Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
「さくらのVPS」のインフラと運用 / How we operate the Infrastr...
Search
chamaharun
October 08, 2019
Technology
2.5k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
「さくらのVPS」のインフラと運用 / How we operate the Infrastructure of Sakura VPS
「さくらの夕べ ヤンジェネバトル」でお話した内容です。
https://connpass.com/event/146504/
chamaharun
October 08, 2019
More Decks by chamaharun
See All by chamaharun
さくらのVPSを支える技術とこれから / Technology behind SAKURA VPS and the future
chamaharun
5
6.6k
Let's Encryptで始めるSSL証明書
chamaharun
1
330
Other Decks in Technology
See All in Technology
AI x 開発生産性を取り巻く予算戦略と投資対効果
i35_267
7
2.7k
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
510
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
120
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
320
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
20260720_クラウド女子会×PyLadiesTokyoコラボ Amazon Bedrock ハンズオン用資料
yuuka51
1
110
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
220
AICoEでAIネイティブ組織への進化
yukiogawa
0
210
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.2k
[Droidcon Orlando '26] The Android Lens: Applying Mobile Forensics to AI Performance
amanda_hinchman
1
100
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
290
文字起こし基盤の信頼性
abnoumaru
0
100
Featured
See All Featured
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
Raft: Consensus for Rubyists
vanstee
141
7.6k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Prompt Engineering for Job Search
mfonobong
0
380
KATA
mclloyd
PRO
35
15k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Optimizing for Happiness
mojombo
378
71k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
How to Talk to Developers About Accessibility
jct
2
420
Deep Space Network (abreviated)
tonyrice
0
230
Unsuck your backbone
ammeep
672
58k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Transcript
© SAKURA Internet Inc. 「さくらのVPS」のインフラと運⽤ @さくらの⼣べ ヤンジェネバトル さくらインターネット株式会社 技術本部 ⼩林
巧
⾃⼰紹介
⼩林 巧 (こばやし たくみ) •
[email protected]
@chamaharun • 2017年4⽉⼊社 新卒3年⽬
