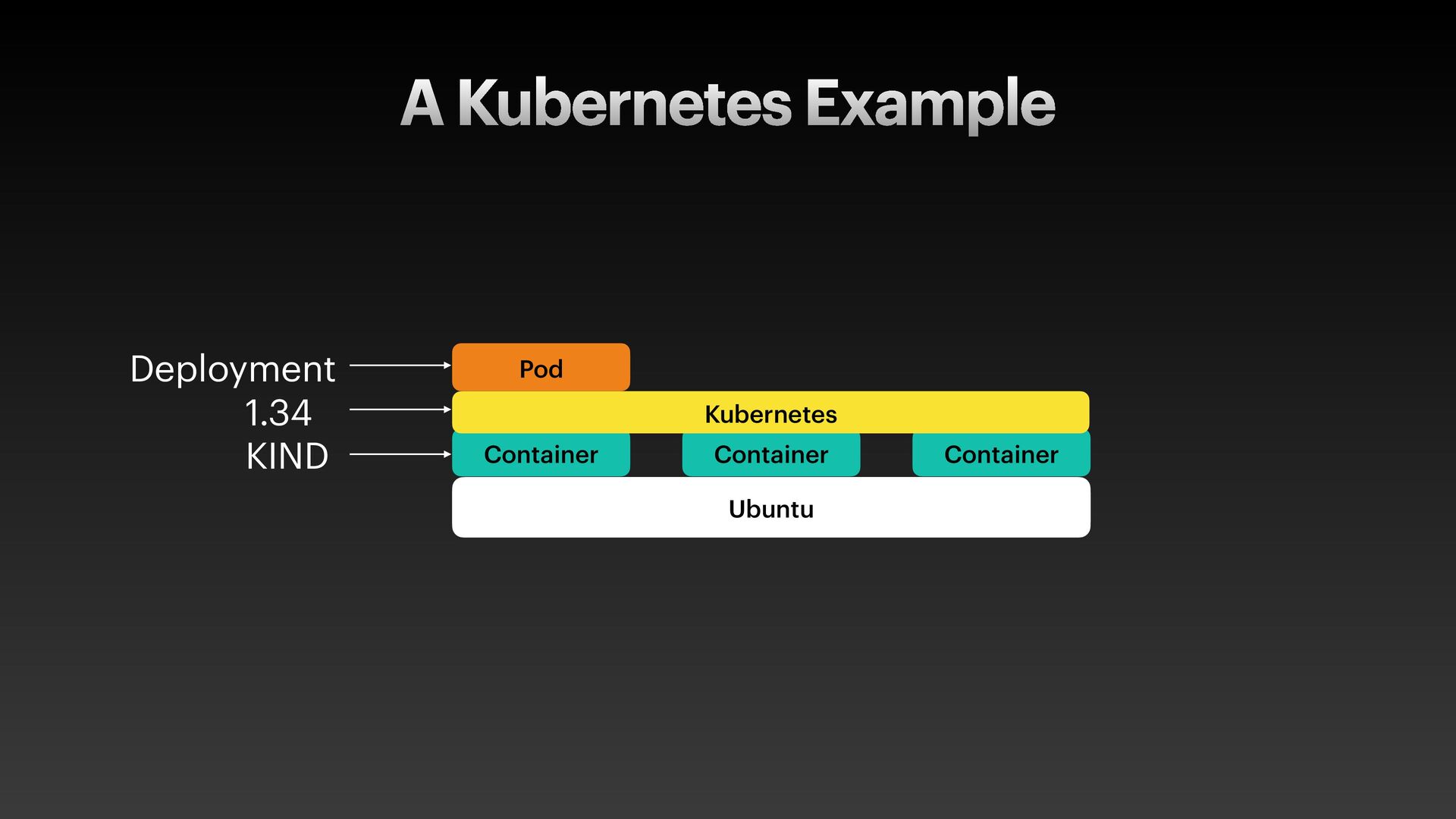
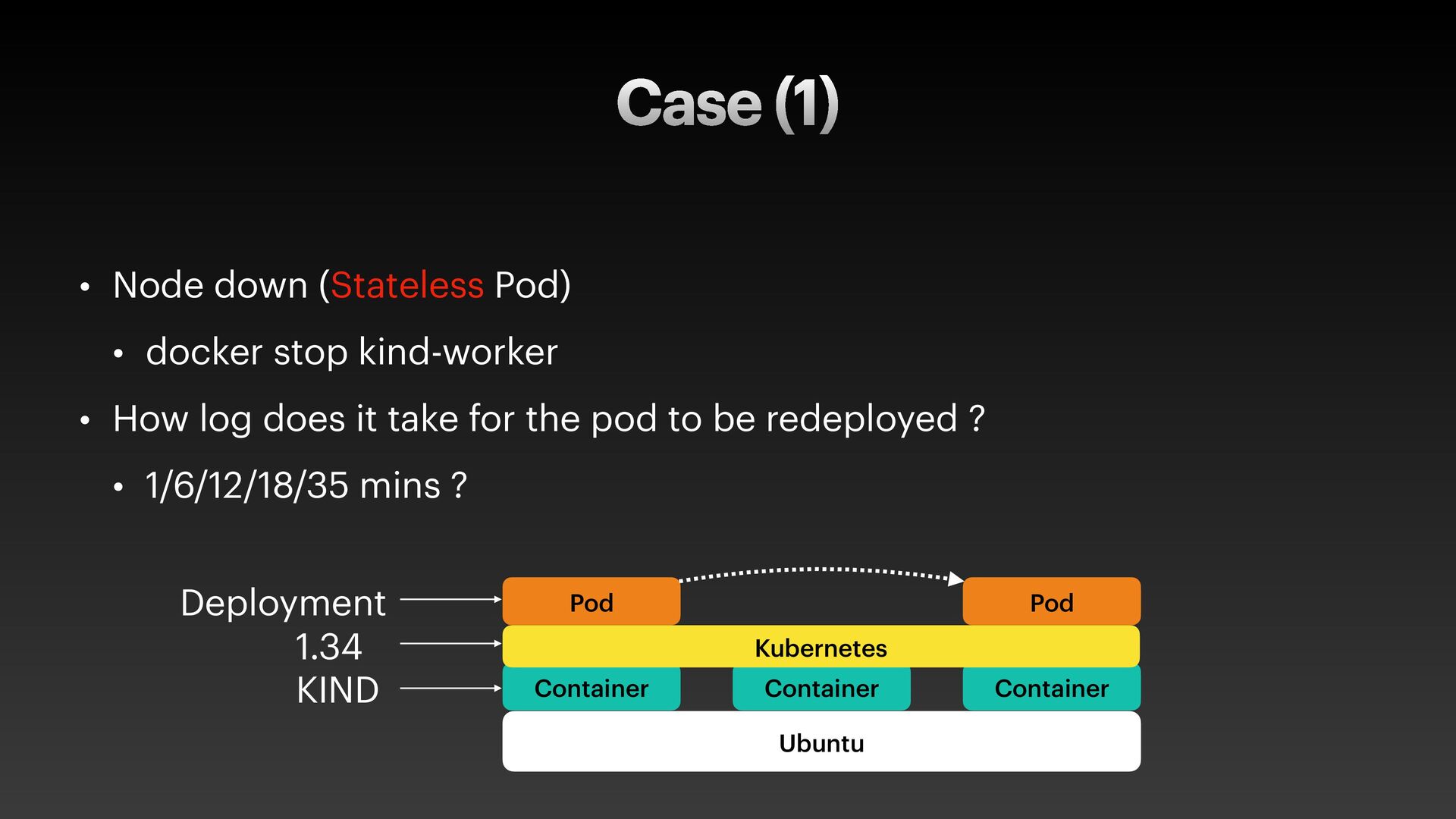
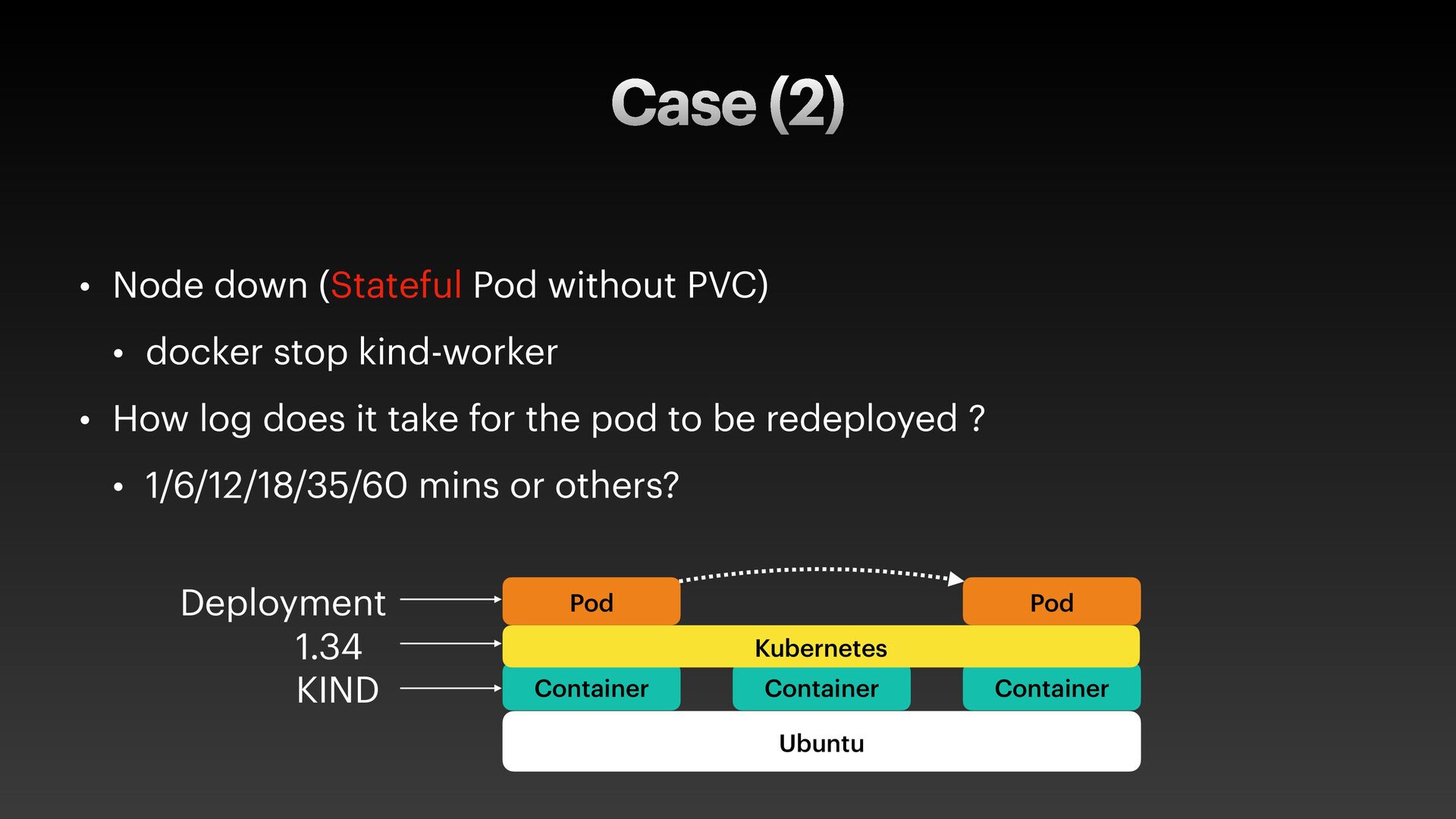
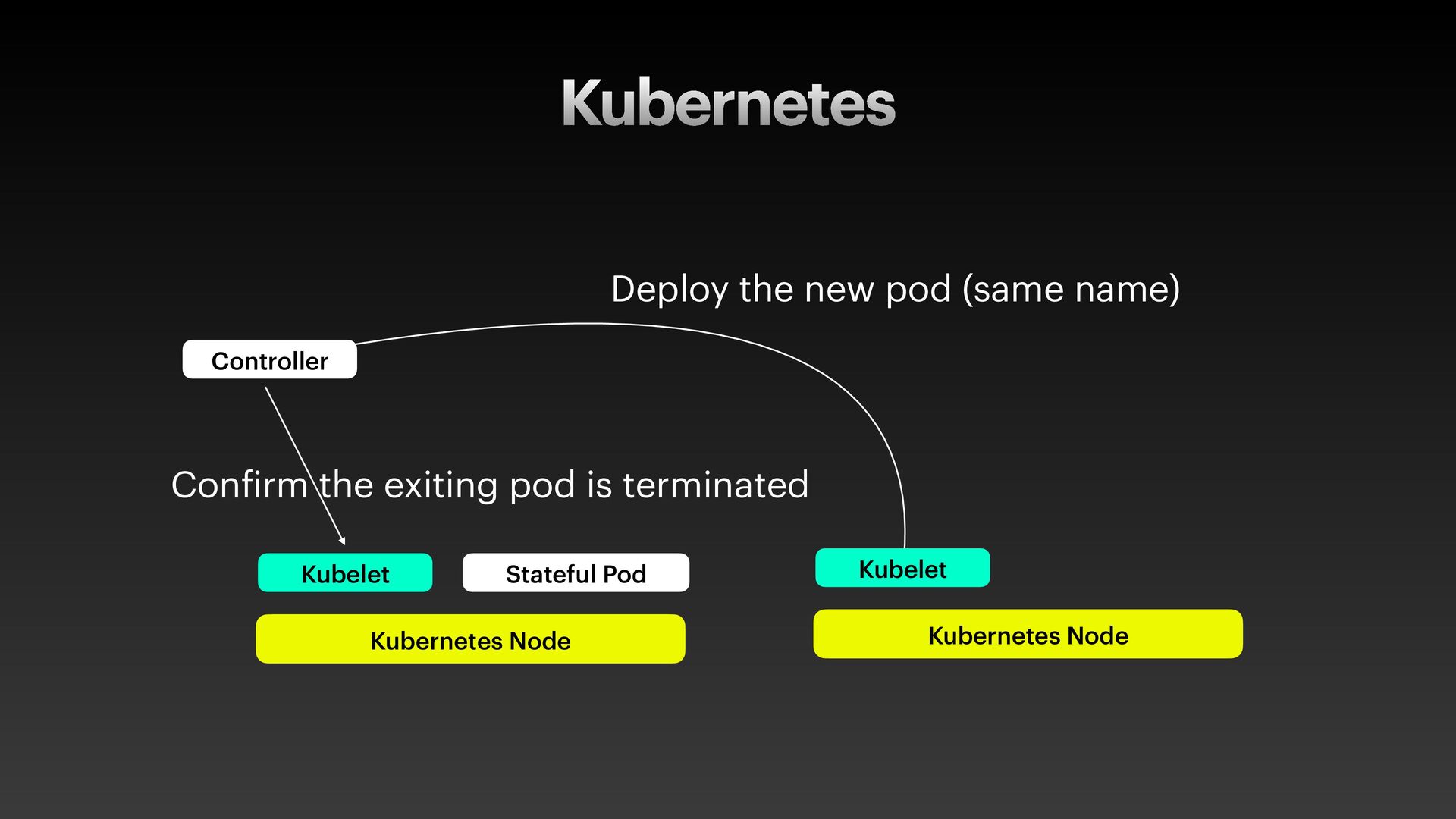
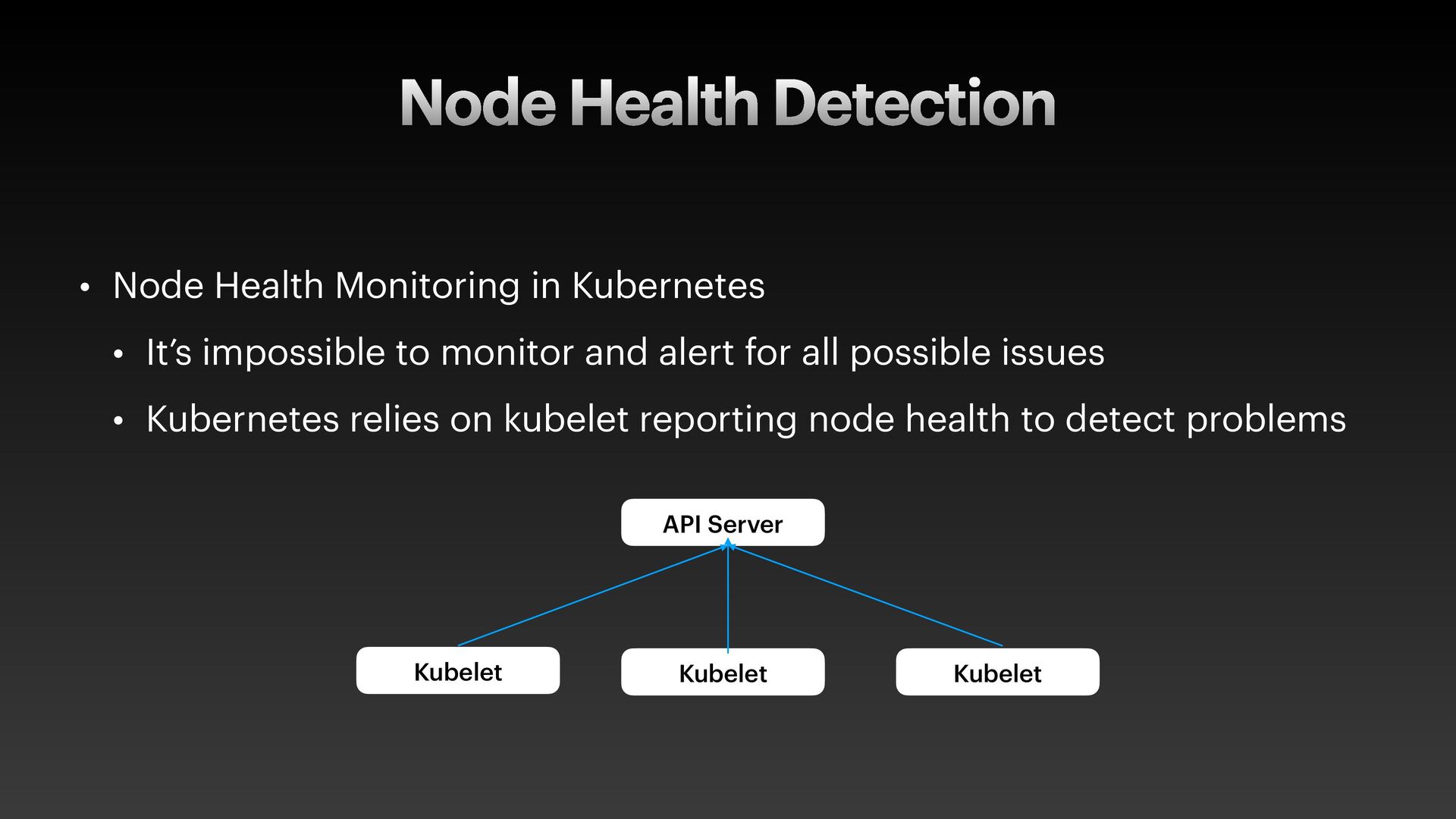
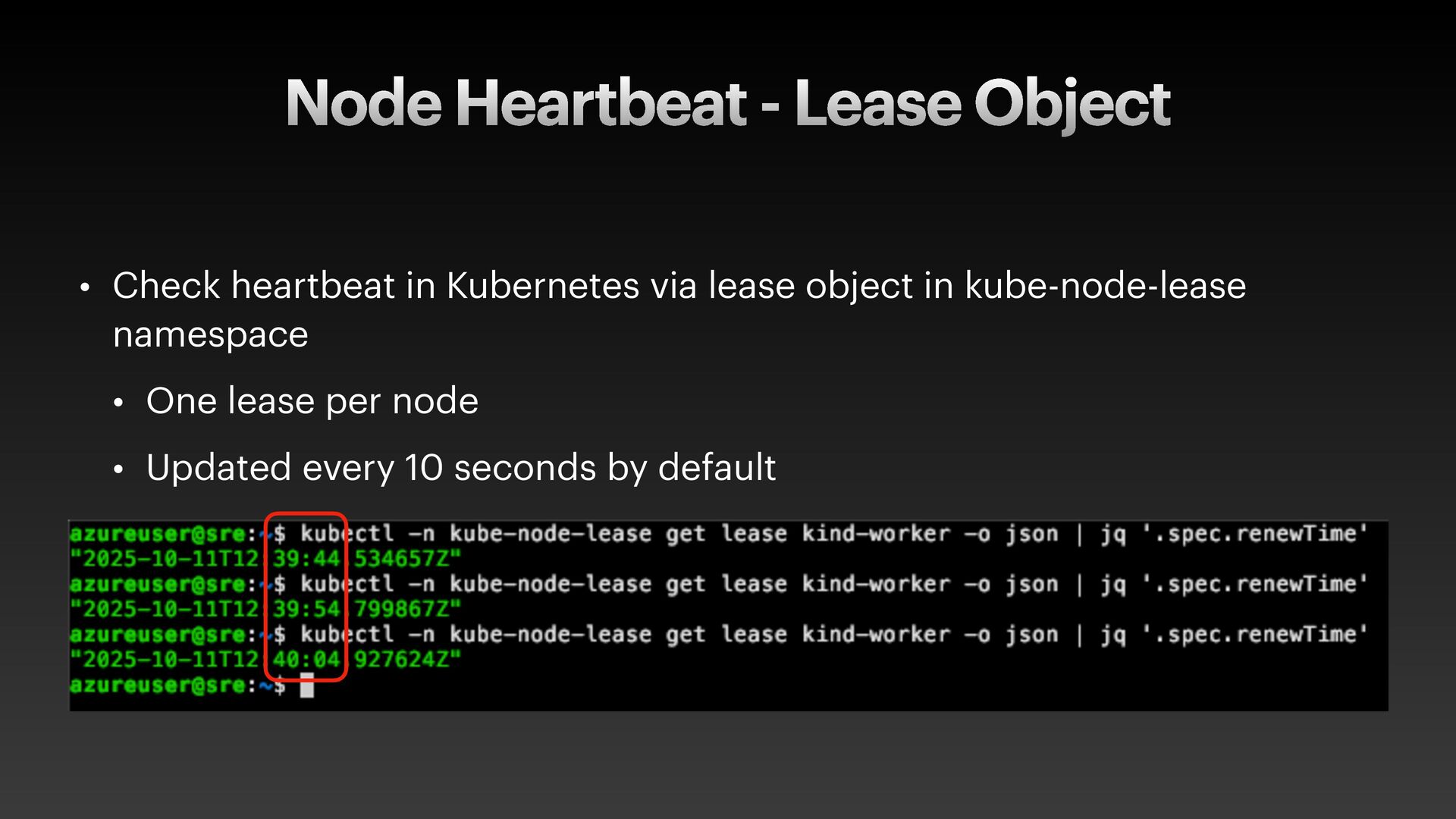
