Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
atmaCup#19 2nd Place Solution
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
chimuichimu
April 11, 2025
480
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
atmaCup#19 2nd Place Solution
chimuichimu
April 11, 2025
More Decks by chimuichimu
See All by chimuichimu
書籍紹介:アジャイルなチームをつくる ふりかえりガイドブック
chimuichimu
0
140
朝 Kaggle のすすめ
chimuichimu
3
700
Wantedly Visit における相互推薦システムの活用事例
chimuichimu
1
380
データ駆動で実現する、人と企業のマッチング
chimuichimu
0
170
PydanticAI × Logfire ではじめる LLM エージェントのモニタリング
chimuichimu
3
1.5k
ウォンテッドリーの推薦システム開発を支える評価とデプロイの仕組み
chimuichimu
1
1.8k
進化計算ライブラリ DEAP の紹介
chimuichimu
2
360
Spotify Web API を使った分析で新しいお気に入りアーティストを発見する
chimuichimu
3
360
非競プロ勢によるUSPTOコンペ参加記
chimuichimu
2
3k
Featured
See All Featured
Writing Fast Ruby
sferik
630
63k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
220
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Into the Great Unknown - MozCon
thekraken
41
2.6k
Raft: Consensus for Rubyists
vanstee
141
7.6k
HDC tutorial
michielstock
2
740
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Transcript
