Data Science in astro image processing: looking for exoplanets using machine learning
Talk presented at the “Data science in the Alps” workshop. The program of this meeting was composed of a mixture of talks about methodological research and about various scientific applications of data science.
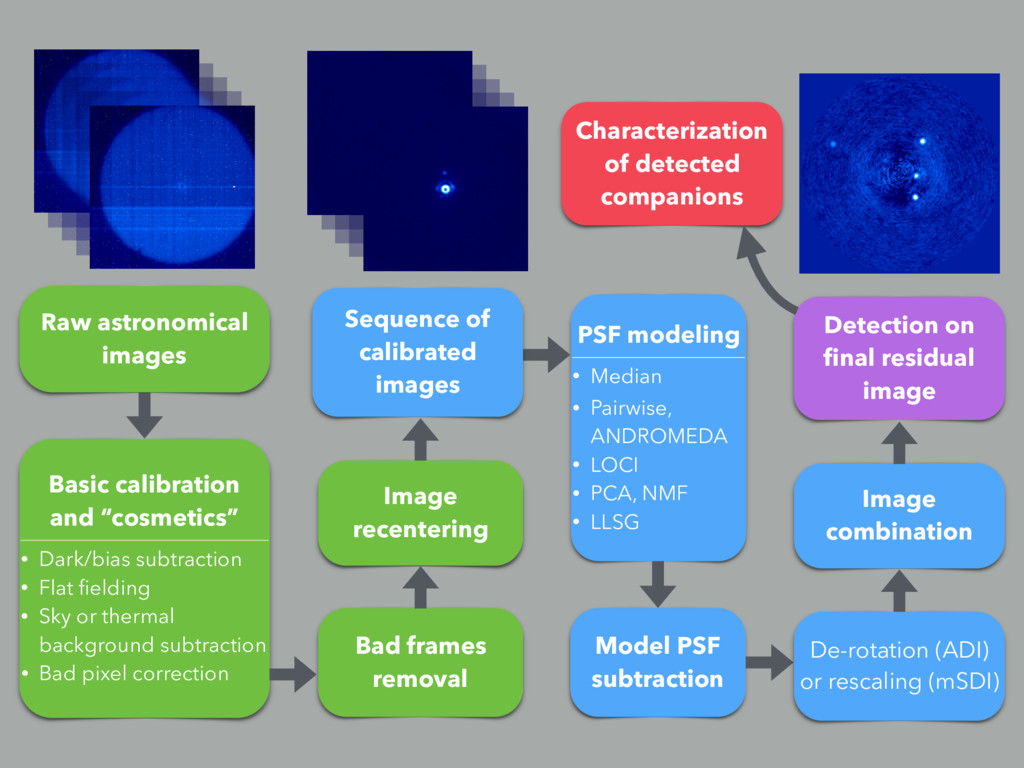
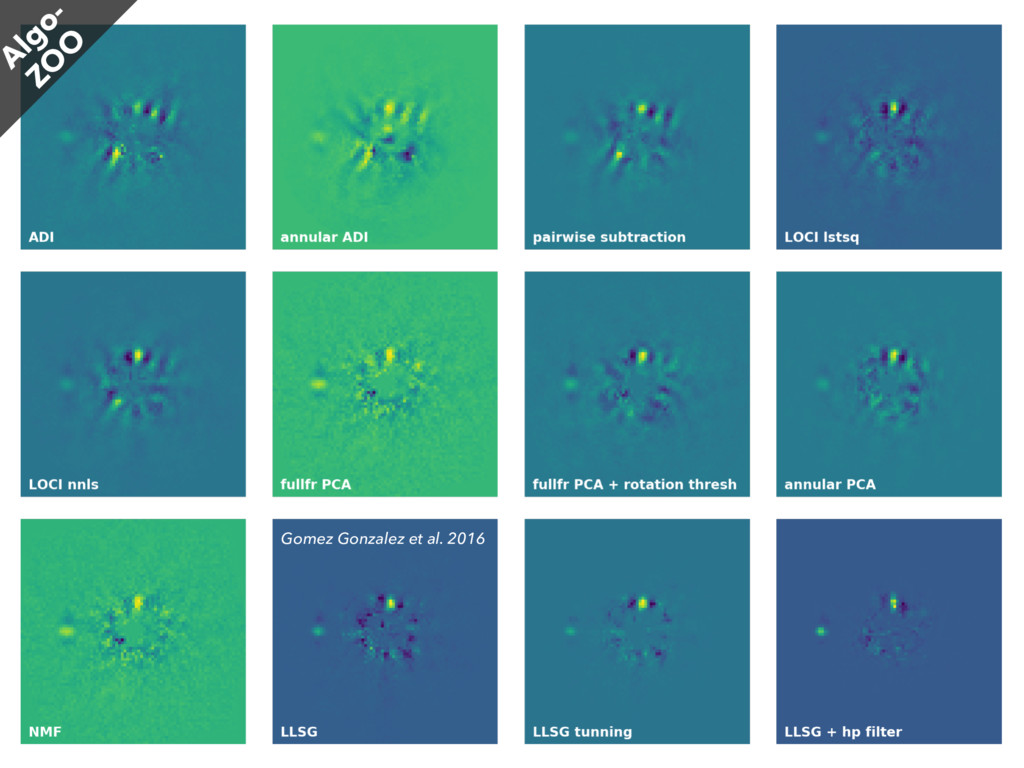
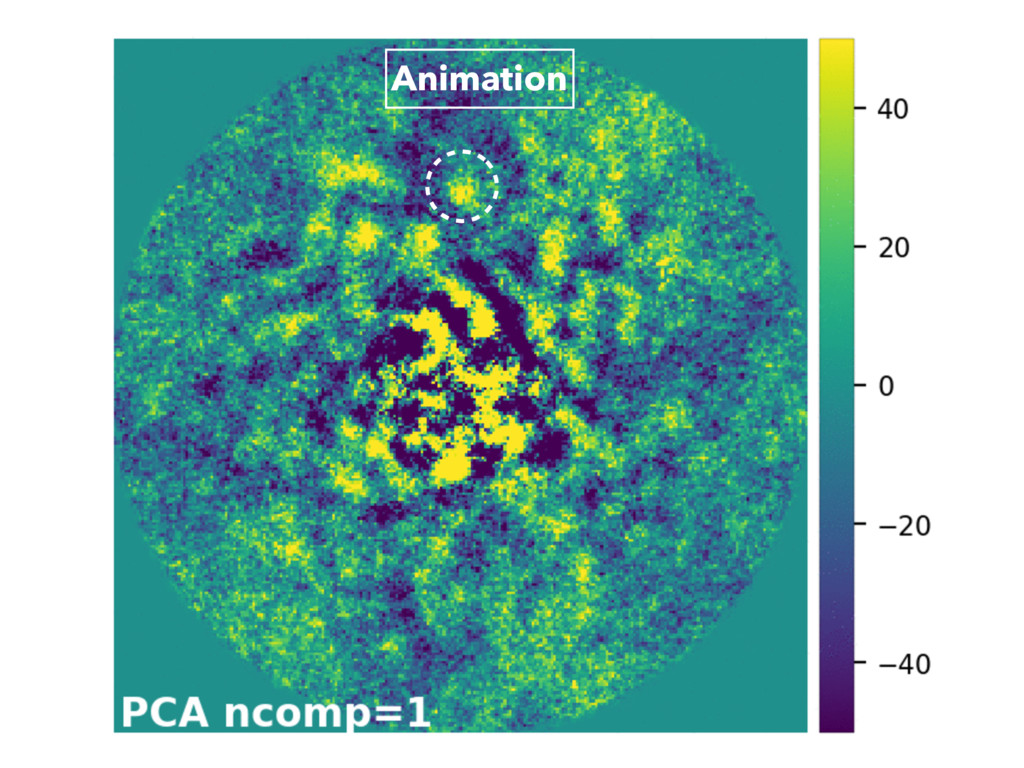
• Sky or thermal background subtraction • Bad pixel correction Raw astronomical images Detection on final residual image Image recentering Bad frames removal PSF modeling • Median • Pairwise, ANDROMEDA • LOCI • PCA, NMF • LLSG Image combination Model PSF subtraction De-rotation (ADI) or rescaling (mSDI) Characterization of detected companions Sequence of calibrated images
