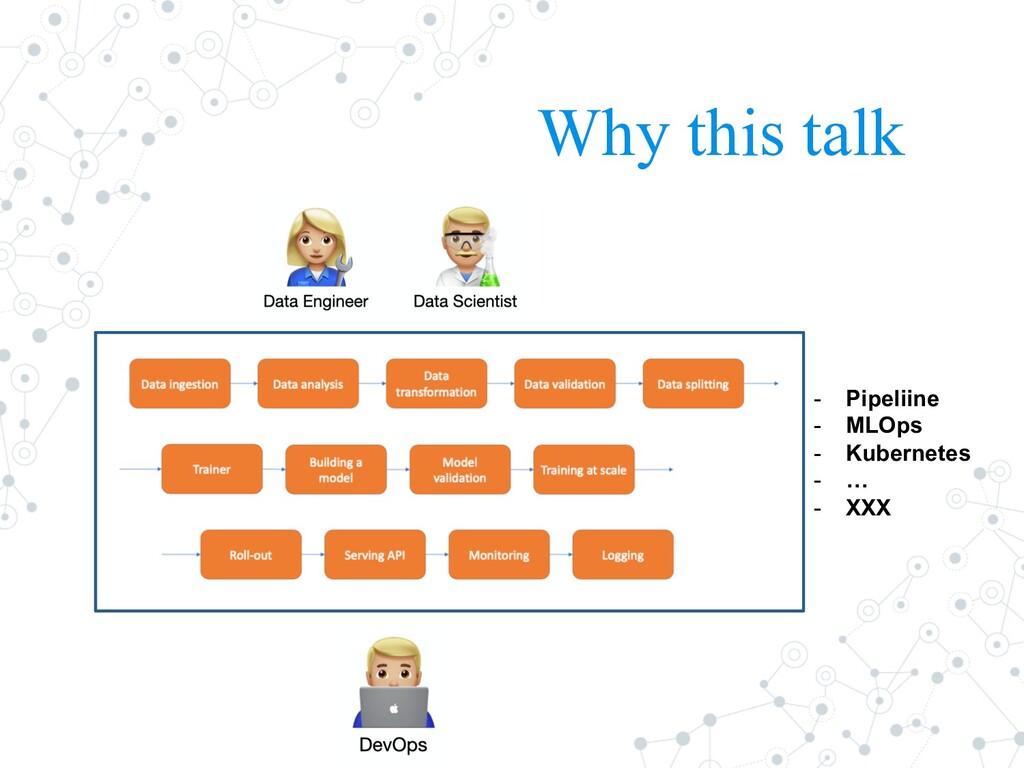
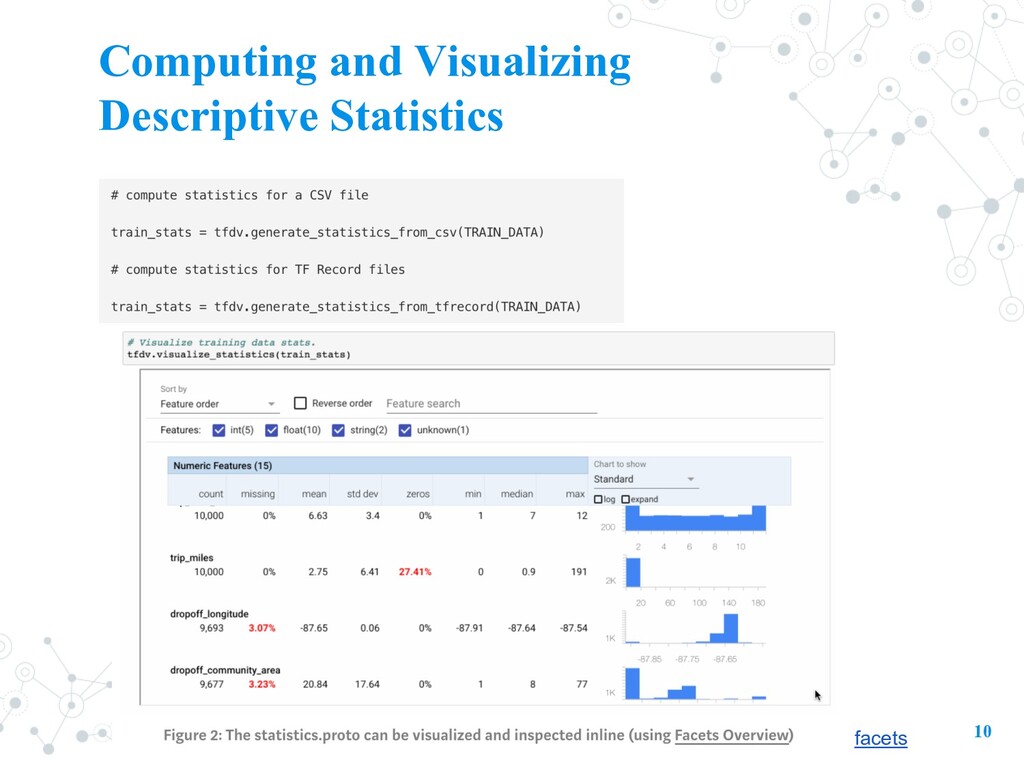
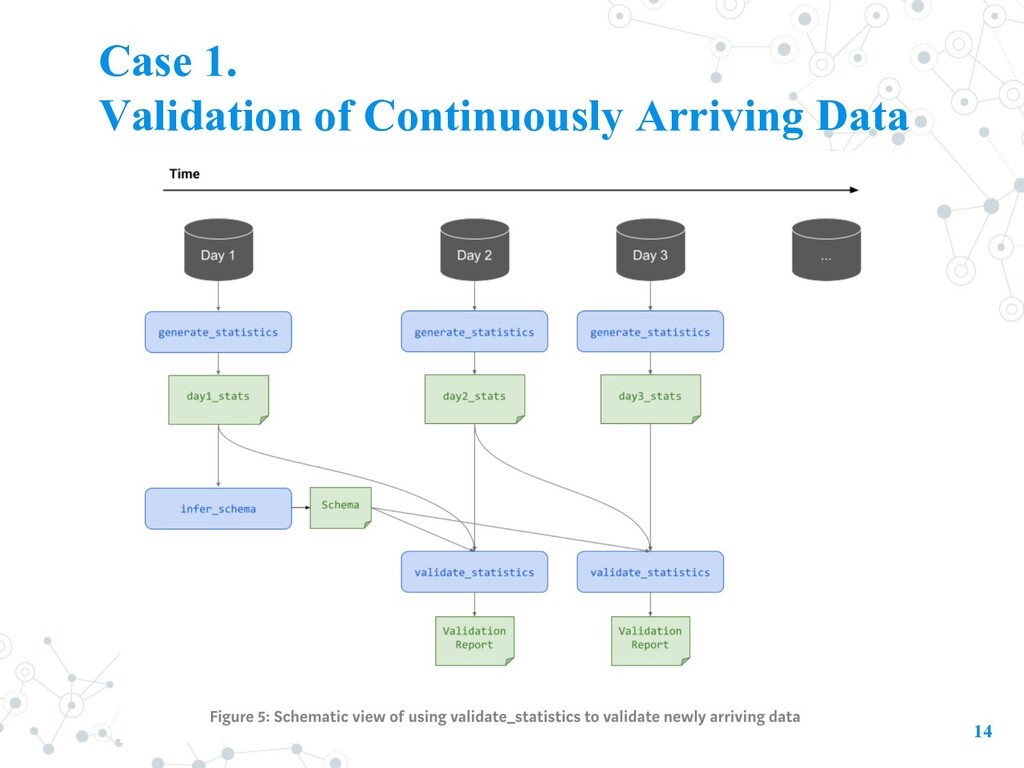
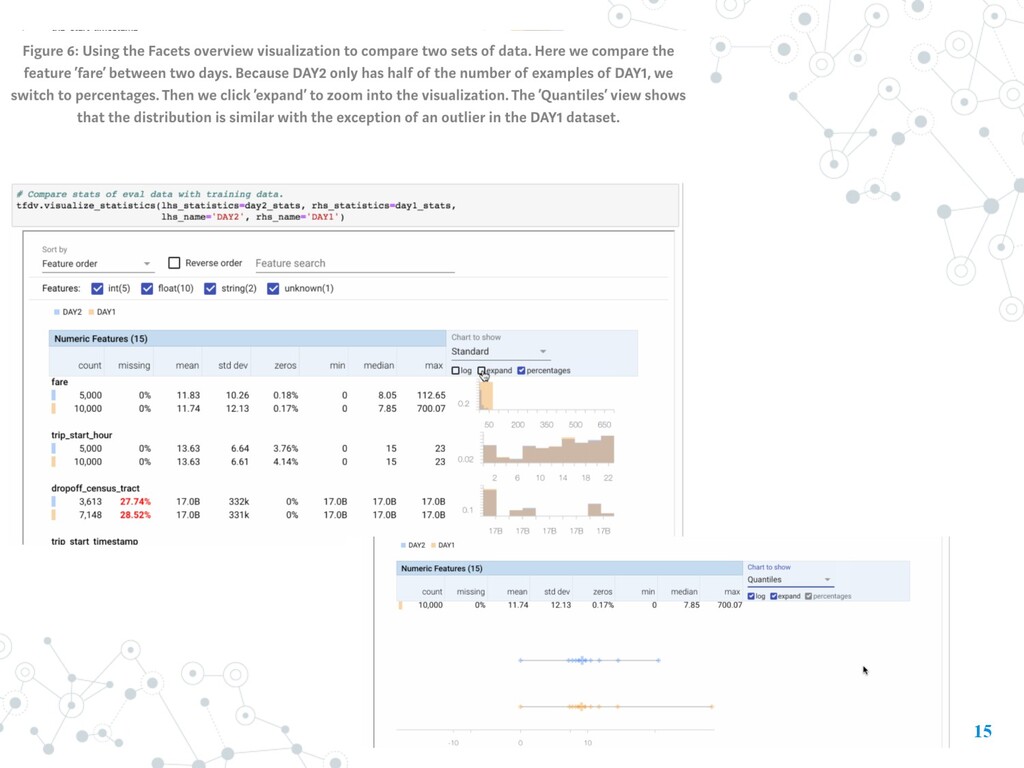
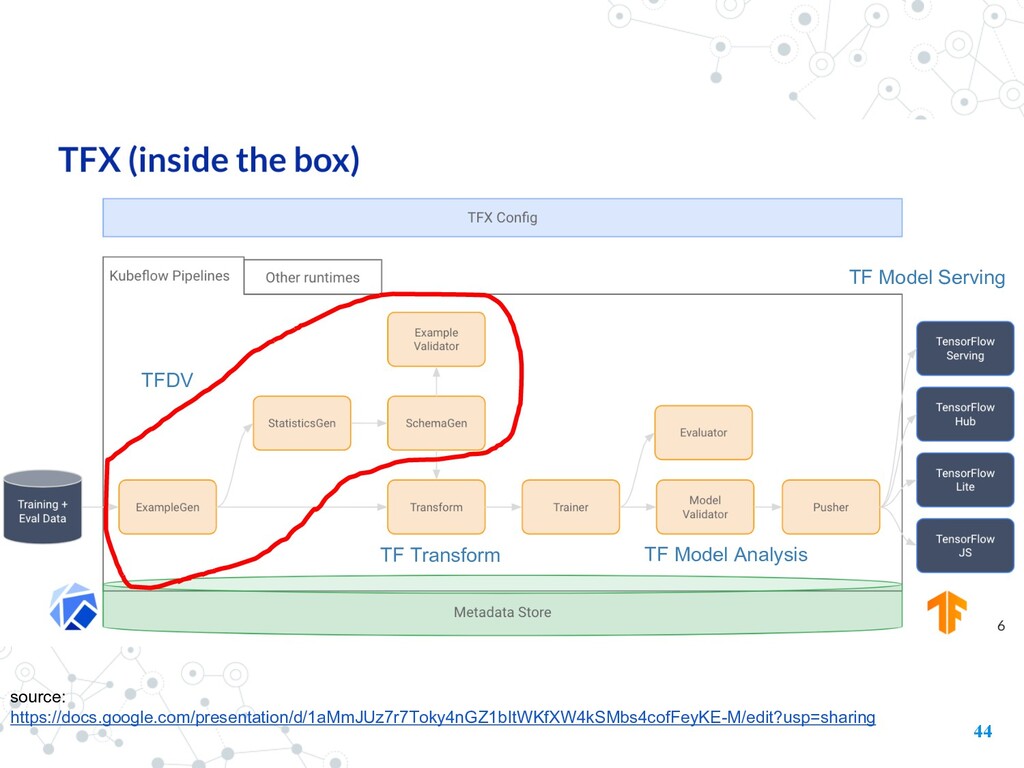
Model itself • “garbage in, garbage out” • open-source library that helps developers automatically analyze, validate, and monitor their ML data at scale. • TFDV is part of the TFX Platform and this technology is used to analyze and validate PB of data at Google every day • Data Validation: 1. Computing and Visualizing Descriptive Statistics 2. Inferring a Schema 3. Validating New Data 8
formats • underline it uses Apache Beam to define and process its data pipelines. can use Beam IO connectors, Ptransforms to process different formats • TFDV provides two helper functions for CSV and TFRecord of serialized tf.Examples. • Scale: creates an Apache Beam pipeline which can run in • DirectRunner in the notebook environment • DataflowRunner on Google Cloud Platform • Kubeflow pipeline / Airflow 9
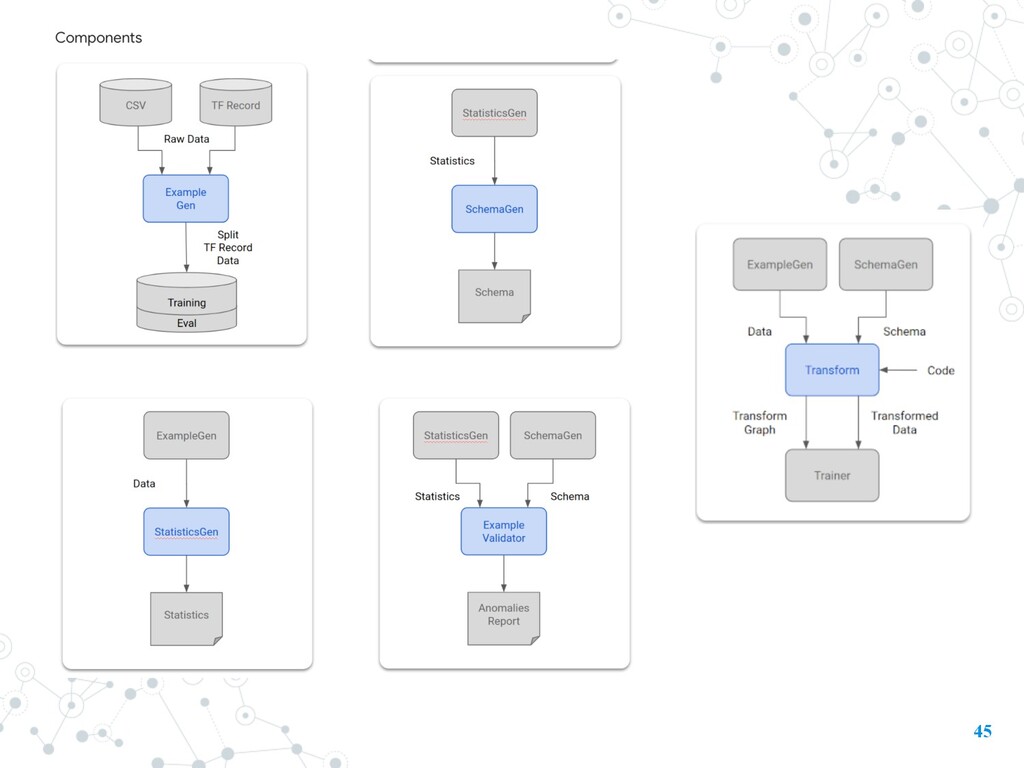
infers a schema (schema.proto) . • To reflect the stable characteristics of the data. • Schema • Do data validation • this schema format is also used as the interface to other components in the TFX ecosystem. E.g. data transform use TensorFlow Transform.
