Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MongoDB Vectorsearchではじめるカスタマイズ可能な生成AIアプリ開発
Search
chie8842
July 11, 2024
Technology
59
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MongoDB Vectorsearchではじめるカスタマイズ可能な生成AIアプリ開発
DB Tech Showcase 2024の資料
chie8842
July 11, 2024
More Decks by chie8842
See All by chie8842
MongoDB Atlas:モダンなアプリ開発を支えるデータプラットフォームのご紹介
chie8842
0
51
MongoDB Atlas Search のご紹介
chie8842
2
2.4k
MongoDB Atlas Vectorsearchではじめる生成AIアプリ開発
chie8842
3
2.1k
AWS GlueとAWS Lake Formationではじめるデータマネジメント
chie8842
0
1.2k
Distributed Processing in Python
chie8842
2
870
クックパッドにおける推薦(と検索)の取り組み
chie8842
20
8.2k
Understanding distributed processing in Python
chie8842
2
2.3k
Performance Tuning Tips of TensorFlow Inference
chie8842
1
790
クックパッドにおけるCloud AutoML事例
chie8842
9
8.2k
Other Decks in Technology
See All in Technology
Git 研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
440
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.7k
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
330
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
14
5.7k
人とエージェントが高め合う協業設計
kintotechdev
0
950
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
220
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
340
GoでCコンパイラを作った話
repunit
0
160
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
160
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
970
AIで楽になるはずが、なぜ疲れる?
kinopeee
0
100
データ活用研修 問いの発見と仮説構築【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
310
Featured
See All Featured
Everyday Curiosity
cassininazir
0
260
HDC tutorial
michielstock
2
750
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
The Invisible Side of Design
smashingmag
301