所属 • 技術本部 ミドルウェアグループ • 仮想化基盤チーム VPSインフラ担当 経歴 • 2014/2 〜 DCOPチーム アルバイト • 2017/6 〜 SVOPチーム • 2018/3 〜 仮想化基盤チーム 著書 • 技術評論社 イラスト図解でよくわかる ITインフラの基礎知識(共著) • 技術評論社 Software Design 2018年7⽉号/2018年10⽉号(寄稿)
• さくらのVPSのサービスについて • さくらのVPSの仕組み • 運⽤するにあたって⾟いところと今後の意気込み 今⽇お話すること 注意事項等 • サービス提供上公開できないこともあります(DC所在地や原価等)
• 「for Windows」「ベアメタルプラン」は仕様が違います • 資料作成当時(2019年9⽉)の情報です 発表当時資料になく⼝頭で説明・補⾜した部分は発表後にここに追記しています。
「さくらのVPS」とは
さくらのVPS使っている⼈!
• Virtual Private Server = 仮想専⽤サーバ • 2010年 サービス開始 •
注⽂するとVMが作成されグローバルIPとrootパスが送られてくる • コントロールパネルから起動・停⽌・ローカル接続などができる さくらのVPS VM = Virtual Machine 仮想マシン 直近の主な機能拡充 • 「サーバ監視β」提供開始(2019年1⽉) • パケットフィルタ機能リリース(2019年6⽉) • CentOS 8 提供開始(2019年10⽉)など 詳しくは「VPSニュース」へ https://vps-news.sakura.ad.jp/
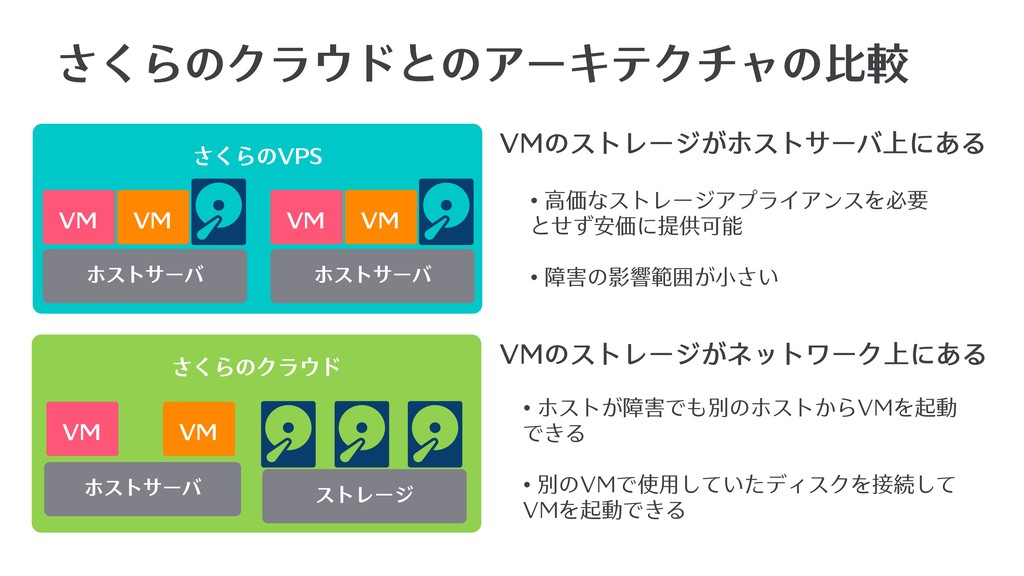
さくらのクラウドとのアーキテクチャの⽐較 さくらのVPS さくらのクラウド VM ホストサーバ VM ホストサーバ VM VM VM
ホストサーバ VM ストレージ VMのストレージがホストサーバ上にある VMのストレージがネットワーク上にある • ⾼価なストレージアプライアンスを必要 とせず安価に提供可能 • 障害の影響範囲が⼩さい • ホストが障害でも別のホストからVMを起動 できる • 別のVMで使⽤していたディスクを接続して VMを起動できる
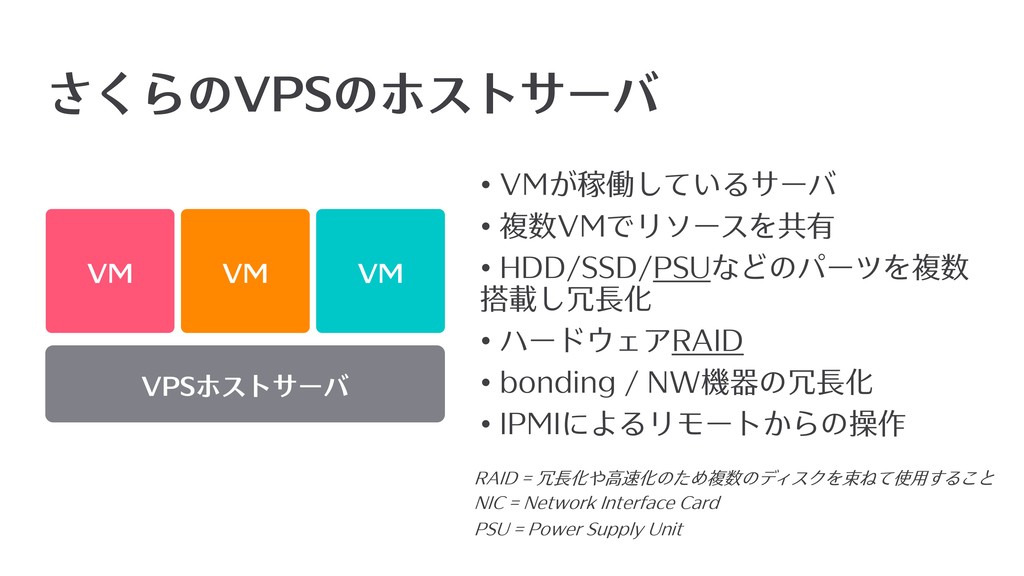
さくらのVPSのホストサーバ VM VPSホストサーバ VM VM • VMが稼働しているサーバ • 複数VMでリソースを共有 •