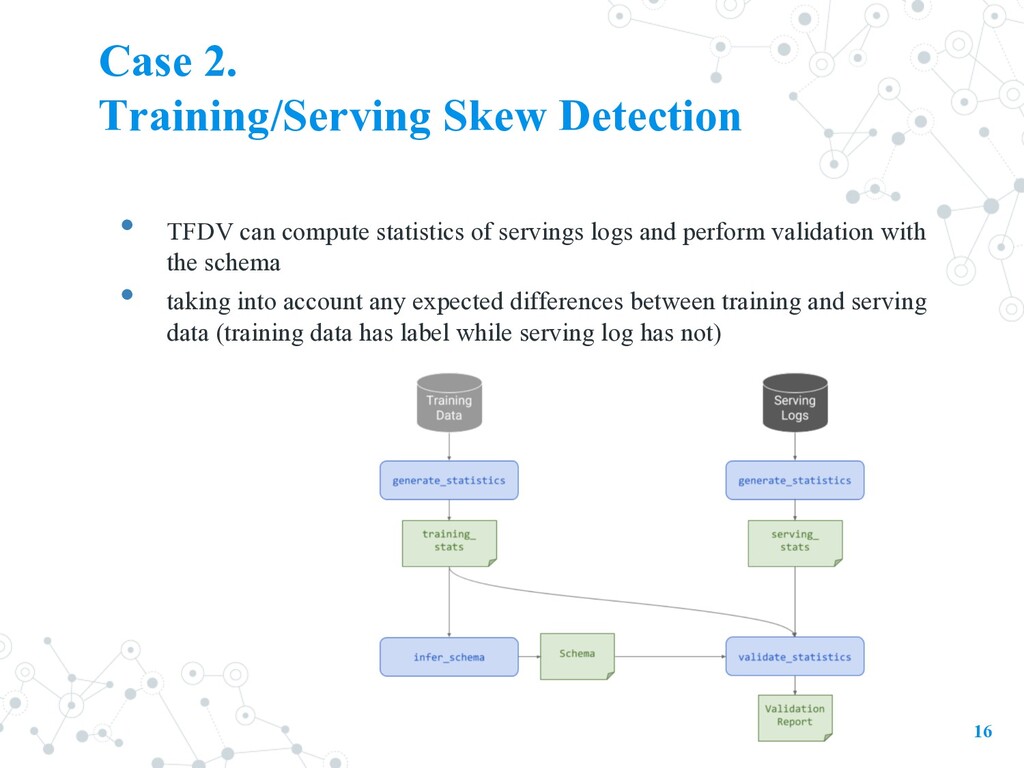
statistics of servings logs and perform validation with the schema • taking into account any expected differences between training and serving data (training data has label while serving log has not)
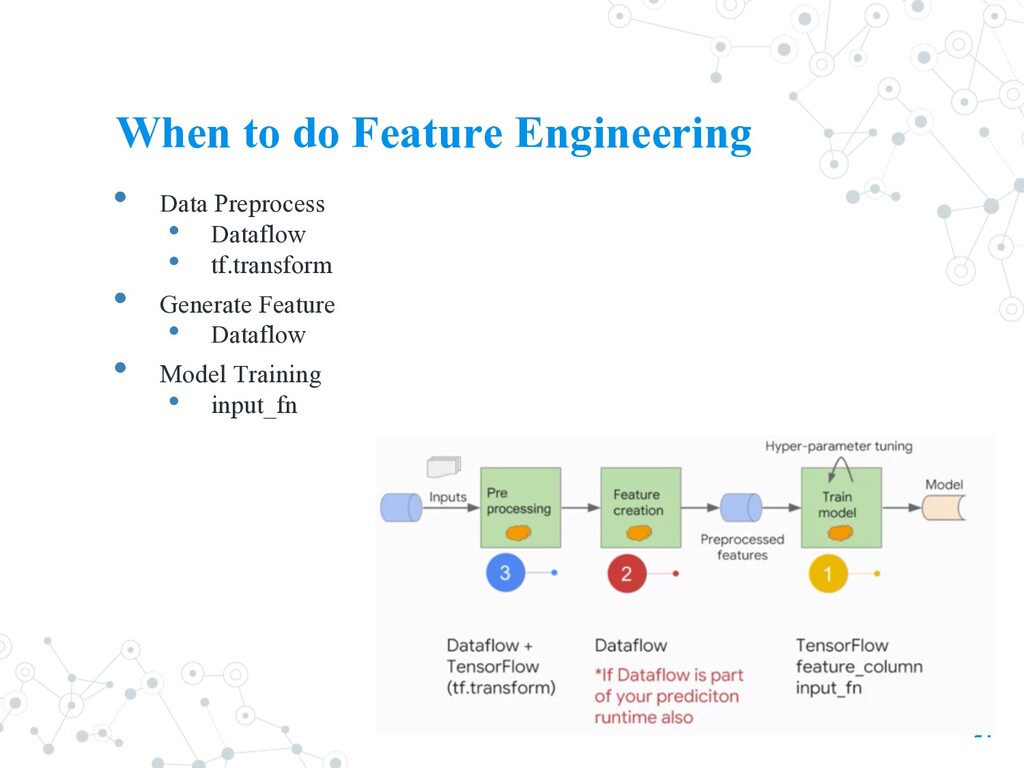
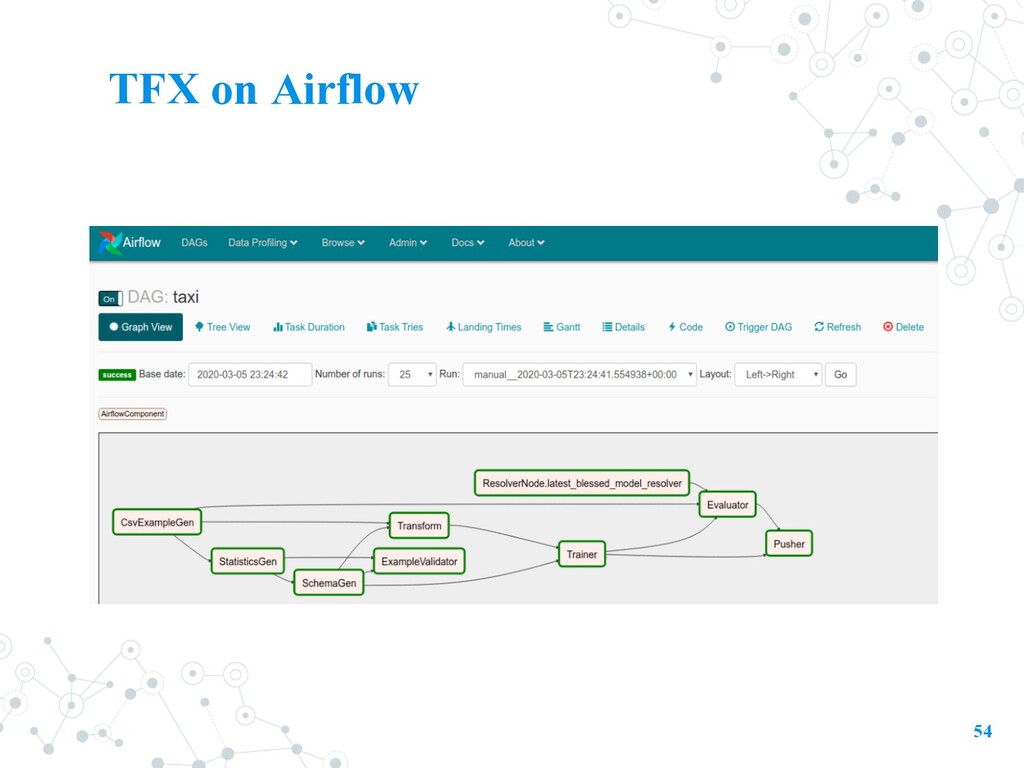
Run these using large scale data processing frameworks (ref) • Local (Airflow) • Apache Beam • Dataflow (Google Cloud Service) • Kubeflow Pipeline • Exporting the pipeline in a way that can be run as part of a TensorFlow graph. (so can use in training and serving) • TFT requires the specification of a schema to parse the data into tensors. • User can 1. manually specifying a schema (by specifying the type of each feature) 2. using the TFDV inferred schema radically simplifies the use of TFT. 18
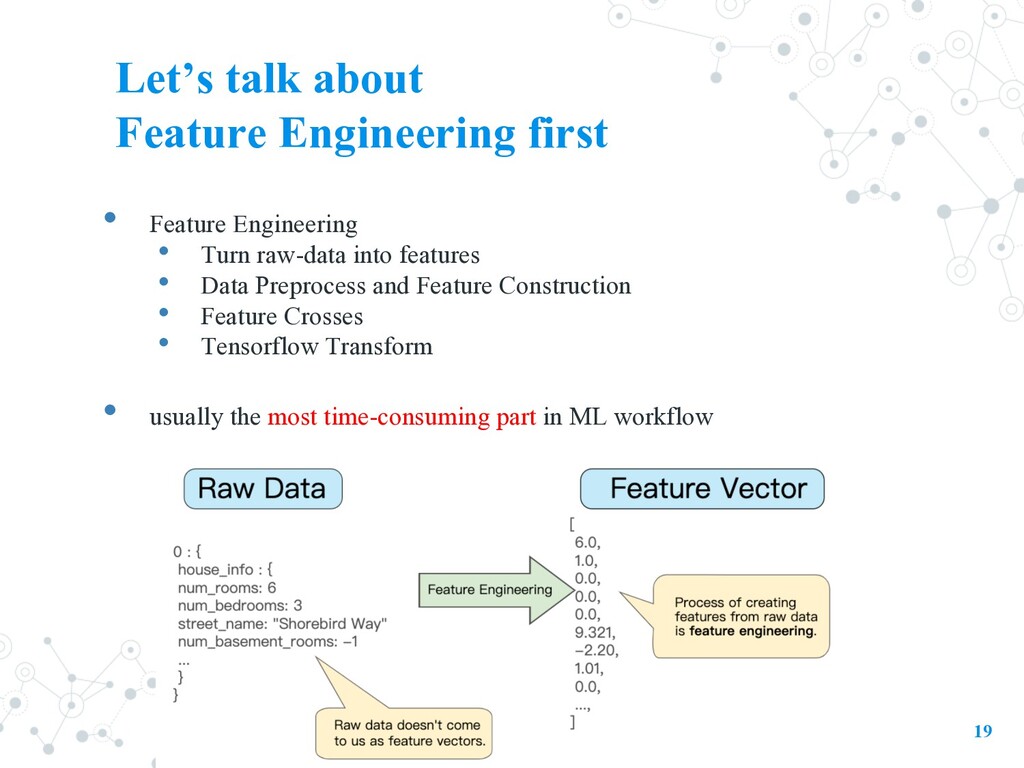
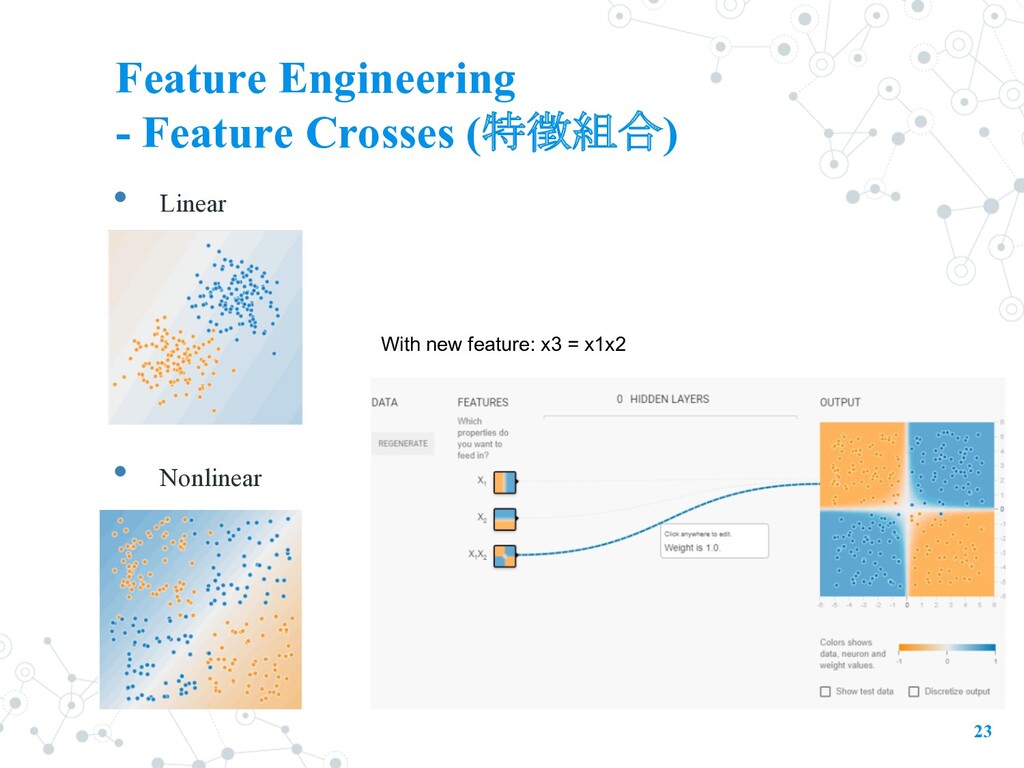
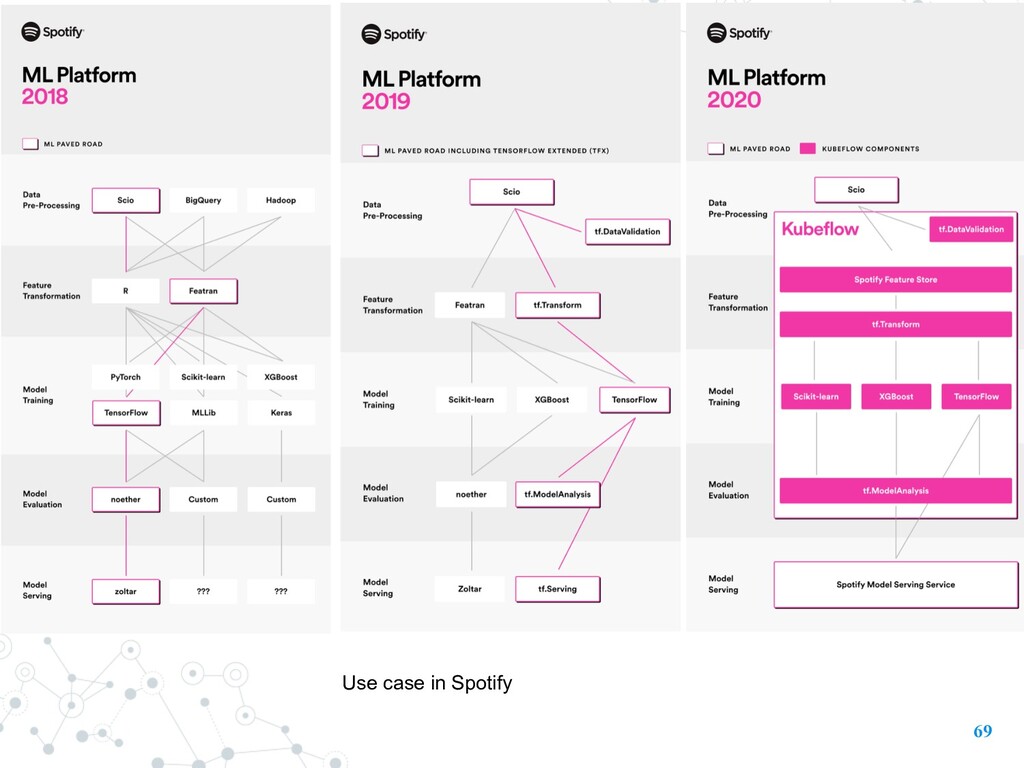
Preprocess and Feature Construction • Feature Crosses • Tensorflow Transform • usually the most time-consuming part in ML workflow 19 Let’s talk about Feature Engineering first
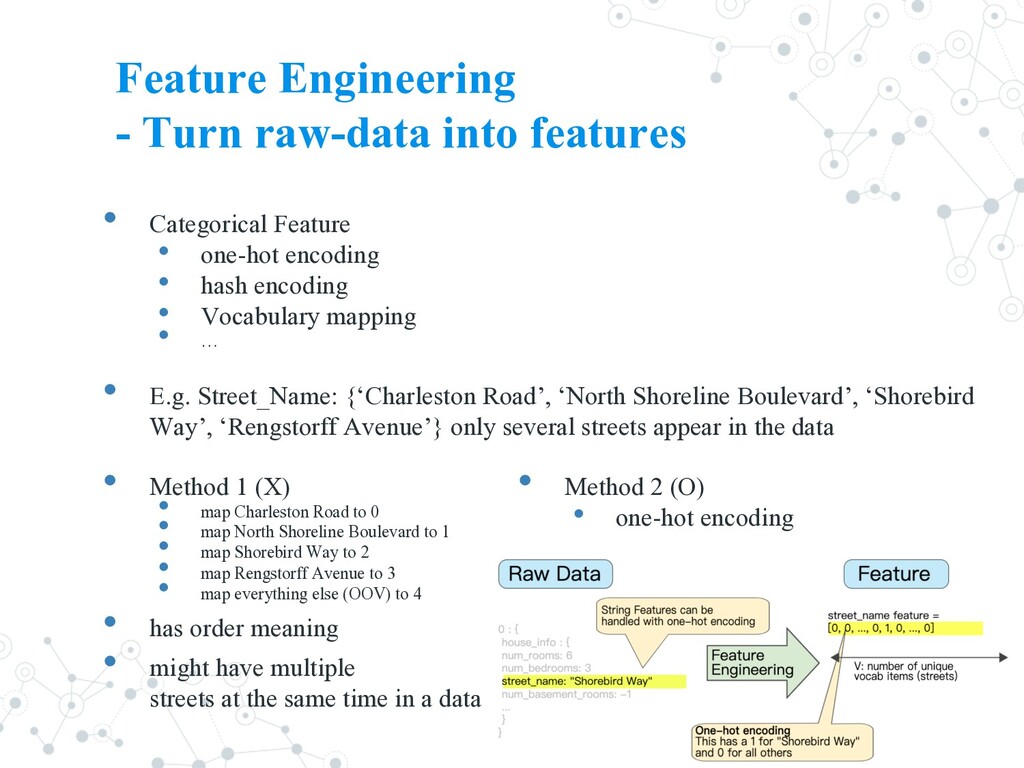
