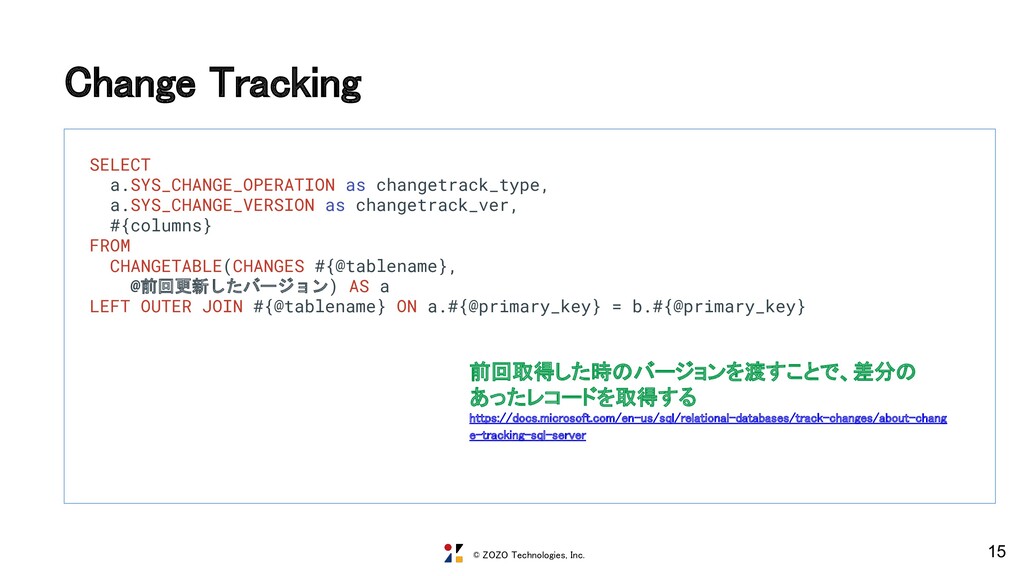
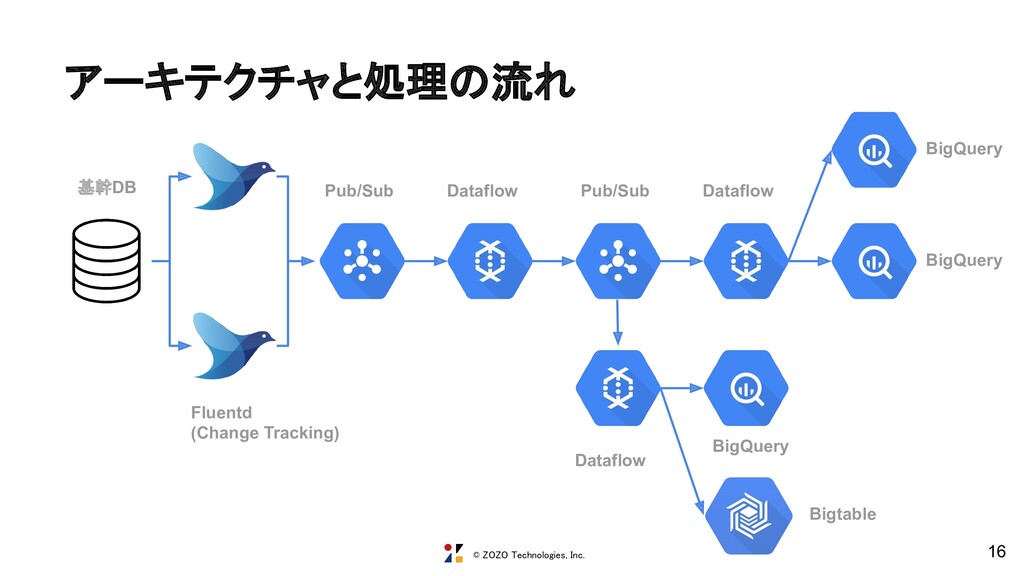
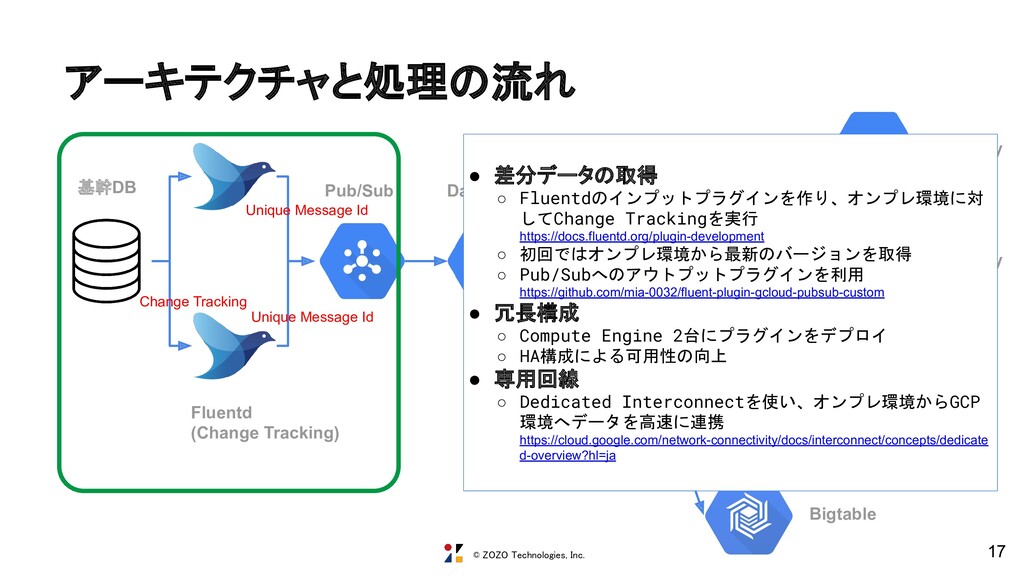
changetrack_type, a.SYS_CHANGE_VERSION as changetrack_ver, #{columns} FROM CHANGETABLE(CHANGES #{@tablename}, @前回更新したバージョン) AS a LEFT OUTER JOIN #{@tablename} ON a.#{@primary_key} = b.#{@primary_key} 前回取得した時のバージョンを渡すことで、差分の あったレコードを取得する https://docs.microsoft.com/en-us/sql/relational-databases/track-changes/about-chang e-tracking-sql-server
@last_synchronization_version bigint; SET @last_synchronization_version = #{changetrack_ver}; SET lock_timeout #{@lock_timeout} SELECT CONCAT('#{@tablename}','-',a.#{@primary_key.join(',').gsub(',', ',a.')