HDD/SSD/PSUなどのパーツを複数 搭載し冗⻑化 • ハードウェアRAID • bonding / NW機器の冗⻑化 • IPMIによるリモートからの操作 NIC = Network Interface Card PSU = Power Supply Unit RAID = 冗⻑化や⾼速化のため複数のディスクを束ねて使⽤すること
〇〇Stackなどのクラウド管理基盤ソフトウェアを使⽤せず⾃前で実装 • KVM+QEMU (仮想マシンの実⾏環境) • libvirt (仮想マシンの制御) • Linux Bridge
+ (Nested)VLAN(仮想マシンのNW) • LVM(仮想マシンのストレージ) さくらのVPSの実装 ⾃社で開発・保守することで低コストで運⽤&不具合に迅速に対応 KVM = Kernel-based Virtual Machine LVM = Logical Volume Manager
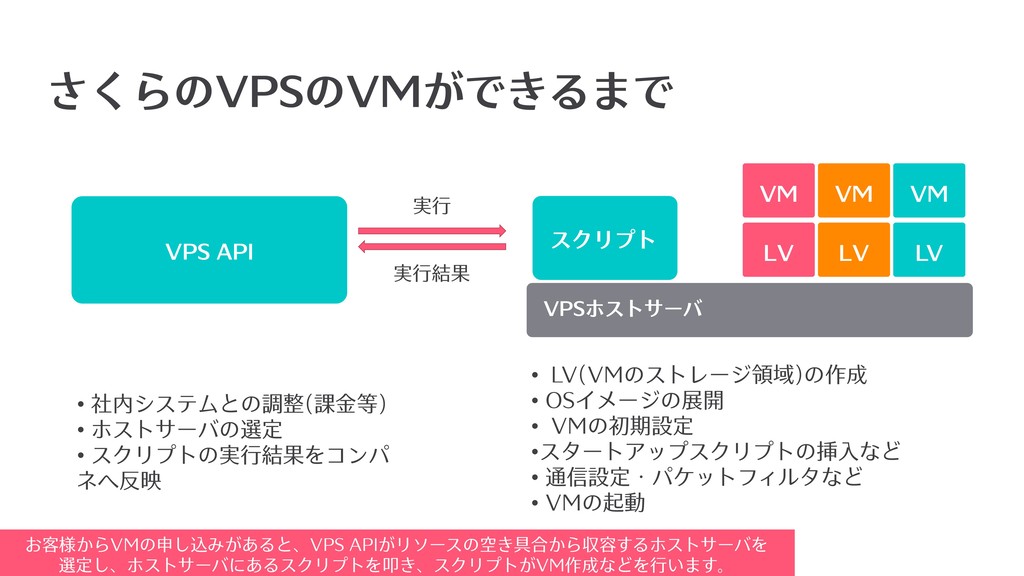
さくらのVPSのVMができるまで VM VPSホストサーバ VM VM スクリプト VPS API 実⾏ LV
LV LV 実⾏結果 • 社内システムとの調整(課⾦等) • ホストサーバの選定 • スクリプトの実⾏結果をコンパ ネへ反映 • LV(VMのストレージ領域)の作成 • OSイメージの展開 • VMの初期設定 •スタートアップスクリプトの挿⼊など • 通信設定・パケットフィルタなど • VMの起動 お客様からVMの申し込みがあると、VPS APIがリソースの空き具合から収容するホストサーバを 選定し、ホストサーバにあるスクリプトを叩き、スクリプトがVM作成などを⾏います。
「さくらのVPS」の運⽤
• サービスを安定的に提供し続けること = 監視を⾏い障害が発⽣したら対応する・発⽣しにくいようにする • サービス品質の継続的向上 = パフォーマンス改善・機能追加など 運⽤ 「さくらのVPS」では開発と運⽤には明確な線引きはなく、
メンバーそれぞれの得意分野で開発・運⽤を⾏っている サービスを安定して提供し続けるのは当然⼤事ですが、お客様に選ばれ使い続けていただくためには、 サービスを維持するだけでなく改善も必要で、開発も運⽤に含まれると考えています。
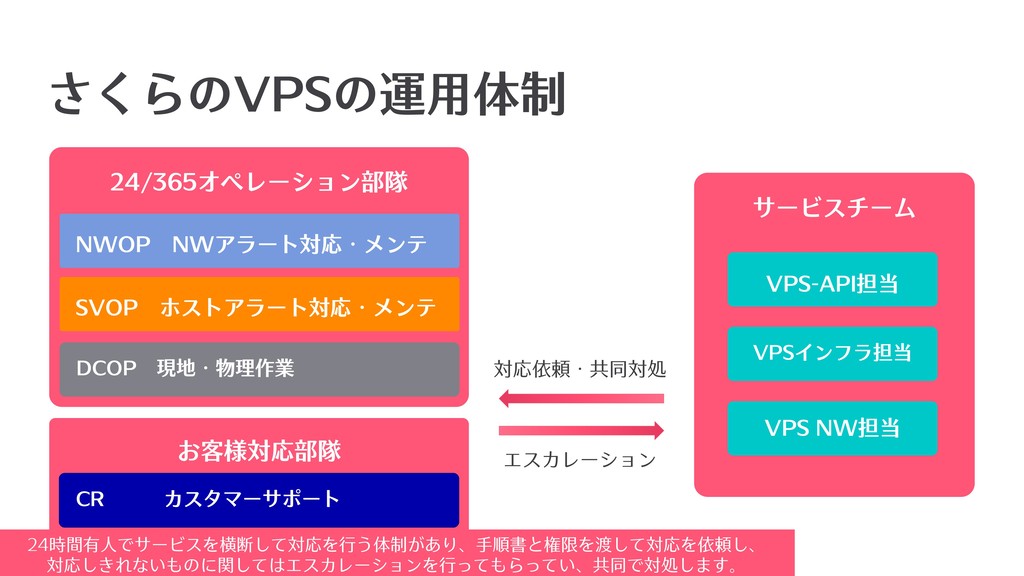
サービスチーム お客様対応部隊 さくらのVPSの運⽤体制 24/365オペレーション部隊 DCOP 現地・物理作業 SVOP ホストアラート対応・メンテ VPSインフラ担当 VPS-API担当