52k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Google's AI Overviews - The New Search
badams
0
1.1k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
570
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.7k
Transcript
MongoDB Vectorsearchではじめる カスタマイズ可能な生成AIアプリ開発 林田 千瑛 MongoDB Singapore ソリューションアーキテクト WELCOME
自己紹介 林田 千瑛 MongoDB のソリューションアーキテクト インフラエンジニア→ソフトウェアエンジニア→ソリューションアーキテクト Web企業にてデータ基盤・機械学習基盤・検索サービス開発に 従事した後、クラウドベンダのソリューションアーキテクトを経て 2023年11月からMongoDBに入社
生成AIにより変わる社会 $4.4兆 生成AIが1年に生み出す 経済利益の予想 60-70% 生成AIによって自動化されると 予想される作業 Source: McKinsey GenAI
report
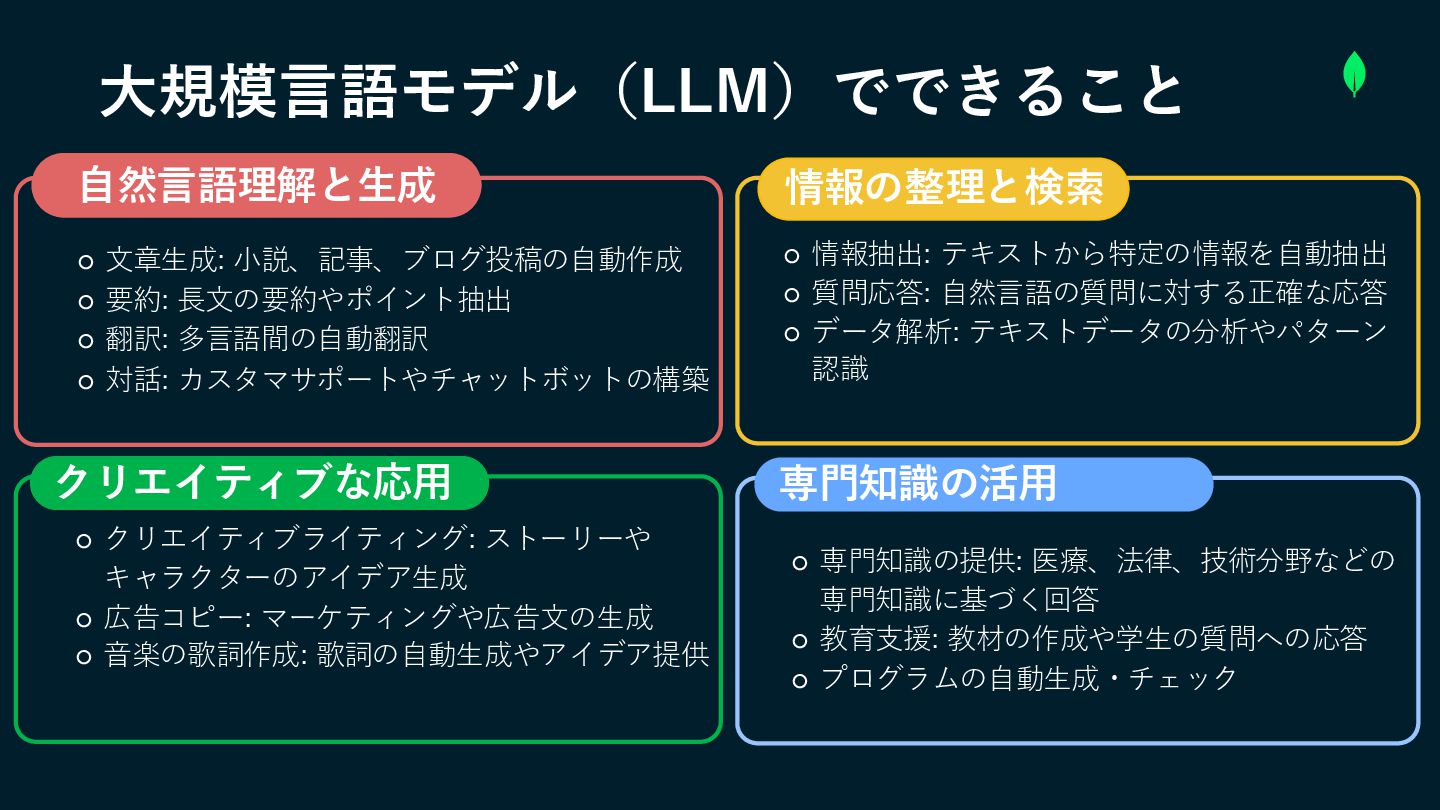
大規模言語モデル(LLM)でできること ◦ ◦ 文章生成: 小説、記事、ブログ投稿の自動作成 ◦ 要約: 長文の要約やポイント抽出 ◦ 翻訳:
多言語間の自動翻訳 ◦ 対話: カスタマサポートやチャットボットの構築 ◦ クリエイティブライティング: ストーリーや キャラクターのアイデア生成 ◦ 広告コピー: マーケティングや広告文の生成 ◦ 音楽の歌詞作成: 歌詞の自動生成やアイデア提供 ◦ 情報抽出: テキストから特定の情報を自動抽出 ◦ 質問応答: 自然言語の質問に対する正確な応答 ◦ データ解析: テキストデータの分析やパターン 認識 ◦ 専門知識の提供: 医療、法律、技術分野などの 専門知識に基づく回答 ◦ 教育支援: 教材の作成や学生の質問への応答 ◦ プログラムの自動生成・チェック 自然言語理解と生成 情報の整理と検索 クリエイティブな応用 専門知識の活用
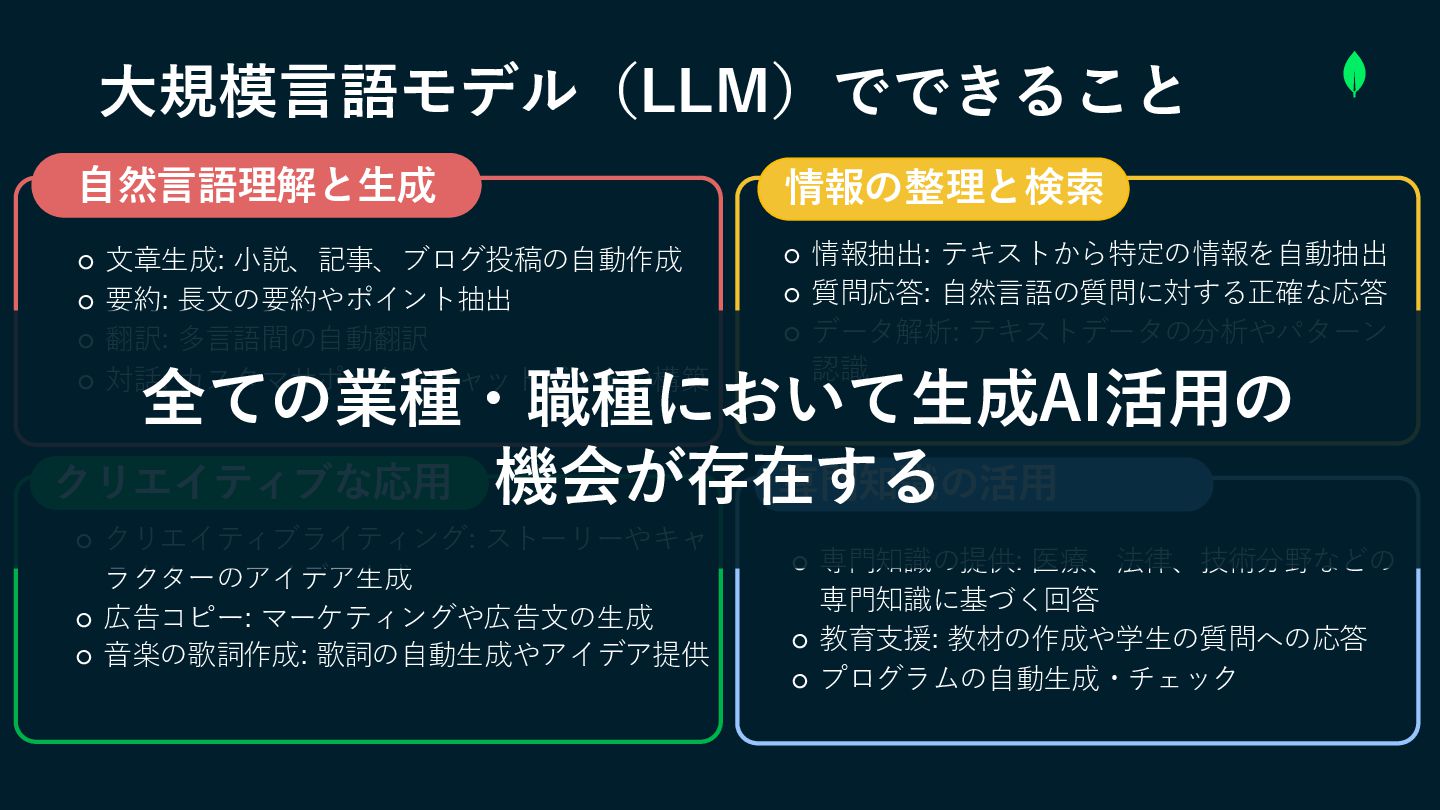
大規模言語モデル(LLM)でできること ◦ ◦ 文章生成: 小説、記事、ブログ投稿の自動作成 ◦ 要約: 長文の要約やポイント抽出 ◦ 翻訳:
多言語間の自動翻訳 ◦ 対話: カスタマサポートやチャットボットの構築 ◦ クリエイティブライティング: ストーリーやキャ ラクターのアイデア生成 ◦ 広告コピー: マーケティングや広告文の生成 ◦ 音楽の歌詞作成: 歌詞の自動生成やアイデア提供 ◦ 情報抽出: テキストから特定の情報を自動抽出 ◦ 質問応答: 自然言語の質問に対する正確な応答 ◦ データ解析: テキストデータの分析やパターン 認識 ◦ 専門知識の提供: 医療、法律、技術分野などの 専門知識に基づく回答 ◦ 教育支援: 教材の作成や学生の質問への応答 ◦ プログラムの自動生成・チェック 自然言語理解と生成 情報の整理と検索 クリエイティブな応用 専門知識の活用 全ての業種・職種において生成AI活用の 機会が存在する
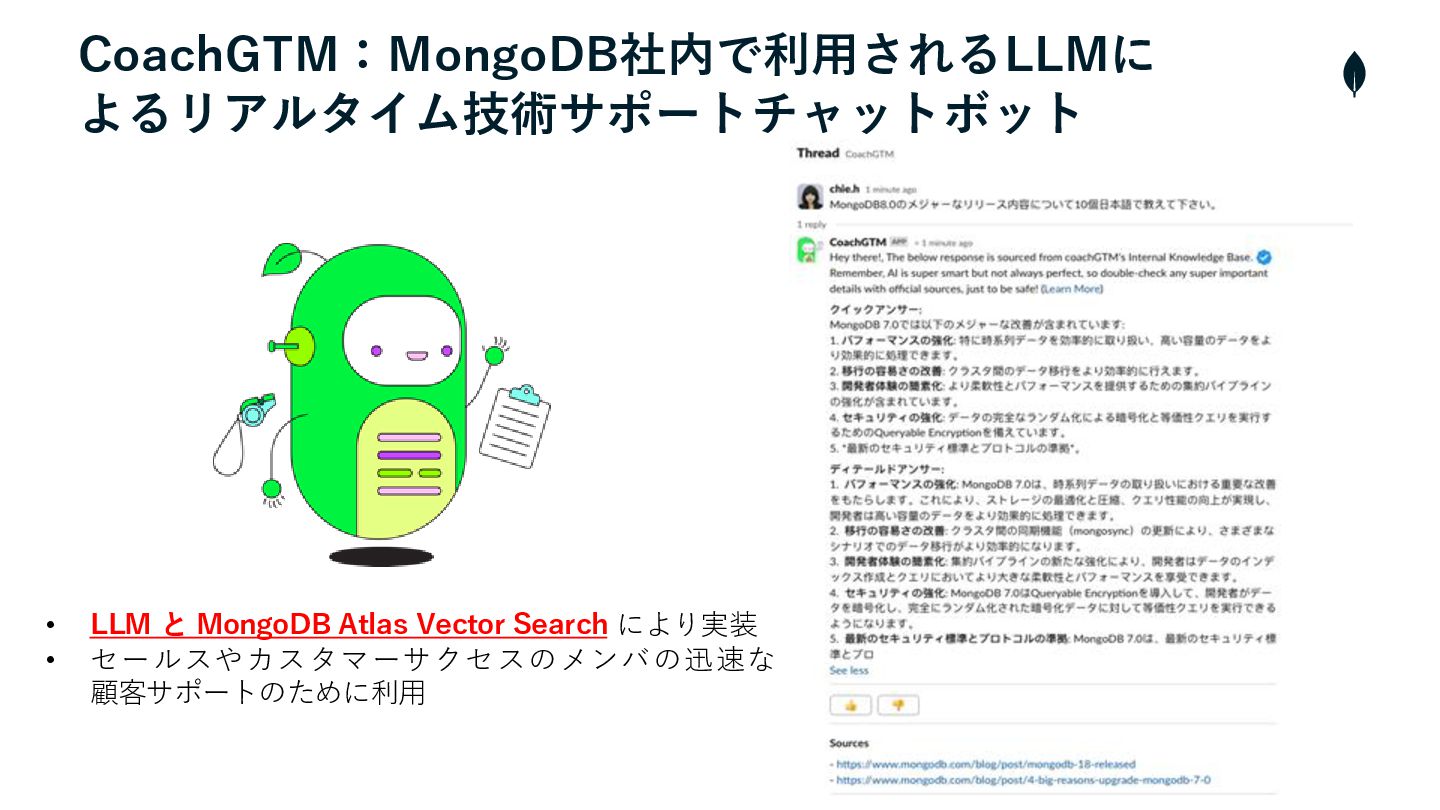
CoachGTM:MongoDB社内で利用されるLLMに よるリアルタイム技術サポートチャットボット • LLM と MongoDB Atlas Vector Search により実装
• セールスやカスタマーサクセスのメンバの迅速な 顧客サポートのために利用
臨床試験報告書の自動生成により、 新薬承認のプロセスを劇的に高速化 • 170カ国で薬を販売する年商335億ドルの 製薬企業 • MongoDB Atlas と Amazon