Vocabulary mapping • … • E.g. Street_Name: {‘Charleston Road’, ‘North Shoreline Boulevard’, ‘Shorebird Way’, ‘Rengstorff Avenue’} only several streets appear in the data • Method 1 (X) • map Charleston Road to 0 • map North Shoreline Boulevard to 1 • map Shorebird Way to 2 • map Rengstorff Avenue to 3 • map everything else (OOV) to 4 • has order meaning • might have multiple streets at the same time in a data 21 Feature Engineering - Turn raw-data into features • Method 2 (O) • one-hot encoding
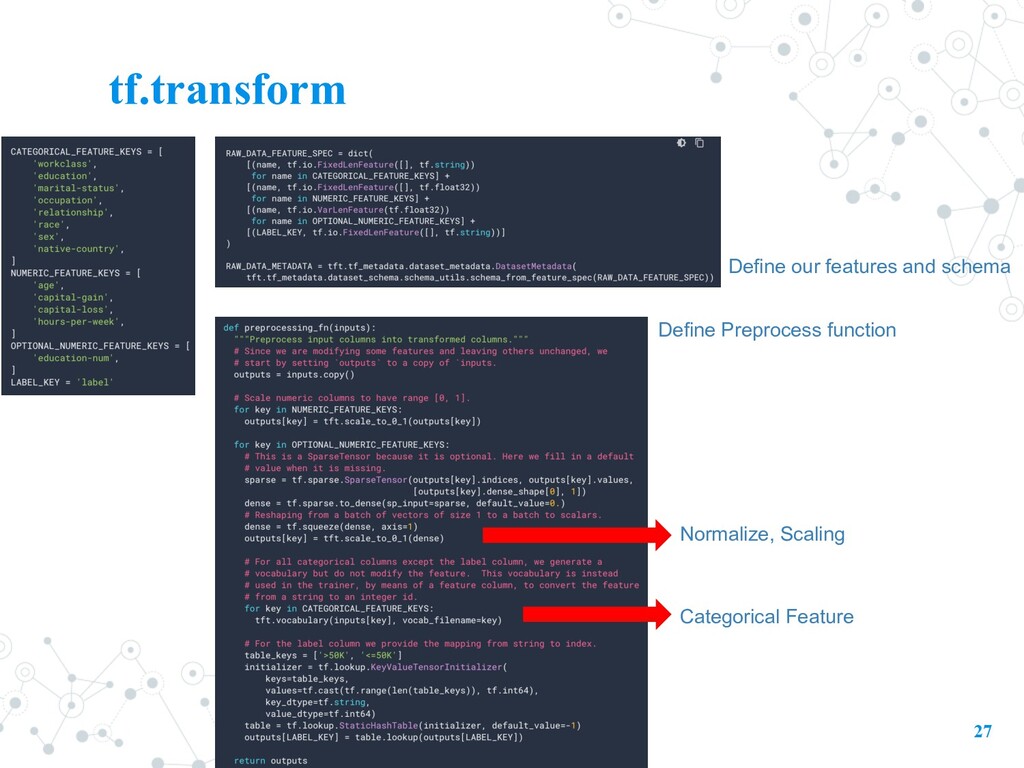
for TensorFlow • creating features that require a full pass over the training dataset. • E.g. • Normalize an input value by using the mean and standard deviation (normalize) • Convert strings to integers by generating a vocabulary over all of the input values (word2vec) • Convert floats to integers by assigning them to buckets, based on the observed data distribution (Bucketing) • TensorFlow => on a single example or a batch of examples. • tf.Transform => extends these capabilities to support full passes over the entire training dataset. (Where we need Apache Beam to help)
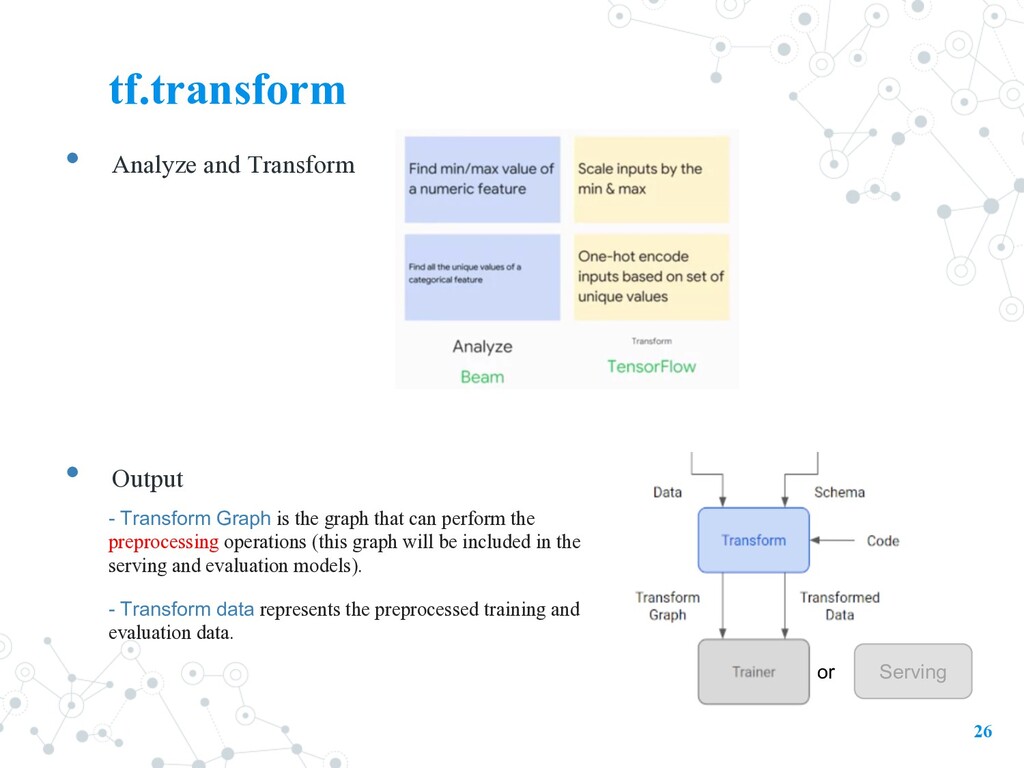
