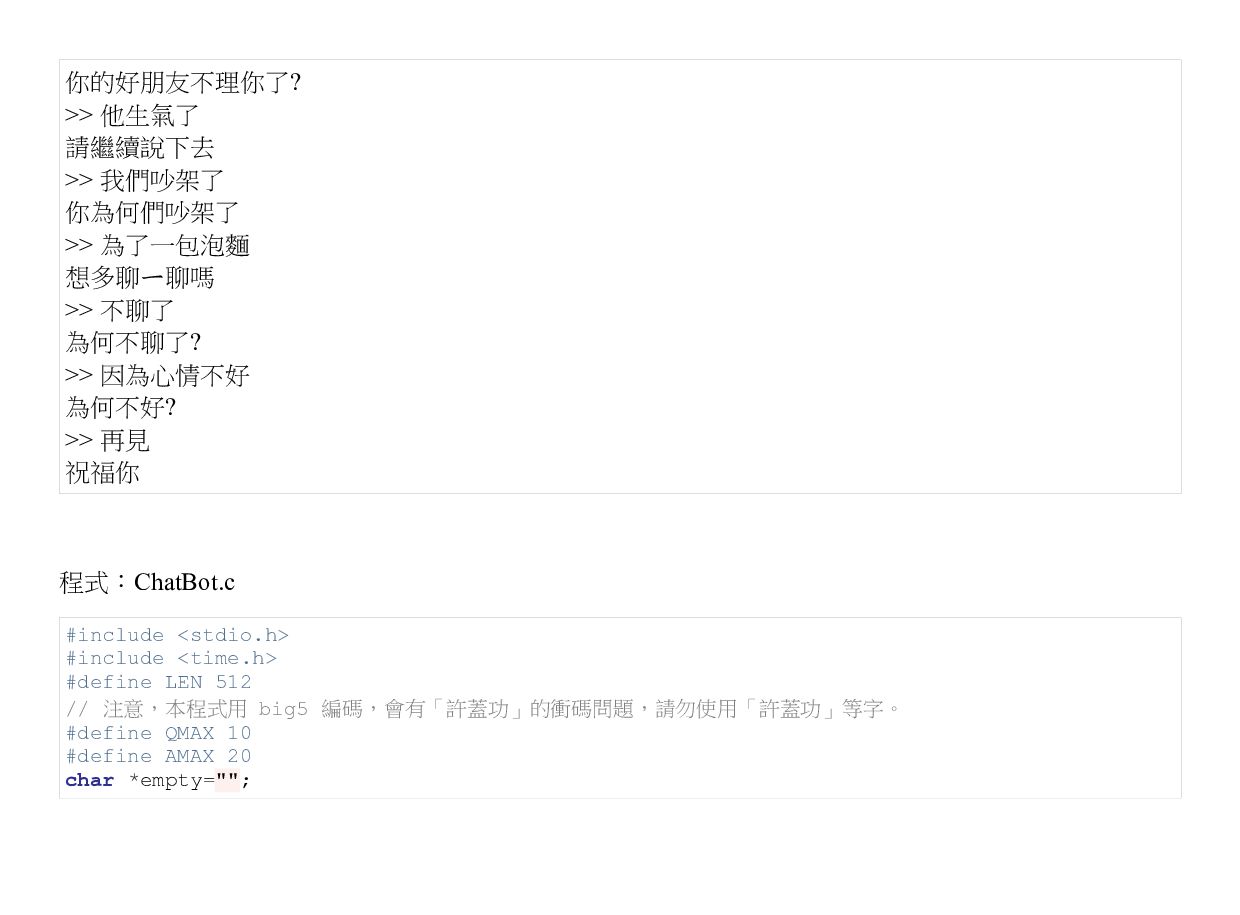
qa[]={ { .q={"謝謝", NULL}, .a={"不客氣!", NULL} }, { .q={"對不起", "抱歉", "不好意思", NULL}, .a={"別說抱歉 !", "別客氣,儘管說 !", NULL} }, { .q={"可否", "可不可以", NULL}, .a={"你確定想%s", NULL} }, { .q={"我的", NULL}, .a={"你的%s?", NULL} }, { .q={"我", NULL}, .a={"你為何%s", NULL} }, { .q={"你是", NULL}, .a={"你認為我是%s", NULL} }, { .q={"認為", "以為", NULL}, .a={"為何說%s?", NULL} }, { .q={"感覺", NULL}, .a={"常有這種感覺嗎?", NULL} }, { .q={"為何不", NULL}, .a={"你希望我%s", NULL} }, { .q={"是否", NULL}, .a={"為何想知道是否%s", NULL} }, { .q={"不能", NULL}, .a={"為何不能%s?", "你試過了嗎?", NULL} }, { .q={"我是", NULL}, .a={"你好,久仰久仰!", NULL} }, { .q={"甚麼","什麼","何時","誰","哪裡","如何","為何","因何", NULL}, .a={"為何這樣問?","為何你對這問題有興趣?","你認為答案是甚麼呢?", NULL} }, { .q={"原因", NULL}, .a={"這是真正