BedRock を 利用した生成AIシステム 顧客の声 「MongoDB Atlas の優れた点は、レポートのネイティブ ベクトル埋め込みを、関連するテキスト スニペットや メタデータのすべてと並べて保存できることです」 「非常に強力で複雑なクエリを迅速に実行できるのです。 ベクトル埋め込みごとに、どのソース ドキュメントから 取得したか、誰がいつ作成したかに基づいてフィルター 処理できます。」 臨床試験報告書(CSR)の例
なぜLLM(素のChatGPT等)ではだめなのか LLMモデルの学習データに含まれない内容について答えられない • 「今日の天気」などのリアルタイムな情報、ドメイン固有のデータに基づく質疑応 答ができない • 信頼性の低いデータに基づく回答が行われる場合がある • それっぽい嘘情報を答えてしまう(Hallucination) Retrieval
Augmented Generation (RAG) LLMモデルのコンテキスト不足による問題を情報検索技術との融合に より解決
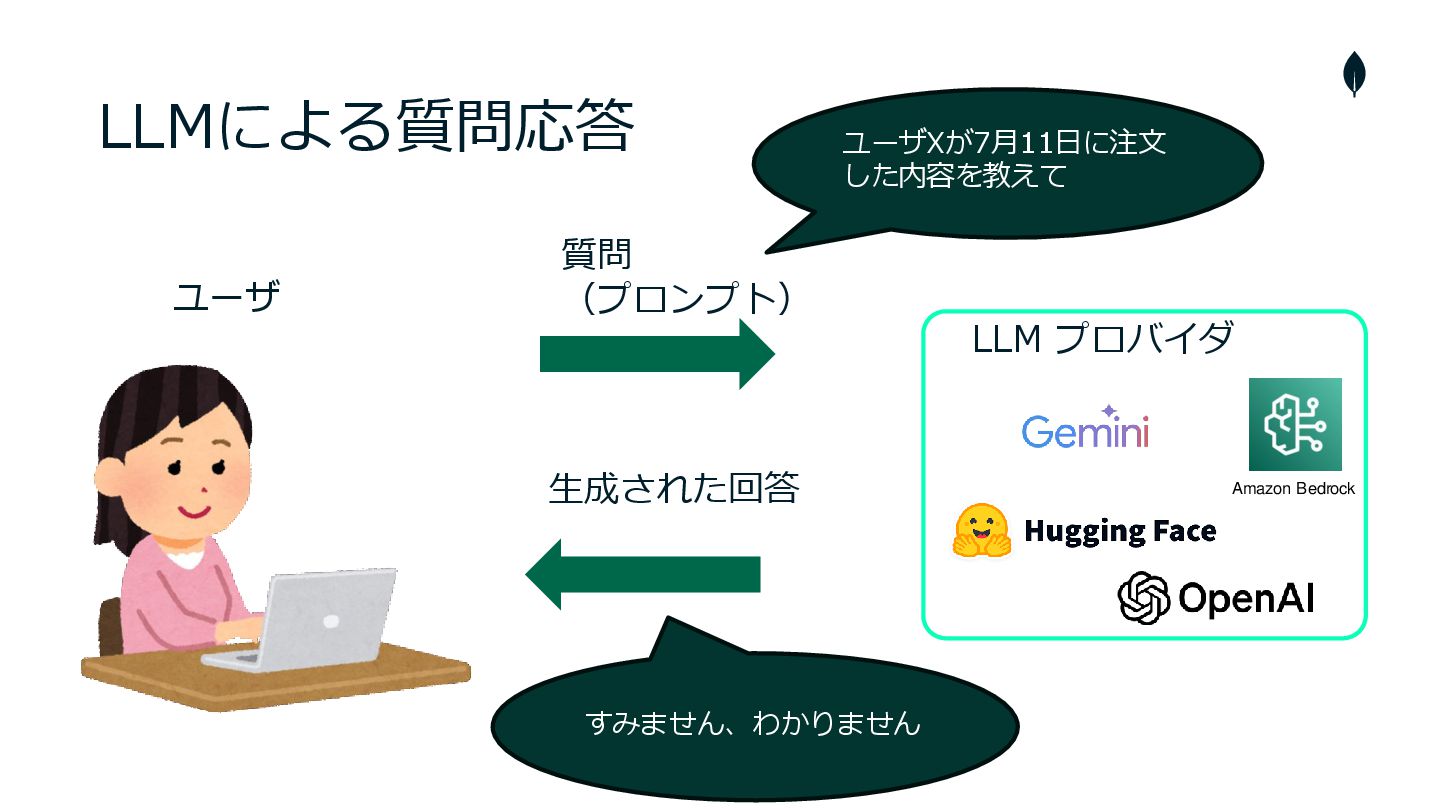
LLMによる質問応答 ユーザ 質問 (プロンプト) 生成された回答 ユーザXが7月11日に注文 した内容を教えて すみません、わかりません LLM プロバイダ
Amazon Bedrock
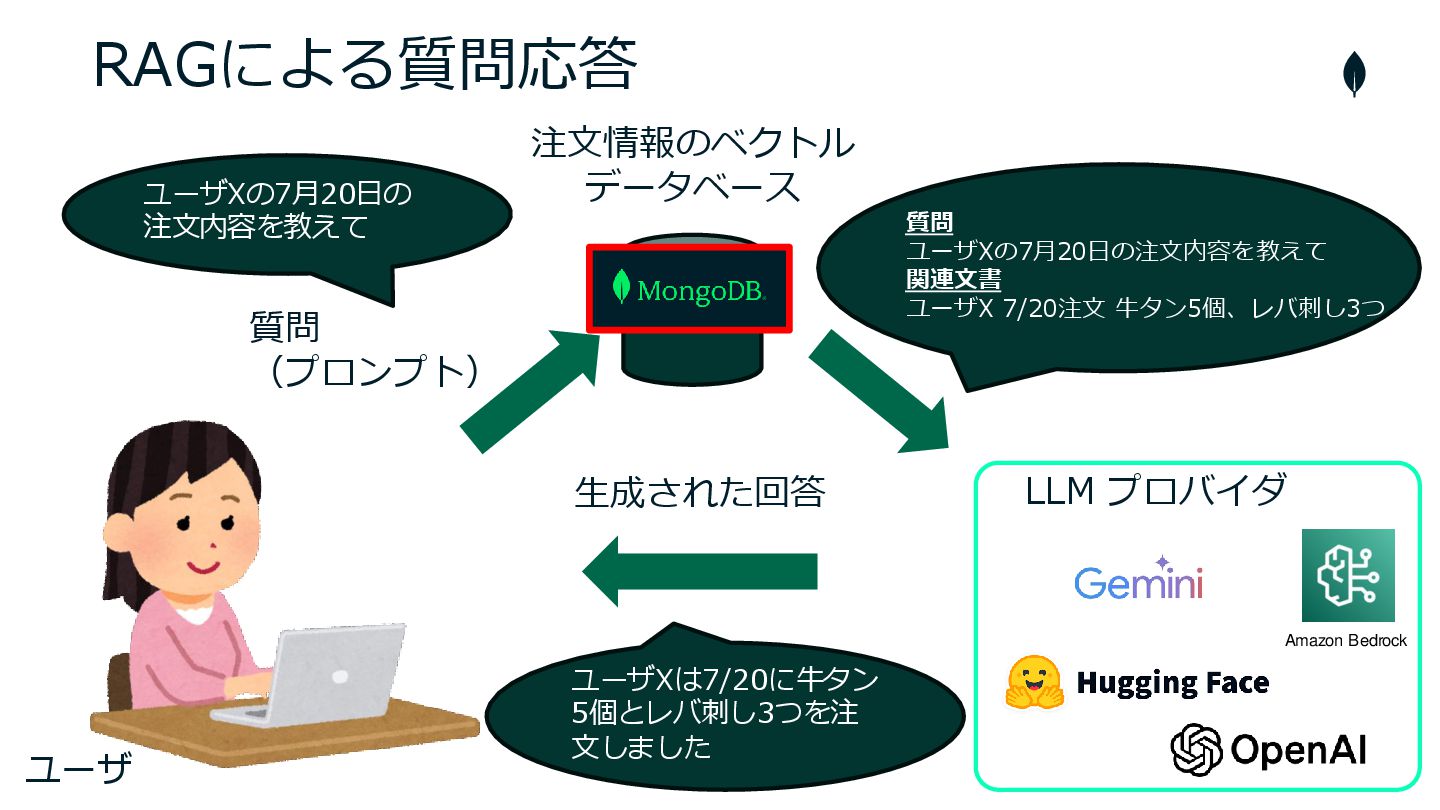
RAGによる質問応答 LLM プロバイダ Amazon Bedrock ユーザXは7/20に牛タン 5個とレバ刺し3つを注 文しました 質問 ユーザXの7月20日の注文内容を教えて
関連文書 ユーザX 7/20注文 牛タン5個、レバ刺し3つ ユーザXの7月20日の 注文内容を教えて 注文情報のベクトル データベース ユーザ 質問 (プロンプト) 生成された回答
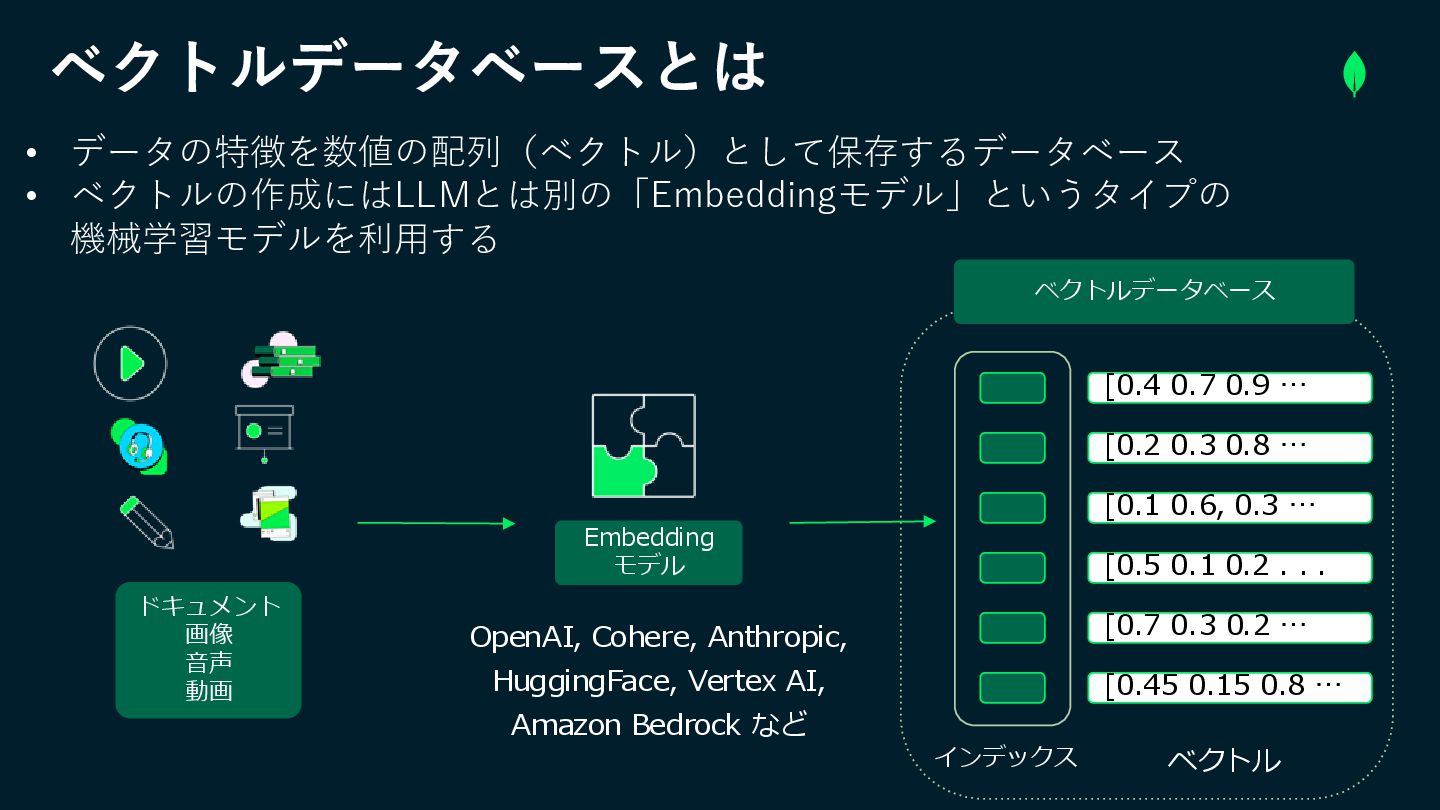
インデックス ベクトルデータベースとは Embedding モデル OpenAI, Cohere, Anthropic, HuggingFace, Vertex AI,
Amazon Bedrock など ドキュメント 画像 音声 動画 [0.4 0.7 0.9 … [0.2 0.3 0.8 … [0.1 0.6, 0.3 … [0.5 0.1 0.2 . . . [0.7 0.3 0.2 … [0.45 0.15 0.8 … ベクトル ベクトルデータベース • データの特徴を数値の配列(ベクトル)として保存するデータベース • ベクトルの作成にはLLMとは別の「Embeddingモデル」というタイプの 機械学習モデルを利用する
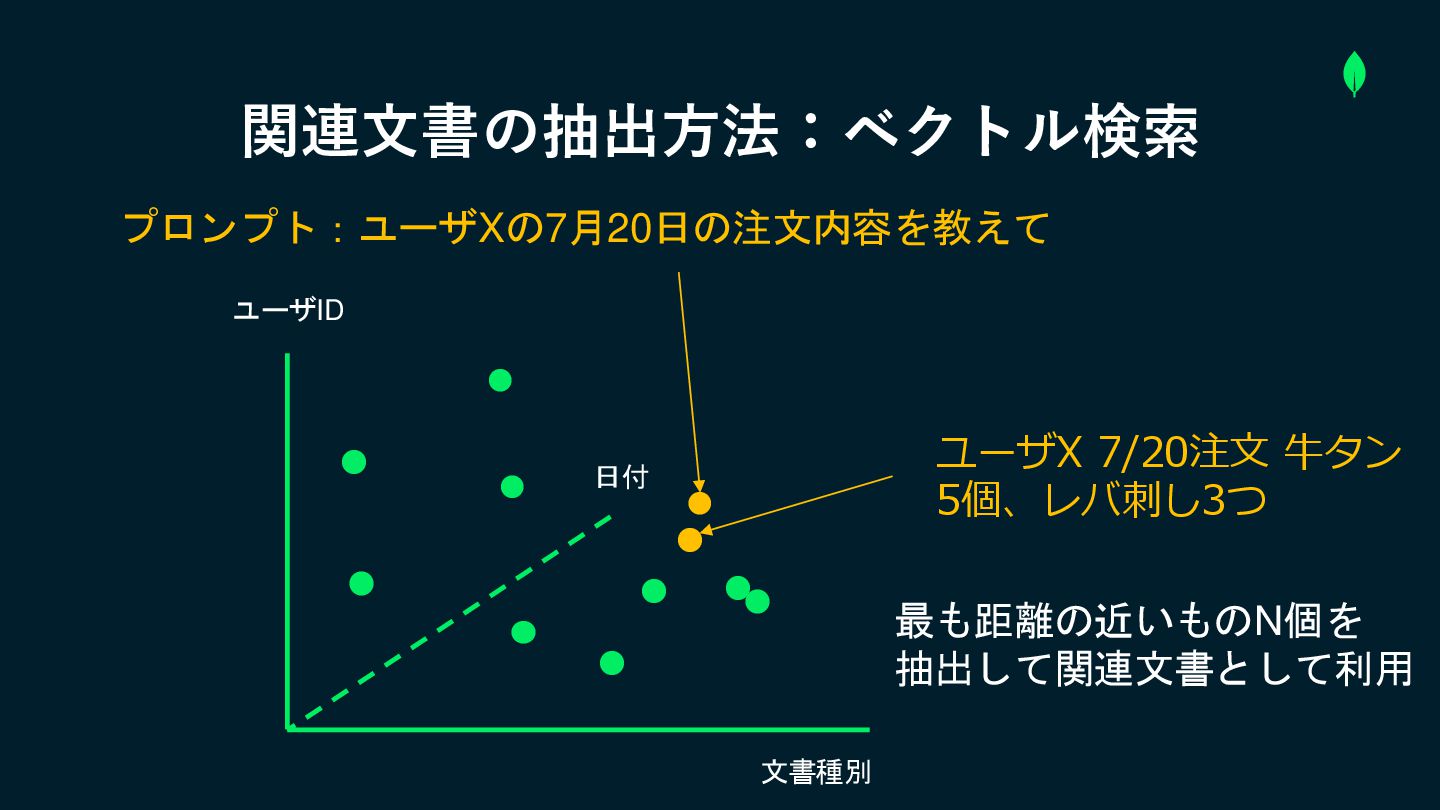
関連文書の抽出方法:ベクトル検索 ユーザID 文書種別 日付 [0.3, 0.4, 0.2, 0.1…] 数字の配列で示される ベクトル
データを数値配列で表し、距離の近いものを類似データとして抽出する ベクトルデータの例
関連文書の抽出方法:ベクトル検索 ユーザID 文書種別 日付 ユーザX 7/20注文 牛タン 5個、レバ刺し3つ プロンプト:ユーザXの7月20日の注文内容を教えて 最も距離の近いものN個を
抽出して関連文書として利用
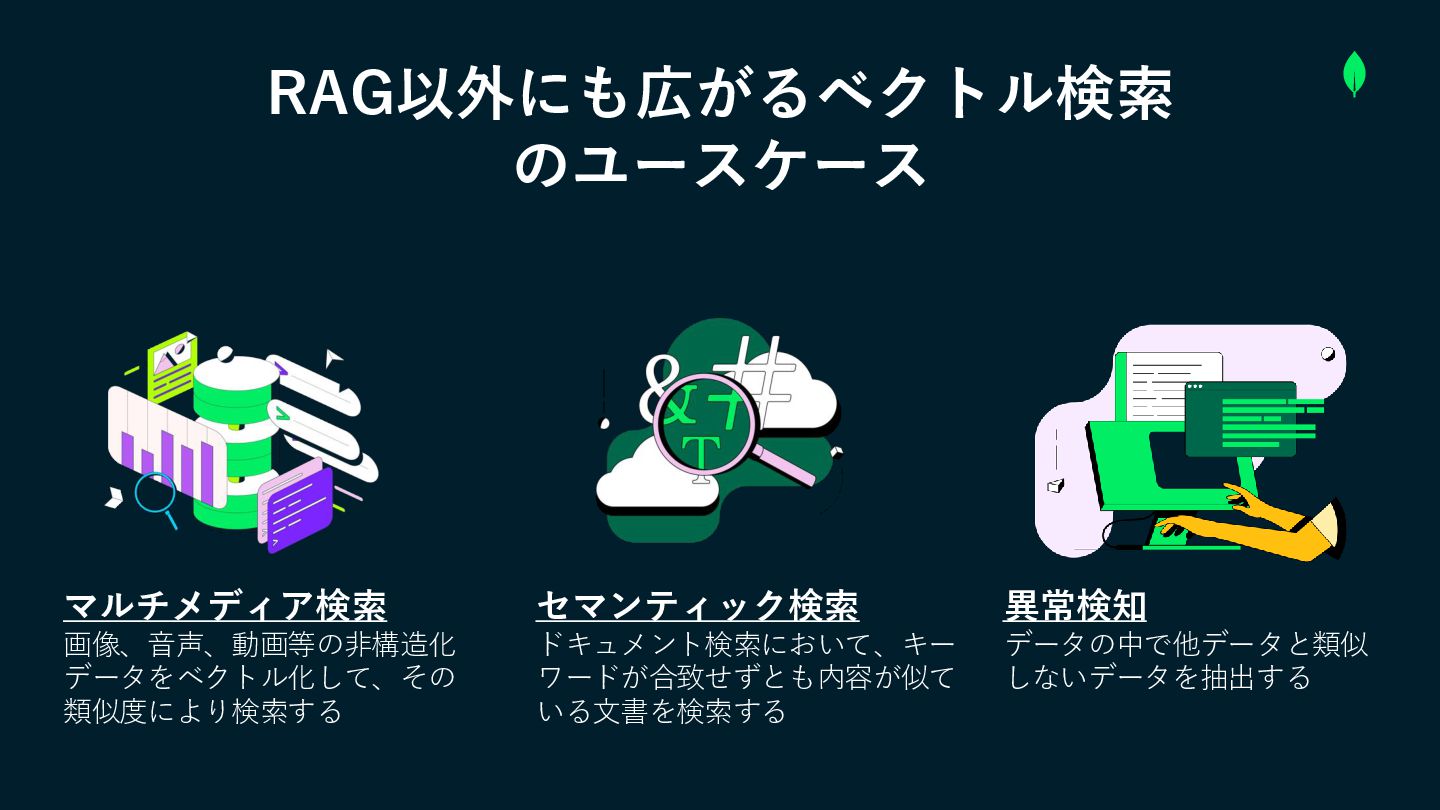
RAG以外にも広がるベクトル検索 のユースケース マルチメディア検索 画像、音声、動画等の非構造化 データをベクトル化して、その 類似度により検索する セマンティック検索 ドキュメント検索において、キー ワードが合致せずとも内容が似て いる文書を検索する
異常検知 データの中で他データと類似 しないデータを抽出する
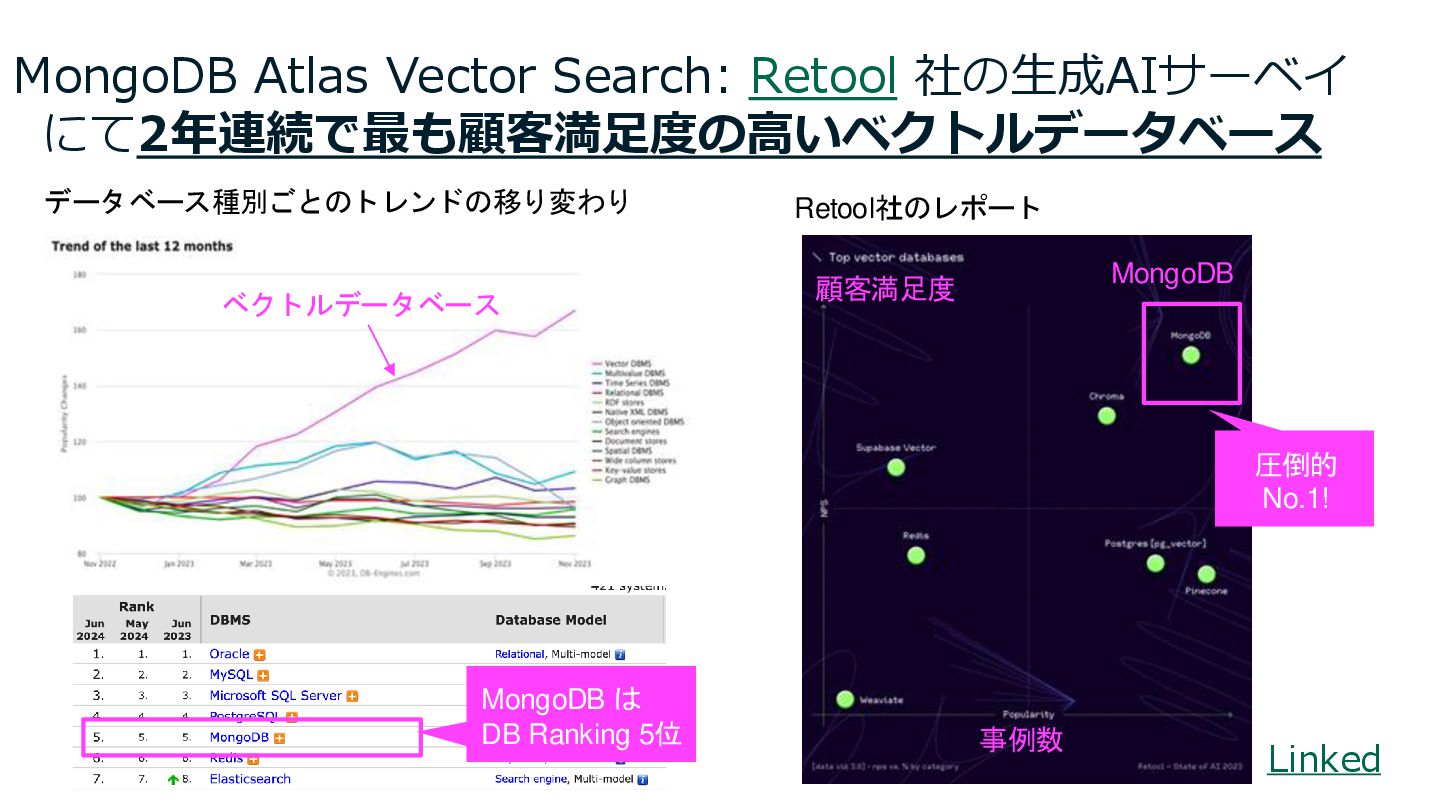
