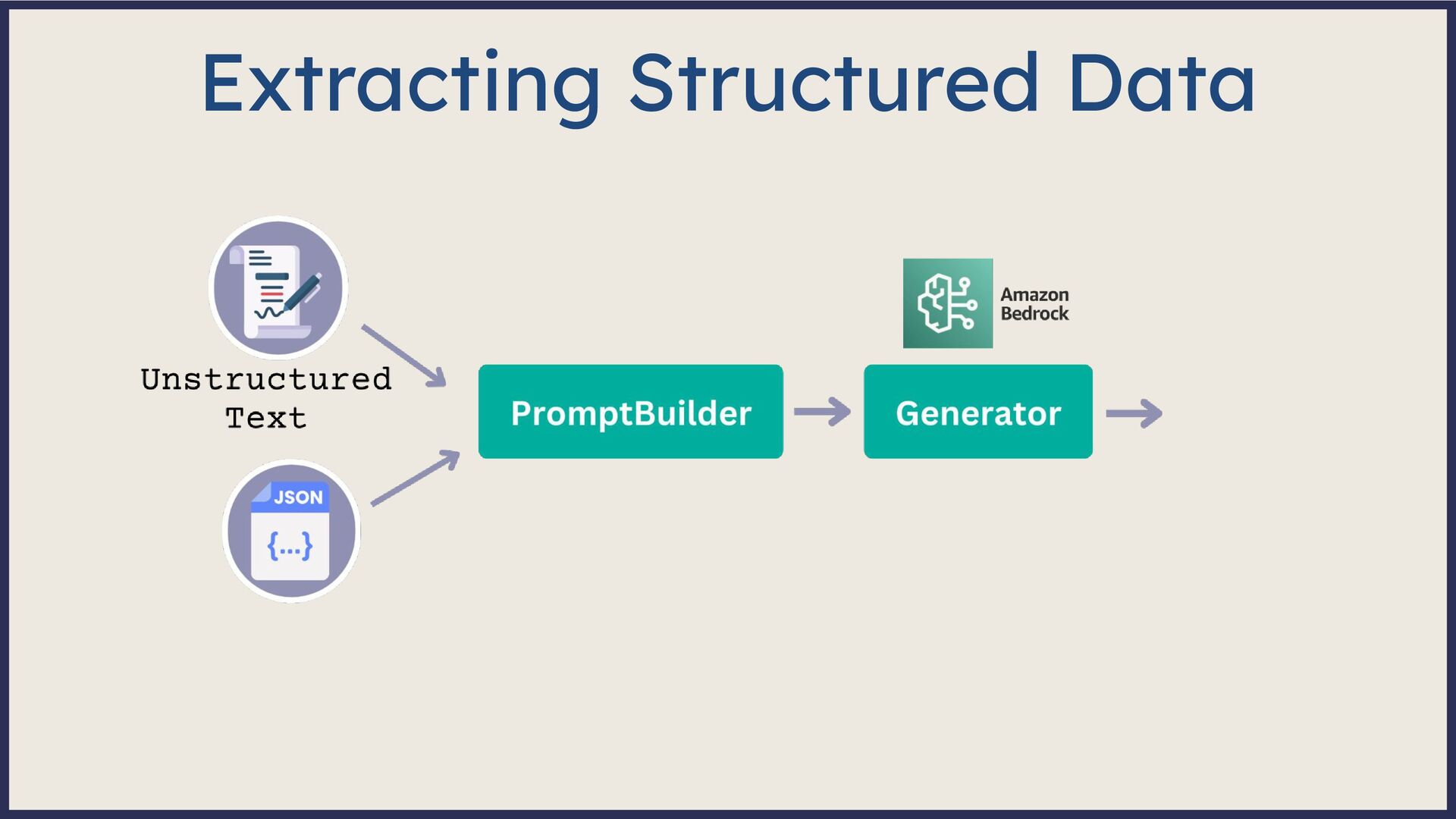
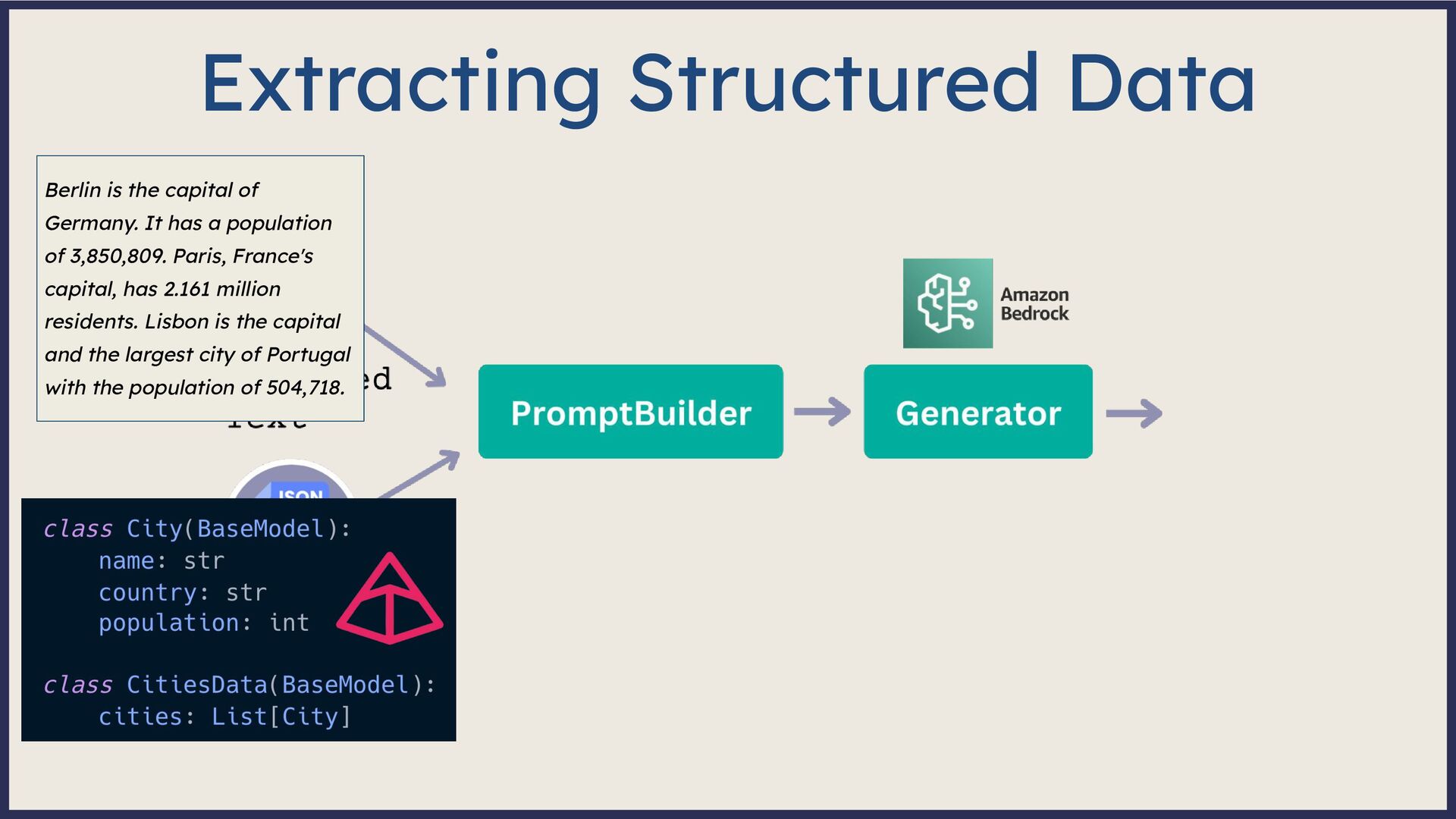
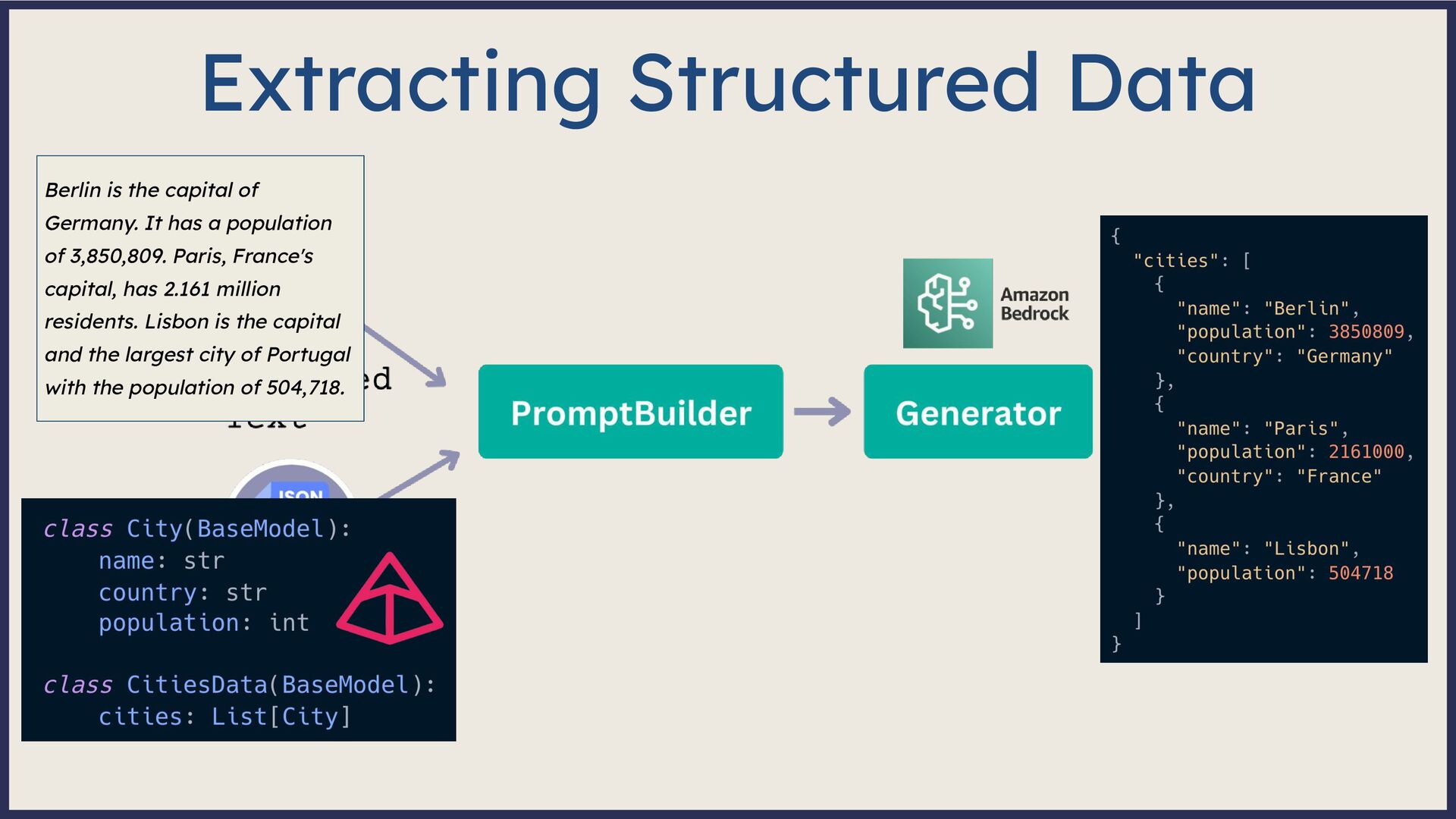
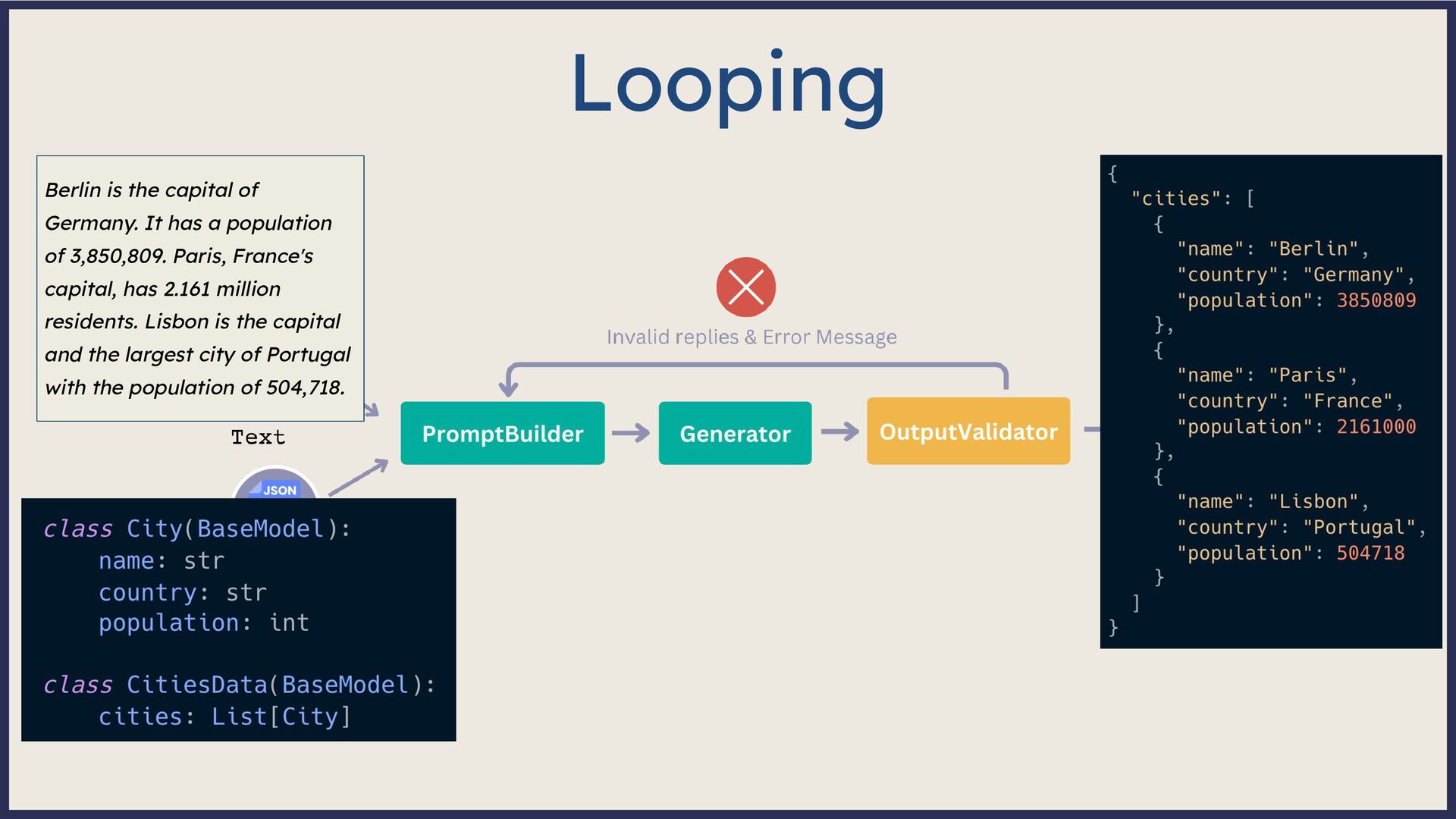
Large Language Model (LLM)-based systems have demonstrated remarkable advancements in various natural language processing (NLP) tasks, particularly through the Retrieval Augmented Generation (RAG) approach. This approach addresses some of the pitfalls associated with LLMs, such as hallucinations or issues related to the recentness of its training data. However, RAG systems may encounter other challenges in real-world scenarios, including handling out-of-domain queries (e.g., requesting medical advice from a finance app), struggling to generate meaningful answers from poorly retrieved data, or failing to provide any answer at all. To address these situations effectively, it is necessary to implement a fallback mechanism capable of gracefully handling such scenarios. This fallback mechanism can incorporate alternative strategies, such as conducting a web search with the same query to retrieve more up-to-date information or utilizing alternative information sources (such as Slack, Notion, Google Drive, etc.) to gather more relevant data and generate a satisfactory or comprehensive response. However, the question arises: how can we determine if the response is inadequate? During this session, we will start from scratch and lay the groundwork for generative AI applications. Next, we will explore various fallback mechanism techniques and ensure that our system can assess the adequacy of a response and improve it if necessary without human intervention. On the practical side, we will use the open-source LLM framework Haystack and Amazon Bedrock foundation models to implement end-to-end RAG systems. By the end of this talk, you will have learned to select the appropriate fallback method for your use case, enabling you to develop more dependable and versatile LLM-based systems and implement them effectively using Amazon Bedrock and Haystack.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}