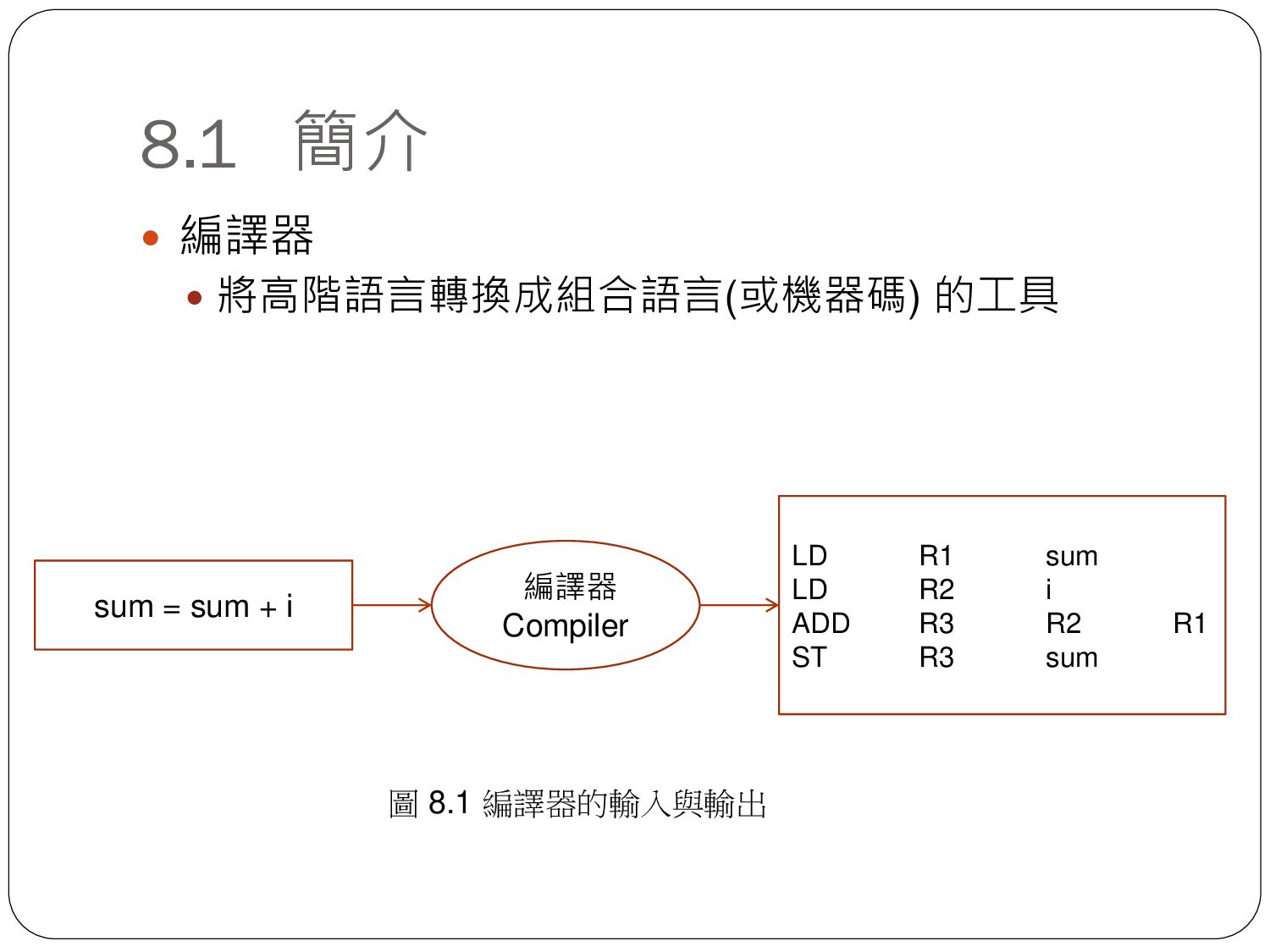
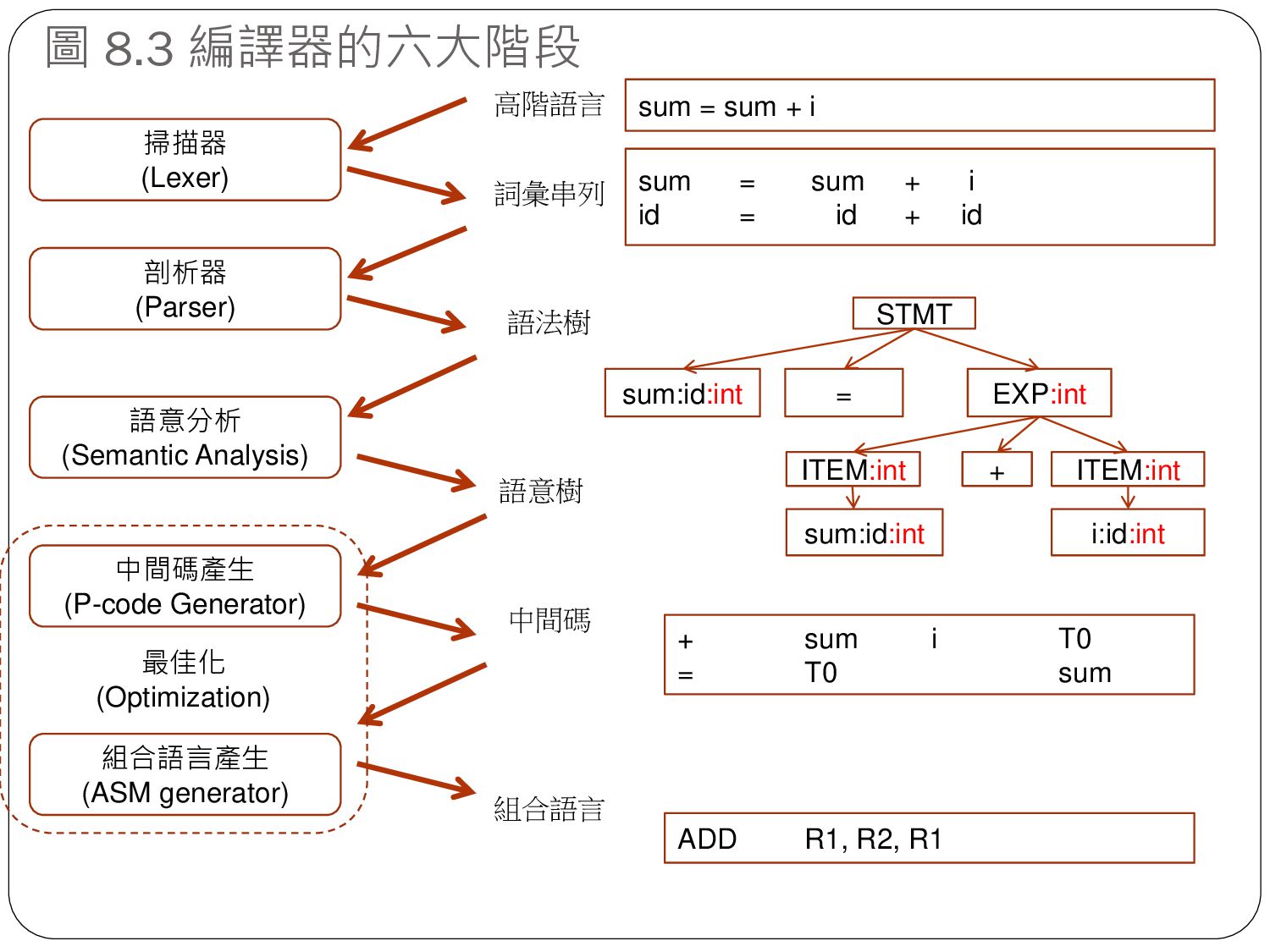
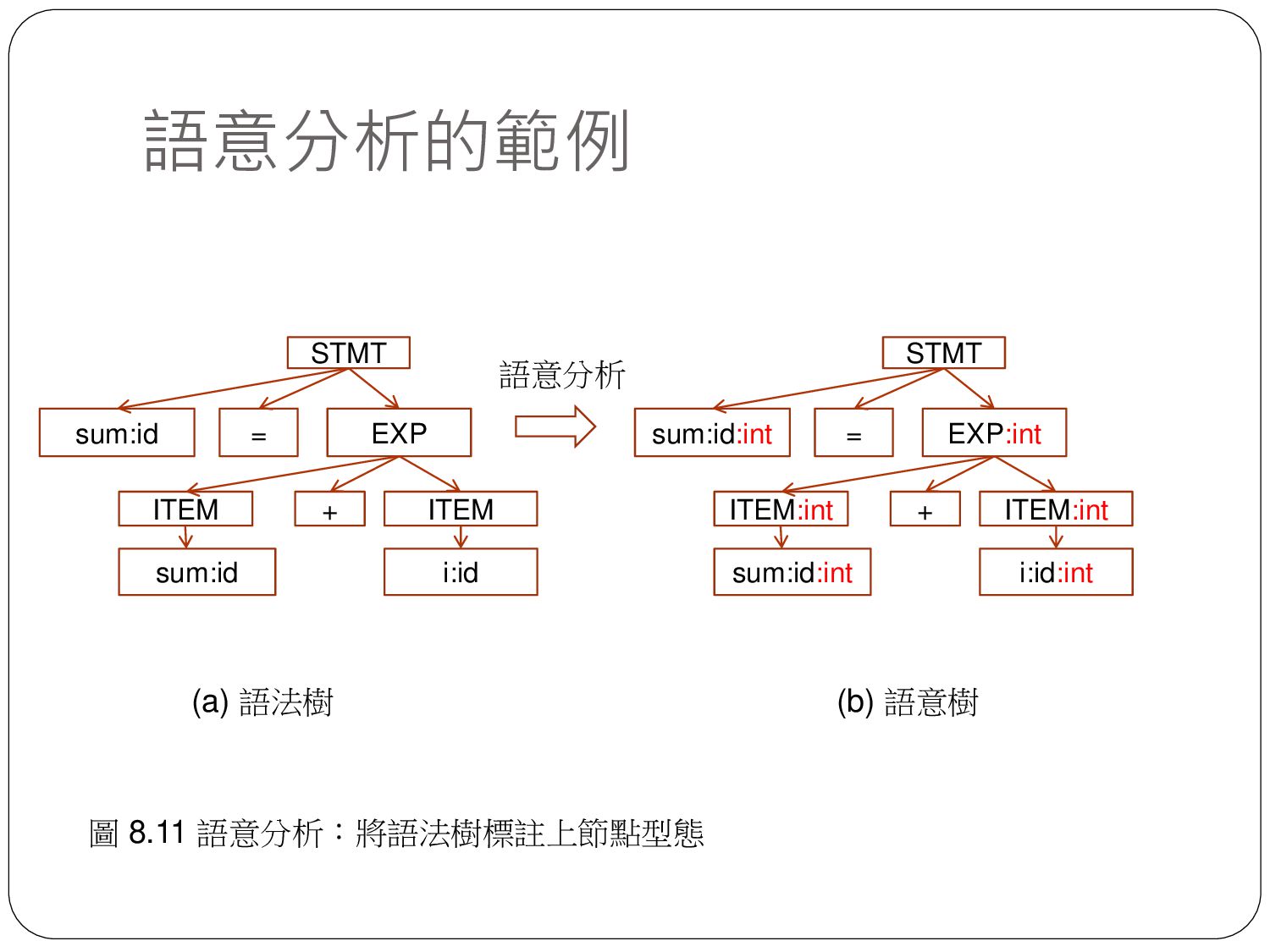
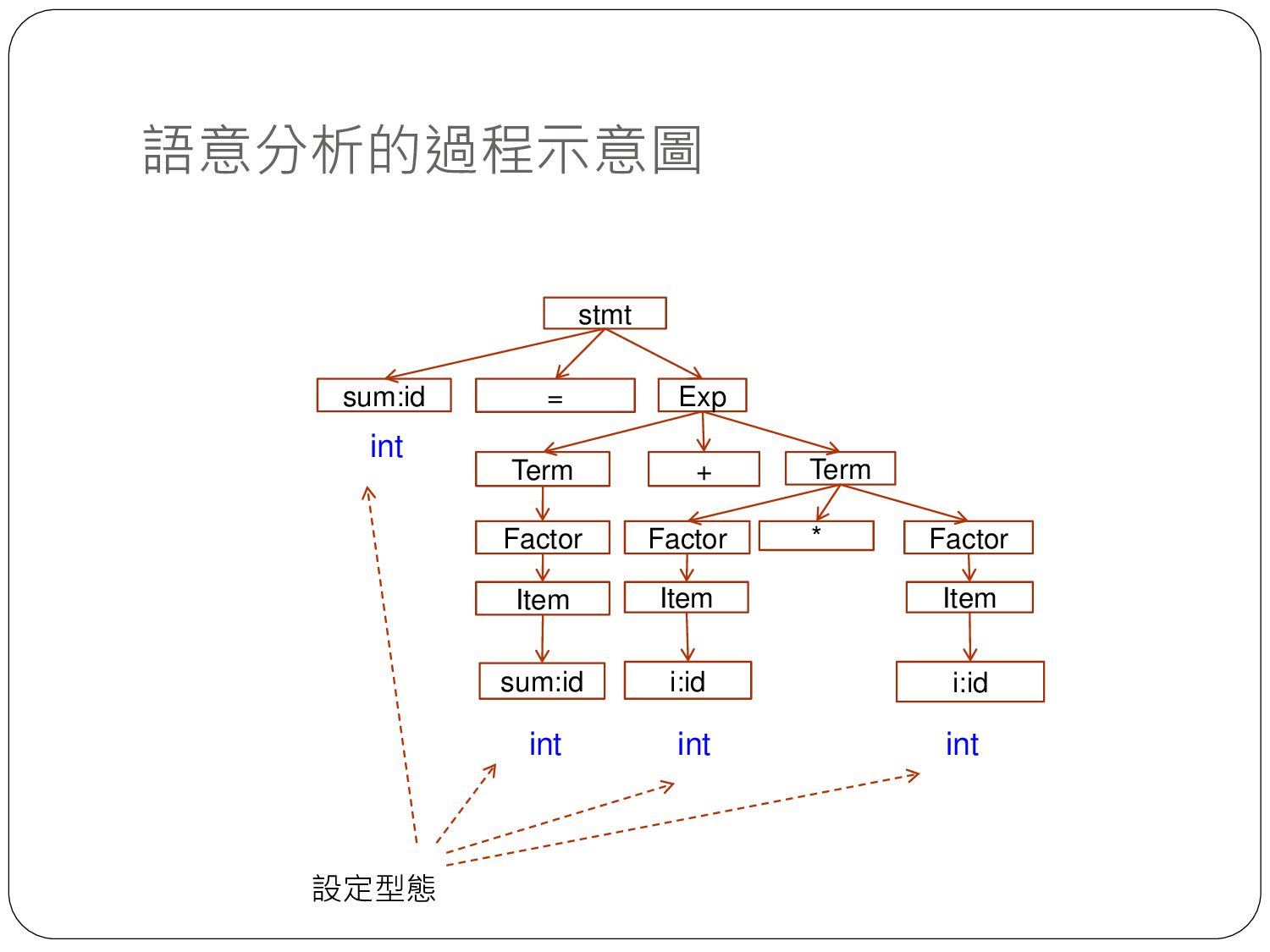
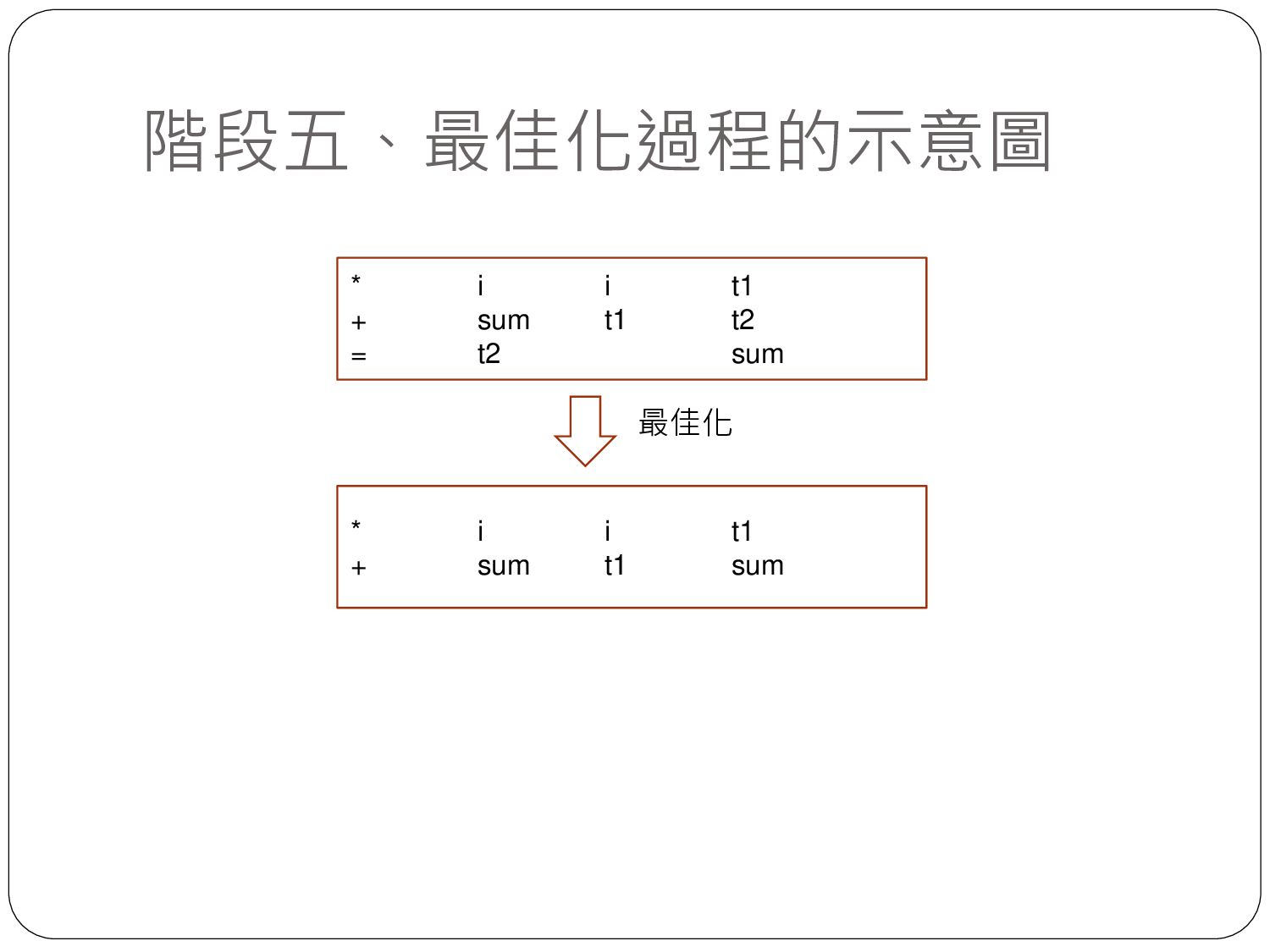