MongoDB Atlas Vector Search: Retool 社の生成AIサーベイ にて2年連続で最も顧客満足度の高いベクトルデータベース Linked データベース種別ごとのトレンドの移り変わり ベクトルデータベース
MongoDB 事例数 顧客満足度 圧倒的 No.1! Retool社のレポート MongoDB は DB Ranking 5位
ベクトルデータベースに求められる要件 •簡単にスモールスタート可能 ◦ ラーニングコストが少ない ◦ 簡単にアプリに組み込み ◦ ノーコスト/ローコストではじめられる ◦ インフラ管理不要
•複雑なクエリ要件に対応 ◦ あらゆるデータをベクトルデータと一緒に 保存可能 ◦ 複雑なDBクエリとベクトル検索を組み合わせ 可能 ◦ ベクトルデータの二重持ち、上書きなどのアプ リ仕様の変更に柔軟に対応可能 •LLMアプリへの組み込み容易性 ◦ クラウドサービスとのコラボレーション ◦ LLMアプリ開発フレームワークとの統合 ◦ アプリコードの自動生成 •スケーラブル・低レイテンシ ◦ 大量アクセス・大量データに対応できる ◦ アクセス急増に応じてスケールできる ◦ 低レイテンシ •エンタープライズレベルのセキュリティ ◦ VPC Peering/IPアクセス制御 ◦ 暗号化 ◦ 認証・認可 ◦ 監査ログモニタリング/アラート
ベクトルデータベースに求められる要件 •簡単にスモールスタート可能 ◦ ラーニングコストが少ない ◦ 簡単にアプリに組み込み ◦ ノーコスト/ローコストではじめられる ◦ インフラ管理不要
•複雑なクエリ要件に対応 ◦ あらゆるデータをベクトルデータと一緒に 保存可能 ◦ 複雑なDBクエリとベクトル検索を組み合わせ 可能 ◦ ベクトルデータの二重持ち、上書きなどのアプ リ仕様の変更に柔軟に対応可能 •LLMアプリへの組み込み容易性 ◦ クラウドサービスとのコラボレーション ◦ LLMアプリ開発フレームワークとの統合 ◦ アプリコードの自動生成 •スケーラブル・低レイテンシ ◦ 大量アクセス・大量データに対応できる ◦ アクセス急増に応じてスケールできる ◦ 低レイテンシ •エンタープライズレベルのセキュリティ ◦ VPC Peering/IPアクセス制御 ◦ 暗号化 ◦ 認証・認可 ◦ 監査ログモニタリング/アラート
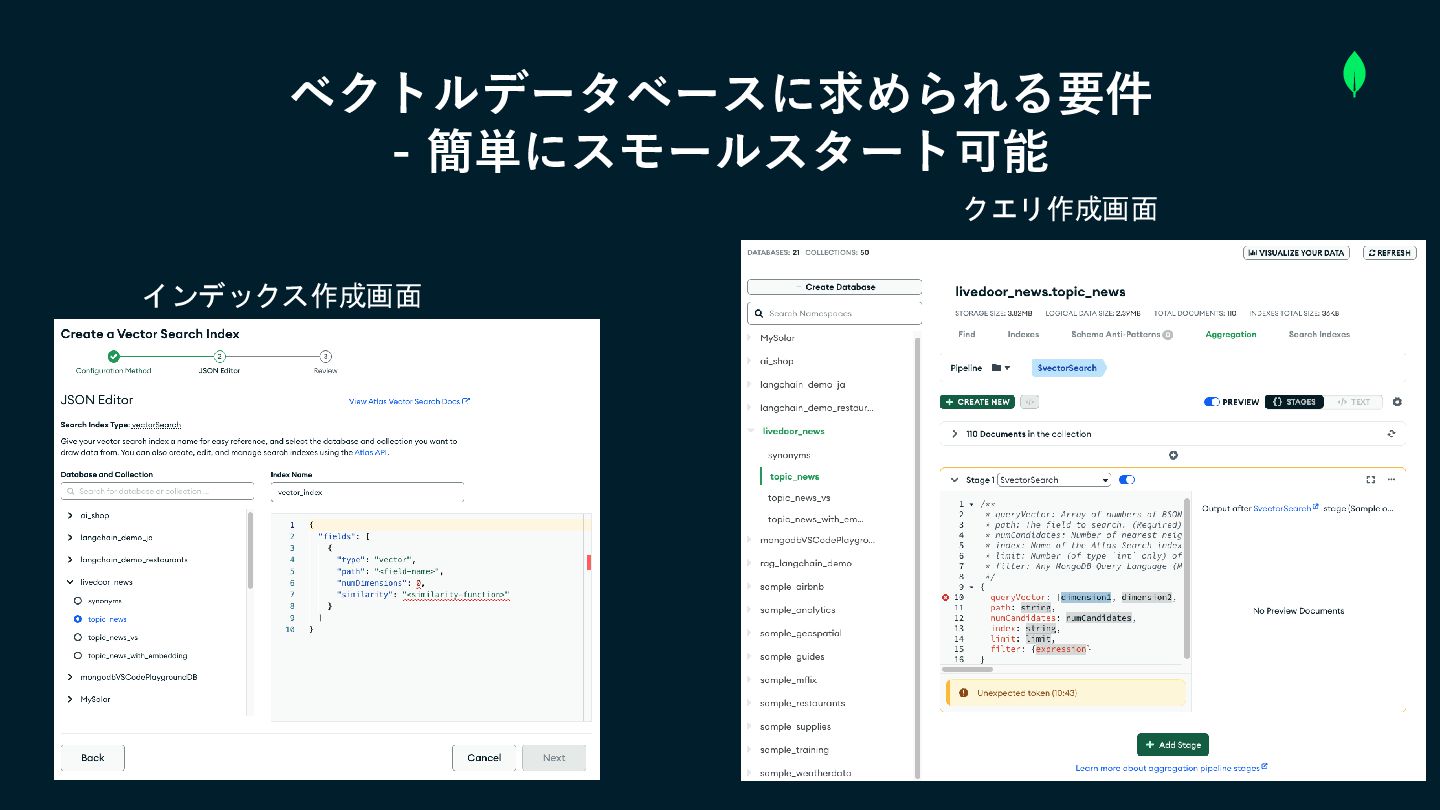
ベクトルデータベースに求められる要件 - 簡単にスモールスタート可能 クエリ作成画面 インデックス作成画面
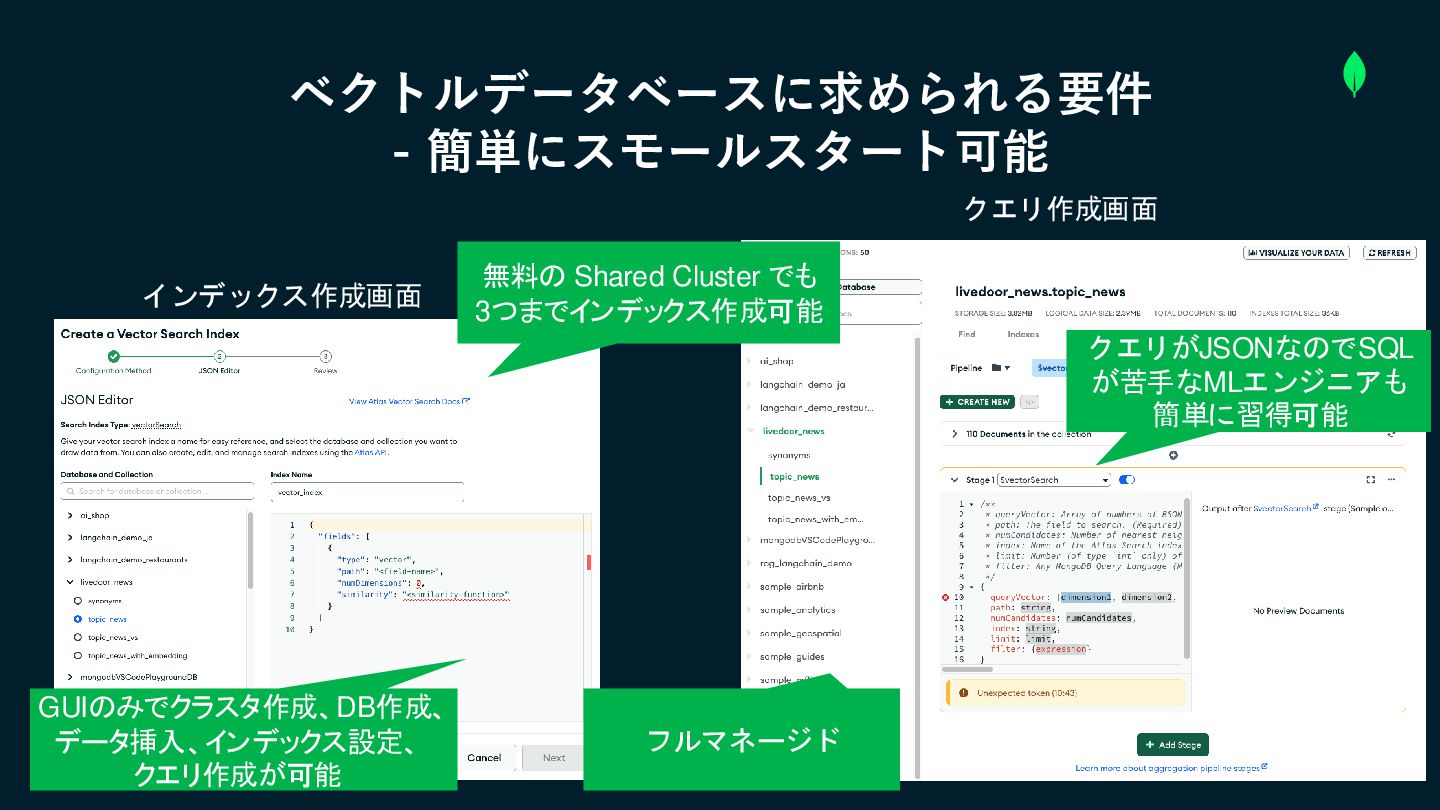
ベクトルデータベースに求められる要件 - 簡単にスモールスタート可能 クエリ作成画面 インデックス作成画面 フルマネージド クエリがJSONなのでSQL が苦手なMLエンジニアも 簡単に習得可能 無料の
Shared Cluster でも 3つまでインデックス作成可能 GUIのみでクラスタ作成、DB作成、 データ挿入、インデックス設定、 クエリ作成が可能
ベクトルデータベースに求められる要件 •簡単にスモールスタート可能 ◦ ラーニングコストが少ない ◦ 簡単にアプリに組み込み ◦ ノーコスト/ローコストではじめられる ◦ インフラ管理不要
•複雑なクエリ要件に対応 ◦ あらゆるデータをベクトルデータと一緒に 保存可能 ◦ 複雑なDBクエリとベクトル検索を組み合わせ 可能 ◦ ベクトルデータの二重持ち、上書きなどのアプ リ仕様の変更に柔軟に対応可能 •LLMアプリへの組み込み容易性 ◦ クラウドサービスとのコラボレーション ◦ LLMアプリ開発フレームワークとの統合 ◦ アプリコードの自動生成 •スケーラブル・低レイテンシ ◦ 大量アクセス・大量データに対応できる ◦ アクセス急増に応じてスケールできる ◦ 低レイテンシ •エンタープライズレベルのセキュリティ ◦ VPC Peering/IPアクセス制御 ◦ 暗号化 ◦ 認証・認可 ◦ 監査ログモニタリング/アラート
Vector Search GEN AI powered APP LLM Prompt Context Orchestration