的原因嗎?", "這是真正的原因嗎?", NULL} }, { .q={"理由", NULL}, .a={"這說明了甚麼呢?", "還有其他理由嗎?", NULL} }, { .q={"你好","嗨","您好", NULL}, .a={"你好,有甚麼問題嗎?", NULL} }, { .q={"或者", NULL}, .a={"你好像不太確定?", NULL} }, { .q={"你是", NULL}, .a={"你認為我是%s", NULL} }, { .q={"不曉得","不知道", NULL}, .a={"為何不知道?","在想想看,有沒有甚麼可能性?", NULL} },
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![E =T | T [+-*/] E T = [0-9] |](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![else { printf("%d:%c ", i, s[i]); i++; } } }](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_64.jpg){kind=link}
{kind=link}
{kind=link}
![wcssbrk(str1,aeiou)=00403032 wchar_t str2[20]; wcscpy(str2, str1); printf("str2=%ls\n", str2); // str2=Hi!你好 printf("wcscmp(str1,str2)=%d\n",](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![int len = size/sizeof(wchar_t); fread(text, sizeof(wchar_t), len, file); fclose(file); text[len]](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_73.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![程式:escan.c10 #include <stdio.h> char text[] = "Mr. Jamie is a](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_81.jpg){kind=link}
{kind=link}
{kind=link}
![牛肉面 牛肉面 [niu2 rou4 mian4] /beef noodle soup/ 牛膝 牛膝](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_84.jpg){kind=link}
![#define LEN 512 int main(int argc, char *argv[]) { uinit();](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_85.jpg){kind=link}
{kind=link}