sum = sum + i sum = sum + i id = id + id EXP:int ITEM:int ITEM:int + STMT sum:id:int = + sum i T0 = T0 sum sum:id:int i:id:int 高階語言 詞彙串列 語法樹 中間碼產生 (P-code Generator) 語意樹 最佳化 (Optimization) 組合語言產生 (ASM generator) ADD R1, R2, R1 中間碼 組合語言
轉換方法 if isNext(b) { next(b); parseB(); } else if isNext(c) { next(c); parseC(); } 規則:A = b B | c C while (isNext(b)) { next(b); parseB(); } 規則:A = (b B)*
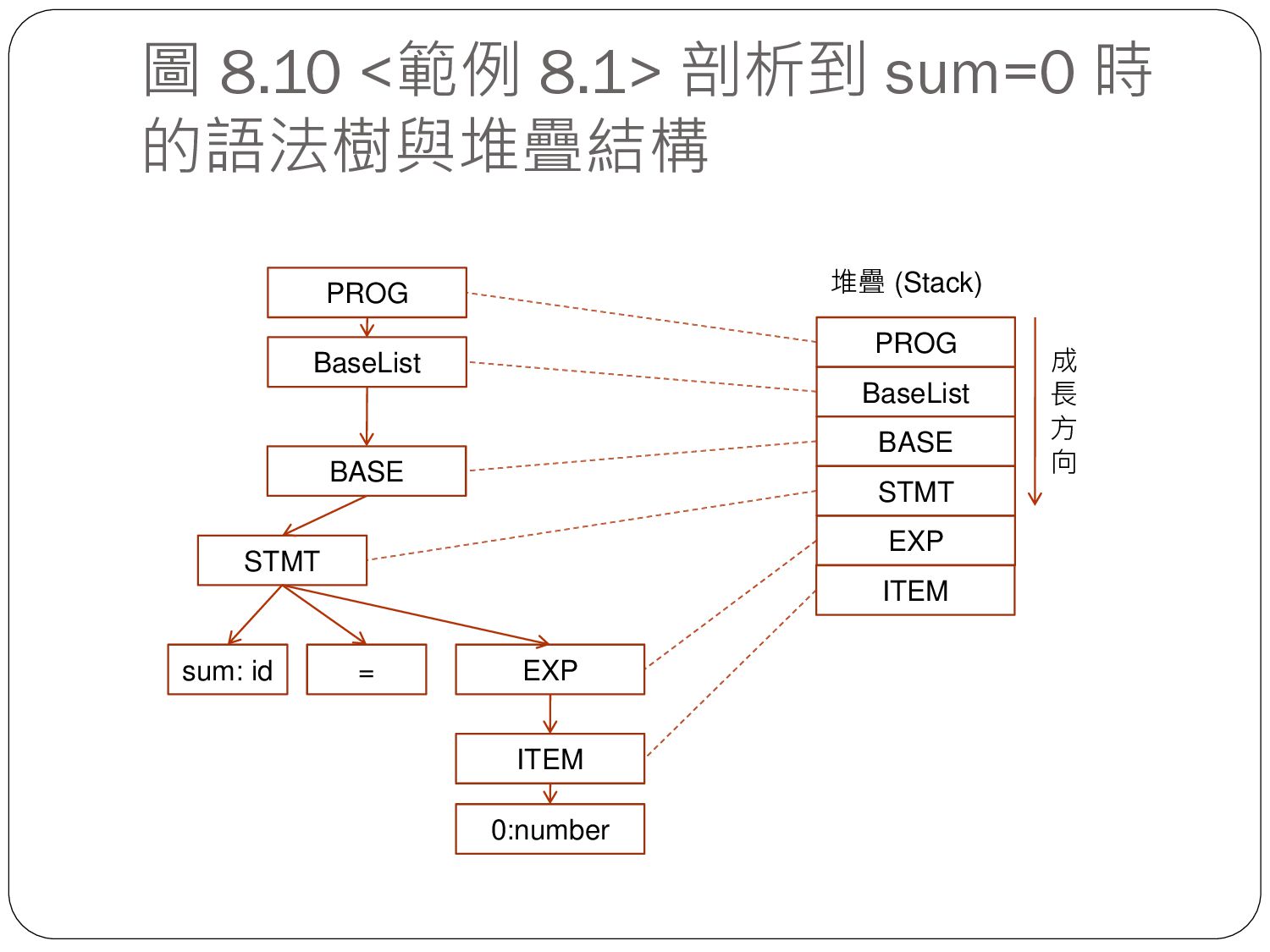
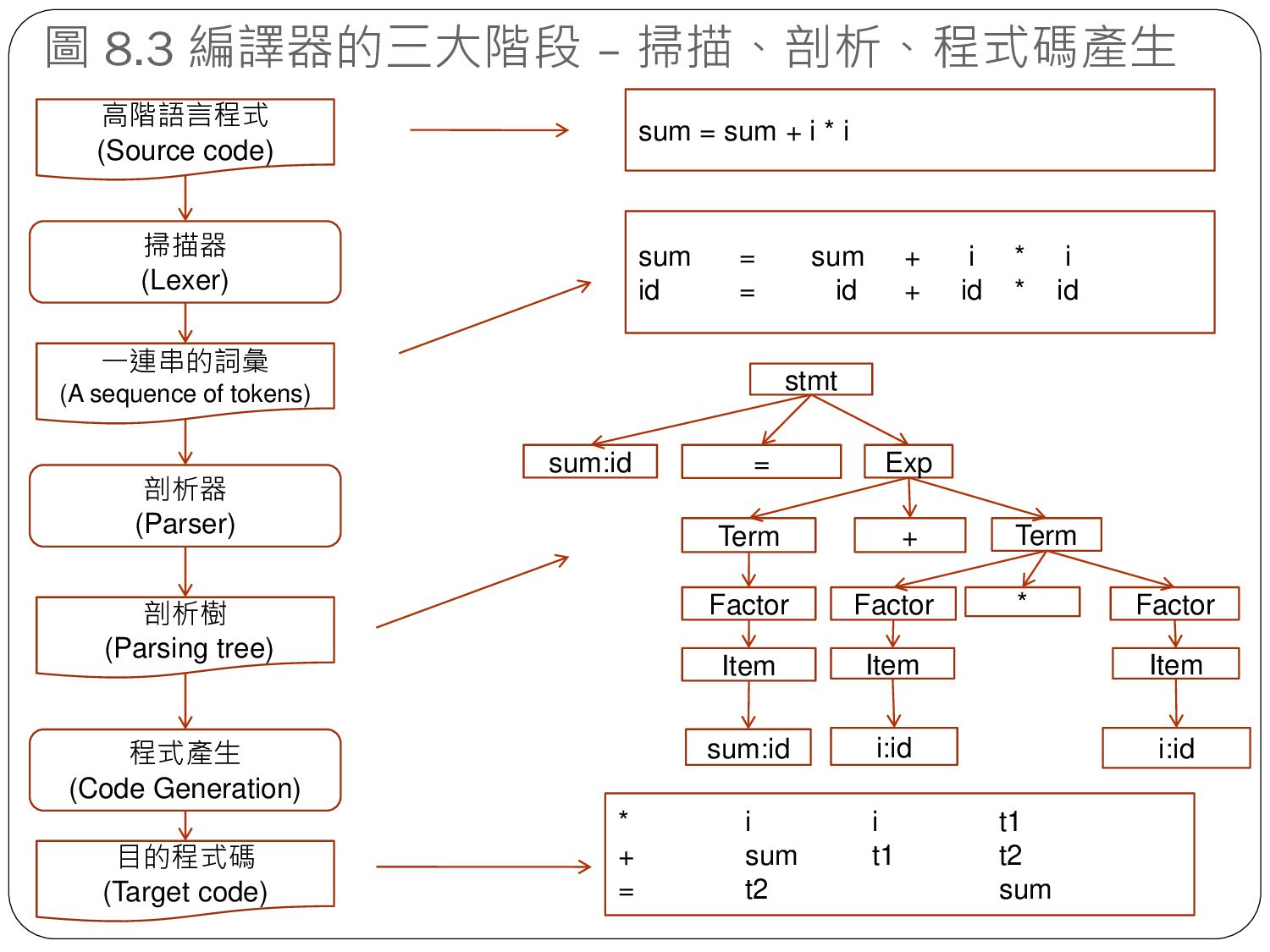
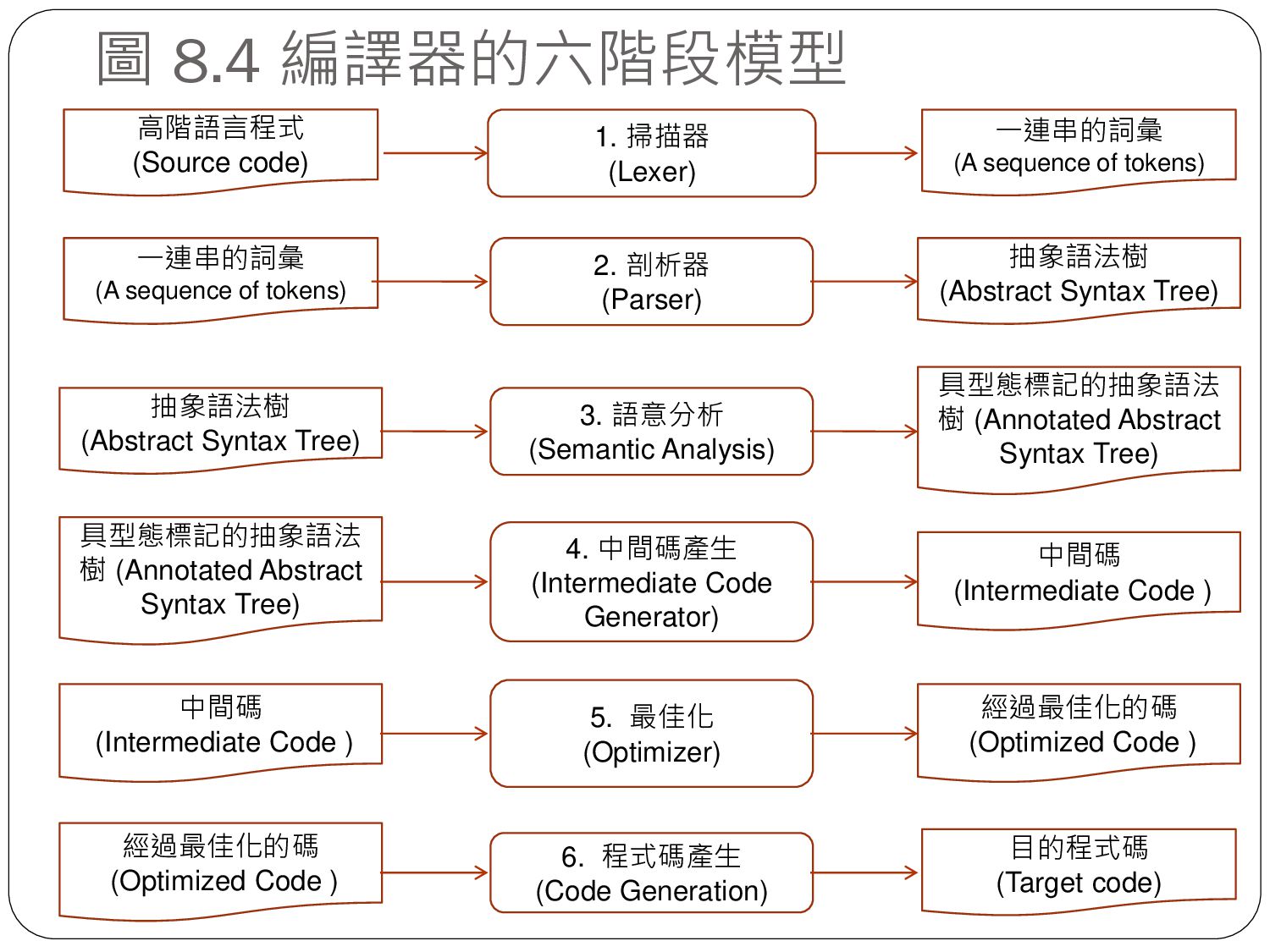
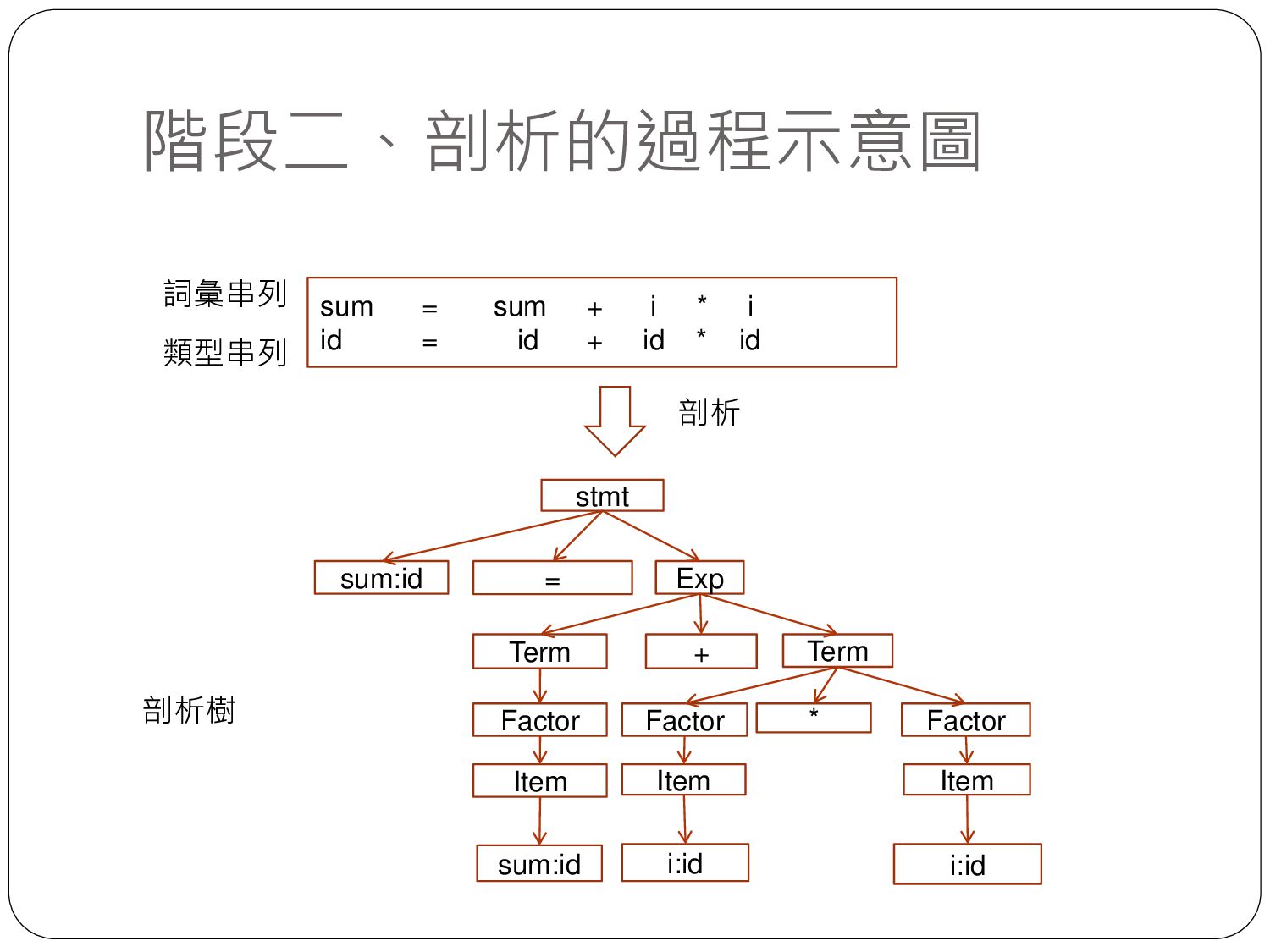
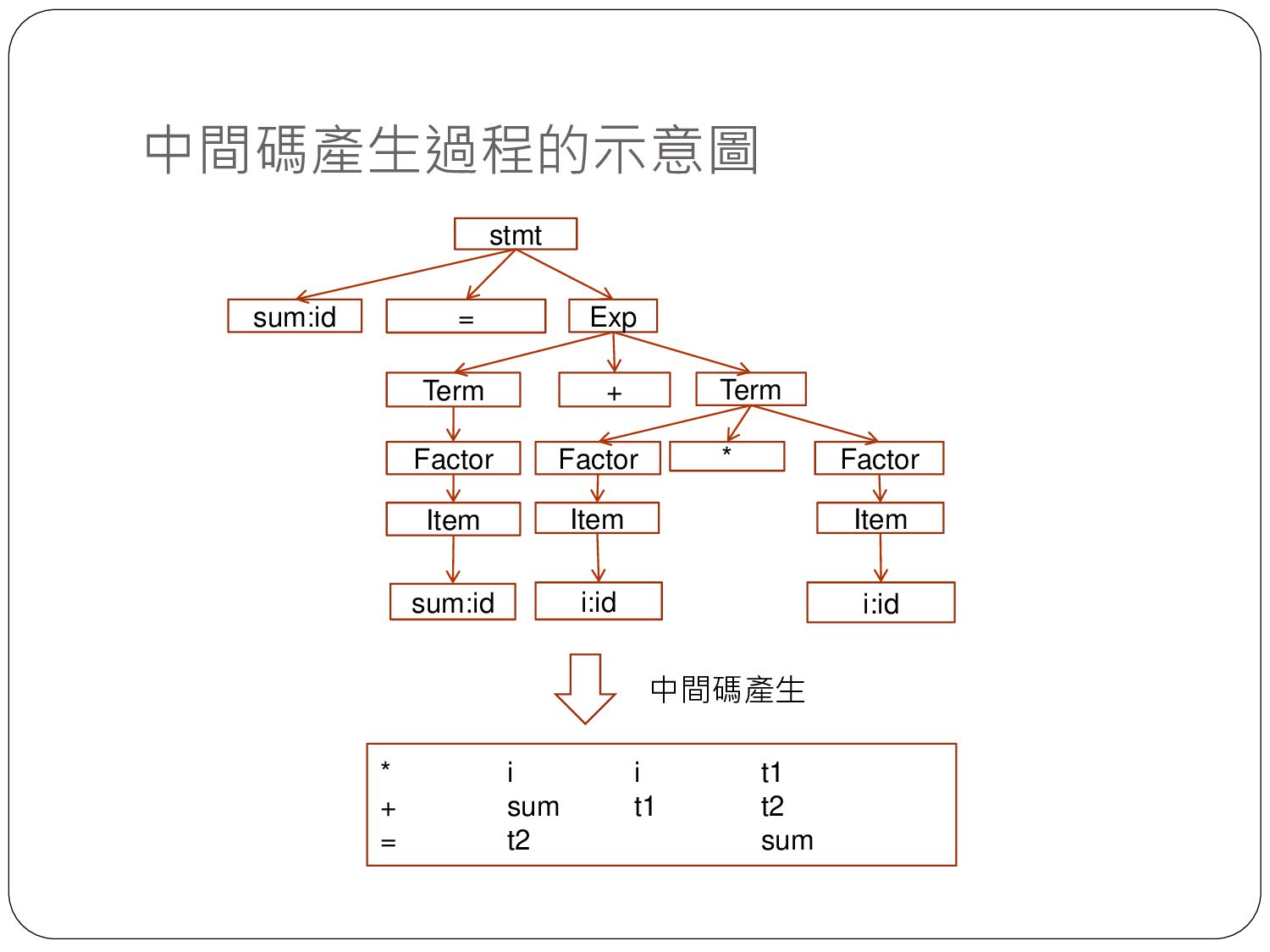