},a.SYS_CHANGE_VERSION) as massage_unique_id, '#{@tablename}' as table_name, '#{@changetrack_interval}' as changetrack_interval, '#{Time.now.utc}' as changetrack_start_time, a.SYS_CHANGE_OPERATION as changetrack_type, a.SYS_CHANGE_VERSION as changetrack_ver, #{columns} FROM CHANGETABLE(CHANGES #{@tablename}, @last_synchronization_version) AS a LEFT OUTER JOIN #{@tablename} ON a.#{@primary_key} = b.#{@primary_key} """ メッセージIDを付与 BigQueryで最新のマスタ情報を参照できるよう にChange Trackingのバージョンも渡す
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
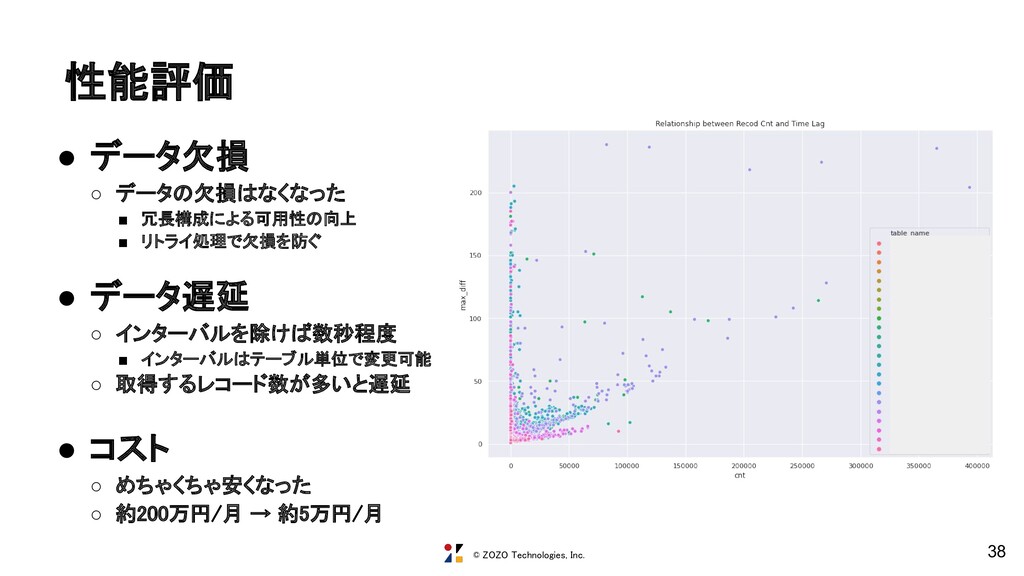{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}