![line=牛磺酸 牛磺酸 [niu2 huang2 suan1] /taurine/ tc=牛磺酸 sc=牛磺酸 pr=niu2 huang2](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_87.jpg){kind=link}
![line=牛蒡 牛蒡 [niu2 pang2] /burdock/ tc=牛蒡 sc=牛蒡 pr=niu2 pang2 en=burdock](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_88.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![scan("%[ ]"); } int N() { next("%[a-z] ", "|dog|bone|cat|"); printf("N(%s)",](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_98.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![char *isList[][2] // 詞彙與標記的關係串列 = {{"敲", "knock"}, {"爸爸", "people"}, {"釘子",](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_113.jpg){kind=link}
{kind=link}
![for (i=0; i<strlen(str); ) { int wi = wordFind(&str[i]); char](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_115.jpg){kind=link}
![} } return NIL; } // 印出詞彙陣列 int wordsPrint(char *words[])](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_116.jpg){kind=link}
![assert(fills[si] < FILLS); slots[si][fills[si]++] = tokens[ti]; } } } for](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_117.jpg){kind=link}
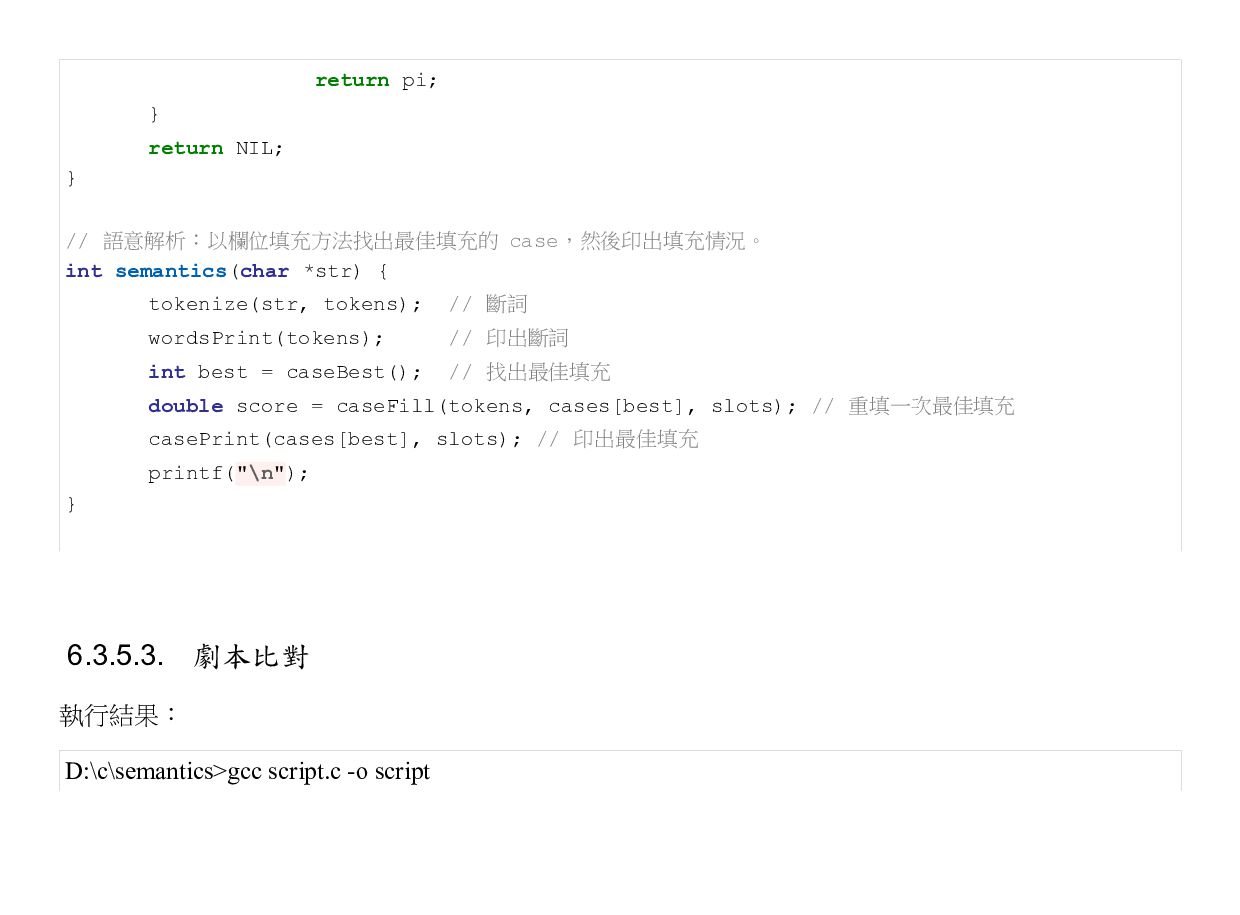
![} // 印出填充的情況 int casePrint(char *fields[SLOTS], char *slots[SLOTS][FILLS]) { int](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_118.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
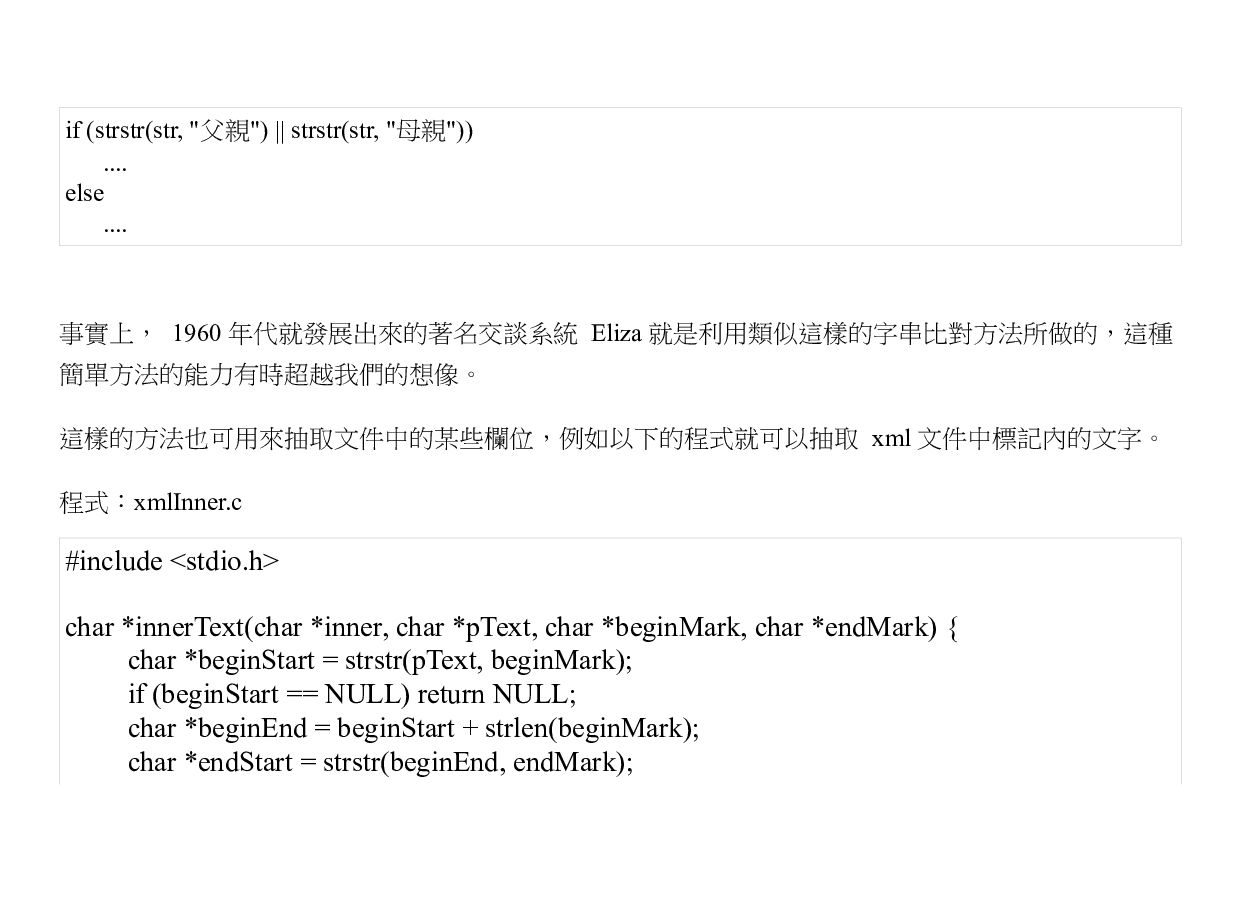
![// 劇本比對:使用格變語法 char *sentences[] = {"約翰與瑪莉是大學的同班同學", "在大三時約翰愛上了瑪莉", "畢業後他們就結婚了", "並且生了一個小男孩麥克", "約翰畢業後進入一家大公司工作",](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_122.