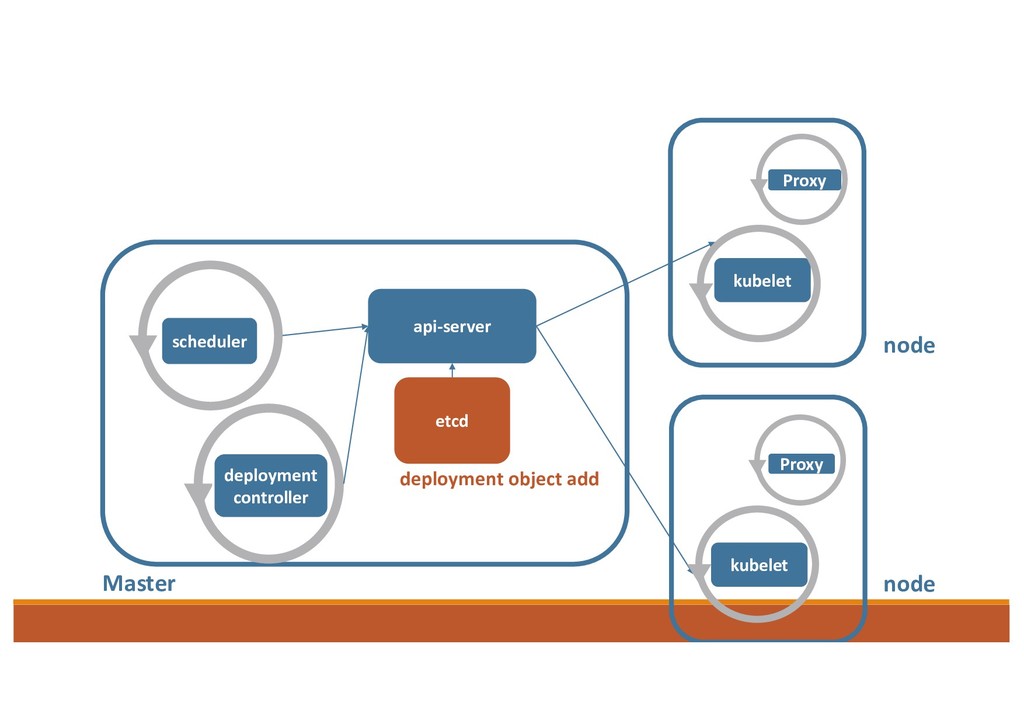
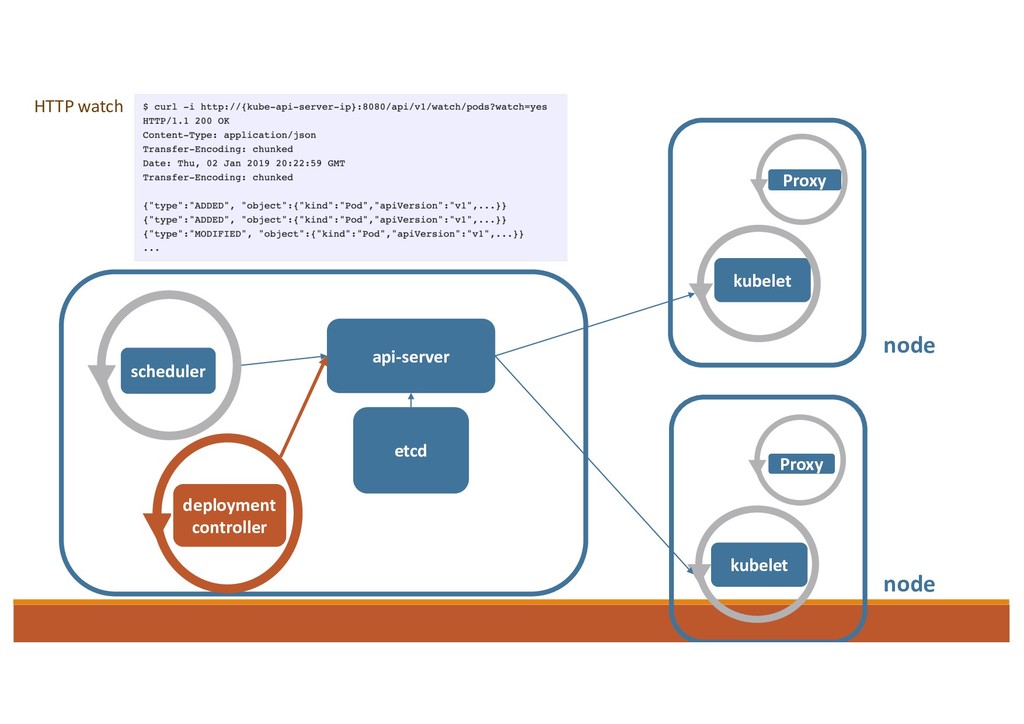
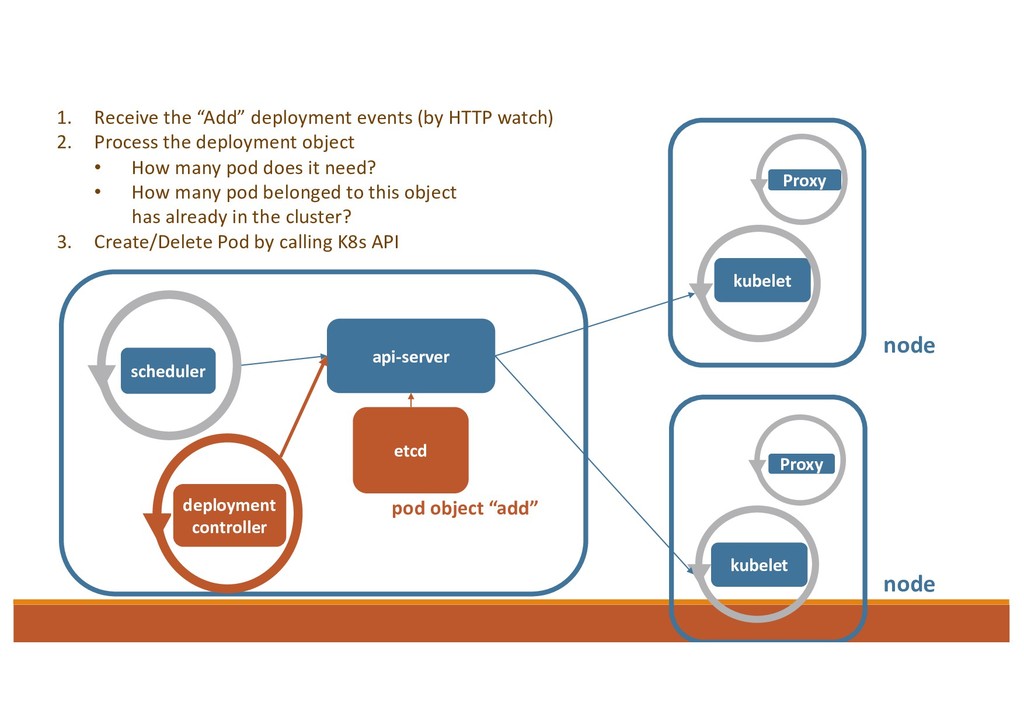
1. Receive the “Add” deployment events (by HTTP watch) 2. Process the deployment object • How many pod does it need? • How many pod belonged to this object has already in the cluster? 