production) ~Feb. 2009 • Engineer at 10gen - “The Company” • Scala support (maintain and develop drivers, improve and assist third party frameworks, community steering) • Java support (contribute to maintenance of drivers, features. Focus is on improving integration for non-Java JVM languages w/ our Java toolchain) • Hadoop support (develop & maintain MongoDB’s Hadoop integration layers, assist deployments) • Support (Free community & commercial) • Community Outreach (Meetups, Conferences) • Training & Consulting Monday, July 4, 2011
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables Monday, July 4, 2011
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” Monday, July 4, 2011
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” • Once we turn the relational data back into objects ... Monday, July 4, 2011
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” • Once we turn the relational data back into objects ... • We still need to convert it to data for our frontend Monday, July 4, 2011
• Structure of a single object is NOT immediately clear to someone glancing at the shell data • We have to flatten our object out into three tables • 7 separate inserts just to add “Programming in Scala” • Once we turn the relational data back into objects ... • We still need to convert it to data for our frontend • I don’t know about you, but I have better things to do with my time. Monday, July 4, 2011
memory) •OS controls what data in RAM •When a piece of data isn't found, a page fault occurs (Expensive + Locking!) •OS goes to disk to fetch the data •Indexes are part of the Regular Database files •Deployment Trick: Pre-Warm your Database (PreWarming your cache) to prevent cold start slowdown Operating System map files on the Filesystem to Virtual Memory Monday, July 4, 2011
“Foo, Bar” and “Foo, Bar, Baz” • The Query Optimizer figures out the order but can’t do things in reverse • You can pass hints to force a specific index: db.collection.find({username: ‘foo’, city: ‘New York’}).hint({‘username’: 1}) • Missing Values are indexed as “null” • This includes unique indexes • Deployment Trick: 1.8 has Sparse and Covered Indexes! • system.indexes ! Monday, July 4, 2011
storage needs •e.g. 4 20 gig disks gives you 40 gigs of usable space •LVM of RAID 10 on EBS seems to smooth out performance and reliability best for MongoDB RAID 10 (Mirrored sets inside a striped set; minimum 4 disks) Monday, July 4, 2011
bit MongoDB Build •32 Bit has a 2 gig limit; imposed by the operating systems for memory mapped files •Clients can be 32 bit •MongoDB Supports (little endian only) •Linux, FreeBSD, OS X (on Intel, not PowerPC) •Windows •Solaris (Intel only, Joyent offers a cloud service which works for Mongo) OS Monday, July 4, 2011
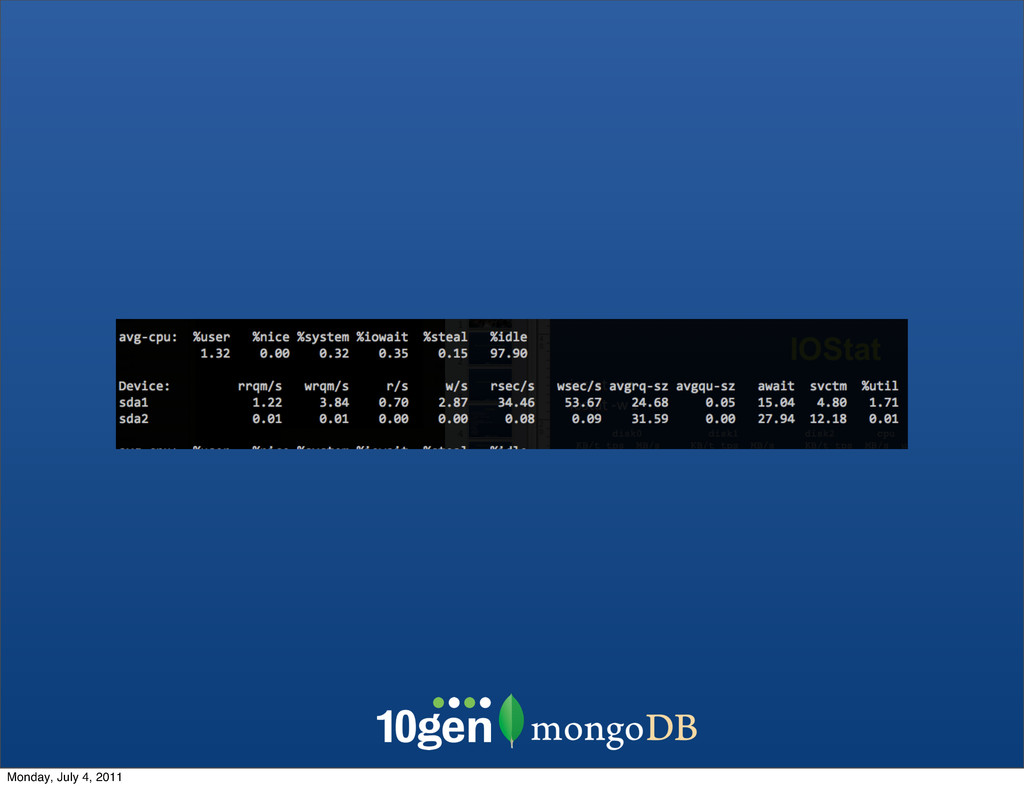
can be a bottleneck in large datasets where working set > ram •~200-300Mb/s on XL EC2 instances, but YMMV (EBS is slower) •On Amazon Latency spikes are common, 400-600ms (No, this is not a good thing) Similarly, iostat ships on most Linux machines (or can be installed) [sysstat package on Ubuntu] Monday, July 4, 2011