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![語法 正則表達式 範例 整數 [0-9]+ 3704 有小數點的實數 [0-9]+\.[0-9]+ 7.93 英文詞彙](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_129.jpg){kind=link}
{kind=link}
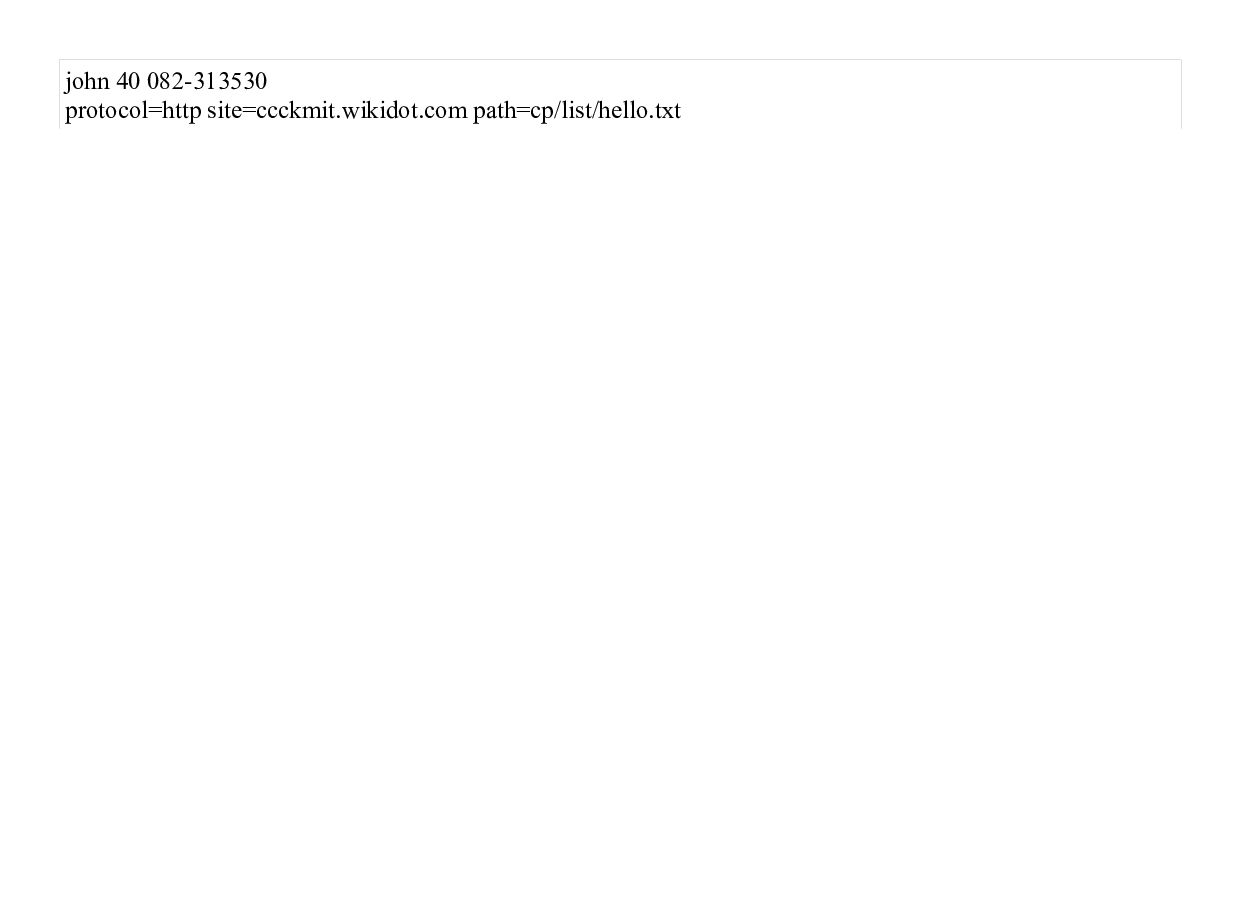
![printf("%s %d %s\n", name, age, tel); sscanf("name:john age:40 tel:082-313530", "%*[^:]:%s](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_131.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![typedef struct { char *q[QMAX]; char *a[AMAX]; } QA; QA](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_136.jpg){kind=link}
{kind=link}
![target[len] = '\0'; sprintf(target+len, "%s%s", to, match+strlen(from)); } } void](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_138.jpg){kind=link}