2025/4/11 (金) atmaCup#19 振り返り会資料 2nd Place Solution takaito chimuichimu
2 自己紹介 (takaito) 名前: 高野 海斗 略歴: 2021年3月: 博士後期課程 修了
(理工学博士) 2021年4月: 資産運用会社 入社 (クオンツ・アナリスト) 専門分野: 自然言語処理,モデル開発,リサーチ データ分析コンペをやり始めたきっかけが atmaCup! 直近のatmaCupの成績 #17 4th (Solo) & nyk510賞 #18 5th (Team suk1yak1さん) #19 2nd (Team chimuichimuさん) & nyk510賞
3 自己紹介 (chimuichimu) 名前: 市村 千晃 略歴: 2017年3月: 修士課程 修了
(宇宙物理) 2017年4月: システムエンジニア@SIer 2021年5月: データサイエンティスト@SIer 2024年3月: データサイエンティスト@ウォンテッドリー株式会社 専門分野: 推薦システム 今年の目標: Kaggle Master になりたい!
4 目次 • ソリューション ◦ 概要 ◦ takaito part ◦
chimuichimu part ◦ アンサンブル • コンペの取り組み方
5 目次 • ソリューション ◦ 概要 ◦ takaito part ◦
chimuichimu part ◦ アンサンブル • コンペの取り組み方
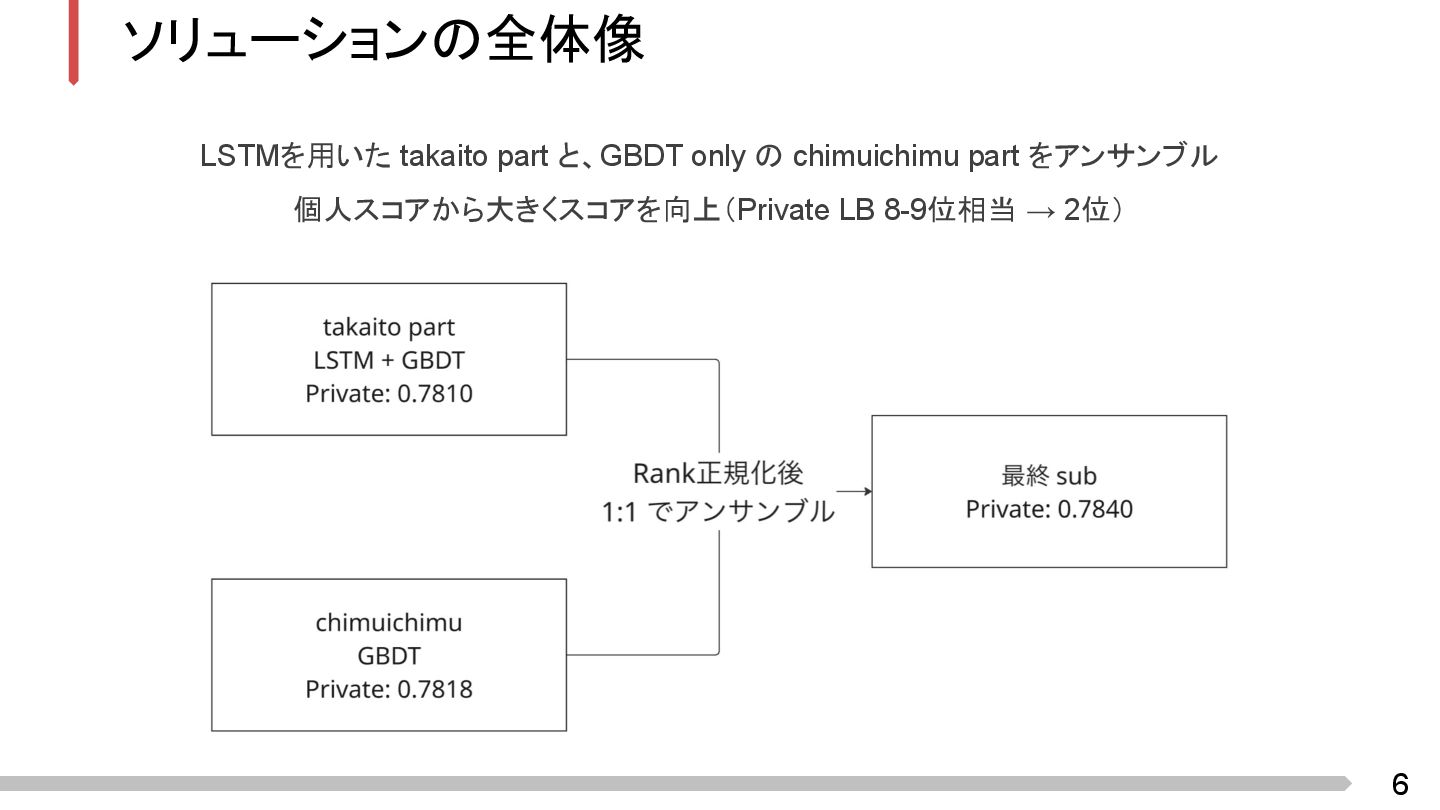
6 ソリューションの全体像 LSTMを用いた takaito part と、GBDT only の chimuichimu part
をアンサンブル 個人スコアから大きくスコアを向上(Private LB 8-9位相当 → 2位)
7 目次 • ソリューション ◦ 概要 ◦ takaito part ◦
chimuichimu part ◦ アンサンブル • コンペの取り組み方
8 概要 optuna使って,各目的変数ごとに以下のモデル群の出力の適切な加重平均を計算 ・ lightgbm ver1 ・ lightgbm ver4 ・
xgboost ver1 ・ xgboost ver4 ・ catboost ver1 ・ LSTM ver1 ・ LSTM ver3 ・ LSTM ver6 ・ BiLSTM ver1 ・ BiLSTM ver3 ・ BiLSTM ver6 ・ verの違いは使用する特徴量 ・ 最終的なweightは 勾配ブースティング系 : LSTM系 = 1 : 3 くらい ・ 特徴量を加えれば加えるほど単一モデルの性能は向上 ・ LSTM系のモデルが重要なので,本日はそちらのみを紹介