different disks •Best to aggregate your IO across multiple disks •File Allocation All data & namespace files are stored in the 'data' directory (--dbpath) Monday, July 4, 2011
response id op code (insert) \x68\x00\x00\x00 \xXX\xXX\xXX\xXX \x00\x00\x00\x00 \xd2\x07\x00\x00 reserved collection name document(s) \x00\x00\x00\x00 f o o . t e s t \x00 BSON Data http://www.mongodb.org/display/DOCS/Mongo+Wire+Protocol Monday, July 4, 2011
ext4 by default) •For best performance reformat to EXT4 / XFS •Make sure you use a recent version of EXT4 •Striping (MDADM / LVM) aggregates I/O •See previous recommendations about RAID 10 EC2 Monday, July 4, 2011
be needed occasionally on indices and datafiles •db.repair() •Replica Sets: •Rolling repairs, start nodes up with --repair param • Deployment Trick: For large bulk data operations consider removing indexes and re-adding them later! (better : a new DB may help) Maintenance Monday, July 4, 2011
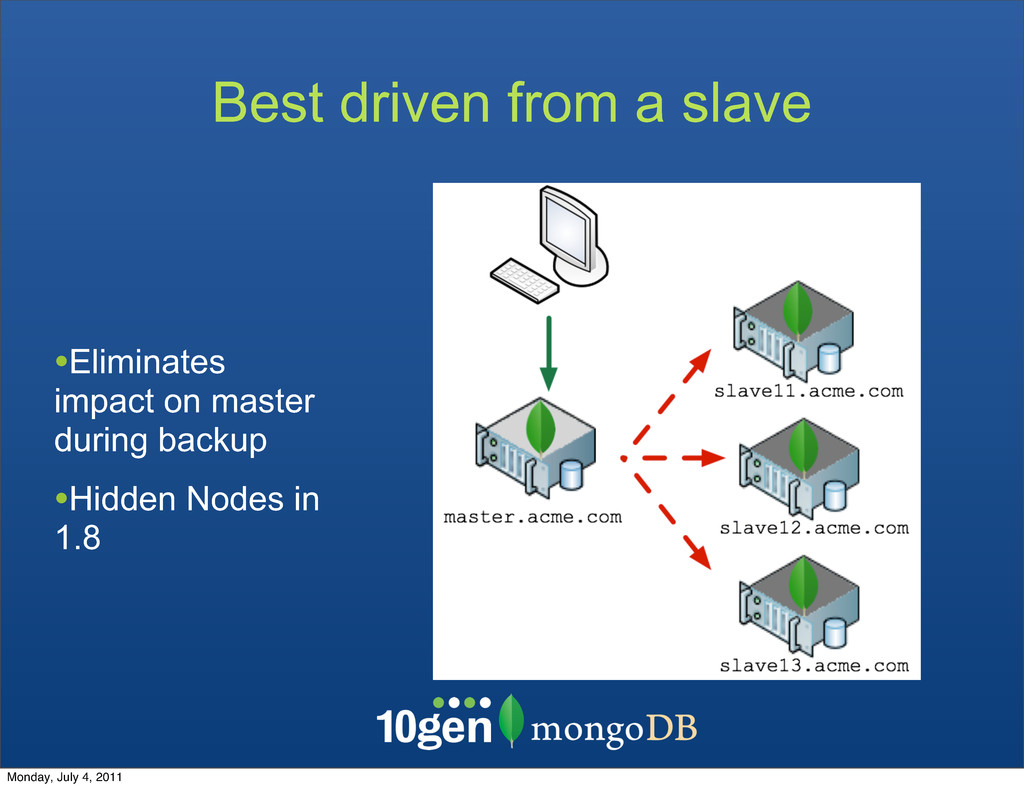
necessarily consistent from start to finish (Unless you lock the database) •mongorestore to restore binary dump •Deployment Trick #1: database doesn't have to be up to restore, can use dbpath • Deployment Trick #2: mongodump with replSetName/ <hostlist> will automatically read from a slave! mongodump / mongorestore Monday, July 4, 2011