3. Create/Delete Pod by calling K8s API etcd pod object “add”
own object and resource in the k8s? Custom Resource Definition (CRD) + Custom Controller = Operator Pattern • I know CRD, but how to build a Custom Controller? 1. Old and Hard way 2. Fashion and Easy way
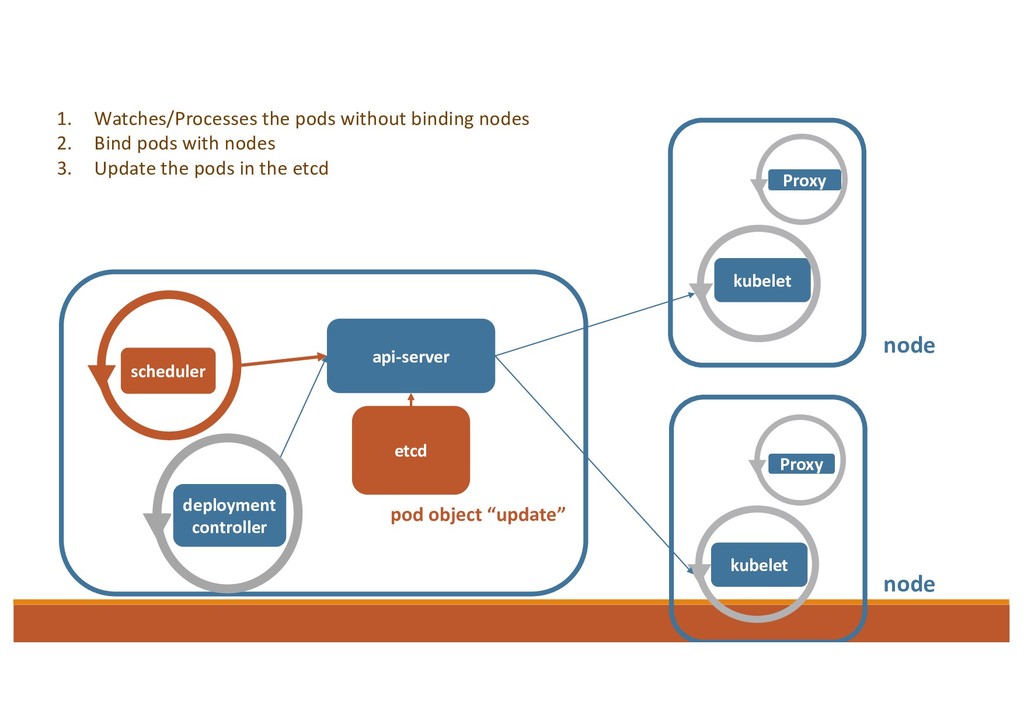
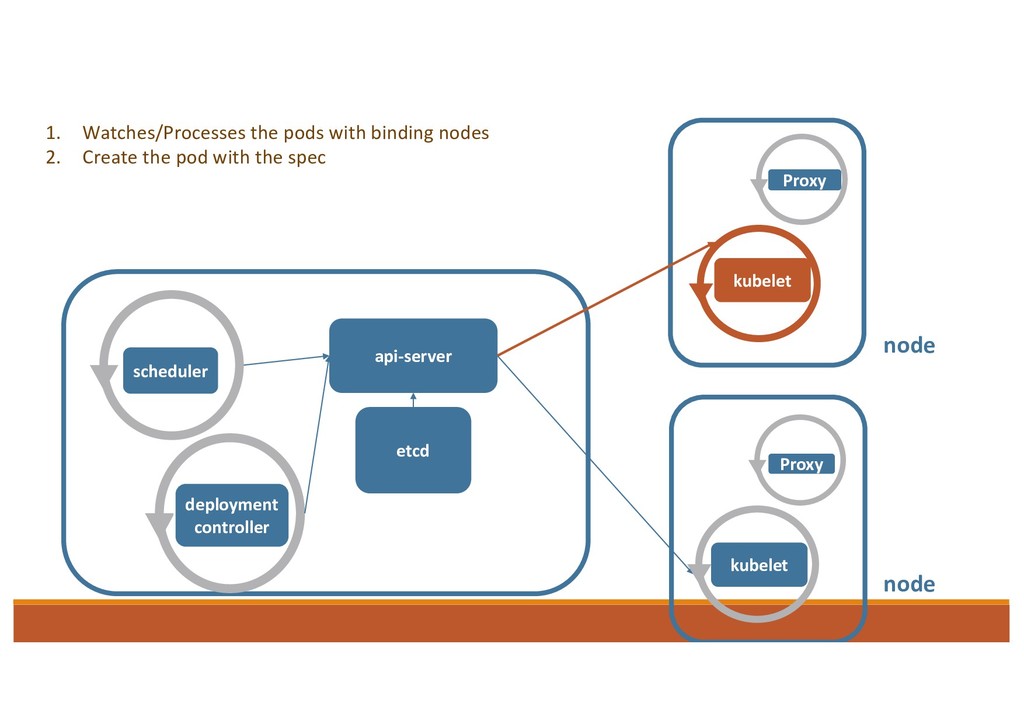
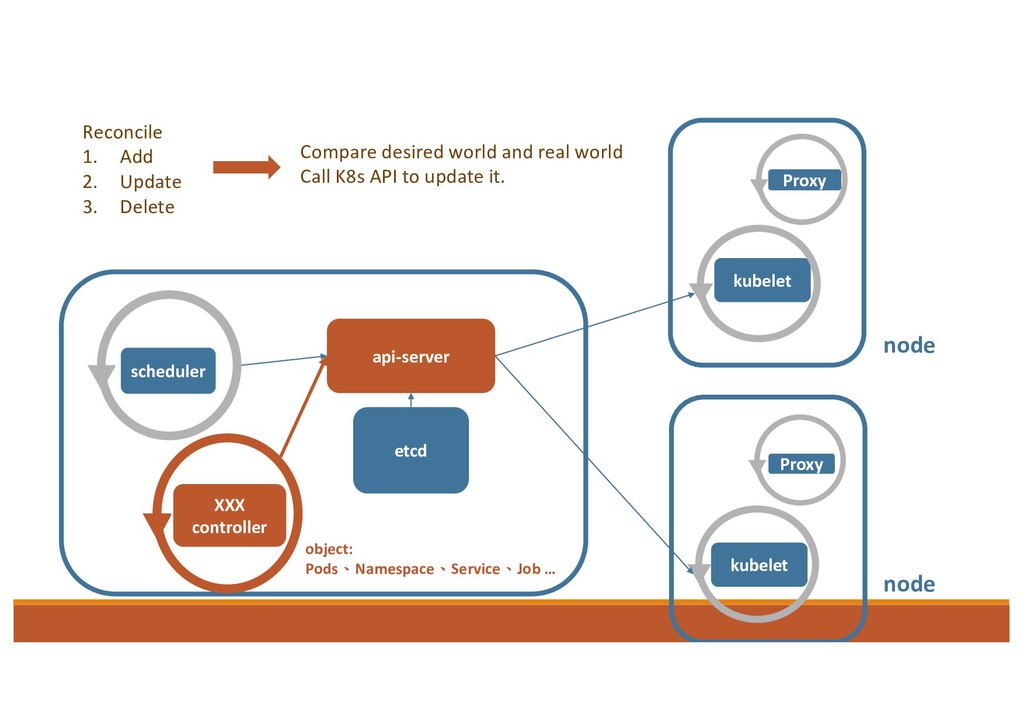
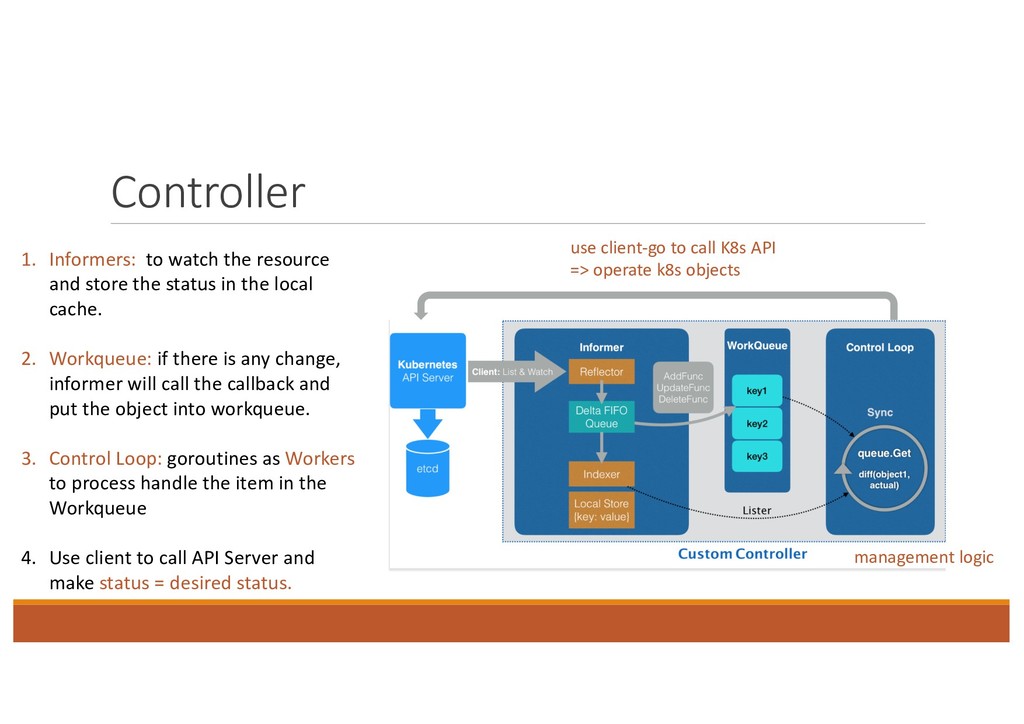
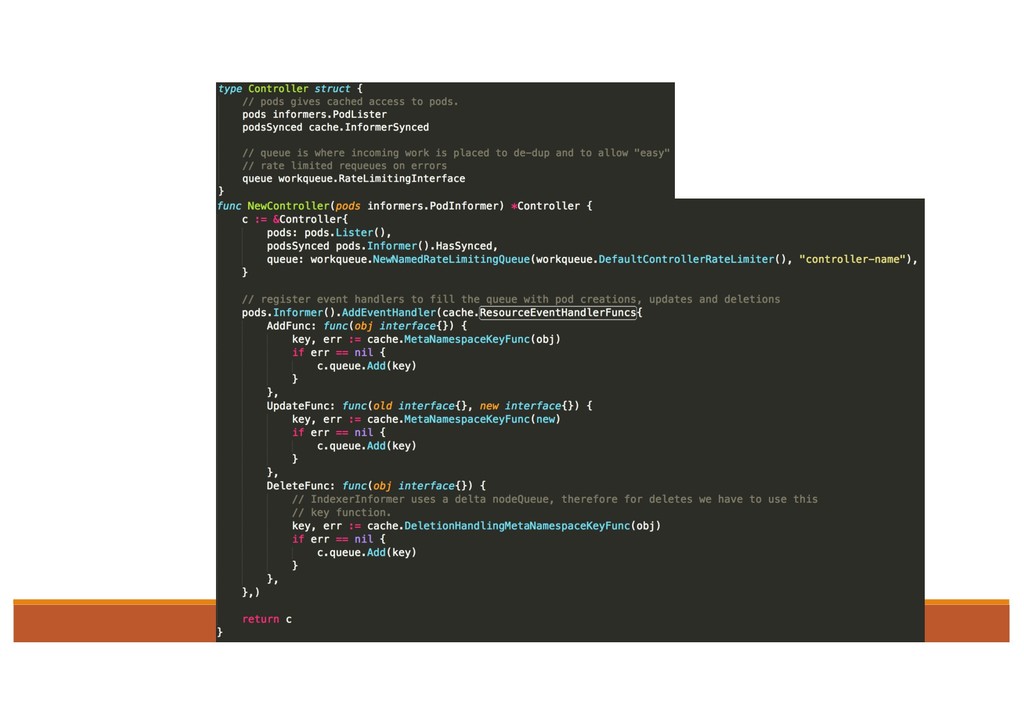
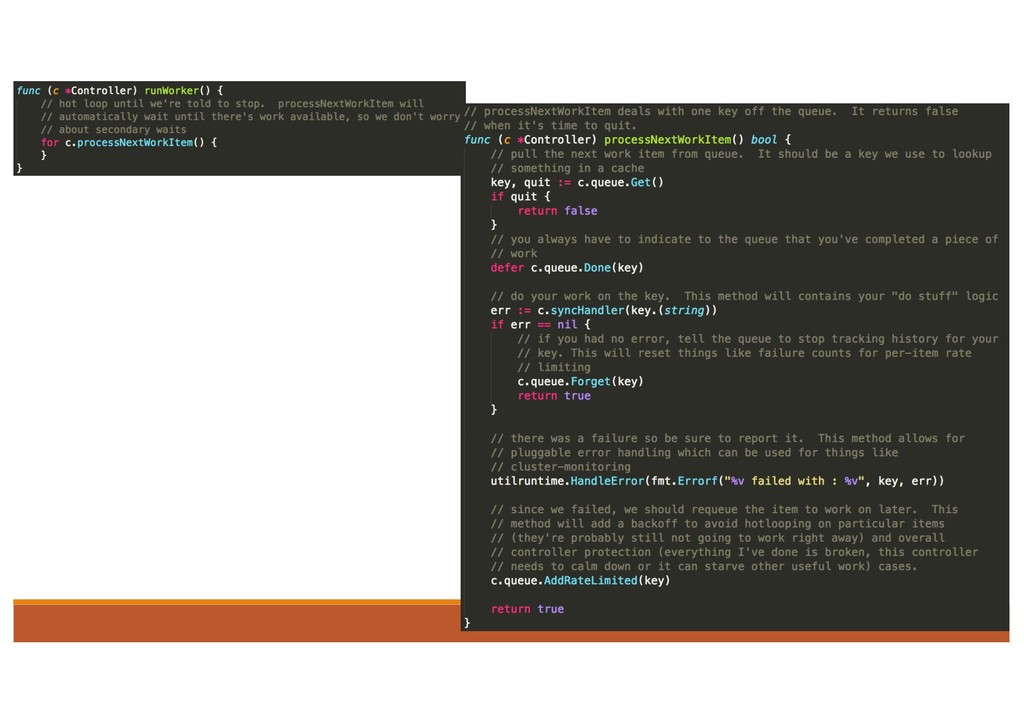
operate k8s objects 1. Informers: to watch the resource and store the status in the local cache. 2. Workqueue: if there is any change, informer will call the callback and put the object into workqueue. 3. Control Loop: goroutines as Workers to process handle the item in the Workqueue 4. Use client to call API Server and make status = desired status.