NWOP NWアラート対応・メンテ 対応依頼・共同対処 エスカレーション CR カスタマーサポート VPS NW担当 24時間有⼈でサービスを横断して対応を⾏う体制があり、⼿順書と権限を渡して対応を依頼し、 対応しきれないものに関してはエスカレーションを⾏ってもらってい、共同で対処します。
機械は必ず壊れる • 特に回転系 (HDD / PSUなど) 障害と計画メンテナンス • ホットスワップのパーツはダウンタイムなしで交換 •
障害の予兆を検知し、計画メンテナンスを⾏う ⼀部ホットスワップにより交換できないものもありますが、NICなど冗⻑化しているパーツであれば ⽚側が動作している間にメンテナンスを計画しホストサーバを停⽌して交換します。
HW交換メンテナンスの流れ 計画メンテナンス対応例 メンテ情報掲載 シャットダウン 筐体交換 復旧確認 • アラート等を検知 • メンテナンス情報の掲載と対象ユーザへの
メール送信(1〜2週間前) • VMの状態保存とホストサーバのシャット ダウン • 予備機とディスク 以外の筐体を交換 • ホスト正常性を確認し VMの状態を復元 • VMの疎通確認 所要時間3時間程度:通常は深夜帯に実施 予備機は障害機と同スペックのものを複数⽤意しており、対応するスロットのディスクを差し替え、 障害機が設置してあったラックの位置にマウントし結線する運⽤を⾏っております。
• 崩れたRAIDは再作成するしかない • バックアップから復旧するのに時間がかかる • CCを定期的に実⾏し不整合を検出・修正する • RAID/SMARTエラー値をホスト・スロット毎に追跡して予防交換 ストレージ障害は影響が⼤きい CC(Consistency
Check) = 仮想ドライブのデータ整合性をチェック修正するRAIDカードの機能 CCを定期的に実⾏していても、不良スロットの影響により動作が不安定になることがあるので、 SMARTやRAIDカードのエラー値をチェックして、状況次第で予防交換を⾏います。
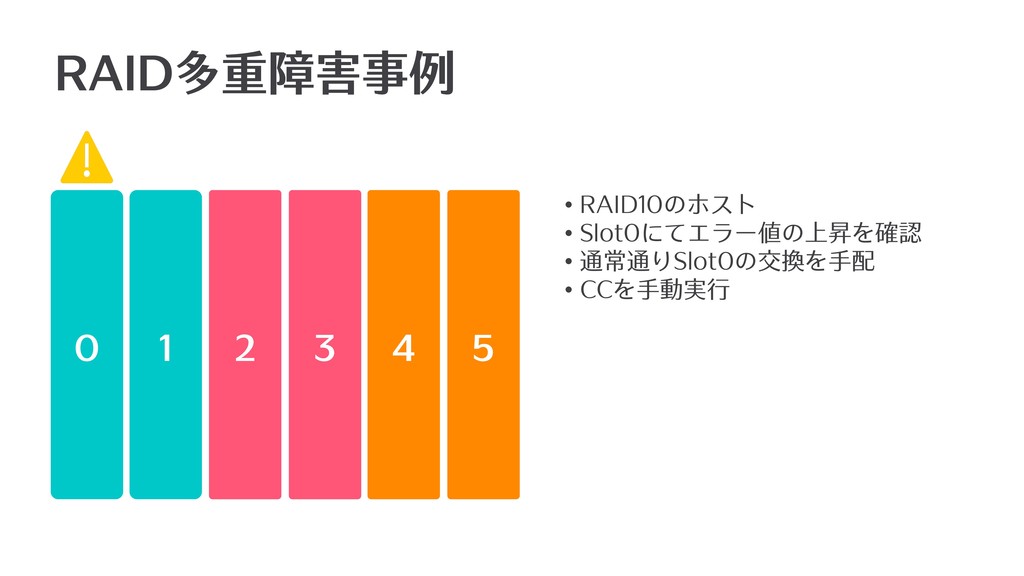
0 4 1 2 3 5 RAID多重障害事例 • RAID10のホスト •
Slot0にてエラー値の上昇を確認 • 通常通りSlot0の交換を⼿配 • CCを⼿動実⾏
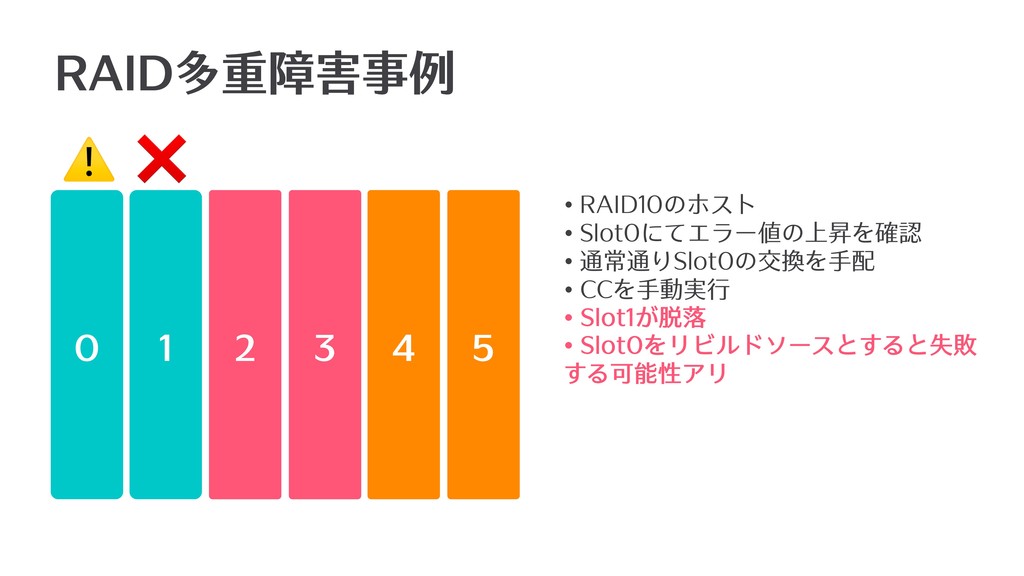
0 4 1 2 3 5 RAID多重障害事例 ❌ ⚠ •