Layer Single View _id: ObjectID(‘62f13a3fe7321ca47aecb216’) symbol: “ABMD” quarter: 4 year: 2021 Date: 2021-04-29T20:10:40.000+00:00 Content: “Operator: Ladies and gentleman, thank you for standing by, and welcome…” Content_embeddings: Array 0: 0.03898080065846443 1: -0.05879044905304909 2: 0.04323239979442215 3: -0.021337900310754776 4: -0.036346953362226486 5: 0.028689613565802574 6: -0.03514527902007103 7: -0.07414846867322922 8: -0.00993054173886776 9: 0.007234036456793547 10: -0.03197460621595383 ドキュメントに格納される埋め込みベクトルの例 ベクトル埋め込み
ベクトルデータベースに求められる要件 - 複雑なクエリ要件に対応 db.embedded_movies.aggregate([ {"$vectorSearch": { "index": "rrf-vector-search", "path": "plot_embedding",
"queryVector": [-0.0105516575,-0.014830452,...], "numCandidates": 100, "limit": 20}}, {"$project": { "vs_score": 1,"_id": "$docs._id","title": "$docs.title"} {"$unionWith": { "coll": "movies","pipeline": [ {"$search": { "index": "rrf-full-text-search", "phrase": {"query": "new york","path": "title"}}},{ "$project": { "fts_score": 1, "_id": "$docs._id", "title": "$docs.title"}]}}, {"$group": { "_id": "$title", "vs_score": {"$max": "$vs_score"}, "fts_score": {"$max": "$fts_score"}}}, {"$project": { "_id": 1,"title": 1, "vs_score": {"$ifNull": ["$vs_score", 0]}, "fts_score": {"$ifNull": ["$fts_score", 0]}}}, {"$sort": {"score": -1}}, {"$limit": 10} ]) ベクトル検索 全文検索 DBクエリ
ベクトルデータベースに求められる要件 - 複雑なクエリ要件に対応 db.embedded_movies.aggregate([ {"$vectorSearch": { "index": "rrf-vector-search", "path": "plot_embedding",