- Transform Graph is the graph that can perform the preprocessing operations (this graph will be included in the serving and evaluation models). - Transform data represents the preprocessed training and evaluation data.
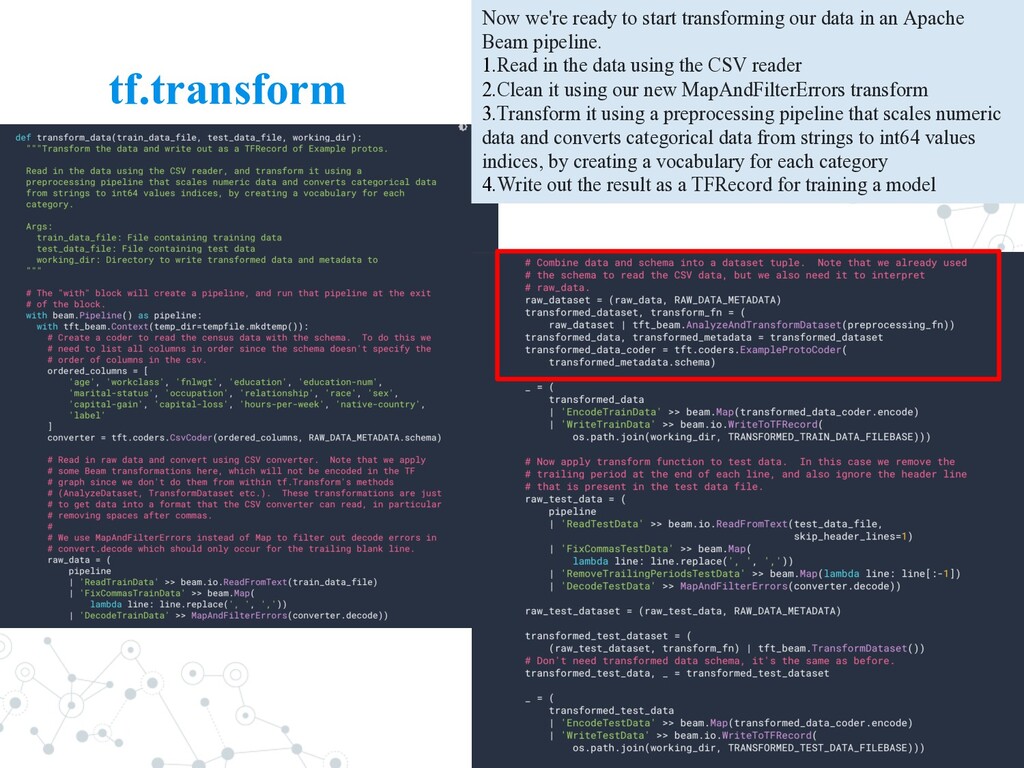
in an Apache Beam pipeline. 1.Read in the data using the CSV reader 2.Clean it using our new MapAndFilterErrors transform 3.Transform it using a preprocessing pipeline that scales numeric data and converts categorical data from strings to int64 values indices, by creating a vocabulary for each category 4.Write out the result as a TFRecord for training a model
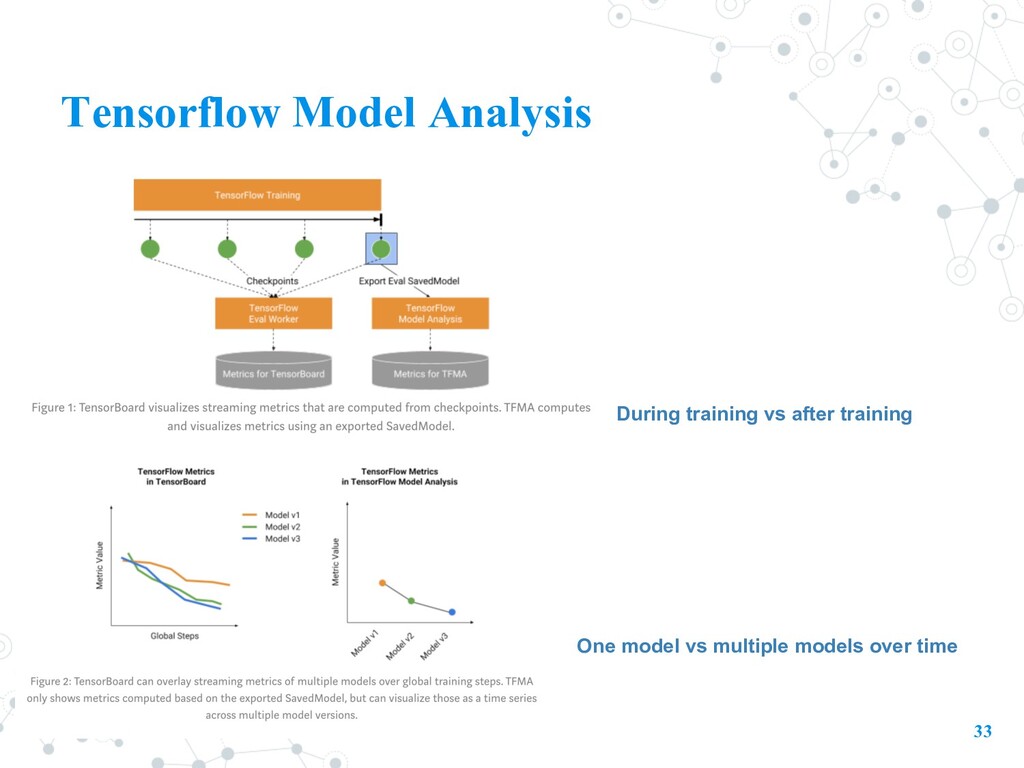
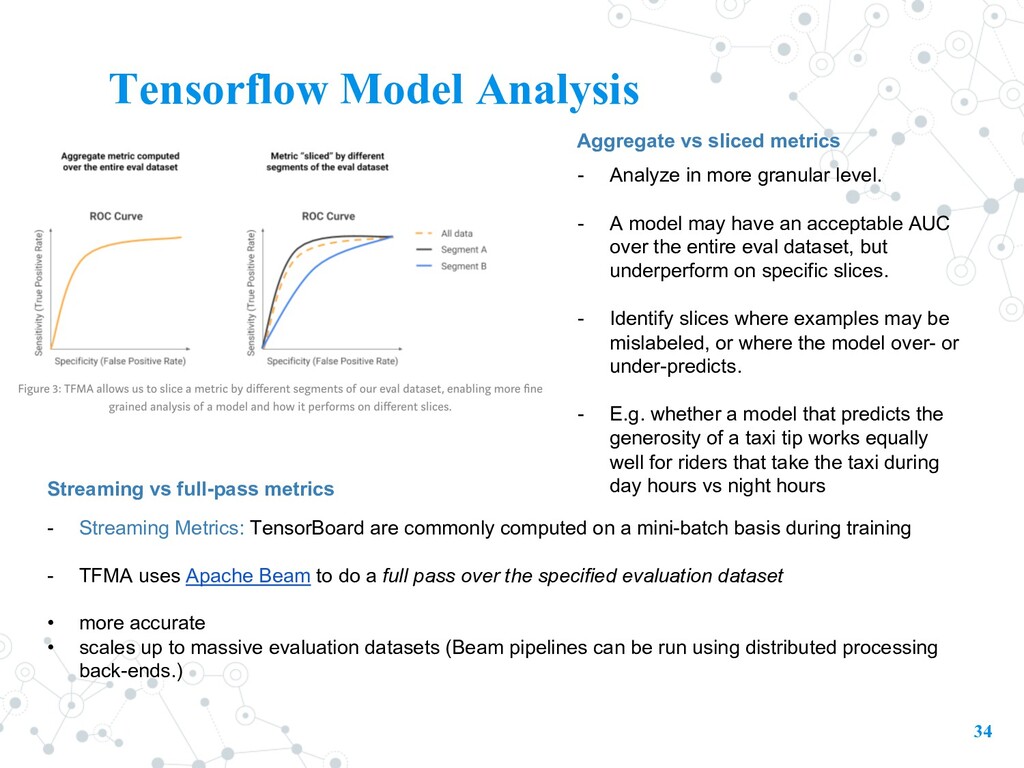
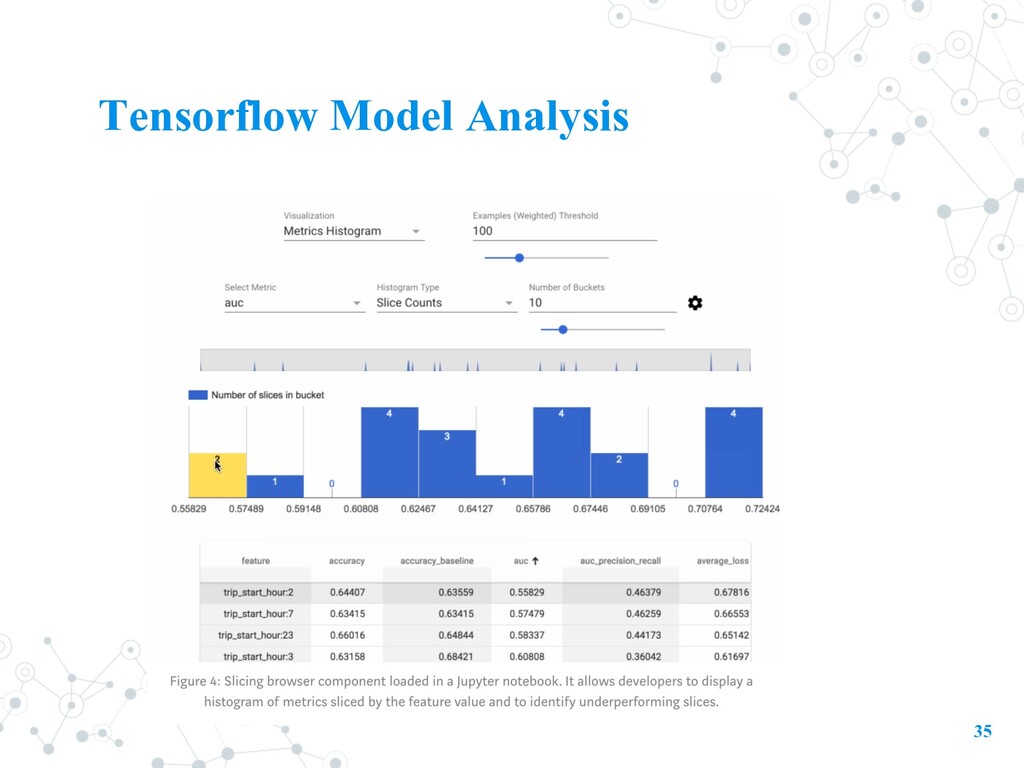
models. • evaluate models on large amounts of data in a distributed manner, using the same metrics defined in their trainer. • combines the power of TensorFlow and Apache Beam to compute and visualize evaluation metrics. • Goal: Before deploying, ML developers need to evaluate it to ensure that it meets specific quality thresholds and behaves as expected for all relevant slices of data.