sequence of tokens) 剖析樹 (Parsing tree) 目的程式碼 (Target code) 掃描器 (Lexer) 剖析器 (Parser) 程式產生 (Code Generation) sum = sum + i * i sum = sum + i * i id = id + id * id Exp Term Term + Factor Factor Factor * i:id i:id sum:id stmt sum:id Item Item Item = * i i t1 + sum t1 t2 = t2 sum
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![以正規表達式進行掃描 整數 number = [0-9]+ 名稱 ](https://files.speakerdeck.com/presentations/3dd9128bbc564520aa7e8d6d70dacc7c/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
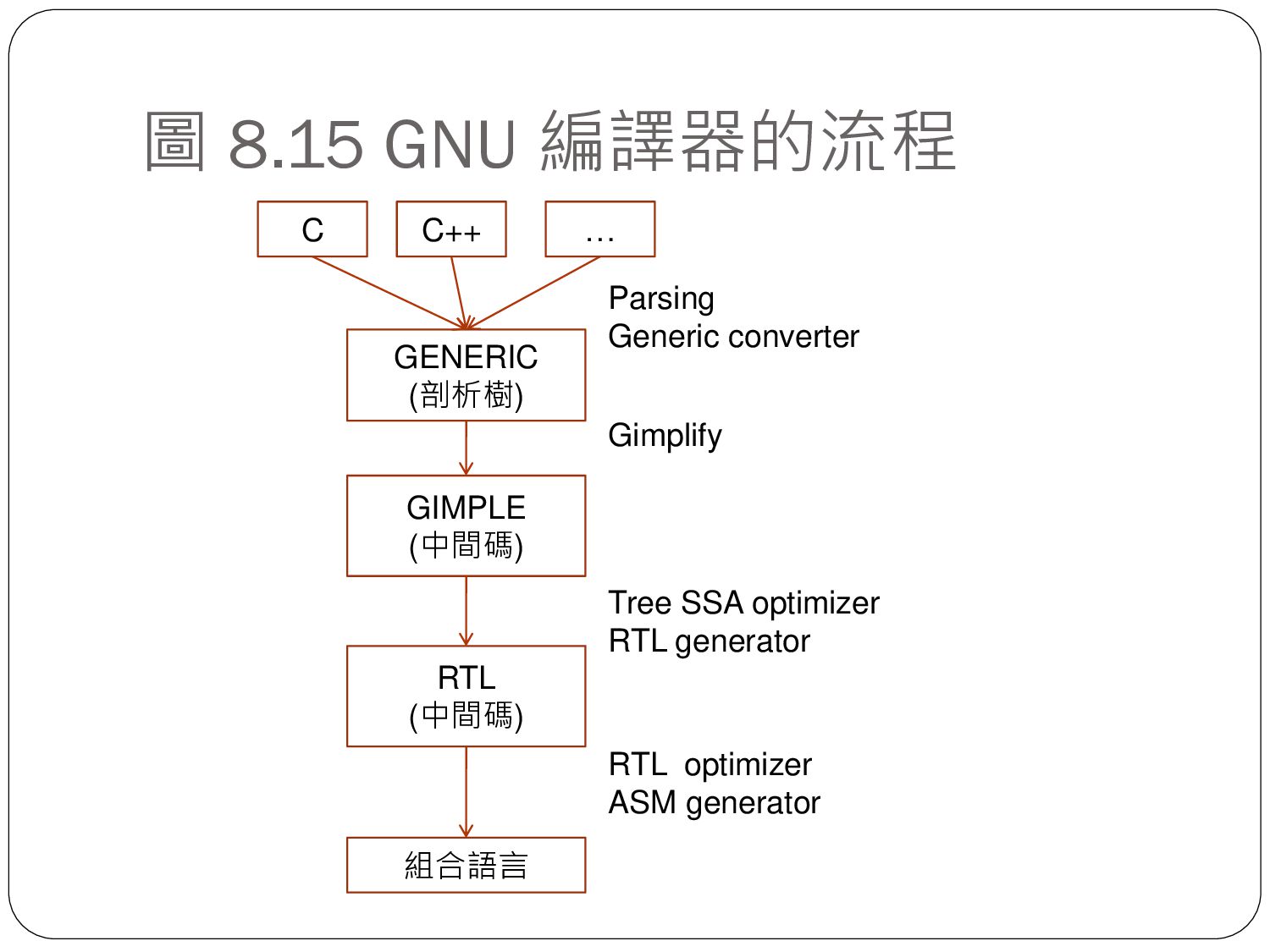{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