RAID10のホスト • Slot0にてエラー値の上昇を確認 • 通常通りSlot0の交換を⼿配 • CCを⼿動実⾏ • Slot1が脱落 • Slot0をリビルドソースとすると失敗 する可能性アリ
0 4 1 2 3 5 • RAID10のホスト • Slot0にてエラー値の上昇を確認
• 通常通りSlot0の交換を⼿配 • CCを⼿動実⾏ • Slot1が脱落 • Slot0をリビルドソースとすると失敗 する可能性アリ RAID多重障害事例 ⚠ 緊急メンテナンスを実施し、 VMを別ホストに退避 Slot1をこのまま交換してしまうとVMのデータ消失に繋がる恐れがあったので、 やむを得ず緊急で深夜帯にVMの移設を⾏いました。
0 4 1 2 3 5 RAID多重障害事例 VM移設後 • slot1を交換(3⽇後)
→リビルド →完⾛ • slot0が脱落(22⽇後) →交換 →リビルド →完⾛ RAIDの状態は元に戻りましたが、データが破損し⻑時間のダウンタイムが発⽣するよりはよかったと 考えています。このように最悪の事態を回避するために緊急メンテナンスを⾏うこともあります。
• ユーザーからの問い合わせ対応 • 障害エスカレーション対応 • ベンダーとの保守の調整 • ⽇常的なメンテナンス • ⼤規模なメンテナンス
• Abuse対応 • 運⽤・サービス改善 VPSインフラメンバーの⽇常
• ユーザーからの問い合わせ対応 • 障害エスカレーション対応 • ベンダーとの保守の調整 • ⽇常的なメンテナンス • ⼤規模なメンテナンス
• Abuse対応 • 運⽤・サービス改善 VPSインフラメンバーの⽇常 「⽇常的なメンテナンス」についてはディスクの予防交換などが該当します。
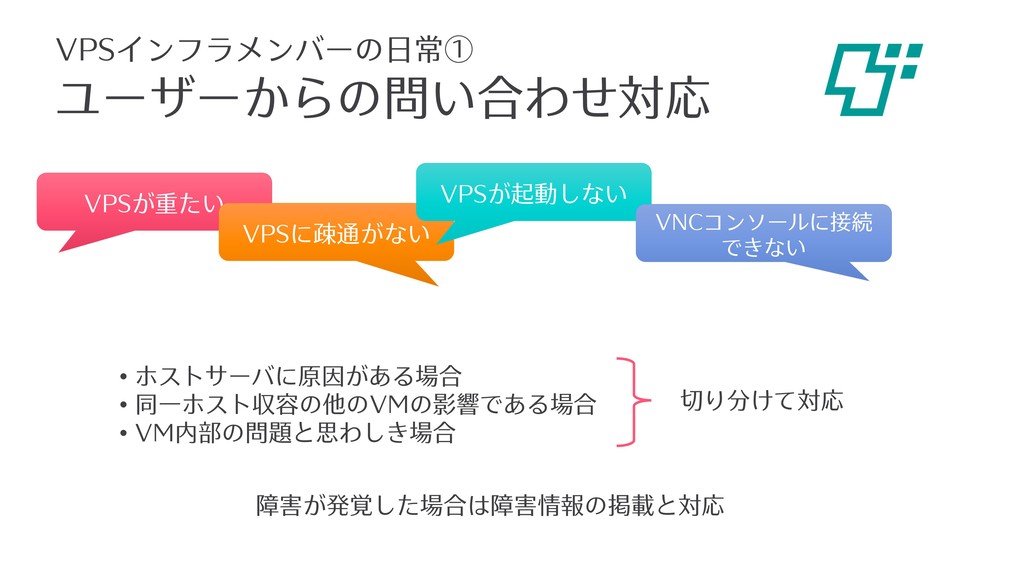
ユーザーからの問い合わせ対応 VPSインフラメンバーの⽇常① • ホストサーバに原因がある場合 • 同⼀ホスト収容の他のVMの影響である場合 • VM内部の問題と思わしき場合 障害が発覚した場合は障害情報の掲載と対応 VPSが重たい
VPSに疎通がない VPSが起動しない VNCコンソールに接続 できない 切り分けて対応
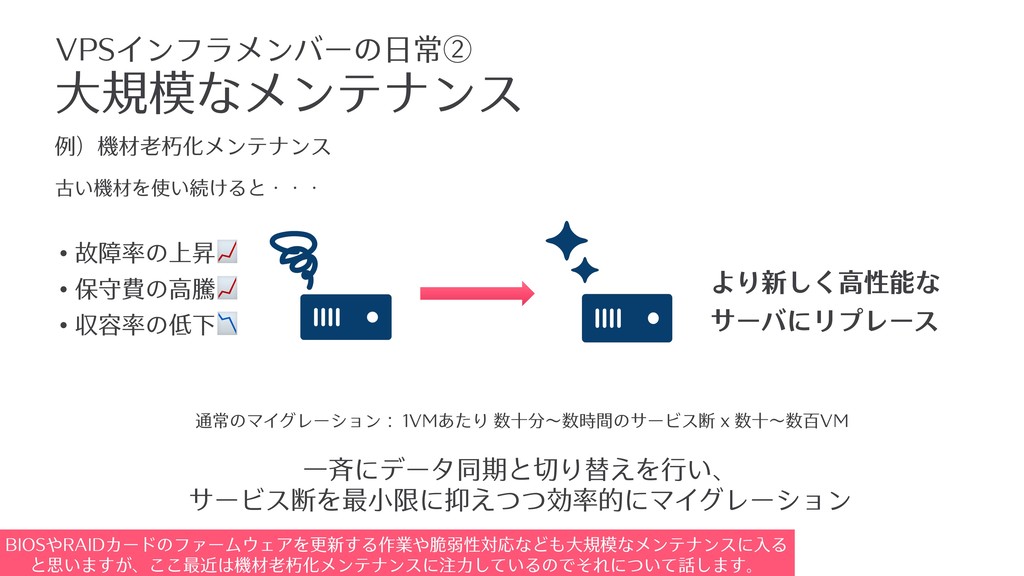
• 故障率の上昇 • 保守費の⾼騰 • 収容率の低下 ⼤規模なメンテナンス VPSインフラメンバーの⽇常② より新しく⾼性能な サーバにリプレース