actual scholarship is the full software environment, code and data, that produced the result.” Buckheit and Donoho, 1995 “Today, software is to scientific research what Galileo’s telescope was to astronomy: a tool, combining science and engineering. It lies outside the central field of principal competence among the researchers that rely on it. … it builds upon scientific progress and shapes our scientific vision.” Pradal 2015
Developing and maintaining open-source code is not trivial. • And a great responsibility… • Making sure the code is scientifically correct • and that it’s readable, free of bugs and well- documented Best practices for scientific computing (Wilson et al. 2012) Good enough practices in scientific computing (Wilson et al. 2016)
Box “…if the model is going to be wrong anyway, why not see if you can get the computer to ‘quickly’ learn a model from the data, rather than have a human laboriously derive a model from a lot of thought.” Peter Norvig
the input samples to the labels given a labeled dataset : min f∈F 1 n n i=1 L(yi, f(xi )) + λΩ(f) f : X → Y, (xi, yi )i=1,...,n Supervised learning Goodfellow et al. 2016
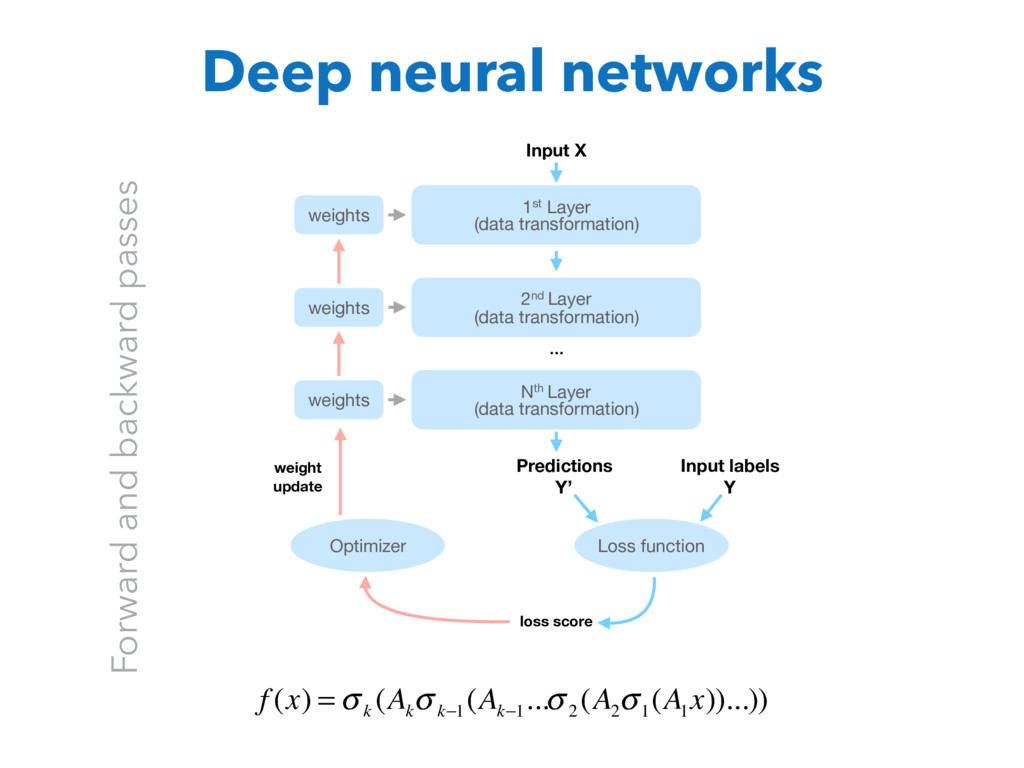
Nth Layer (data transformation) … Predictions Y’ Input labels Y Loss function weights weights weights Optimizer loss score weight update Forward and backward passes f (x) = σ k (A k σ k−1 (A k−1 ...σ 2 (A 2 σ 1 (A 1 x))...)) Deep neural networks
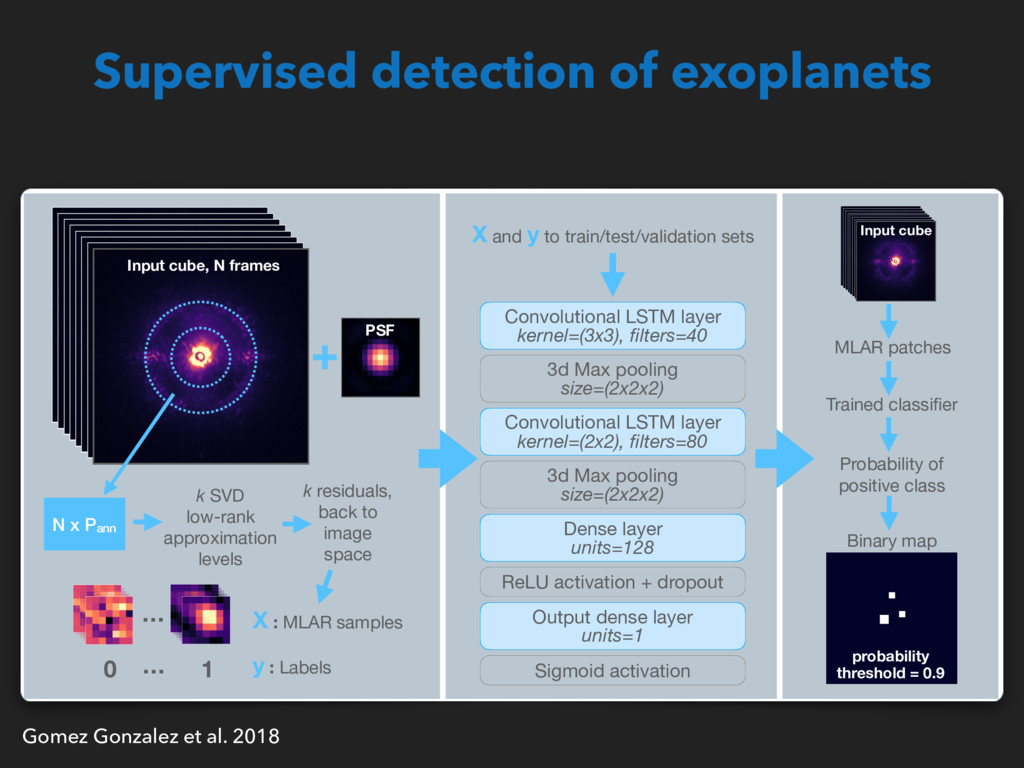
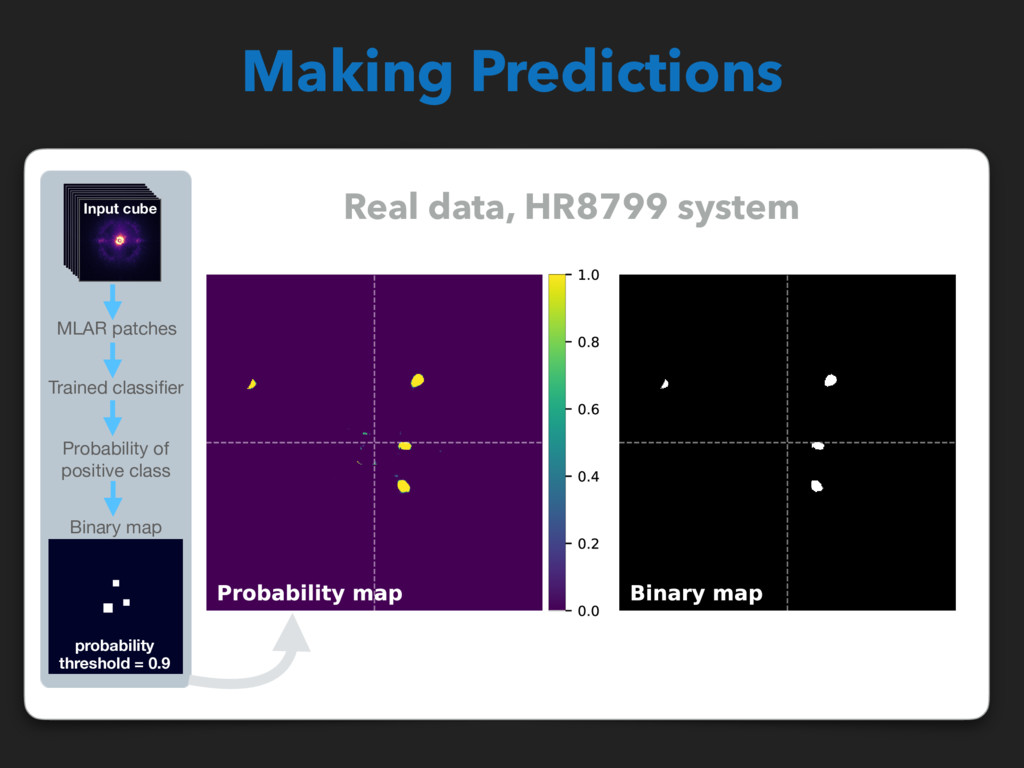
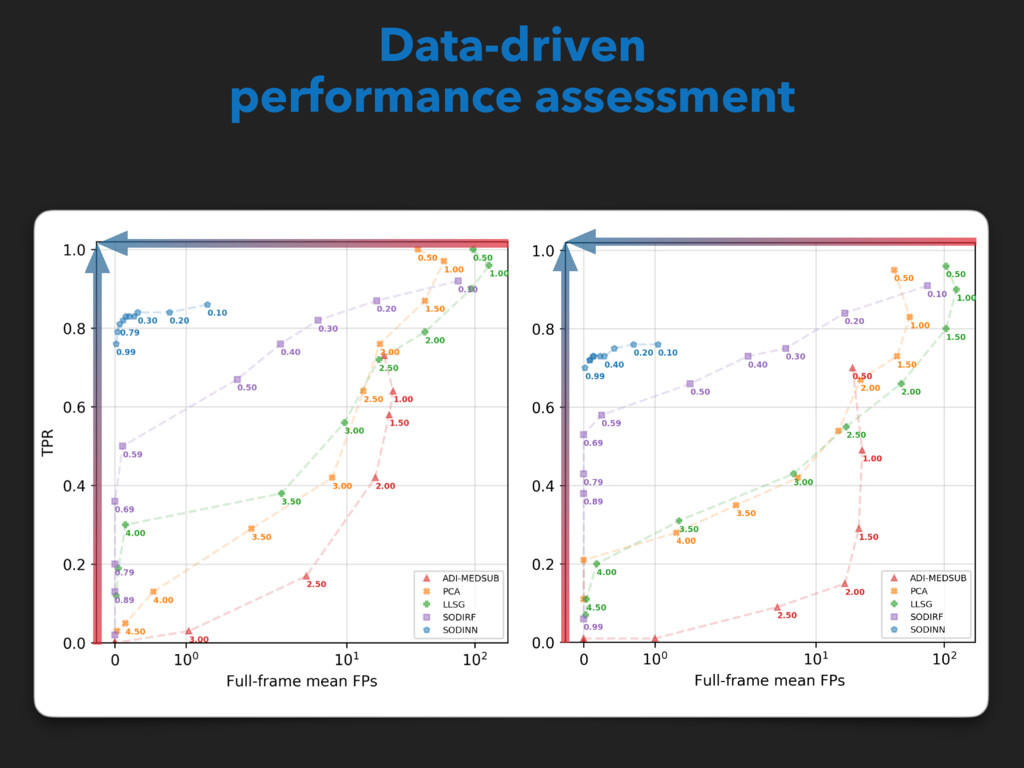