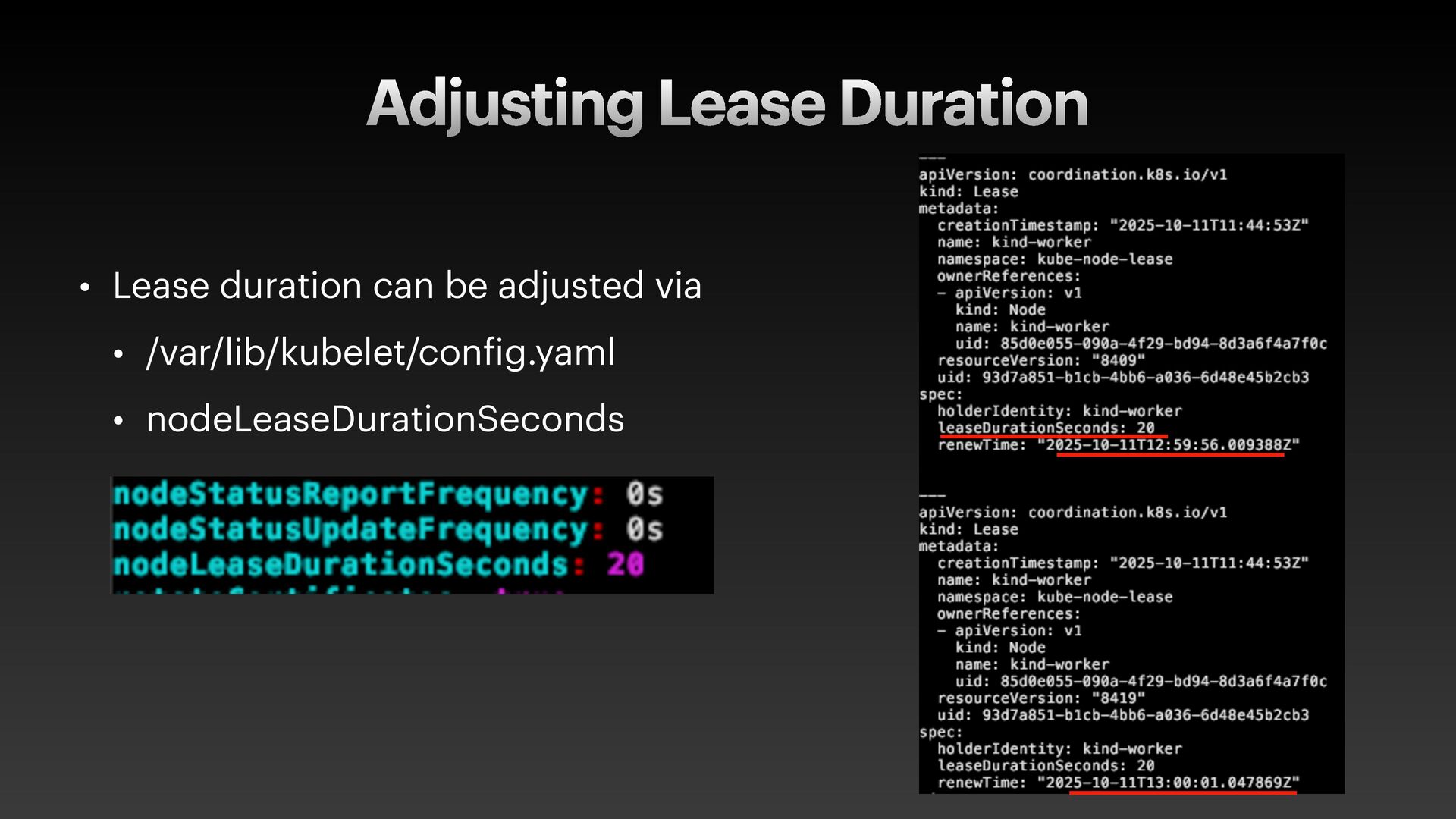
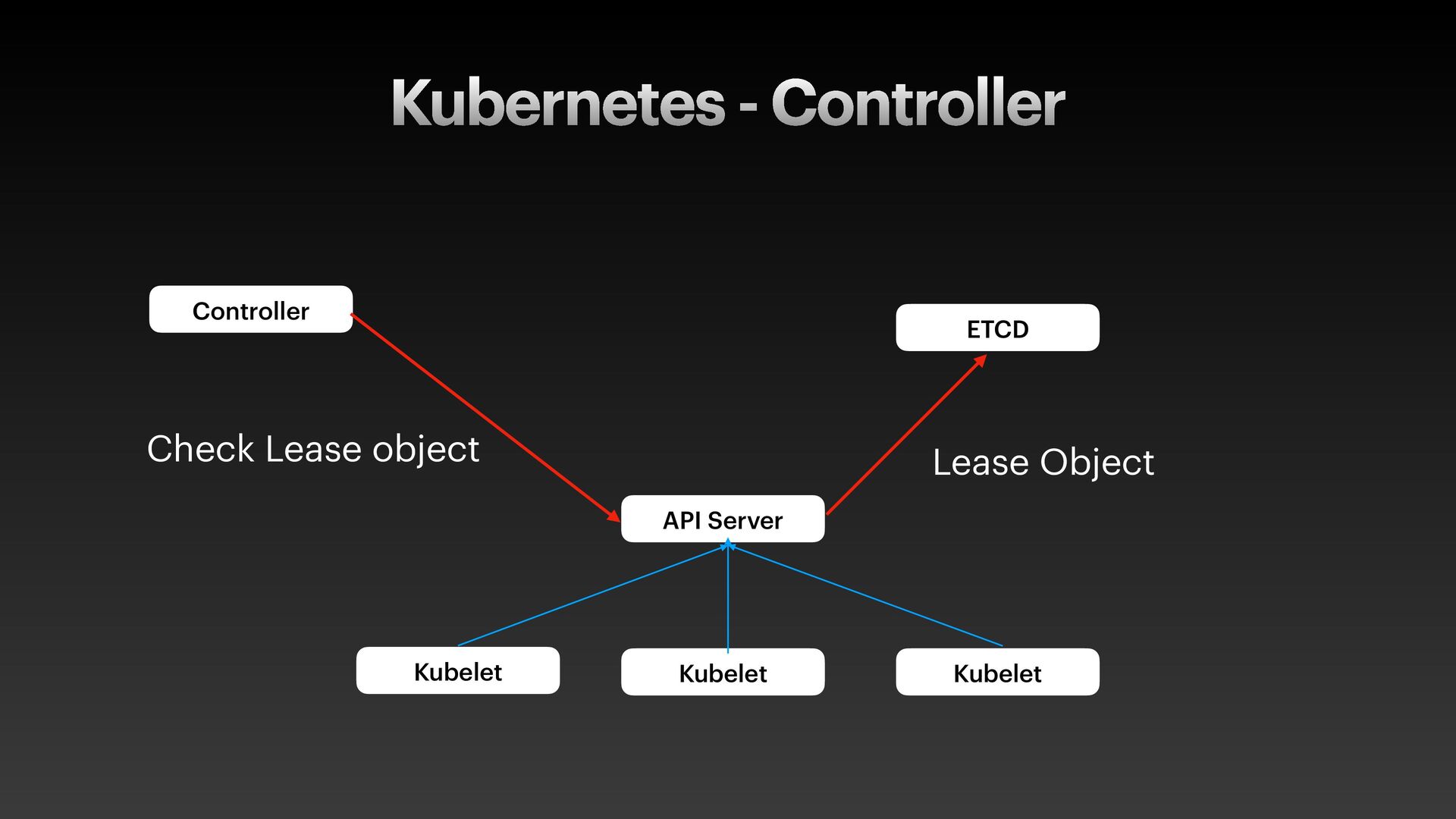
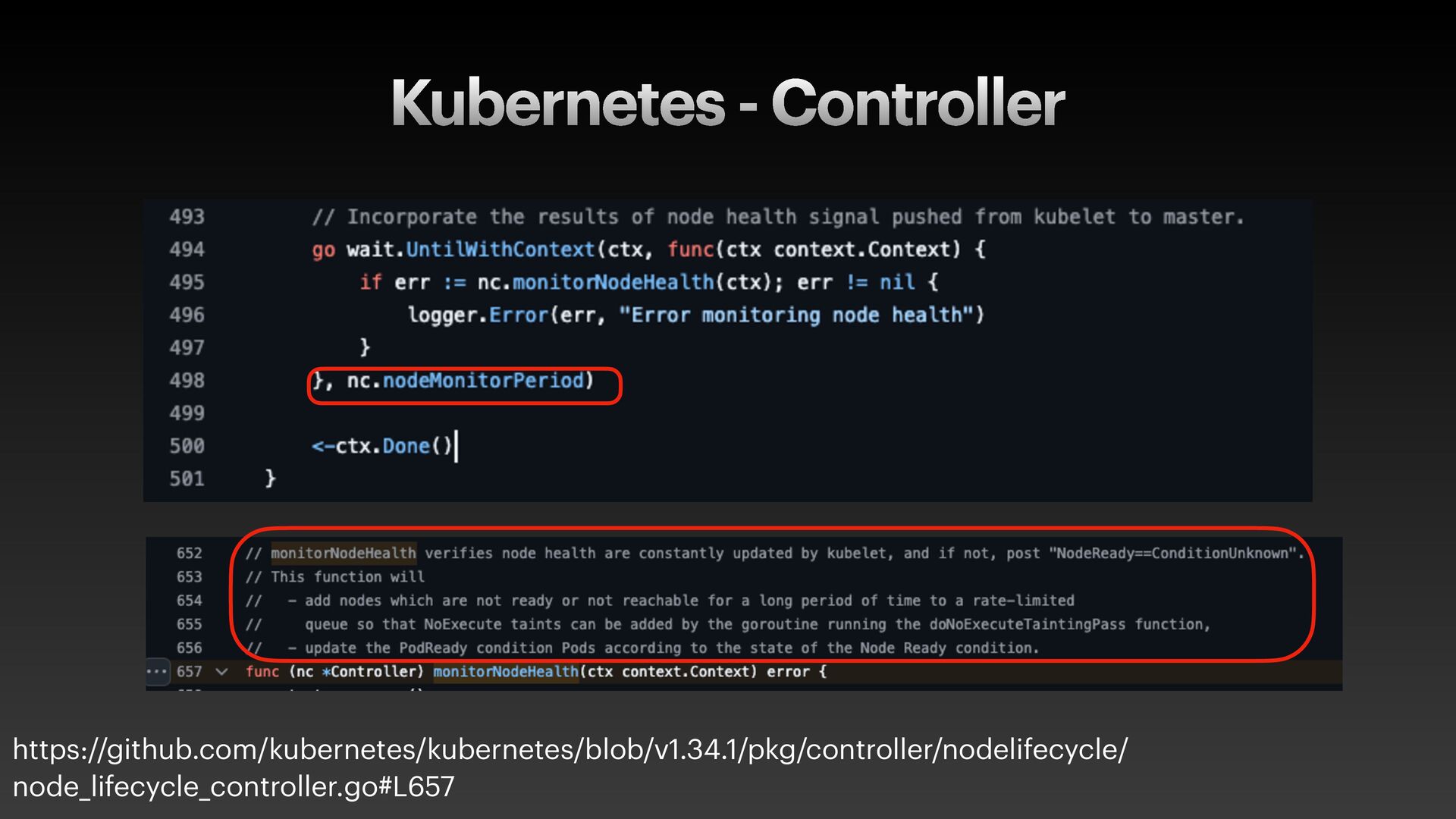
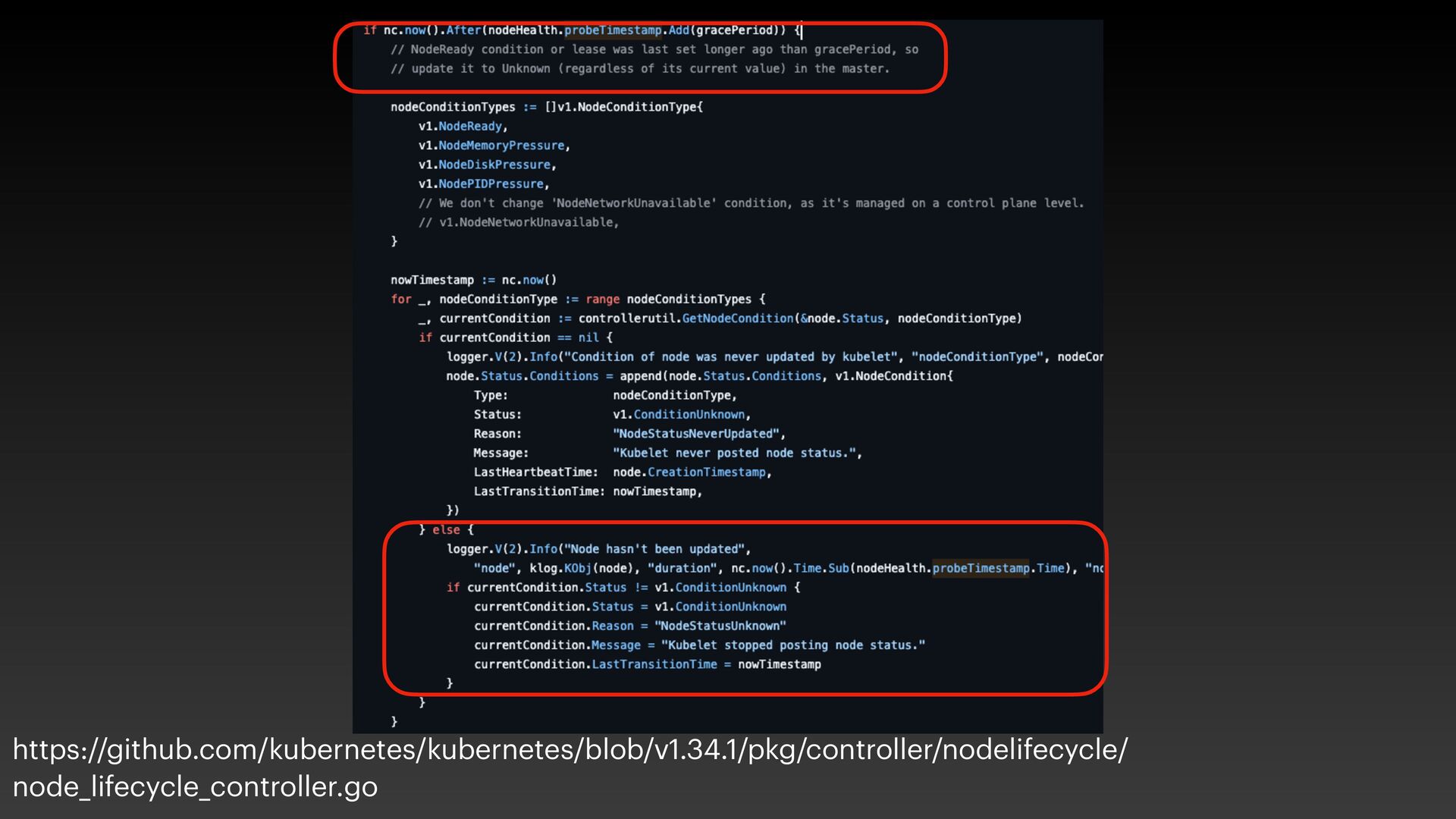
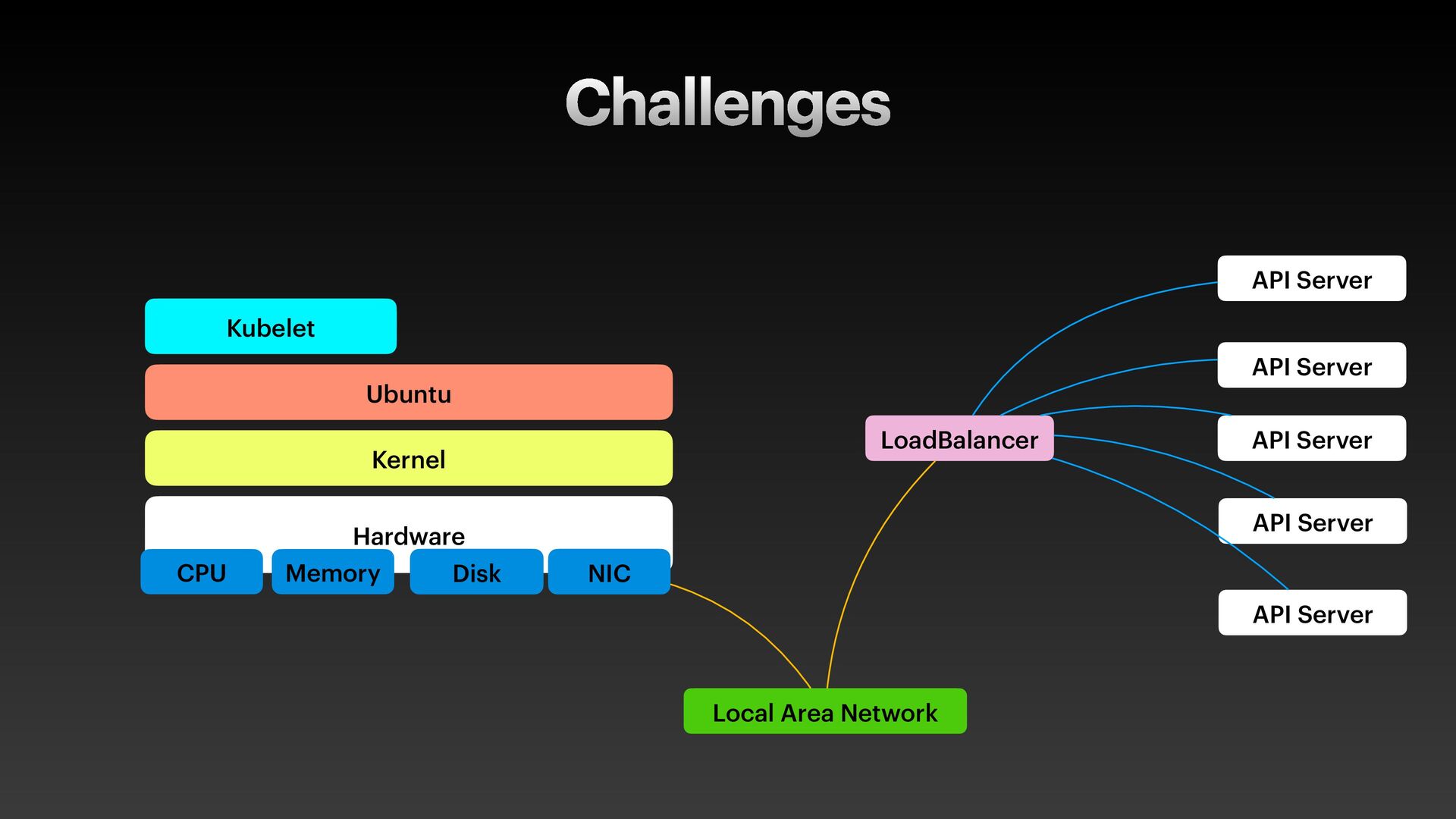
