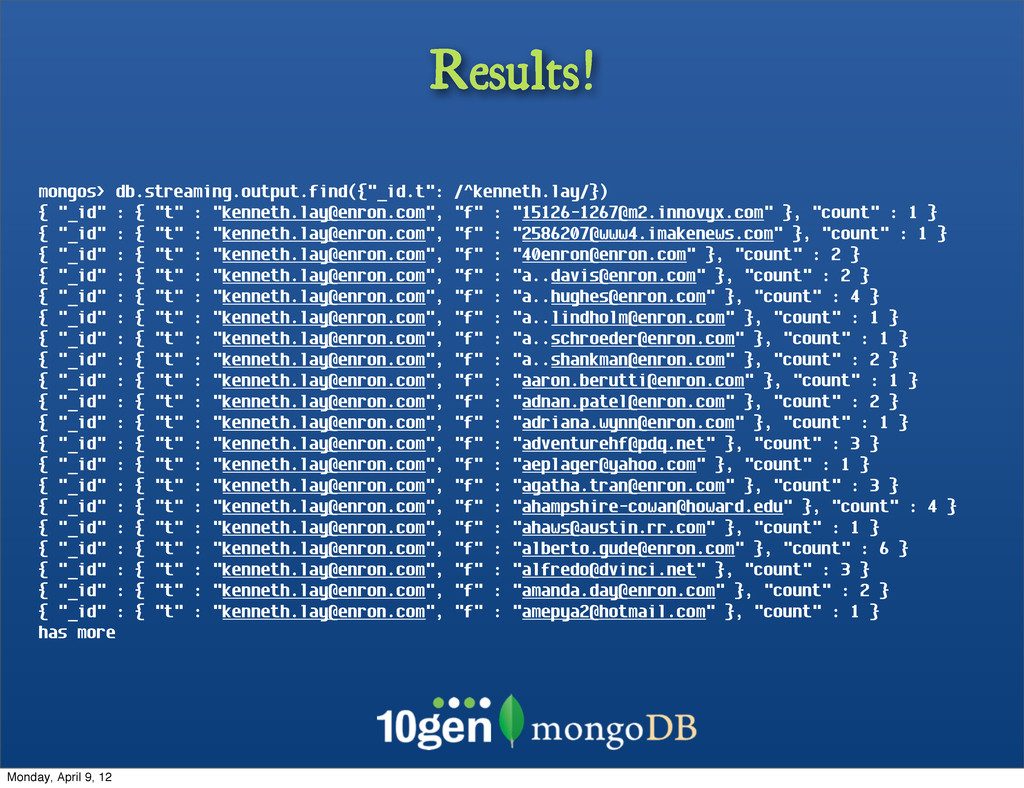
"
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 2 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 2 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 4 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 2 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 2 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 3 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 3 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 4 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 6 