full-pass metrics - Analyze in more granular level. - A model may have an acceptable AUC over the entire eval dataset, but underperform on specific slices. - Identify slices where examples may be mislabeled, or where the model over- or under-predicts. - E.g. whether a model that predicts the generosity of a taxi tip works equally well for riders that take the taxi during day hours vs night hours - Streaming Metrics: TensorBoard are commonly computed on a mini-batch basis during training - TFMA uses Apache Beam to do a full pass over the specified evaluation dataset • more accurate • scales up to massive evaluation datasets (Beam pipelines can be run using distributed processing back-ends.)
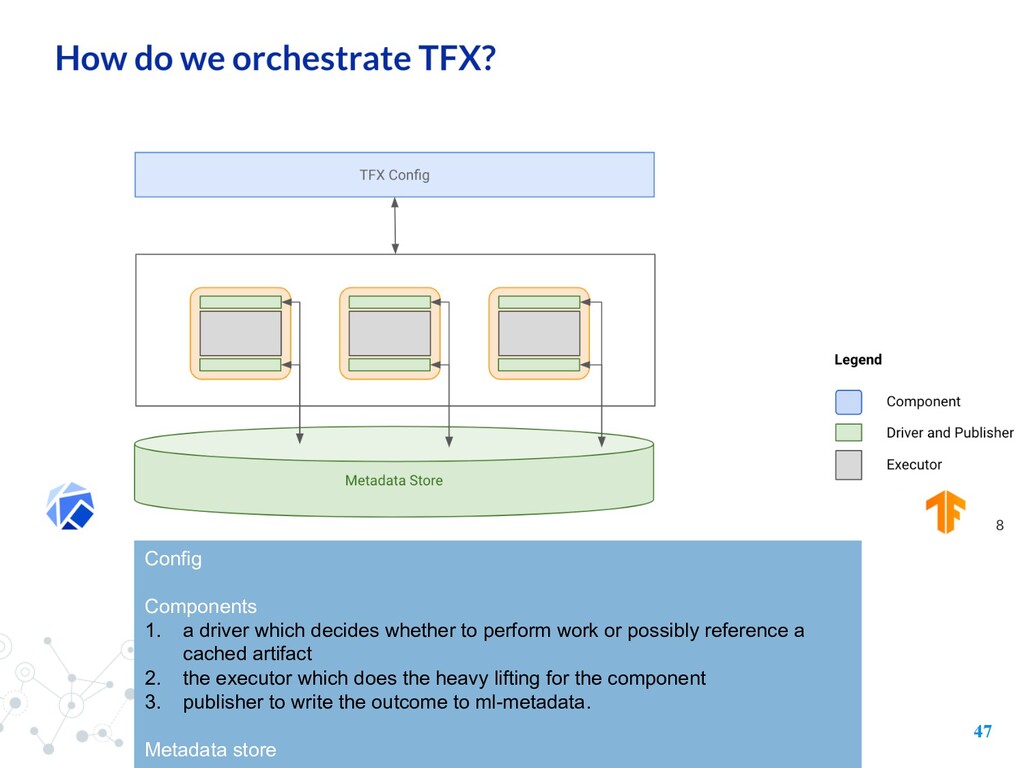
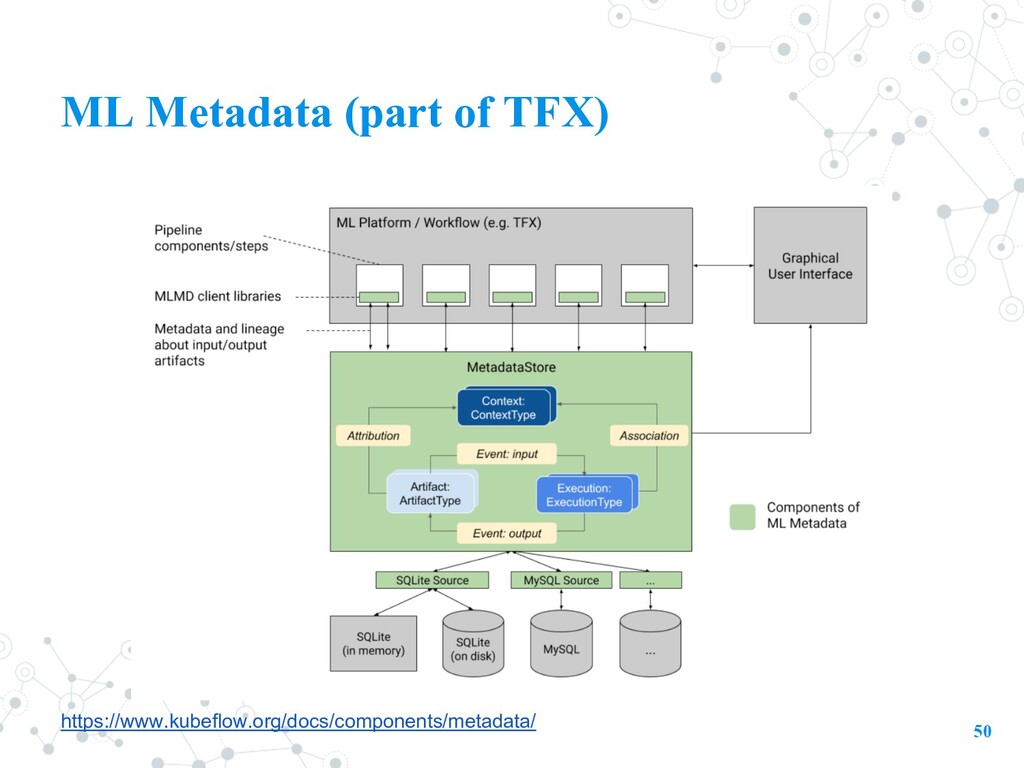
an orchestrator such as Apache Airflow, Kubeflow Pipelines, or Apache Beam to orchestrate a pre-defined pipeline graph of TFX components. • Interactive notebook(local): the notebook itself is the orchestrator, running each TFX component as you execute the notebook cells. Metadata • Production: MLMD stores metadata properties in a database such as MySQL or SQLite, and stores the metadata payloads in a persistent store such as on your filesystem. • Interactive notebook(local): both properties and payloads are stored in an ephemeral SQLite database in the /tmp directory on the Jupyter notebook or Colab server.