back to image space X : MLAR samples 0 1 Convolutional LSTM layer kernel=(3x3), filters=40 Convolutional LSTM layer kernel=(2x2), filters=80 Dense layer units=128 Output dense layer units=1 3d Max pooling size=(2x2x2) 3d Max pooling size=(2x2x2) ReLU activation + dropout Sigmoid activation X and y to train/test/validation sets Probability of positive class MLAR patches Binary map probability threshold = 0.9 Trained classifier PSF Input cube, N frames Input cube y : Labels … … (a) (b) (c) Supervised detection of exoplanets Gomez Gonzalez et al. 2018
Approximation Residual (MLAR) samples M ∈ Rn×p M = UΣV T = n i=1 σiuivT i res = M − MBT k Bk (a) (b) (a) (b) Generating a labeled dataset C+ C- Labels: y ∈ {c−, c+}
- to make predictions on new samples: Training a classifier f : X → Y ˆ y = p(c+| MLAR sample) Training a model Convolutional LSTM layer kernel=(3x3), filters=40 Convolutional LSTM layer kernel=(2x2), filters=80 Dense layer units=128 Output dense layer units=1 3d Max pooling size=(2x2x2) 3d Max pooling size=(2x2x2) ReLU activation + dropout Sigmoid activation X and y to train/test/validation sets
To integrate cutting-edge AI developments • Ensuring the use of robust statistical approaches and well-suited metrics • Open peer-review http://jakevdp.github.io/blog/2014/08/22/hacking-academia/ Open (academic) data science
The Journal of Open Source Software • The Journal of Open Research Software • Knowledge sharing • Data challenges (benchmark datasets) • Chance to transform science!!! https://joss.theoj.org/ https://openresearchsoftware.metajnl.com/ Open (academic) data science