古い機材を使い続けると・・・ 通常のマイグレーション: 1VMあたり 数⼗分〜数時間のサービス断 x 数⼗〜数百VM ⼀⻫にデータ同期と切り替えを⾏い、 サービス断を最⼩限に抑えつつ効率的にマイグレーション 例)機材⽼朽化メンテナンス BIOSやRAIDカードのファームウェアを更新する作業や脆弱性対応なども⼤規模なメンテナンスに⼊る と思いますが、ここ最近は機材⽼朽化メンテナンスに注⼒しているのでそれについて話します。
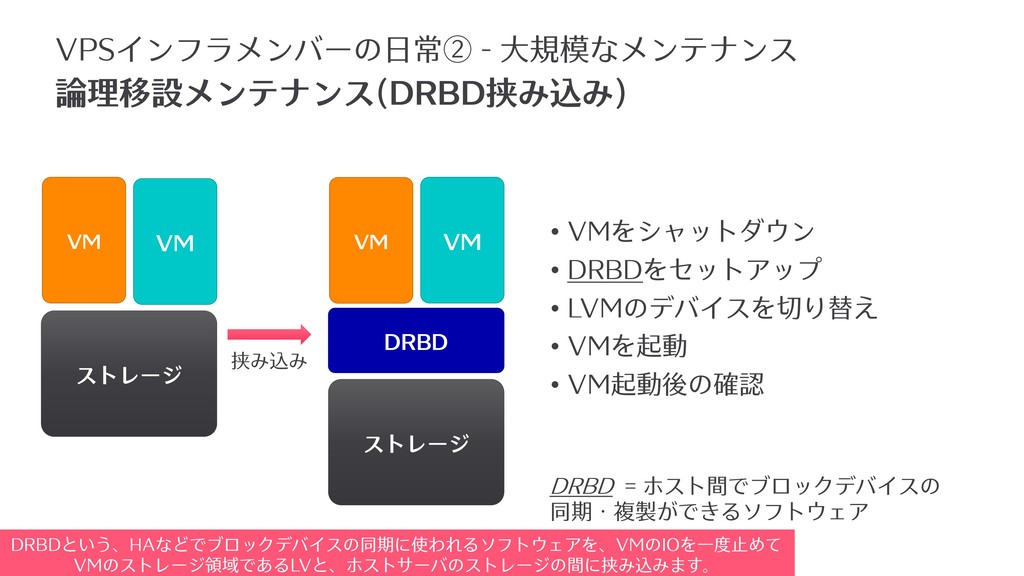
論理移設メンテナンス(DRBD挟み込み) VM ストレージ VM • VMをシャットダウン • DRBDをセットアップ • LVMのデバイスを切り替え
• VMを起動 • VM起動後の確認 DRBD 挟み込み VM VM DRBD = ホスト間でブロックデバイスの 同期・複製ができるソフトウェア VPSインフラメンバーの⽇常② - ⼤規模なメンテナンス ストレージ DRBDという、HAなどでブロックデバイスの同期に使われるソフトウェアを、VMのIOを⼀度⽌めて VMのストレージ領域であるLVと、ホストサーバのストレージの間に挟み込みます。
論理移設メンテナンス(VMデータ同期) DRBD データ 同期 VM VM VPSインフラメンバーの⽇常② - ⼤規模なメンテナンス ストレージ
DRBD • DRBD⼊り新ホスト を構築 • 新旧ホストを接続 • データの同期 VM ストレージ VM DRBD ⼀度挟み込んでしまえば、VMを停⽌することなくVMデータの同期を開始できます。 右側のDRBDデバイスはもう⼀つの旧ホストから⼊ってくるVMの領域になります。
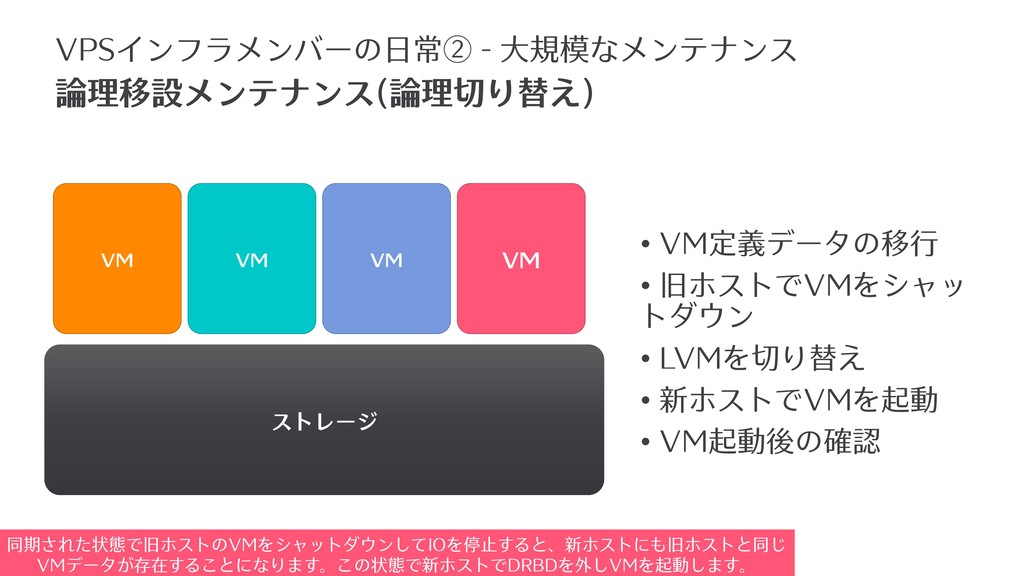
• VM定義データの移⾏ • 旧ホストでVMをシャッ トダウン • LVMを切り替え • 新ホストでVMを起動 •
VM起動後の確認 ストレージ VM VM VM VM 論理移設メンテナンス(論理切り替え) VPSインフラメンバーの⽇常② - ⼤規模なメンテナンス 同期された状態で旧ホストのVMをシャットダウンしてIOを停⽌すると、新ホストにも旧ホストと同じ VMデータが存在することになります。この状態で新ホストでDRBDを外しVMを起動します。