perform work or possibly reference a cached artifact 2. the executor which does the heavy lifting for the component 3. publisher to write the outcome to ml-metadata. Metadata store
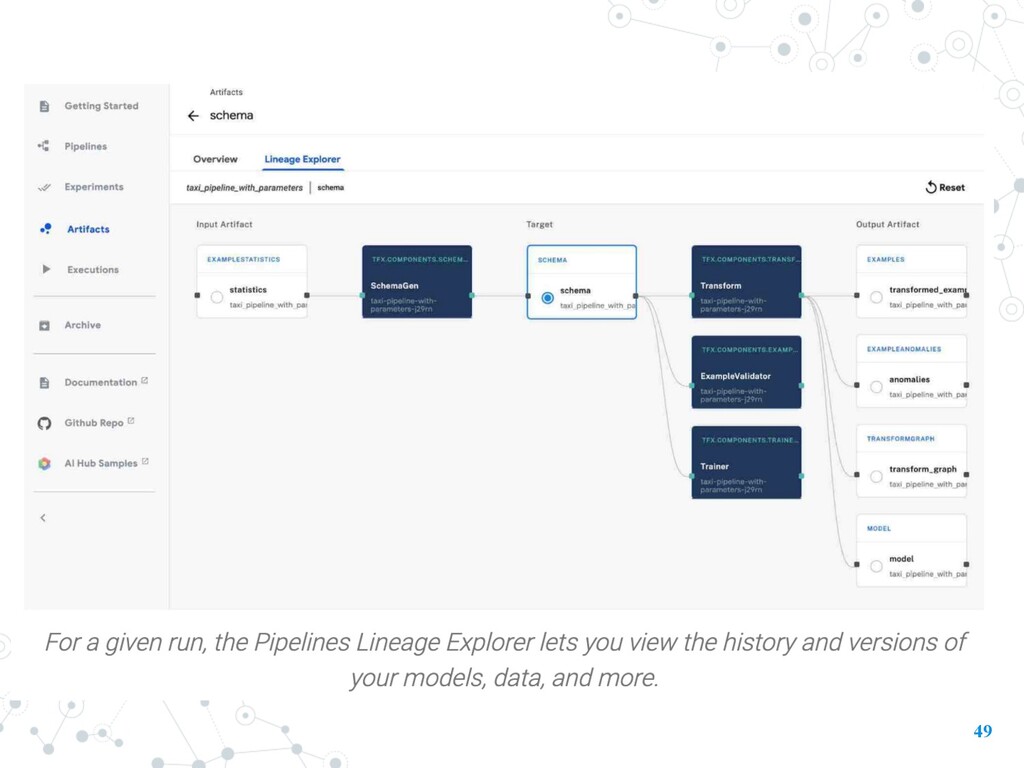
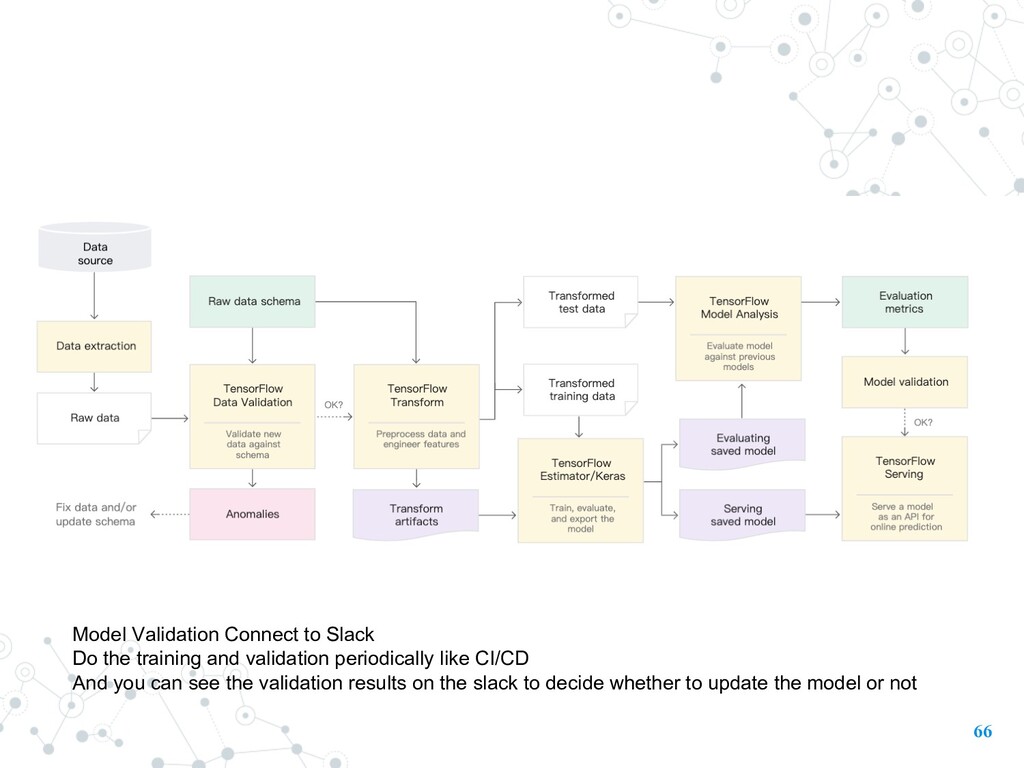
control, you shouldn’t train models without lineage tracking. Lineage Tracking shows the history and versions of your models, data, and more. source: https://docs.google.com/presentation/d/1aMmJUz7r7Toky4nGZ1bItWKfXW4kSMbs4cofFeyKE-M/edit?usp=sharing
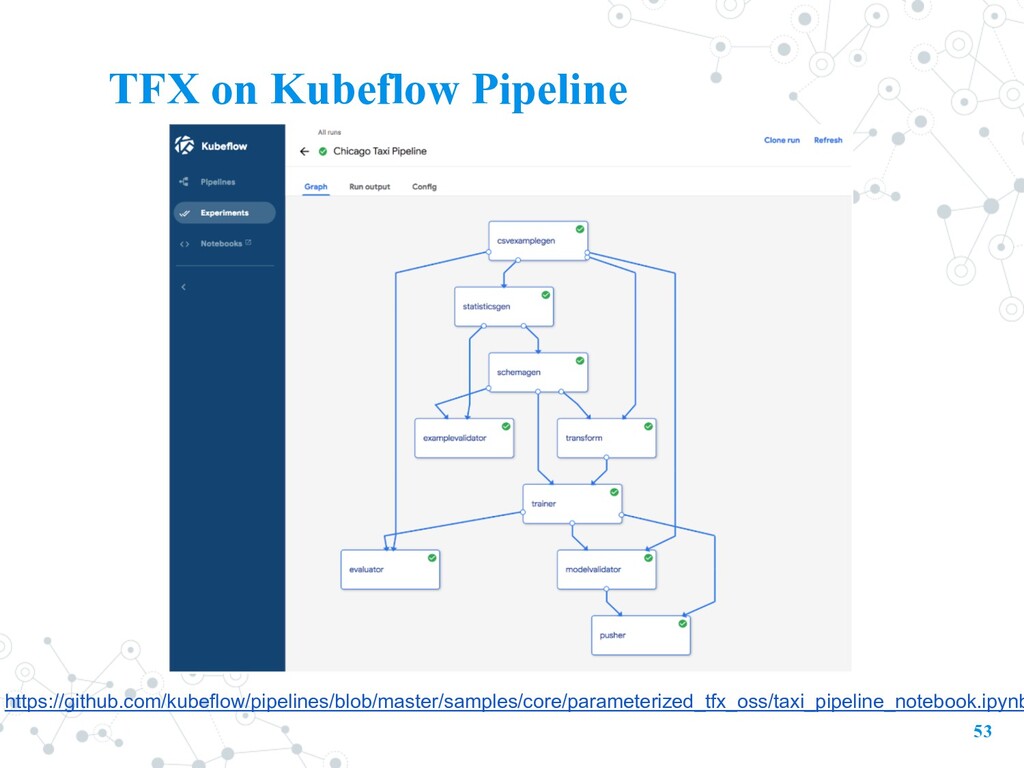
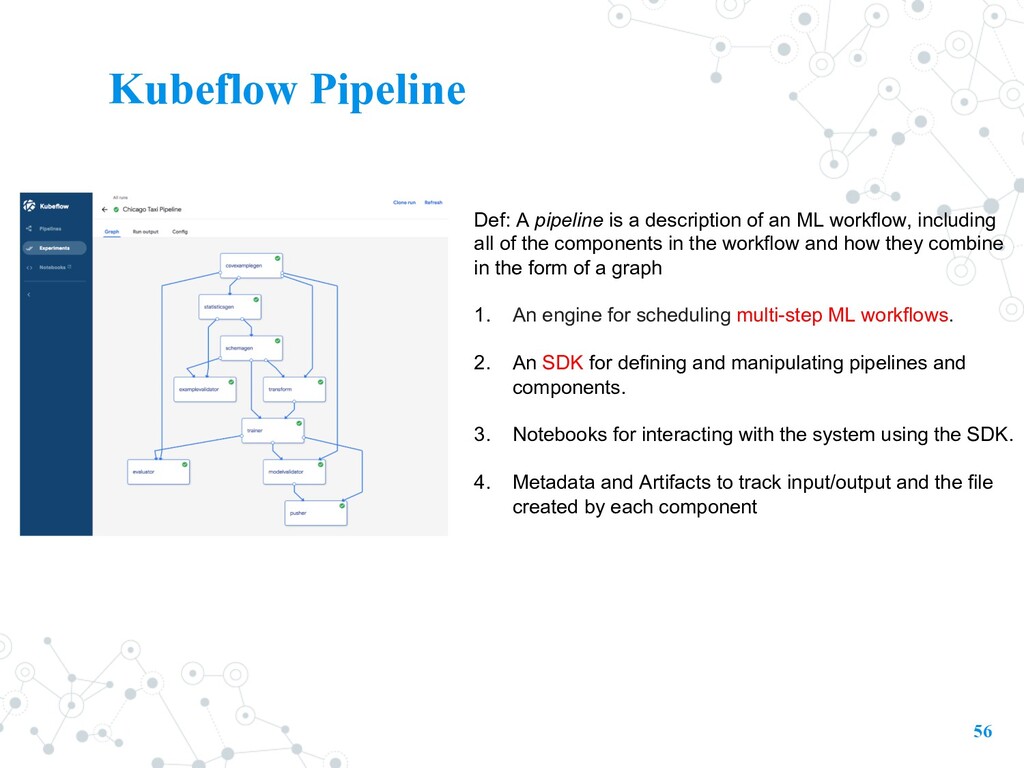
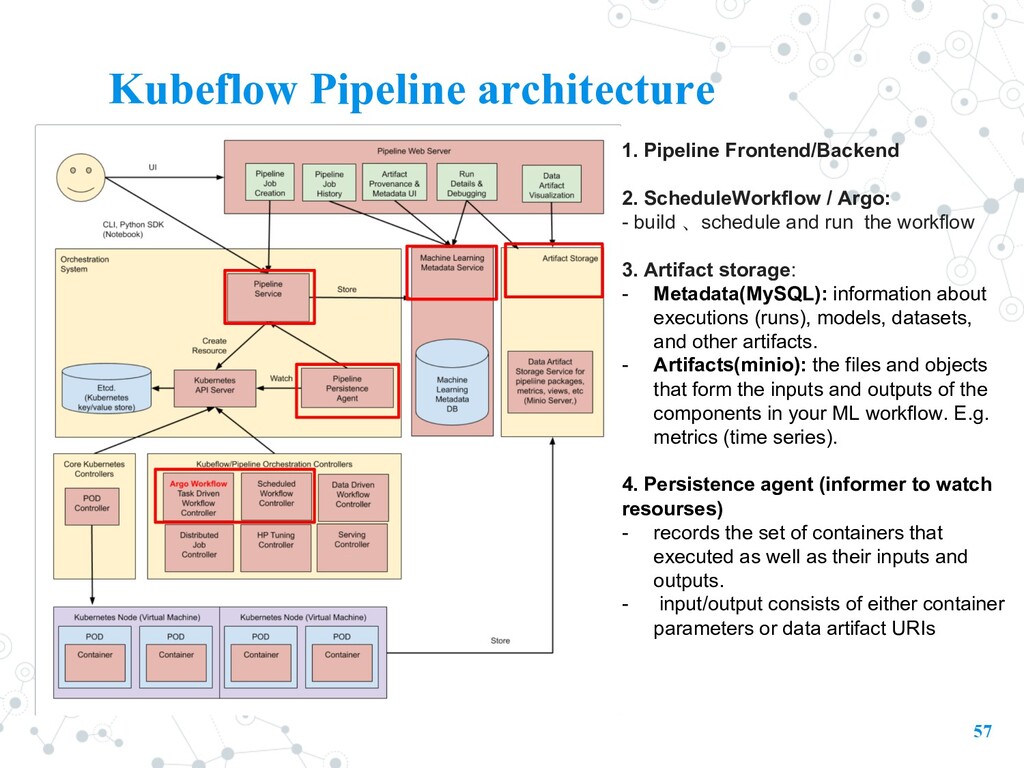
workflow, including all of the components in the workflow and how they combine in the form of a graph 1. An engine for scheduling multi-step ML workflows. 2. An SDK for defining and manipulating pipelines and components. 3. Notebooks for interacting with the system using the SDK. 4. Metadata and Artifacts to track input/output and the file created by each component Kubeflow Pipeline