![for (acount = 0; qa[i].a[acount] != NULL; acount++); ai =](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_139.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![[X] : 代表 noun phrase (Y) : 代表 adverbial phrase](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_143.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![if (strncmp(word, words[i], strlen(words[i]))==0) return i; } return NIL; }](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_153.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
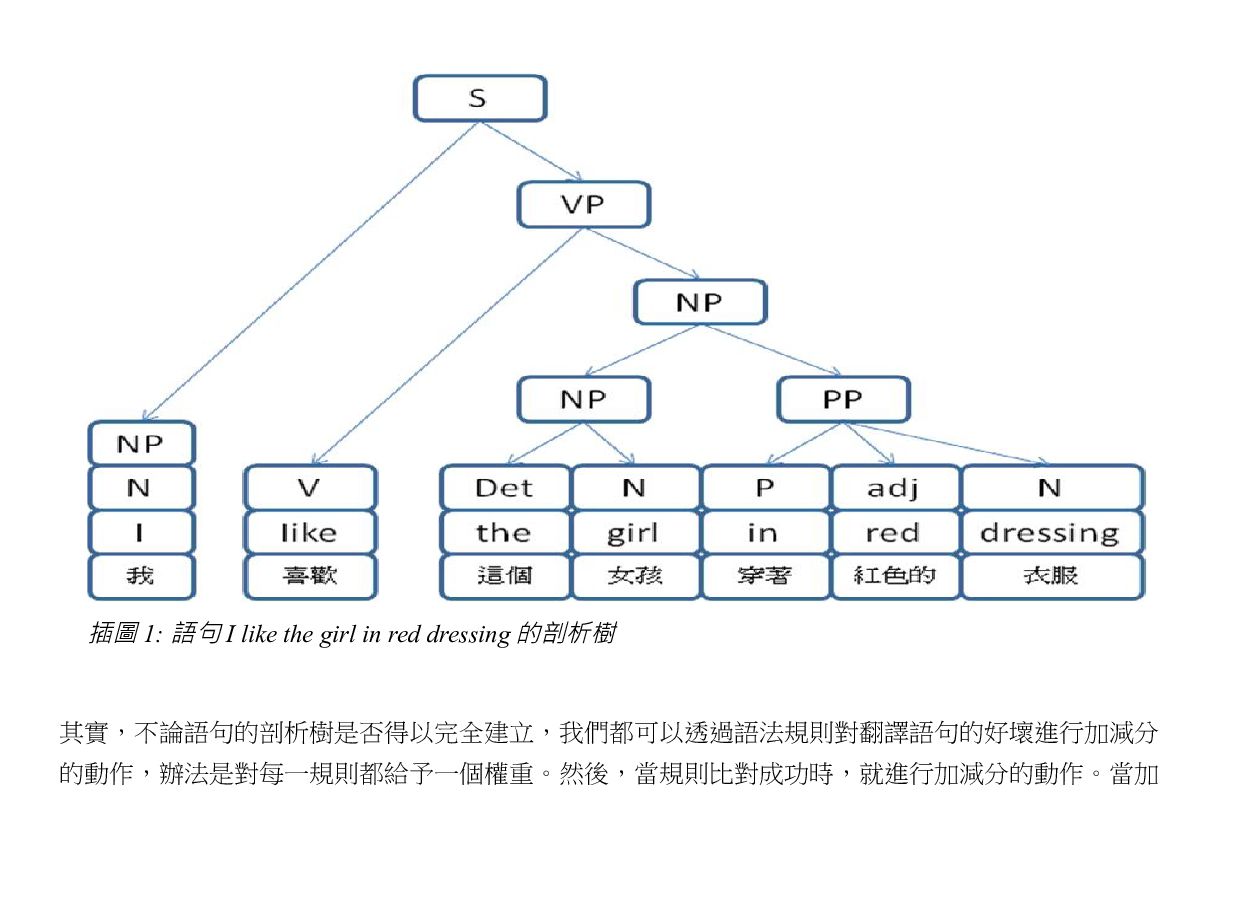{kind=link}
{kind=link}
{kind=link}
{kind=link}
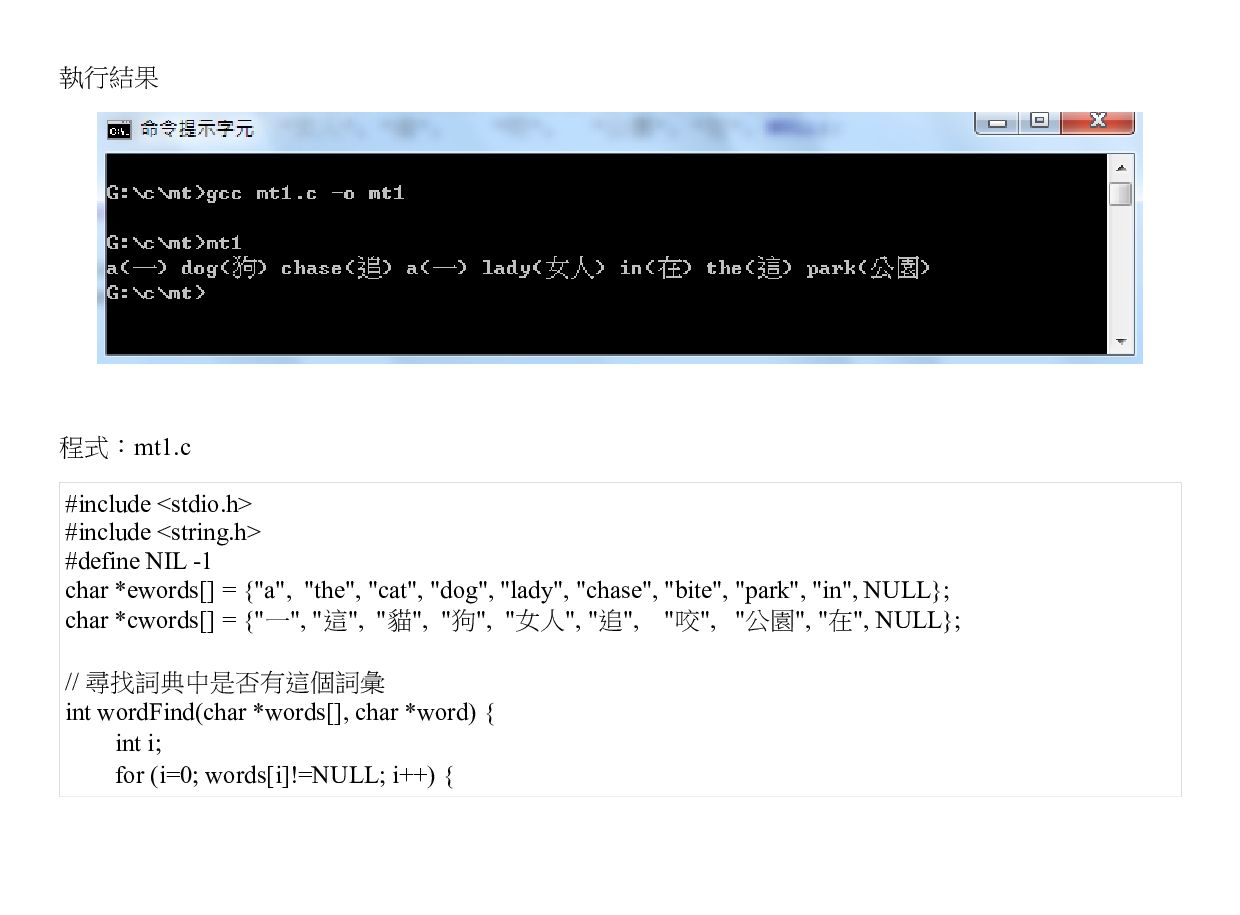