"queryVector": [-0.0105516575,-0.014830452,...], "numCandidates": 100, "limit": 20}}, {"$project": { "vs_score": 1,"_id": "$docs._id","title": "$docs.title"} {"$unionWith": { "coll": "movies","pipeline": [ {"$search": { "index": "rrf-full-text-search", "phrase": {"query": "new york","path": "title"}}},{ "$project": { "fts_score": 1, "_id": "$docs._id", "title": "$docs.title"}]}}, {"$group": { "_id": "$title", "vs_score": {"$max": "$vs_score"}, "fts_score": {"$max": "$fts_score"}}}, {"$project": { "_id": 1,"title": 1, "vs_score": {"$ifNull": ["$vs_score", 0]}, "fts_score": {"$ifNull": ["$fts_score", 0]}}}, {"$sort": {"score": -1}}, {"$limit": 10} ]) 長文テキスト、非構造データ、複雑な半構造 化データなどを格納可能な多様なスキーマ アプリ側の変更に簡単に追従可能なデータ モデル 単独クエリでDBクエリ、全文検索、 ベクトル検索クエリを実現可能なクエリ 言語とインデックス ACIDトランザクション
ベクトルデータベースに求められる要件 •簡単にスモールスタート可能 ◦ ラーニングコストが少ない ◦ 簡単にアプリに組み込み ◦ ノーコスト/ローコストではじめられる ◦ インフラ管理不要
•複雑なクエリ要件に対応 ◦ あらゆるデータをベクトルデータと一緒に 保存可能 ◦ 複雑なDBクエリとベクトル検索を組み合わせ 可能 ◦ ベクトルデータの二重持ち、上書きなどのアプ リ仕様の変更に柔軟に対応可能 •LLMアプリへの組み込み容易性 ◦ クラウドサービスとのコラボレーション ◦ LLMアプリ開発フレームワークとの統合 ◦ アプリコードの自動生成 •スケーラブル・低レイテンシ ◦ 大量アクセス・大量データに対応できる ◦ アクセス急増に応じてスケールできる ◦ 低レイテンシ •エンタープライズレベルのセキュリティ ◦ VPC Peering/IPアクセス制御 ◦ 暗号化 ◦ 認証・認可 ◦ 監査ログモニタリング/アラート
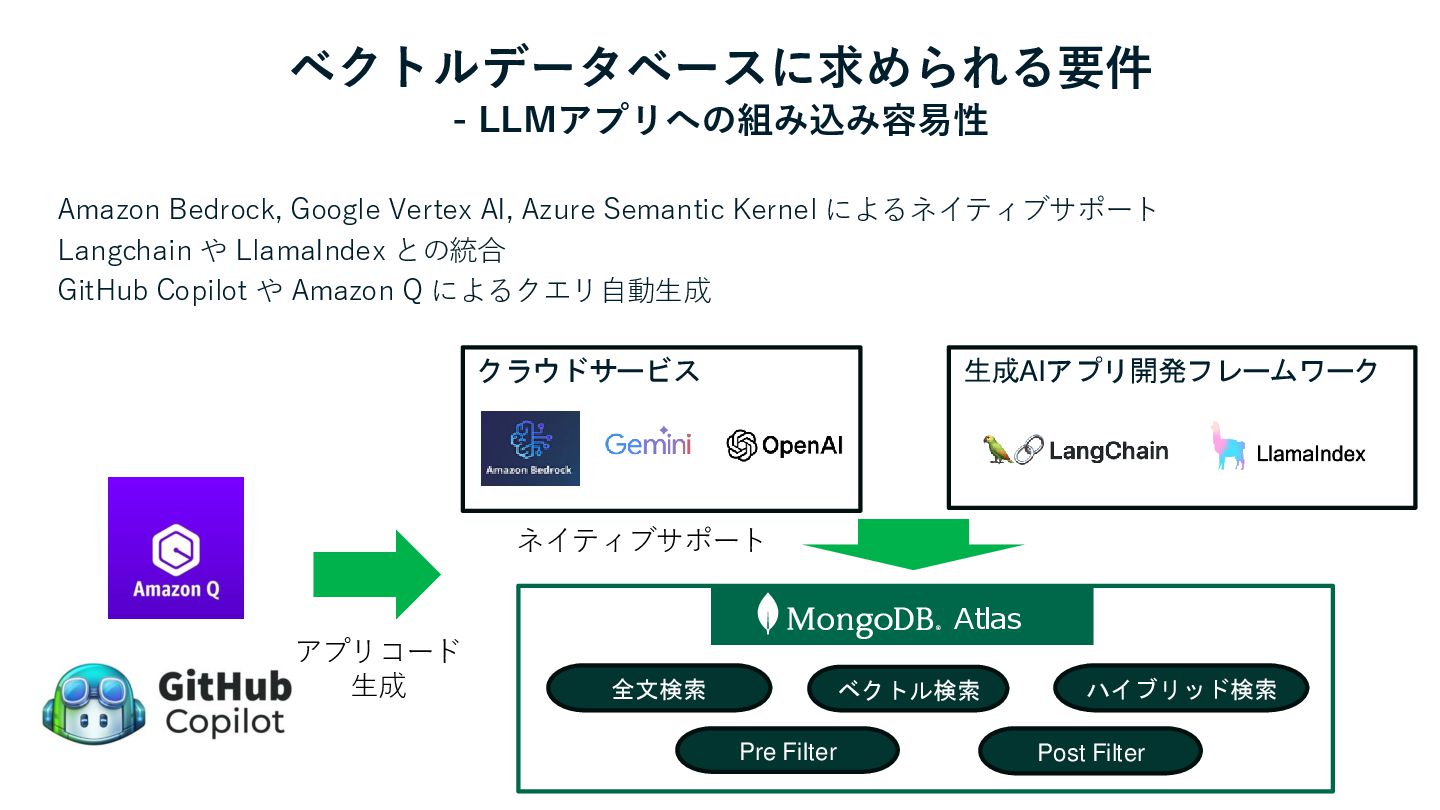
ベクトルデータベースに求められる要件 - LLMアプリへの組み込み容易性 Atlas ベクトル検索 Pre Filter Post Filter 全文検索
ハイブリッド検索 クラウドサービス 生成AIアプリ開発フレームワーク Amazon Bedrock, Google Vertex AI, Azure Semantic Kernel によるネイティブサポート Langchain や LlamaIndex との統合 GitHub Copilot や Amazon Q によるクエリ自動生成 アプリコード 生成 ネイティブサポート
ベクトルデータベースに求められる要件 •簡単にスモールスタート可能 ◦ ラーニングコストが少ない ◦ 簡単にアプリに組み込み ◦ ノーコスト/ローコストではじめられる ◦ インフラ管理不要
•複雑なクエリ要件に対応 ◦ あらゆるデータをベクトルデータと一緒に 保存可能 ◦ 複雑なDBクエリとベクトル検索を組み合わせ 可能 ◦ ベクトルデータの二重持ち、上書きなどのアプ リ仕様の変更に柔軟に対応可能 •LLMアプリへの組み込み容易性 ◦ クラウドサービスとのコラボレーション ◦ LLMアプリ開発フレームワークとの統合 ◦ アプリコードの自動生成 •スケーラブル・低レイテンシ ◦ 大量アクセス・大量データに対応できる ◦ アクセス急増に応じてスケールできる ◦ 低レイテンシ •エンタープライズレベルのセキュリティ ◦ VPC Peering/IPアクセス制御 ◦ 暗号化 ◦ 認証・認可 ◦ 監査ログモニタリング/アラート
