In “The intertwined quest for understanding biological intelligence and creating artificial intelligence,” Surya Ganguli maps out his vision for a new research program that seeks to, “unify the disciplines of neuroscience, psychology, cognitive science and AI.” He points to a handful of clues at confluence of these disciplines and hints at untapped sources of insight waiting to be discovered - by the observant explorer. Next Monday, at the Cognitively Informed Reading Group, we will survey some places where past treasure was found, such as temporal difference learning, wake-sleep, variational methods, memory networks and world models. We will then visit two outposts on the frontiers of computational neuroscience and social psychology where some some strange new patterns are emerging... Join us on _Monday, February 11th at 11:30am in A.14_ to take part in this quest.
Required Reading
"The intertwined quest for understanding biological intelligence and creating artificial intelligence" (Ganguli, 2018):
https://hai.stanford.edu/news/the_intertwined_quest_for_understanding_biological_intelligence_and_creating_artificial_intelligence/
Suggested Reading
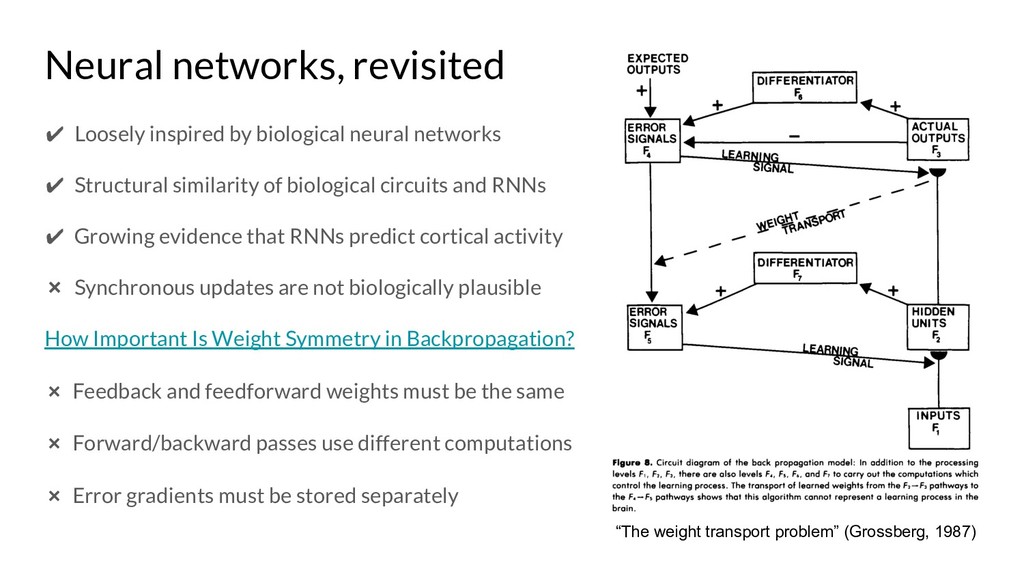
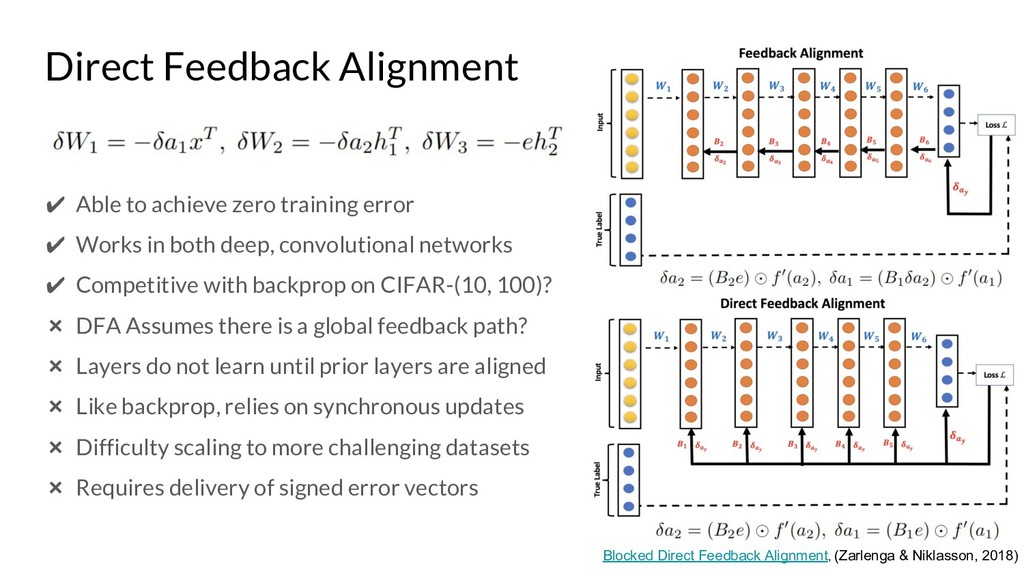
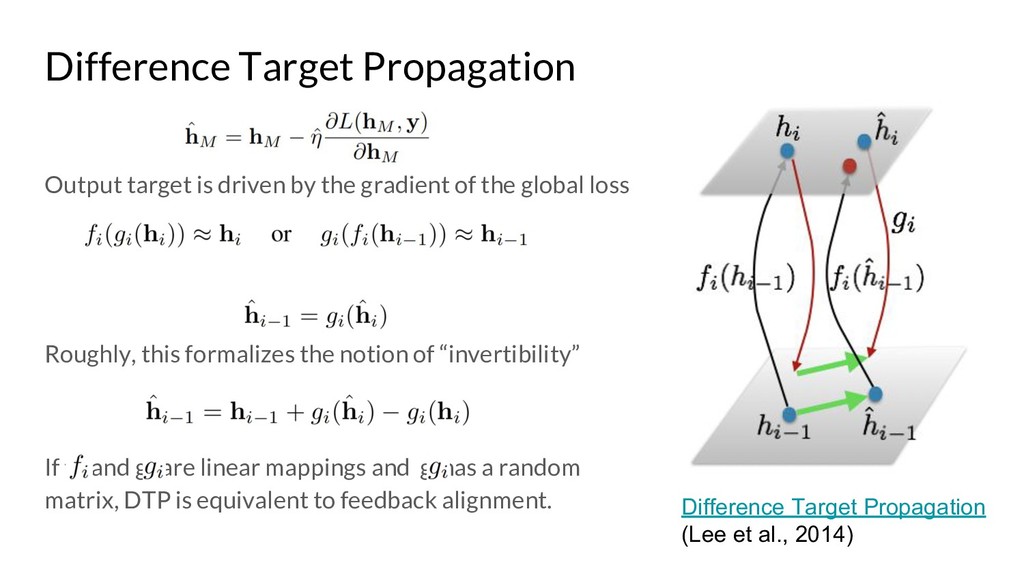
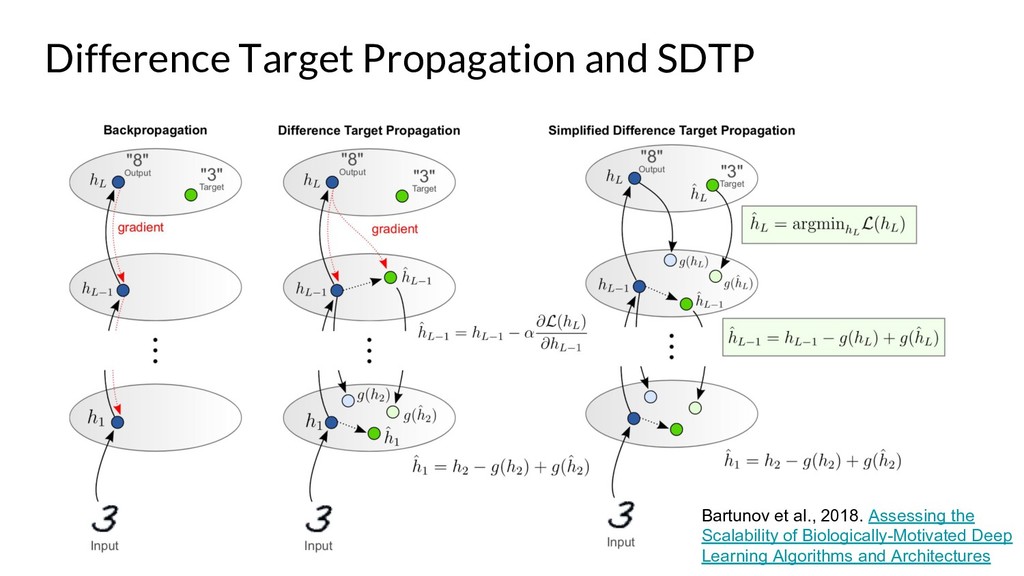
Assessing the Scalability of Biologically-Motivated Deep Learning Algorithms and Architectures (Bartunov et al., 2018): https://arxiv.org/pdf/1807.04587.pdf
Machine Theory of Mind (Rabinowitz et al., 2018): https://arxiv.org/pdf/1802.07740.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
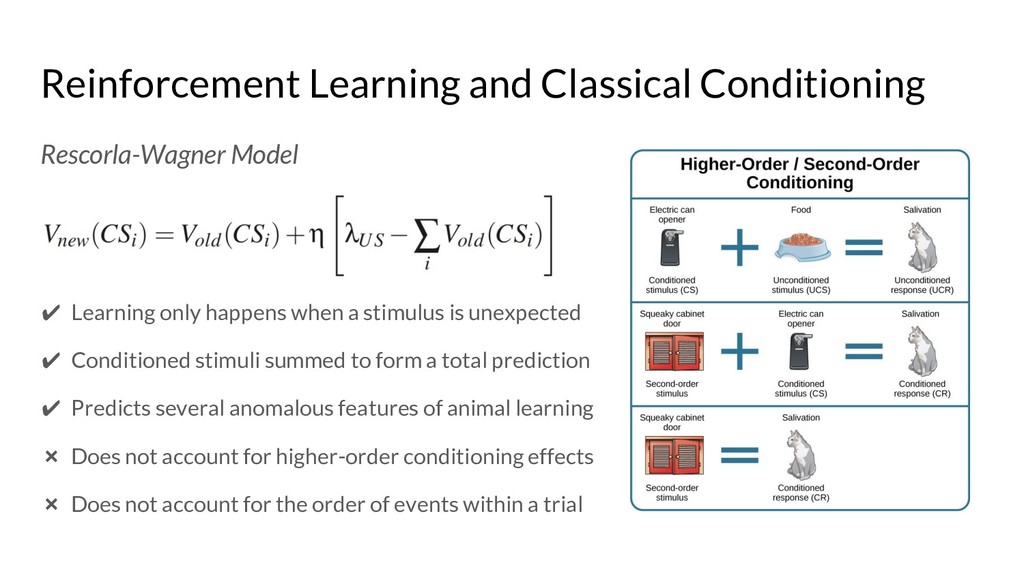{kind=link}
{kind=link}
{kind=link}
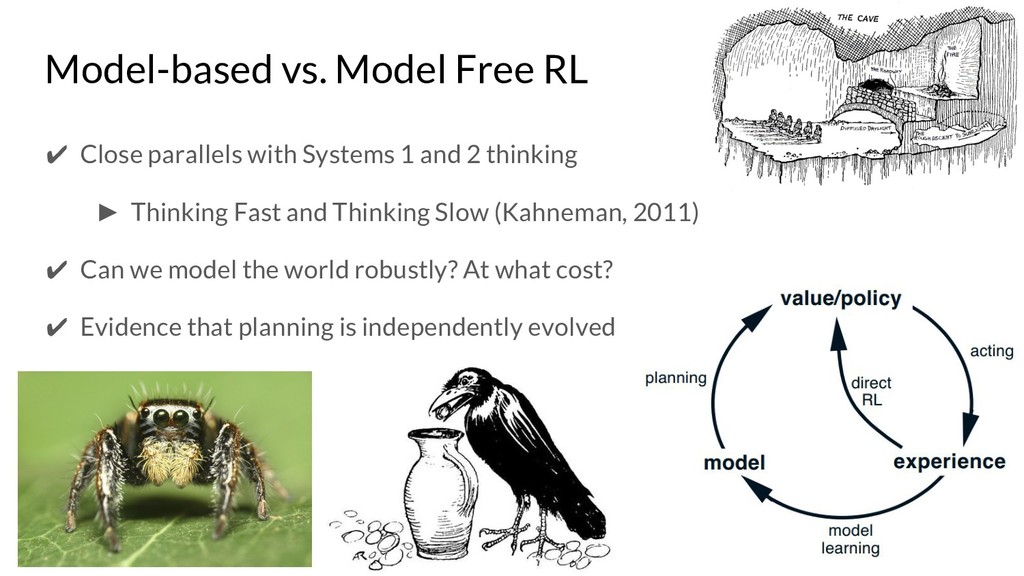{kind=link}
