Amikor valakinek azt mondom, adattárházakkal foglalkozom, mindig megkapom a következő kérdést: 'Jó, de ez miben különbözik egy "hagyományos" adatbázistól?'. Ebben az előadásban éppen ezt nézzük át: mik a főbb különbségek, miért tudnak a felhasználók nagy mennyiségű adatot gyorsan lekérdezni, milyen tervezési módszereket használunk adattárházaknál.
{kind=link}
{kind=link}
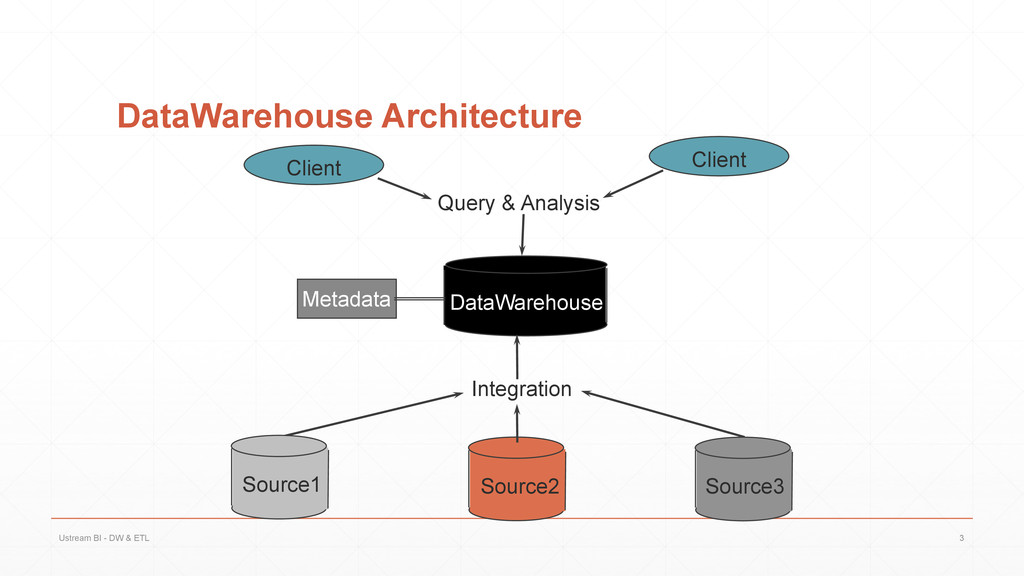{kind=link}
{kind=link}
{kind=link}
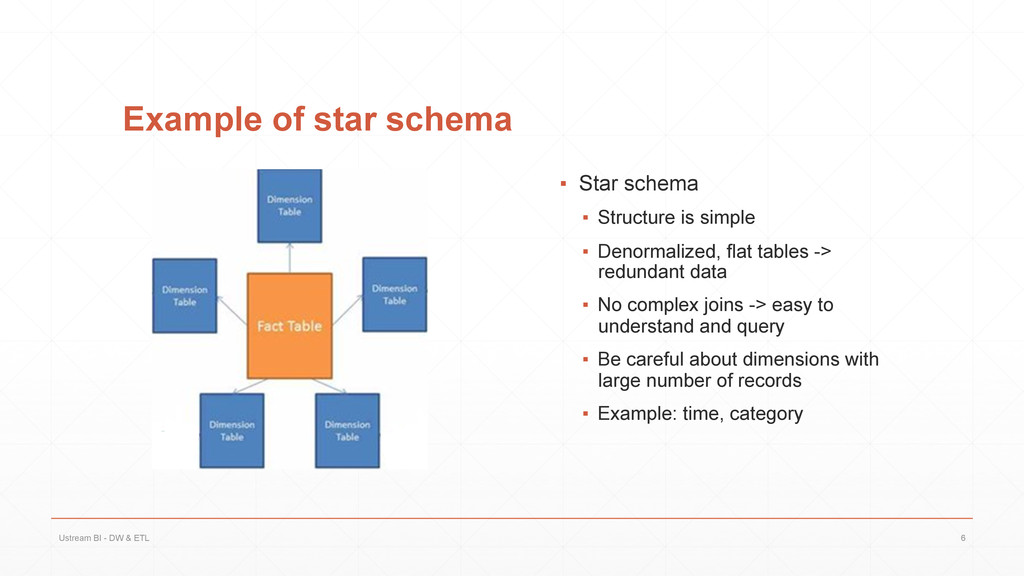{kind=link}
{kind=link}