Argo: - build 、schedule and run the workflow 3. Artifact storage: - Metadata(MySQL): information about executions (runs), models, datasets, and other artifacts. - Artifacts(minio): the files and objects that form the inputs and outputs of the components in your ML workflow. E.g. metrics (time series). 4. Persistence agent (informer to watch resourses) - records the set of containers that executed as well as their inputs and outputs. - input/output consists of either container parameters or data artifact URIs
a self-contained set of user code, packaged as a Docker image, that performs one step in the pipeline. Artifacts of this components Container v1 spec (might add k8sresource/daemon… in the future) Input/output and the type
is in the container image. 1. define code 2. build image 3. turn into kfp components • Turn Python function into Component directly • Build Python module and Dockerfile to build image and then define Components • Use Reusable Components Demo 59 Ref: https://github.com/kubeflow/pipelines/tree/master/samples/tutorials/mnist https://github.com/ChanYiLin/kfp_notebook_example
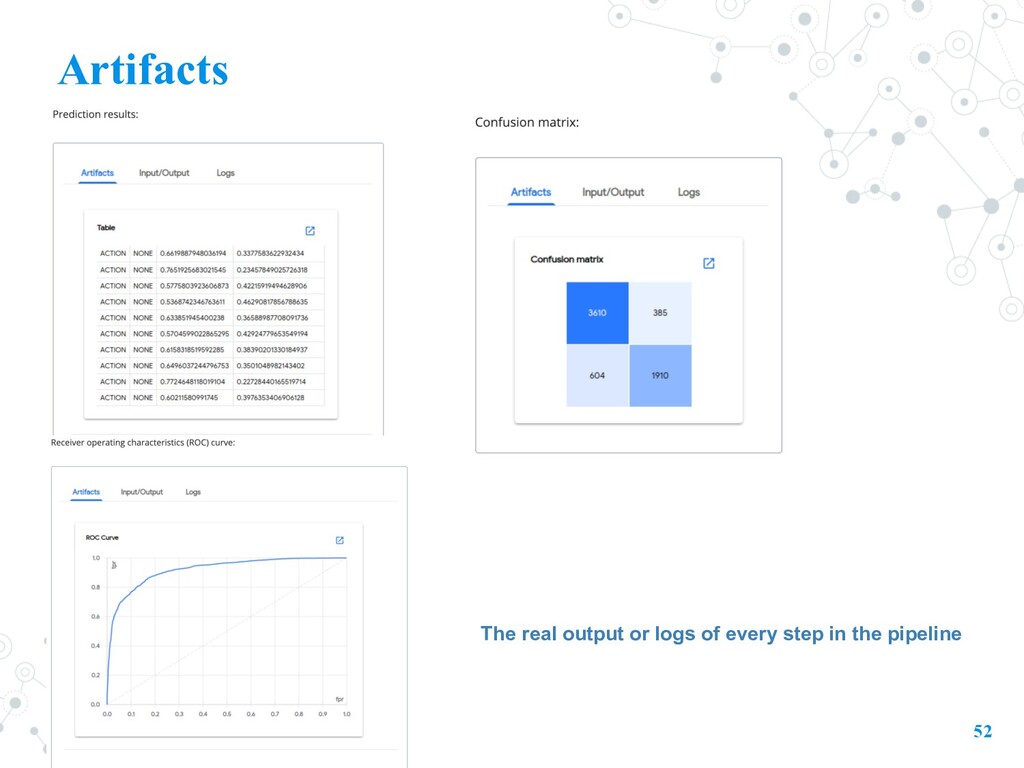
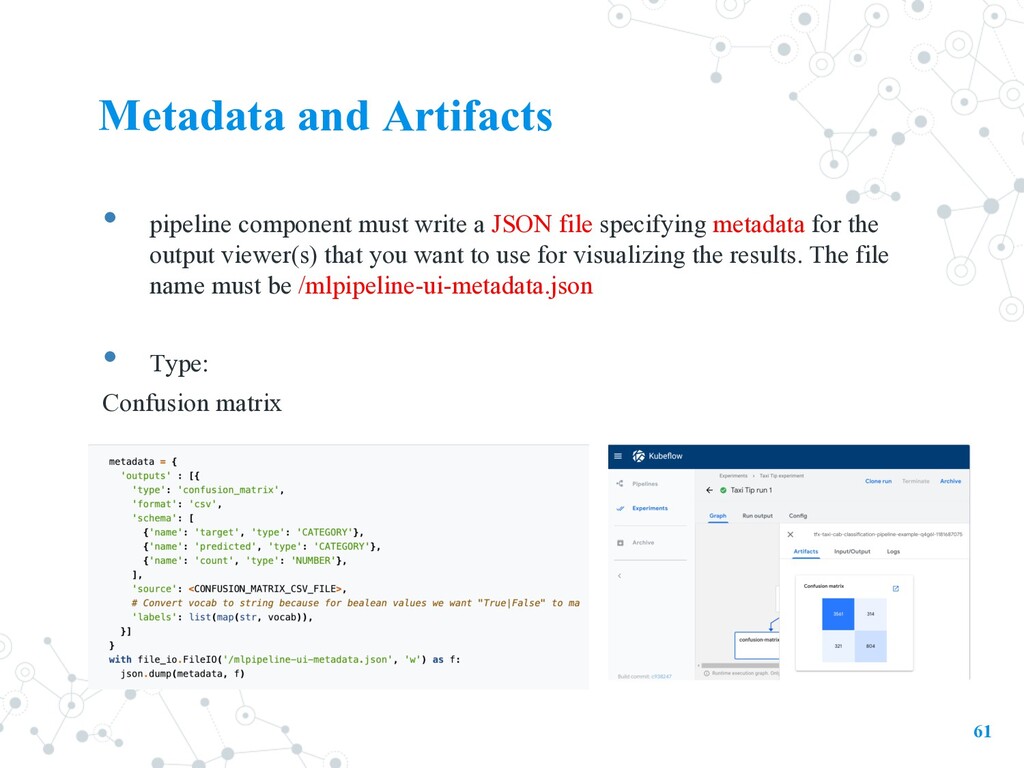
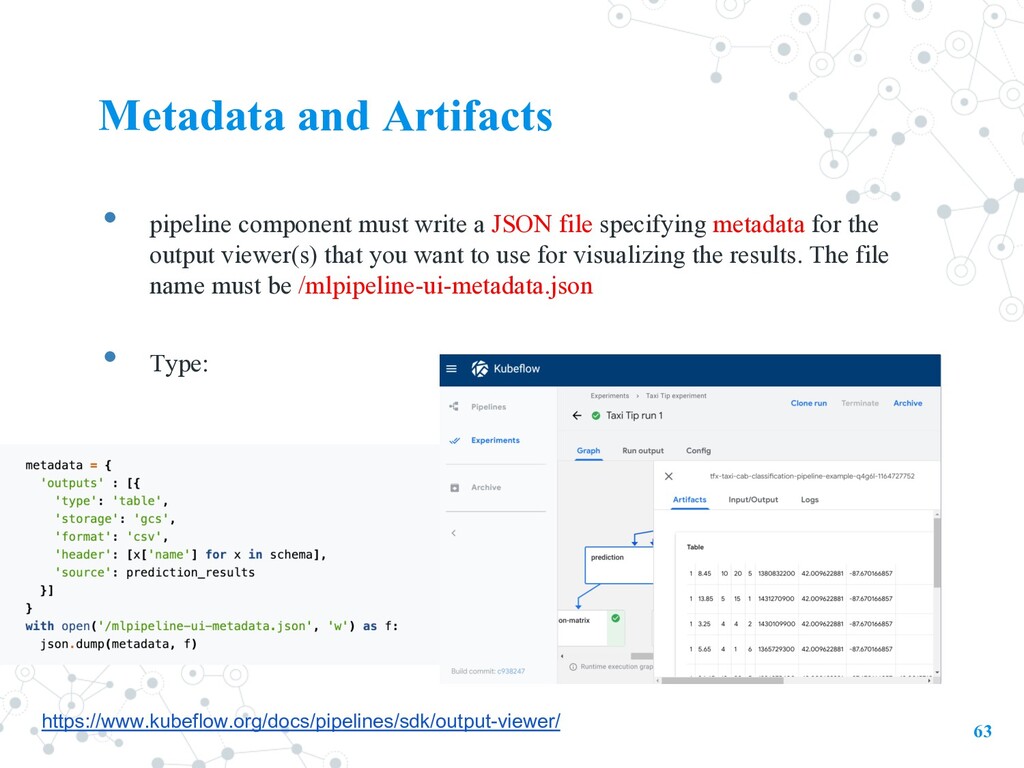
file specifying metadata for the output viewer(s) that you want to use for visualizing the results. The file name must be /mlpipeline-ui-metadata.json • Type: Confusion matrix 61