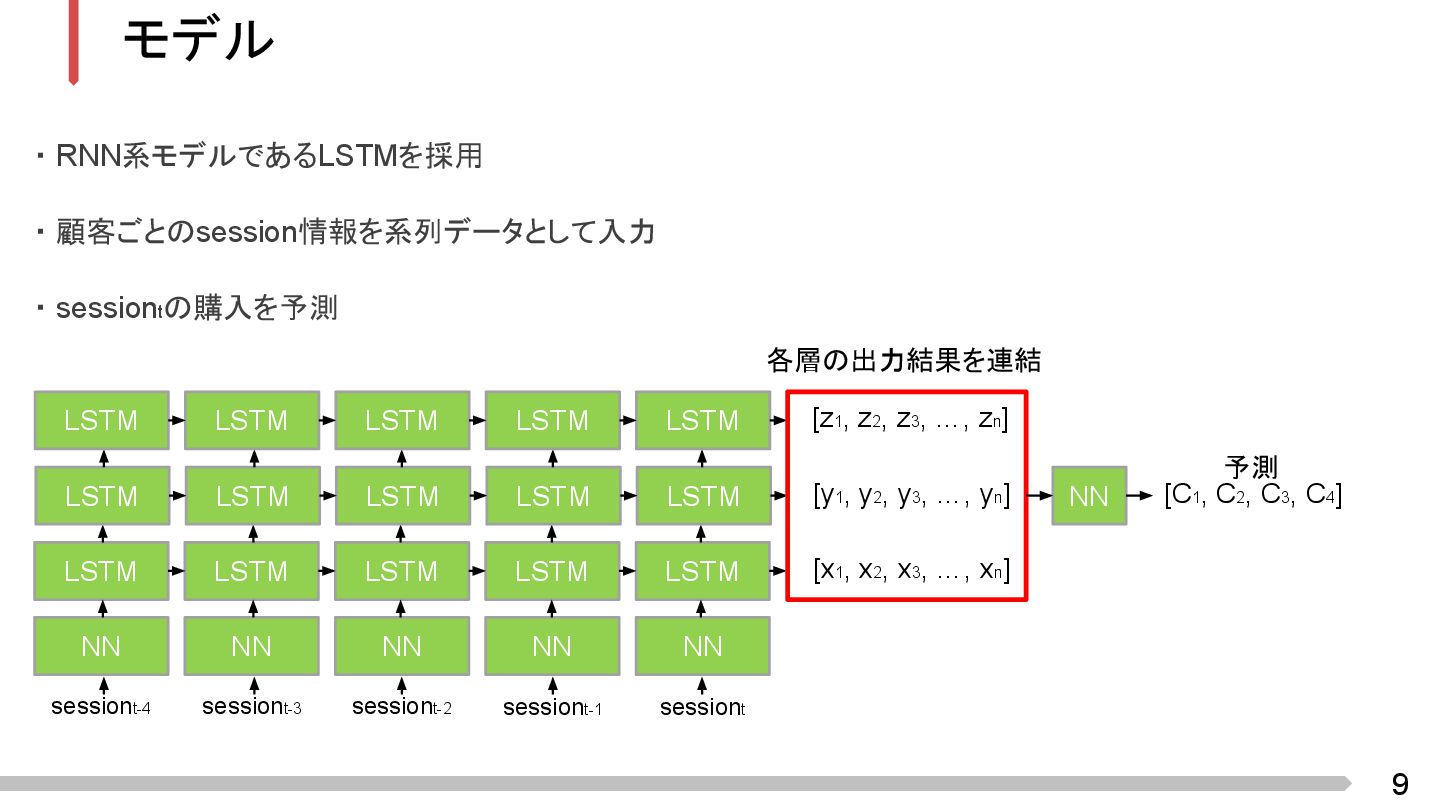
9 モデル ・ RNN系モデルであるLSTMを採用 ・ 顧客ごとのsession情報を系列データとして入力 ・ sessiontの購入を予測 LSTM LSTM
LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM [x1 , x2 , x3 , …, xn ] [y1 , y2 , y3 , …, yn ] [z1 , z2 , z3 , …, zn ] NN 各層の出力結果を連結 [C1 , C2 , C3 , C4 ] NN NN NN NN NN sessiont sessiont-1 sessiont-2 sessiont-3 sessiont-4 予測
10 session系列の作成 ・ 基本的な特徴量 ・ 時刻,曜日,祝日など(時間情報) ・ 年代,性別(ユーザー情報) ・ 店舗情報
・ shift特徴量 ・ 予測対象の購入フラグ,購入数など ・ 各カテゴリの購入数VectorをSVDで次元圧縮したembedding ・ 支払い額,割引額など sessiont 基本的な特徴量 時刻: 18 曜日: 火曜 年齢: 30代 店舗: X店 shift特徴量 チョコ購入数: 1 ビール購入数: 2 : SVD1: 0.6 SVD2: 0.4 : 支払い額: 7000円 割引額: 200円 sessiont-1 基本的な特徴量 時刻: 14 曜日: 日曜 年齢: 30代 店舗: X店 shift特徴量 チョコ購入数: NA ビール購入数: NA : SVD1: NA SVD2: NA : 支払い額: NA 割引額: NA shift [C1 , C2 , C3 , C4 , …, Cn ] SVD [SVD1 , SVD2 , SVD3 , …, SVD32 ]
11 工夫点 ・ テストデータは先頭sessionのみであるが,学習データ確保のために同日の sessionに関しても学習時に使用 ・ ランダムにsession系列をカットすることによる Data Augmentation ・
各sessionの予測ではなく,t時点のsessionのみを予測することで学習を安定させる ・ t時点のsessionのみ予測することから, BiLSTM(双方向LSTM)に拡張してもReakしない (予測対象日の時刻や曜日,店舗などの情報を踏まえた上で情報を流せるのが大きな強みになる) カット!