{kind=link}
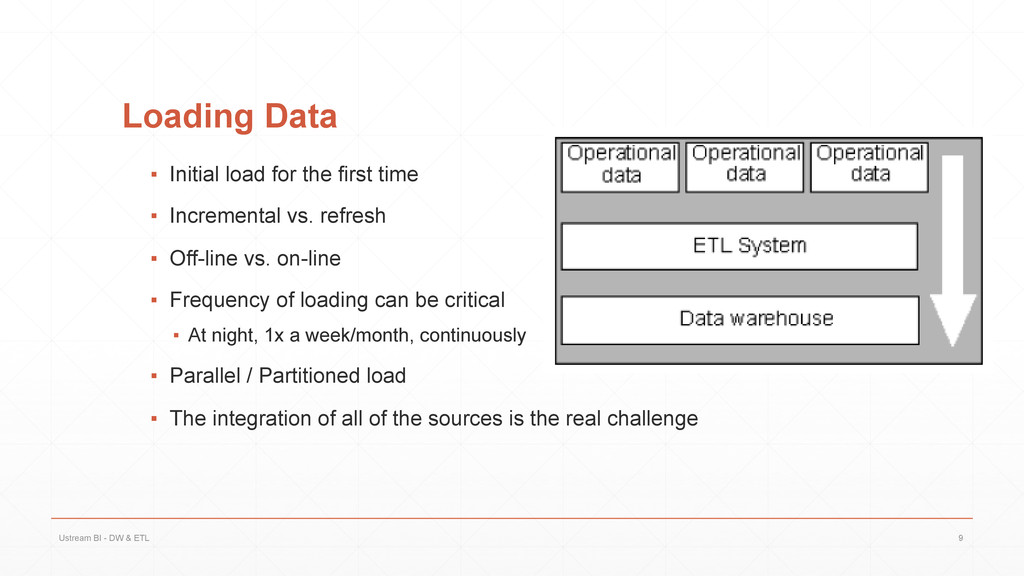{kind=link}
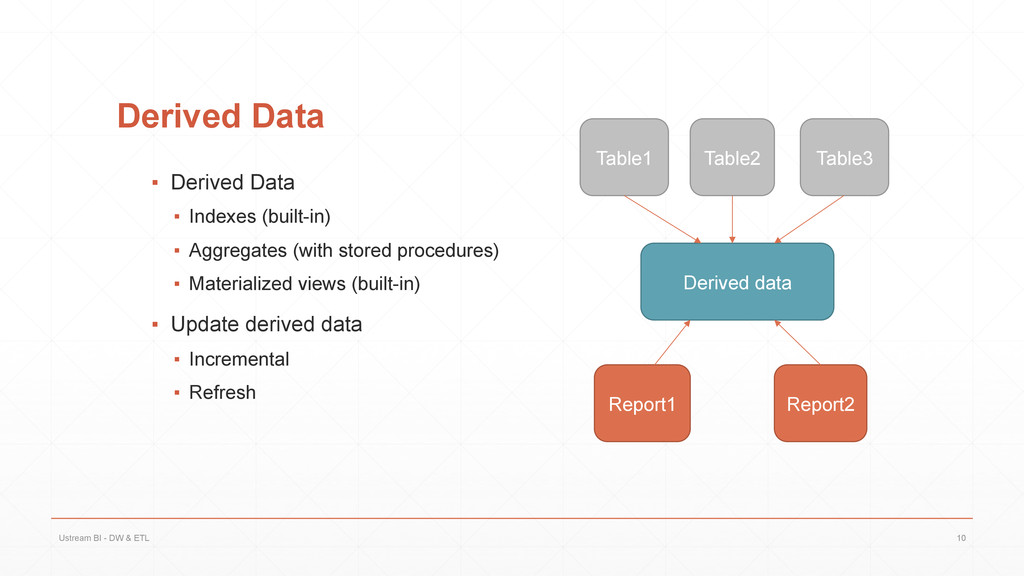{kind=link}
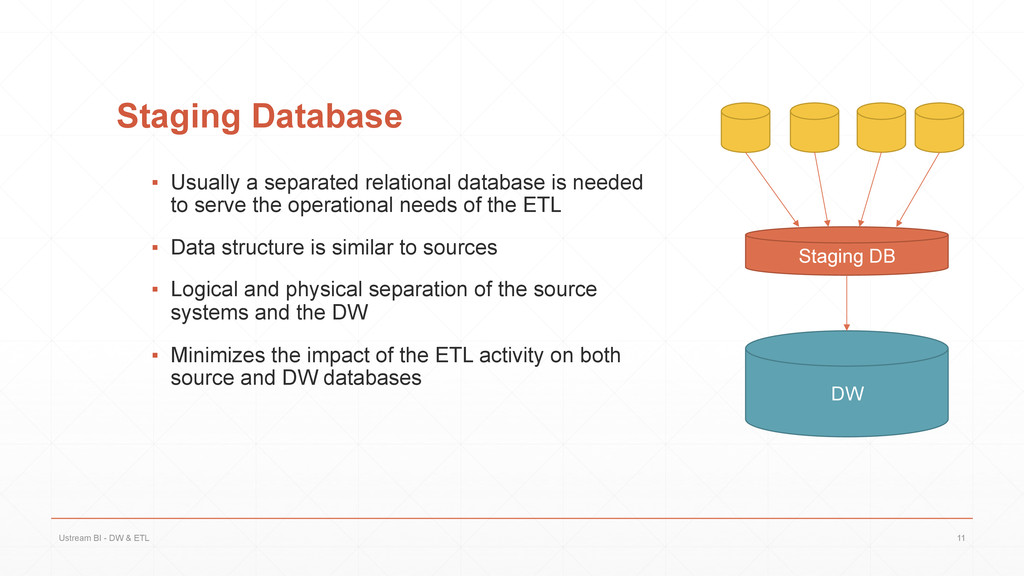{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
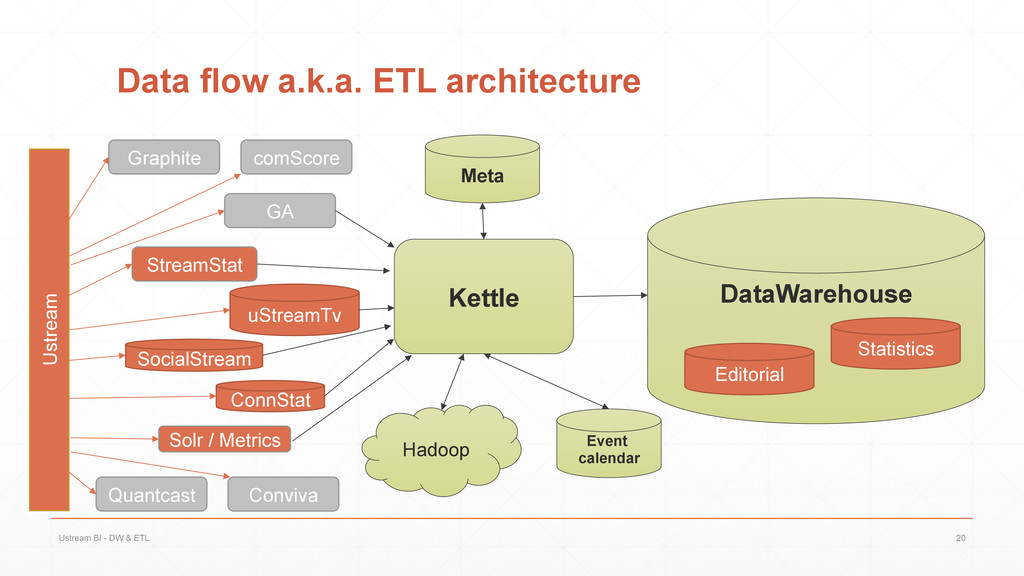{kind=link}