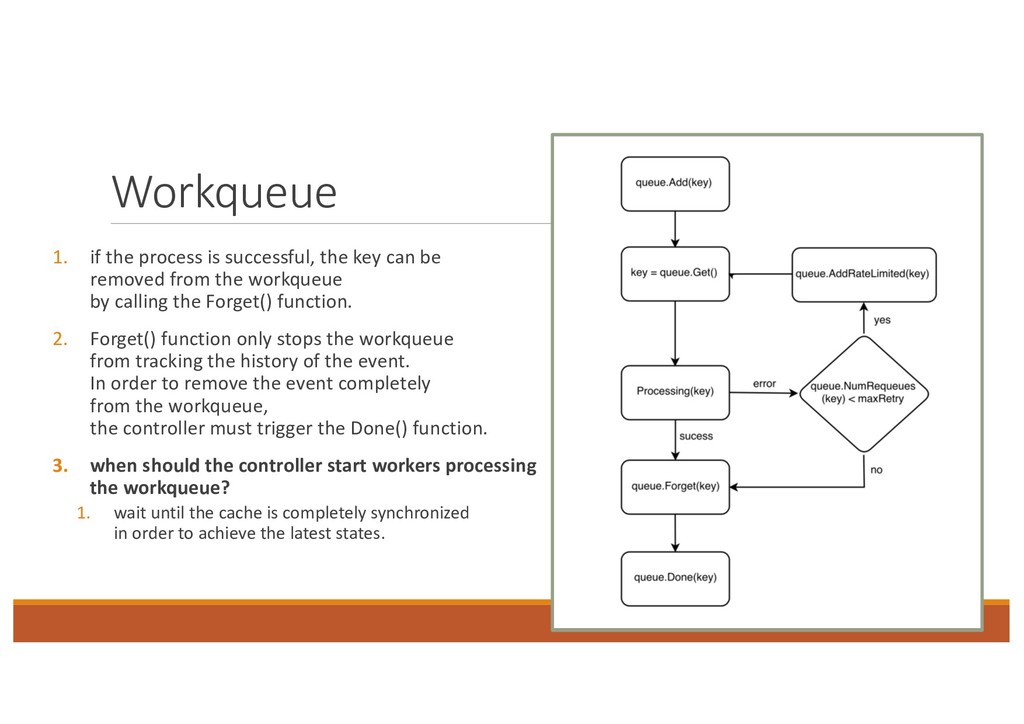
be removed from the workqueue by calling the Forget() function. 2. Forget() function only stops the workqueue from tracking the history of the event. In order to remove the event completely from the workqueue, the controller must trigger the Done() function. 3. when should the controller start workers processing the workqueue? 1. wait until the cache is completely synchronized in order to achieve the latest states.
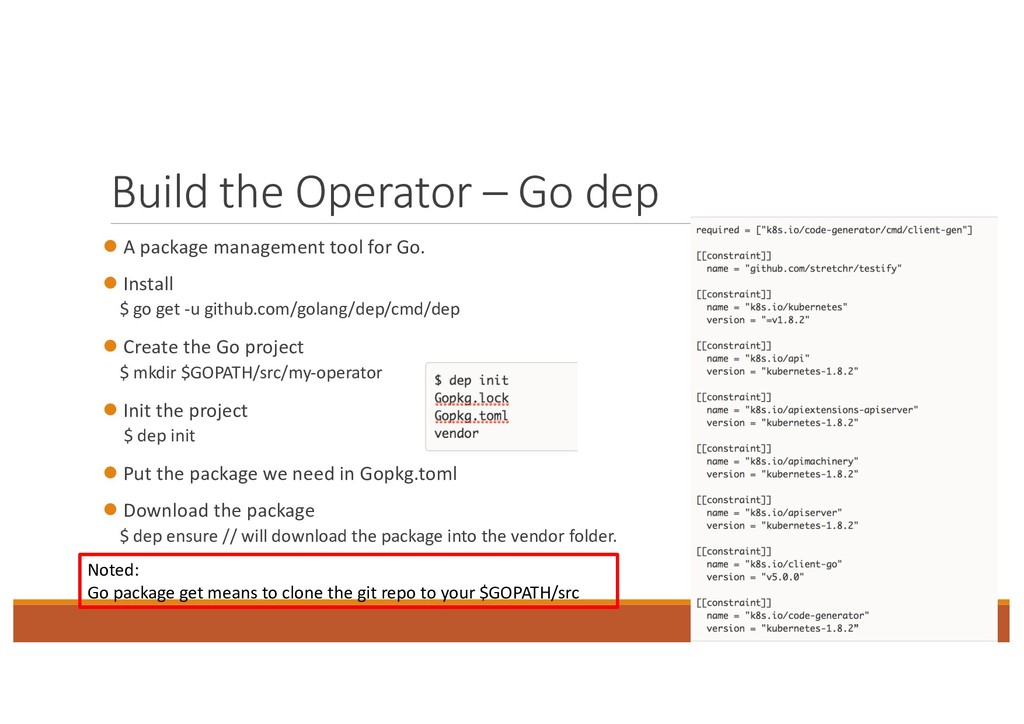
tool for Go. l Install $ go get -u github.com/golang/dep/cmd/dep l Create the Go project $ mkdir $GOPATH/src/my-operator l Init the project $ dep init l Put the package we need in Gopkg.toml l Download the package $ dep ensure // will download the package into the vendor folder. Noted: Go package get means to clone the git repo to your $GOPATH/src
-p $GOPATH/src/my-operator/pkg/apis/student/v1 l create 3 files in pkg/apis/student/v1 1. doc.go 2. register.go 3. types.go l $ mkdir $GOPATH/src/my-operator/hack l Create codegen.sh in hack Noted: Just copy the files from the rook/operator-kit, and modified it. CRD