• 「さくらのVPS」は独⾃実装で⼯夫することにより、コストを下げ リーズナブルにサービスを提供できている。 • サービス開始から約10年が経過し、様々なノウハウを培ってきた⼀ ⽅、運⽤上の課題が⾒えてきた。 • 今後は省⼒化・⾃動化を推進し、運⽤の負荷を低減するとともに よりよいサービスづくりに注⼒していきたい。 まとめ
© SAKURA Internet Inc. ありがとうございました
おまけ:運⽤・サービス改善 時間があったのでVPSインフラメンバーの⽇常③「運⽤・サービス改善」についてお話します。
RAIDアラートの対応の流れ(従来) • SSHで対象ホストにログイン→コマンドでスロットの特定 • 対象ホストの設置位置・保守⽤ログなどを取得しメールで交換依頼 • 現地で保守⽤ディスクと交換→⾃動でリビルド開始 • SSHで対象ホストにログイン→リビルド開始を確認 アラート
検知 交換対象 特定 ディスク 交換 リビルド 確認 「⼿順があるし⾃動化できそう」 VPSインフラメンバーの⽇常③ - 運⽤・サービス改善 これはまだ実験中で本番投⼊していない取り組みなんですが、アラートを検知してから復旧するまで、 有⼈によるオペレーション多いと実際に対応しながら思った事がありまして、
RAIDアラートの対応の流れ(⾃動化) • アラートスクリプト内部で交換対象を特定 • 必要情報を収集し依頼チケット作成&Slack通知 • 現地で保守⽤ディスクと交換→⾃動でリビルド開始 • SSHで対象ホストにログイン→リビルド開始を確認 ディスク交換以外の部分は監視サーバに設置するスクリプトで実⾏!
→年間数百⼈時の⼯数削減 アラート 検知 交換依頼・ 通知 ディスク 交換 リビルド 確認 VPSインフラメンバーの⽇常③ - 運⽤・サービス改善 監視の仕組みを⾒直し、スクリプトにオペレーションの⼀部を⾏わせることで省⼒化ができます。 運⽤者の負荷が減って、サービスの改善に繋がるようなことを今後はもっとやりたいと思っています。
{kind=link}
{kind=link}
![⼩林 巧 (こばやし たくみ) • [email protected] @chamaharun • 2017年4⽉⼊社 新卒3年⽬](https://files.speakerdeck.com/presentations/cbfcf42abed148359a455cdca5fd58e4/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}