◦ Four specifications - BLAKE 224, 256, 384, 512 ◦ HAIFA construction - Salt handling ◦ Three-stage internal hash function • Stage 1 - Initialization ◦ Input: 8 chaining words, 4 salt words, 2 counter words ◦ Additionally, 16 constant words ◦ Produces 16-word input for the rounds arranged in a 4x4 matrix
Input: 16 chaining words, 16 message words, 16 constant words ◦ 14 rounds of the "G function" per message block • Stage 2 cont'd - G function ◦ Applies the Gi function eight times ◦ First - Columns of the input 4x4 matrix ◦ Second - Diagonals of the input 4x4 matrix
function ◦ Four input words, a row or diagonal from the 4x4 matrix ◦ Additionally, two constant words and two message words selected with a permutation ◦ Four output words put back into the row or column • Stage 3 - Finalization ◦ Input: 4x4 matrix (16 words), 8 original chaining words, 8 salt words ◦ Produces the next 8 chaining words
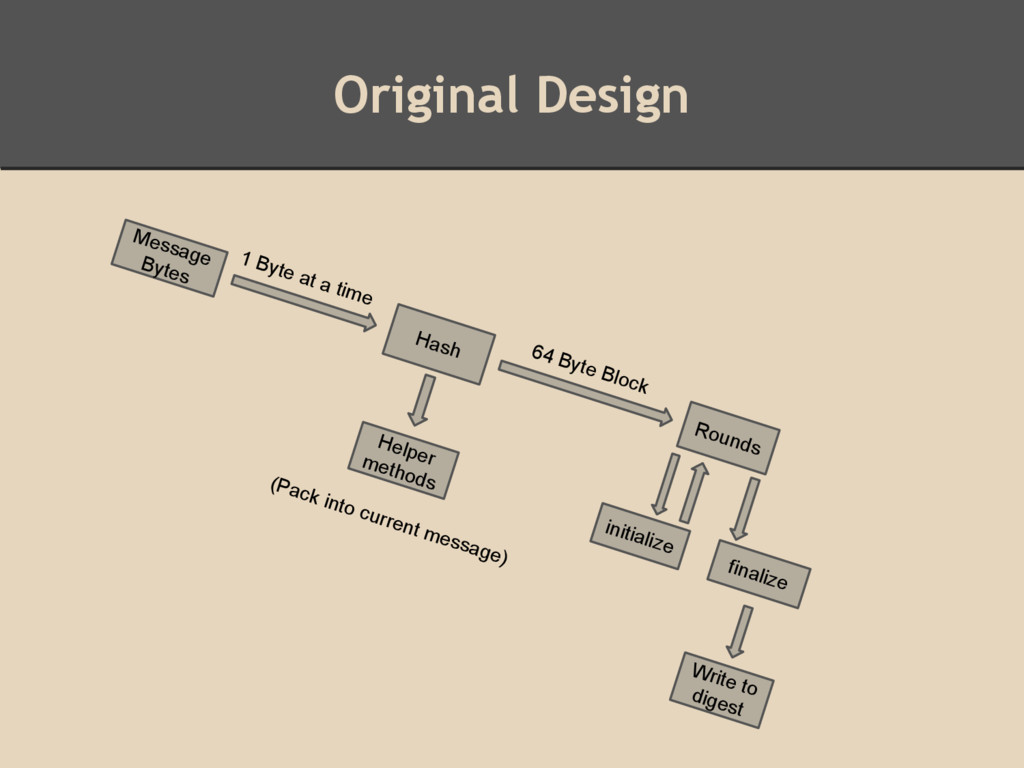
values • int [] currentmessage • final int [] constants • final int [][] permutation table • int makes sense because of the word size Methods hash, rounds, initialize, finalize, digest