backups •USE AMAZON AVAILABILITY ZONES •DR / HA With Journaling, you can run an LVM or EBS snapshot and recover later without locking Monday, July 4, 2011
by members of a “replica set” • The system elects a primary (master) • Failure of the master is detected, and a new master is elected • Application writes get an error if there is no quorum to elect a new master • Reads continue to be fulfilled Monday, July 4, 2011
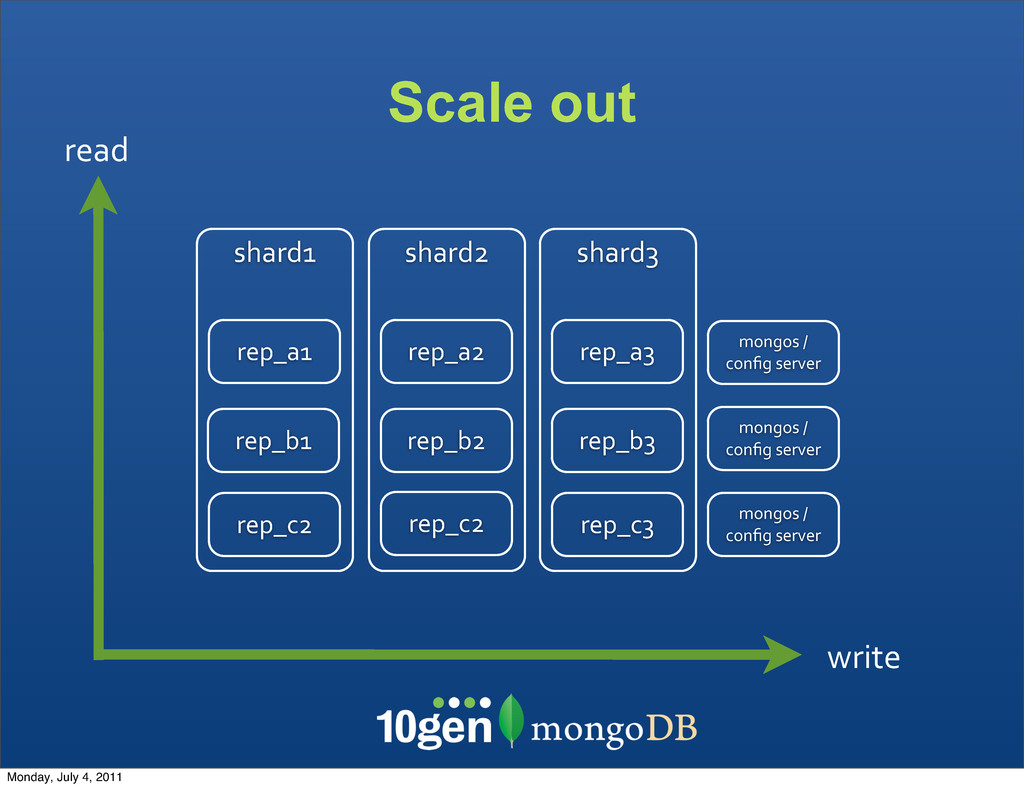
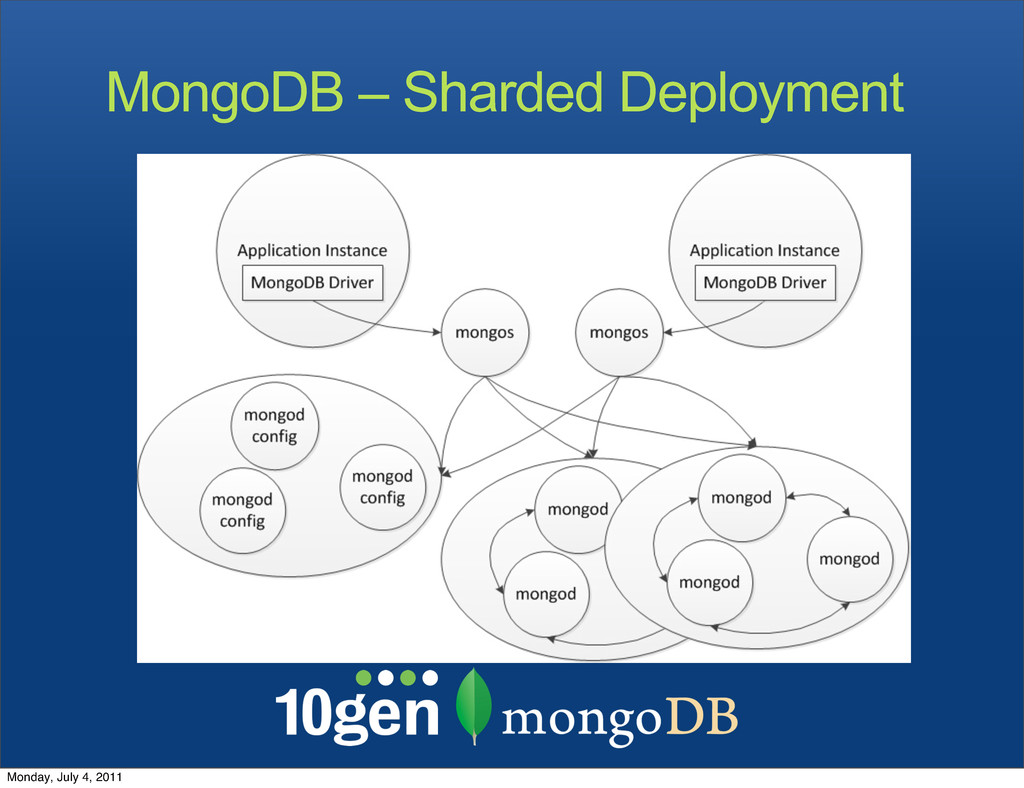
Each shard is served by its own replica set • New shards (each a replica set) can be added at any time • Shard key ranges are automatically balanced Monday, July 4, 2011
• Servers should have a lot of memory • Files are allocated as needed • Documents in a collection are kept on a list using a geographical addressing scheme • Indexes (B*-trees) point to documents using geographical addresses Monday, July 4, 2011
each other • A majority of votes is required to elect a new primary • Members can be assigned priorities to affect the election • e.g., an “invisible” replica can be created with zero priority for backup purposes Monday, July 4, 2011
{kind=link}
![Introductions • Brendan McAdams <[email protected]> • Started using MongoDB (in](https://files.speakerdeck.com/presentations/4e120b1957530855fe000002/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![•iostat [args] <seconds per poll> •-x for extended report •Disk](https://files.speakerdeck.com/presentations/4e120b1957530855fe000002/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}