generate the code. • You can now write the operator with your custom resource API of course in Golang … Reference: Almost all the operator •etcd: https://github.com/coreos/etcd-operator •Kubeflow/tf-operator: https://github.com/kubeflow/tf-operator •rook: https://github.com/rook/rook •all Kubernetes controller: https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/job/job_controller.go
Wraps all the details into a framework, all you need to do is 1. Define CRD 2. Define management logic as webhook ! ⦁ When there is a event (add/delete/update) related to your CRD 1. Metacontroller will be triggered 2. Send the current CRD object to you in JSON format 3. You define the management logic depend on the status of the object 4. Send the desired status back also in JSON format
on the desired state specified in a parent object. ⦁E.g. Deployment Controller in K8s. Deployment manages a set of pods. Your own CRD The child objects your CRD is managing. Like pod.
the child objects when they are deleted. ⦁ Recreate: when the status of child objects are different from the desired state, delete and recreate it. ⦁ InPlace: update the status of child objects without recreate it. ⦁Child Update Status Checks - Status Condition Check ⦁ type ⦁ status ⦁ reason ⦁Finalize Hook ⦁ you can do something before your CRD is killed,
service and will be called by Metacontroller ⦁ Define your own webhook function 1. Send the current CRD object to you in JSON format 2. You define the management logic depend on the status of the object 3. Send the desired status back also in JSON format ⦁ You can simply mounted using configmap
(Annotation) ⦁ Use Kubernetes default scheduler to schedule tensorflow container ◦ No gang-scheduling – Deadlock will exist in the system 35 Node1 Node2 A2 A3 B3 B2 Default Scheduler in Pod level (Round Robin placement) Tensorflow Tensorflow GPU GPU GPU GPU Kubernetes A1 B1 A2 B2 A3 B3
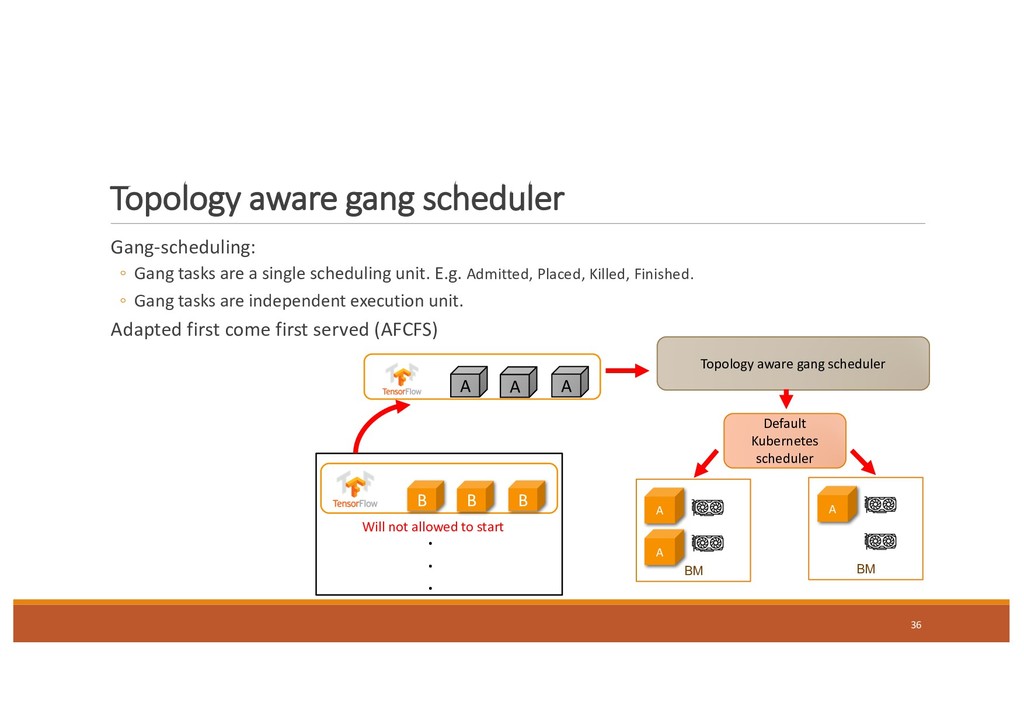
single scheduling unit. E.g. Admitted, Placed, Killed, Finished. ◦ Gang tasks are independent execution unit. Adapted first come first served (AFCFS) 36 B B B . . . Topology aware gang scheduler A A A BM A A BM A Default Kubernetes scheduler Will not allowed to start
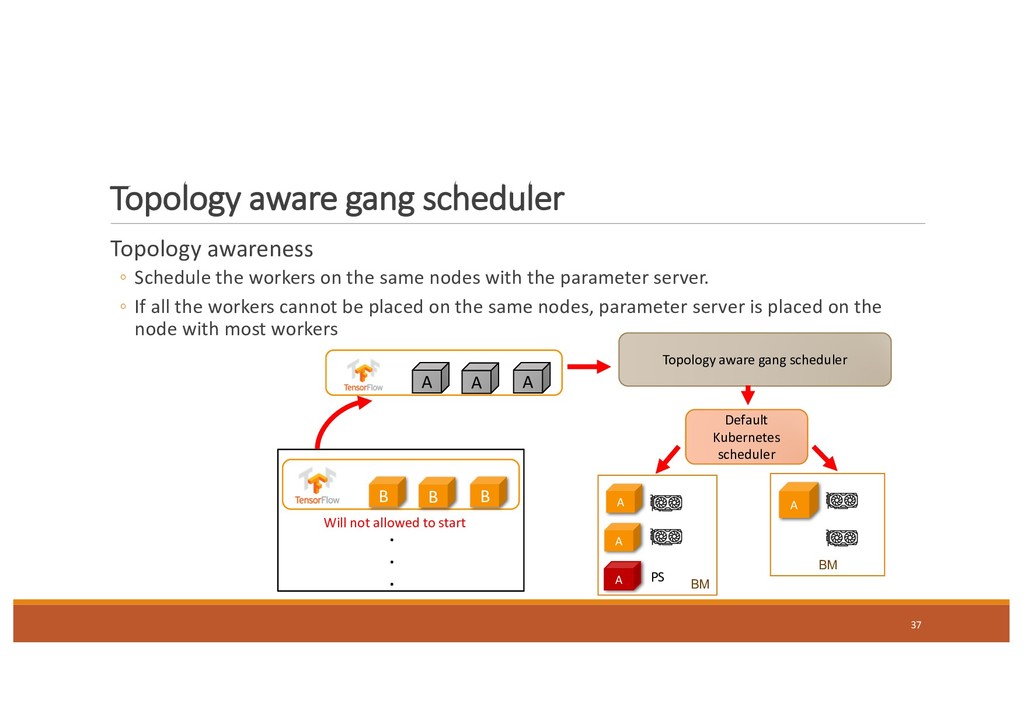