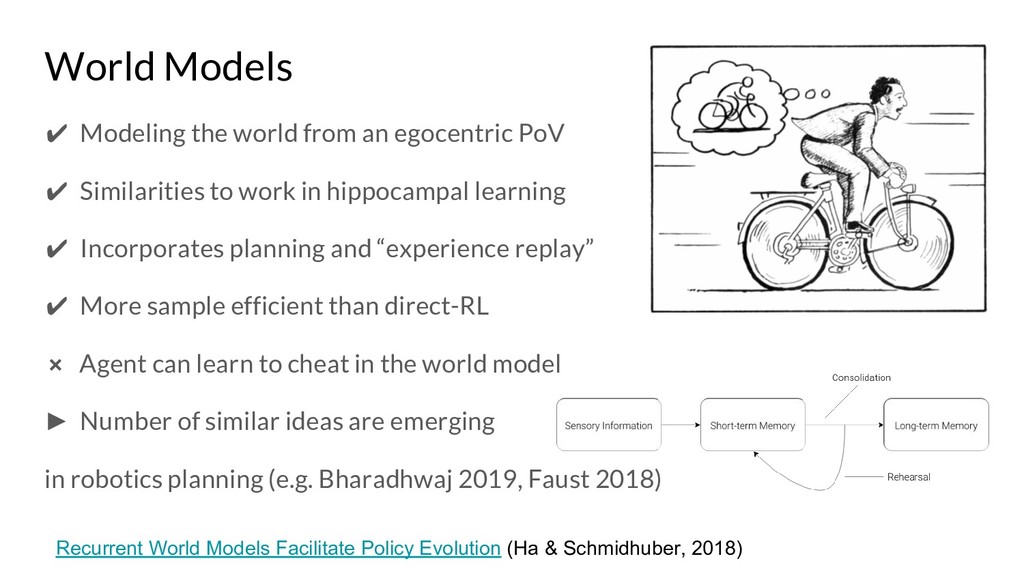{kind=link}
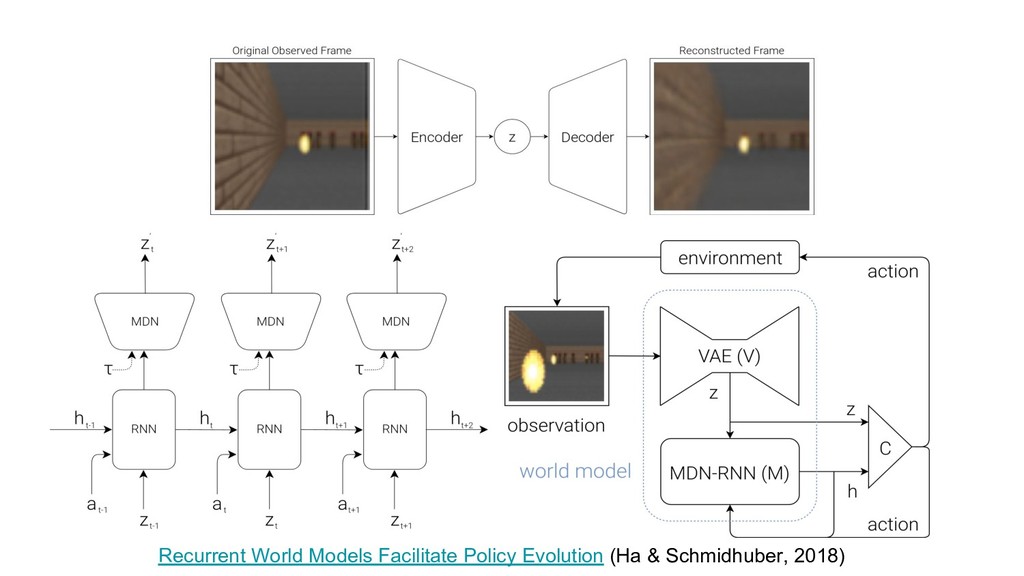{kind=link}
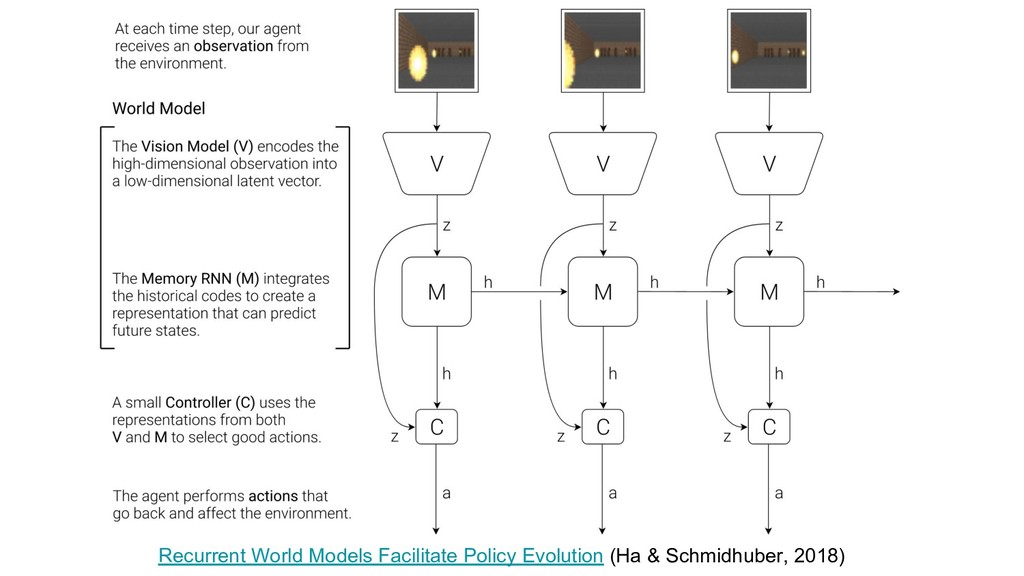{kind=link}
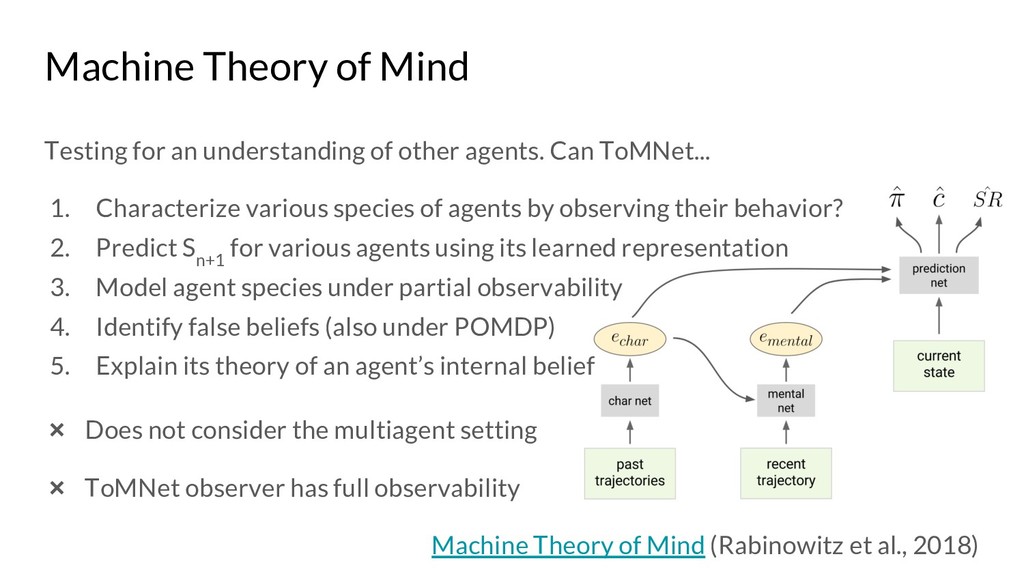{kind=link}
{kind=link}
{kind=link}
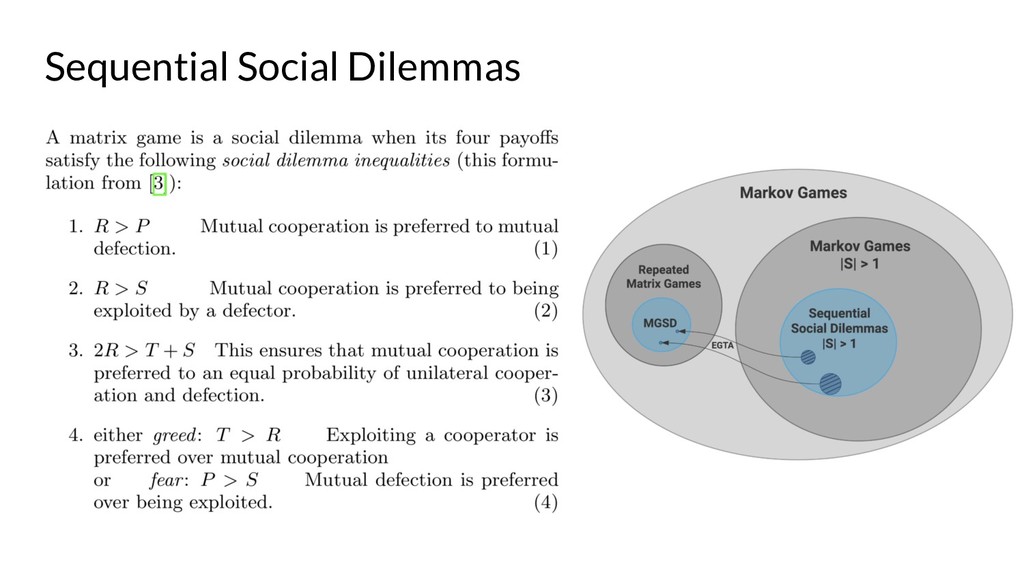{kind=link}
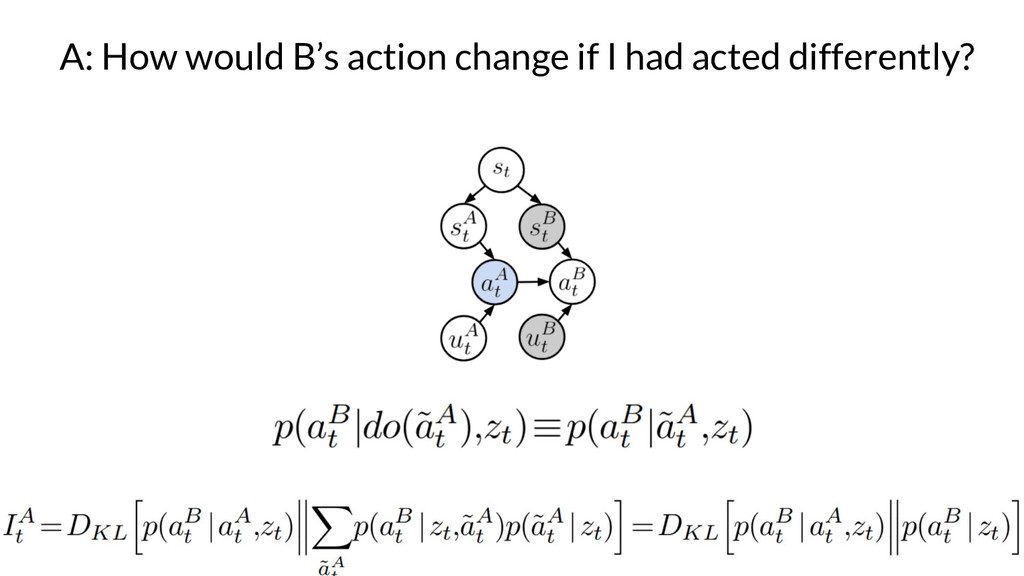{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}