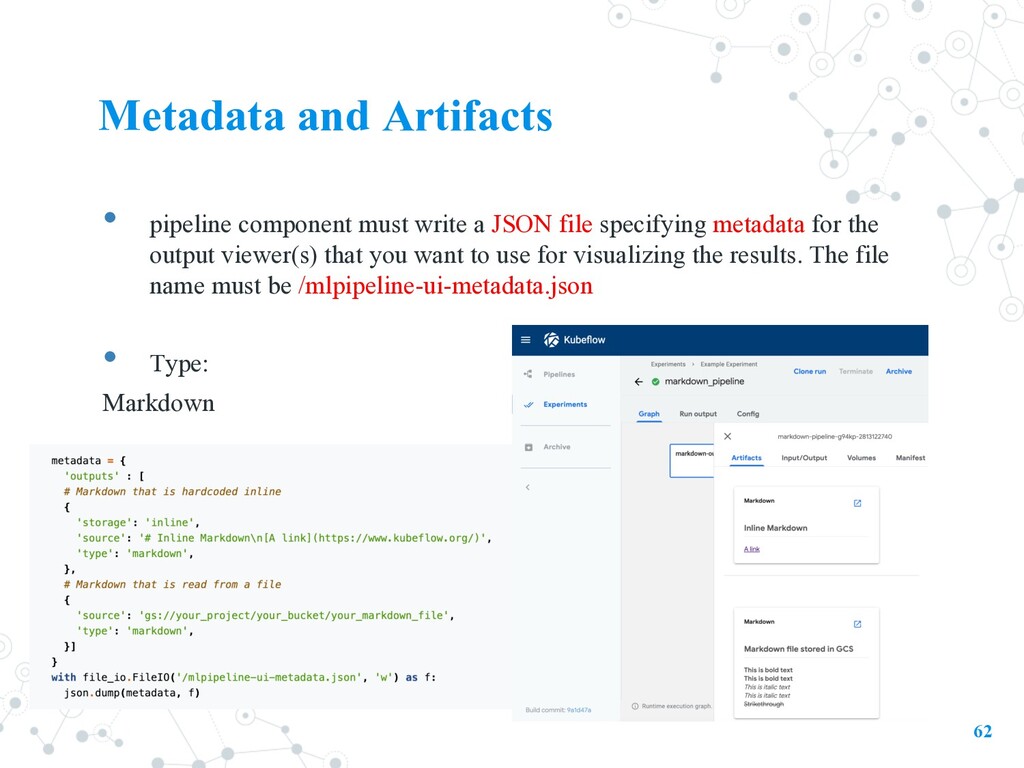
file specifying metadata for the output viewer(s) that you want to use for visualizing the results. The file name must be /mlpipeline-ui-metadata.json • Type: Markdown 62
file specifying metadata for the output viewer(s) that you want to use for visualizing the results. The file name must be /mlpipeline-ui-metadata.json • Type: 63 https://www.kubeflow.org/docs/pipelines/sdk/output-viewer/
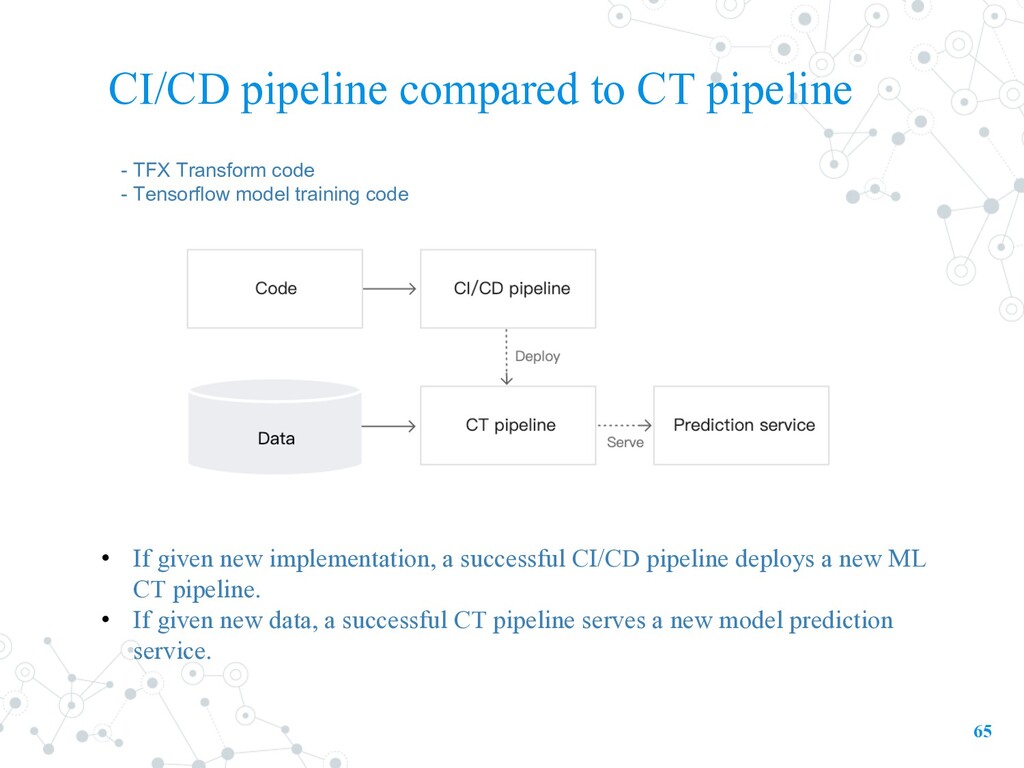
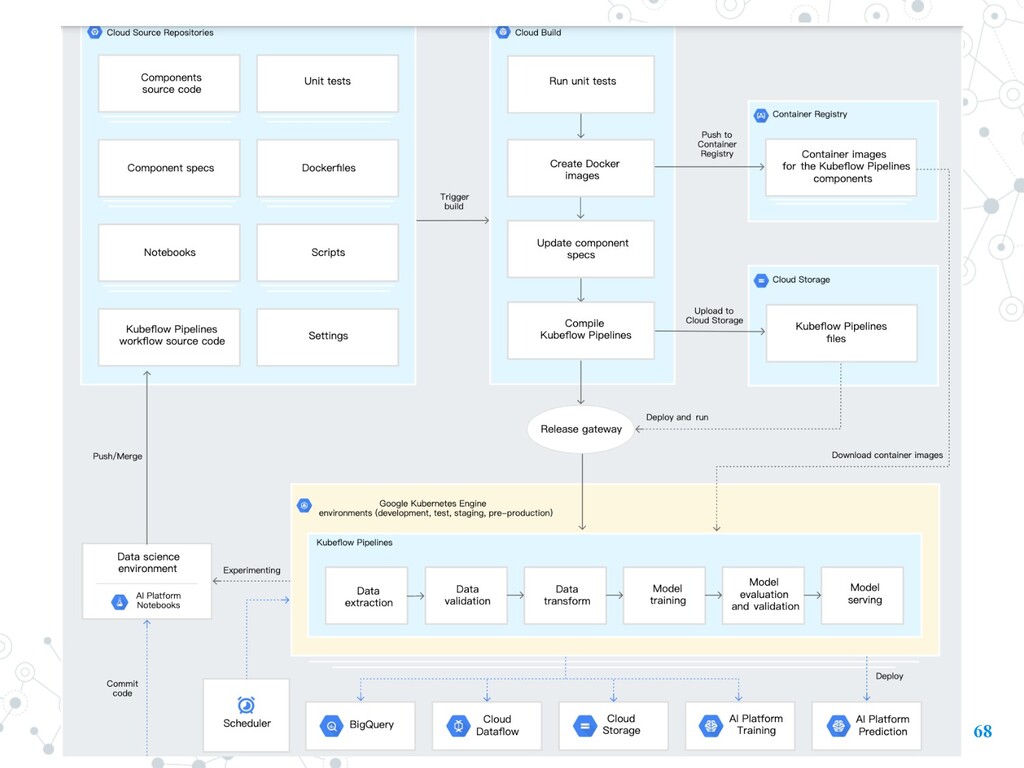
code - Tensorflow model training code • If given new implementation, a successful CI/CD pipeline deploys a new ML CT pipeline. • If given new data, a successful CT pipeline serves a new model prediction service.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![46 more details: https://www.tensorflow.org/tfx/tutorials/tfx/components#evaluator [Tensorflow Data Validation] stats = tfdv.generate_statistics_from_csv(input_data)](https://files.speakerdeck.com/presentations/04d2733765f2463c85180801078a7549/slide_45.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}