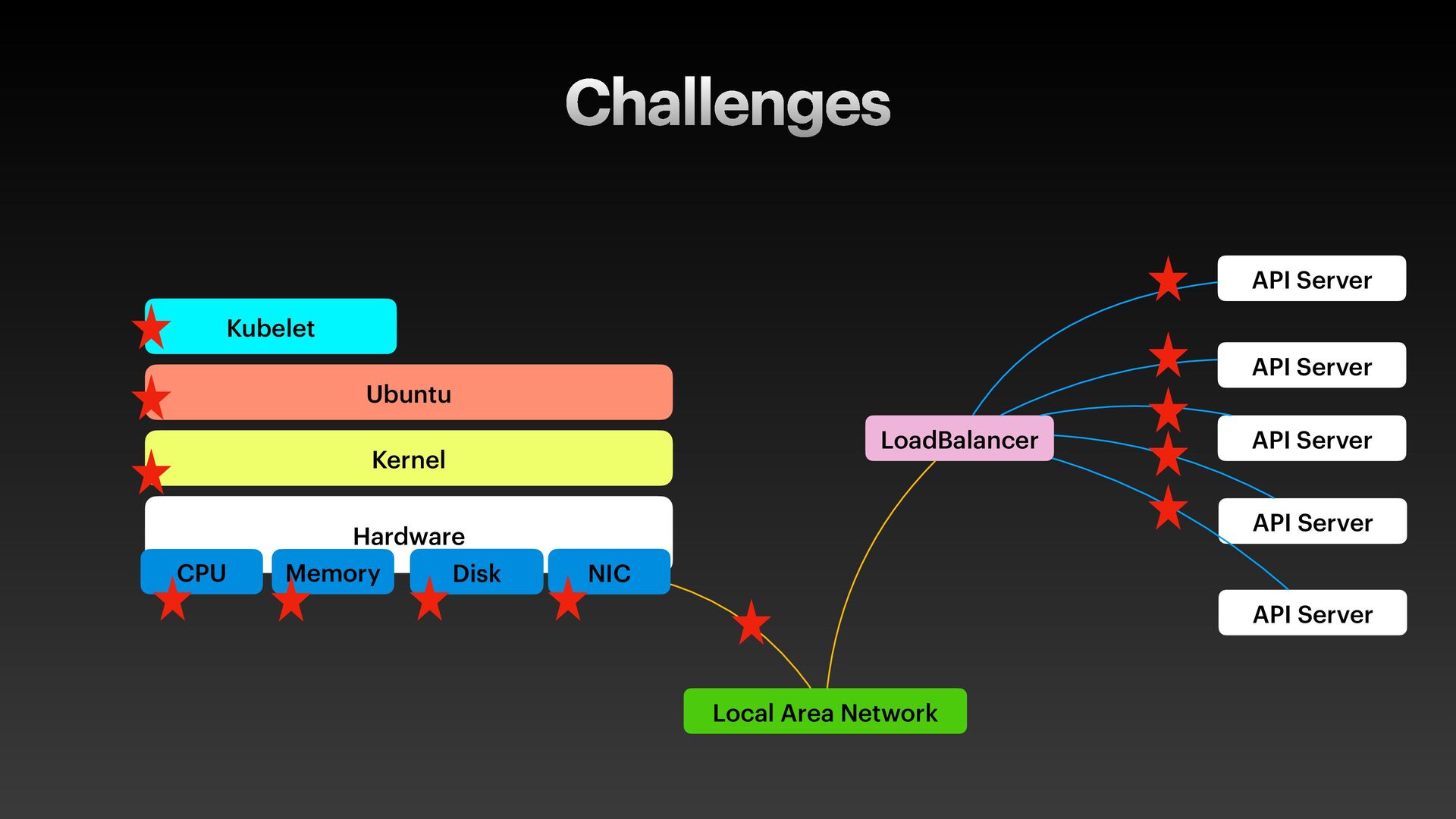
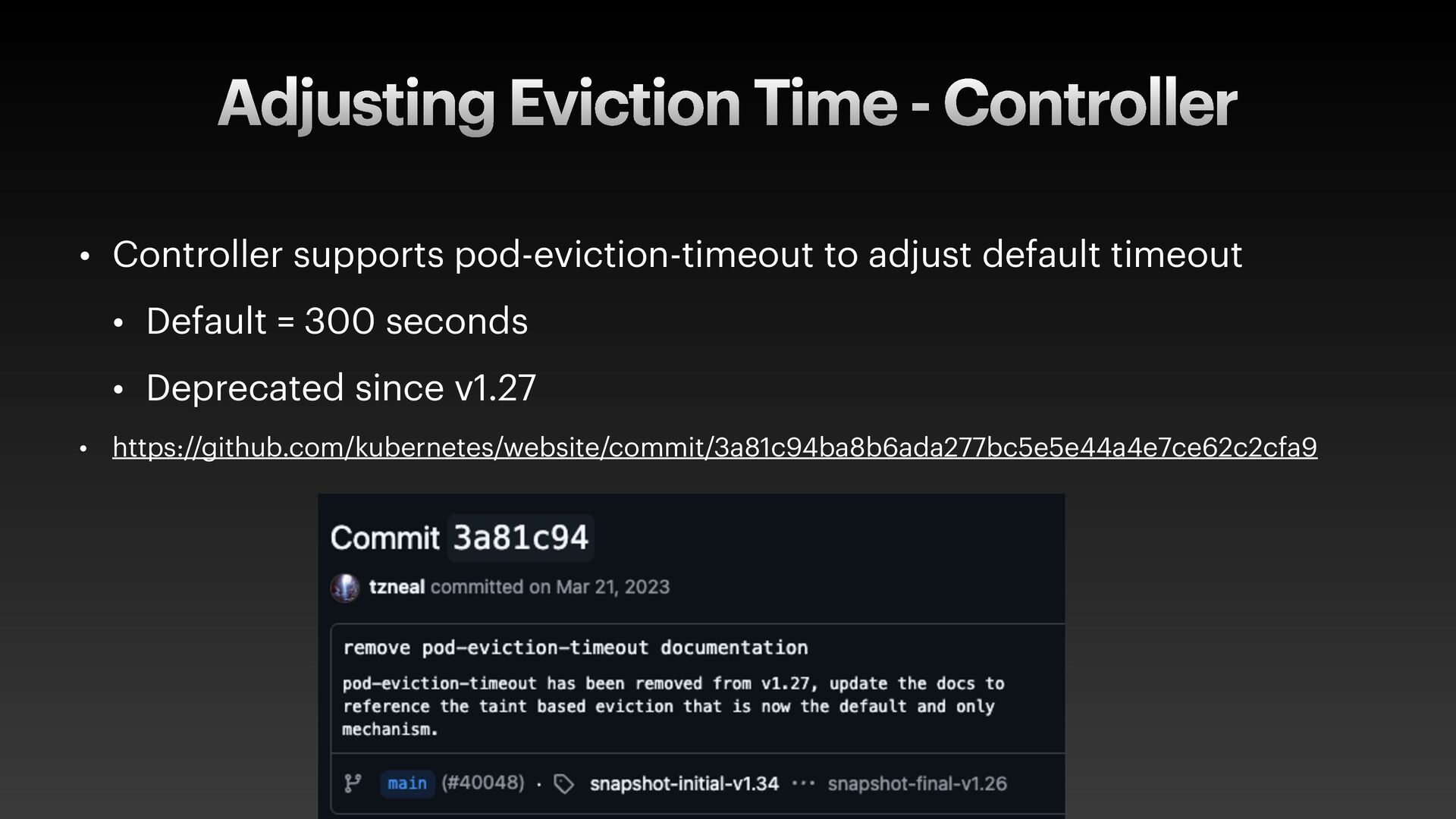
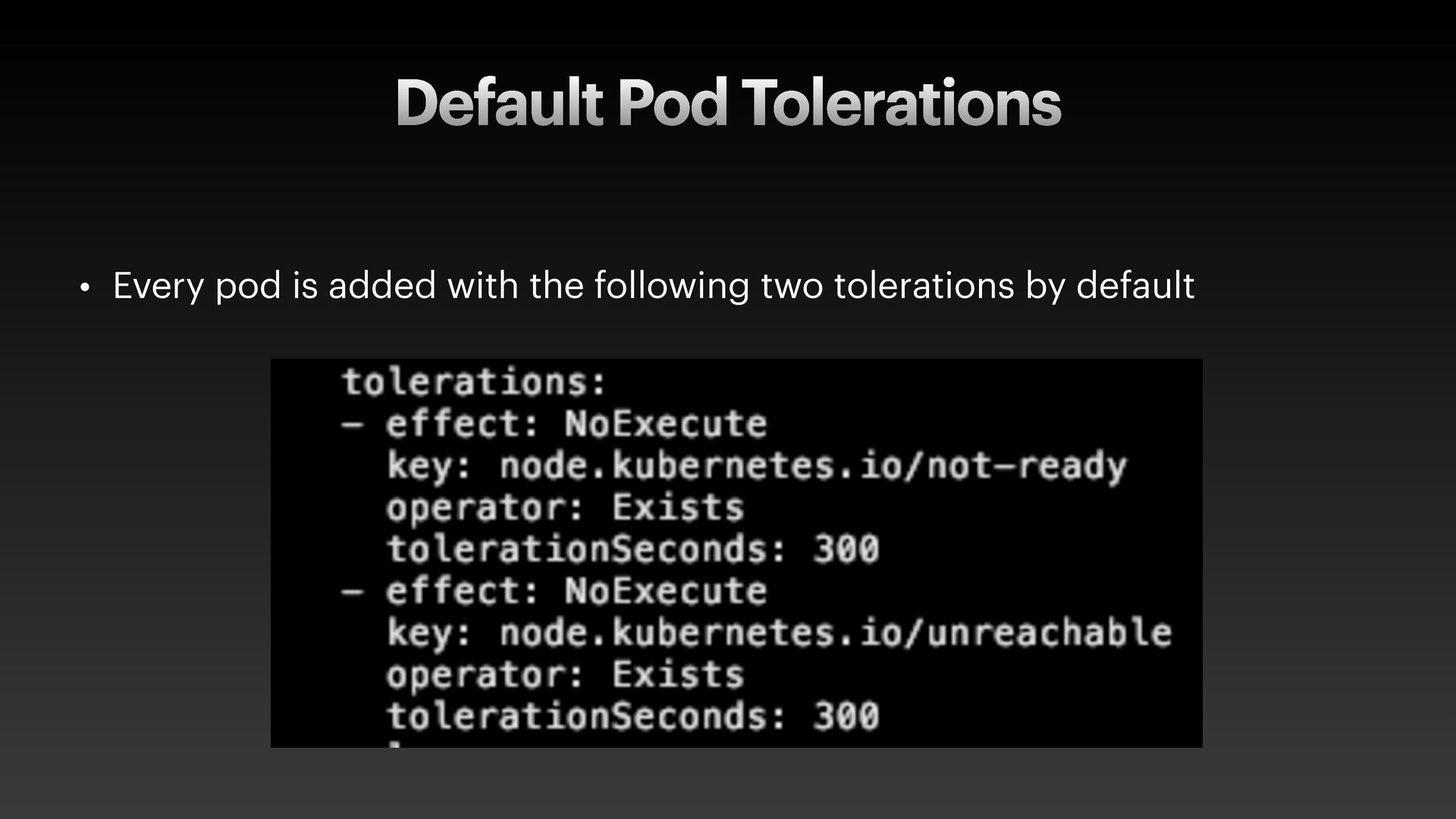
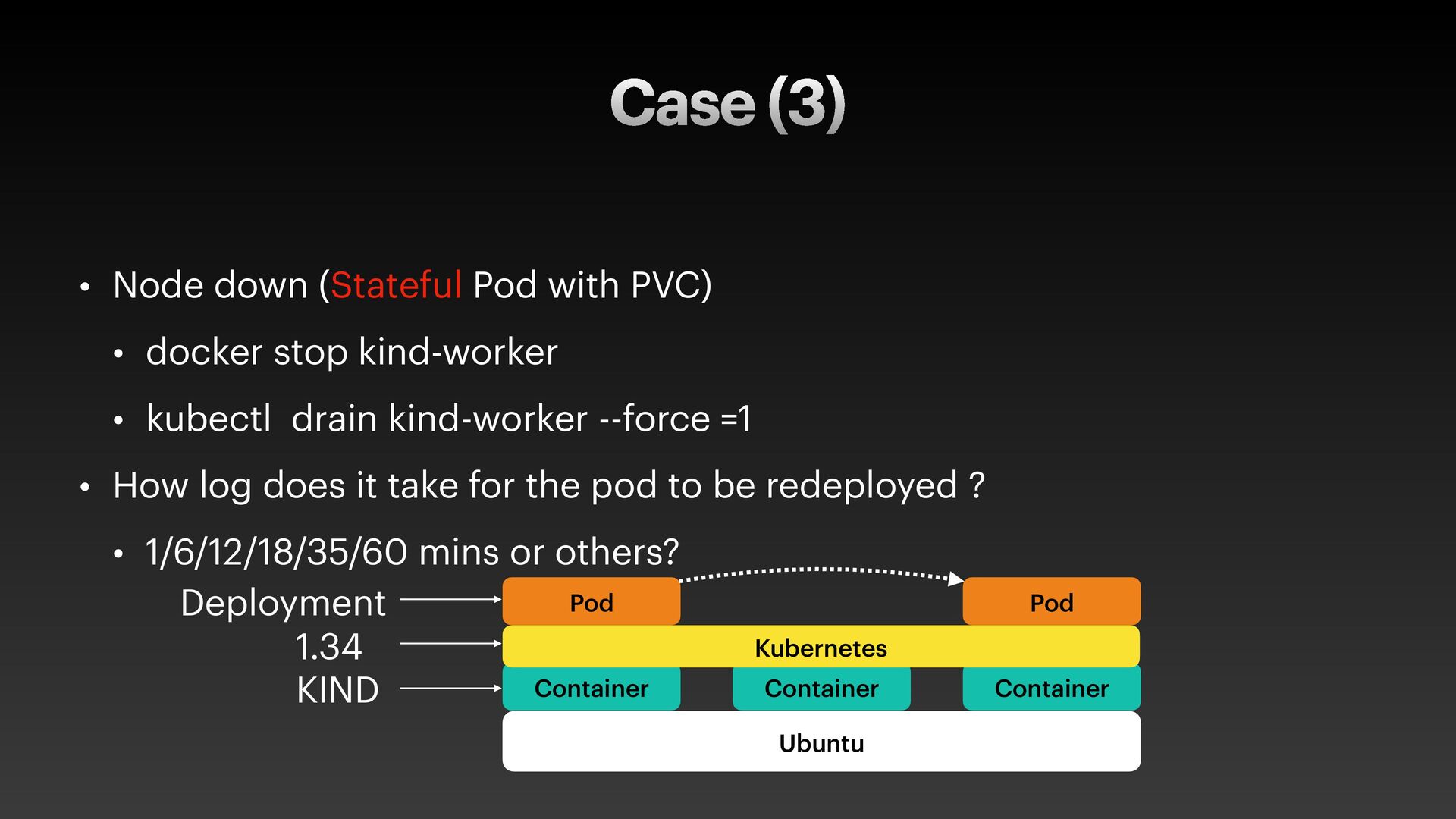
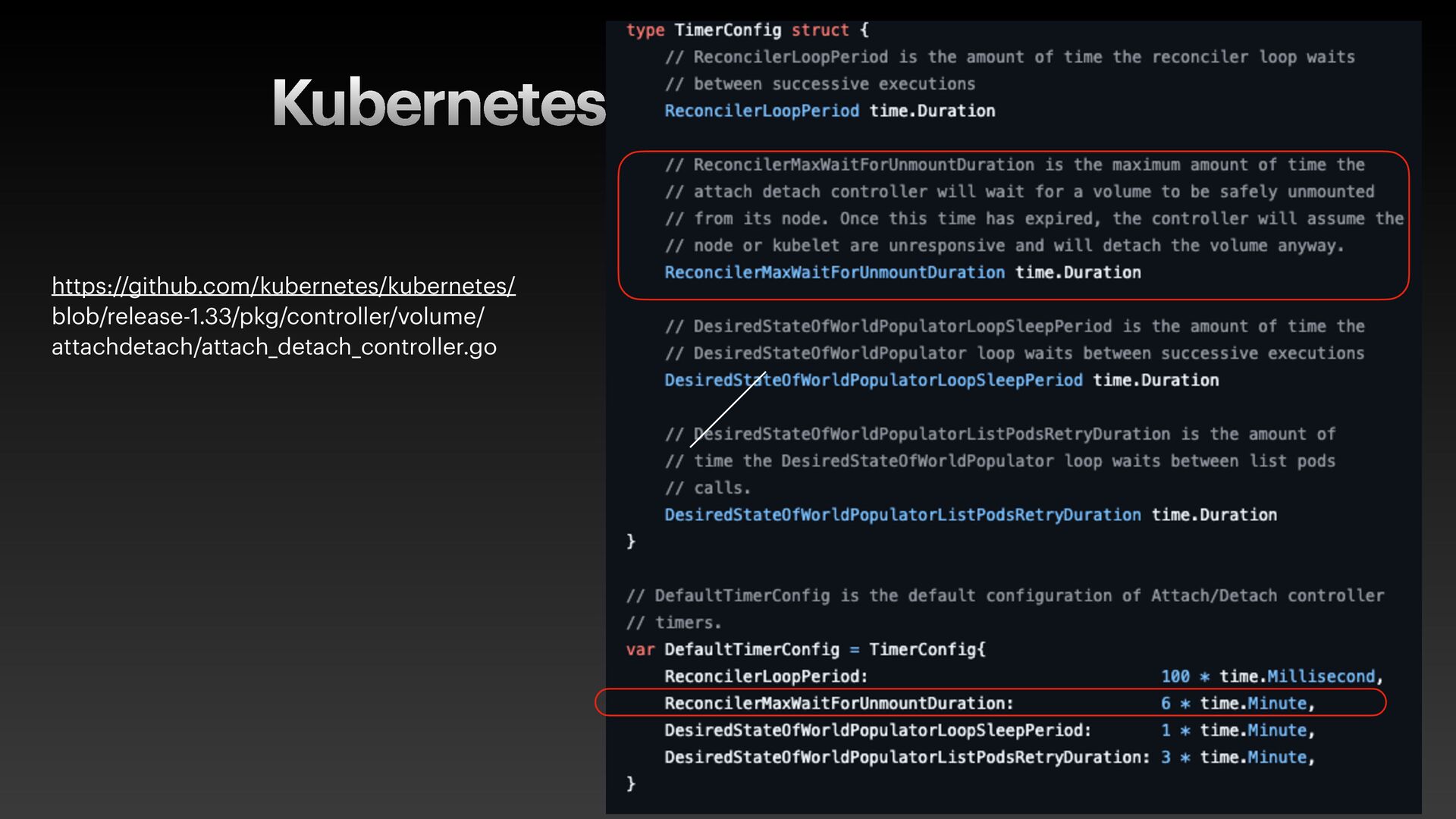
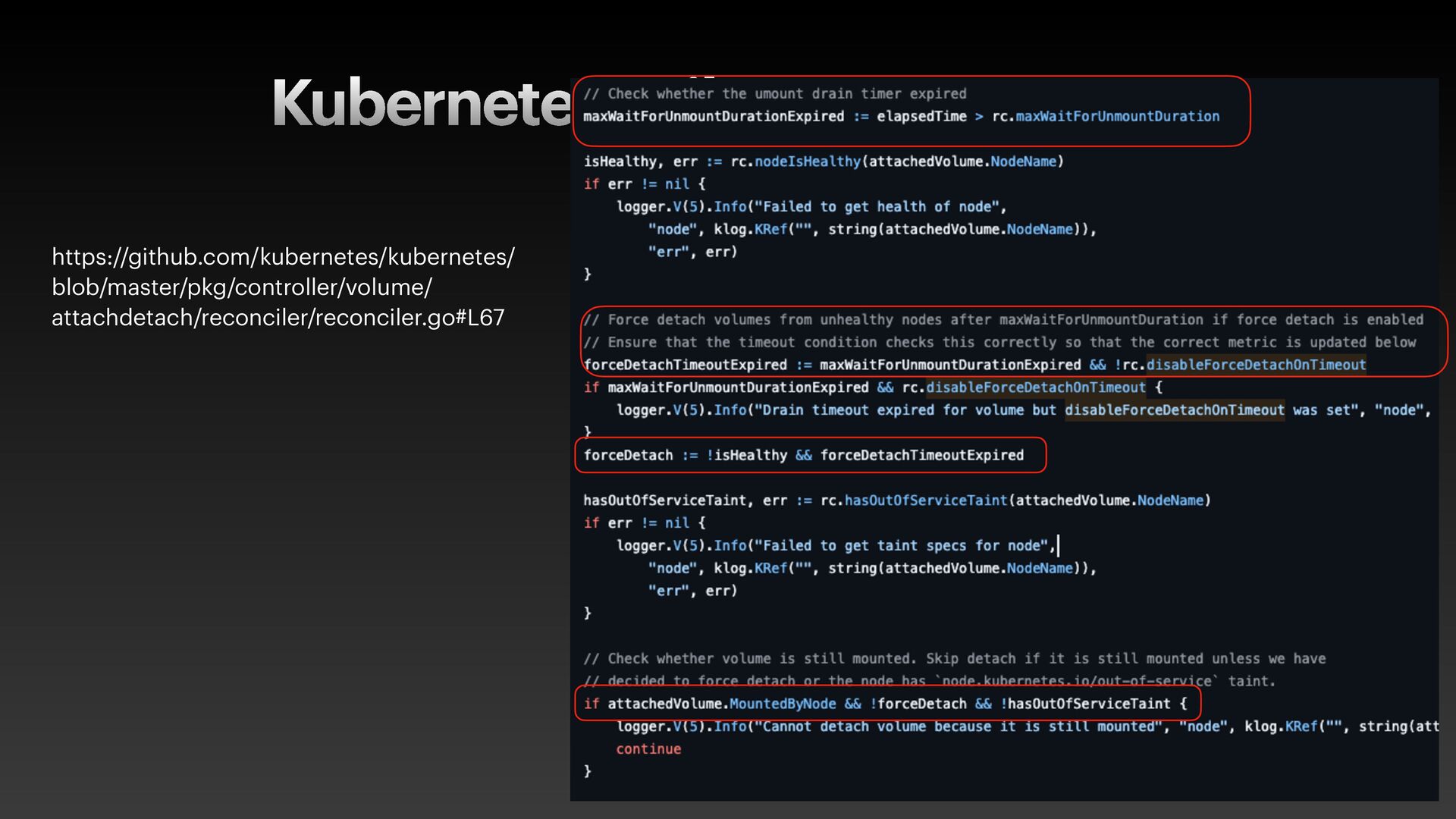