0...13 //14 rounds per message block //four columns then four diagonals for i in 0...3 perform Gi function on column i //using r and i for the permutations for i in 0...3 perform Gi function on diagonal i+4 //using r and i+4 for the permutations finalize (m) //and write to the digest
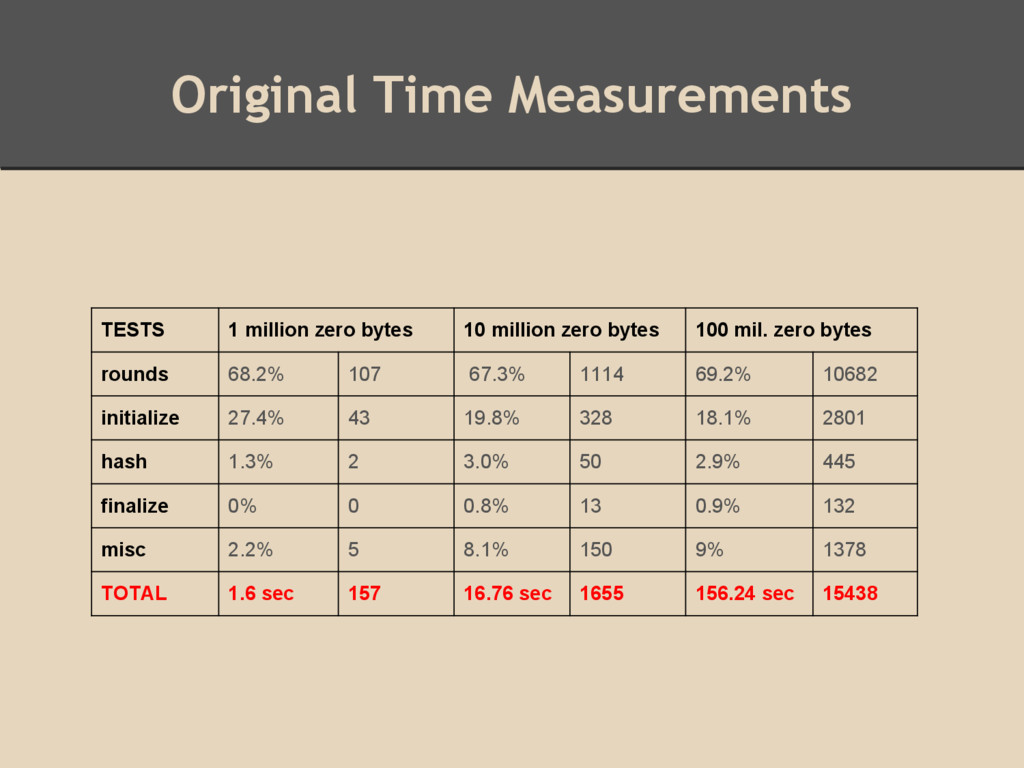
68%) of code execution time ◦ Major contributors ▪ looping for row, column steps ▪ in-line arithmetic (yields same pattern of values) ▪ indexing operations for our fields
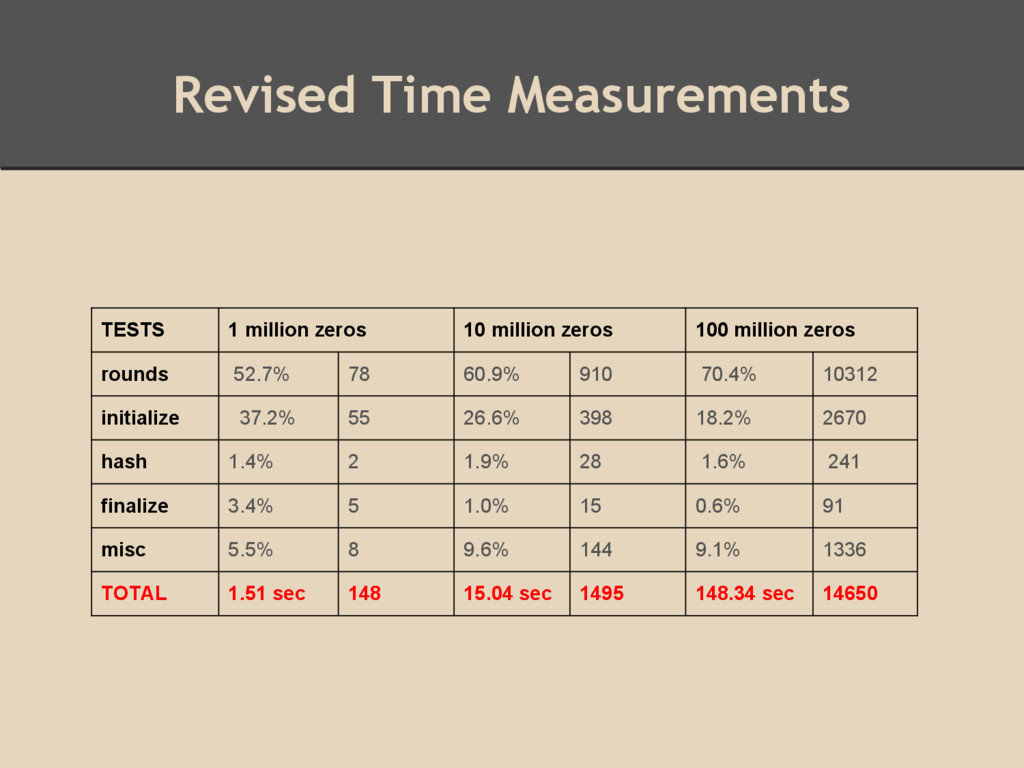
100 million bytes hashed - 148.34s vs 156.24s. ◦ 10 million bytes hashed - 15.14s vs 16.76s. ◦ 1 million bytes hashed - 1.51s vs 1.60s. • Between 5% and 10% gains for each category.
and still be quite strong. • Methods for optimizing algorithms, and how it affects the running time. • Java is not a great platform for fast execution. • Future Work: ◦ Implementations in C and/or FPGA (hardware) for platform advantages and parallelization. ◦ Analysis though NIST test suite and TEST001
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Original Design Fields • int [] digest - also chaining](https://files.speakerdeck.com/presentations/15ae5bfb92644245a9b0b7c99116aacd/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}