![原文:a dog chase a lady in the park 翻譯:a(一)[隻]dog(狗)in(在)the(這)[個]park(公園)chase(追)a(一)[個]lady(女人) 程式碼:mt2.c](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_162.jpg){kind=link}
![struct _Node *childs[NODES]; int childCount; } Node; Node nodes[1000]; int](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_163.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![char *people[] = {"lady", "man", NULL}; char *ewords[] = {"a",](https://files.speakerdeck.com/presentations/ab9420b0217e424f8d22da1615896e3b/slide_167.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
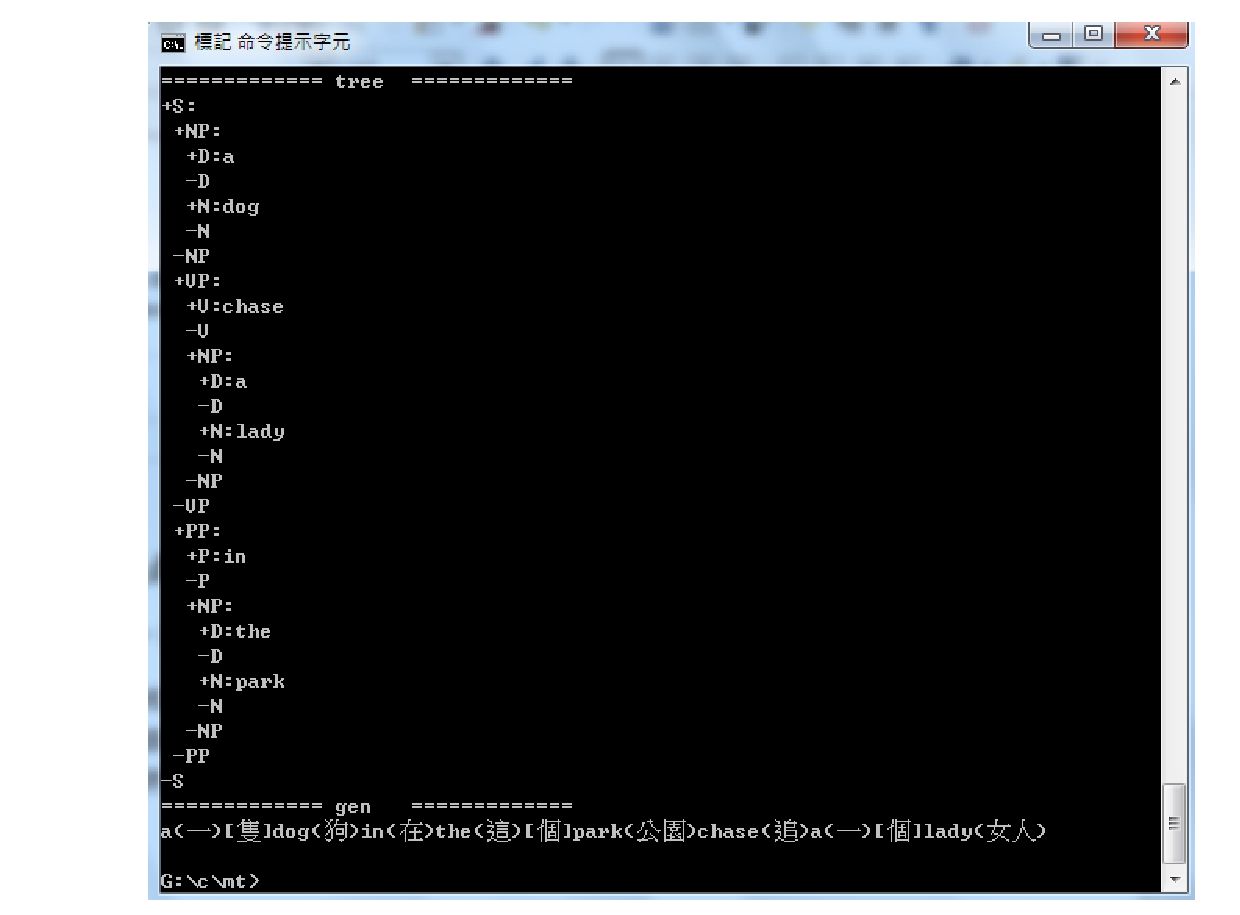{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
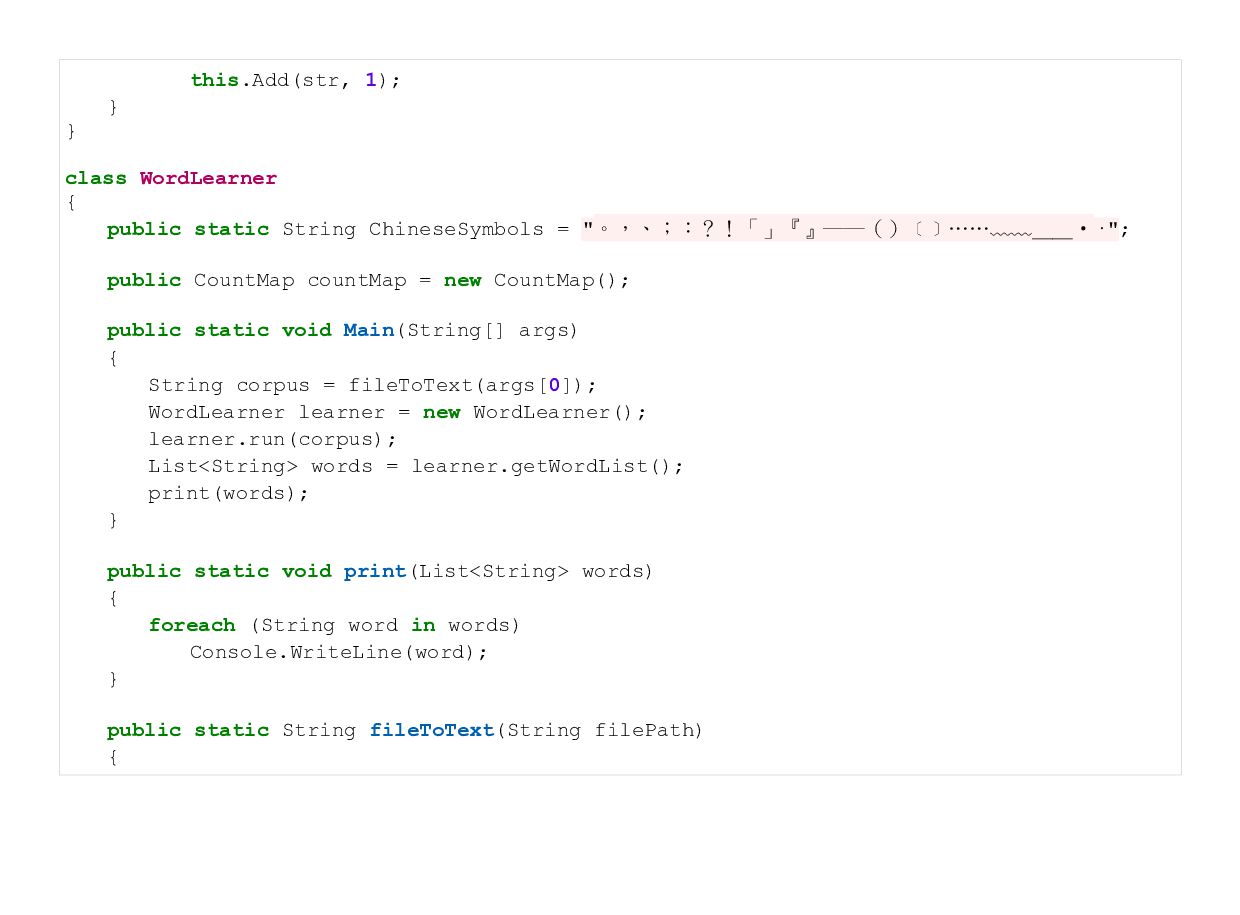{kind=link}
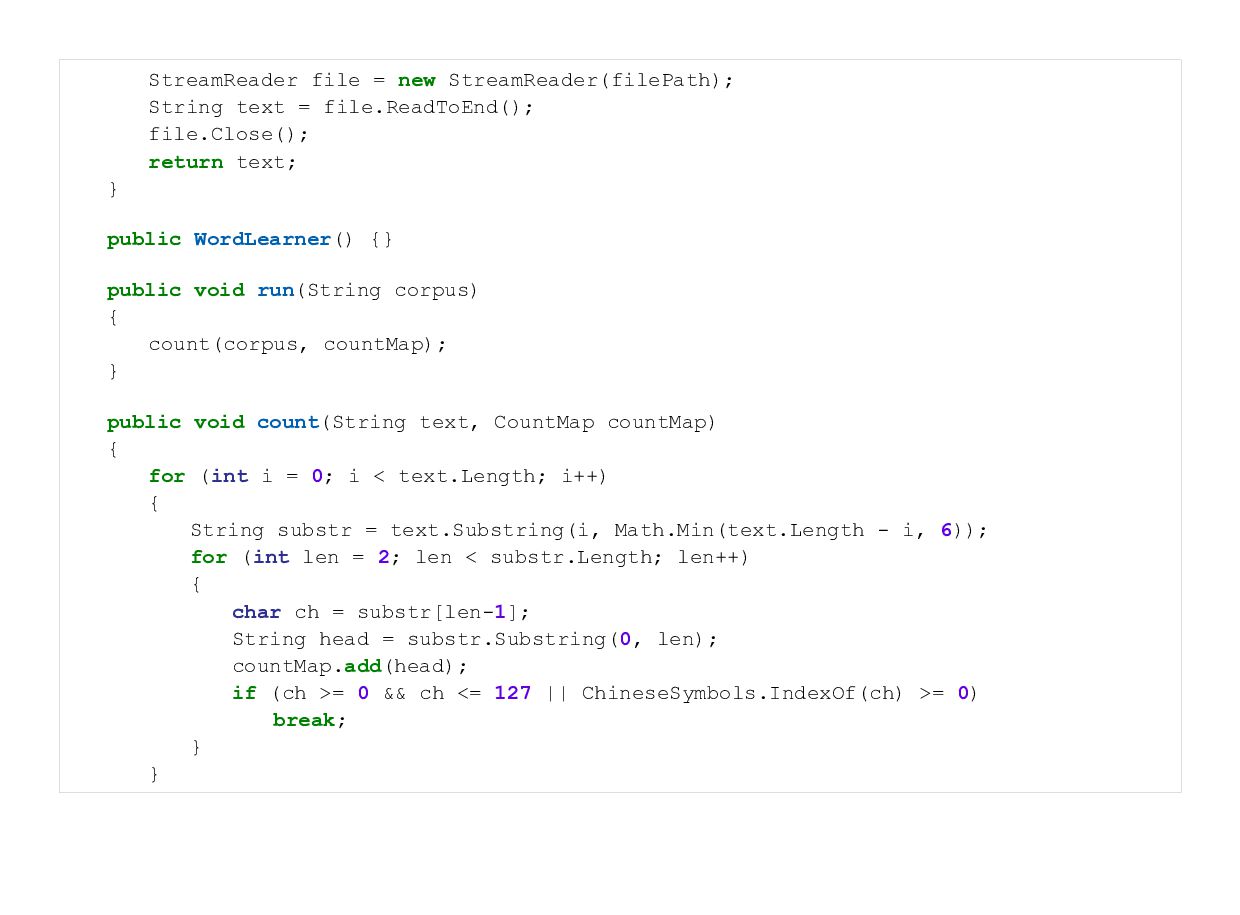{kind=link}
{kind=link}