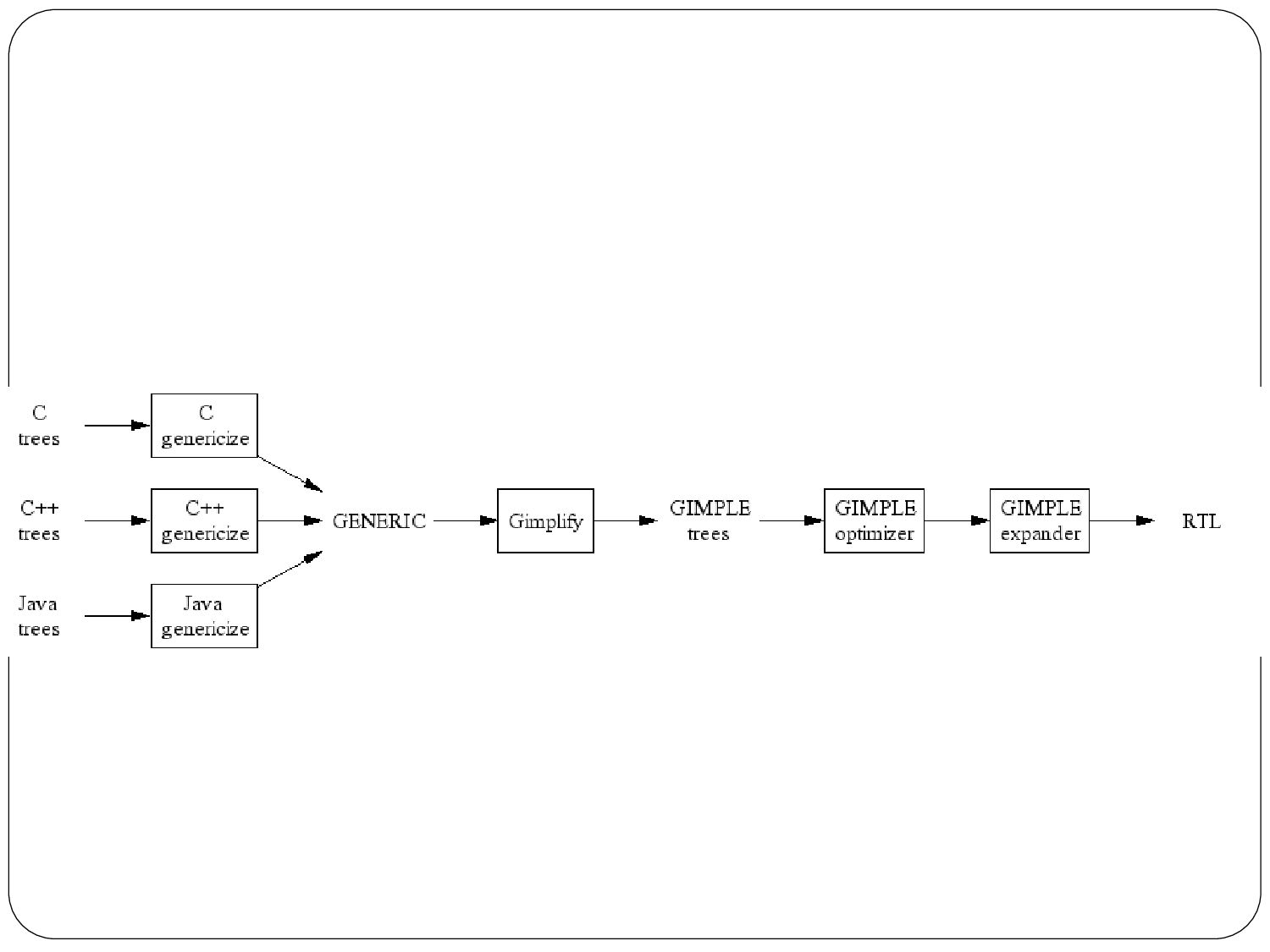{kind=link}
{kind=link}
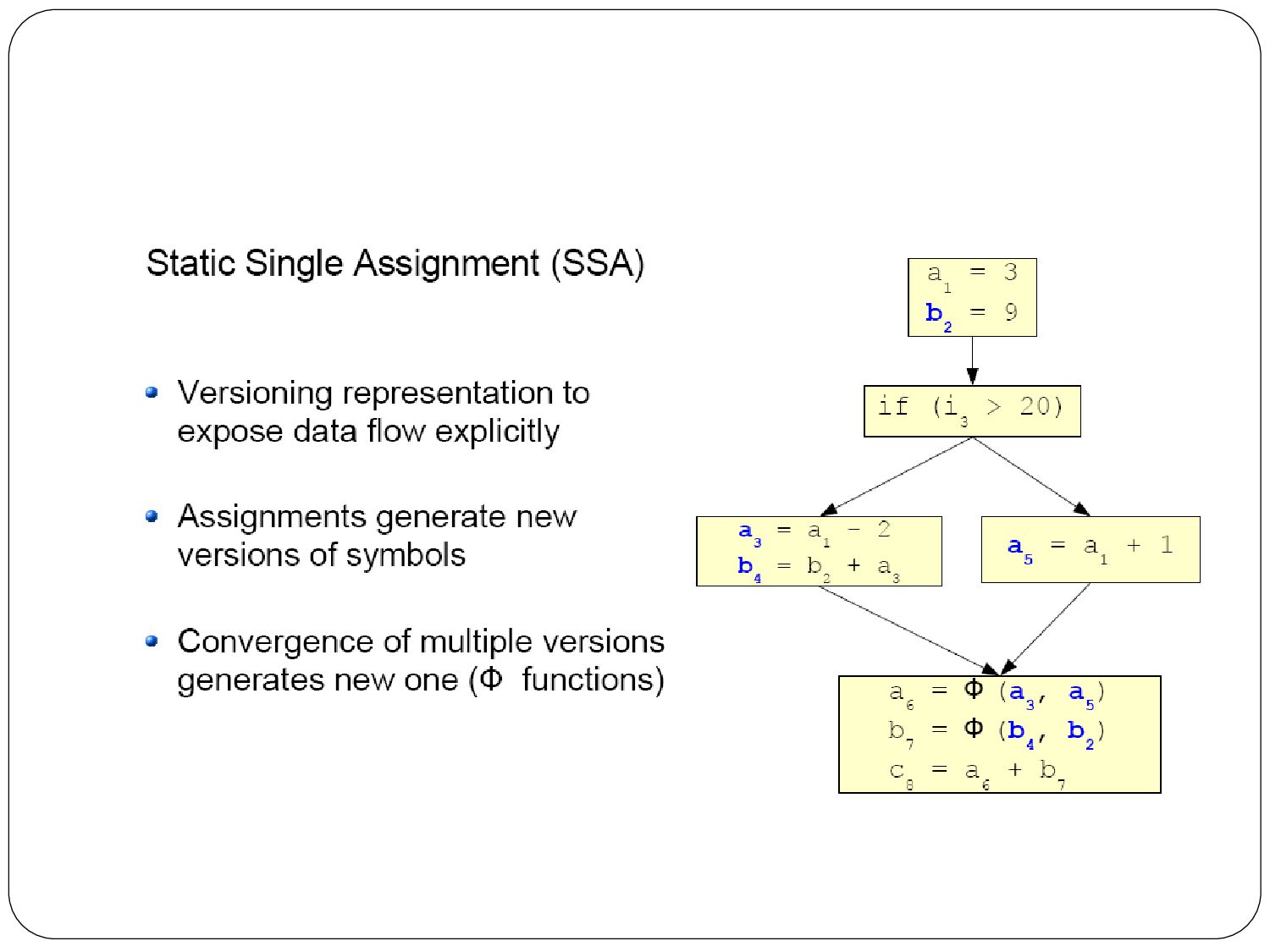{kind=link}
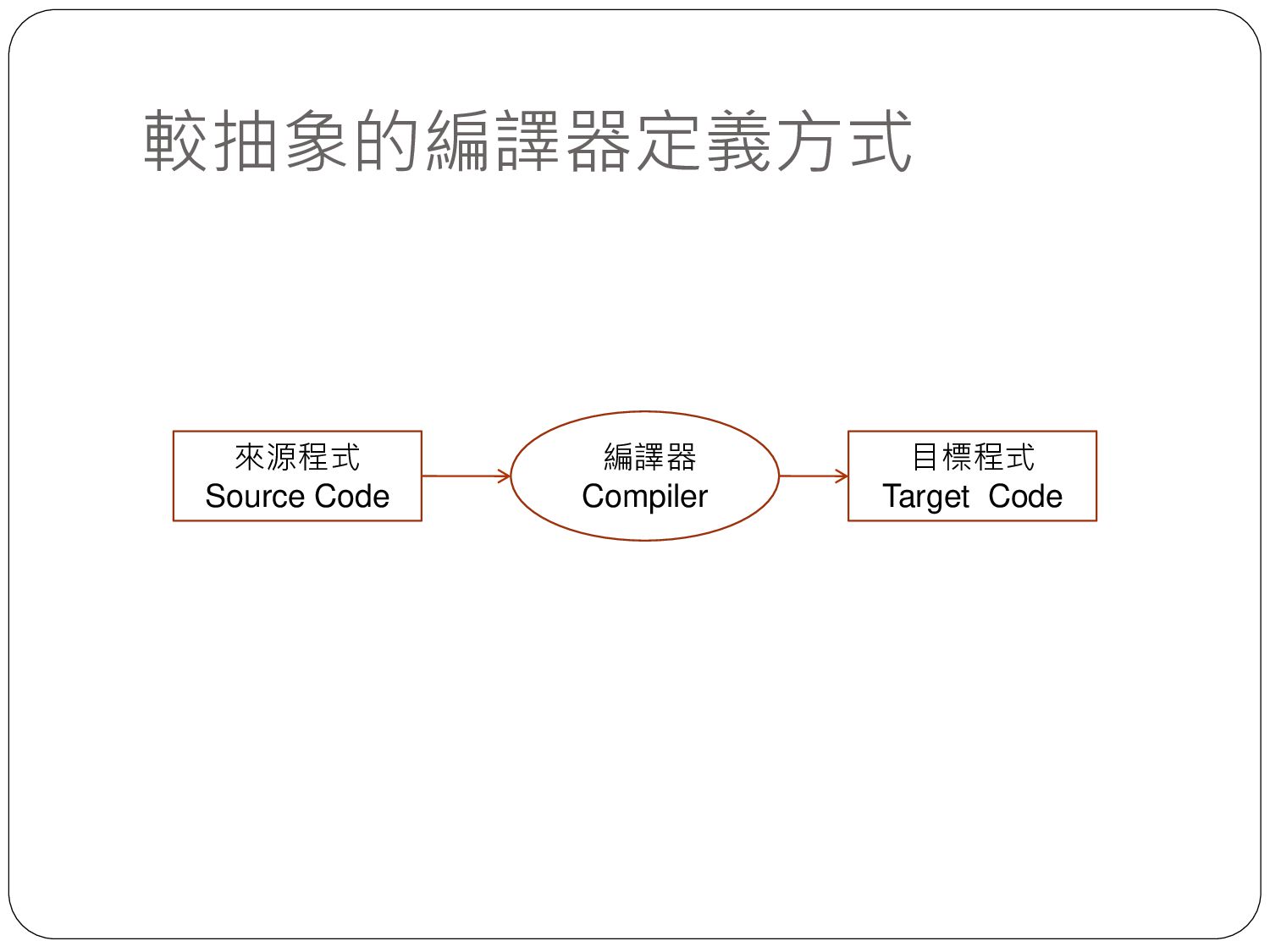{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}