12 目次 • ソリューション ◦ 概要 ◦ takaito part ◦
chimuichimu part ◦ アンサンブル • コンペの取り組み方
概要 • 主に顧客の購買情報をベースにした特徴量(合計300程度)を作成 • GBDT モデルを全期間データで学習 • LightGBM と XGBoost
をアンサンブル 13
特徴量 • 顧客 x 売上日の集約特徴量 ← 特に重要(詳細は次ページ) • embedding ベースの特徴量
• 属性ごと(年代、性別、年代*性別、、、)のターゲットカテゴリの発生確率 • 属性(店舗、年代、性別) • 時間特徴(日、休日、祝日、翌日が休日) 14
特徴量(顧客 x 売上日の集約特徴量) • 顧客 x 売上日単位で集約特徴量を作成 ◦ 顧客単位で集約しないのは、未来の情報のリークを防ぐため ◦
過去のセッション数、売上数量、商品数、、、 ◦ 過去の {カテゴリ} に対するセッション数、売上数量、購買確率、、、 ターゲットのカテゴリ (ビールをよく買う人は、次も買うかも) 共起カテゴリ (酒好きの人は、次はビールを買うかも) 阻害カテゴリ (米10kg買ったら、しばらく米は買わなそう) 15
モデリング • ターゲットカテゴリごとに GBDT で2値分類モデルを学習 • LightGBM と XGBoost を使用
◦ スコアに大差はなし • Test 予測時は全期間のデータを使用 ◦ スコアが大きく改善 ◦ early stopping は使えないので、CV の best round + 定数で学習 • 10月後半のデータを学習・評価から除外(詳細は次ページ) 16
モデリング(10月後半データの扱い) • 10月後半に全店舗、全ターゲットカテゴリで売上が上昇 ◦ 何らかの大規模なセールやポイントキャンペーンなどが行われたと予想 • 方針 ◦ 平常と異なる購買行動にモデルが fit
しないよう学習・評価から除外 ◦ ただ購買したという情報は使いたいので、test 推論の特徴量計算には使用 17
18 目次 • ソリューション ◦ 概要 ◦ takaito part ◦
chimuichimu part ◦ アンサンブル • コンペの取り組み方
19 チームでのアンサンブルに関して 最終サブに関して ・ サブ数に余裕があったため LBを見ながら,chimuichimuさんと自身のサブをRank正規化してアンサンブル ・ いったん5:5を試した後に,6:4や4:6も試したが,5:5がLBでベスト (こちらを最終サブとして選択 )
余談 ・ 出力の分布とかを見たところ大きく差はなかったので,そのままの出力でアンサンブルを試したが LBは悪化した ・ コンペ終了後に確認したところ, chimuichimuさんとのアンサンブルはLSTM系のモデルのみの方が良かった ・ 仮にchimuichimuさんのサブは変えず,BiLSTMのみを5:5でアンサンブルしたところ Public: 0.7855 (Topは0.7853), Private: 0.7846 (Topは0.7843) であった...(その後0.7848まで更新) ・ 自身の手元のみでは,勾配ブースティング系を 25%混ぜた方が良かったが,chimuichimuさんのサブは勾配ブースティング系 だったので,これらをそこまで混ぜる必要がなかったようでした ・ 検証の仕方が異なっていたことや時間の制約でこのあたりこだわれなかったのは反省点
20 目次 • ソリューション ◦ 概要 ◦ takaito part ◦
chimuichimu part ◦ アンサンブル • コンペの取り組み方
21 atmaCup開催中に考えていたこと (takaito) 前提 1. 土日に多くの初学者が手を動かせるようにチュートリアル的なディスカッションは早めに投稿したい 2. チームを組みたいのでサブ数は押さえたい 3. 他にもやることたくさんあるので時間はそこまで取れない
実際の戦い方 ・ 1. は初日数時間で実装し,そのままサブの一部として使用することでソロでのスコアの底上げに寄与させた ・ 2. は早い段階でCVとLBの相関が得られる実験設定を見つけることができた (おかげで10/12が緑の画面) ・ 3. の解決策として,特徴量作りがあまり必要でないであろう NN系のモデルにメインの時間を割くことに決めた (過去の同じ曜日,店舗,時間帯の特徴量をどの程度 rollingするかなど,特徴量作成には時間がかかるため ) ・ 勾配ブースティングを使っている参加者の方が圧倒的に多い印象があり,チームマージの観点からも NN系を選択
意識していたこと(chimuichimu) • リークの防止 ◦ 時系列性があるコンペだったのでリークしないように注意した ◦ 特に atma のような短期コンペで事故が起きると取り返しがつかない ◦
特徴量に未来情報が入りこまないか?特徴量重要度が異常に高いものがないか? CV / LBの乖離 は?などをチェック • 限られた時間リソースへの対策 ◦ プライベートの事情で時間が取りづらいことが予め分かっていた ◦ やること / やらないことの線引き: testのコールドスタートユーザーは 10%弱程度しかいない → 顧客の 過去履歴をしっかり使いきるのが重要。 ECログは早々に使わない意思決定。 ◦ チームマージを見据えて早めに声をかける。マージを受けてもらえるよう、初速で良いスコアを出せる ように頑張る ◦ 朝早起きしてコンペに取り組む時間を確保 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}