on the same nodes with the parameter server. ◦ If all the workers cannot be placed on the same nodes, parameter server is placed on the node with most workers 37 B B B . . . Topology aware gang scheduler A A A BM A A BM A Default Kubernetes scheduler Will not allowed to start PS A
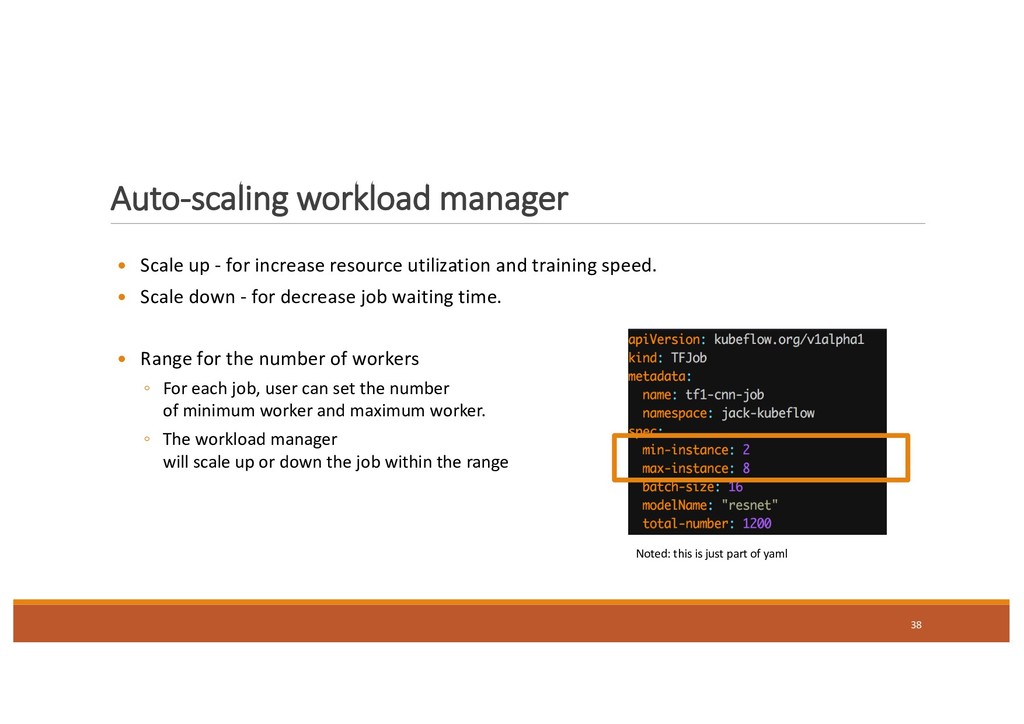
training speed. Scale down - for decrease job waiting time. Range for the number of workers ◦ For each job, user can set the number of minimum worker and maximum worker. ◦ The workload manager will scale up or down the job within the range Auto-scaling workload manager Noted: this is just part of yaml
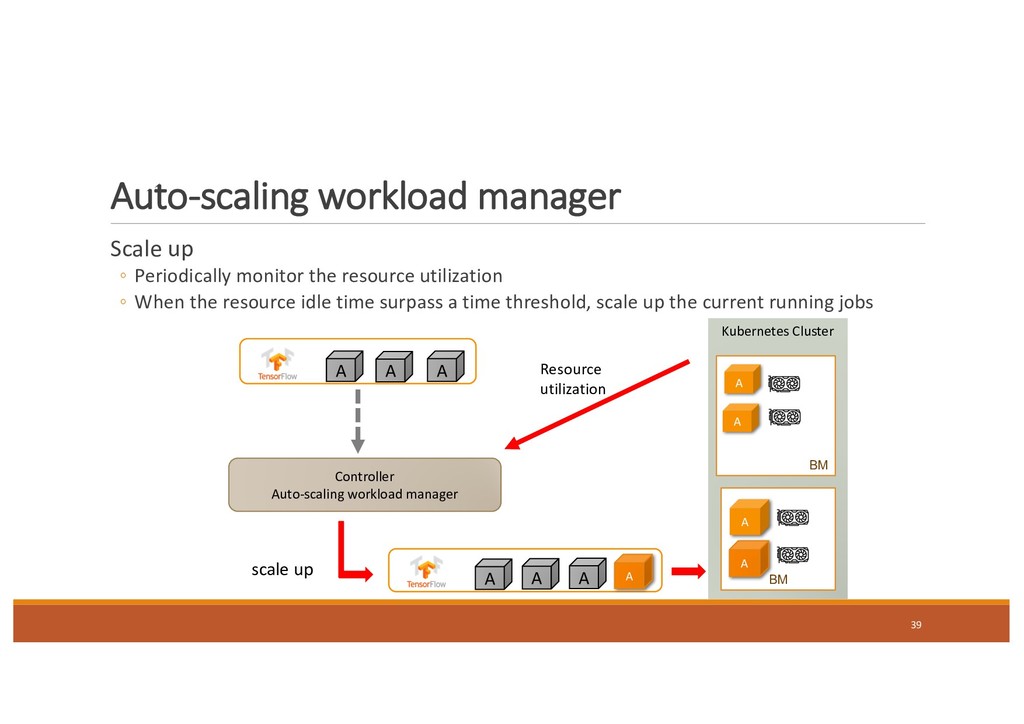
the resource utilization ◦ When the resource idle time surpass a time threshold, scale up the current running jobs 39 Controller Auto-scaling workload manager BM A A BM A A A A A A A A A Resource utilization scale up
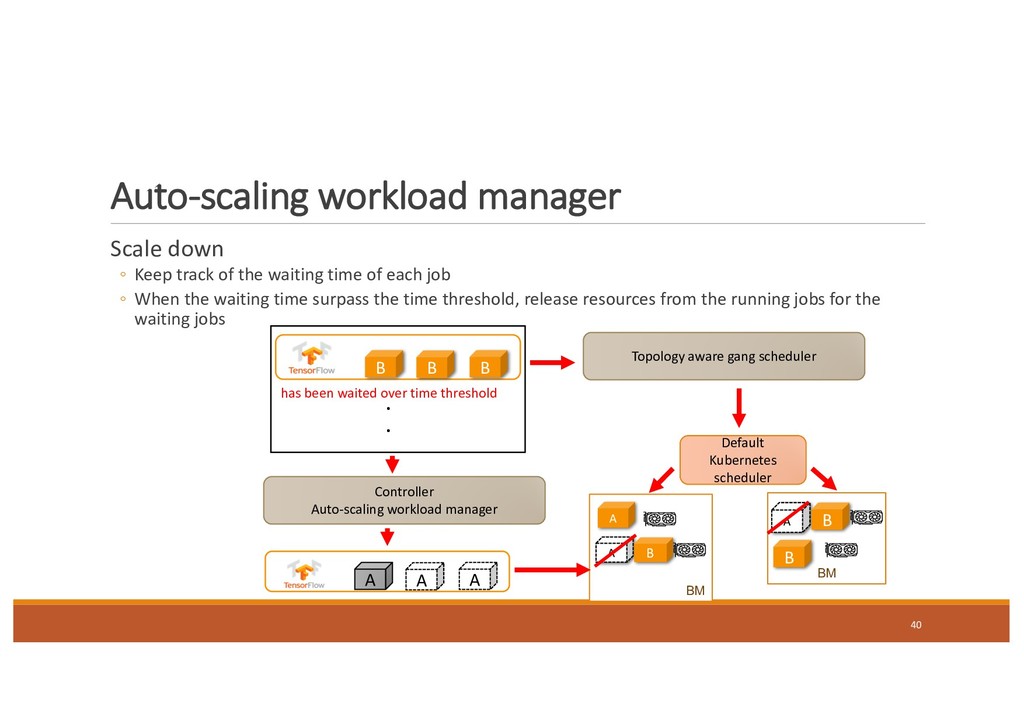
waiting time of each job ◦ When the waiting time surpass the time threshold, release resources from the running jobs for the waiting jobs 40 Controller Auto-scaling workload manager A A A BM A A BM A Default Kubernetes scheduler B B B . . has been waited over time threshold Topology aware gang scheduler B B B
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}