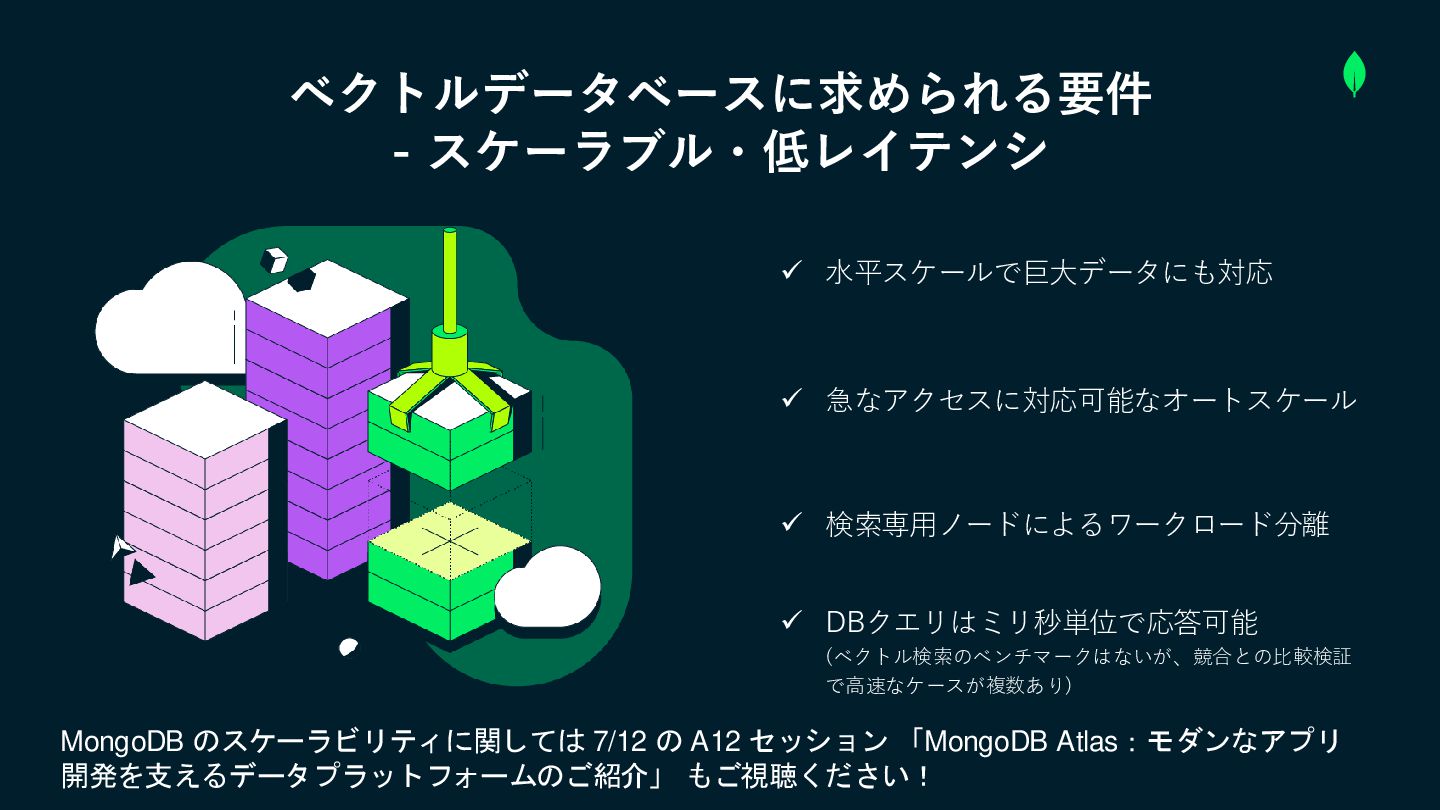
ベクトルデータベースに求められる要件 - スケーラブル・低レイテンシ ✓ 水平スケールで巨大データにも対応 ✓ 急なアクセスに対応可能なオートスケール ✓ DBクエリはミリ秒単位で応答可能 (ベクトル検索のベンチマークはないが、競合との比較検証
で高速なケースが複数あり) MongoDB のスケーラビリティに関しては 7/12 の A12 セッション 「MongoDB Atlas:モダンなアプリ 開発を支えるデータプラットフォームのご紹介」 もご視聴ください! ✓ 検索専用ノードによるワークロード分離
ベクトルデータベースに求められる要件 •簡単にスモールスタート可能 ◦ ラーニングコストが少ない ◦ 簡単にアプリに組み込み ◦ ノーコスト/ローコストではじめられる ◦ インフラ管理不要
•複雑なクエリ要件に対応 ◦ あらゆるデータをベクトルデータと一緒に 保存可能 ◦ 複雑なDBクエリとベクトル検索を組み合わせ 可能 ◦ ベクトルデータの二重持ち、上書きなどのアプ リ仕様の変更に柔軟に対応可能 •LLMアプリへの組み込み容易性 ◦ クラウドサービスとのコラボレーション ◦ LLMアプリ開発フレームワークとの統合 ◦ アプリコードの自動生成 •スケーラブル・低レイテンシ ◦ 大量アクセス・大量データに対応できる ◦ アクセス急増に応じてスケールできる ◦ 低レイテンシ •エンタープライズレベルのセキュリティ ◦ VPC Peering/IPアクセス制御 ◦ 暗号化 ◦ 認証・認可 ◦ 監査ログモニタリング/アラート
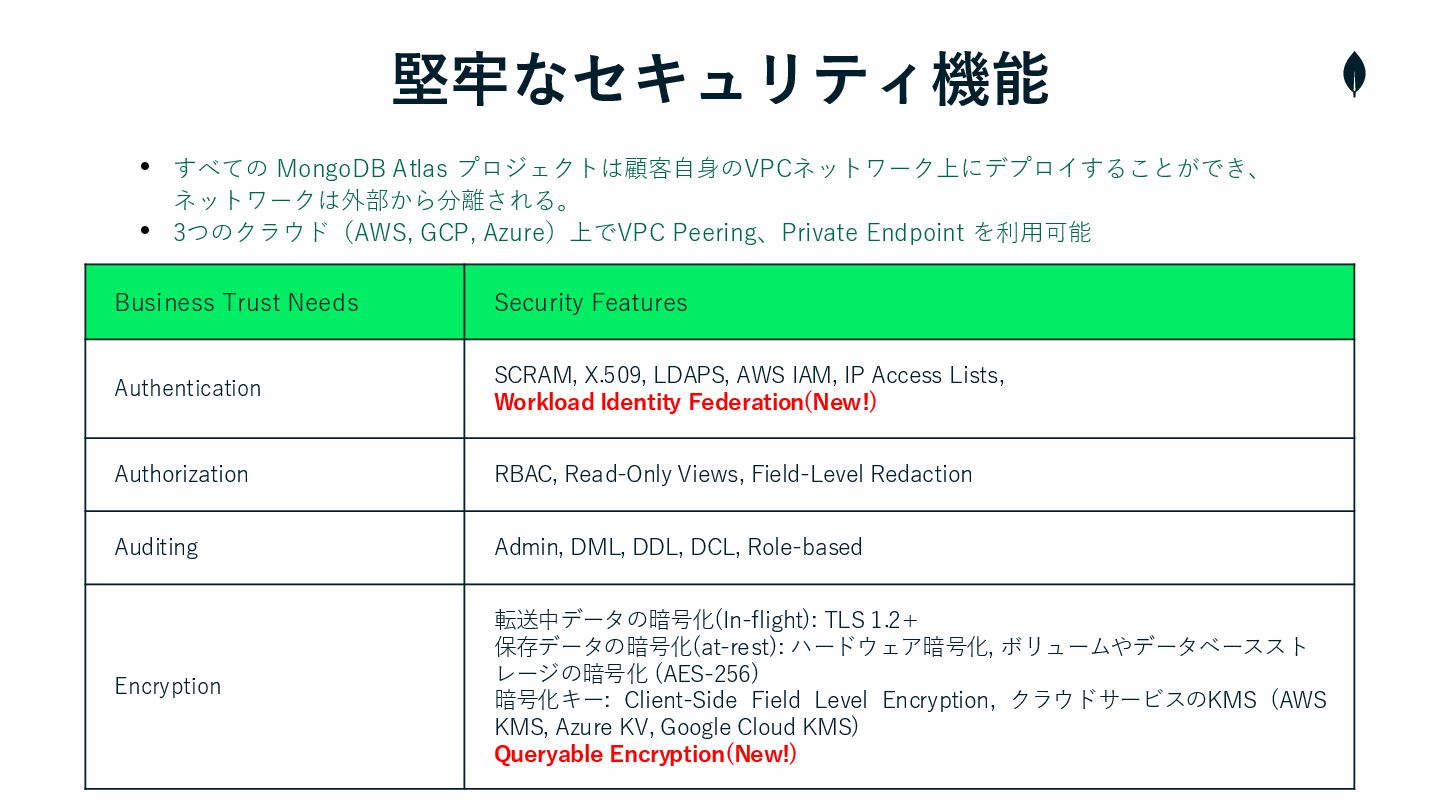
堅牢なセキュリティ機能 Business Trust Needs Security Features Authentication SCRAM, X.509, LDAPS,
AWS IAM, IP Access Lists, Workload Identity Federation(New!) Authorization RBAC, Read-Only Views, Field-Level Redaction Auditing Admin, DML, DDL, DCL, Role-based Encryption 転送中データの暗号化(In-flight): TLS 1.2+ 保存データの暗号化(at-rest): ハードウェア暗号化, ボリュームやデータベーススト レージの暗号化 (AES-256) 暗号化キー: Client-Side Field Level Encryption, クラウドサービスのKMS (AWS KMS, Azure KV, Google Cloud KMS) Queryable Encryption(New!) • すべての MongoDB Atlas プロジェクトは顧客自身のVPCネットワーク上にデプロイすることができ、 ネットワークは外部から分離される。 • 3つのクラウド(AWS, GCP, Azure)上でVPC Peering、Private Endpoint を利用可能
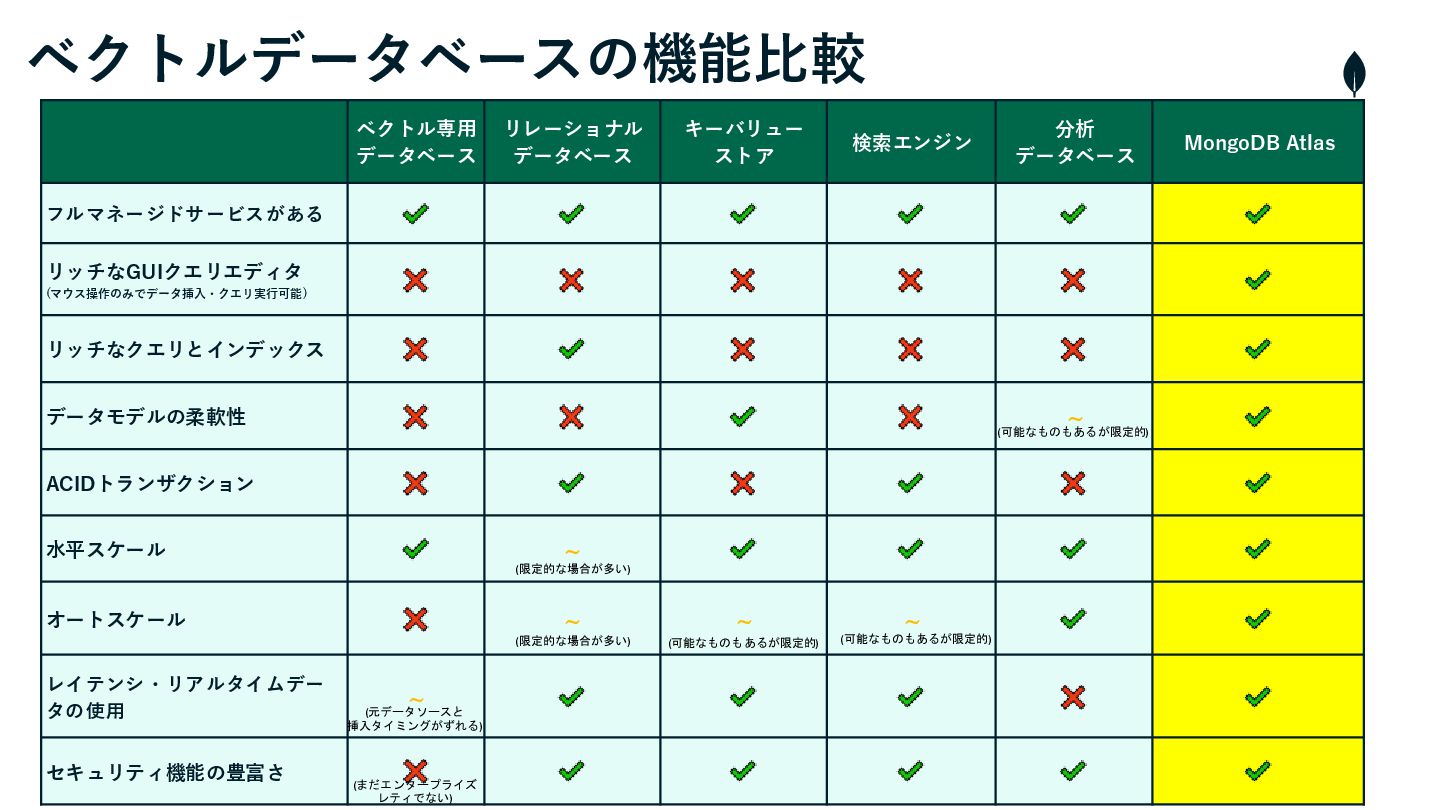
ベクトルデータベースの機能比較 ベクトル専用 データベース リレーショナル データベース キーバリュー ストア 検索エンジン 分析 データベース
MongoDB Atlas フルマネージドサービスがある リッチなGUIクエリエディタ (マウス操作のみでデータ挿入・クエリ実行可能) リッチなクエリとインデックス データモデルの柔軟性 ~ ACIDトランザクション 水平スケール ~ オートスケール ~ ~ ~ レイテンシ・リアルタイムデー タの使用 ~ セキュリティ機能の豊富さ (限定的な場合が多い) (限定的な場合が多い) (可能なものもあるが限定的) (可能なものもあるが限定的) (元データソースと 挿入タイミングがずれる) (まだエンタープライズ レティでない) (可能なものもあるが限定的)