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 3 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 2 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } has more Monday, April 9, 12
![Brendan McAdams 10gen, Inc. [email protected] @rit Taming The Elephant In](https://files.speakerdeck.com/presentations/4f837e6731949f001f011ca1/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
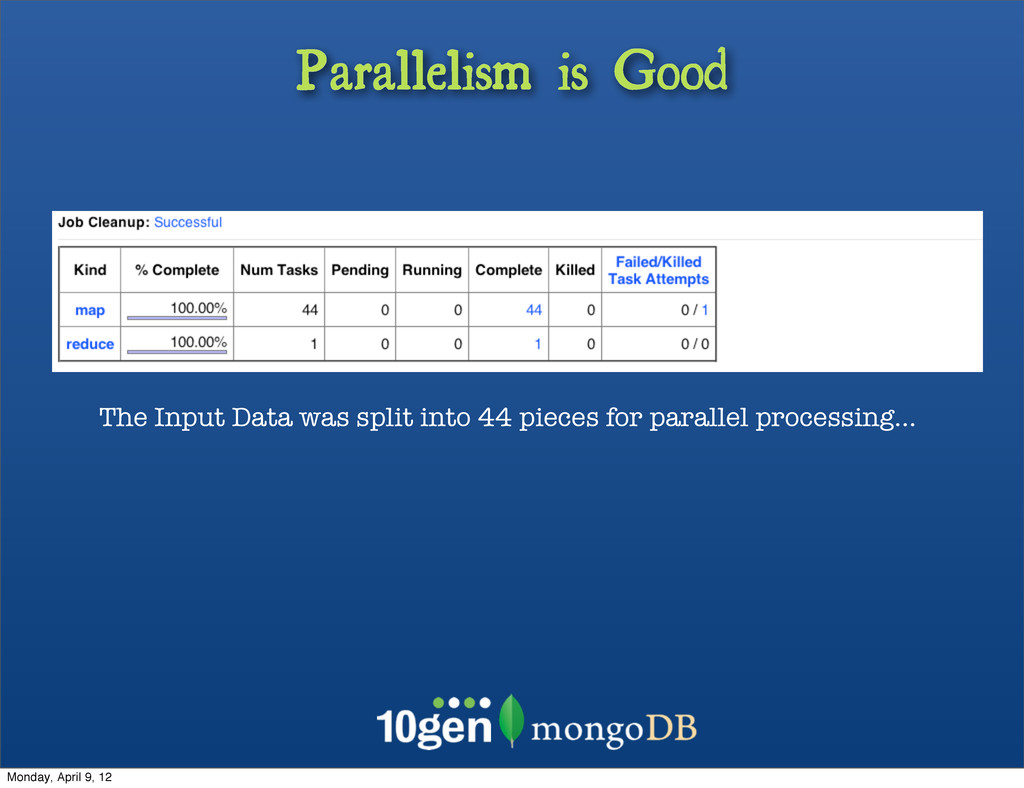{kind=link}
{kind=link}
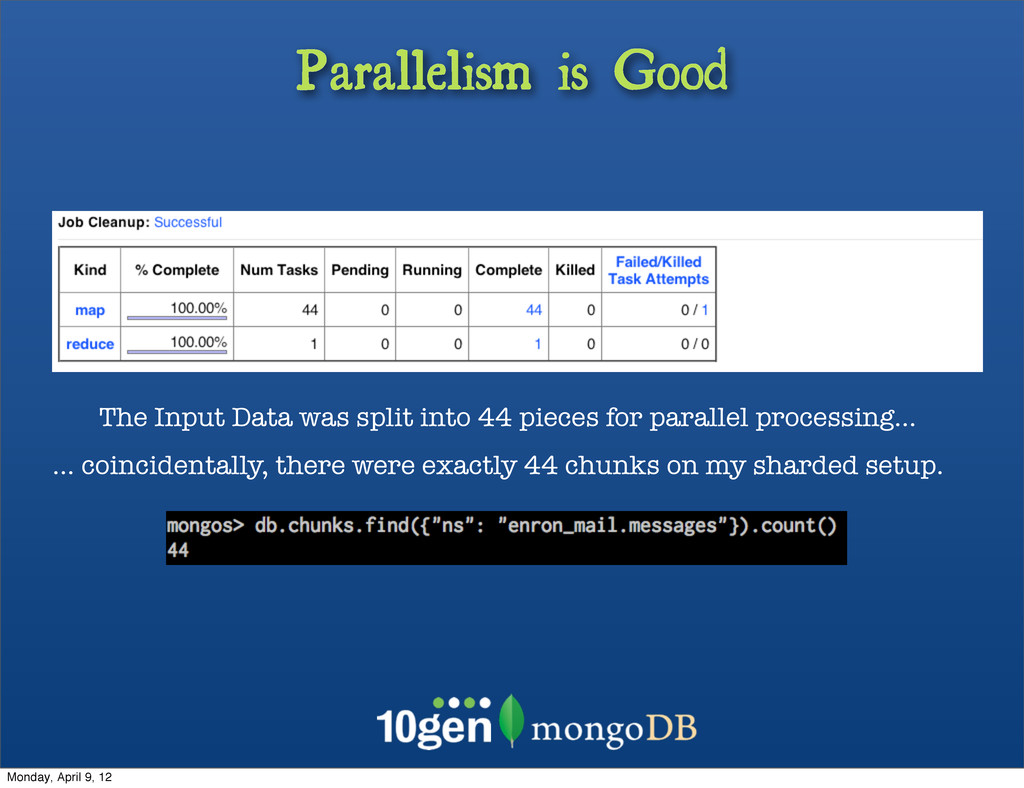{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}