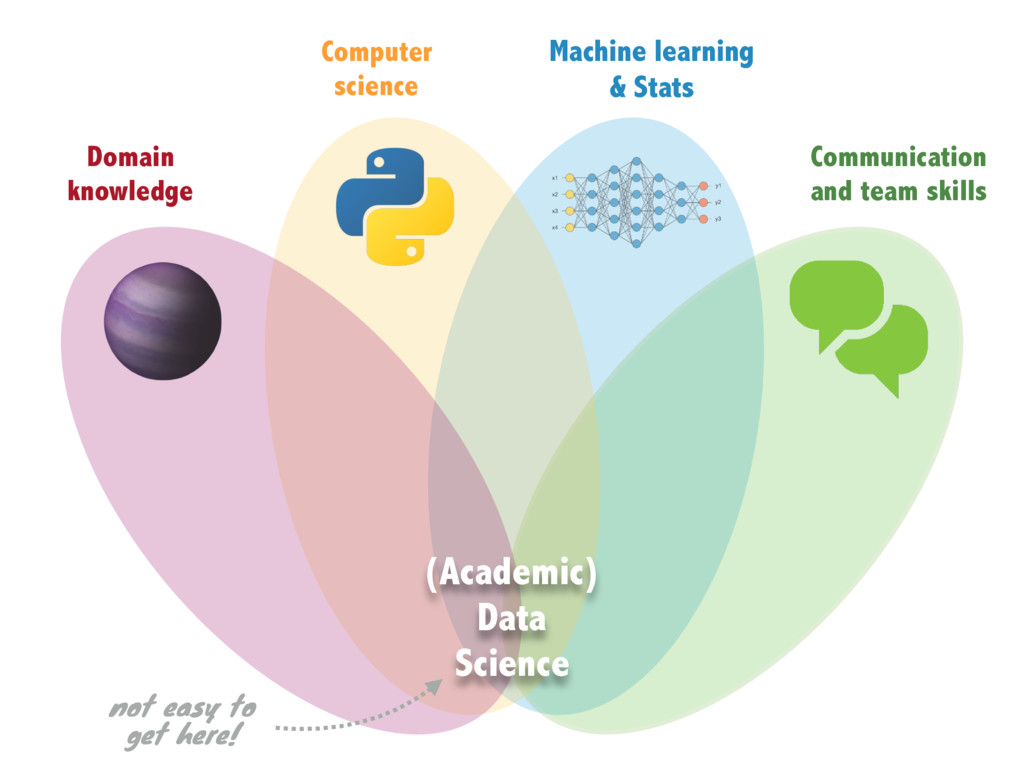
and assessment mechanisms for promotion • No clear paths/protocols for establishing collaborations (multidisciplinarity) • It is often not trivial to navigate and integrate knowledge from different disciplines • Never-ending impostor syndrome https://www.nature.com/articles/s41599-017-0039-7 http://blog.fperez.org/2013/11/an-ambitious-experiment-in-data-science.html https://www.space.com/39420-becoming-astrophysicist-keeps-getting-tougher.html Interdisciplinarity: challenges
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![¡Gracias! [email protected] carlgogo carlosalbertogomezgonzalez https://carlgogo.github.io/](https://files.speakerdeck.com/presentations/9d223467867b4d6f8a67a5f333ab4def/slide_44.jpg){kind=link}