ベクトルデータベースの要件とMongoDB の機能まとめ •簡単にスモールスタート可能 ◦ クエリがJSON形式のためSQLが苦手なアプリ/ML エンジニアにも使いやすい ◦ GUIのみでクラスタ作成、DB作成、データ挿入、イ ンデックス設定、クエリ作成が可能 ◦
無料のShared Clusterで簡単に機能を試せる ◦ フルマネージドサービス •複雑なクエリ要件に対応 ◦ 長文テキスト、非構造データ、複雑な半構造化 データなどを格納可能な多様なスキーマ ◦ アプリ側の変更に簡単に追従可能なデータモデル ◦ 単独クエリでDBクエリ、全文検索、ベクトル検索 クエリを実現可能なクエリ言語とインデックス ◦ ACIDトランザクション •LLMアプリへの組み込み容易性 ◦ Amazon Bedrock, Google Vertex AI, Azure Semantic Kernel によるネイティブサポート ◦ Langchain や LlamaIndex との統合 ◦ GitHub Copilot や Amazon Q によるクエリ自動生成 • スケーラブル・低レイテンシ ◦ 水平スケールで巨大データにも対応 ◦ 急なアクセスに対応可能なオートスケール ◦ 検索専用ノードによるワークロード分離 ◦ DBクエリはミリ秒単位で応答可能 (ベクトル検索のベンチマークはないが、競合との比較検証で高速なケースが複数あり) • エンタープライズレベルのセキュリティ ◦ VPC Peering/IPアクセス制御 ◦ 暗号化(In flight, At rest, Queryable Encryption) ◦ 認証・認可(プロジェクト/クラスタ/DB/コレクションレベル) ◦ 監査ログモニタリング/アラート
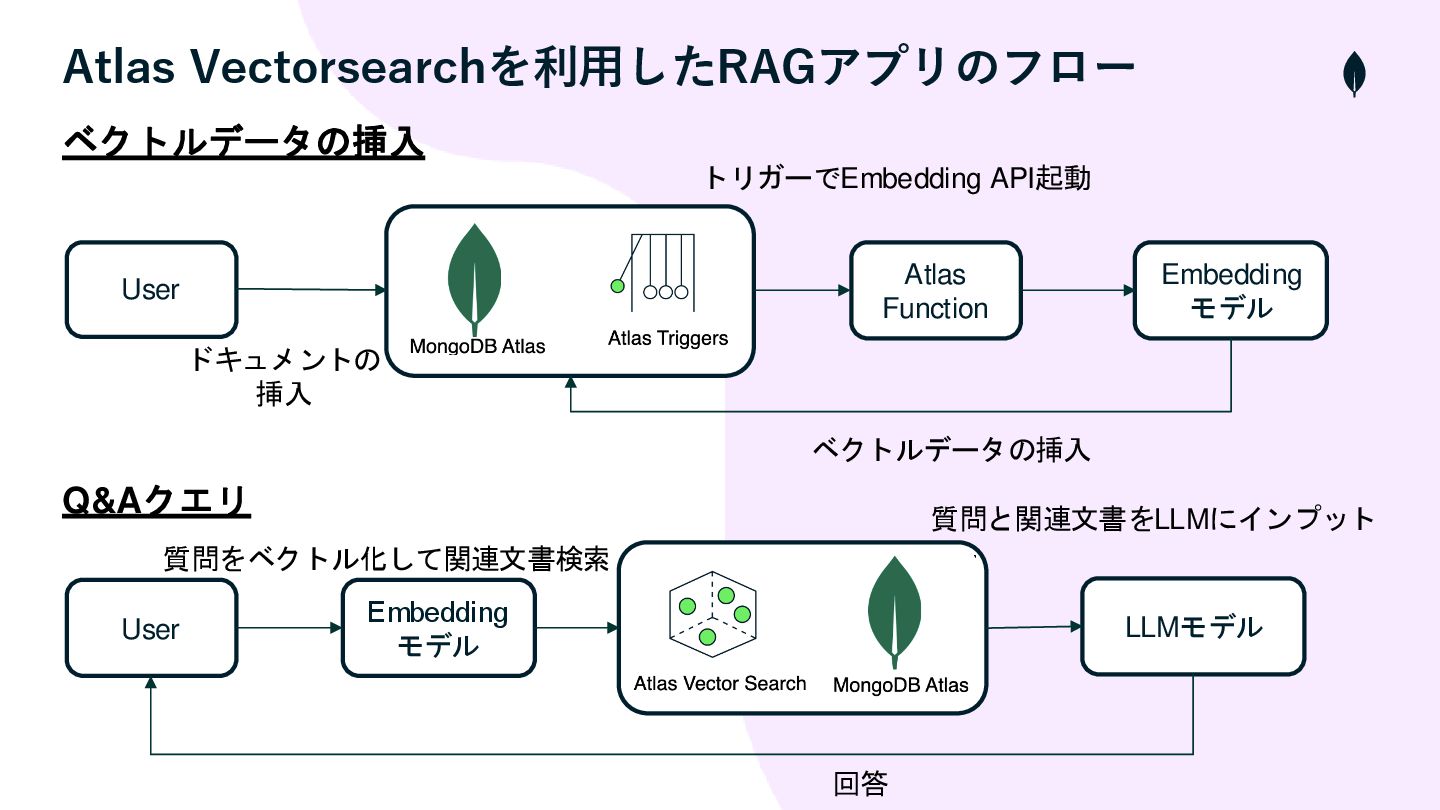
Atlas Vectorsearchを利用したRAGアプリのフロー User Atlas Function Embedding モデル User Embedding モデル
LLMモデル ベクトルデータの挿入 Q&Aクエリ ベクトルデータの挿入 ドキュメントの 挿入 トリガーでEmbedding API起動 回答 質問をベクトル化して関連文書検索 質問と関連文書をLLMにインプット
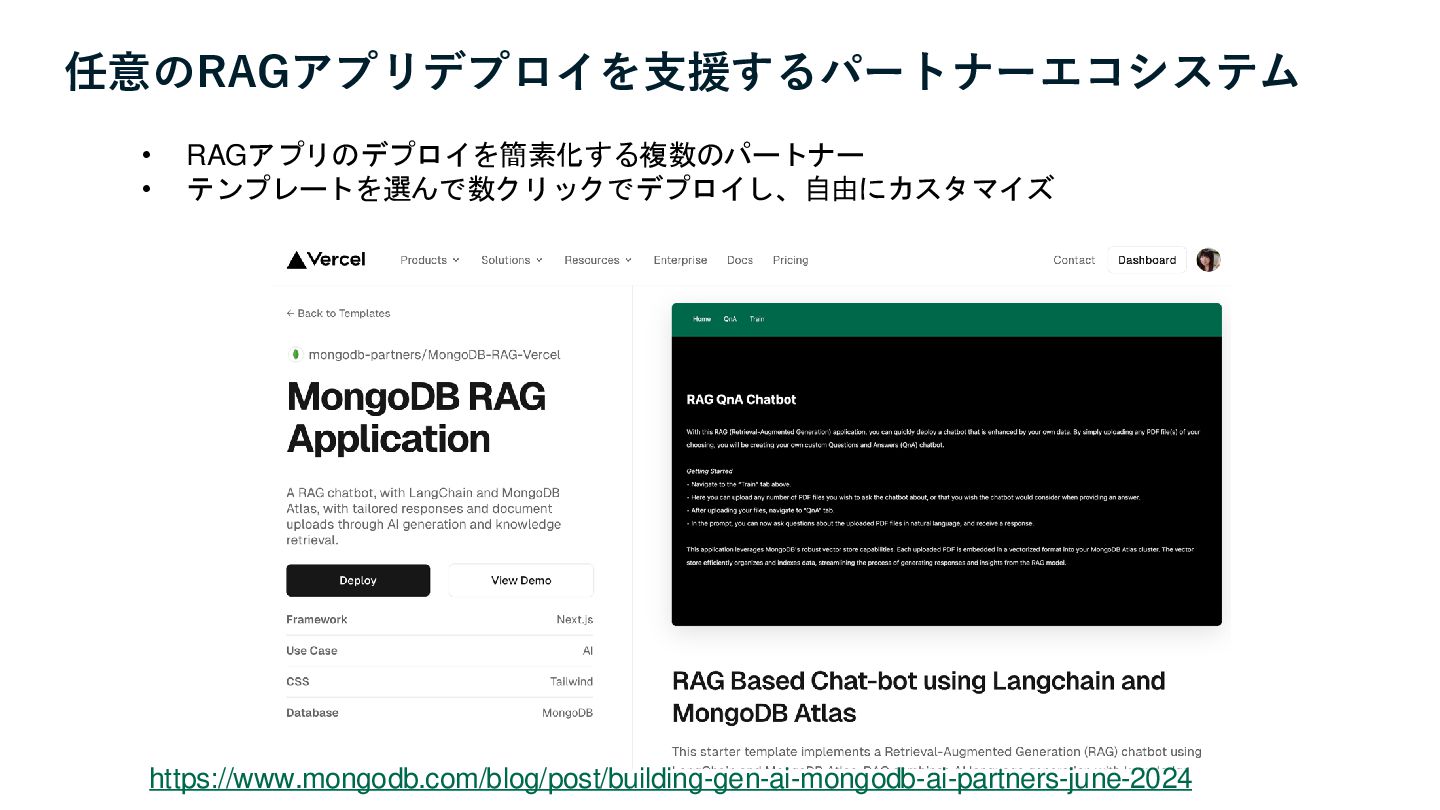
任意のRAGアプリデプロイを支援するパートナーエコシステム https://www.mongodb.com/blog/post/building-gen-ai-mongodb-ai-partners-june-2024 • RAGアプリのデプロイを簡素化する複数のパートナー • テンプレートを選んで数クリックでデプロイし、自由にカスタマイズ
MongoDB Atlasの機能は、期限なし 無料の M0 クラスタで簡単にお試し いただけます ※本番環境としては、課金が必要なM10以上の利用をおすすめします ※ M0クラスタでは、データサイズやインデックス数などの機能制限があります
Q&A ご質問がありましたら、どうぞブースにきてお気軽にお声がけ ください! フィードバック QRコードをスキャンして、セッション アンケートにご協力ください。 ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![関連文書の抽出方法:ベクトル検索 ユーザID 文書種別 日付 [0.3, 0.4, 0.2, 0.1…] 数字の配列で示される ベクトル](https://files.speakerdeck.com/presentations/8035a07261914824879a658ccaec4cb7/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}