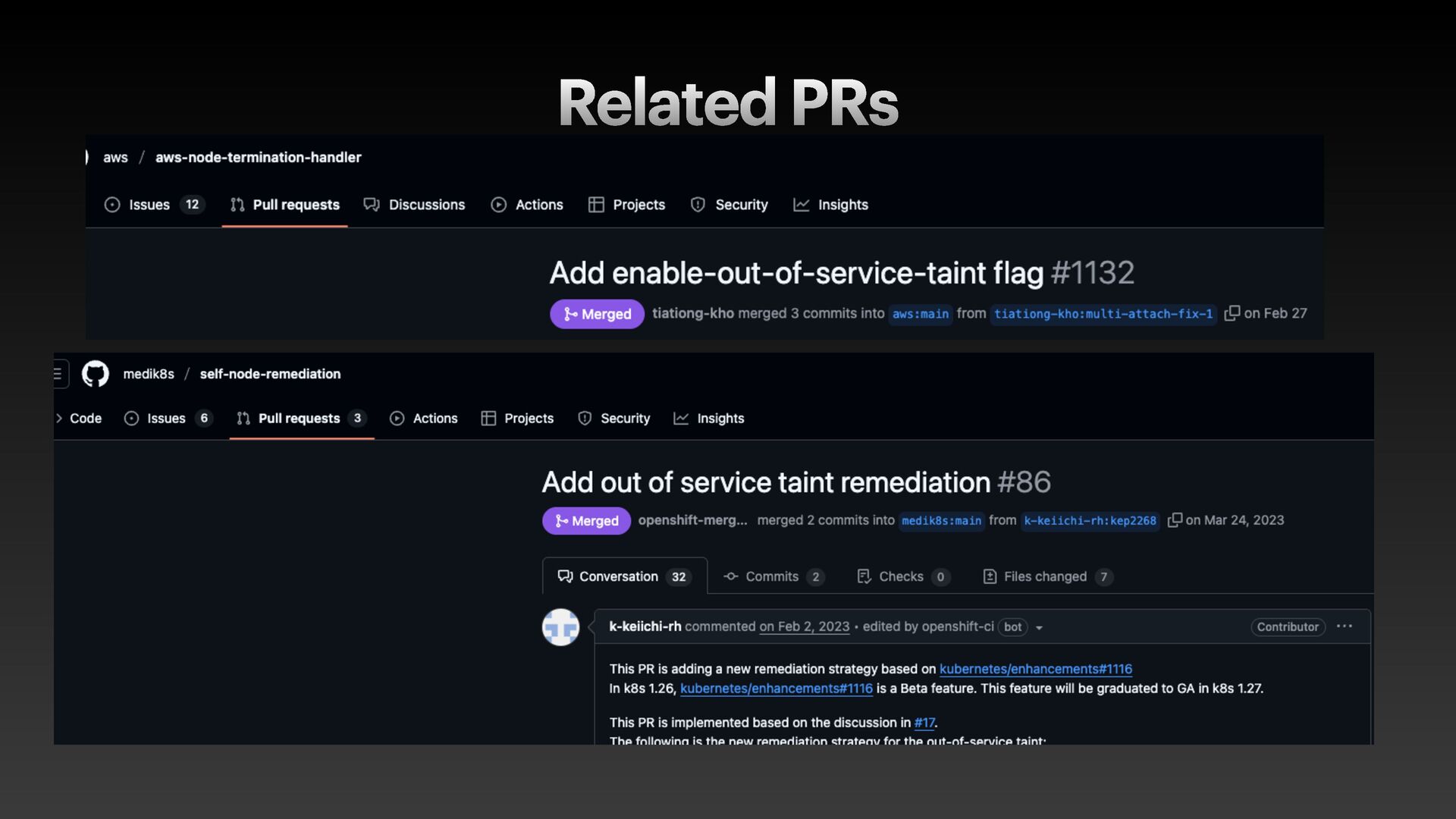
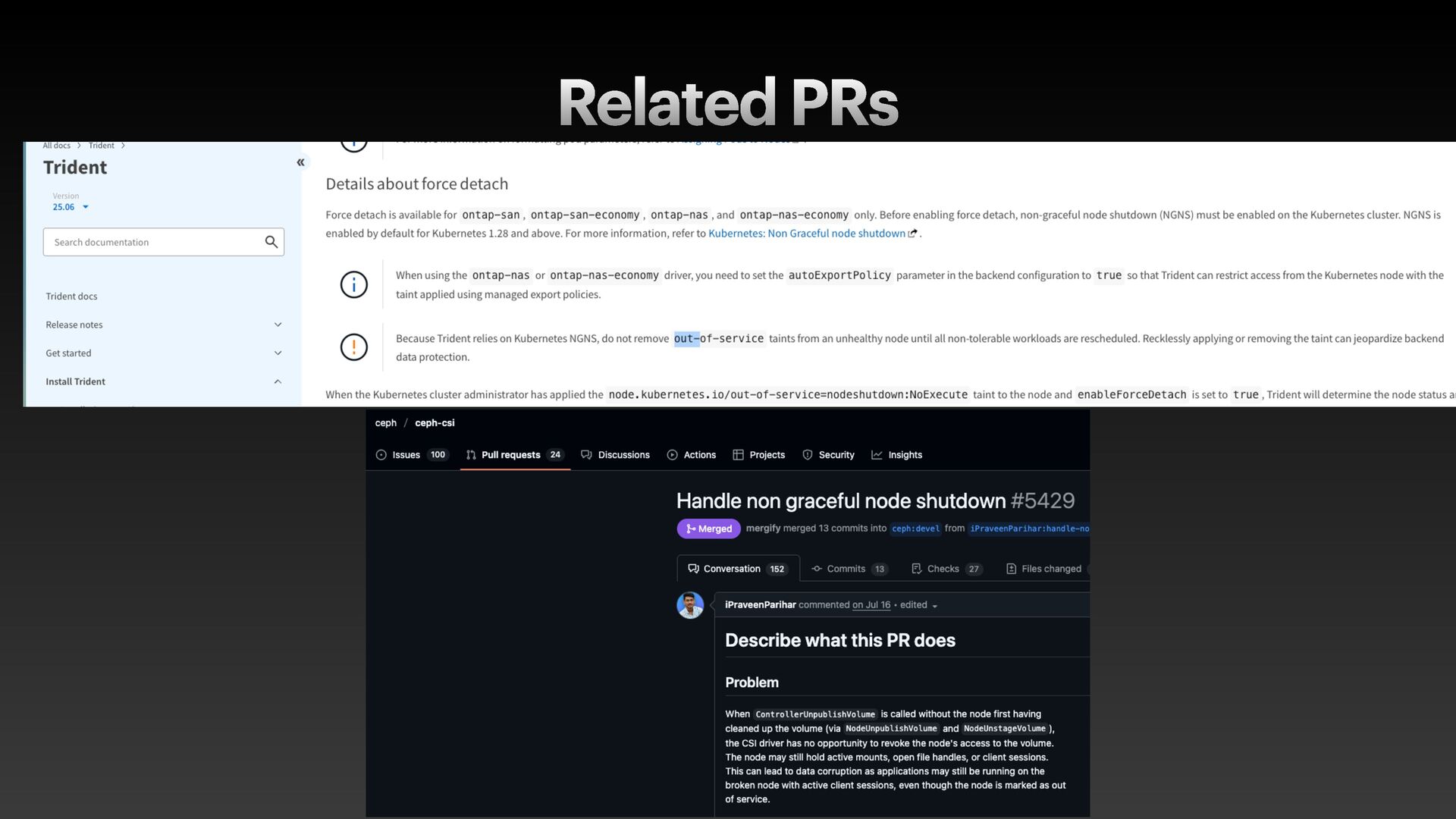
The presentation slides by HungWei Chiu provide an in-depth operational discussion of Kubernetes self-healing and failover design, particularly focusing on the differences between stateless and stateful applications. The source explains that stateless pods will eventually be redeployed following a node failure, with a total recovery time of approximately 350 seconds by default, determined by node health detection (50 seconds) and pod eviction timeouts (300 seconds). Conversely, stateful pods are not automatically redeployed upon node failure, requiring manual intervention due to challenges like persistent volume unmounting. Key factors discussed for failover include the time to declare a node unhealthy using Kubelet lease objects and the time until pods are evicted using taints and tolerations. The source also introduces the OutOfServiceTaint as a manual solution to accelerate the recovery of StatefulSets by reducing the default six-minute volume unmount timeout during node downtime.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}